前回の記事ではmetric learningとSSIMオートエンコーダの異常検知性能を
比較しました。
その際、偶然にも異常検知性能を劇的に上げる方法を発見したため、
報告させていただきます。
ただし、なぜ異常検知性能が上がるのか、その理由ははっきりと分かっていません。
※コードはこちらに置きました。
その方法は?
端的にいって、畳み込みニューラルネットワーク(CNN)の深い層の出力ではなく
浅い層の出力で判定することで、異常検知性能が上がりました。
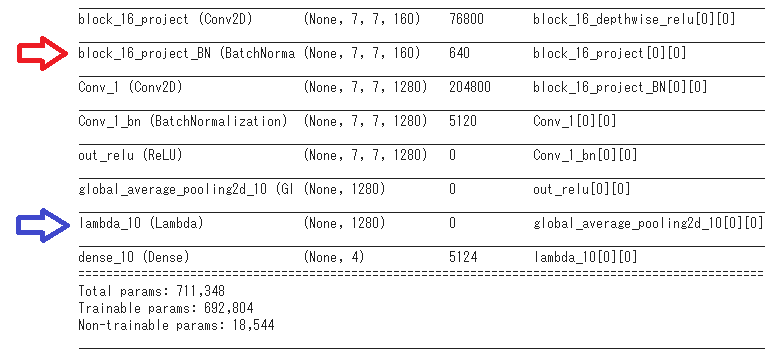
本来は、上図で青色の最終層の出力を取り出す(metric learning)ところを、
間違えて赤色の中間層で出力を取り出したところ、AUCが0.2ポイントほど
上がりました。
これは、中間層で出力を取り出しているため、もはやmetric learningで
すらありません。しかし、異常検知性能は上がります。
結論から
結局、本手法が有効かどうかはデータに依存することが分かりました。
工業製品のように決まった位置、明度、縮尺であれば、本手法で劇的な精度アップが望めます。
一方、cifar-10のような位置や角度、縮尺や明度が決まっていないものは、恐らく
「metric learning」の方が良いスコアを出します。
使い方としては、本手法とmetric learningを使ってみて、良いスコアを出した方を
採用するというのがベストな気がします。
最高のパフォーマンスを得るには?
この手法を実際に使う場合、どのような条件だと最高のパフォーマンスを
出すのか知りたいため、以下の検証を行いました。そして、実験結果も
併記しておきました。
-
どの出力層で取り出すと一番性能が出るのか?
$\rightarrow$出力を取り出す層は、浅すぎても深すぎてもダメ -
「metric learningの有無」によって性能が変わるのか?
$\rightarrow$「metric learning」の有無による影響はない -
一般的なモデルや軽量モデルでも同じ効果があるのか?
$\rightarrow$MobileNet V2でもVGG16でも効果があった -
様々な画像データでも効果があるのか?
$\rightarrow$4つの物体の異常検知で効果があった -
cifar-10のような多様な画像でも効果があるのか?
$\rightarrow$**効果はなかった。**metric learningの方が良いスコアを出した。
実験
上記の検証を行うために、実験を5つ行いました。
※コードはこちらに置きました。
条件
| 画像の種類 | 学習データの数 | テストデータ(正常)の数 | テストデータ(異常)の数 |
|---|---|---|---|
| Cable | 224 | 58 | 92 |
| Leather | 245 | 32 | 92 |
| Carpet | 280 | 28 | 89 |
| Capsule | 219 | 23 | 109 |
- 学習データは上記4種類のデータ全てを渡しました。つまり、968個のデータです。
- 学習済モデルを使用、つまり転移学習
- 異常スコアはLOFで算出
- 10回試行してAUCを取得
実験中、以下の項目は変更しますが、特段の指定がない場合は
以下の設定とします。
- epochは50、最適化手法はSGD
- 今回使うmetric learningはL2 SoftmaxLoss
- バッチサイズは128
- ベースモデルはMobileNet V2($\alpha=0.5$)
- 画像のサイズは224 x 224
実験1 どの出力層で取り出すと一番性能が出るのか?
ここでは、出力層を変えながらスコアの比較を行います。
MobileNetV2の層を見たところ、
- expand_BN
- depthwise_BN
- project_BN
の三種類があり、これらの出力で異常検知したところ、「project_BN」のスコアが
一番良かったです。
そこで、各層の「project_BN」を取り出し、異常検知を行います。
下の図は、出力層を変えたときのAUCを示しています。
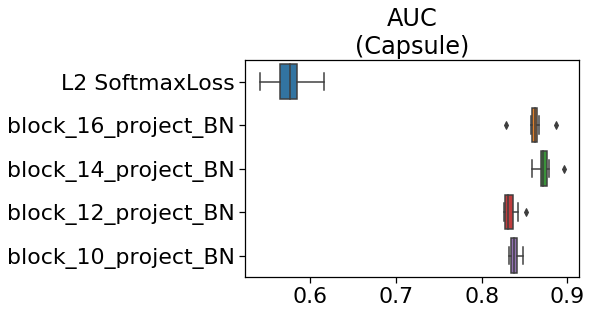
ご覧のように、L2-SoftmaxLossよりも、中間層で取り出した出力で異常検知した方が
スコアが劇的に上がります。これが私がミスしたときに起きた現象です。
正直、驚きました。
もう少し拡大してみます。
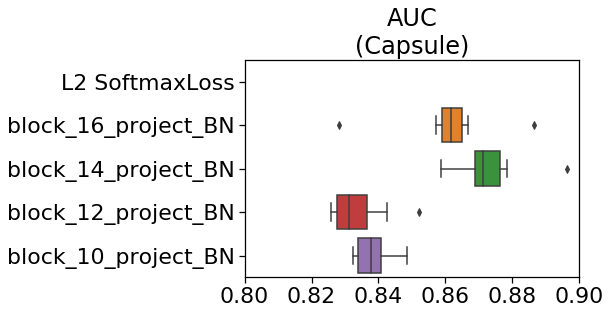
出力を取り出す層は、深すぎても浅すぎてもダメで、最適値がありそうです。
これはデータに依存する可能性もあります。適宜変えながらスコアを観察して
みると良いかもしれません。
下の図は、一番良いスコアを示した「block_14_project_BN」の出力を
t-sneで可視化したものです。
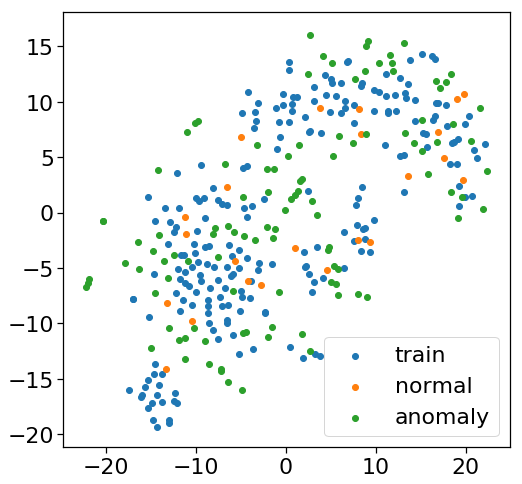
正常データ数:23、異常データ数:109のため、公平な比較はできませんが、
正常データが学習データの近くにプロットされている気がします。
また、当然といえば当然なのですが、metric learningと違って、学習データが
ひとまとまりになることはないようです。
異常スコアと画像の特徴を見てみます。
異常スコアが大きいと、正常からかけ離れたものを意味します。
まずは、異常スコアが大きい異常サンプルです。

カプセルの変形や割れが目立ちます。前回と比べるとかなり分かりやすい
サンプルが多くなった印象です。
続いて、異常スコアが小さいものです。

前回同様、わずかな印字ミスが多い傾向です。
全体的に、前回と比べて、異常スコアが小さくなっていると思われます。
そういった意味で、余裕度が小さくなっている可能性があります。
実験2 「metric learningの有無」によって性能が変わるのか?
ここでは、metric learningの有無によるスコアの比較を行います。
下の図はmetric learningを使わずに学習させた結果です。
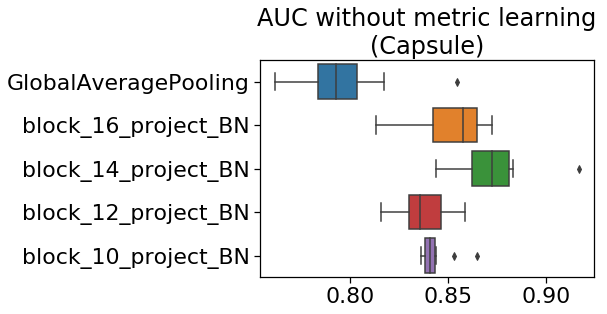
ご覧のように、実験1と同じ結果になりました。
metric learningにより追加された最終層の影響は、ほぼないようです。
実験3 一般的なモデルや軽量モデルでも同じ効果があるのか?
これまでは、MobileNetV2で実験を行ってきました。
正直いって、MobileNet系は演算を軽くするための特殊なモデルです。
この特殊性のために本手法の効果が出たという可能性もあります。
ここでは、VGG16でも本手法の効果があるのかを検証します。
主な変更点は以下のとおりです。
- ベースモデルをVGG16に変更
- バッチサイズが128だと、Colabからエラーが出たため32に変更
- metric learningは使わない
下の図は、VGG16で学習したときのAUCです。
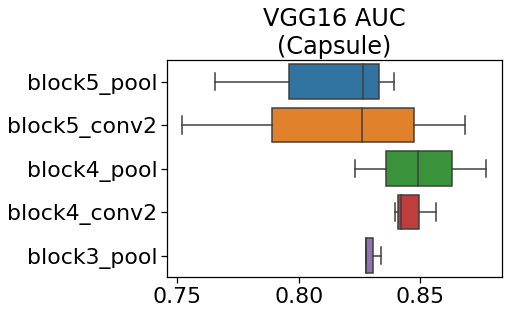
ご覧のように、VGG16でも効果があることが分かりました。
ただし、実験1,2の結果に比べAUCの値が低くなっています。これは、VGG16の学習時に
使うハイパーパラメータを最適化していないため、もっとAUCが上がる可能性もあります。
実験4 様々な画像データでも効果があるのか?
ここでは、Capsule以外の画像でも効果があるのかを検証します。
下の図は、4つの画像で異常検知したときのAUCです。
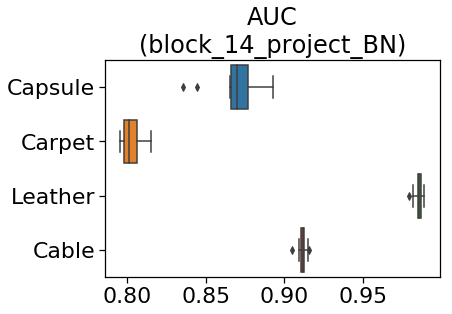
図だけだと分かりにくいので、前回記事よりAUCの中央値を抜粋して比較します。
| 画像の種類 | L2-SoftmaxLoss(AUC) | 本手法(AUC) |
|---|---|---|
| Cable | 0.72 | 0.91 |
| Leather | 0.91 | 0.99 |
| Carpet | 0.71 | 0.8 |
| Capsule | 0.57 | 0.87 |
上の表のように、どんな画像でもL2-SoftmaxLoss(metric learning)のスコアを
上回っており、本手法の効果が大きいことが分かります。
実験5 cifar-10のような多様な画像でも効果があるのか?
これまでは、一定の明るさと位置で撮影された物体の異常検知を見てきました。
カプセルの画像を見たとおり、細かい特徴を捉える必要がありました。
一方、cifar-10の画像だと多様な明るさ、位置、大きさがあり、細かいという
よりは画像全体の特徴を掴まなければいけません。そこで、以下の条件で実験を行います。
- cifar-10の画像8000枚を参照データとする
- 鹿を正常画像、馬を異常画像とする
- 画像のサイズは96 x 96
- epochは10、最適化手法はAdam
下の図は、cifar-10で学習し、取り出す出力層を変えて異常検知したときのAUCです。
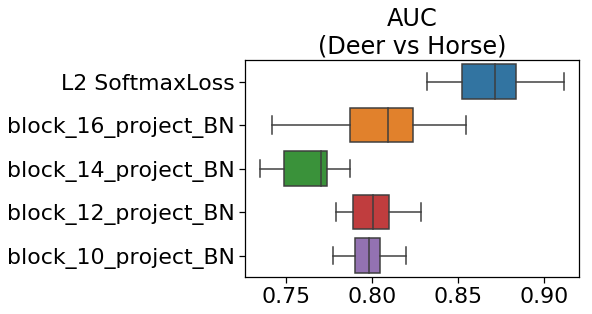
ご覧のように、L2-SoftmaxLoss(metric learning)が良いスコアを示しました。
スコアの逆転現象が起こった理由は後で考察します。
実験 番外編 MobileNetV2が本気を出したら?
最後に、個人的な興味の実験を行います。
ここでは、MobileNet V2の$\alpha$の値を変えて実験します。
$\alpha$の値は大きいほど高精度になりますが、推論速度が落ちてきます。
以下の条件で実験を行います。
- $\alpha=0.5$→$\alpha=1$(本気)に変更
- バッチサイズが128だと、Colabからエラーが出たため64に変更
下の図は、MobileNet V2の$\alpha$の値を変えたときのAUCです。
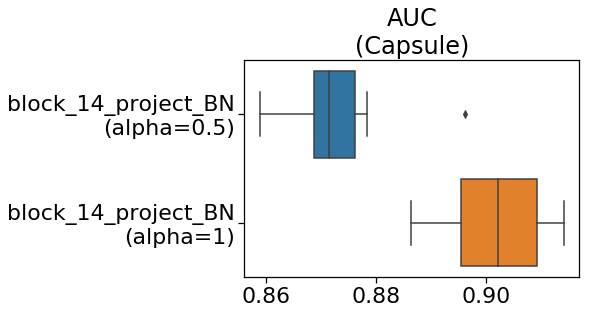
ご覧のように、$\alpha$の大きい方が良いスコアが出ました。
もしかしたら、ResNetなど重いモデルに変えるとより良いスコアが出るかもしれません。
本手法の使い方
以上の実験から、本手法の使い方が見えてきます。
手順は以下のとおりです。
- 学習済みモデルを用意する
- 最終層で分類用の全結合を追加して、分類問題を学習させる(正常データ+参照データ)
- 中間層からの出力を取り出し、LOFで異常検知
metric learningと比べ、非常にシンプルな方法になりました。
こんな方法でスコアが劇的に上がるのは、驚きです。
チューニングするとすれば、以下のポイントが挙げられます。
- モデルを変更してみる(MobileNet V2の$\alpha$を変えたり、ResNetに変えたり)
- 出力を取り出す中間層を変えてみる
なお、実験はしていませんが、最適化手法はSGDが適切だと思われます。
Adamだと学習済の重みが壊れてしまう可能性があります。
考察
色々と謎が残る本手法ですが、今のところ以下2つの謎について考察してみました。
-
なぜcifar-10で効果がなかったのか?
ImageNetで学習した重みは画像の特徴を良く捉えています。従って、MVTEC-ADのような
同じような位置、明度、縮尺の正常画像を入れると中間層の出力は同じような分布になるはずです。
一方、異常画像は違う特徴を持っているはずです。そのため、違う分布となり、異常検知が
可能となります。ところが、cifar-10の正常画像は異なる位置、明度、縮尺のため中間層の
分布は同じようにはならないと思われます。そのため、スコアは伸びなかったと推察されます。 -
なぜ出力を取り出す層は深すぎるとダメなのか?
CNNは、浅い層では画像の細かい部分を、深い層では画像の全体的な特徴を捉えていると
言われています(こちらを参照)。MVTEC-ADは前回の記事でもご紹介したとおり非常に
細かい特徴を捉える必要がありました。そのため、正常/異常の差は深い層より浅い層の方が
明瞭になると思われます。従って、実験結果からも、深い層ではなく、ある程度浅い層から
取り出した出力の方がスコアが伸びたと思われます。
まとめ
- metric learningを使わずに、非常にシンプルな方法で異常検知性能を上げることができる。
- どのモデルでも効果があると思われる。
- ただし、同じような位置、明度、縮尺の画像じゃないと効果は望めない。