ディープラーニングを使った異常検知が進歩していますが、最新情報を追うのが大変です。
ここでは、最新情報をまとめておきます(随時更新)。
本稿では、以下の内容を記します。
- ディープラーニングを使った異常検知について、簡単に歴史をまとめます。
- 最新の手法(2019年当時)について、ベンチマークを行います。
歴史
完全に独断と偏見で作った歴史です。
全ての論文は読めていないので、ご了承ください。
【~2017年】オートエンコーダによる異常検知
-
オートエンコーダによる異常検知
2、3年前はオートエンコーダによる異常検知が主流でした。オートエンコーダでは、元画像と再構築画像との差をとって、その和が大きいとき異常と認識させています。Qiitaの記事でも、オートエンコーダによる異常検知はたくさんありますので、気になる人は探してみてください。 -
Variational AutoEocoder(VAE)による異常検知(その1)
VAEはオートエンコーダを確率的に扱えるようにしたものです。従って、確率的にあり得るかどうか判定できるため、オートエンコーダよりも異常検知性能が良いとされています。 -
VAEによる異常検知(その2)
VAEを異常検知に使った場合、「頻出画像と似た構図のもの」は異常と見なされにくい傾向がありました。上記の論文では、損失関数の一部を取り出し、頻出であろうがなかろうが異常を見つけることに成功しています。
【2018年】特徴抽出器による異常検知
DOCは画期的な手法で、ディープラーニングを特徴抽出器として使うことで
データ(画像)に含まれる特徴をある部分に固めてしまう手法です。
個人的には、「ディープラーニングによる異常検知は実戦で十分使える!」と
感動を覚えました。
【2019年】metric learning(距離学習)による異常検知
metric learningは、似たもの同士を固めてプロットする学習方法です。
ディープラーニングの分野で注目を浴び始めたのは、FaceNetが登場した
頃からだと思います。
metric learningは、本来、異常検知のために開発されたものではありません。
特に、FaceNetは人の同定(同一人物かどうか判定)を行うために開発されました。
metric learningの考え方は、nクラスで学習させたモデルがあったとして、n+1クラス目が
出てきたときに再学習させるのは非常に非効率です。そこで、似たもの同士を固めてプロット
しておけば、新たなn+1クラスのデータは既存のnクラスとは全然違う位置にプロットされる
ので、再学習は必要ないというものです。
この考え方は異常検知でも有効で、正常データで学習させたmetric learningのモデルに
異常データを入れると、正常データとは違う場所にプロットされるはずです。従って、
異常検知が可能になる仕組みです。
※metric learningを使った異常検知について、以下の記事が非常に参考になります。
【2020年】ハイブリッド
最近の手法は、オートエンコーダやGAN、metric learningなどを組み合わせたものが
多くなってきています。組み合わせることにより、それぞれの長所を伸ばし、短所を
補うことが可能になります。
-
SSIMオートエンコーダによる異常検知
オートエンコーダによる異常検知は、細かい異常部分を捉えることが難しいと言われています。
そこで、SSIMという画像類似度を測る指標を併用することで、細かい異常部分を捉える
ことに成功したのがSSIMオートエンコーダです。2018年に登場した手法で、オートエンコーダ
による異常検知の性能を大幅に上回りました。(metirc learningと対決させた記事はこちら) -
弱教師あり学習
異常検知の実際の運用を考えた場合、「異常データ」を少数持っている場合が想定されます。
弱教師あり学習は、そのような少数の異常データを活用することで、異常検知性能を底上げ
する手法です。(効果が薄いという報告も多数あります(^^;。) -
自己教師あり学習(←これがおススメ!)
工業製品で起こりうる異常は、細かな傷や変色が多いと予想されます。自己教師あり学習では
このような細かな異常を人為的に作り出し、metric learningで学習することにより、高精度な
異常の検出と可視化を可能にしました。(※こちらも参考になれば幸いです。) -
デュアルオートエンコーダ
GANによる異常検知も登場していますが、GANを使いこなすのが難しいため、なかなかスコアが
伸びませんでした。この手法はオートエンコーダを二つ用意することで、GANの不安定性を
補完した論文です。(~~いずれ、Qiitaでも記事を書く予定です。~~再現しなかったため、断念しました) -
距離学習と幾何変換による異常検知
正常画像を幾何変換(例えば90度回転)させて学習し、テスト画像でも幾何変換して、それが当てられる
かで正常/異常を見分ける手法が、過去に提案されています。(詳細はこちらを参照)ここで紹介する
手法は、幾何変換だけではなく、距離学習と組み合わせて、さらに精度を上げた手法です。
CIFAR10でSOTA。この手法は画像だけではなくテーブルデータにも適用可能で、いくつかの
データセットでSOTAを達成しています。
【決定版?】EfficientNetを使った異常検知手法
ImageNetで学習したEfficientNetを使った異常検知手法です。「正常画像は各層で出てくる
特徴も同じはず」という仮定で考えると、正常画像では各層の特徴で固まりができます。
その固まりからのマハラノビス距離で異常かどうか判定します。異常は正常にはない特徴を
持っているため、マハラノビス距離が大きくなります。更に、固有値の小さい方からのPCAを
適用することで、性能を上げることができます。
簡単な解説は以下に書きました。
https://qiita.com/shinmura0/items/5f2c363812f7cdcc8771
可視化
-
AnoGAN
AnoGANはGANの表現力を頼りに異常検知する手法です。
可視化だけではなく、異常スコアの算出もできます。 -
Ano-Unet V2
Ano-Unet V2は、metric learningやオートエンコーダに後付け可能な可視化専用の
ネットワークです。Ano-Unetに対し、推論の高速化とハイパラの調整不要を行い、
さらに使いやすくしたものです。 -
学習済EfficientNetを使った異常検知手法の可視化
決定版ともいえる「学習済EfficientNetを使った異常検知手法」の可視化です。
テクスチャー系に強く、オブジェクト系には弱いです。
ベンチマーク
ここからは、2019年当時、最新だったmetric learningなどのベンチマークを行います。
- DOC
- L2-SoftmaxLoss
- ArcFace
コード全体はこちら
条件
- DOCのepochは5、最適化手法はSGD
- metric learningのepochは10、最適化手法はAdam
- バッチサイズは128
- ベースモデルはMobileNet V2(学習済モデルを使用、つまり転移学習)
- DOCとL2-SoftmaxLossの異常スコアはLOFで算出
- それぞれのモデルで10回試行してAUCを算出
- データはFashion-MNISTとcifar-10を使用
<Fashion-MNIST>
データの内訳は以下のとおりです。
正常は「スニーカー」、異常は「ブーツ」。
| 個数 | クラス数 | 備考 | |
|---|---|---|---|
| 学習用リファレンスデータ | 8000 | 8 | スニーカーとブーツを除く |
| 学習用正常データ | 1000 | 1 | スニーカー |
| テストデータ(正常) | 1000 | 1 | スニーカー |
| テストデータ(異常) | 1000 | 1 | ブーツ |
※学習用リファレンスデータとは、学習用正常データと見比べるためのデータです。
<cifar-10>
データの内訳は以下のとおりです。
正常は「鹿」、異常は「馬」。
| 個数 | クラス数 | 備考 | |
|---|---|---|---|
| 学習用リファレンスデータ | 8000 | 8 | 鹿と馬を除く |
| 学習用正常データ | 1000 | 1 | 鹿 |
| テストデータ(正常) | 1000 | 1 | 鹿 |
| テストデータ(異常) | 1000 | 1 | 馬 |
実装
コード全体はこちら
-
DOC
実装はこちらを参考にしてください。 -
L2-Softmax-Loss
異常検知ではありませんが、こちらで実装しています。 -
ArcFace
実装は、こちらを参考に(ほとんどコピー)させていただきました。
結果
Fashion MNISTの結果
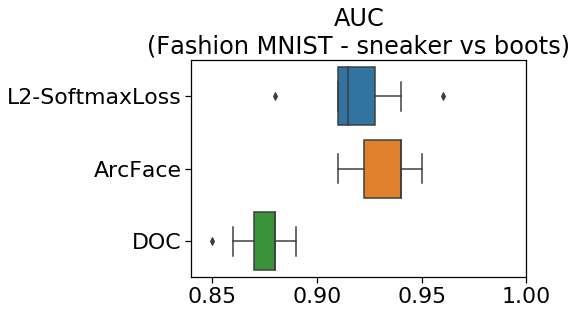
L2-SoftmaxLossとArcFaceが良いスコアを示しました。
やはり、距離学習による異常検知は性能が良いようです。
中央値が重なって見づらいですが、DOCとの差は中央値で0.05ポイント
(全体の精度は10%くらい?)の差が出ています。
L2-SoftmaxLossは、以前の結果と食い違っていますが、以前は
データ数も少なく、最適化手法のlrも違う値でした。
cifar-10の結果
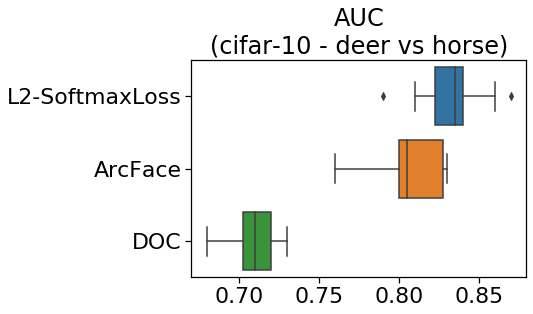
こちらも、L2-SoftmaxLossとArcFaceが良いスコアになりました。
DOCとの差はさらに大きくなっています。
metric learningの可能性
metric learningは異常検知性能が良いことが分かりました。
さらに、様々な可能性を秘めています。
-
「異常検知」と「クラス分類」を同時に実行
metric learningは元々、分類タスクを行うことができます。こちらのArcFaceの事例では、
ペットボトルの種類を分類しながら、コサイン類似度が小さい場合は、学習していない
未知のものと見なしています。これはArcFaceに限らず、metric learning全般で行うことが
できます。つまり、「metric learningでは、異常検知を行いつつ、同時にクラス分類もできる」
ということです。個人的に、これは衝撃的な内容でした。 -
異常データの分類
これはやっていないので、推測の域を出ませんが、ImageNetなどの画像で学習させた
metric learningのモデルでは、全く見たことがない異常のデータを弾き、かつ異常
モードを特定することができると思われます。例えば、ある製品を画像検査するときに、
「傷」「へこみ」「変色」などの異常画像を弾きつつ、それぞれ異常の種類に応じて、
クラスタリングすることも可能になると思われます。つまり、「異常検知を行いつつ、
同時に異常モードが特定できる(再学習不要)」ということです。cifar-10の画像で
ここまでできるかどうか分かりませんが、夢がかなり広がります。
まとめると、metric learningは異常検知性能も良いし、クラス分類もできるし、
異常モードの特定もできる凄いヤツ。
つまり、**metric learningは最強!**ということです。
画像以外のデータへの適用
現在、画像以外のデータを分析しています。
今までは、非ディープラーニングベースでしたが、ディープなL2-SoftmaxLossを使って
異常検知することで、AUCが0.1ポイント(全体の精度は10%)向上しました。
ちなみに、ここでもArcFaceよりL2-SoftmaxLossの方が良い性能を示しました。
ディープラーニングは画像以外のデータでも効果があります。
(8/7追記)
上記のモデル、さらに、アンサンブルをとることでAUCが累計0.25ポイント(全体の
精度は20%)向上しました。ディープ×アンサンブルはやってみる価値あります。
処理は重くなりますが。
まとめ
- 現在(2019年当時)、ディープラーニングによる異常検知で一番性能が良いのはmetric learning
- metric learningは異常検知のみならず、様々な可能性を秘めている
- ディープラーニングによる異常検知は、画像以外のデータでも有効
更新履歴
2019/8/6 初稿
2019/9/7 SSIMオートエンコーダ・黒魔術・metric learningのリンク追加
2019/10/11 自己教師あり学習・Ano-Unet V2のリンク追加
2019/11/11 コードのバグ修正・AUCの結果を差し替え
2020/2/17 黒魔術削除、弱教師あり学習・デュアルオートエンコーダを追記
2020/5/18 デュアルオートエンコーダを修正、幾何変換による異常検知を追記
2021/3/10 学習済EfficientNetによる異常検知手法を追加