
News
2021/4/30 ㊗この記事の英語版が、論文に引用されました。
…というか、個人的には「この記事のアイデアを拡張して、汎用的なアイデアにした上で論文化してくれた」、と勝手に喜んでいます。
・引用された論文: "CutPaste: Self-Supervised Learning for Anomaly Detection and Localization", arXiv:2104.04015 [cs.CV], 2020.

この「[16]」です。
はじめに
Deep metric learningの評価を段階的に試してきました。
- Part 1: 分類器で学習できるMetric learningを簡潔なコードで試す
- Part 2: 深層距離学習(Deep Metric Learning)各手法の定量評価 (MNIST/CIFAR10・異常検知)
今回は、こちらの記事「【精度対決】リアルな画像で異常検知」で紹介&トライされている MVTec Software GmbH 社の「MVTec Anomaly Detection Dataset (MVTec AD)」への応用を試みます。今回の試みでは、
- 実応用に近いデータでどの程度の性能が出せるのかを評価する。
- 異常検知とともに、ヒートマップにより異常部位の特定も試みる。
- 精度を上げるための問題設定を行い、精度向上に対する汎用性について考える。
また、
- ソースコードのgithubリポジトリ: github.com/daisukelab/metric_learning/MVTecAD
- 英語版の記事をMediumに同時ポストする試みも行いました。 ⇒ "Spotting Defects! - Deep Metric Learning Solution For MVTec Anomaly Detection Dataset" @Medium
MVTec Anomaly Detection Dataset (MVTec AD)
URL: https://www.mvtec.com/company/research/datasets/mvtec-ad/
2019年6月に公開されたばかりのデータセットで、15カテゴリーから工業製品や農作物、各ドメインごとの欠陥、画像内のさまざまな配置、さらに欠陥領域のセグメンテーションデータもアノテーションに含まれていて、素晴らしいデータセットです。

図: MVTec ADウェブサイトより、緑の正常サンプルに対する赤の異常サンプル例。
「私たちの知る限り、教師なし異常検出のタスクには(MNIST, CIFAR-10などに)相当するデータセットは存在しません。」
そのため教師なしの異常検出(およびセグメンテーション)研究分野へMNIST、CIFAR10、またはImageNetの役割を果たすために作られたようです。またデータセットだけではなく、GAN・オートエンコーダー・その他の従来の方法などのベースライン手法も十分評価され論文にまとめられています[1]。
評価した手法
これまでの記事同様、下記を評価しました。
- L2-constrained Softmax Loss[2]
- ArcFace[3]
- CosFace[4]
- SphereFace[5]
- CenterLoss[6]
- 加えて、通常のCNN
 図: Figure 1. from CosFace[4]: An overview of the proposed CosFace framework.
図: Figure 1. from CosFace[4]: An overview of the proposed CosFace framework.
実験
学習はいわゆる普通の分類問題として行われます。この学習フェーズについて、3つの異なる分類問題設定を行いました。学習パラメーター等が多少異なりますが、純粋にデータの違いで生じる過学習を防ぎ、ある程度学習が十分に進む程度の違いに留めてあります。
実験は次々に失敗し、新しく考案した方法でようやく成功しました。
- 実験1:従来の教師付きマルチクラス分類問題
- 実験2:正常・異常(欠陥)クラスの二値分類問題
- 実験3:通常のサンプルから異常なサンプルを生成する自己教師あり学習
- さらに一つ:すべてのカテゴリでAUC 90%を超えるには
実験1:従来の教師付きマルチクラス分類問題
MVTec ADの論文でも述べられるように、多くの先行研究では、MNIST、CIFAR10などの主要な画像データセットを評価に使用しています。問題の設定は次のとおりです。
- 学習の準備として、元のクラスの一部を「正常」に割り当て、その他のクラスは「異常」に割り当てて、最終的な異常検出タスクの分類とします。
 図: CIFAR-10クラス分割例
図: CIFAR-10クラス分割例
- 「正常」としたクラスサンプルのみをモデルに分類問題として学習させます。異常サンプルは使用されず、モデルは正常クラスについてのみ識別するよう学習します。
- 推論時には、学習したモデルを使ってすべてのテストサンプルの距離を計算し、正常か異常かを判断して評価します。
なお、これは前回までの記事と同じ問題設定です。今回は「【精度対決】リアルな画像で異常検知」と同じクラスを使ってみました。
- 次の4つのカテゴリの「欠陥なし」(正常)サンプルを学習します: 「カプセル」、「カーペット」、「革」、「ケーブル」。したがって、学習はこれら4つのクラスのマルチクラス分類問題です。
- テストはカテゴリごとに実行されます。 各カテゴリのすべてのテストサンプルが評価され、最後にパフォーマンスを評価するためにAUCが計算されます。
- テストクラスは学習クラスとは異なることに注意してください。テストサンプルは、正常な「good」サンプルと、さまざまなタイプの異常サンプルで構成されます。

図: 学習バッチの例、4つのクラスの分類問題。
学習は問題なく終了します。互いに大きく異なる画像を分類するのは簡単な問題です。
ただし通常のCNN分類とは異なり、これは実際に距離学習に対応させたCNNを分類問題で学習させるだけで、サンプル間の距離の測定を学習します。
距離の測定と異常識別
テスト段階では、次の手順ですべてのテストサンプルの通常クラスからの距離を測定します。
- 学習済みモデルから最終層を切り取ると、モデルは512次元の特徴量を出力します。 (ResNet18を使用、FC層の直前は512次元)
- $N$個の学習サンプル$x_n$の特徴量$e_n$を事前に取得します。(すべての$x_n$をモデルに与えて特徴量を出力させる)
- 次に、$m$番目のテストサンプル$x_m$の特徴量$e_m$を取得し、学習サンプルの特徴量$e_n$との間でコサイン距離を計算します。結果として学習サンプルとの距離が$N$個得られます。
- そして$N$個の距離から最小値を選びます。この最小距離こそが、テストサンプル$x_m$の正常との距離$d_m$です。
- $M$個すべてのテストサンプルの距離が得られるまで、手順3と4を繰り返します。
- 距離から正常・異常に分類するにはしきい値を設定します。距離が短いサンプルは正常であり、距離が長い他のサンプルは異常として検出されます。
マルチクラス分類問題で学習させた結果
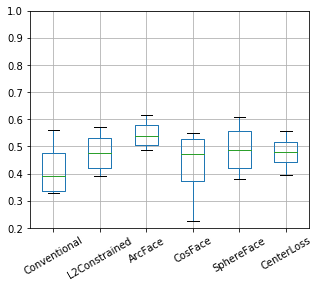
グラフ: 評価結果のAUC値。
距離の学習は失敗したようです(ほとんどが0.5未満、ランダムな回答よりも悪い精度)。これは当然かもしれません:
- 「カプセル」と「ケーブル」のような非常に異なるオブジェクトを識別するように訓練された。
- にもかかわらず、非常に類似した対象間でテストした。「正常なカプセル」に対して「(少しだけ)異常なカプセル」の距離は、「カプセル」と「ケーブル」の距離よりずっと近いでしょう。
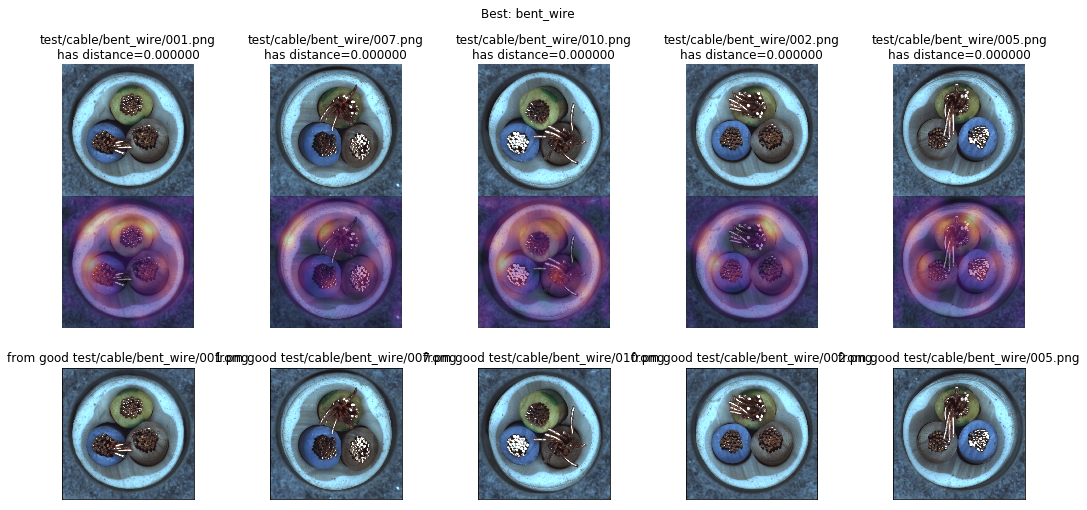
図: ケーブルを与えたときのヒートマップ。欠陥箇所に集中できず広く反応している様子が見える。
したがって、距離学習評価で従来行われている問題設定は、MVTec ADのようなシナリオでは難しいのかもしれません…
「わずかな違い」を識別するように、モデルを動機付ける必要がありそうです。
実験2:正常・異常(欠陥)クラスの二値分類問題
わずかな違いを見つけられるように学習させたいので、
- テストセットから欠陥クラスを1つを選択し(テストセットのみに欠陥クラスがある)、そのクラスのサンプルを異常クラスとして学習データに入れてしまいます。
- これで、正常・異常を判別する二値分類問題になりました。

図: 学習バッチ例、"good"に対する"broken_large"の二値分類。
しかし結果は改善しませんでした。

グラフ: 評価結果のAUC値。
基本的に、異常クラスのサンプルサイズが小さすぎます。正常クラスのサンプルサイズは約200以上ですが、異常クラスは約10個で、非常に不均衡です。この問題を軽減するため以下を行いましたが、機能しませんでした。
- 異常クラスのオーバーサンプリング、Augmentation、およびMixupのようなトレーニング手法を使用。
僅かな違いを見つけられるよう訓練させる試行錯誤は続く…
実験3:通常のサンプルから異常なサンプルを生成する自己教師あり学習
この実験はKaggle的なシンプルなアイデアです。
今必要なのは、正常とわずかな違いがある異常サンプルです。であれば、正常サンプルから異常サンプルを生成すればいいのでは…。
こういった異常サンプルさえ準備できれば、元の正常サンプルとのわずかな違いを区別できるようにモデルを学習させることができます。したがってこの実験は二値分類問題で、正常サンプルのみを使ったものなので自己教師あり学習となります。
この実験のため、新しいデータセットクラス(実際はfast.aiライブラリ[7]のImageListクラス)を作成しました。動作として:
- まず学習サンプルを単純に倍にする。
- 偶数番号のサンプルには正常ラベルを、奇数番号のサンプルには異常ラベルを割り当てます。
そうすると、元々の学習サンプルすべてに「AnomalyTwin(異常な双子)」が用意されました。 - 画像が読み出されるときに、異常としてラベル付けされた画像はランダムな線を引きます。この僅かな線が、正常サンプルとの小さな違いです。このときランダムに線を引くので、データ拡張としても作用しているはずです。

図: 学習バッチの例。「正常」と「異常」の両方があり、すべての異常サンプルには欠陥の線が描かれる。
想定通りの結果が得られました。
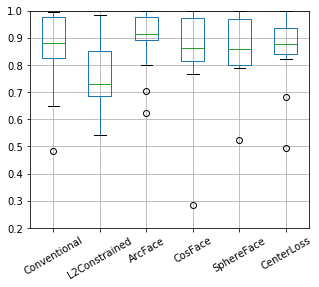
グラフ: 評価結果のAUC値。大きく改善。
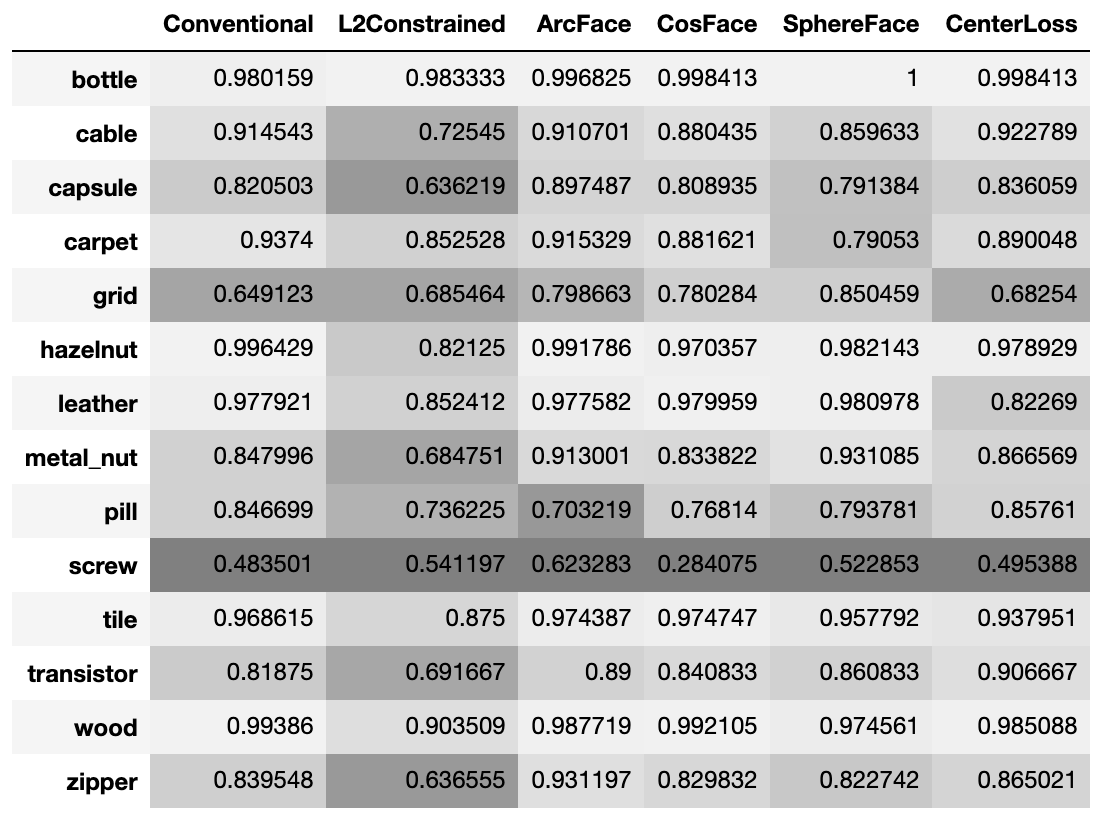 表: 評価結果のAUC値詳細、CosFaceやArcFaceが良く安定している様子。
表: 評価結果のAUC値詳細、CosFaceやArcFaceが良く安定している様子。
Grad-CAMによるアクティベーションヒートマップでサンプルをチェックしてみます。成功例では、ヒートマップが画像上の欠陥部分を捉えています。

図: Grad-CAMによるヒートマップ、ArcFaceでヘーゼルナッツをテストしたAUC 99%の例。テストサンプルとそのヒートマップ(上と真ん中)に対して一番距離が近かった学習サンプル(下)。
しかし以下の失敗事例では、モデルが欠陥を捉えていないことを示しています。この種の欠陥を見つけられるよう学習できていません。似たような例がさらにいくつかあり、改善のための余地があることを示しています。

図: Grad-CAMによるヒートマップ、ArcFaceでネジをテストしたAUC 62.3%の例。モデルは欠陥部分を見つけられず、画像全体を散漫と見ている様子。
さらに一つ:すべてのカテゴリでAUC 90%を超えるには
最終的に、さらに調整してすべてのカテゴリでAUC 90%を達成した結果を示します。
調整は実際簡単で、異常モードをうまく表現できるように生成方法を調整しただけです。
さて、これはどういう意味を持つのでしょうか…? これは、テストサンプルで発生する欠陥モードの知識を利用したので、カンニングのようなものです。
- したがって、これは事前に欠陥モードの知識が利用できないユースケースには適用できません。
- それでも多くの場合、ある程度の欠陥モードは既知でしょう(工程での不良一覧は%やppmの不良率で整理されていることが一般的かと思われます)。
既知の欠陥モードやありえそうなモードの検出を自動化するのには役立つのではないでしょうか。

図: Grad-CAMによるヒートマップ、ArcFaceでネジをテストしたAUC 62.3%⇒91%への改善例。ネジ先端の欠陥を見つけている様子。

図: Grad-CAMによるヒートマップ、ArcFaceでトランジスタ実装をテストしたAUC 89%⇒95.8%への改善例。足の欠陥を見つけている様子。
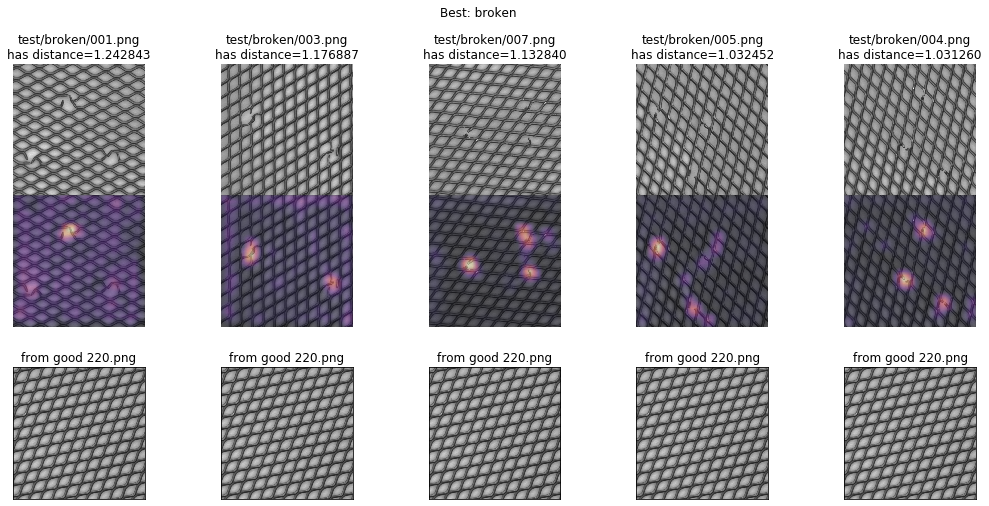
図: Grad-CAMによるヒートマップ、ArcFaceで格子をテストしたAUC 79.8%⇒99.9%への改善例。欠陥部分を見つけている様子。

図: 特徴量の分布、上記のArcFaceで格子をテストした例。右上隅の異常サンプルの集団から遠く離れ、正常サンプルは左下隅に円を形作っています。
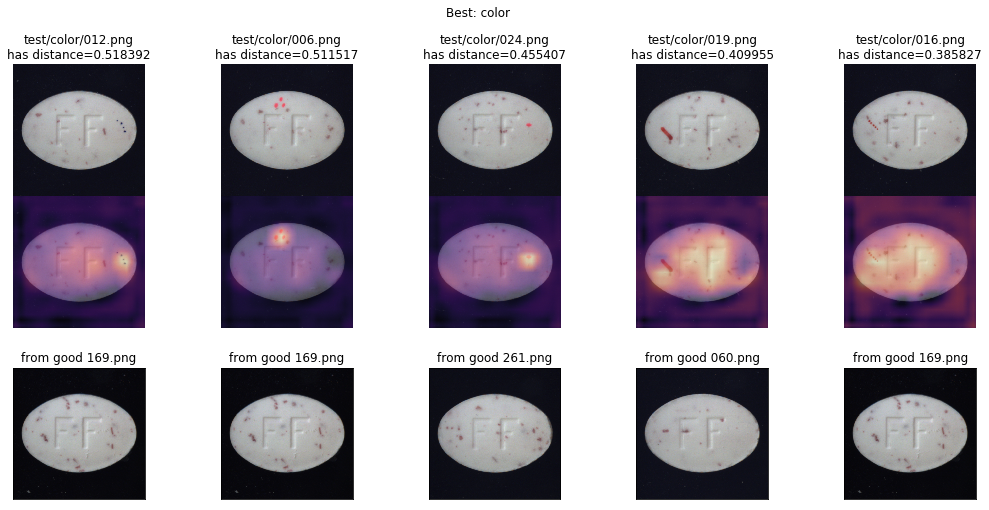
図: Grad-CAMによるヒートマップ、ArcFaceで錠剤をテストしたAUC 70%⇒93.5%への改善例。 一部の欠陥は正しく検出されていますが、右の2つの例はモデルが散漫に反応しています(将来の失敗リスク)。
データセットの論文結果との比較
MVTec ADの論文[1]では、すべてセグメンテーション出力に基づいた結果になっています。そのため基本的に比較することは困難です。
- 論文の結果では、「カーペット」、「ケーブル」、「金属ナット」、「ジッパー」などはAUC 90%未満となっています。
- しかしセグメンテーションのピクセル値の正解不正解の数でTPR / FPRが計算され(※再現させていないため理解が間違っているかもしれません)、距離ベースよりもずっと難しい問題を解いています。
- 画像が正常であるか異常であるかを単純に判断する限りでは、深層距離学習の方が単純ですので、論文で説明されている複雑なしきい値の決定を必要とするセグメンテーションベースの検出と比較すると役立つかもしれません。
最後に…
この記事の実験では、次のことが示されました。
- 深層距離学習の手法を使って、自己教師あり学習でのMVTec ADデータセットの画像異常検知が実装できました。
- また、成功している場合には、そのgrad-CAMで欠陥部分を示すこともある程度成果を出せました。
- もしくは、少なくともAUC 90%以上のパフォーマンスで欠陥の有無を区別できました。
- 一つの手法だけではなく、セグメンテーションベースと組み合わせ/アンサンブルすることにより、パフォーマンスが向上したり、潜在的な応用の可能性が広がるかもしれません。
もっと最後に…
この記事何だか変だな…? そうお気づきの方へ、実は多くの部分が自動翻訳なのです(そういう異常検知のオチでもあります…)。
英語版の記事を先に書きながら、その過程でもGoogle翻訳を使ってある程度良い日本語に変換されるように、必要な箇所を修正していきました。
★つまり、NLPでモデルの学習に使われる逆翻訳結果と比較してlossを評価するリアル版です! :)
さすがにコピペでは仕上がりませんでしたが、3〜4割程度はそのまま使えています。
自動翻訳の精度がここまで上がったのも、とても頼もしく感じました。
References
- [1] Paul Bergmann, Michael Fauser, David Sattlegger, Carsten Steger. MVTec AD - A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection; in: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
- [2] R. Ranjan, C. D. Castillo, and R. Chellappa. L2-constrained softmax loss for discriminative face verification. arXiv preprint arXiv:1703.09507, 2017. https://arxiv.org/pdf/1703.09507.pdf
- [3] J. Deng, J. Guo, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. arXiv preprint arXiv:1801.07698, 2018. https://arxiv.org/pdf/1801.07698.pdf
- [4] H. Wang, Y. Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu, CosFace: Large Margin Cosine Loss for Deep Face Recognition, arXiv preprint arXiv:1801.09414, 2018. https://arxiv.org/pdf/1801.09414.pdf
- [5] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song. SphereFace: Deep Hypersphere Embedding for Face Recognition. In CVPR, 2017. https://arxiv.org/pdf/1704.08063.pdf
- [6] Y. Wen, K. Zhang, Z. Li, and Y. Qiao, A discriminative feature learning approach for deep face recognition," in European Conference on Computer Vision. Springer, 2016, pp. 499–515. https://ydwen.github.io/papers/WenECCV16.pdf
- [7] Jeremy Howard et al. (2018). The fast.ai deep learning library, https://github.com/fastai/fastai.