3. 分析編
Cloud Pak for Data as a Serviceハンズオンメニュー一覧
本記事では、上記の1.構築編、および2.設定編によって準備された環境を用いて、データユーザがどのようにデータを検索し分析環境へ持っていくか、という導線を体験いただくように記載しています。
公式ドキュメント
- IBM Cloud Pak for Data as a Service の公式ドキュメントはこちらをご参照下さい。
1.データ検索
- CP4D画面上の検索窓(Global Search)から、例えば顧客情報を得たいので、「顧客」と入力してエンターキーを押します。
2.ビジネス用語の確認
顧客、という検索の結果、複数の結果が出ました。
まずはビジネス用語として出てきた「オンライン顧客」という用語を確認します。
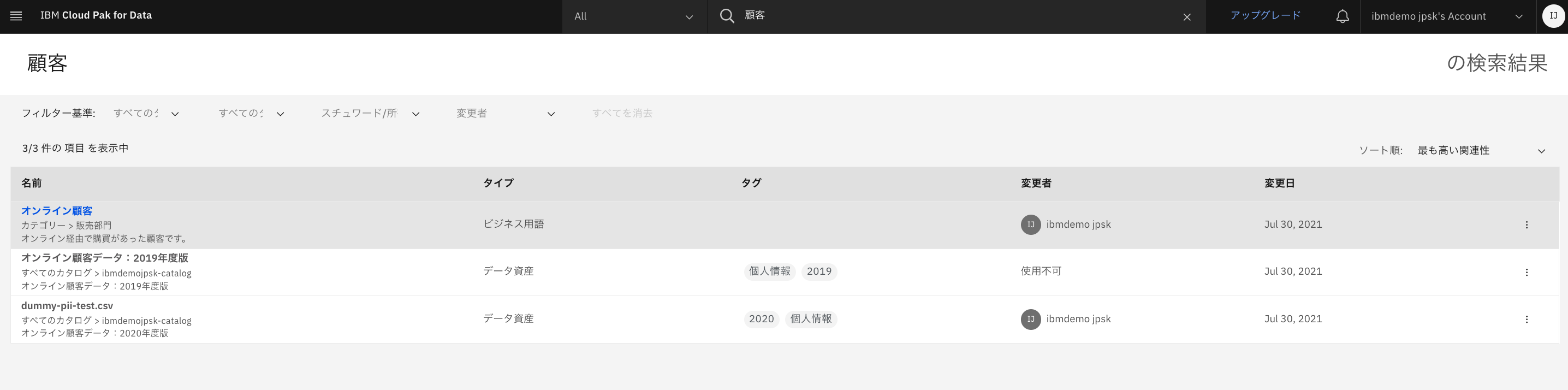
オンライン顧客、というビジネス用語を確認します。
ここで、関連コンテンツ、という箇所を見てみましょう。
2.1.関連コンテンツ(データ)の確認
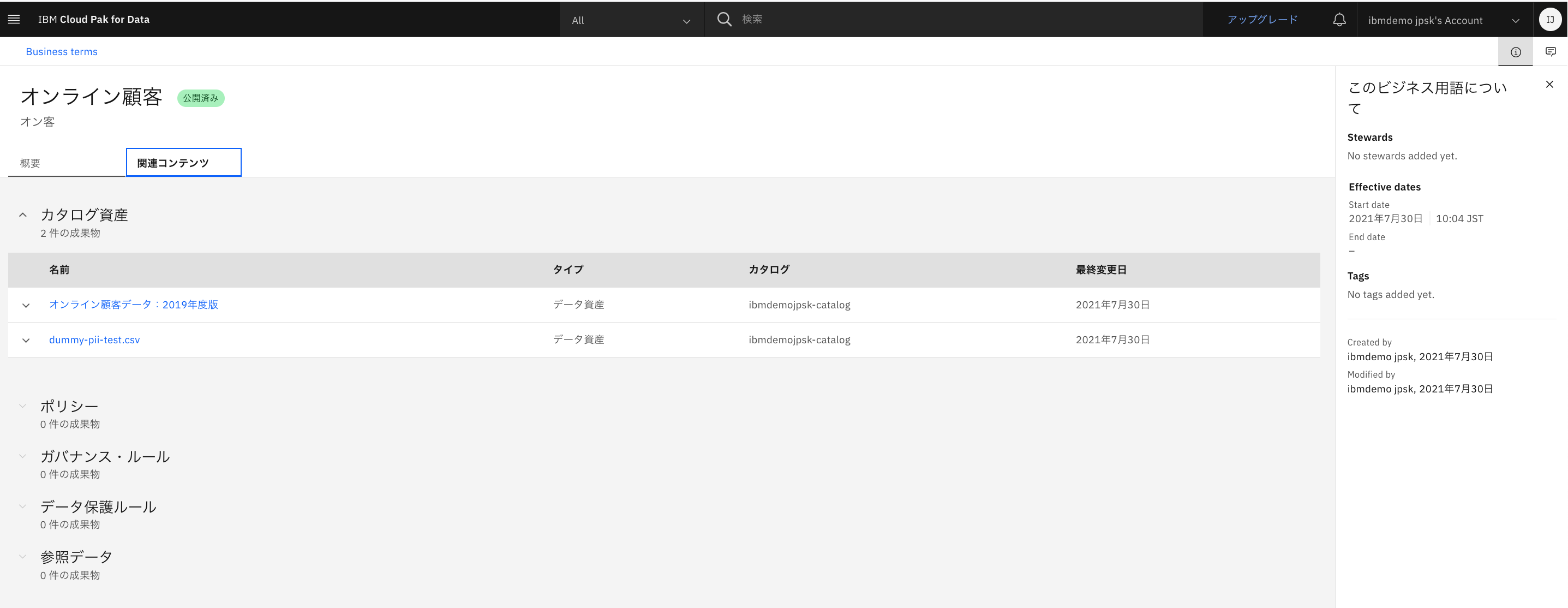
3.関連するカタログ上のデータ(オンライン顧客データ)の確認。
- ビジネス用語に紐付けられたカタログ上のデータが表示されます。
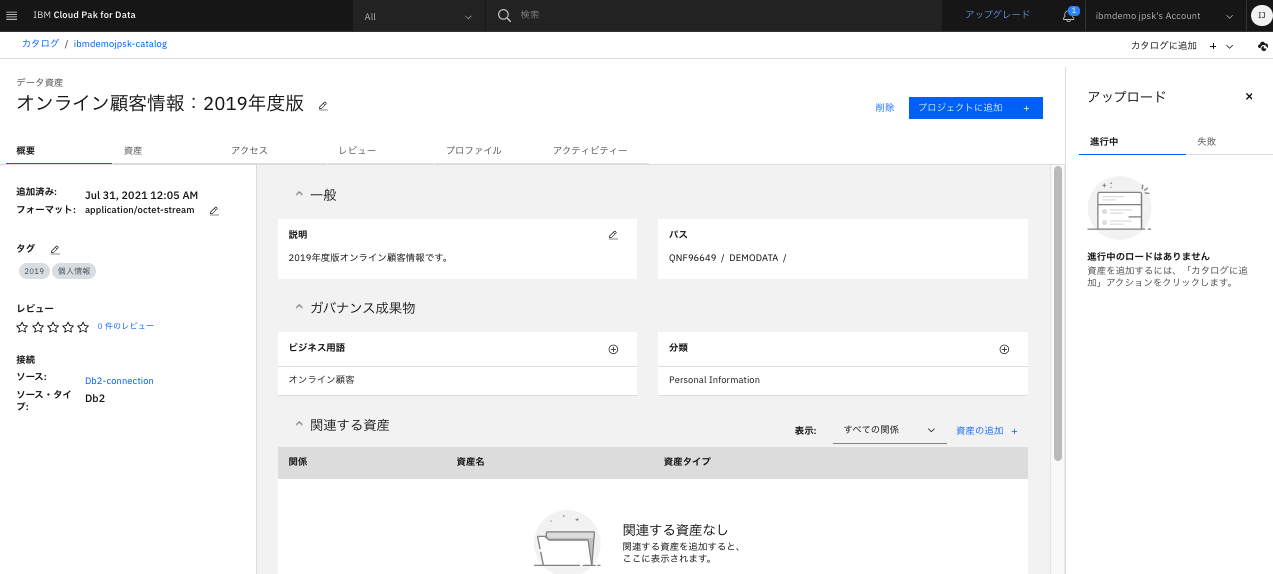
3.1.概要 タブ
- データに関する一般的な説明、データの格納パス、ビジネス用語や分類等のメタデータ等が確認できます。
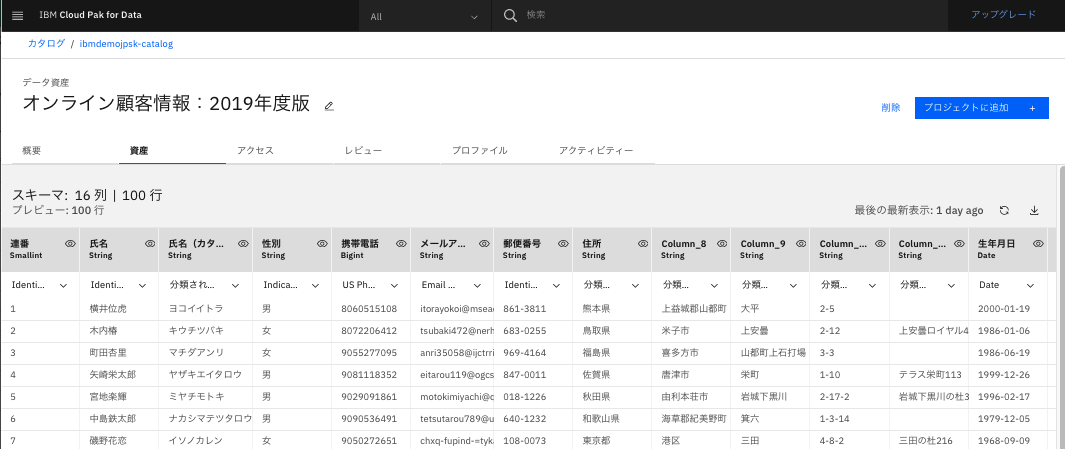
3.2.資産 タブ
- データのプレビューが見られます。なお、マスキングしている場合でも、このデータの管理者であるIDではデータ自体はマスクされません。
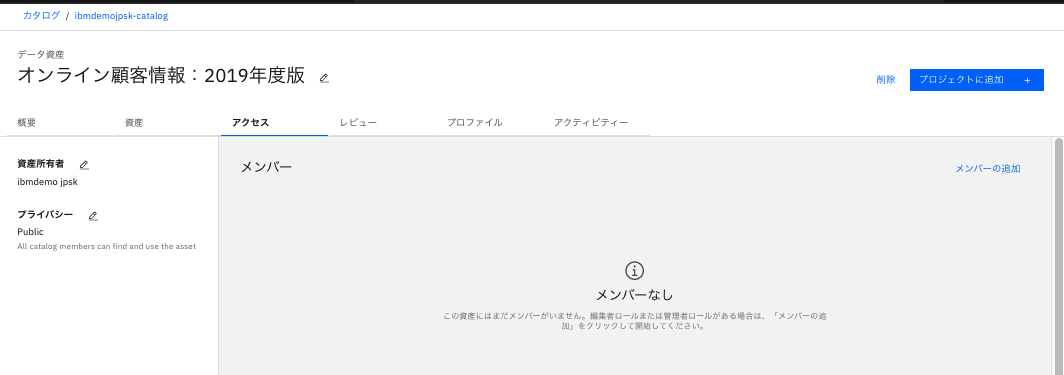
3.3.アクセス タブ
- このデータ個別にユーザをし招待したい場合は、ここから「メンバーの追加」をクリックして追加できます。
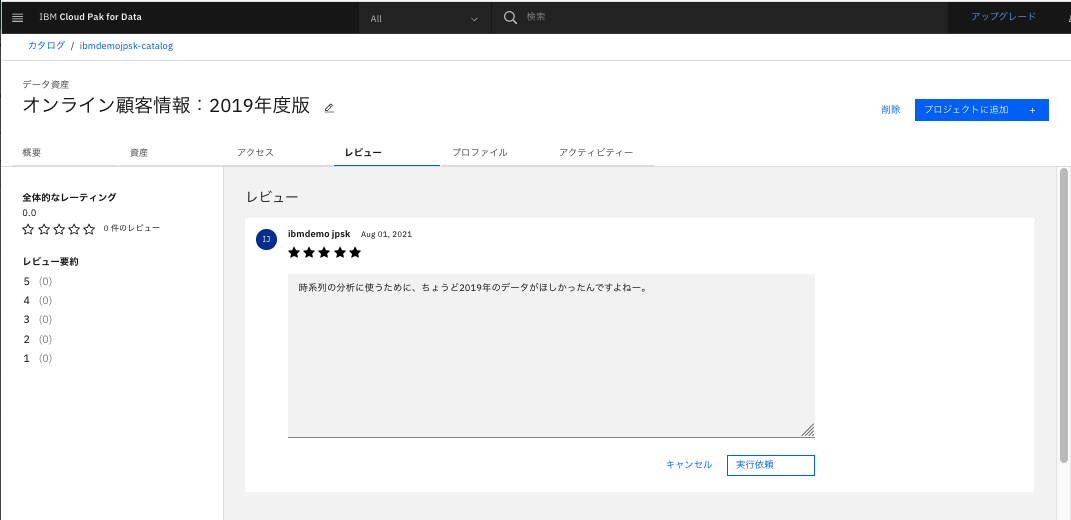
3.4.レビュー タブ
データのレーティングや感想等を記載できます。
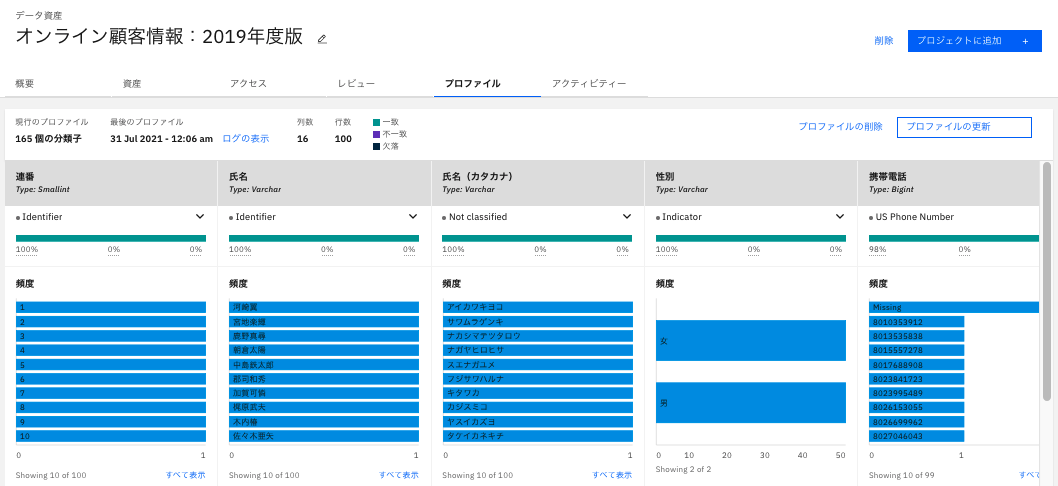
3.5.プロファイル タブ
- データの全体的な傾向を把握できます。

3.6.アクティビティー タブ
カタログに追加されてからの、いわゆるデータのリネージュ(来歴)を確認できますが、ライトプランでは使用できません。
4.プロジェクトへの追加
4.1.プロジェクトに、カタログからデータ資産を追加。
-
カタログで見つかったデータを、分析用のプロジェクトに格納します。
-
なお、データが保護ルールでブロックされている場合、管理者以外はそのデータをプロジェクトに格納できません。
-
当該データ資産を表示して、画面右上の「プロジェクトに追加」をクリック。
-
「ターゲット」箇所で自分のプロジェクトを指定して、画面右下の「追加」ボタンをクリック。
- 今回は「接続されたデータ資産」が対象のため、その「接続」定義(Db2-Connection)も併せてプロジェクトへコピーされます。
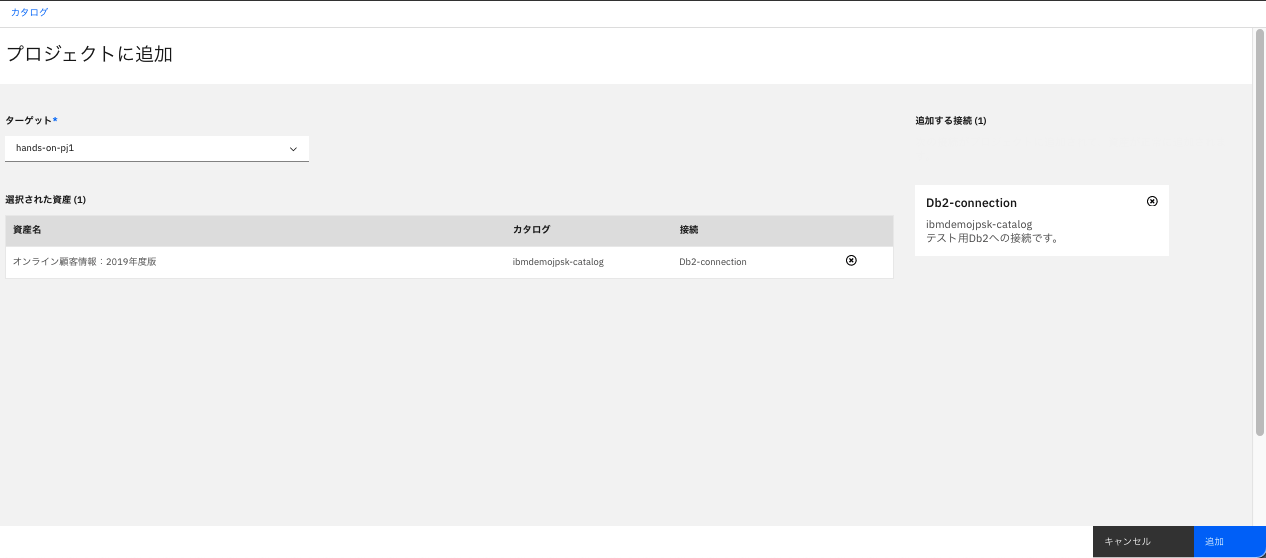
- 今回は「接続されたデータ資産」が対象のため、その「接続」定義(Db2-Connection)も併せてプロジェクトへコピーされます。
-
画面右上にプロジェクトに追加された旨の表示がでるので、「プロジェクトに移動」をクリック。
-
プロジェクトにデータが追加されたことを確認。
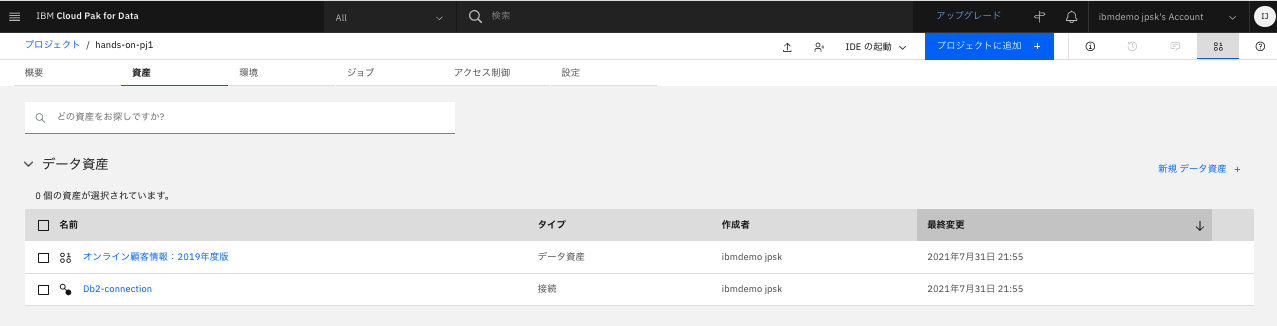
4.2.プロジェクトに、コラボレータを追加。
-
プロジェクトの「アクセス制御」タブから、画面右上の「コラボレーターの追加」をクリック。
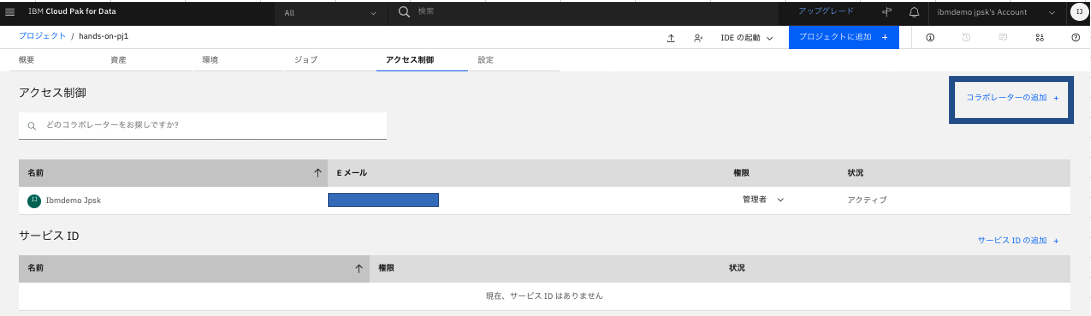
-
メールアドレスを入力して、コラボレーターを追加します。
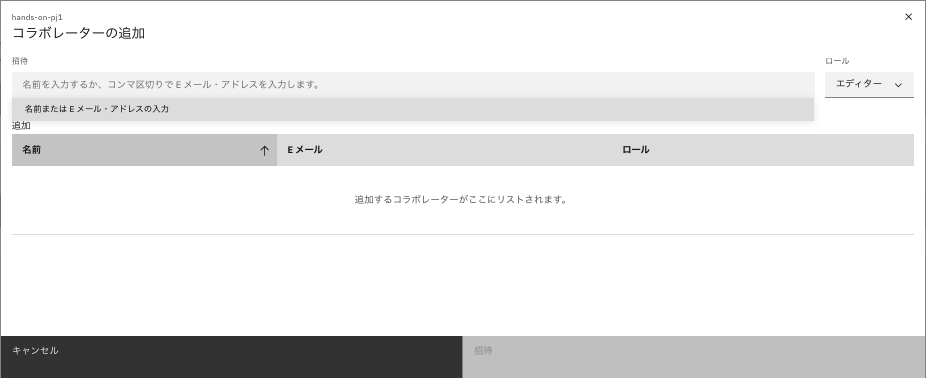
-
アドレスを途中まで入力すると候補が表示されるので選択します。
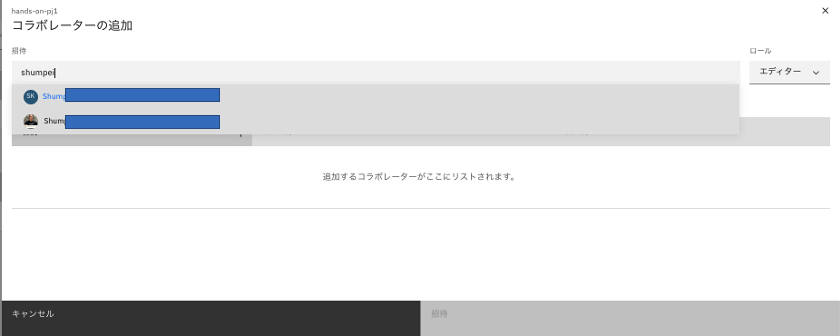
-
ロールを選択して、「招待」をクリックします。(画面の例では「エディター」としています。)
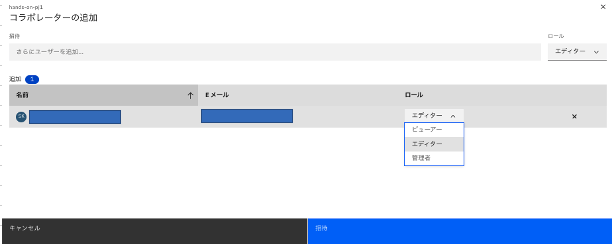
-
このプロジェクトに対して、エディターとして新規にユーザーが追加されました。
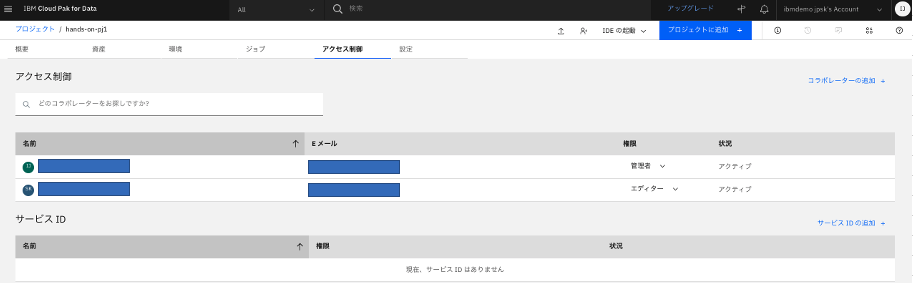
-
以下は、プロジェクトに招待されたユーザの画面
-
プロジェクトの一覧で、自分が招待されたプロジェクトが表示されており、先程設定したロールになっていることがわかります。
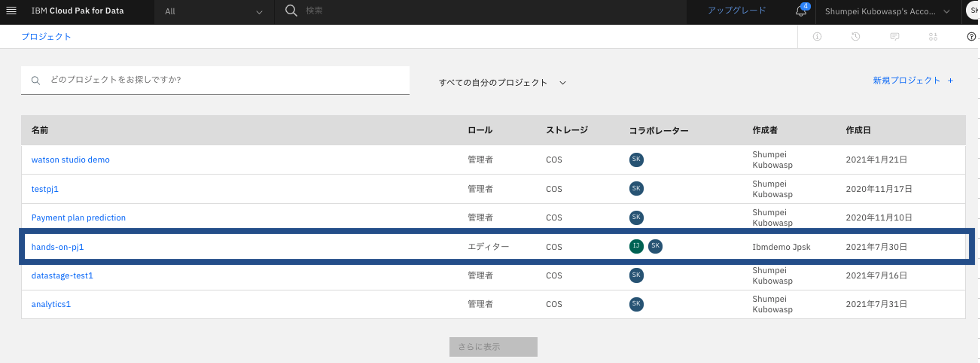
5.データの整形(Data Refinery)
- プロジェクト内に保存されたデータを、使いやすいように整形・精製(Refine)、また可視化も出来るジョブを作成・実行します。
- 公式ドキュメントとしては、こちらを参考にしてください。
5.1.Data Refinery の起動
-
プロジェクトで、右端の点3つのボタンをクリックして、「整形」をクリックします。
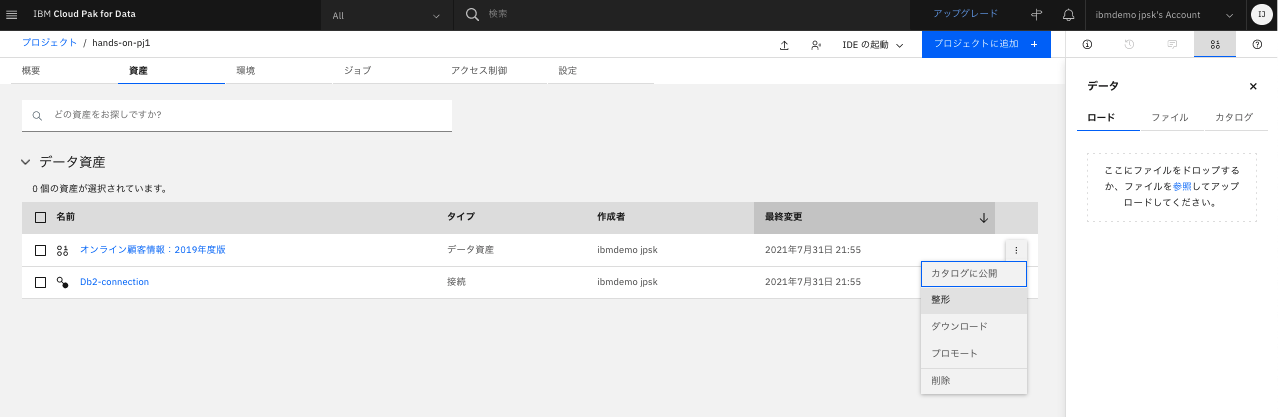
-
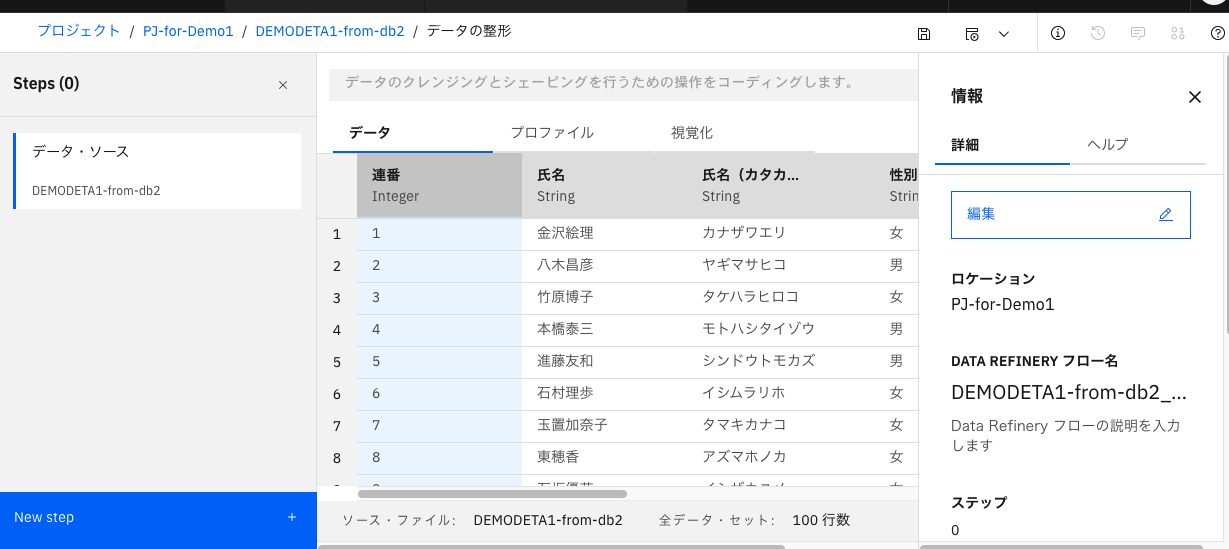
データの整形画面が起動します。画面右上に表示が出ますが、プレビューの処理に少し時間がかかる場合があります。
-
画面の左側は、修正対象のデータと、それに修正を加えていく処理のステップが記載される場所です。
- (「✗」ボタンで消せますし、画面に再度出す場合は画面右上の「i」のアイコンをクリックすると現れます)
-
画面真ん中は対象データのプレビュー、プロファイル、視覚化(グラフ)が確認できます。
-
画面の右側は、対象のデータソース等の情報が記載されます。
- (「✗」ボタンで消せますし、画面に再度出す場合は画面左上の「Steps」という箇所をクリックすると現れます)
5.1.1.データプロファイル
- 画面右上の「処理中」表示が消えたら、画面真ん中に表示されている「データ」タブの横の「プロファイル」タブをクリックします。
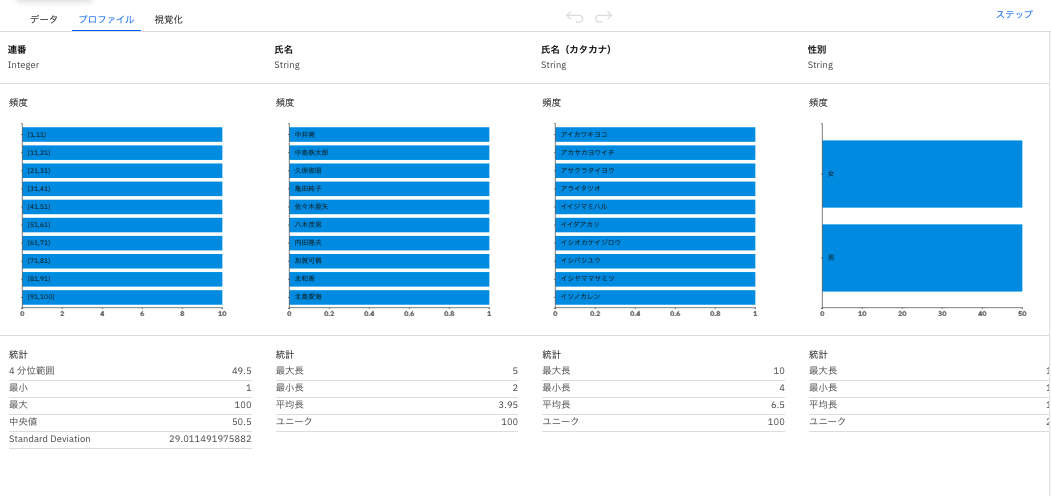
5.1.2.データ視覚化
-
その横の「視覚化」タブをクリックします。
-
いくつかのグラフ候補が現れます。全部で33種類のグラフが準備されています。
-
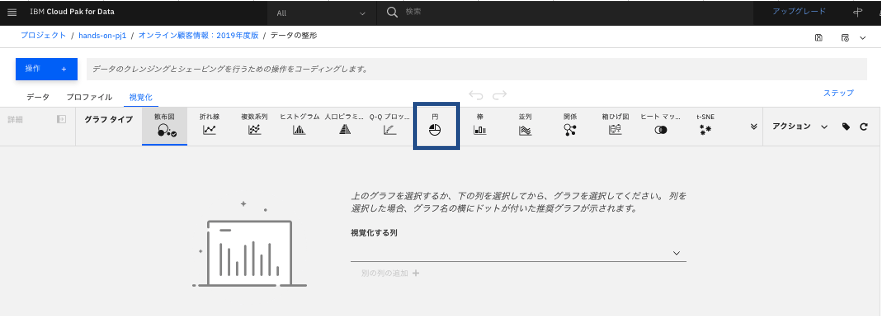
ここでは例えば円グラフを選択します。
-
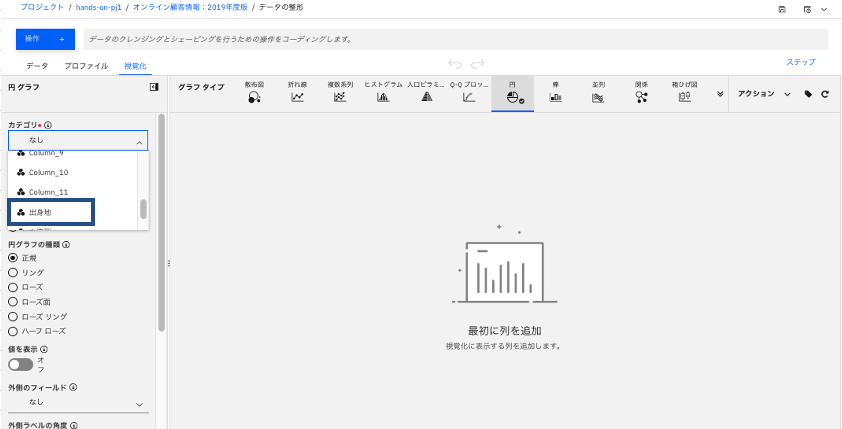
画面左側の「カテゴリ」から選択したい列を選びます。ここでは例えば「出身地」を選択します。
-
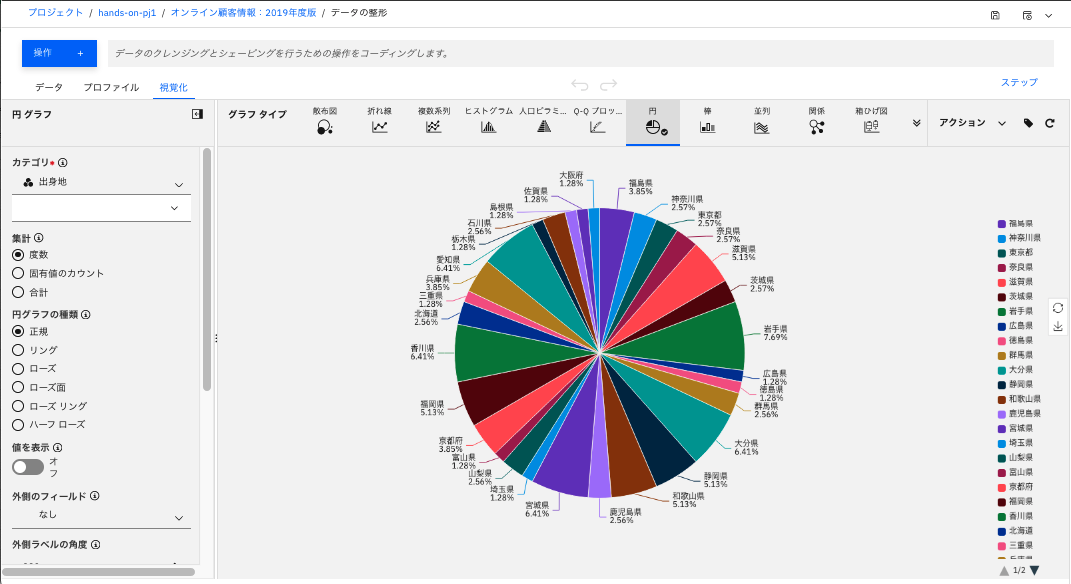
出身地別の円グラフが表示されます。
-
出身地の下のドロップダウンリストから、表示したい値だけを選択することもできます。
-
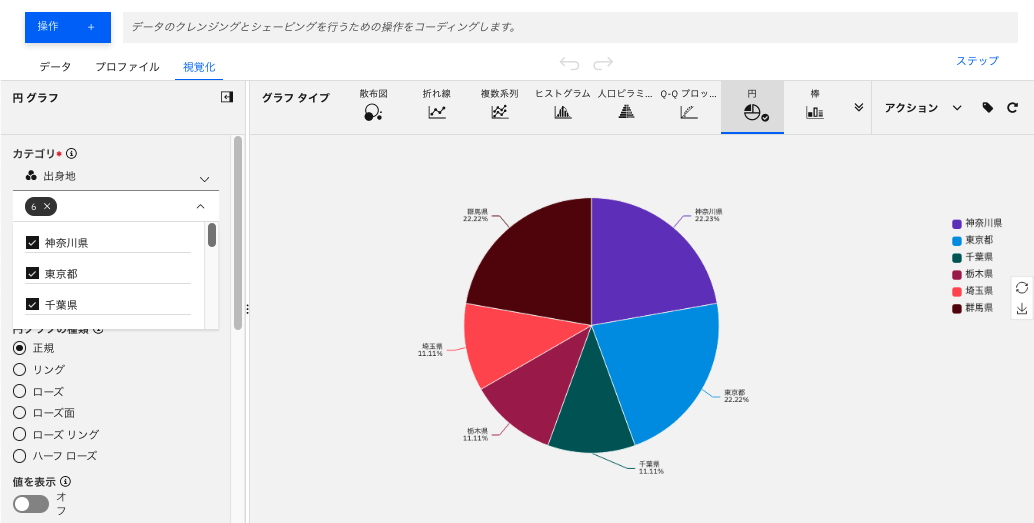
円グラフの種類を選べます。最初のものは「正規」の円グラフですが、以下のような「リング」や
-
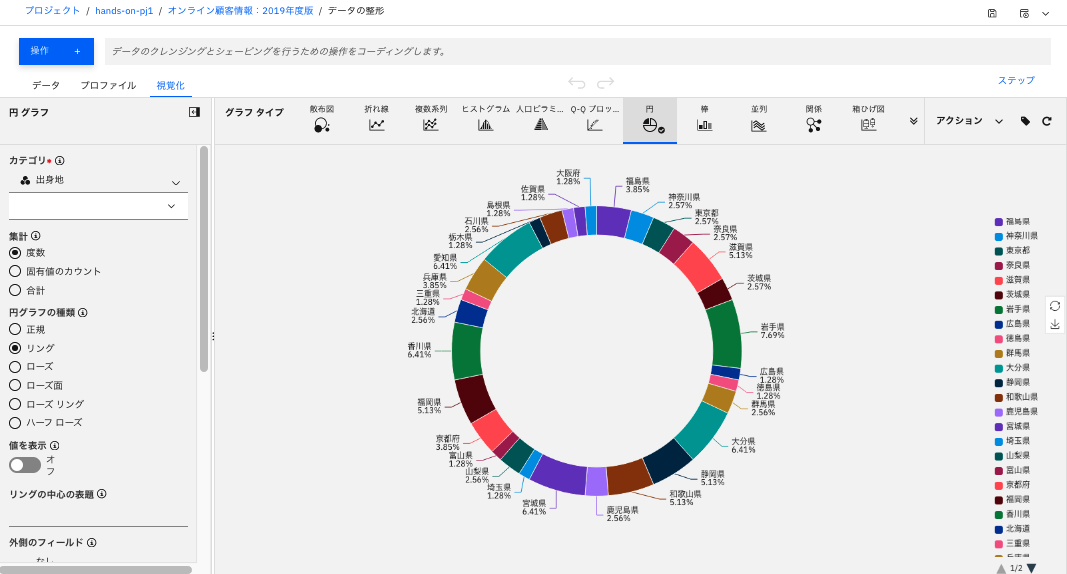
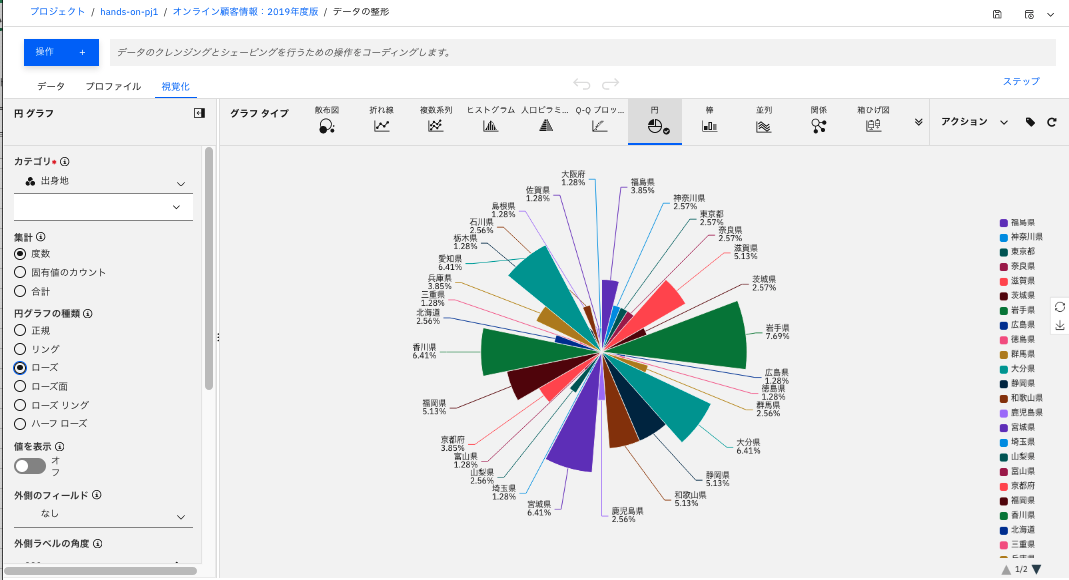
以下のような「ローズ」等、複数の表示方法を選択できます。
-
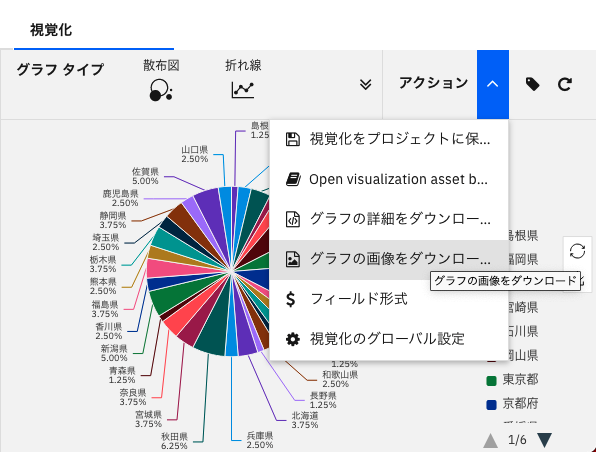
画面右上の「アクション」の箇所から、グラフをプロジェクト(visualization asset browser)に保存したり、グラフの詳細(JSON形式)や画像(PNG形式)をダウンロードすることも可能です。
5.1.3.データ整形の操作
-
「データ」タブに戻り、画面右上の「処理中」表示が消えたら、画面左下の「New Step」ボタンを押します。
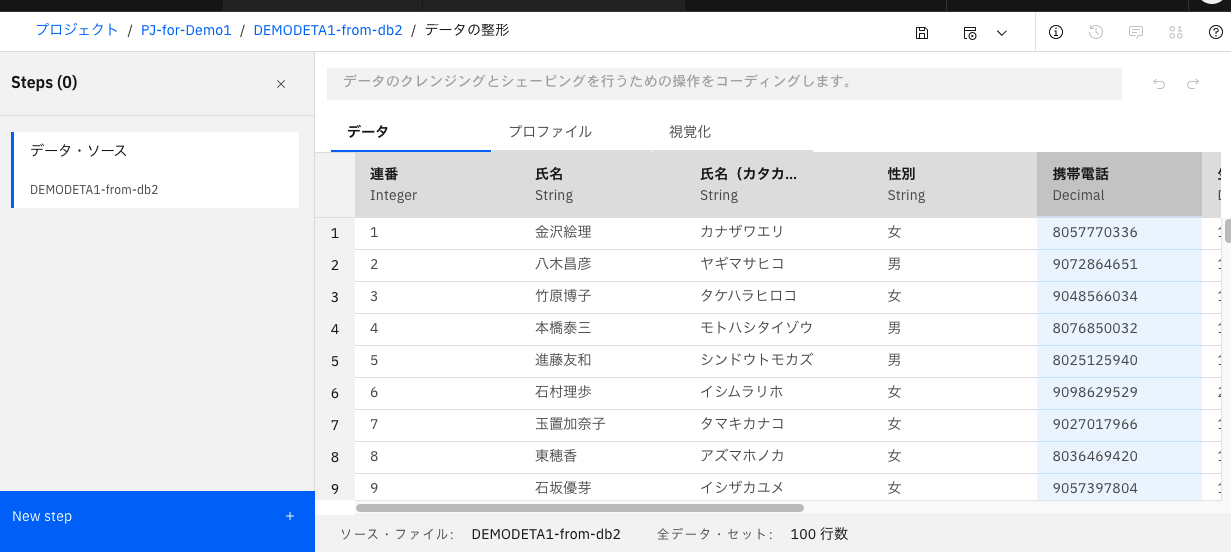
-
操作可能なコマンドの一覧が表示されます。
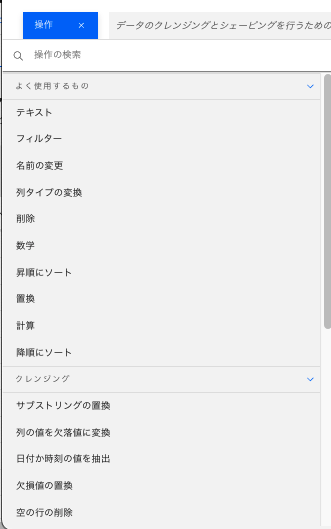
-
今回は、簡単にフィルタリングをしてみます。「フィルター」をクリックします。
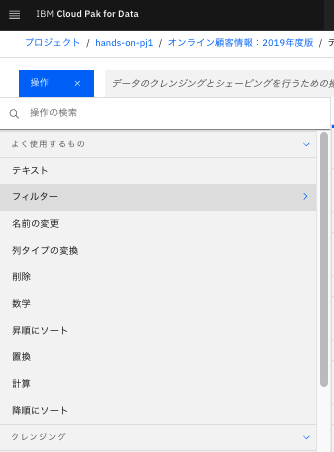
-
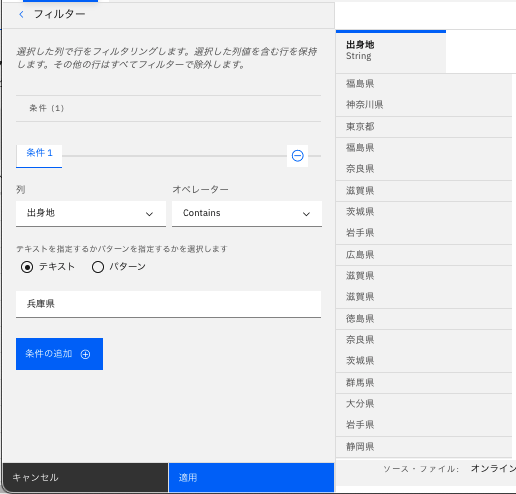
フィルターしたい列を選択肢、その条件を選びます。
-
この例では、「出身者」列に「兵庫県」が含まれている列を選択します。
-
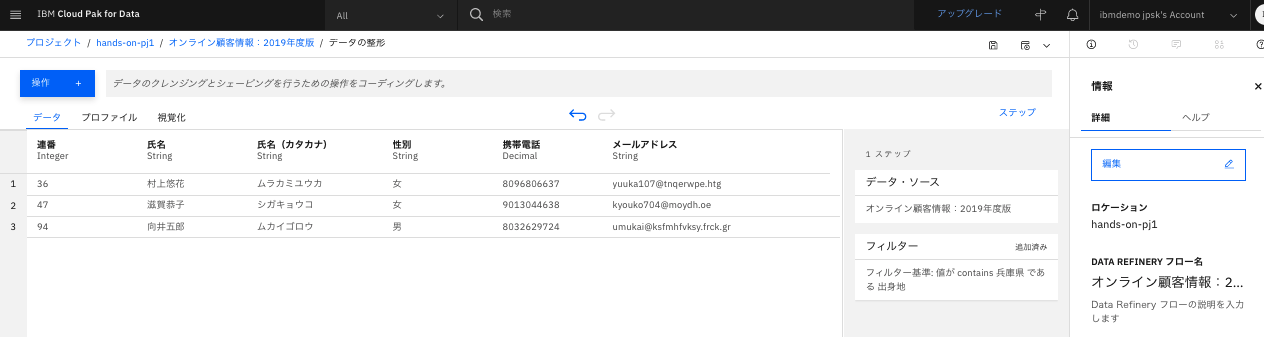
「適用」をクリックします。
-
結果のプレビューが見られました。
5.1.3.1.データ出力先を、プロジェクト内のcsvファイル(デフォルト設定)にする場合(今回実施します。)
- 今回のハンズオンではこちらの例で進みます。
- 5.1.3.3.の箇所まで読み飛ばしてください。
5.1.3.2.データ出力先を、他のデータベース等に設定する場合(今回は実施しません。)
-
今回のハンズオンでは以下の操作は行いません。参考として、様々なDBへ出力も出来るのだな、という点を抑えていただければ結構です。
-
画面右側の「編集」ボタンをクリック。
-
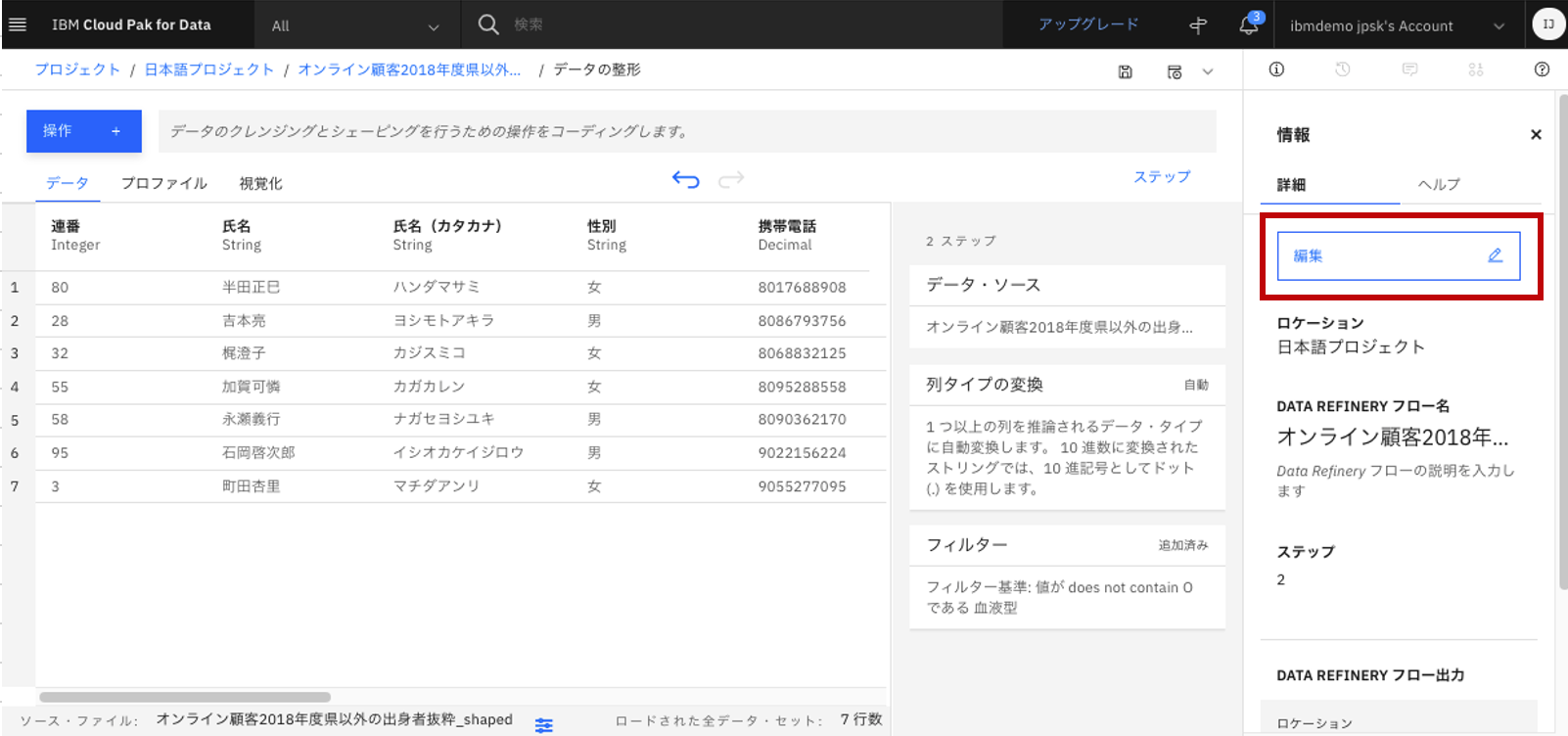
-
「出力の編集」をクリック。
-
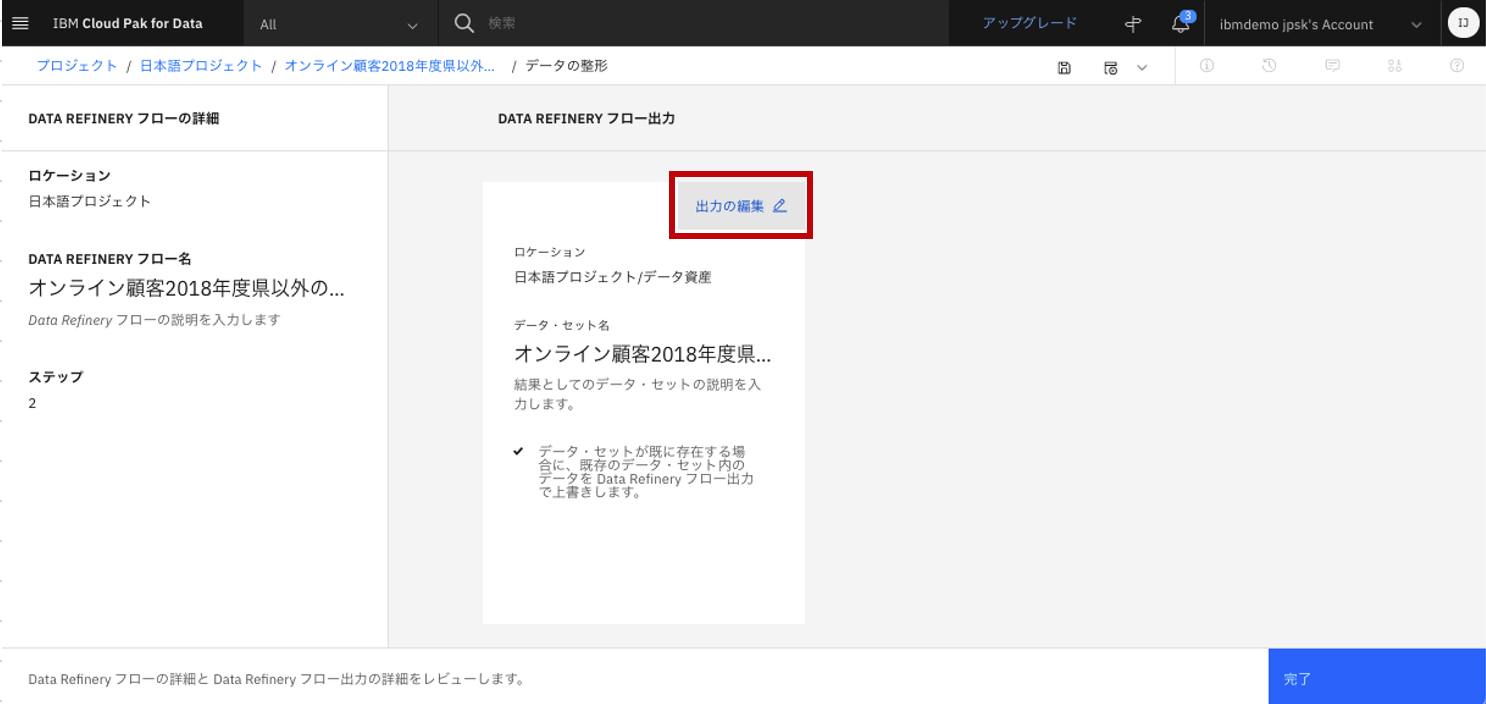
-
「ロケーション」箇所の右側のペンのマークをクリック。
-
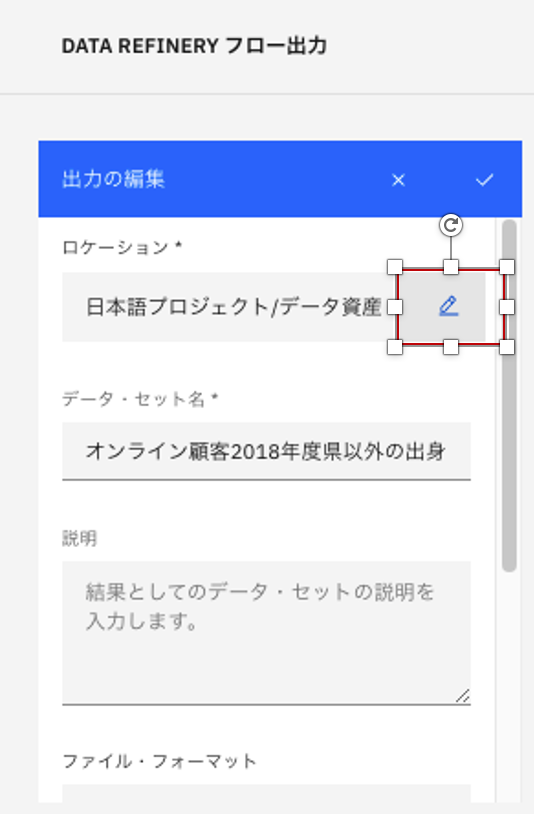
-
出力したいデータベースのテーブルを選択して、「ロケーションの保存」をクリック。
-
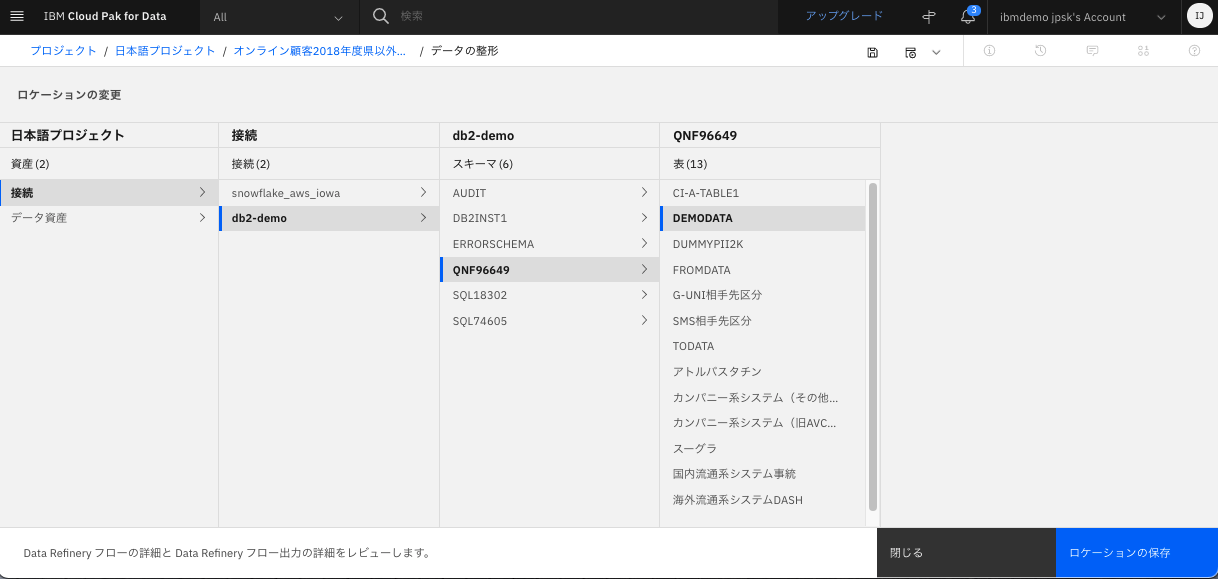
-
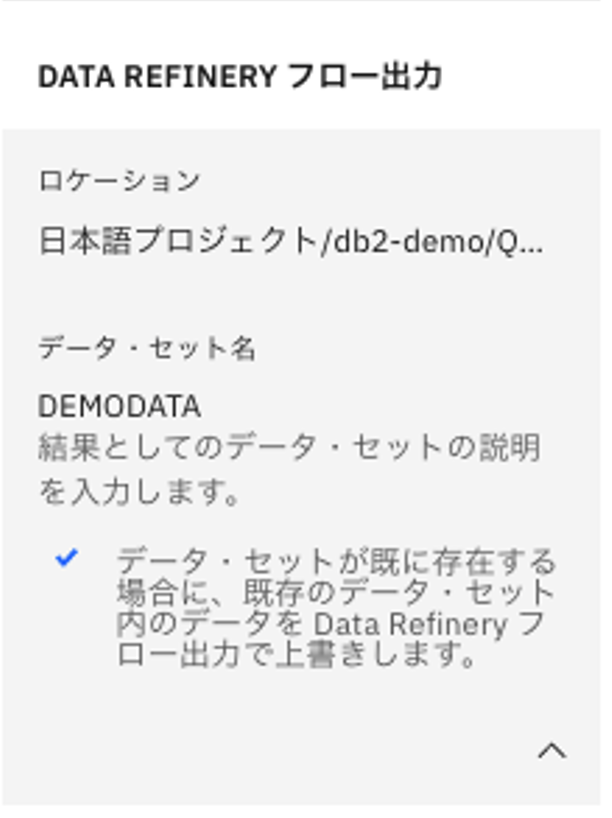
データセット名や説明を確認し、出力先への出力方法を選択。
-
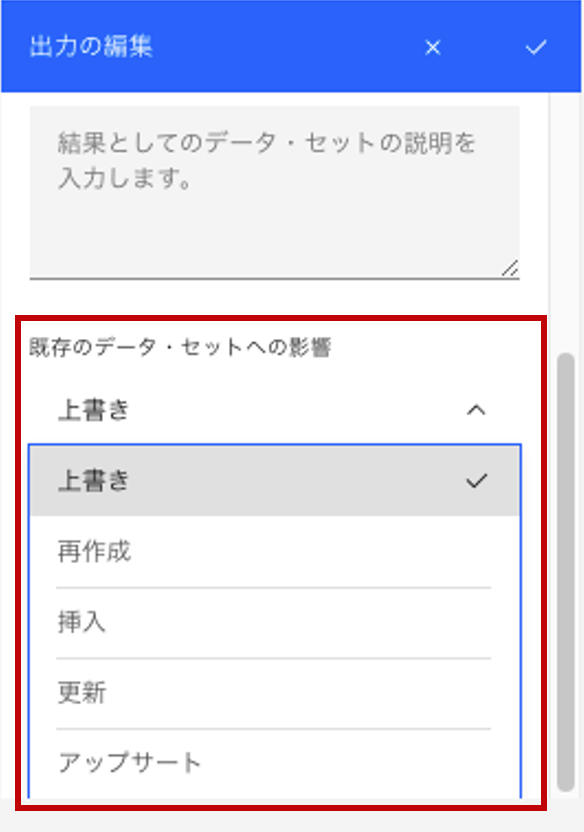
-
「出力の編集」の横のチェックマークをクリック。
-
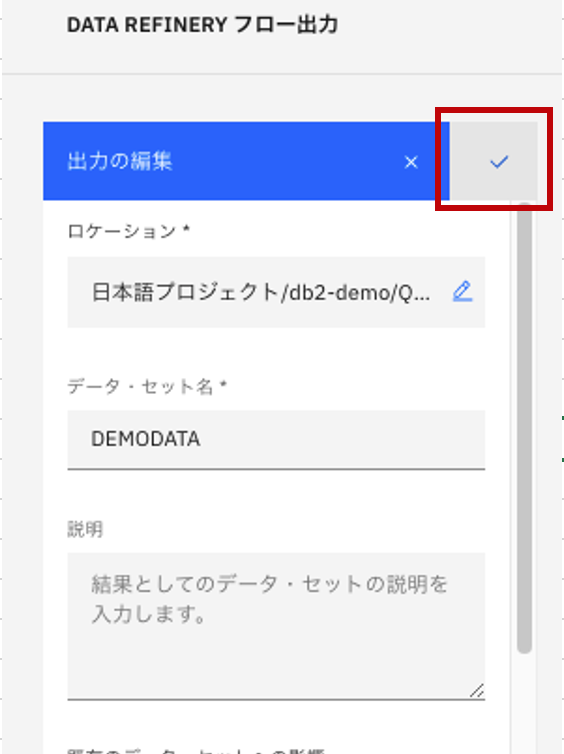
-
画面右下の「完了」をクリック。
-
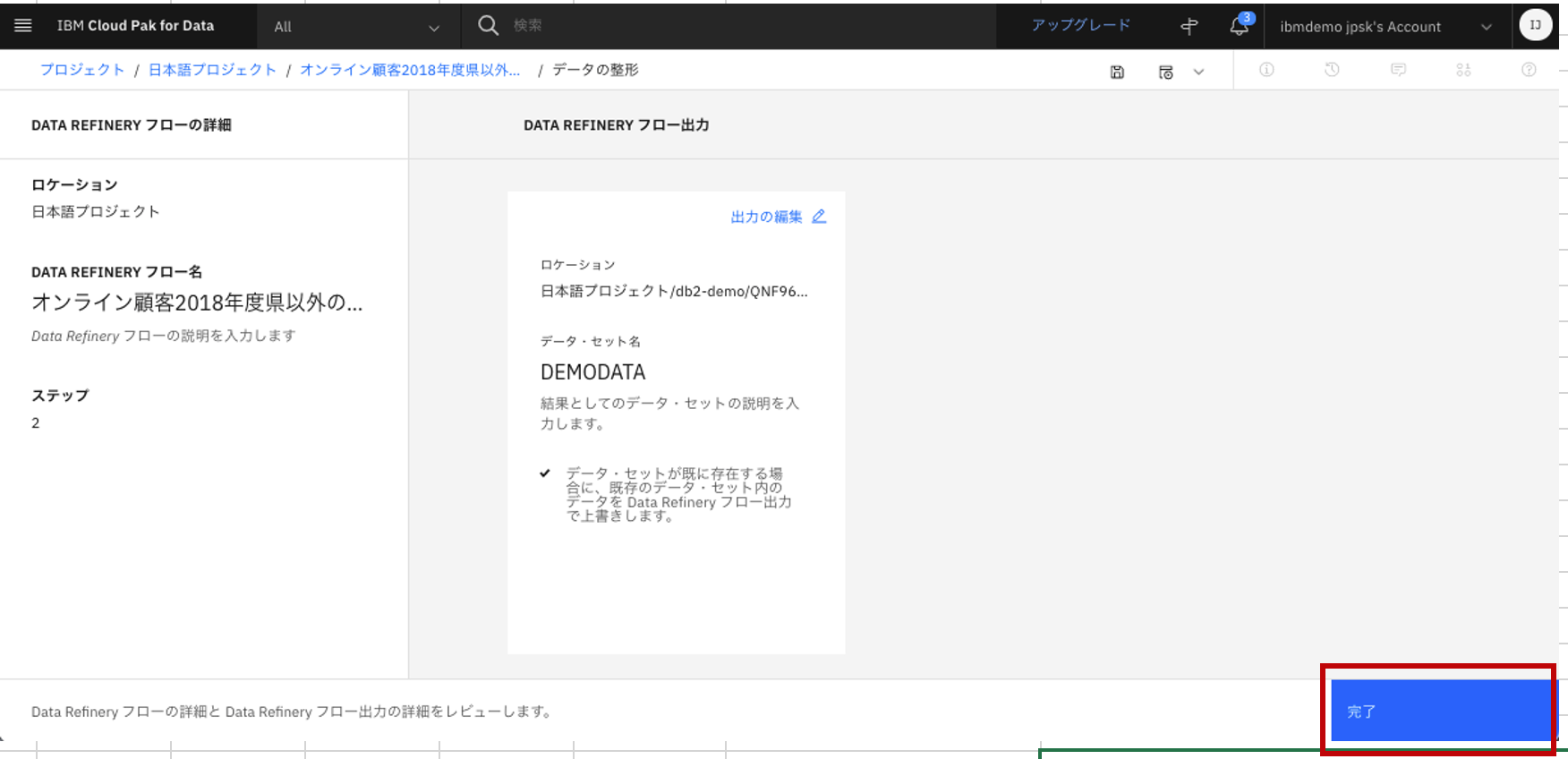
-
画面右下の「Data Refineryフロー出力」の箇所が変更されていることを確認
-
5.1.3.3.データ保存以降の処理
-
(デフォルト設定のcsv出力の場合で記載しています。)
-
このジョブ設定を保存して、結果を作成してみます。
-
画面右上の「ジョブ」ボタンから「ジョブを保存して作成」をクリックします。
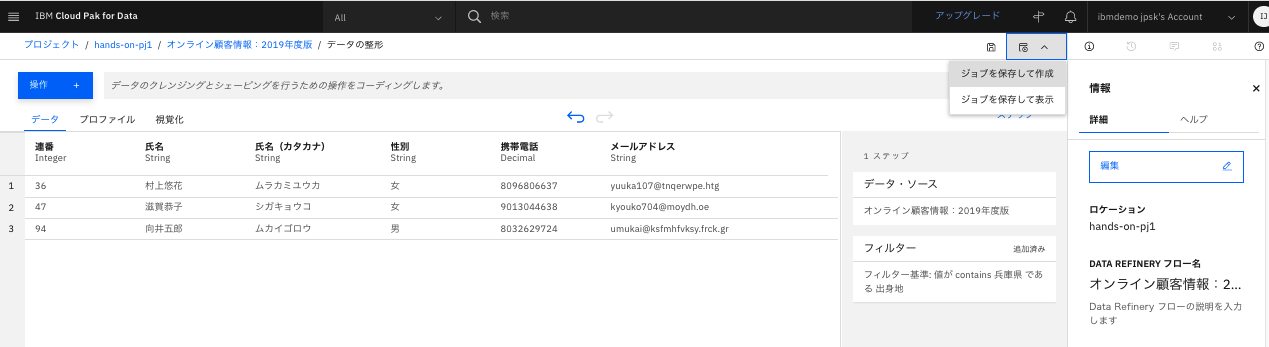
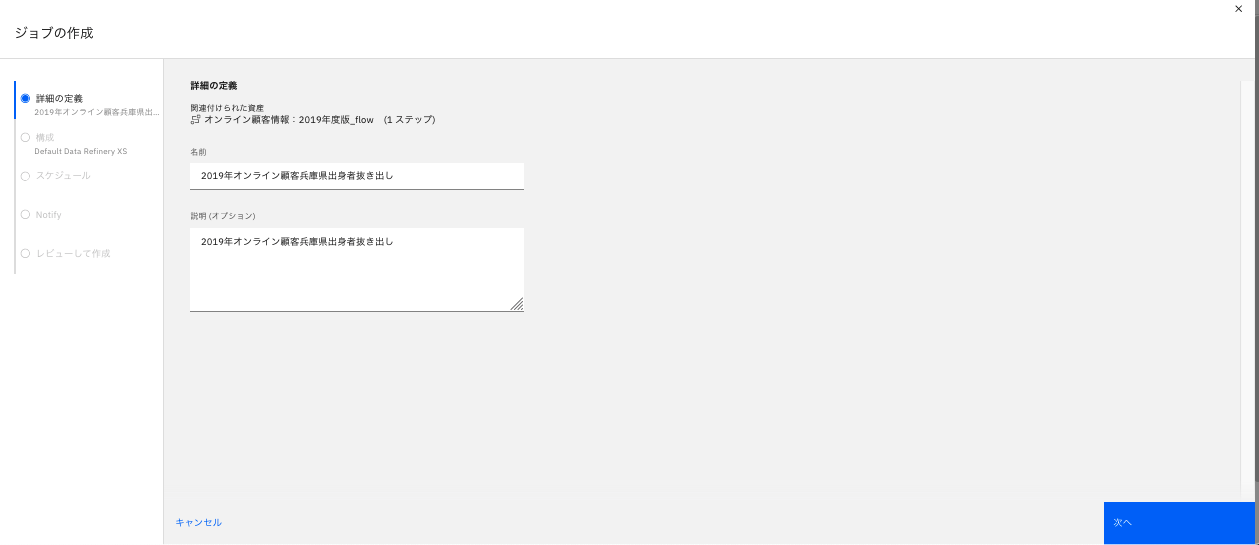
-
「名前」「説明」を入力して「次へ」をクリックします。
-
データの入力・出力を確認し、「次へ」をクリックします。
-
オプションとして、作成物の保持期間を指定しても良いです。(チェックボックス)
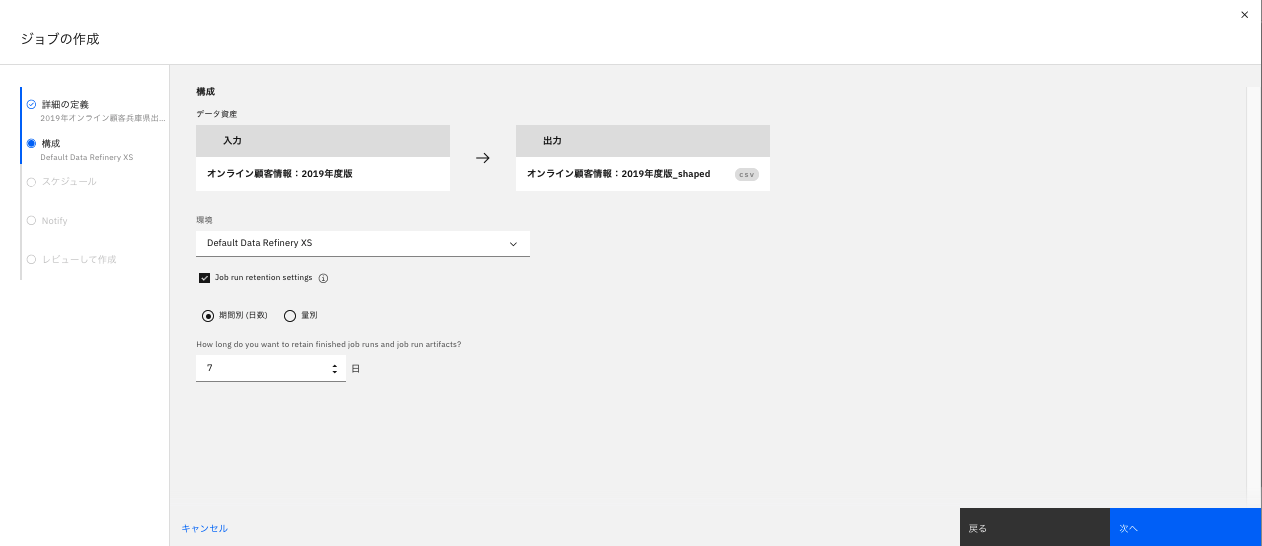
-
ジョブなので、スケジューリングが可能ですが、今回はそのまま実行するのでオフのまま「次へ」をクリックします。

-
仮にスケジューリングする場合は、以下のような設定が可能です。
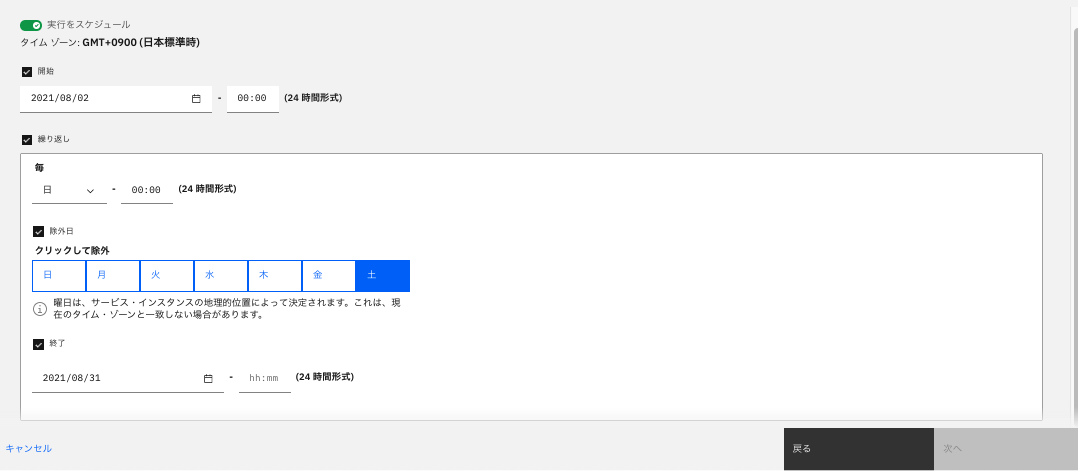
-
通知の要否です。今回はオンにしてみます。
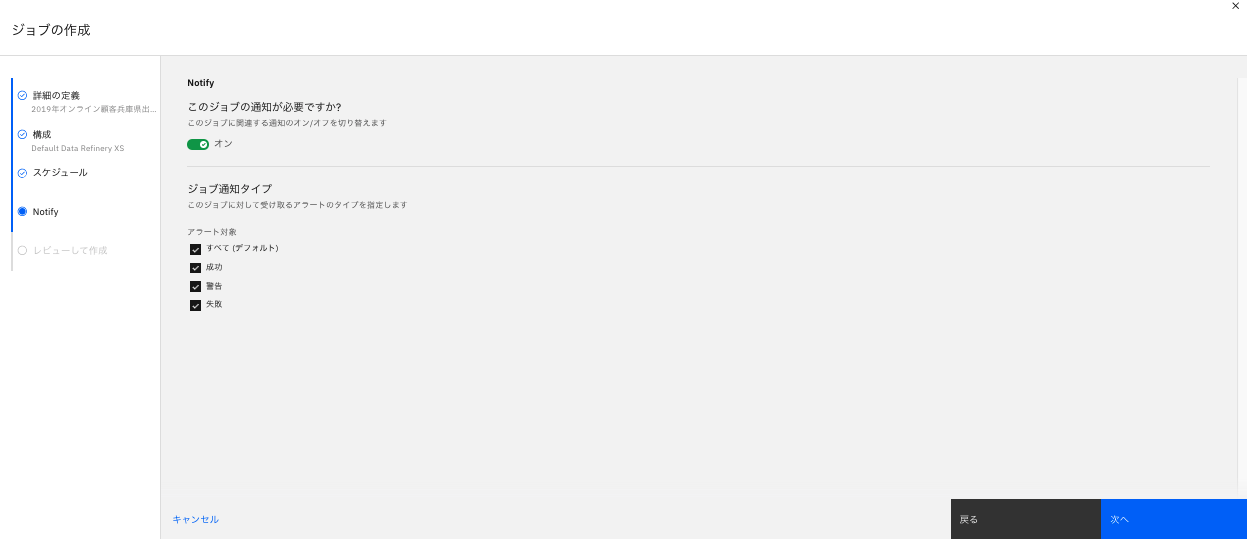
-
ジョブ内容を確認します。今回はそのまま実行するので、「作成して実行」をクリックします。
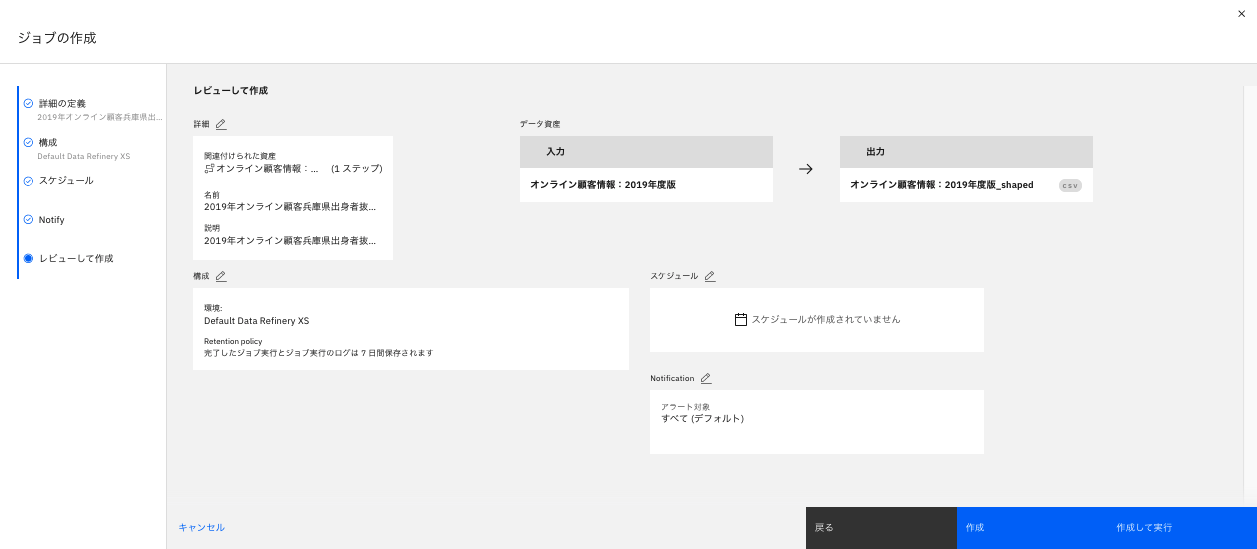
-
ジョブが開始された通知が表示されます。
-
プロジェクトに戻ります。画面左上のプロジェクト名をクリックします。
-
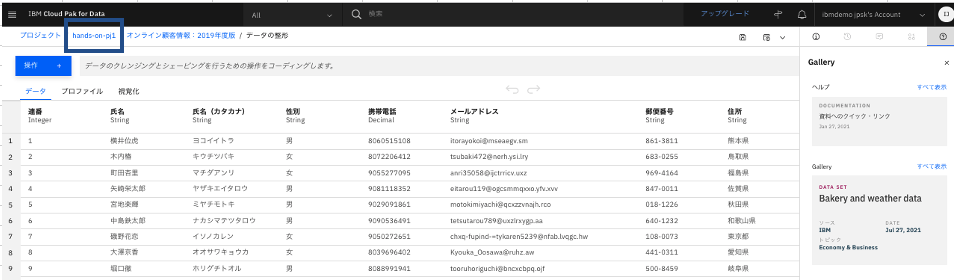
データ資産一覧に戻りました。
-
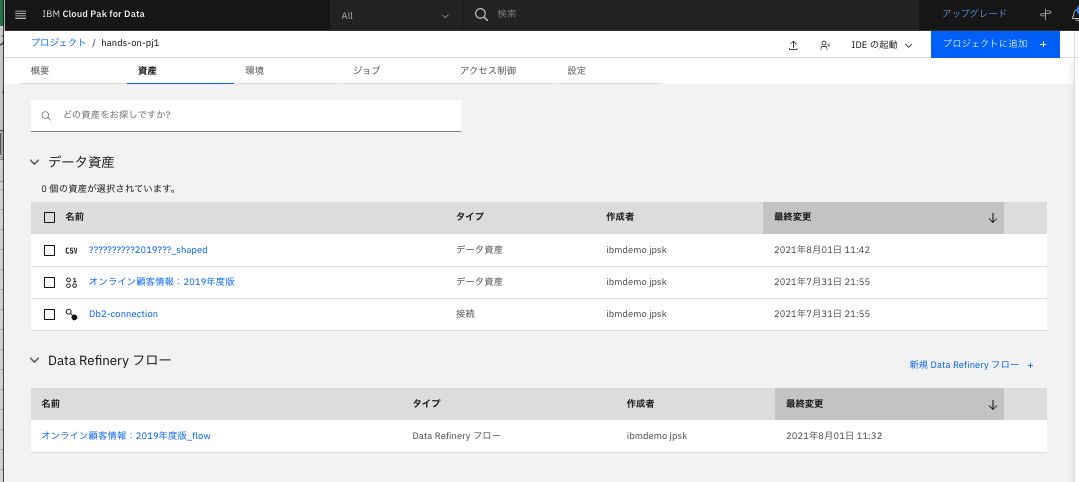
先程作成したRefineryフローと、そのフローにより作成された新規データファイル(csv)が保存されていることがわかります。(一部日本語名称が文字化けしていますが。。。)
-
「ジョブ」タブを確認します。Refineryで実行したジョブの履歴が記載されています。
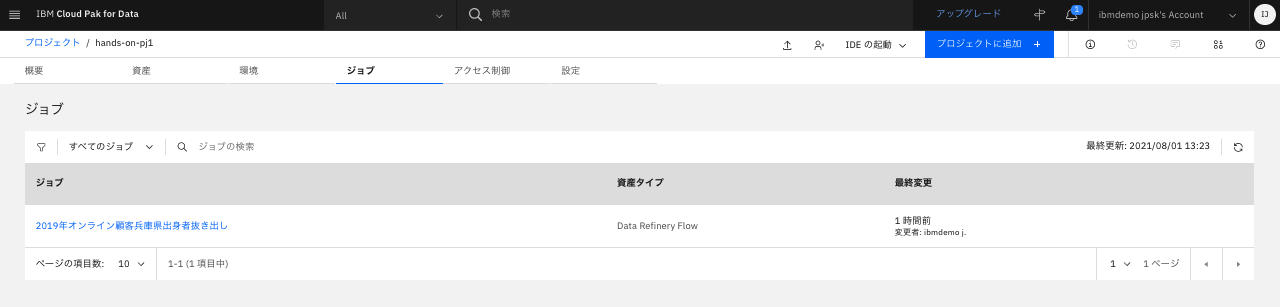
-
ジョブ名をクリックすると、その詳細内容が確認できます。
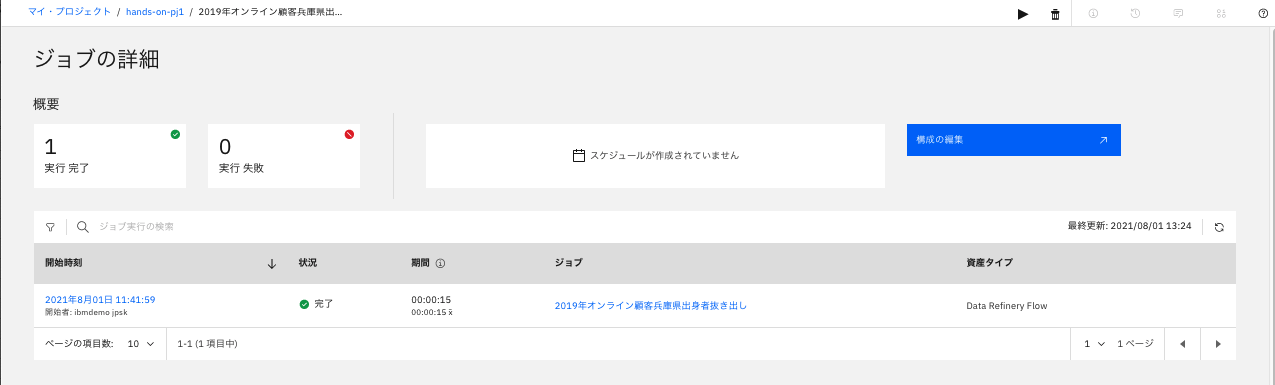
-
「開始時刻」のリンクをクリックすると、ジョブのログが確認できます。
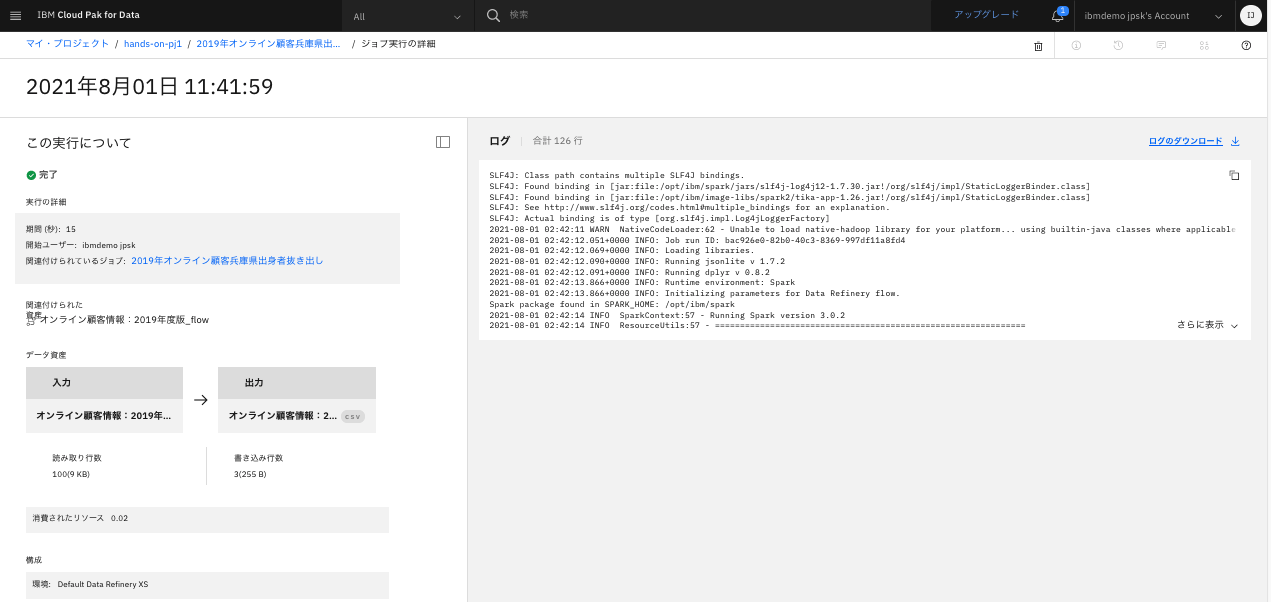
-
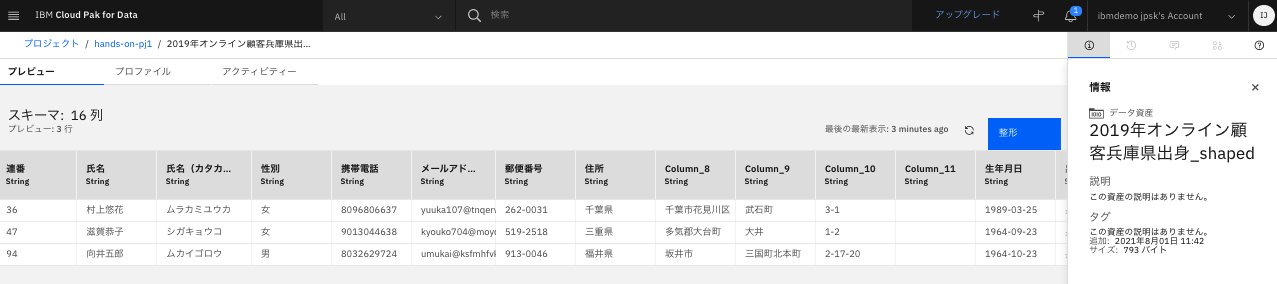
プロジェクトの「資産」タブに戻って、整形したデータ(ファイル名の末尾が_shapedのもの)を確認します。
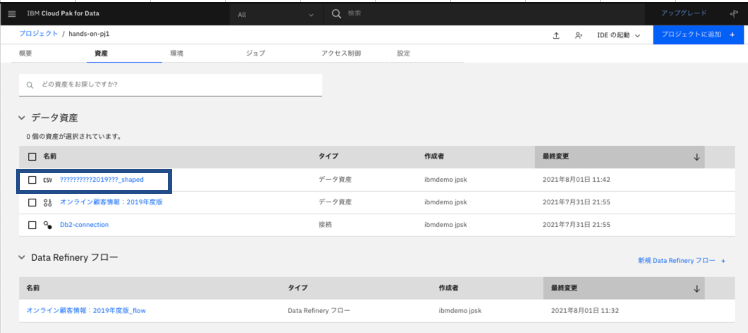
5.1.4.ファイルの修正
-
整形したデータが確認できました。ファイル名が文字化けしているので、修正します。画面右上の「i」のボタンをクリックします。
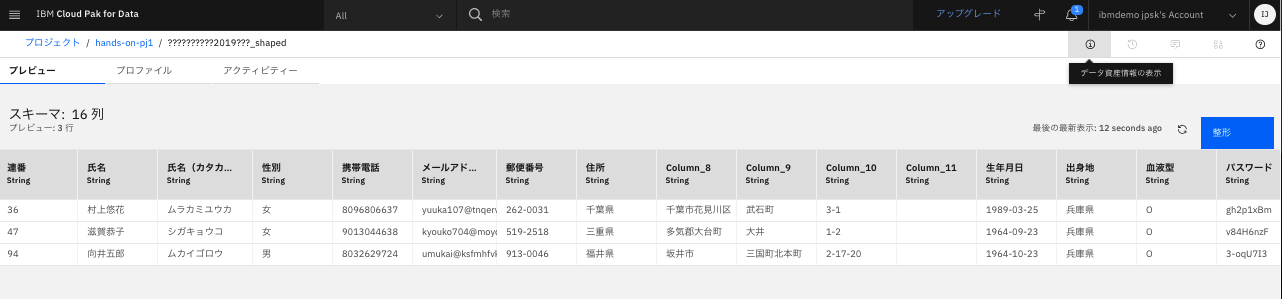
-
ファイル名右のペンのアイコンをクリックして名称を編集します。
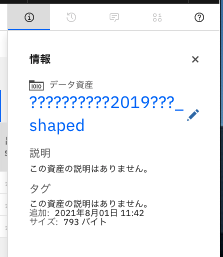
-ファイル名を修正して「適用」をクリックします。
-
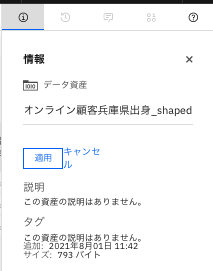
-
ファイル名が修正されました。
その他、分析用のハンズオン
-
こちらのリンク先に記載されている、「データ利用者向け」の以下手順も参考になさってください。
-
IBM Cloud Pak for Data as a Service ハンズオン資料 3.分析編-A:ダッシュボードで新型コロナの新規陽性者変遷を見る
-
[IBM Cloud Pak for Data as a Serviceを始めてみる(7.ダッシュボードの作成)]
(https://qiita.com/Asuka_Saito/items/79a3b9cd7f65b45d04a3) -
IBM Cloud Pak for Data as a Serviceを始めてみる(14.GoSalesのデータを使う)
-
IBM Cloud Pak for Data as a Serviceを始めてみる(15.コールセンターのデータセットを使う)
-
IBM Cloud Pak for Data as a Serviceを始めてみる(16.Modelerフローのサンプルを使ってみる - 薬剤研究例 )
-
IBM Cloud Pak for Data as a Serviceを始めてみる(19.Modelerフローで不良品件数予測モデルを開発する )
-
WiDS Tokyo@IBM 2021開催記念?: AutoAIの時系列予測で今後30日の東京の新型コロナ感染数予測をしてみる
次のハンズオン
- 4.利用(ETL)編は、こちらです。