リニューアルのお知らせ
「深層距離学習(Deep Metric Learning)各手法の定量評価 (MNIST/CIFAR10・異常検知)」
こちらの記事で、定量的な評価を含めて改めることになりました。
CIFAR10を使った可視化で、手法の特徴が見える結果が得られています。
はじめに
異常検知の観点から、Metric learningに注目している人が多いようです。
- copypasteの日記: Metric Learning 入門 - 異常検知につながる未知クラス分類など様々に実験されていて、MNISTだけでなく天気の表形式データでの分類をされているのも面白い。
- Qiita: 【まとめ】ディープラーニングを使った異常検知 - 異常検知への現実的な応用の観点でまとめられています。
- Qiita: metric learning を少し勉強したからまとめる - 異常検知をきっかけとしたコンテキストで簡潔にまとめられています。
- Qiita: [Keras]MobileNetV2+ArcFaceを使ってペットボトルを分類してみた! - ペットボトル以外の異常画像も距離をしきい値で区別して区別されている実例。
ところが、いくつか異常検知に関しての記事では L2-constrained Softmax Loss [1] が一番性能が出ているようで、KaggleではMetric learningといえば ArcFace [2] などで性能が出ているケースと違う状況が気になりました。
そこでこの記事では、
- CNNの分類器をベースにしたMetric learningを、改めて比較してみました。
- __みなさんそれぞれご自分の問題に試しやすい__よう、できるだけ短いコードでまとめました。分類器として簡単に学習できるはずですが、残念ながらすぐに転用できるように短くまとめてあるコードが見つからなかった経緯があります…。
- 「どれが良い」という結論ではなく、各手法を取り入れるときのポイントを纏めるよう心がけました。
- コードはgithubにノートブックとしておいてあります。
他にも以下の記事を参考にしました。
- Qiita: モダンな深層距離学習 (deep metric learning) 手法: SphereFace, CosFace, ArcFace - それぞれの特徴を簡潔にわかりやすく説明された素晴らしい記事です。
- zhihu.com: 人脸识别损失函数简介与Pytorch实现:ArcFace、SphereFace、CosFace - 中国語ですが、論文の数式や図、コードを的確に並べてあり、とってもわかりやすいです。脱帽しました。
- Qiita: Deep Metric Learning の定番⁈ Triplet Lossを徹底解説 - Triplet lossについて素晴らしい記事です。
実験方法
- MNISTデータセット。
- モデルはResNet18のみ、Fast.aiライブラリを使用。
- <更新>最終的なFC層直前のembeddings(更新前「
Softmax直前の10個のlogits」)を可視化して、その様子を観察。
MNIST データセット
MNISTデータセット、一行でロードできるはずですが…、fast.aiの場合3と7だけの簡易データになっているため、pytorchのdatasetsから取得したデータを一旦標準的な形式で用意したほうが簡単でした。
このコードが一番長くてすいません…
def prepare_full_MNIST_databunch(data_folder, tfms):
"""
Prepare dataset as images under:
data_folder/images/('train' or 'valid')/(class)
where filenames are:
img(class)_(count index).png
"""
# 単にpytorchのユーティリティでダウンロードする。
train_ds = datasets.MNIST(data_folder, train=True, download=True,
transform=transforms.Compose([
transforms.Normalize((0.1307,), (0.3081,))
]))
valid_ds = datasets.MNIST(data_folder, train=False,
transform=transforms.Compose([
transforms.Normalize((0.1307,), (0.3081,))
]))
# データをdata_folder以下のフォルダに整理し直す。Keras/fast.aiで標準的に使いやすい形式に。
def have_already_been_done():
return (data_folder/'images').is_dir()
def build_images_folder(data_root, X, labels, dest_folder):
images = data_folder/'images'
for i, (x, y) in tqdm.tqdm(enumerate(zip(X, labels))):
folder = images/dest_folder/f'{y}'
ensure_folder(folder)
x = x.numpy()
image = np.stack([x for ch in range(3)], axis=-1)
PIL.Image.fromarray(image).save(folder/f'img{y}_{i:06d}.png')
if not have_already_been_done():
build_images_folder(data_root=DATA, X=train_ds.train_data,
labels=train_ds.train_labels, dest_folder='train')
build_images_folder(data_root=DATA, X=valid_ds.test_data,
labels=valid_ds.test_labels, dest_folder='valid')
return ImageDataBunch.from_folder(DATA/'images', ds_tfms=tfms)
下記のように1行でImageDataBunchでデータを準備できるようになりました。
data = prepare_full_MNIST_databunch(Path('data'), get_transforms(do_flip=False))
可視化
データセットをそのままt-SNEで可視化して、元々どれくらいばらついた状態にあるかを見てみます。

元々わりと分離されているようで、以降その分は差し引いて考えたほうが良いようです。可視化は下記のように行いました。show_2D_tSNEなどは、githubのコードをご覧ください。
raw_x = np.array([a.data.numpy() for a in data.valid_ds.x])
raw_y = np.array([int(y.obj) for y in data.valid_ds.y])
raw_x = raw_x.reshape((len(raw_x), -1))
if False: # 処理に時間がかかるため、直ぐに結果を見たい場合Trueにして下さい。
LIMIT = 1000
chosen_idxes = np.random.choice(list(range(len(raw_x))), LIMIT)
raw_x = raw_x[chosen_idxes]
raw_y = raw_y[chosen_idxes]
show_2D_tSNE(raw_x, raw_y, 'Raw sample distributions (t-SNE)')
各種法の実験
1. CNN(ResNet18)をそのまま学習したとき
MNISTを学習し、学習後のmodelが出力するlogitsを観察します。
def learner_conventional(train_data):
learn = cnn_learner(train_data, models.resnet18, metrics=accuracy)
learn.fit(1)
learn.unfreeze()
learn.fit(3)
return learn
learn = learner_conventional(data)
embs = get_embeddings(body_feature_model(learn.model), data.valid_dl)
show_2D_tSNE(embs, [int(y) for y in data.valid_ds.y], title='Simply trained ResNet18 (t-SNE)')
- 乱暴かもしれません、ImageNet学習済みモデルの転移学習です。4 epochで学習がほぼ終わります。
- モデルの出力をそのままt-SNEで可視化しています。

10クラス全て分類され、出来ないものが少しばらついている様子が観察できます。
(詳細解説) body_feature_model()でのモデルの切り出しについて
embeddings取得のため、モデルが10次元のlogitsにまとめる直前、今回のResNet18では512次元のembeddingsを得るため、下記の関数で切り出しています。
def body_feature_model(model):
"""
Returns a model that output flattened features directly from CNN body.
"""
try:
body, head = list(model.org_model.children()) # For XXNet defined in this notebook
except:
body, head = list(model.children()) # For original pytorch model
return nn.Sequential(body, head[:-1])
元のモデルのうち、
Sequential(
(0): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
:
) ↑ここまでbody、↓ここからhead
(1): Sequential(
(0): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(1): Flatten()
(2): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25)
(4): Linear(in_features=1024, out_features=512, bias=True)
(5): ReLU(inplace)
(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5)
(8): Linear(in_features=512, out_features=10, bias=True)
)
)
head部分の(8): Linear(in_features=512, out_features=10, bias=True)だけが切り取られます。
〜省略〜
(5): ReLU(inplace)
(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5)
)
)
2. L2-constrained Softmax Loss
L2-constrained softmax loss [1] は、数行追加したクラスで元のモデルをwrapすれば実装できます。このときの $\alpha$ は論文で使われた値で試しました。
class L2ConstraintedNet(nn.Module):
def __init__(self, org_model, alpha=16, num_classes=1000):
super().__init__()
self.org_model = org_model
self.alpha = alpha
def forward(self, x):
x = self.org_model(x)
# モデルの出力をL2ノルムで割り、定数alpha倍する
l2 = torch.sqrt((x**2).sum()) # 基本的にこの行を追加しただけ
x = self.alpha * (x / l2) # 基本的にこの行を追加しただけ
return x
これを使い、一行追加してモデルを L2-constrained Softmax にすれば、自分のモデルに取り入れることが出来ます。
def learner_L2ConstraintedNet(train_data):
learn = cnn_learner(train_data, models.resnet18, metrics=accuracy)
learn.model = L2ConstraintedNet(learn.model) # <<== この行を追加しただけ
learn.fit(1)
learn.unfreeze()
learn.fit(5) # <<== epochを増やしました
return learn
learn = learner_L2ConstraintedNet(data)
embs = get_embeddings(body_feature_model(learn.model), data.valid_dl)
show_2D_tSNE(embs, [int(y) for y in data.valid_ds.y], title='L2 constrainted ResNet18 (t-SNE)')
普通の分類器への追加はすごく単純でしたが、クラスタがかなりまとまっていて、頑健性が向上しそうな様子です。
(分類精度そのものは、MNISTでは99%程度に達するためどの手法もほぼ変わりません。この問題は精度の比較には適していないようです。)
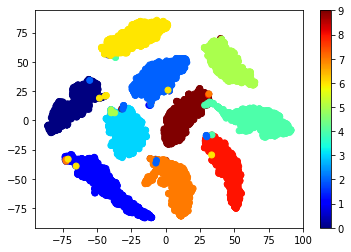
(詳細解説) モデルの出力とget_embeddings()について
Pytorchの場合、モデルの実装にSoftmaxが組み込まれていないため、出力に新しい層をつなげてモデルを簡単に拡張できます。
L2ConstraintedNetでは、forward()内でl2で割ったり定数をかけたりする層を追加しました。
この拡張された層の出力が、新たなモデルの出力となり、logitsとしてロス関数の演算やlearn.predict()での推論で利用されます。
(KerasではSoftmax後の数値が得られたように記憶しています… 間違っていたら後日訂正します)
この実験ではdata_loaderから得られる全てのデータポイントを実装モデルに与え、その出力embeddingsを得ています。(データ数, 10 embeddings)の配列が得られます。
def get_embeddings(embedding_model, data_loader, label_catcher=None, return_y=False):
"""
Calculate embeddings for all samples in a data_loader.
Args:
label_catcher: LearnerCallback for keeping last batch labels.
return_y: Also returns labels, for working with training set.
"""
embs, ys = [], []
for X, y in data_loader:
# 各batch (X, y) に対して、
# labels (y) をセットし、
if label_catcher:
label_catcher.on_batch_begin(X, y, train=False)
# 各データサンプルのembeddingsをバッチ一括に取得してembsに溜め込む
with torch.no_grad():
# Note that model's output is not softmax'ed.
out = embedding_model(X).cpu().detach().numpy()
out = out.reshape((len(out), -1))
embs.append(out)
ys.append(y)
# 溜め込んだembeddingsを一つにまとめる -> (number of samples, length of one sample embeddings)
embs = np.concatenate(embs) # 今回はvalidセットの結果が (10000, 10) で得られるはずです
ys = np.concatenate(ys)
if return_y:
return embs, ys # 指定されれば、正解ラベルも同時に返す (trainセットの場合に使うため)
return embs
この関数を使ってvalidセットの結果(10000, 10)を得て、t-SNEで二次元に可視化しています。
3. ArcFace
ArcFace [2] は、下記に紹介されている https://github.com/ronghuaiyang/arcface-pytorch この実装を使えば数行で実装できます。
- Qiita: モダンな深層距離学習 (deep metric learning) 手法: SphereFace, CosFace, ArcFace、
- zhihu.com: 人脸识别损失函数简介与Pytorch实现:ArcFace、SphereFace、CosFace
ただ、fast.aiでは学習のコードがライブラリ内に隠蔽されています。モデルはforward(self, x)で呼ばれるため、ラベルが与えられずそのままでは使えません。
そこで、LabelCatcherクラスのコールバックを追加し、バッチのラベルをこのクラスで保持することにします。モデルで推論する際には、この保持されたラベルを参照して、ArcFaceの処理を行うことにしました。
class LabelCatcher(LearnerCallback):
last_labels = None
def __init__(self, learn:Learner):
super().__init__(learn)
def on_batch_begin(self, last_input, last_target, train, **kwargs):
LabelCatcher.last_labels = last_target
return {'last_input': last_input, 'last_target': last_target}
class XFaceNet(nn.Module):
def __init__(self, org_model, data, xface_product=ArcMarginProduct, m=0.5):
super().__init__()
self.org_model = org_model
self.feature_model = body_feature_model(org_model)
self.metric_fc = xface_product(512, data.c, m=m).cuda() # 今回は512次元決め打ちとした
def forward(self, x):
x = self.feature_model(x) # logitsになる直前の層に接続する
x = self.metric_fc(x, LabelCatcher.last_labels) # <<= 1層追加する (ArcFaceの処理)
return x
ArcFace(やその他Face)のイメージで良く説明されていますが、「一番最後に、レイヤーを一層追加する」と理解すると簡単です。
追加した層が、勝手にArcFaceの処理を行ってクラス間の距離を開けてくれるはずです。
def learner_ArcFace(train_data):
learn = cnn_learner(train_data, models.resnet18, metrics=accuracy)
learn.model = XFaceNet(learn.model, train_data, ArcMarginProduct, m=0.5) # この行を追加
learn.callback_fns.append(partial(LabelCatcher)) # この行も追加
learn.fit(1)
learn.unfreeze()
learn.fit(5)
return learn
learn = learner_ArcFace(data)
embs = get_embeddings(body_feature_model(learn.model), data.valid_dl)
show_2D_tSNE(embs, [int(y) for y in data.valid_ds.y], title='ArcFace (t-SNE)')
t-SNEで可視化すると、解釈に難しい結果となってしまいました。
 512次元embeddingsのt-SNE2次元可視化
512次元embeddingsのt-SNE2次元可視化
今回512次元のembeddingsに層を接続しましたが、クラス数の10次元まで圧縮されたfeatureというかlogitsを可視化した場合、下のようにクラス間の距離がわかりやすい可視化結果になっています。
 10次元logitsのt-SNE2次元可視化
10次元logitsのt-SNE2次元可視化
(詳細解説) モデルのlogitsをt-SNE2次元可視化する場合
body_feature_model()を使うと、512次元のembeddingsが10次元のクラス数にまとめられる前のモデル出力が得られますが、取り除けばlogitsで可視化できます。
embs = get_embeddings(learn.model, data.valid_dl) # body_feature_model()を除くと、モデルの最終層logitsを可視化
show_2D_tSNE(embs, [int(y) for y in data.valid_ds.y], title='ArcFace (t-SNE)')
どの手法もlossとしてモデル全体で学習されるはずですが、
どの層が一番discriminativeなfeatureになっているのか…
識者の方々、コメントお待ちしています(__)
4. CosFace
CosFace [3] も https://github.com/ronghuaiyang/arcface-pytorch の実装を使います。
def learner_CosFace(train_data):
learn = cnn_learner(train_data, models.resnet18, metrics=accuracy)
learn.model = XFaceNet(learn.model, train_data, AddMarginProduct, m=0.4) # この行を変更
learn.callback_fns.append(partial(LabelCatcher))
learn.fit(1)
learn.unfreeze()
learn.fit(5)
return learn
learn = learner_CosFace(data)
embs = get_embeddings(body_feature_model(learn.model), data.valid_dl)
show_2D_tSNE(embs, [int(y) for y in data.valid_ds.y], title='CosFace (t-SNE)')
 512次元embeddingsのt-SNE2次元可視化
512次元embeddingsのt-SNE2次元可視化
ArcFace同様、上の512次元のembeddingsに比べて、クラス数の10次元logitsを可視化した場合、クラス間の距離が取られているような可視化結果になりました。
 10次元logitsのt-SNE2次元可視化
10次元logitsのt-SNE2次元可視化
5. SphereFace
SphereFace [4] も同じく https://github.com/ronghuaiyang/arcface-pytorch の実装を使いました。
def learner_SphereFace(train_data):
learn = cnn_learner(train_data, models.resnet18, metrics=accuracy)
learn.model = XFaceNet(learn.model, train_data, SphereProduct, m=int(4)) # この行を変更
learn.callback_fns.append(partial(LabelCatcher))
learn.fit(1)
learn.unfreeze()
learn.fit(5)
return learn
learn = learner_SphereFace(data)
embs = get_embeddings(body_feature_model(learn.model), data.valid_dl)
show_2D_tSNE(embs, [int(y) for y in data.valid_ds.y], title='SphereFace (t-SNE)')
 512次元embeddingsのt-SNE2次元可視化
512次元embeddingsのt-SNE2次元可視化
SphereFaceは、10次元になっても同じようなt-SNE2次元の可視化結果となりました。
 10次元logitsのt-SNE2次元可視化
10次元logitsのt-SNE2次元可視化
6. Center Loss
Center Loss [5]は、Loss関数として実装すればネットワークに変更を加える必要はないので、その方が有利な場合にはご検討いただけると思います。
https://github.com/KaiyangZhou/pytorch-center-loss こちらの実装を使えば簡単です。
CenterLoss()で得られるLossは、
新しいLoss = 元々のLoss + 係数 x センターLoss
として使うため、WrapCenterLossを用意しました。
係数weight_centは、バランスを表示させてみながら調整しました。
class WrapCenterLoss(nn.Module):
"CenterLoss wrapper for https://github.com/KaiyangZhou/pytorch-center-loss."
def __init__(self, learn, data, weight_cent=1/10):
super().__init__()
self.org_loss = learn.loss_func
self.center_loss = CenterLoss(data.c, data.c)
self.weight_cent = weight_cent
def forward(self, output, target):
dL = self.org_loss(output, target)
dC = self.center_loss(output, target)
#print(dL, dC) この表示を有効にすると、元々のLossとCenterLossのバランスを確認できます。
d = dL + self.weight_cent * dC
return d
今回はLoss関数を下記のように入れ替えています。
def learner_CenterLoss(train_data):
learn = cnn_learner(train_data, models.resnet18, metrics=accuracy)
learn.loss_func = WrapCenterLoss(learn, train_data, weight_cent=1/8) # この行でLossを入れ替え
learn.fit(1)
learn.unfreeze()
learn.fit(5)
return learn
learn = learner_CenterLoss(data)
embs = get_embeddings(body_feature_model(learn.model), data.valid_dl)
show_2D_tSNE(embs, [int(y) for y in data.valid_ds.y], title='CenterLoss (t-SNE)')
各クラスのクラスタがまとまるように学習が促進され…、このようになりました。
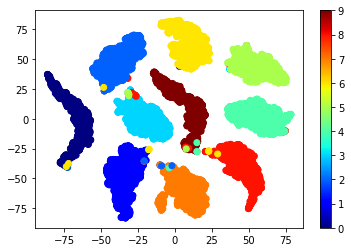 512次元embeddingsのt-SNE2次元可視化
512次元embeddingsのt-SNE2次元可視化
10次元のlogitsのt-SNE2次元可視化は、もっとわかりやすい結果となっています。
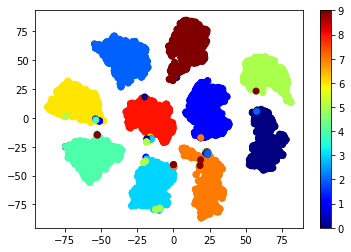 10次元logitsのt-SNE2次元可視化
10次元logitsのt-SNE2次元可視化
クラスごとにまとまっているので、分類器としての頑健性が上がっているはずですし、embeddingsの距離を比較したMetric learningとしての使い方もできるモデルが学習できた はず です。
まとめ
- 各手法を使ったMetric learningを、簡潔に実装出来ました。またfast.ai上でも、簡潔さを失わず実装できることがわかりました。
- オリジナルなコード、自分の理解を深めるにはいいんですが、使い回すには整理されたモジュールになっていてほしいですよね。
- 異常分類もそうですが、普通の分類問題の異常値への頑健性という意味でも、分類のマージンを取れる方法はいつでも併用したいものです。
- 今回有効性を確認できないものもありましたが、どれも原理的に効果が期待できます。適用したい問題に対して、実装しやすいものから試していくと、比較的簡単に結果が出るのではないかと思います。
Future work
Coming soon...
-
既知・未知クラスに対して、embeddingsの距離がどれだけ離れるか、定量的に評価。
⇒ 「深層距離学習(Deep Metric Learning)各手法の定量評価 (MNIST/CIFAR10・異常検知)」 - 分類問題の頑健性がどれだけ向上するのか、定量的に評価したいと思います。
余談: Prototypical Networksについて
Prototypical Networks [6] を使った Few-shot learning の実装を Fine Grained Classifier として再実装して使っていた経緯があります。この手法もMetric learningです。
- 未知クラスの検出(=異常検知)のため、Kaggleでもある程度の実績を上げることが出来た。
- 普通の分類器のbody部分を学習させれば良いので、ResNetなどがそのまま使えた。
- 学習が特殊なので、fast.aiなどの有利なライブラリ環境で使うことは難しかった。
特に最後の点は、Metric learningとして実際の現場で使っていくにはコストが掛かります。今回試したように、普通の分類器の学習でMetric learningできると時間も労力もかからず、何かと有利かと理解しています。たとえFew-shotの場合でも、Kaggleで多くの参加者がArcFace/CosFaceなどで良い結果を残したようです。
References
[1] R. Ranjan, C. D. Castillo, and R. Chellappa. L2-constrained softmax loss for discriminative face verification. arXiv preprint arXiv:1703.09507, 2017. https://arxiv.org/pdf/1703.09507.pdf
[2] J. Deng, J. Guo, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. arXiv preprint arXiv:1801.07698, 2018. https://arxiv.org/pdf/1801.07698.pdf
[3] H. Wang, Y. Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu, CosFace: Large Margin Cosine Loss for Deep Face Recognition, arXiv preprint arXiv:1801.09414, 2018. https://arxiv.org/pdf/1801.09414.pdf
[4] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song. SphereFace: Deep Hypersphere Embedding for Face Recognition. In CVPR, 2017. https://arxiv.org/pdf/1704.08063.pdf
[5] Y. Wen, K. Zhang, Z. Li, and Y. Qiao, A discriminative feature learning approach for deep face recognition,” in European Conference on Computer Vision. Springer, 2016, pp. 499–515. https://ydwen.github.io/papers/WenECCV16.pdf
[6] Jake Snell Kevin Swersky Richard S. Zemel, Prototypical Networks for Few-shot Learning. arXiv preprint arXiv:1703.05175, 2017. https://arxiv.org/pdf/1703.05175.pdf