以前に以下のツイートをしました。
この論文の凄さは、「DNNは学習していない」ということ。学習済モデルを全面的に信用している。それでAUC95.80%は驚愕。
— shinmura0 @ 2/27参加者募集中 (@shinmura0) September 14, 2020
凄まじく早い(学習)ので、エッジなんかで威力を発揮しそう。
(続く) https://t.co/1u6BUQsJnt
個人的に、この論文は画像分野において異常検知の決定版と認識しています。
ただ、弱点を挙げるとすれば「可視化手法がない」ということです。
本稿では、この手法で異常検知しつつ、異常部分を可視化する方法を模索します。
※コードはこちら

先に結論
本稿のターゲットは、「高精度に異常検知しつつ(detection)」、「低速+ある程度の
可視化(segmentation)」です。本稿の内容が適合していない場合、お好みに応じて
手法を変えてください。
-
ある程度のsegmentationで良い場合(本稿の内容)
detectionで学習不要はもちろんのこと、**segmentationも学習不要です。**ただし、
segmentationの際に勾配法を使いますので、推論時間(数秒)が必要です。普段は
segmentationを切っておき、異常があったときだけsegmentationを動作させるのが、
適切です。このsegmentationはテクスチャー系に強く、物体系には弱いです。 -
高精度にsegmentationしたい場合
SOTA論文が多く出されていますので、それらを参考にしてください。
ただし、detectionとsegmentationを両立した手法は、なかなか出てこないのが実状です。 -
高速にsegmentationしたい場合
以前に提案したFaster-GradCAMがオススメです。ただし、異常検知手法は
「自己教師あり学習」一択になります。
この論文の凄いところ
本題に入る前に、この論文の凄さをおさらいしておきます。
Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection
- 学習済EfficientNetを使うことで、DNNの学習は一切行わない(学習ゼロの衝撃!)
- チューニングもほとんど必要ない
- 推論時にDNNを動かすが、EfficientNetなので高速だと予想される
- しかも、AUC95%超えを達成
- batch_size=1でもいけるため、弱小PCでも動くのは地味に嬉しい
実装面を考えた場合、学習ゼロで高精度、さらに推論もある程度高速となれば、
detectionにおいて、これを超える手法はないと言っても過言ではないかもしれません。
(当然、さらなる高速化や、domain shiftに対応した異常検知など、研究の余地は
まだまだたくさんあります。)
詳しくは以下の記事を参考にしてください。
どうやって可視化するのか?
detectionが凄いことは分かりました。ここからは、どうやってsegmentationを
後付けするのか?というお話しです。
最近の研究では、教師なしで異常部分を可視化するものが多くなっています。
ただし、それらの多くは学習が必要で(そもそも学習ゼロが衝撃的なのです!)
「他の手法に後付けできるもの」はあまり多くありません。
本稿では、以下の手法を後付けして異常部分を可視化します。
ICLR2020の異常検知論文を実装してみた
元の画像を勾配法で更新していくという、これもかなり斬新な方法です。
詳しい解説はリンク先をご参照ください。
数式
数式が面倒な方は、ここを飛ばしてください。
こちらのコードに自分の好きなデータを入れれば、可視化の結果が出てきます。
segmentationの論文で、ポイントとなるのは以下の式です。
$$
E(x_t) = L_r(x_t) + \lambda ||x_t-x_0||_1
$$
この式は、画像を勾配法で更新するときに使う損失関数です。基本的にこの値が
下がるほど、画像は正常に近づいていきます。第二項は元の画像から乖離しない
ようにするための正則化項です。第一項は異常度そのものを測るもので、
元の論文では、オートエンコーダの再構成誤差が使われています。
今回はオートエンコーダの再構成誤差は使えないので、第一項には、detectionの
異常度(EfficientNetの特徴量で計算したマハラノビス距離)を使います。
また、更新式は元論文では以下の形でした。
$$
x_{t+1} = x_t - \alpha\cdot(\nabla_xE(x_t)\odot (x_t - f_{VAE}(x_t))^2)
$$
$(x_t - f_{VAE}(x_t))^2$の意味は、「オートエンコーダの再構成誤差が大きい場所
(=異常部分)ほど更新量を大きくしなさい」という意味です。ただ、今回はこれも
使えないため、非常にシンプルな以下の式を使います。
$$
x_{t+1} = x_t - \alpha\cdot\nabla_xE(x_t)
$$
恐らく、このシンプルさが災いしてsegmentation性能が劣化しているものと思われ
ます。今後、何かアイデアを思いついたら、改善したいと思います。
結果
実験には、論文と同じくMVTech-ADを使います。
segmentationは、教師無しで可視化していきます。ただし、その評価は定性的なものに
とどめておきます。定量的な評価をすると、他の論文に敵うはずはないので割愛します。
※コードはこちら
detectionのAUC
参照記事を改変しただけになりますが、一応detectionのAUCも出てきます。
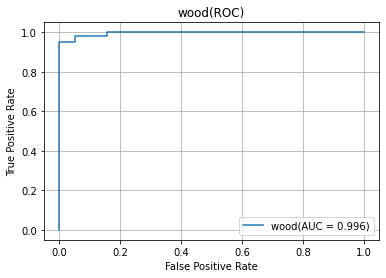
テクスチャー系
いい感じに可視化できています。

オブジェクト系
全然ダメです。

最後のケーブル、ギアっぽいもの、歯ブラシは使えるかもしれません。ちゃんと
detectionできているのですが、segmentationはうまくいかないです。残念。
まとめ
- 学習済EfficientNetのdetectionは、改めて動かすと強力かつ高速
- 本稿で紹介したsegmentationはテクスチャー系に強い