はじめに
MVTec-ADデータセットという工業検査に焦点を当てた異常検出手法をベンチマークするためのデータセットに対し、ImageNet等の通常の画像分類タスクを学習したモデルを用いて高精度な異常検知を行う手法に関する論文[1]があります。
論文[1]によると学習済みのEfficientNetの各ブロックから抽出した特徴量を多変量ガウス分布(MVG)に当てはめてマハラノビス距離を異常スコアとすることでAUROCが96.7% ± 1.0% もの高さを叩き出せるそうです。
論文[1]より引用(Fig.1の抜粋)
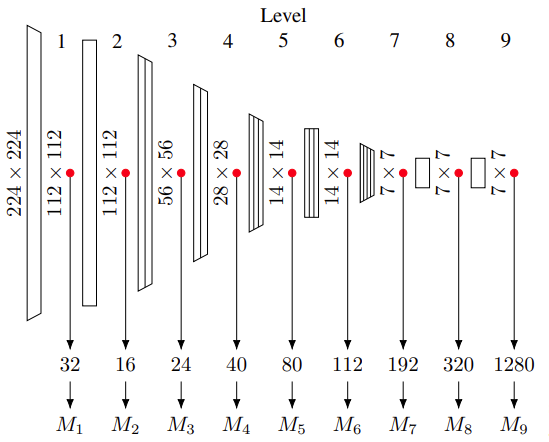
このように各ブロックから取得した特徴量をLevel1, 2... の特徴量として、マハラノビス距離を利用して異常スコアを算出します。どのLevelの出力が異常検知に適しているか確認するため、各Levelの特徴量からスコアを算出した場合と全てのLevelのスコアの合計をスコアとしてAUROCを確認しています。
※画像はEfficientNet-B0のケースなのでサイズが変わればM_nのパラメタ数は変わりますが、理屈は一緒です。(ここで言うブロックはMBConvブロックではないので注意。level1はstem、level9はtop、その他はMBConvブロックからの出力を利用します)。
面白いことにEfficientNetのサイズに関わらず、MVTecデータセットの大半のラベルでLevel7の出力を利用すると最もAUROCが高くなります。概ねLevel1が最も低くLevel7を最大としてその後減少傾向にあるようです。論文[1]ではEfficientNetはImageNetにOverfittingしている可能性があるかもしれないと考察していたので、Noisy-Studentで学習したEfficientNetなら
- Level8やLevel9の出力がより高いAUROCを出すことになるか
- Level7が最大だった場合、AUROC向上が見られるか
を確認してみました。実装の全体は多少整理してからgithubにあげようと思います(が、いつ時間が取れるか微妙なのでとりあえず動きはするコードをgistに上げておきます)。
※普段Tensorflowを使っているのですがどこか実装を間違えたみたいでImageNetで学習したEfficientNetでもロクなAUROCになりませんでした。公式実装[2]を参考に普段使わないPyTorchで書いたのでPyTorchらしい書き方はしていません。書き方は気にしないでください(汗
異常スコア計算の流れ
マハラノビス距離を異常スコアとして利用するので、下記をラベル毎に実施する必要があります。と言ってもそれほどやることはありませんし実装も難しくないです。改めて論文[1]の凄さを感じます。
- 訓練データ全画像を使って正常データの特徴量を抽出
- 訓練データの特徴量の平均と分散を算出
- テストデータ1枚の特徴量と、訓練データの特徴量の平均と分散から距離を算出(テストデータ全画像でループ)
ここからは上記の実装について簡単に見ていきます。実際にはラベル毎に、Level毎に計算する必要がありますが、理屈は一緒なのでループ部分は省略します。また、訓練/テストデータはMVTec-ADのtrain/testデータを指しています。データセットの特徴上訓練データは正常データのみ、テストデータには正常/異常データが含まれています。実運用を考えるのであればテストデータの一部を使って異常スコアの閾値を決めて(かつk-holdして)、分類精度を測るべきだとは思いますが、今回は単純に全テストデータの異常スコアを算出して正常/異常フラグからsklearnのroc_auc_scoreに渡します。
特徴量の抽出
Noisy-Studentの学習済みモデルを利用するためにtorchからEfficientNetを持ってくるのではなくtimmから持ってきます。モデル構築時にMBConvブロックをblockオブジェクトにまとめてくれているので特徴量抽出が非常に簡単になります。
import timm
model = timm.create_model('tf_efficientnet_b4_ns', pretrained=True)
model.to('cpu') # GPUが用意できれば'cuda'
from timm.timm.models.efficientnet import EfficientNet
import torch
import torch.nn.functional as F
def extract_features(inputs: torch.Tensor,
model: EfficientNet) -> Dict[str, torch.Tensor]:
features = dict()
# extract stem features as level 1
x = model.conv_stem(inputs)
x = model.bn1(x)
x = model.act1(x)
features['level_1'] = F.adaptive_avg_pool2d(x, 1)
# extract blocks features as level 2~8
for i, block_layer in enumerate(model.blocks):
x = block_layer(x)
features[f'level_{i+2}'] = F.adaptive_avg_pool2d(x, 1)
# extract top features as level
x = model.conv_head(x)
x = model.bn2(x)
x = model.act2(x)
features['level_9'] = F.adaptive_avg_pool2d(x, 1)
return features
通常のEfficientNetを使う場合は上手いことブロックの出力を得るために工夫が必要みたいです。公式実装[2]のこのファイルを参照してください。
特徴量の平均、分散の算出
ここは単純にsklearnに渡しておしまいです。実際はLevel毎にループすることにはなりますが。
import torch
from sklearn.covariance import LedoitWolf
feat_list = features[f'level_{level}'] # levelは1~9のint, featuresは上述のextract_features()結果
feat = torch.cat(feat_list, 0)
mean = torch.mean(feat.squeeze(), dim=0).cpu().detach().numpy()
cov = LedoitWolf().fit(feat.squeeze().cpu().detach().numpy()).covariance_
異常スコアの算出
ここもsklearnに渡すだけです。実際はLevel毎にループすることにはなりますが。
import numpy as np
from scipy.spatial.distance import mahalanobis
mean, cov = 訓練データ特徴量の平均と分散
cov_inv = np.linalg.inv(cov)
feat_list = テストデータの特徴量リスト
scores = [mahalanobis(feat, mean, cov_inv) for feat in feat_list]
実装のキモになる部分は以上です。算出したスコアと正常異常のフラグのリストをsklearn.metrics.roc_auc_scoreに渡してあげればAUROCが得られます。
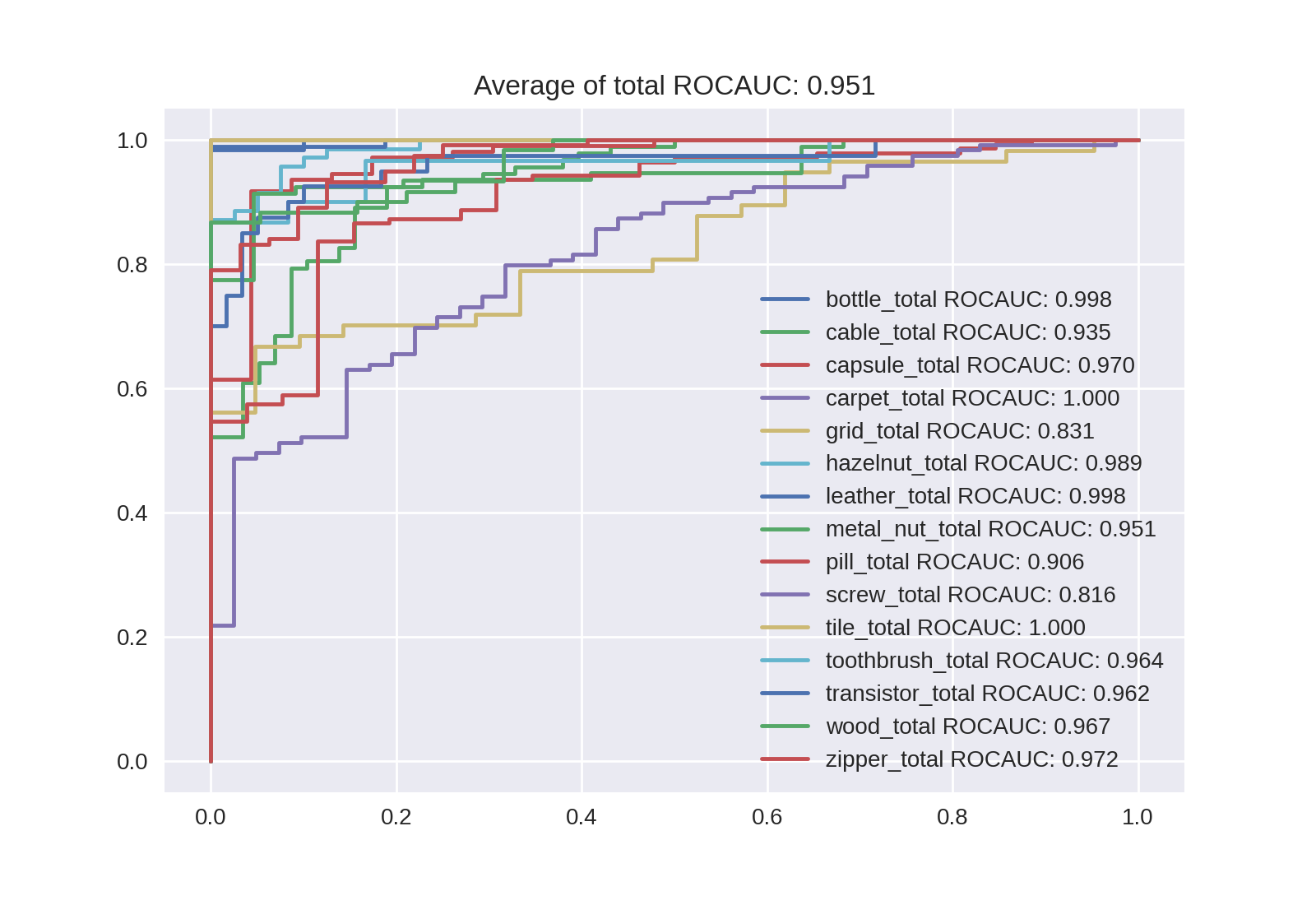
Noisy-Studentの分類結果
| EfficientNet-B4 | EffifientNet-B4-NoisyStudent |
|---|---|
| 0.951 | 0.945 |
 |
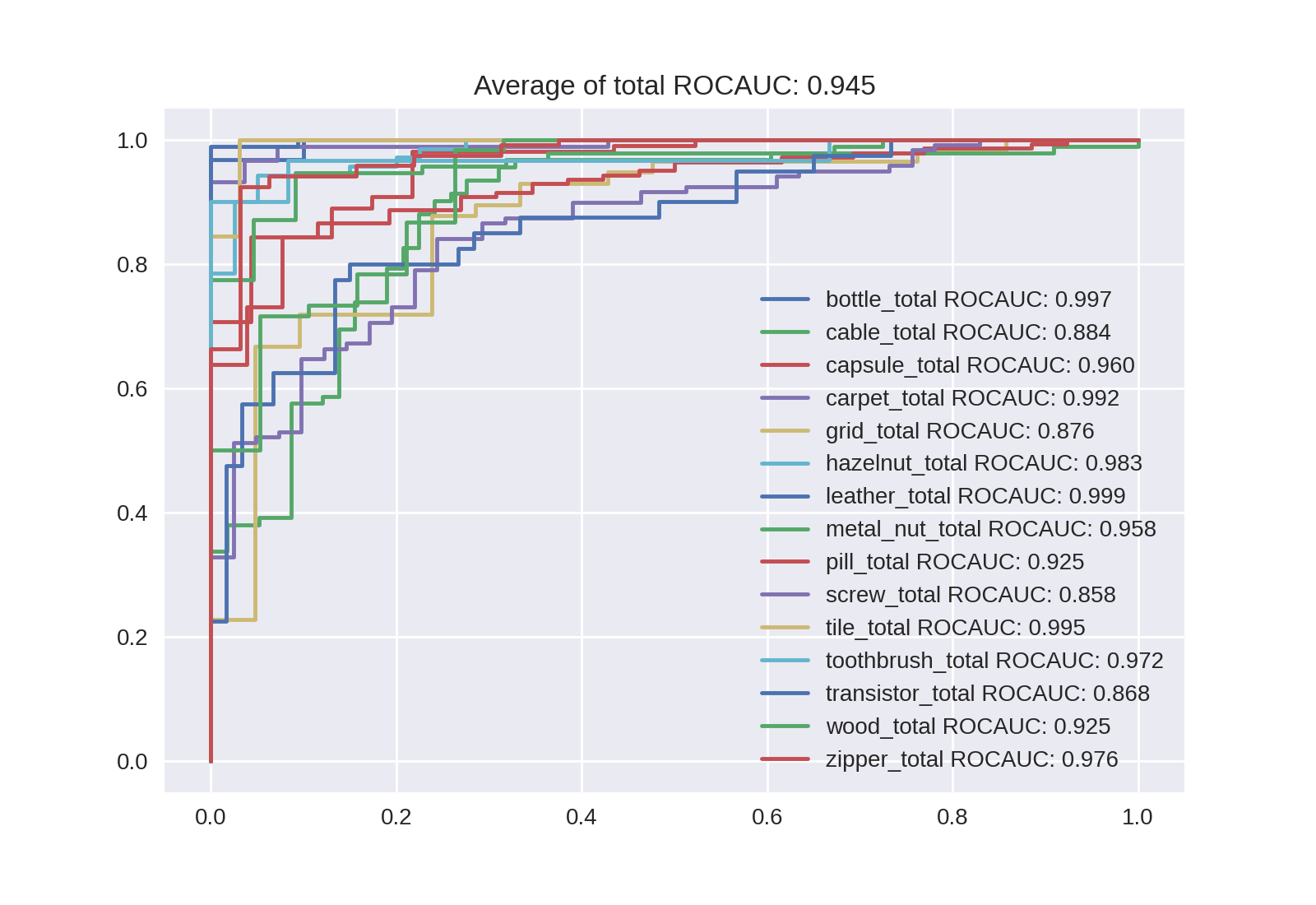 |
Level毎のAUROCも出力しているのですが、量が多く画像サイズが大きくなってしまうので全レベルの異常スコアの合計を異常スコアとした場合のROC曲線とAUROCを貼りました。残念なことにNoisy-StudentのほうがAUROCが下がってしまっていますね...。異常スコアの確認で図と共に後述するように、Level7よりLevel8のほうが良くなることも1ラベルを除きありませんでした。
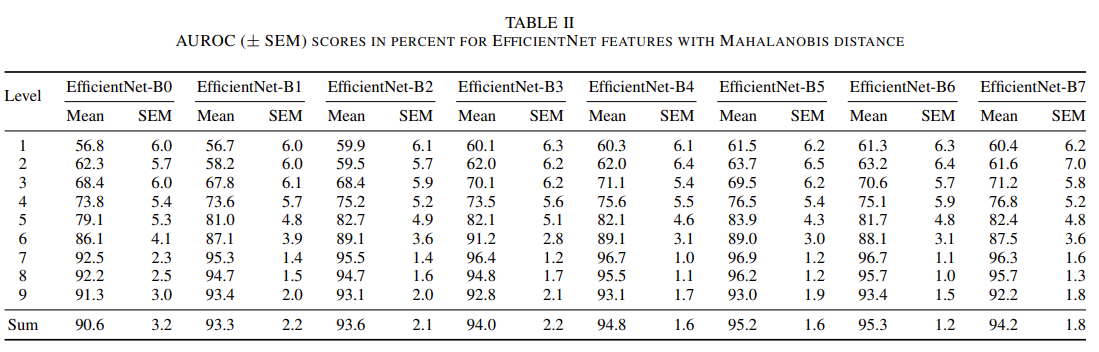
ただ、このまま終わるのは残念なので、より大きなサイズのEfficientNetでAUROCが向上するか確認してみました。論文[1]ではLevel7だけを抽出した場合はB4が最も高く、合計した場合は下記の通りB6まで増加傾向、B7で減少します。
論文[1]より引用(TABLEⅡ)
Noisy-Studentの場合は次のようになります。ROC曲線は興味があればクリックして拡大してください。
| B4 | B5 | B6 | B7 |
|---|---|---|---|
| 0.945 | 0.957 | 0.965 | 0.968 |
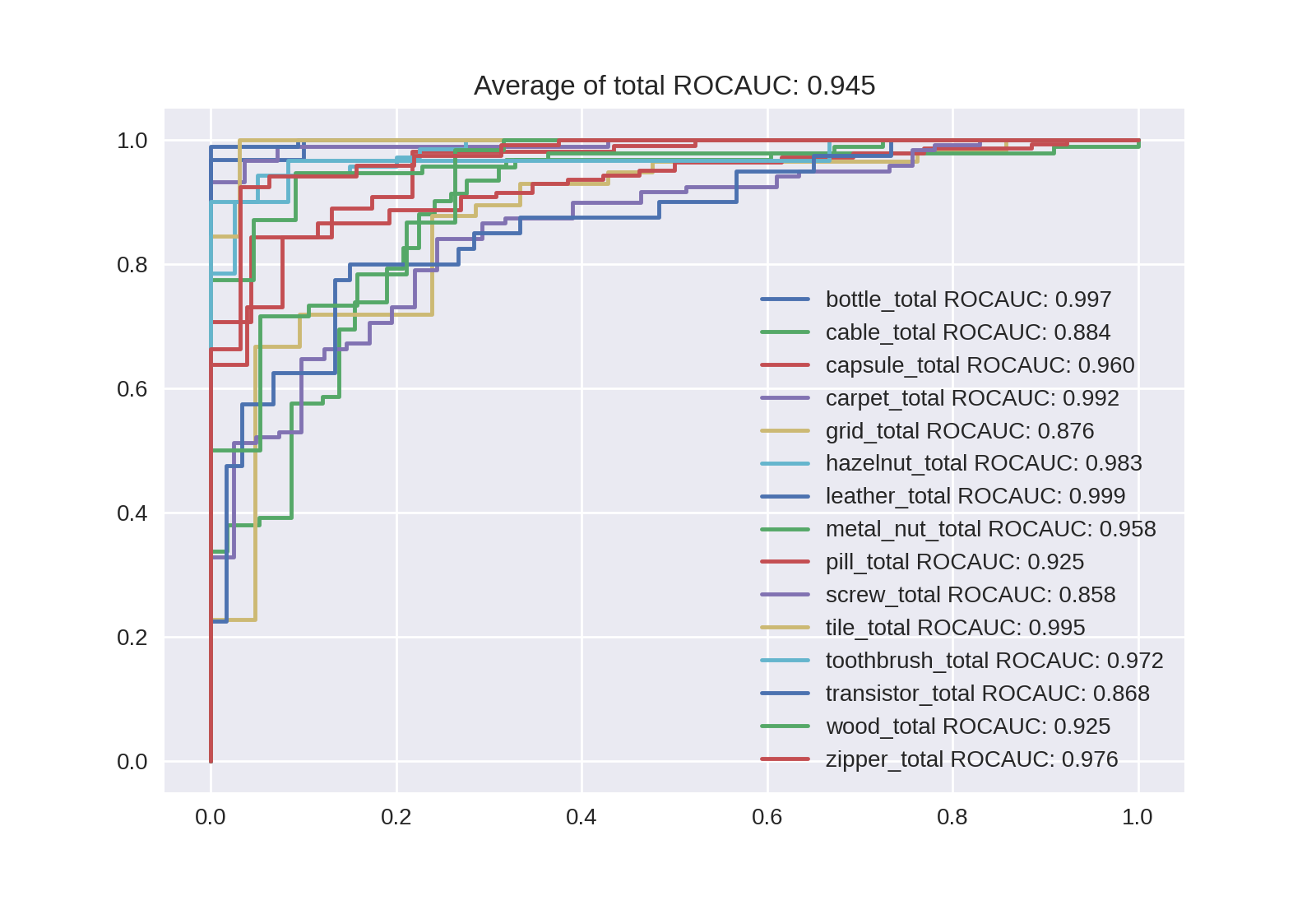 |
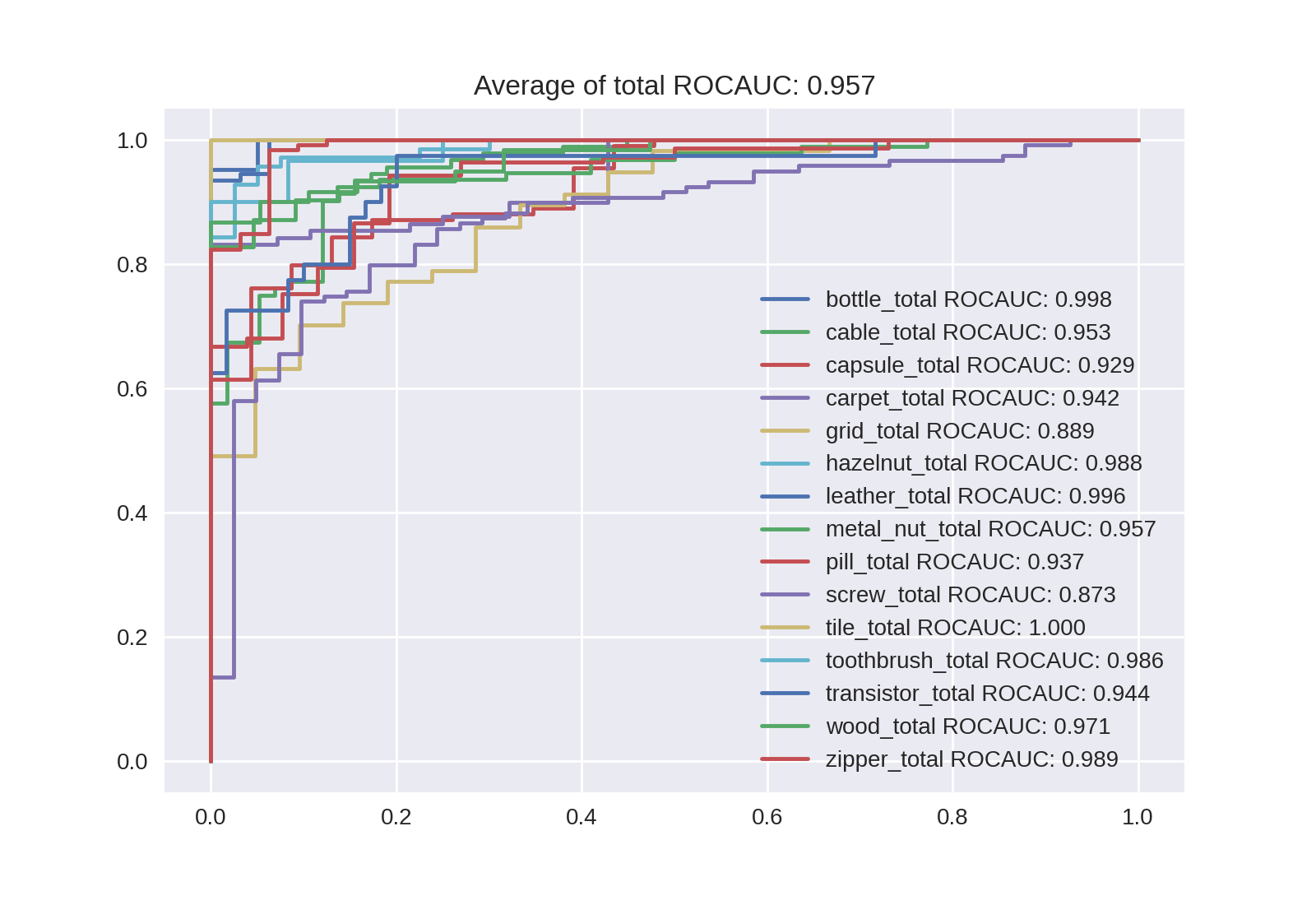 |
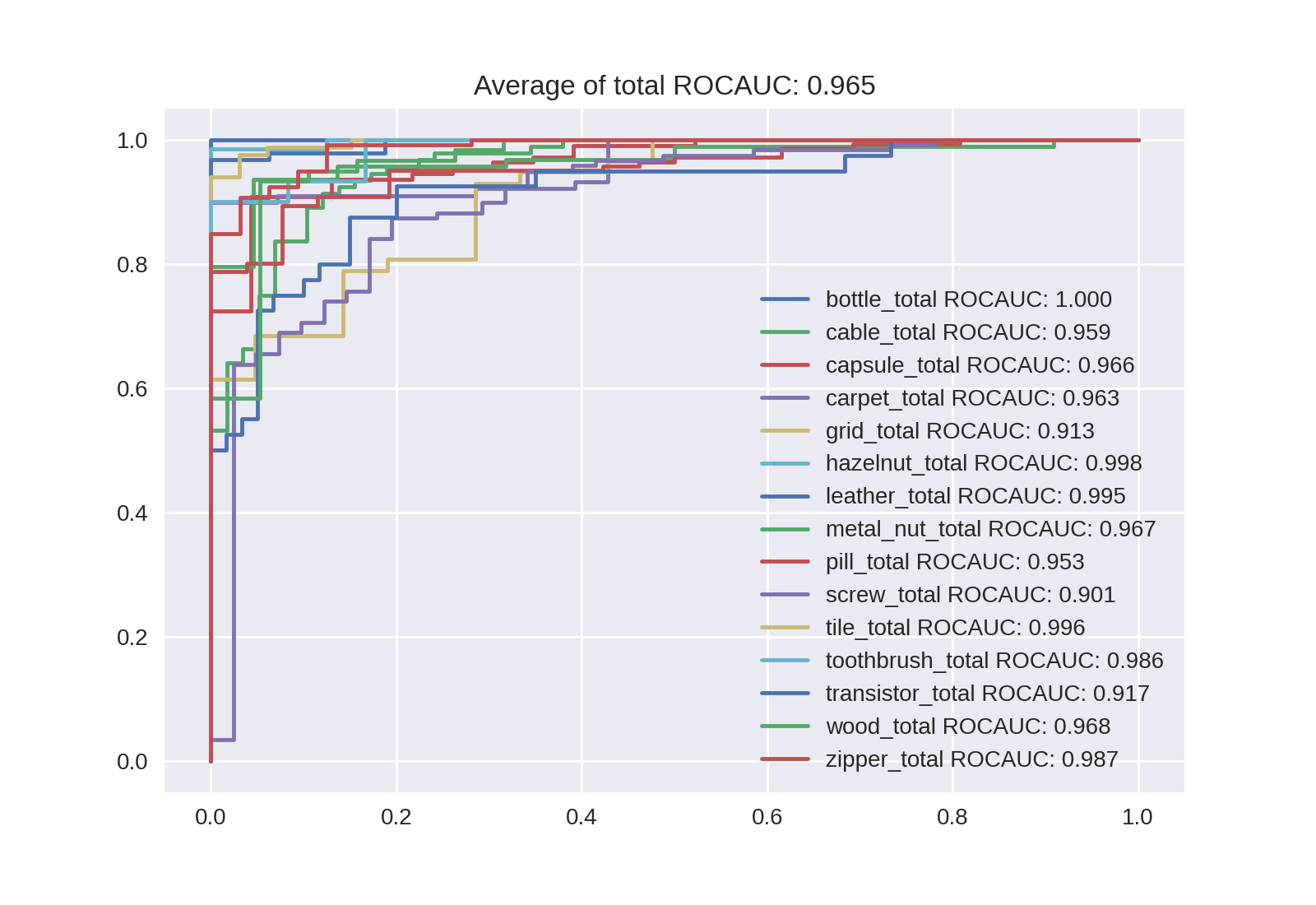 |
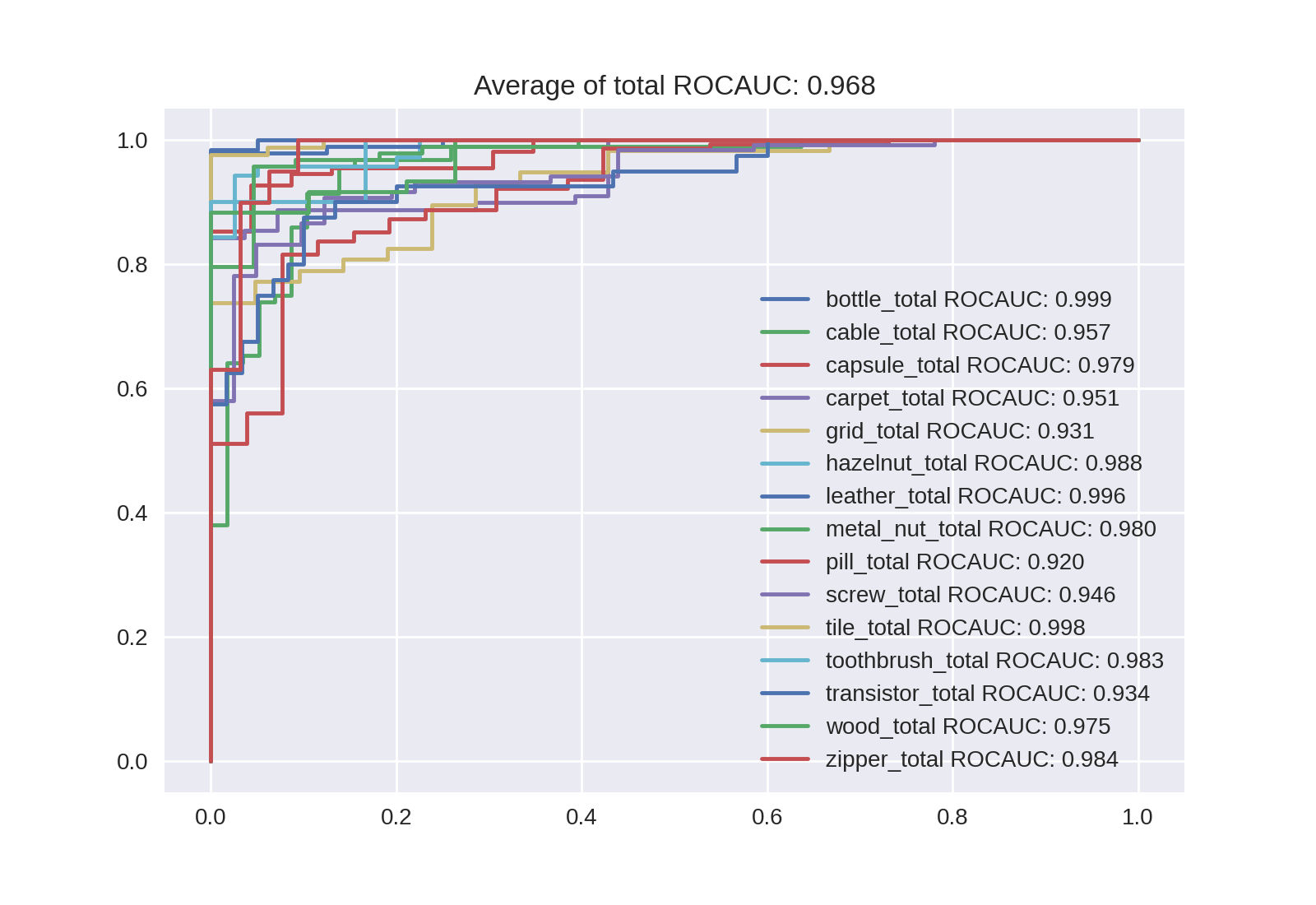 |
微増ですがサイズの拡大でAUROCが向上していることが確認できます。論文[1]では5-holdしていて今回は特になにもしていないので、誤差の考慮ができていませんが、Noisy-StudentのほうがAUROCが高くなる可能性もあるかなと思います。L2まで行くと下がってしまいますが、L2_475ではB7以上のAUROCが出ました。異常スコアの確認で後述しますが、Level7よりもLevel8のほうが高くなるケースも複数ありました。分類結果の最後として最もAUROCが良かったL2_475のROC曲線を貼っておきます。
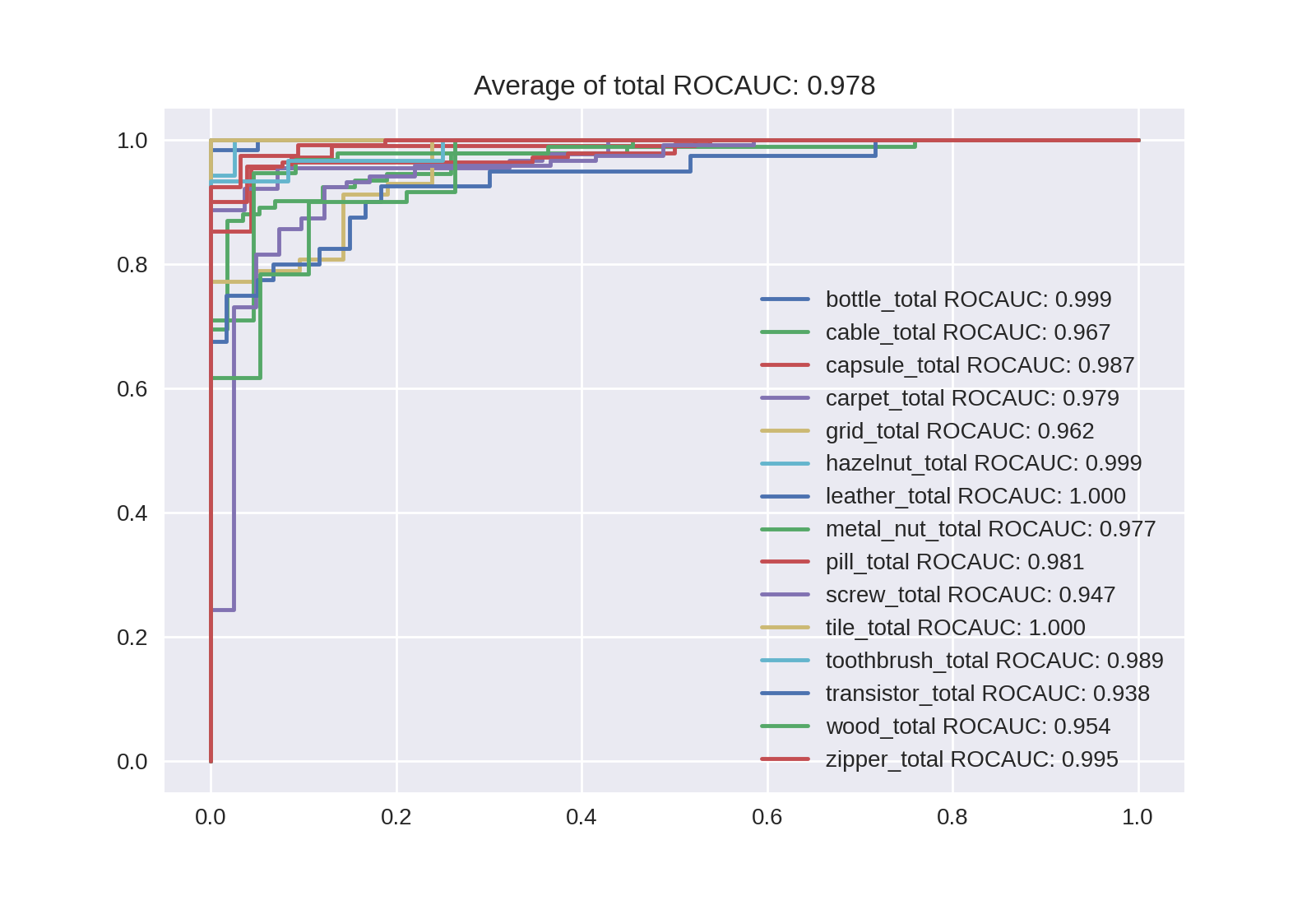
異常スコアの確認
今回のAUROCは単純に異常スコアと正常/異常フラグから算出しただけのものです。実運用を考えると異常スコアから異常の閾値を決めておき、製造した画像を判定にかけるべきでしょう(そもそもこんなにキレイに異常が写せるかという問題はありますが、今回はデータセットのように画像が安定して取れる前提で考えます)。
非常に簡単になってしまいますが、異常スコア(距離)をヒストグラムにしてみました。下記はB4-Noisy-Studentのmetal_nutのヒストグラムです。
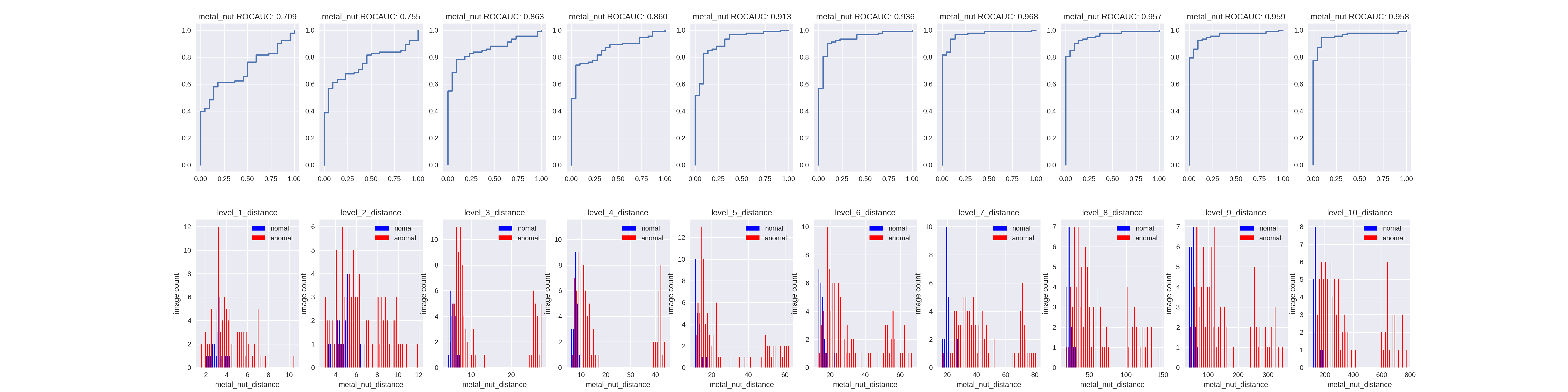
基本的にはこのようにLevel7が最大でその後減少傾向にありますが、L2-Noisy-Studentだと7/15ラベルでLevel8がLevel7を超えているのとLevel7以降がAUROC1で比較できないケースが2つあるので、L2に限ってはLevel8のほうが良い可能性もあります。
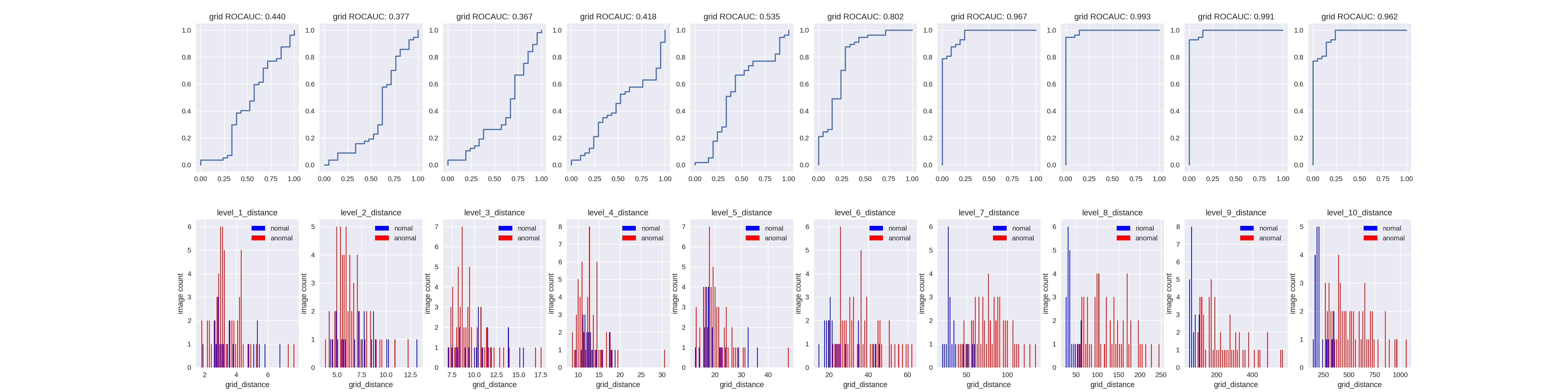
論文[1]を読んでいるときはLevel7が最良になるのはImageNetにOverfitし始めているかもしれないって記載に納得していましたが、最も大きいL2でより深い層が適しているとなると、他にも理由がありそうな感じもします。(元論文もLevel7が最大になる理由についてはあまり考察しておらず、かもしれないくらいの記載ですからここはわかりませんね。単純に深い層より浅い層のほうが模様とか色とかを捉えやすいって話かもしれないですが。)
とは言えL2は非常に大きくやや使いにくいと思われるので、基本的にはLevel7の特徴量を利用するのが最良でありそうです。ただ、単純にAUROCの値だけでなく閾値の決めやすさや人間が納得しやすさも踏まえたモデル選択が実運用では必要だと思います(今回はスコア見ただけですがスコアと画像セットで見たり許容できるFPRで設定するとか)。今回は行っていませんが、異常に近い正常やその逆の画像を見て追加のアプローチも必要そうです(人手なのか画像処理なのかは別として)。
ラベルによってはより小さいサイズのEfficientNetのほうがAUROCが高い場合もあるので、様々なサイズ、Levelで異常スコアを算出してみて分類器として利用することを考えると、学習不要で簡単に作れるこの手法は素晴らしいですね。Colabを使えばとりあえず試してみるコストもかなり抑えられますし、もし常に同じような条件で画像が取れるものがあれば試してみたいと思いました。
備考
論文[1]では他にもPCAで次元削減してみたり、分散が小さい成分が重要な可能性があることを説明したり短いですが色々詰まっています。真面目に論文を読んだのは今回が初めてですが、かなり読みやすかったので論文読んでみようかなって方にもオススメです。
References
- [1] Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection. https://arxiv.org/abs/2005.14140
- [2] 論文[1]の公式実装: https://github.com/ORippler/gaussian-ad-mvtec
- [3] MVTec-AD 今回のデータセット: https://www.mvtec.com/company/research/datasets/mvtec-ad/
- [4] マハラノビス距離について: https://mathwords.net/mahalanobis