前回の記事では、SSIMオートエンコーダによる異常検知を紹介しました。
是非とも「metric learningによる異常検知」と比較したいと思い、調べていたところ、
SSIMの精度が出ている論文を見つけました。
そこで、本稿では以下のことを行います。
- まずは、論文の中身を紹介します。
- 論文中のSSIMの精度と「metric learningによる異常検知」の精度を比較します。
※こちらはPythonデータ分析勉強会#11の発表資料です。
※全体のコードはこちらに置いています。
結論から
論文のデータセットを使って実験したところ、「論文に出てくる全ての異常検知手法
(SSIMオートエンコーダを含む)に対し、metric learningによる異常検知の方が
良いスコアを出しました。」
論文の中身
※本稿の図は、基本的に論文(MVTec AD — A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection)より引用しています。
まずは、論文の中身をざっとご紹介します。
- 異常検知のデータセットを提供する論文です。CVPR2019で公開されました。
- データセットは実際のテクスチャーや物体を写したもので、正常な写真と異常な写真が添付されています。
- 各種異常検知手法のベンチマークも同時に行い、精度と可視化について定量的に評価しています。
- データはこちらよりダウンロードできます。(何故かPythonのAPIを叩かないとダウンロードできませんでした。)
- データセットの数は以下のとおりです。
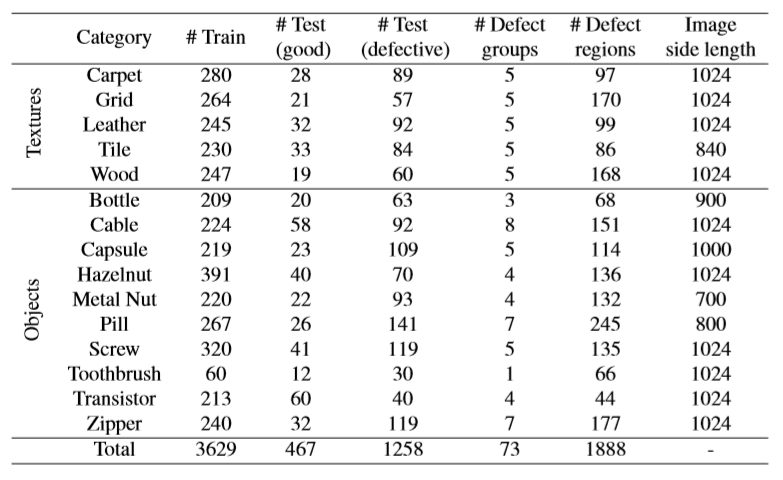
1クラスの学習データは大体200個を超えています。
テストデータの数は異常>正常となっており、かなり不均衡です。
ちなみに、Cable,Capsule,Leather,Carpetのテストデータは以下のとおりです。

ケーブルが無かったり、銅線が無かったり、欠け、印字ミス、傷、打痕、染みなど
多種多様な欠陥があります。
解像度は700 x 700 ~ 1024 x 1024と幅があるようです。
論文に登場する異常検知手法たち
一応、論文中に出てくる異常検知手法たちを紹介します。
結論からいって、論文ではオートエンコーダ($l2$、SSIM)が良いスコアを示しました。
-
オートエンコーダ($l2$)、オートエンコーダ(SSIM)
この手法は前回の記事を参考にしてください。 -
AnoGAN
この手法はこちらに詳しく載っています。 -
CNN Feature Dictionary
ImageNetで学習させたモデルを使って、GlobalAgeragePoolingの出力をPCAで次元圧縮する
手法のようです。最終的にはk-means法を使うようです。metric learningに似ていますが、
スコアはイマイチです。 -
GMM-Based Texture Inspection Model
-
Variation Model
一応、精度を載せておきます。
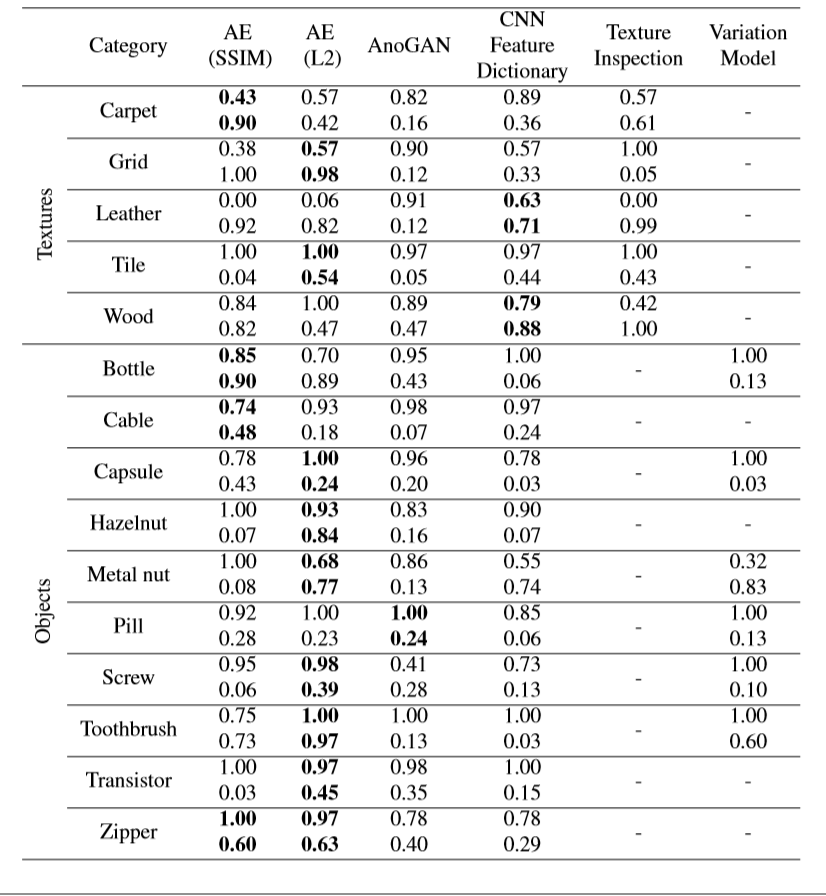
上段はTrue positive rate(再現率)、下段はTrue negative rate(特異度)を示しています。
論文では、AUCではなく、この二つの和が一番大きいものを良い異常検知手法としています。
実験条件
SSIMとmetric learningによる異常検知の性能を比較するために
実験を行います。
※全体のコードはこちらに置いています。Colabで動くはずです。
- MVTEC-ADから難しそうなデータを4つ選定しました。
- 今回は精度のみを比較します。可視化の比較は行いません。
- 選んだデータの数は以下のとおりです。
| 画像の種類 | 学習データの数 | テストデータ(正常)の数 | テストデータ(異常)の数 |
|---|---|---|---|
| Cable | 224 | 58 | 92 |
| Leather | 245 | 32 | 92 |
| Carpet | 280 | 28 | 89 |
| Capsule | 219 | 23 | 109 |
SSIMオートエンコーダ(論文より引用)
- SSIMを適用する窓のサイズは11 x 11
- オートエンコーダの入力画像サイズは256 x 256
- 潜在変数は100
- 学習データはDataAugmentationにより10,000個に増幅
metric learning
- 学習データは上記4種類のデータ全てを渡しました。つまり、968個のデータです。
- 入力画像サイズは224 x 224
- 今回使うmetric learningはL2 SoftmaxLoss
- epochは50、最適化手法はSGD
- バッチサイズは128
- ベースモデルはMobileNet V2($\alpha=0.5$)(学習済モデルを使用、つまり転移学習)
- 異常スコアはLOFで算出
- 10回試行して、それぞれの試行で再現率と特異度の和が高いものを採用
アンサンブル異常検知
metric learningについて、更なる高精度を目指してアンサンブル学習を行います。
アンサンブル学習といっても、やることは単純で、複数のモデルを用意して異常スコアの
平均値をとるだけです。今回は同一構造のモデルを3つ用意し、全く同じデータで学習
させました。
異常検知のアンサンブルは、必ずしも精度向上につながるわけではありません。
ここが教師あり学習と違うところです。精度が上がったら、めっけもんです。
実験結果
Cable
論文では、ケーブルで一番スコアが出たのはSSIMでした。

下の図(自作)は「再現率と特異度の和」と「AUC」を示しています。
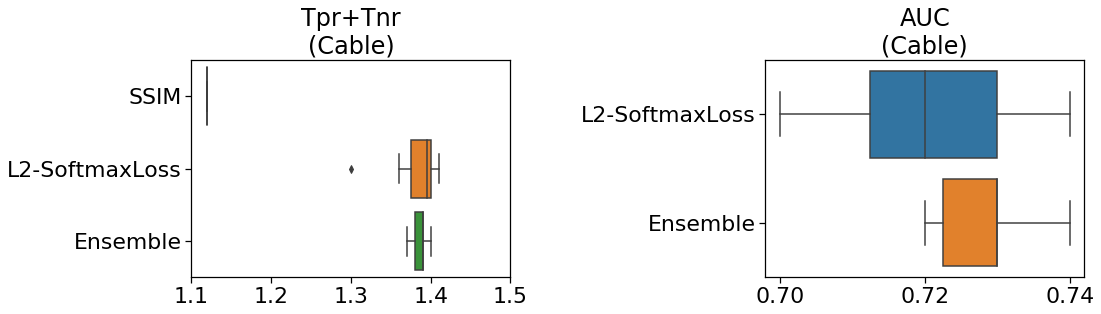
左図のように、metric learningのスコアがSSIMを大きく上回っています。
また、右図からも分かるとおり、単一のモデルよりアンサンブル学習の方が
スコアが上がります。
異常スコアと画像の特徴を見てみます。
異常スコアが大きいと、正常からかけ離れたものを意味します。
まずは、異常スコアが大きい異常サンプルです。

ご覧のようにケーブルがないものやリード線が折れ曲がっているものがあり、
とても分かりやすい異常サンプルです。
続いて、異常スコアが小さい異常サンプルです。

リード線がないものや外のケーブルが割れているものがあります。
直観的にケーブルの割れは分かりやすい気がしますが、異常度が小さいと
判断されています。
Leather
論文では、革で一番スコアが出たのはCNN Feature Dictionaryでした。

下の図(自作)は「再現率と特異度の和」と「AUC」を示しています。
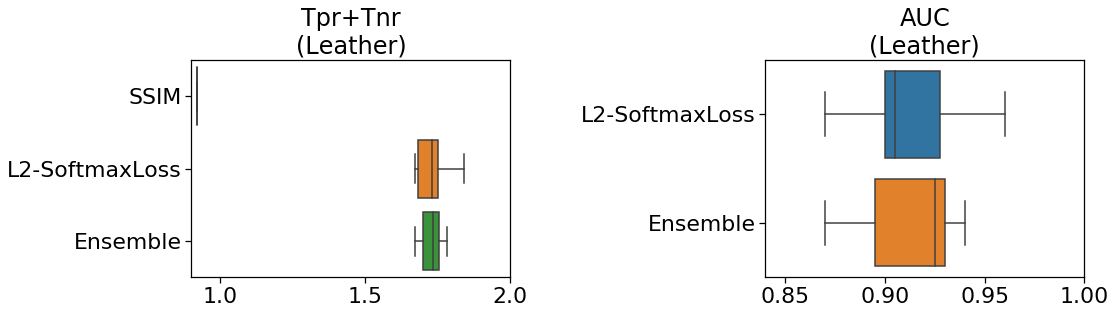
ケーブルと同じような結果になっています。
metric learningの方が、そして、アンサンブル学習の方がより良いスコアが出ています。
異常スコアと画像の特徴を見てみます。
まずは、異常スコアが大きい異常サンプルです。

打痕が大きいものが多く、とても分かりやすい異常サンプルです。
異常スコアが大きいのも頷けます。
続いて、異常スコアが小さい異常サンプルです。

小さな傷があるものが多い印象で、分かりにくい異常サンプルです。
Carpet
論文では、カーペットで一番スコアが出たのはSSIMでした。

下の図(自作)は「再現率と特異度の和」と「AUC」を示しています。
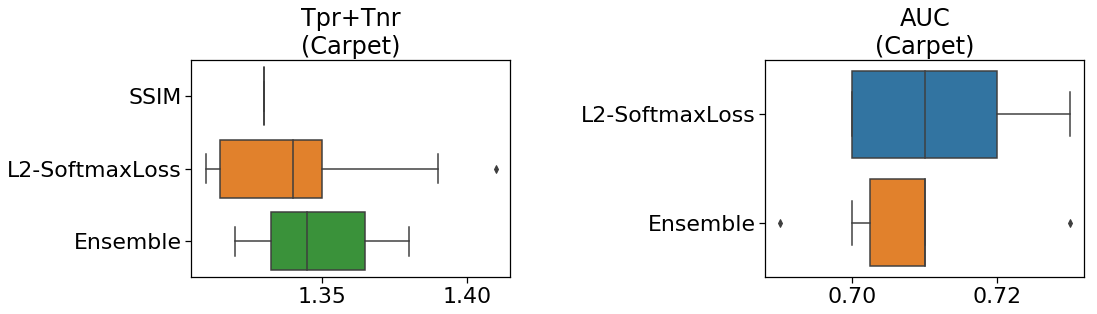
左図より、L2-SoftmaxLossの中央値はSSIMを上回ることが分かりました。
単一のモデルとアンサンブル学習の比較では、ほぼ同じスコアが出ています。
異常スコアと画像の特徴を見てみます。
まずは、異常スコアが大きい異常サンプルです。

変色や大きな傷、糸のほつれなどが目立ちます。
かなり分かりやすいサンプルと言えそうです。
続いて、異常スコアが小さい異常サンプルです。

変色しているものや染みがあるのは分かりますが、異常部分がどこなのか
見つけられないものもあります。これはかなり難しいサンプルと言えそうです。
Capsule
論文では、カプセルで一番スコアが出たのはL2でした。

下の図(自作)は「再現率と特異度の和」と「AUC」を示しています。
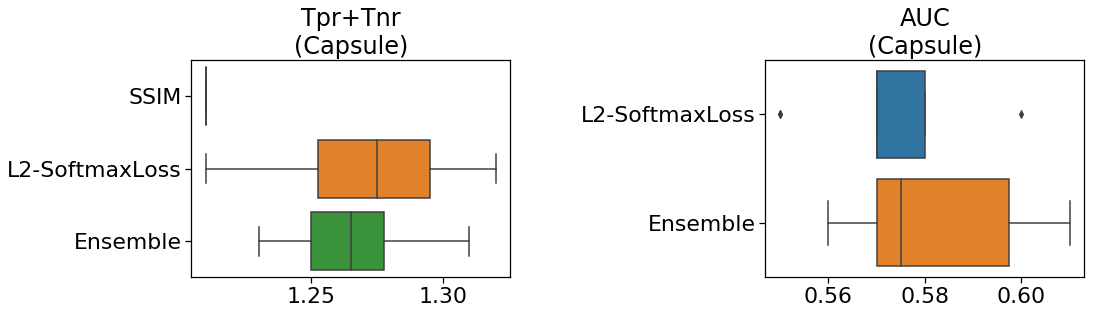
左図より、L2-SoftmaxLossの中央値はSSIMを上回っていることが分かります。
一方、このサンプルだけは、単一モデルの方がアンサンブル学習よりも優れていました。
結果的に、metric learningでは、カプセルのスコアが伸び悩みました。
ただ、次回紹介する黒魔術を使えば劇的にスコアを上げることができます。
具体的にはAUCで0.9を超える結果が出ています。
異常スコアと画像の特徴を見てみます。
まずは、異常スコアが大きい異常サンプルです。

変形したものや印字ミス、欠損などが目立ちます。
とても分かりやすい異常サンプルです。
続いて、異常スコアが小さい異常サンプルです。

パッ見て分かるのは印字ミスくらいで、それも僅かな異常と言えそうです。
その他のサンプルは、異常部分を見つけることが難しそうです。
考察
なぜ、「SSIMオートエンコーダ」より「metric learning」の方が良いスコアを出したのか
考察してみます。
-
ハイパーパラメータの調整
正直、論文ではハイパーパラメータの調整は行われていないと思います。従って、SSIMではもっと精度が出るはずです。ただ、「metric learningのLeatherのスコア」に迫れるかといわれると疑問が残るところです。 -
カラー対応
SSIMは基本的に**グレースケールの画像にしか対応できません。**従って、この論文でもカラー画像をグレースケール画像に変換してベンチマークを行っています。そのためカラーの情報が欠如しており、精度が上がりにくいと思われます。metric learningはカラー画像に対応しています。 -
教師無し学習
SSIMは純粋な教師無し学習です。しかし、metric learningは半教師あり学習に分類されるらしいです。つまり、SSIMは約200枚の正常画像を見て正常な範囲を決めていますが、metric learningは正常画像とは関係ない画像(本稿では、700枚)を見て正常な範囲を決めることができます。これは大きな差になると思われます。 -
転移学習
SSIMでは転移学習は使えませんが、metric learningでは転移学習が使えます。転移学習はディープラーニングを適用する上で、かなり有利に働きます。精度アップはもちろんのこと、学習時間も速くなるので、運用上のメリットも生まれます。
metric learning 精度アップのコツ
- エポックはあまり大きくしない方が良いです。大きくすると、学習済の重みが壊れてしまうので精度が下がります。
- 最適化手法はAdamよりSGDの方が良いようです。Adamにすると、やはり学習済の重みが壊れてしまうと思われます。
- 参照データは多過ぎると良くないようです。最初、cifar-10のデータ2000個を混ぜて学習させましたが、精度が下がりました。
- ベースモデルをInceptionResNetV2へ変えたところ、精度が下がりました。
- DataAugmentationは精度アップにつながりませんでした。元々、metric learningは過学習しにくいと言われており学習データが1クラス当たり200個あれば十分なのでしょう。
- 学習データ数が少数の場合、ArcFaceが良いという報告もあり、L2SoftmaxLossよりArcFaceの方が良いスコアが出るのかもしれません。
- 黒魔術を使う(次回記事参照)
まとめ
- MVTEC-ADはかなり難しいデータセット。異常検知分野の「ImageNet」になり得るかもしれない。
- metric learningは、論文中のどの異常検知手法よりも良いスコアを出した。アンサンブル学習もやってみる価値はある。
- しかも、ベースモデルをMobileNetにできる上、デコーダー部がないので、オートエンコーダよりも高速化することが可能。
- metric learningは異常部分の可視化が弱いのが難点。誰か画期的なアイデアを出してください。
次回は、異常検知性能を劇的に向上させる黒魔術を紹介します。