この記事では
この記事では、画像の異常検知について、2年前の論文で提案された手法を深堀りして、その有用性について見ていきたいと思います。以下のような特徴に注目しました。
- シンプルで効果的な画像の異常検知手法。
- 通常のCNN分類器、データ拡張の主な手法、これだけ。
- 理論的背景もシンプルで、企業等で応用展開しやすい。
画像の異常検知としては、画像の再構成誤差を使ったものに加えて、深層距離学習を使ったものが注目されていると思います。深層距離学習について昨年深く見てみました。
- 深層距離学習(Deep Metric Learning)各手法の定量評価 (MNIST/CIFAR10・異常検知)
- 欠陥発見! MVTec異常検知データセットへの深層距離学習(Deep Metric Learning)応用
これらもCNNを使ったもので、比較的シンプルで性能が高く、汎用性があります。しかし距離学習としての仕組みがあり、全結合層・Softmaxの演算をよく理解する必要があります。
今回の手法では、CNNの分類器を本当にそのまま使うだけで、異常検知が可能になります。
論文について
NIPS2018で発表された手法[1]で、イスラエル工科大学の修士論文(!)です。アイデアはこんな感じです。
- 画像を様々にデータ拡張に変換したものを与えると、正常な画像と異常な画像とでは分類器の出力する確率が異なるはず。
- 正常なときに比べて、異常なときは確率が下がるだろう。
- 正常なデータを様々にデータ拡張して、__自己教師あり学習__の枠組みでCNN分類器を学習させよう。
- データ拡張の中でも、幾何的な変換(90度回転・反転・シフト)がそのような前提に寄与するだろう。
こんなシンプルな仮説でいいんでしょうか…
関連分野: CNNの事前学習でよく行われる自己教師あり学習
この論文のアイデアに似ていることとして、CNN転移学習のための事前学習、それも教師無しでの学習が様々に研究されています。今回の論文のように幾何的な変換を使う方法は、この中の一つと同じことをしていると考えられます。以下のサーベイ論文[2]でまとめられたカテゴリーのうち、__Context-BasedのGeometric Transformation__に相当すると考えられます。
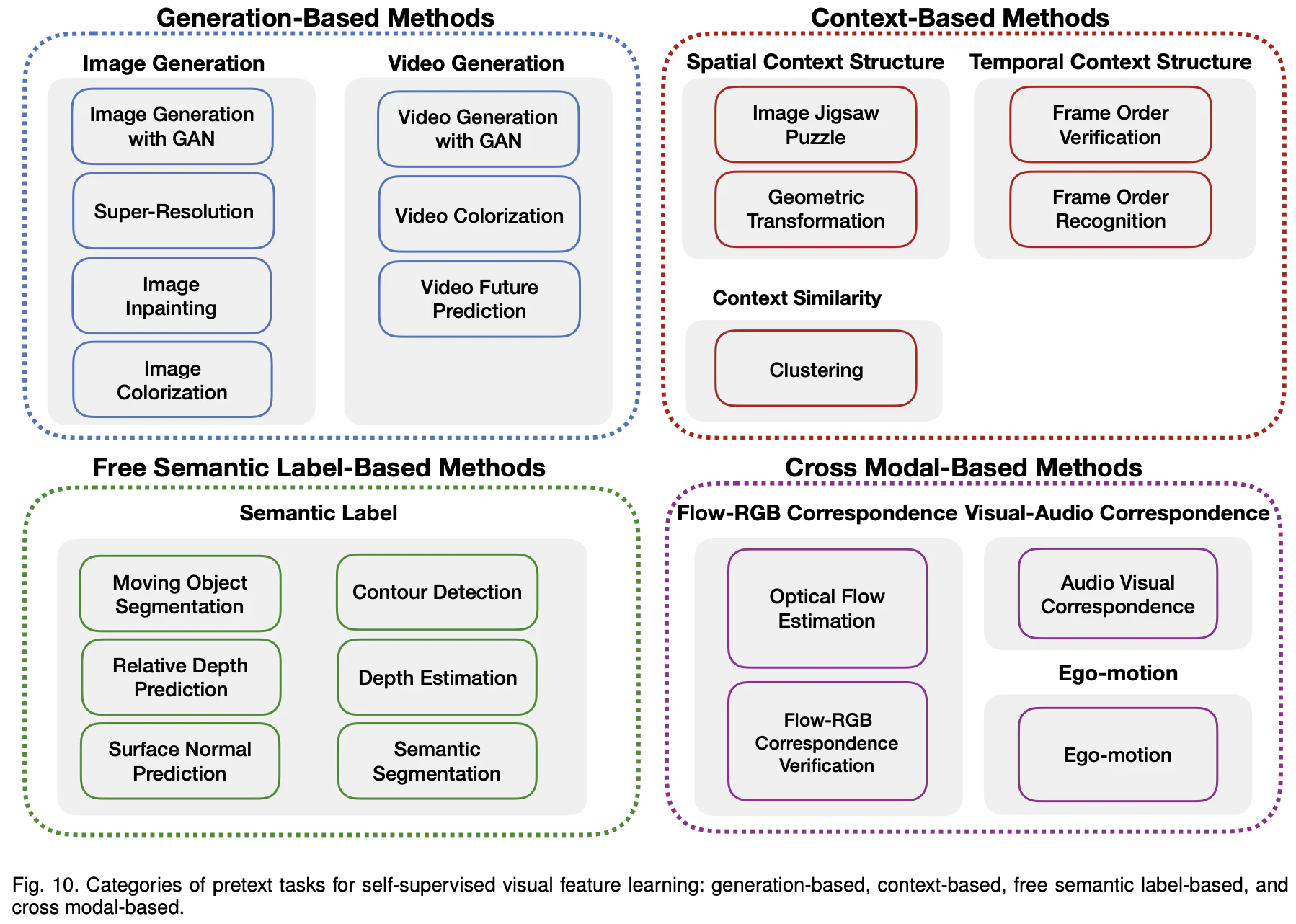
(サーベイ論文「Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey」[2]より)
論文での仮説検証〜アイデアの裏付け
本当にこんなシンプルなアイデアが有効なんでしょうか。
論文の「6 On the Intuition for Using Geometric Transformations」では、MNISTを使った実験で検証しています。
- 検証1 通常を'8'の画像で学習させて、異常を'3'として判定させる。そのときデータ拡張は[そのまま, 水平反転]の二種類のみ。
- 期待: '8'は左右反転しても不変なので、分類器は違いを学習するのは困難だろう。
- 結果: 予想通り、異常データ'3'を混入させたテストでAUROCが0.646と悪い結果。
- 検証2 通常を'3'の画像で学習させて、異常を'8'として判定させる。データ拡張は[そのまま, 水平反転]の二種類のみ。
- 期待: '3'の水平反転を分類器は学習できるだろう。
- 結果: AUROCは0.957に達した。
- 検証3 通常を'8'の画像で学習させて、異常を'3'として判定させる。そのときデータ拡張は[そのまま, 7ピクセルシフト]の二種類のみ。
- 期待: シフトによる変換は識別できるので、分類器は学習できるだろう。
- 結果: 予想通り、AUROCは0.919に達した。
もっと確証を得るために、高い正常性スコア(後述)を得るためには画像がどうあればいいのかを実験しています。
画像の勾配を逆にたどる形で画像補正を繰り返すことを(CNNを攻撃する画像を作る目的と似たような形で)、gradient ascent (最急上昇法) を応用して行い、分類器の出力確率が高くなる画像を生成してみようということです。

([1]「6 On the Intuition for Using Geometric Transformations」より)
- 検証(a): 未知の'0'を学習済み'3'に近づけてみる。
- 結果: 引用した画像(a)の通り、左側の'0'は補正により'3'に読めそうな形に変化しました。
- 検証(b): 既知の'3'にgradient ascentを適用してみる。
- 結果: 想定通り、'3'はそのままで変化しませんでした。
既知・未知のデータに対して幾何的な変換を施すことで、学習済みのCNNの振る舞いがある程度確認できました。幾何的な変換でCNN分類器の出力確率が小さくなることが、少なくとも検証1~3の結果から期待されます。
Normality Score (正常性スコア) について
モデルの出力をもとに「正常性(Normality)」を数値化することで、異常な場合を検出できるようにします。
計算方法はディリクレ分布を使って定式化されいます。素晴らしい論文の解説スライドが公開されていますので、詳しくはそちらを参照して下さい。
しかし、実は簡易計算できます。

(「最新の異常検知手法(NIPS 2018)」解説スライドより)
論文で数式が展開される最後に、こんなことが書かれています。

([1]「4.2 Dirichlet Normality Score」より)
- 簡略化されたスコア関数では、ディリクレ分布のパラメーター推定不要で、簡単に実装できる。
- 少し精度が悪いだけ。
この記事での再現実装では、この簡易計算を利用します。正常性スコアn_sは、下記の通り簡単に計算できるのです。
$n_s(x) = すべての幾何変換{i}に対するモデルの出力確率 y_i(x) の平均$
論文の数式を真面目に読み進むと、最後に少し隠れて 単なる平均でいいんだよ と…。検証していませんので小声ですが、殆ど変わらないのでは、と個人的には見ています。
MVTec異常検知データセットでの独自検証
それではリアリティデータで検証してみます。その「MVTec Anomaly Detection Dataset (MVTec AD)」についてはこちらを御覧ください。
この工業的な応用での実際に近いデータセットで、どのくらいのパフォーマンスが出たのでしょうか。
今回は、90度回転を施した4つのラベルを学習させました(回転なし、90度、180度、270度回転)。
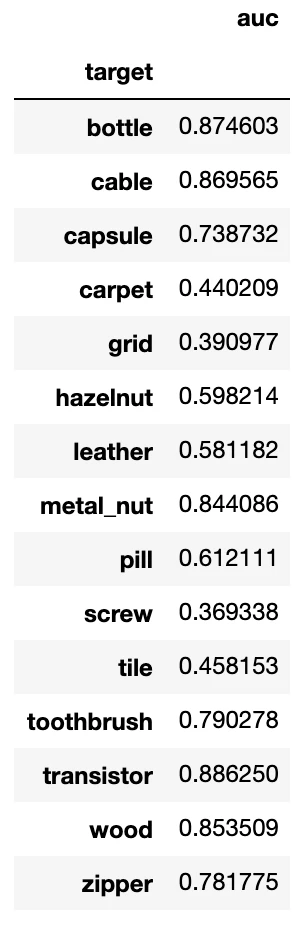
高スコアを記録したもの、そうでないものが分かれました。
- 得意、不得意があり、適用する対象を選ぶ手法であることを示している。
- 得意なものには妥当な結果が得られるが、不得意なものには適用してはいけないことも示唆している。
得意な対象
__幾何変換すると画像の意味が変わること__が条件です。下記にまとめられると考えます。
- 上下・左右といった方向性を持った対象であること。
- データセット自身が決まった方向で撮影されていること。
結果を種類別に解釈していきましょう。
bottle: AUC 0.874603

0-3は、90度ずつ回転したことを表すラベルで、0は回転なしです。このデータは意外だったのですが、ポイントは光が反射している部分かもしれません。テカっている部分は、回転により位置が変わります。この関係性を利用して分類器は学習したのでは、と考えられます。
cable: AUC 0.869565
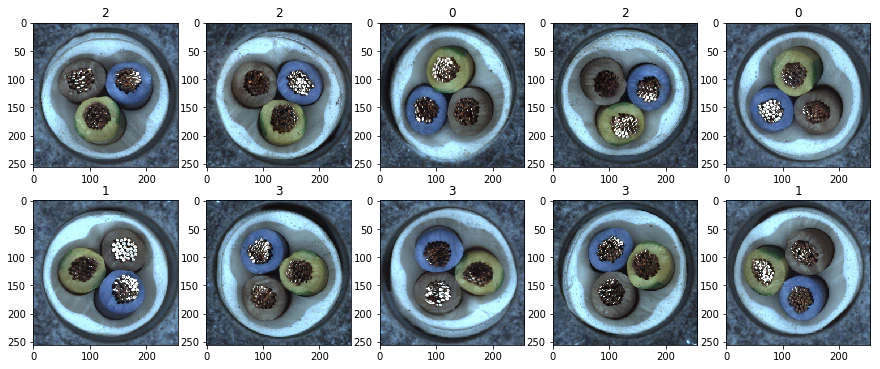
このデータは明らかに方向があります。3つの線はそれぞれ色が決まっているデータなので、分類器は容易に学習できるでしょう。
transistor: AUC 0.886250

このデータも明らかに分類器は方向を学習できるでしょう。
不得意な対象
不得意は全く得意の反対の特性を持ったデータになると考えられます。
- ランダムなテクスチャのように、方向性を持たない画像。
- 方向性のある対象であっても、対象が決まった構図で撮影されておらずランダムにまちまちである場合。
不得意…というより、意味がないので適用してはいけない、と理解すべきかと考えています。
grid: AUC 0.390977

もともと方向がなく自由に撮影されたデータに見えます。一方向から撮影されていれば方向感は出たと思いますが、ランダムな方向は当然学習できなかったと考えられます。
screw: AUC 0.369338

こちらも形状に上下左右はあるものの、撮影の方向がバラバラでした。
tile: AUC 0.458153

明らかにそもそも方向性のないデータですので、学習できなかったものと考えられます。
ヒートマップは?
今回あえてGrad-CAM等のヒートマップを試していません。モデルがどこを見て判断しているのか、ある程度解釈の参考になると思いますが、対象によってまちまちになると想定したため、時間の都合上割愛しました。
しかし何かinsightが得られるかもしれません。気になる方は是非トライしてみて下さい。
おわりに
これまで、シンプルで効果的な手法の論文について紹介し、論文自体での検証内容、有効性をMVTecADデータセットを使った独自検証を通して見てきました。
- シンプルに実装できて、有効な対象には実用的に役立つレベルのAUCが得られることが確認された。
- シンプルなので、設計検証・品質保証などのコストが低く抑えられると考えられます。
また、論文の最後には面白い展望で締めくくられています。
- 応用したい対象(物体の見え方)の知識を予め利用すれば、幾何変換の方法を最適化できるのでは。
- 変換自体の最適化を行えるのでは、そして他のタスク、例えばクラス分類問題などのパフォーマンスを上げられるのでは。
- "Deep uncertainty estimation"や"Deep active learning"に応用できるのでは。
シンプルなアイデアは、本当に幅が広いなと再認識しました。ぜひ応用してみたいと思います。