はじめに
AnoGANというGANを使って正常データと異常データの分類をしよう!!的な論文を読みました.GANはデータを生成するものでは??と思っていましたがこの論文を読みGANはそもそも何をしているのかが理解できました.
開発環境
- python3.6
- macOS mojave 10.14
識別モデルと生成モデル
一般的に画像を分類しようとしたらVGG16などのCNNを使い画像を分類する識別モデルを作ると思います.しかし医療画像などの正常データと異常データで画像の枚数に偏りがあると識別モデルを作ることは難しいとされています.そもそも識別モデルと生成モデルの違いは、
- 識別モデル
- クラスとクラスの識別境界を決める
- 生成モデル
- それぞれのクラスがどのような分布をしてるのかを決める
といった違いがあります(他にももっとあるとは思いますが).イメージは以下の図のようになります.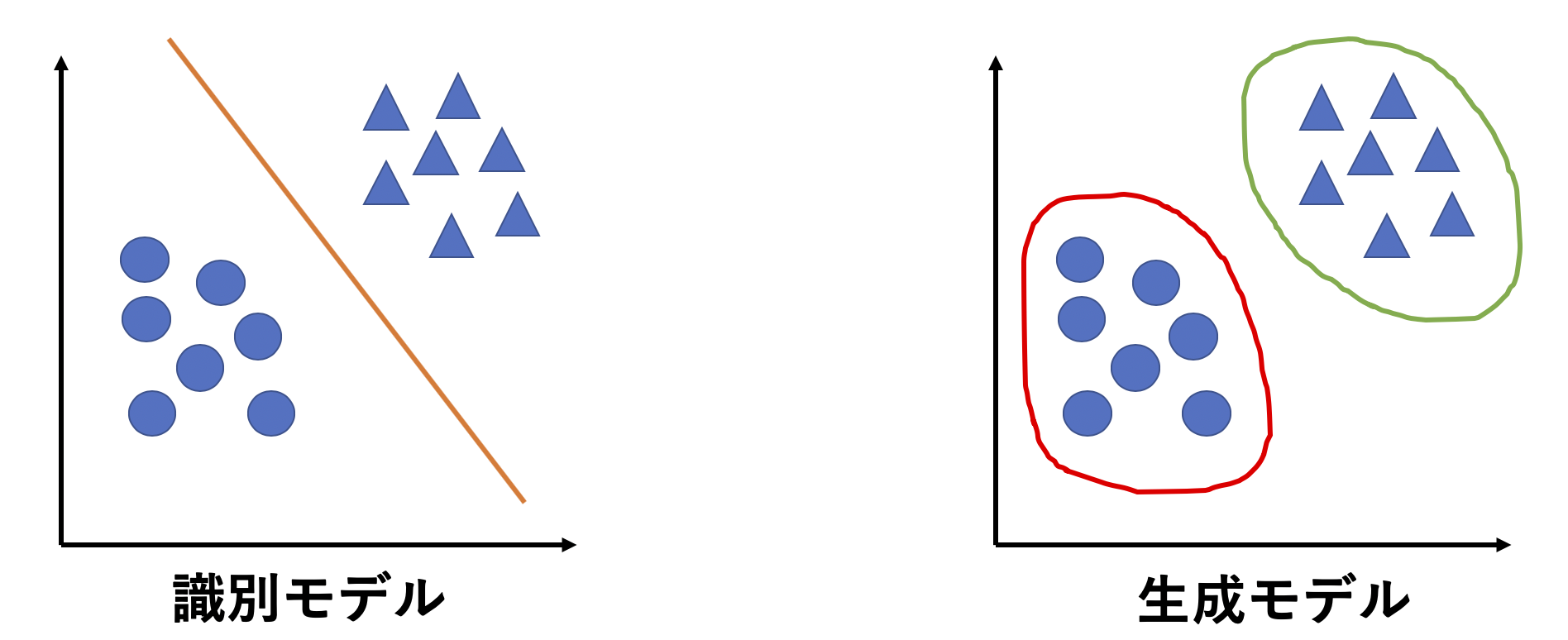
なんで識別モデルは難しいの??
識別モデルでは識別境界を決めるのに正常データと異常データのどちらも大量に用意する必要があります.異常データが少ないと識別境界をうまく決めれず訓練データには対応できても未知の異常データに対応できないといったことが起こります.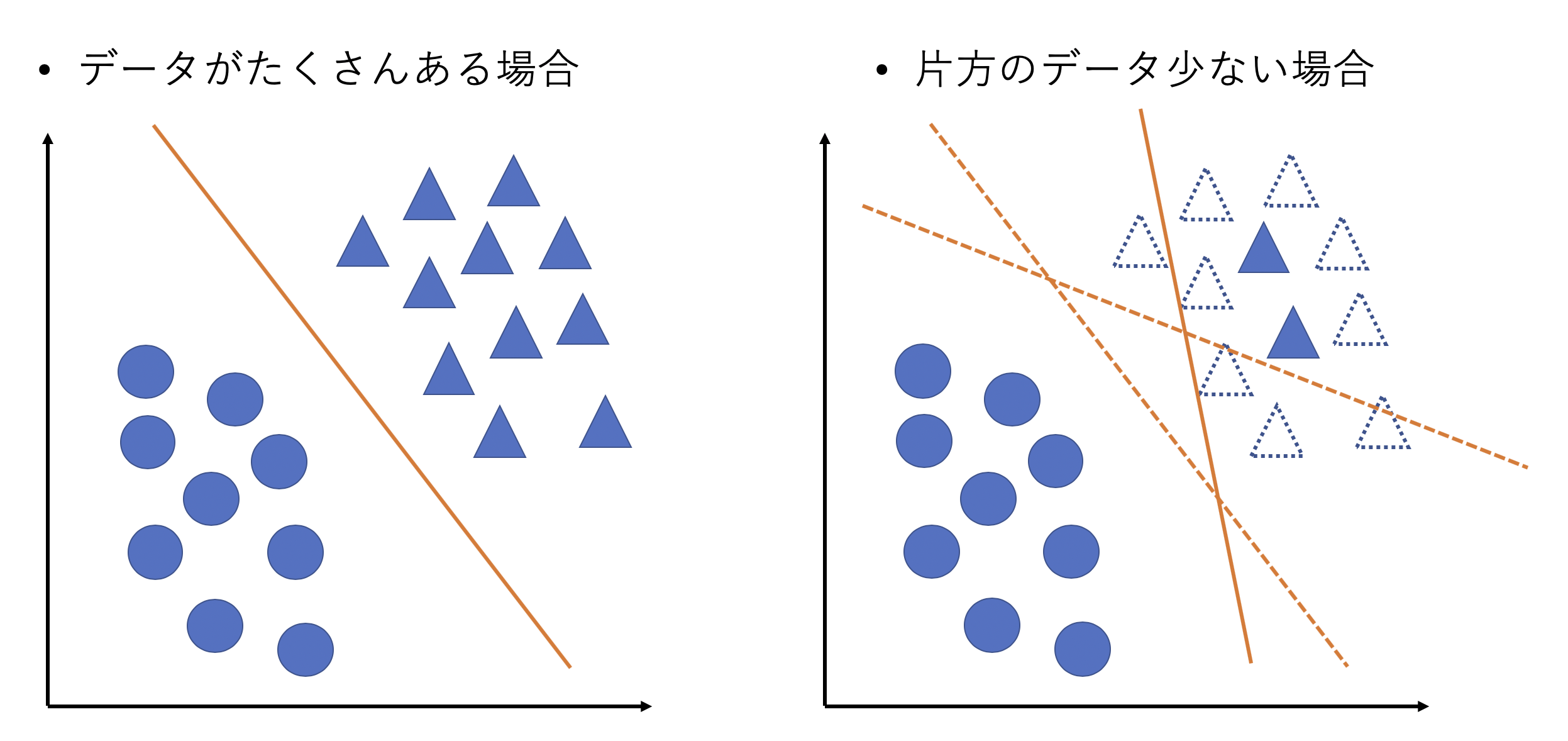
じゃあ生成モデルはどうなの??
GANなどの生成モデルではそれぞれクラスの分布を求めるため異常データが少なくても正常データがどのように分布しているのかは知ることができます.すると、その正常データの分布に従わないデータは全て異常であるとすれば正常と異常に2値分類はできそうなのでは!?ということです.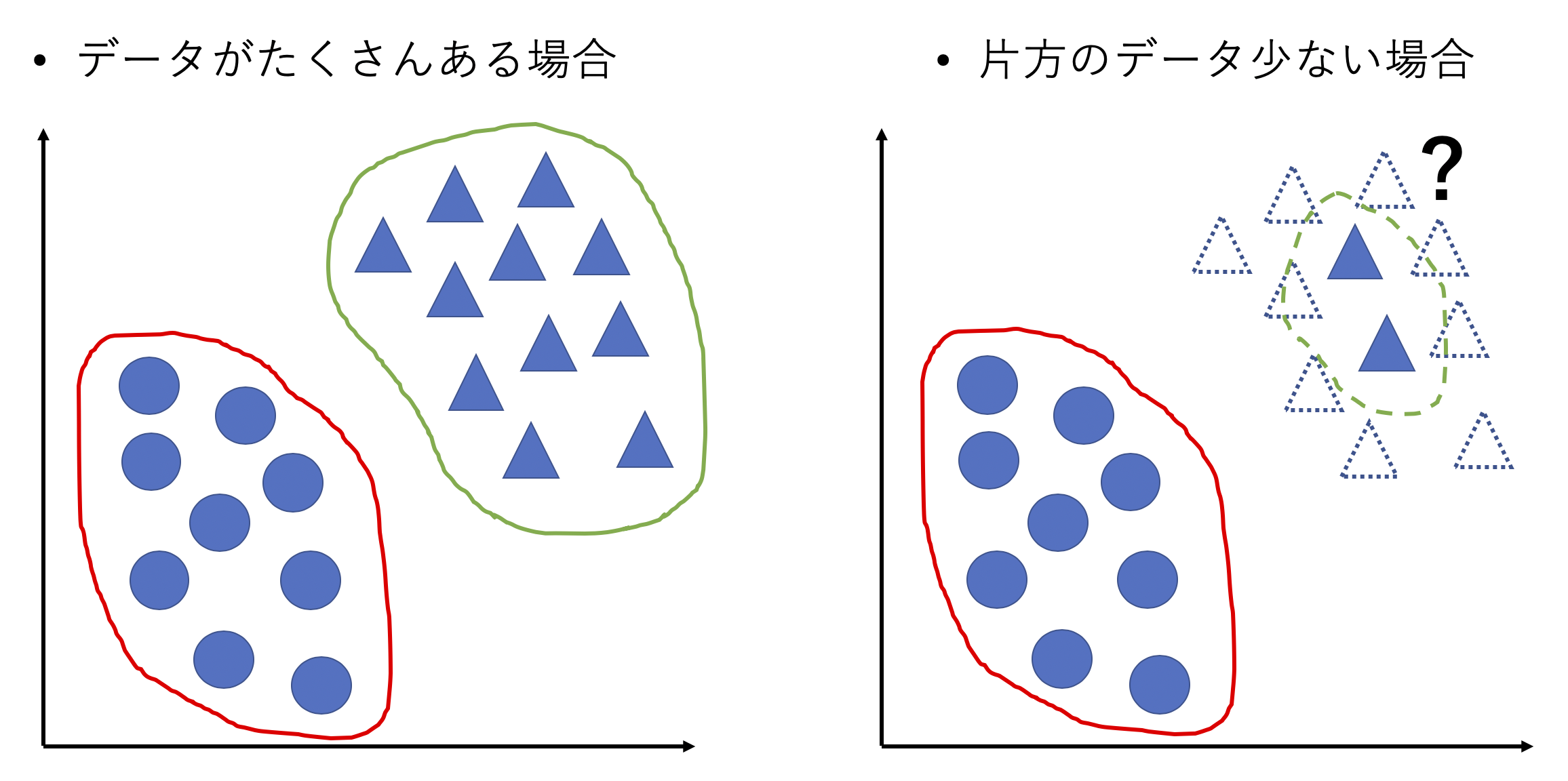
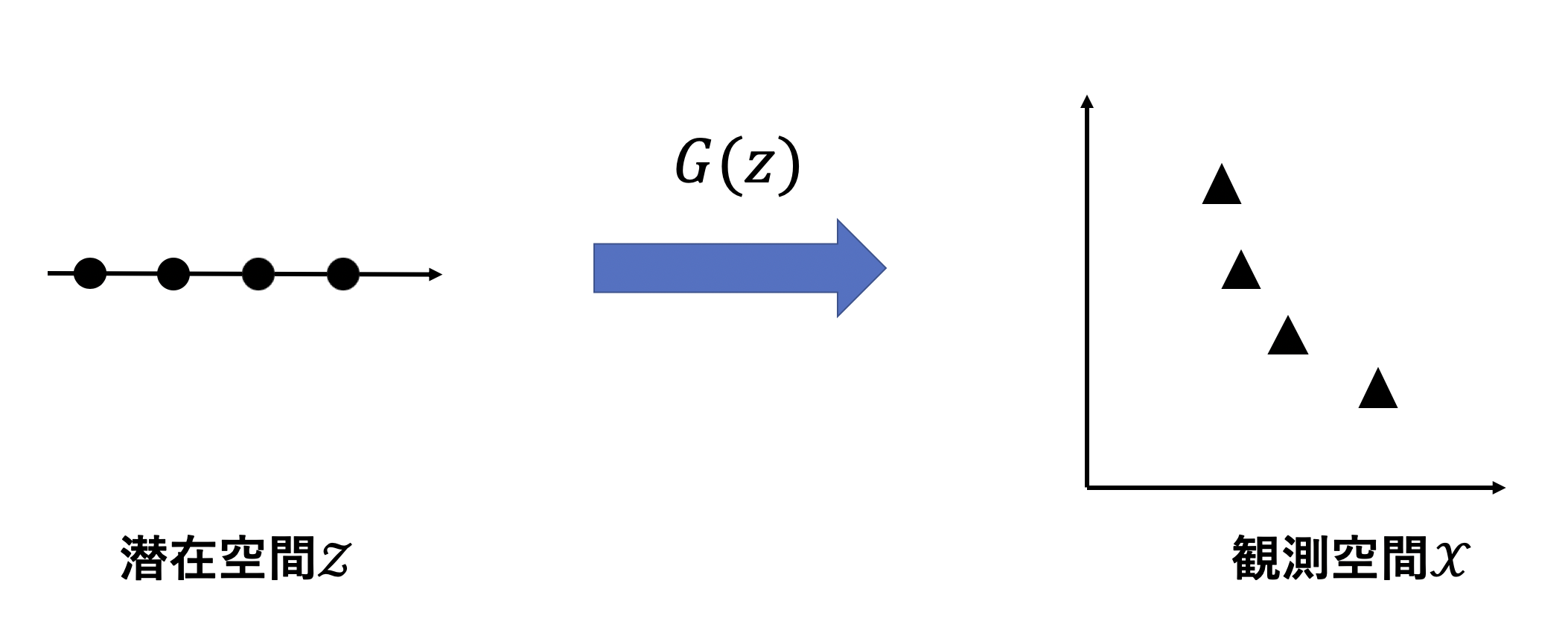
GANとは
GeneratorとDiscriminatorを交互に学習し訓練データのような画像を生成するネットワークのことです.GANは生成モデルの一種であり、訓練データの多様体を学習し低次元空間である潜在空間上の$\boldsymbol{z}$から高次元空間である観測空間上の$\boldsymbol{x}$に写像する$G(\boldsymbol{z})$を学習します.
GANについて詳しく知りたい方は他の方の記事をみてみることをお勧めします.GANの論文を読む際にこちらの記事を参考にさせていただきました.
メインアイデア
論文のアイデアはGANに正常データ多様体だけを学習させれば、潜在空間上の$\boldsymbol{z}$を観測空間上の正常データ多様体にしか写像できないのでは??といったアイデアです.逆に言えば正常データのみを学習したGANは異常データを生成できません.異常データを生成する$z$は存在しないということです.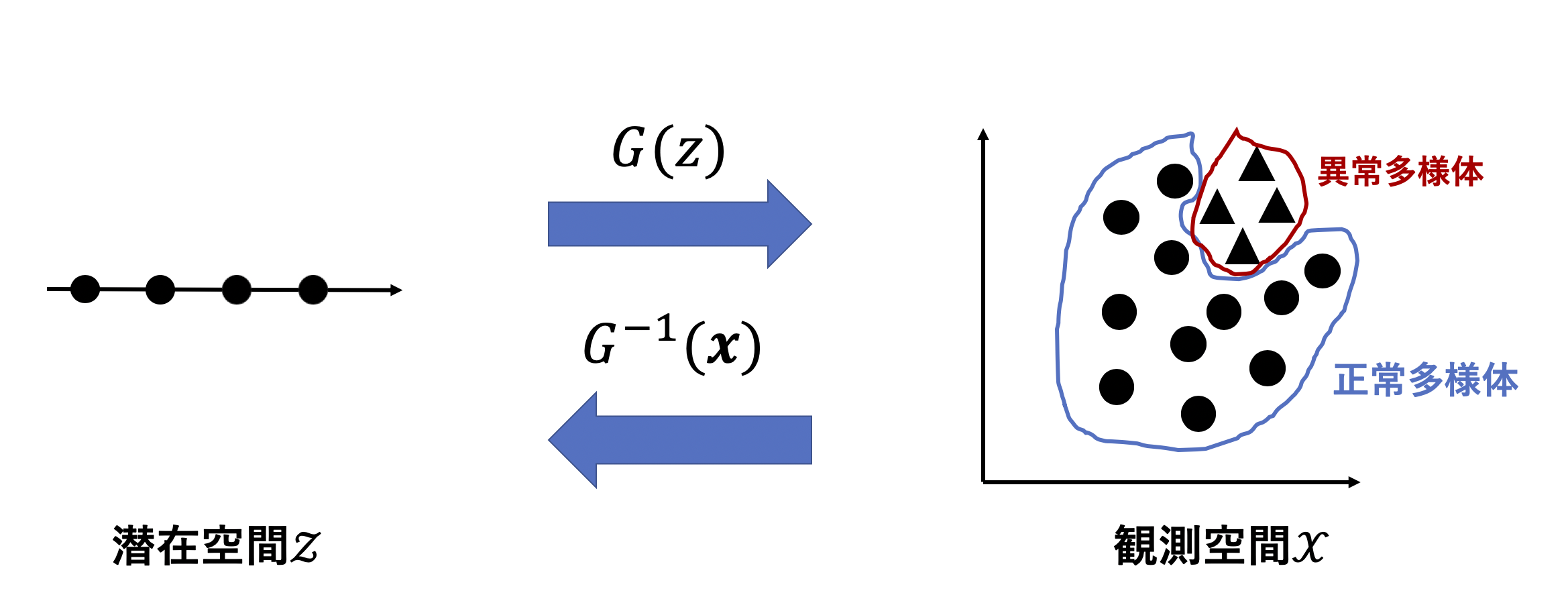
つまり、画像を潜在空間上のある点に逆写像しその点から元の画像が復元できたら正常、復元できなかったら異常ということです.
異常検知アルゴリズム
- GANで正常データのみを学習
- 判定したい画像$\boldsymbol{x}$を潜在空間上の点$\boldsymbol{z_y}$に逆写像
- 点$\boldsymbol{z_y}$を観測空間上に写像($G(\boldsymbol{z_y})$を計算)
- 元画像$\boldsymbol{x}$と生成画像$G(\boldsymbol{z_y})$を比較しピクセル輝度値の差などがある値より大きければ異常
数式で考える
GANは潜在空間の点を観測空間に写像することは簡単ですがその逆写像を求めることは困難です.そこで以下の損失関数を定義しこの関数の値が小さくなるような$\boldsymbol{z}$を勾配法で探します.
\mathcal{L}(\boldsymbol{z_y})=(1-\lambda)\cdot\mathcal{L}_R(\boldsymbol{z})+\lambda\cdot\mathcal{L}_D(\boldsymbol{z})
ここで$\lambda$はハイパーパラメータで0から1の値です.
Residual Loss
上式の$\mathcal{L}_R$はResidualLossと言い生成画像と元画像のピクセルの輝度値の差の合計です.数式で書くと以下になります.
\mathcal{L}_R(\boldsymbol{z})=\sum|\boldsymbol{x}-G(\boldsymbol{z})|
この値が0のとき生成画像と元の画像は同じであると言えます.
Discrimination Loss
生成データが学習した正常なデータの多様体とどれだけ似ているかみたいな値です.数式で書くと以下のになります.
\mathcal{L}_D(\boldsymbol{z})=\sum|\boldsymbol{f}(\boldsymbol{x})-\boldsymbol{f}(G(\boldsymbol{z}))|
ここで$\boldsymbol{f}()$はDiscriminatorの中間層の出力です.
実験
この論文では健康者の医療画像100万枚を学習し病気の画像の異常検知をしてるみたいです.
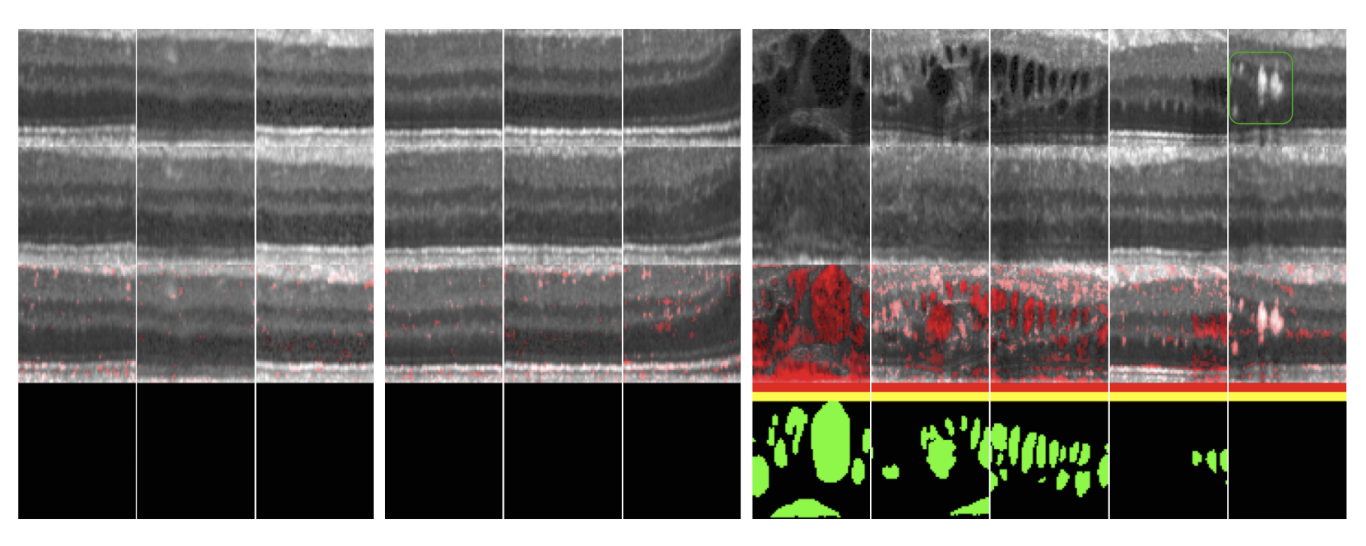
1段目がオリジナル画像、2段目が生成画像、3段目がオリジナルと生成画像の比較です.うまく異常検知できています.
 AnoGANと他のモデルのROC曲線とLossの分布です.他のモデルより面積が大きく性能が良いことがわかります.また、Lossの分布は正常データと異常データとで分布の重なりが小さくうまく分類できています.
ROC曲線は[こちら](https://qiita.com/kenmatsu4/items/550b38f4fa31e9af6f4f)の記事が非常にわかりやすかったです.
AnoGANと他のモデルのROC曲線とLossの分布です.他のモデルより面積が大きく性能が良いことがわかります.また、Lossの分布は正常データと異常データとで分布の重なりが小さくうまく分類できています.
ROC曲線は[こちら](https://qiita.com/kenmatsu4/items/550b38f4fa31e9af6f4f)の記事が非常にわかりやすかったです.
MNISTでやってみた
こちらのソースコードを利用してMNISTの異常検知をしてみました(ただソースコードを動かしただけ...).1の画像のみを学習してそれ以外の数字の画像を異常として検出します.
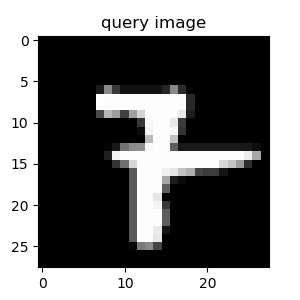
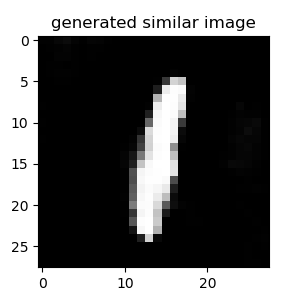
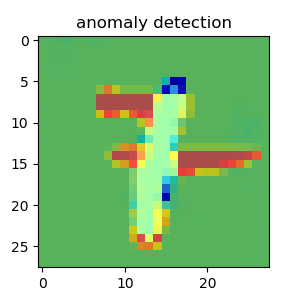
うまく異常検知ができています.
まとめ
GANを使った異常検知ができました.$\boldsymbol{z}$を勾配法によって探すので一枚一枚異常検出に時間がかかると思いました.それの改善策としてこちらの論文がありました.読んだらまた解説記事を書こうと思います.