IBM Cloud Pak for Data の XaaS 版 as a Service の始め方をまとめました。
この記事は主に、データ利用者側の操作を説明しています。
IBM Cloud Pak for Data as a Serviceを始めてみる(5.モデルの自動作成)
目次
- はじめに
- AutoAI を使って不良品予測のモデルを自動で作成する
シリーズ目次
-管理者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(1.プロビジョニング編)
-全員
IBM Cloud Pak for Data as a Serviceを始めてみる(2.ログイン編)
-データ利用者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(3.分析環境編)
IBM Cloud Pak for Data as a Serviceを始めてみる(4.データの前処理編)
IBM Cloud Pak for Data as a Serviceを始めてみる(5.モデルの自動作成)
IBM Cloud Pak for Data as a Serviceを始めてみる(6.モデルのデプロイと呼び出し)
[IBM Cloud Pak for Data as a Serviceを始めてみる(7.ダッシュボードの作成)]
(https://qiita.com/Asuka_Saito/items/79a3b9cd7f65b45d04a3)
-データ提供者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(8.カタログの作成)
IBM Cloud Pak for Data as a Serviceを始めてみる(9.ビジネス用語の作成)
IBM Cloud Pak for Data as a Serviceを始めてみる(10.メタデータのインポート)
IBM Cloud Pak for Data as a Serviceを始めてみる(11.ビジネス用語の割り当て)
-データ利用者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(12.カタログ検索してデータを見つける)
-管理者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(13.Db2のサービスを追加する)
-その他参考
IBM Cloud Pak for Data as a Serviceを始めてみる(14.GoSalesのデータを使う)
IBM Cloud Pak for Data as a Serviceを始めてみる(15.コールセンターのデータセットを使う)
IBM Cloud Pak for Data as a Serviceを始めてみる(16.Modelerフローのサンプルを使ってみる - 薬剤研究例 )
IBM Cloud Pak for Data as a Serviceを始めてみる(17.Db2のサービスへの接続情報を追加する)
IBM Cloud Pak for Data as a Serviceを始めてみる(18.機能改善やアイディアを投稿する)
IBM Cloud Pak for Data as a Serviceを始めてみる(19.Modelerフローで不良品件数予測モデルを開発する )
IBM Cloud Pak for Data as a Serviceを始めてみる(20.無償プランの枠を使い切った場合)
1. はじめに
この記事では、前回までに前処理で精製したcsvファイルを使って、ノンコーディングで機械学習のモデルを作成するところまでを実施したいと思います。
前回までに作成したcsvファイルはこちらにもありますので、必要に応じてご利用ください。
2. AutoAI を使って不良品予測のモデルを自動で作成する
2-1. IBM Cloud Pak for Data as a Serviceにログインし、TOPページを表示します。
すでに、IBM Cloud Pak for Data as a Serviceを始めてみる(3.分析環境編)でプロジェクトを作成している場合は、「最近使用したプロジェクト」にプロジェクト名が表示されますので、クリックします。
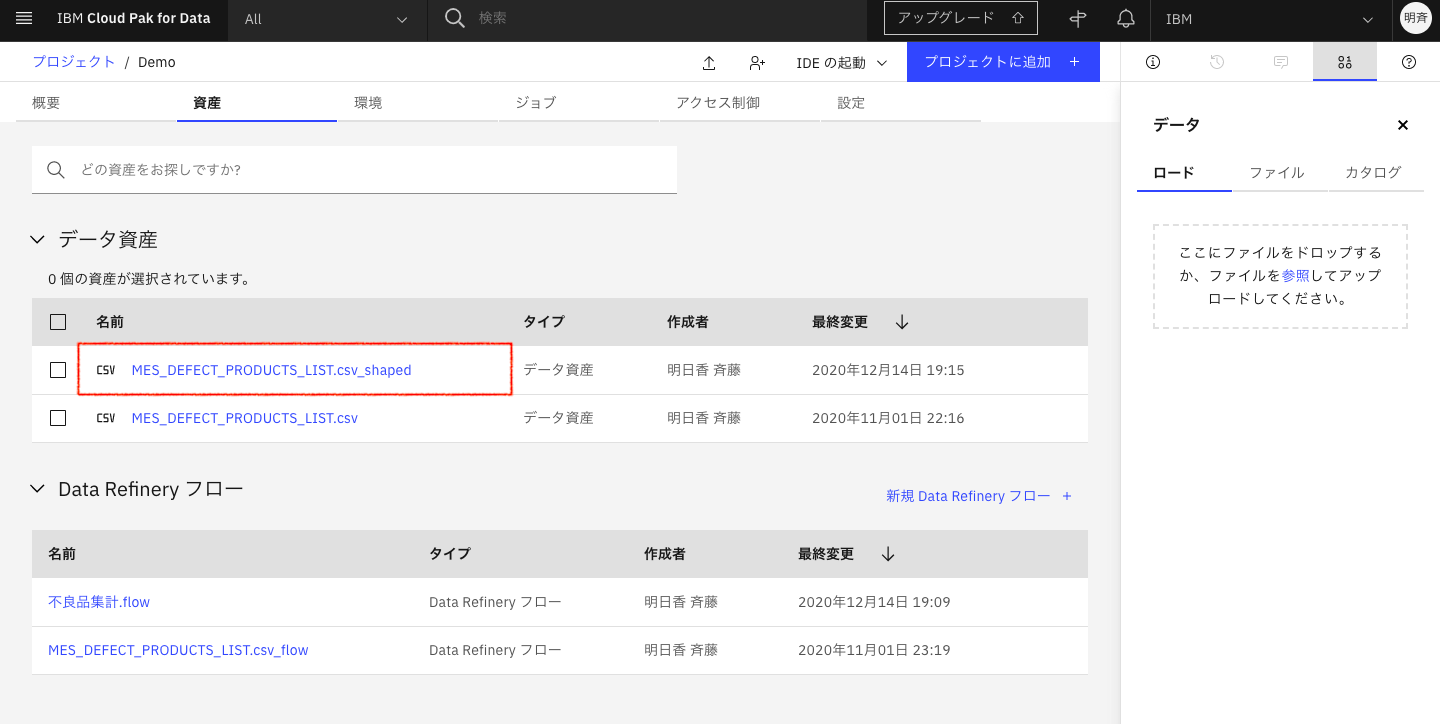
2-2. 「資産」タブを表示すると、IBM Cloud Pak for Data as a Serviceを始めてみる(4.データの前処理編)で精製したcsvファイ「MES_DEFECT_PRODUCTS_LIST.csv_shaped」が保存されています。
ない場合は、こちらにもありますので、必要に応じてダウンロード/アップロードしてご利用ください。
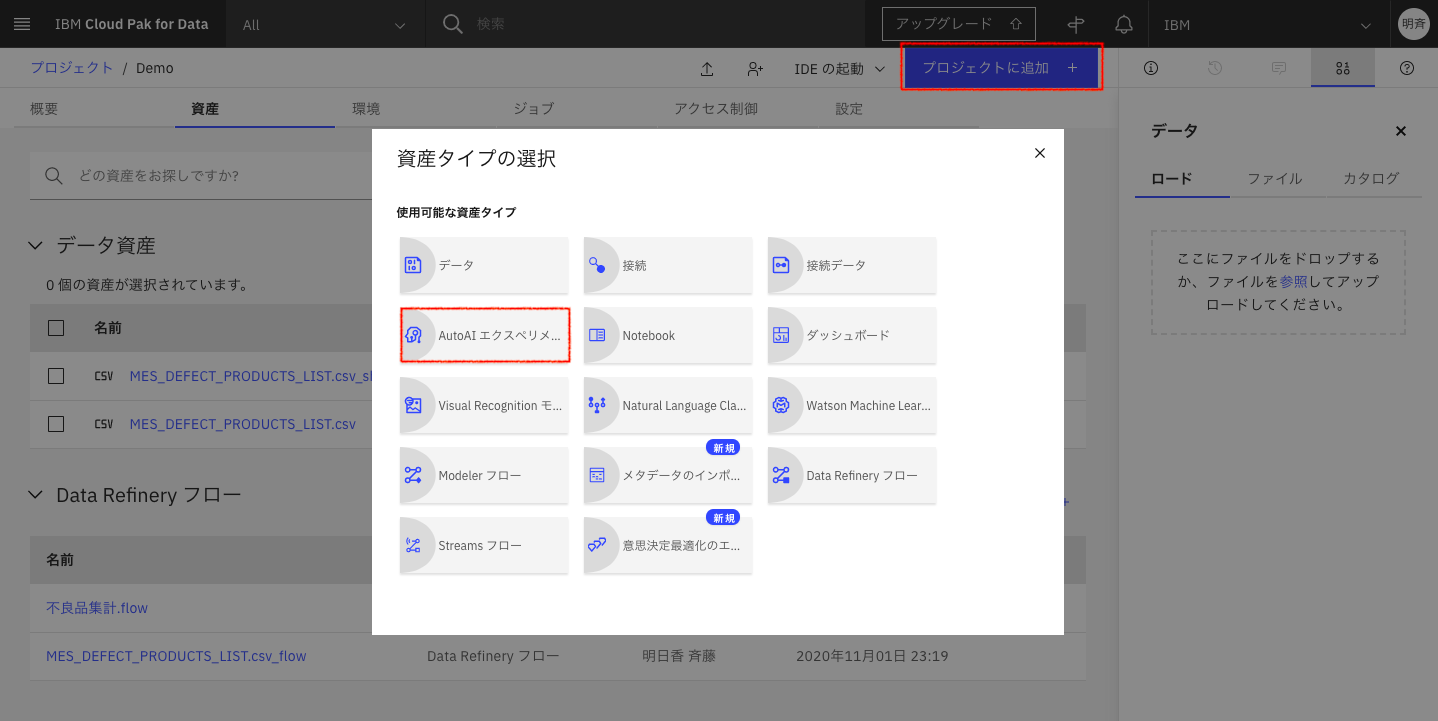
2-3. 分析プロジェクトに「AutoAI」を追加します。「プロジェクトに追加」をクリックして「AutoAIエクスペリメント」をクリックします。
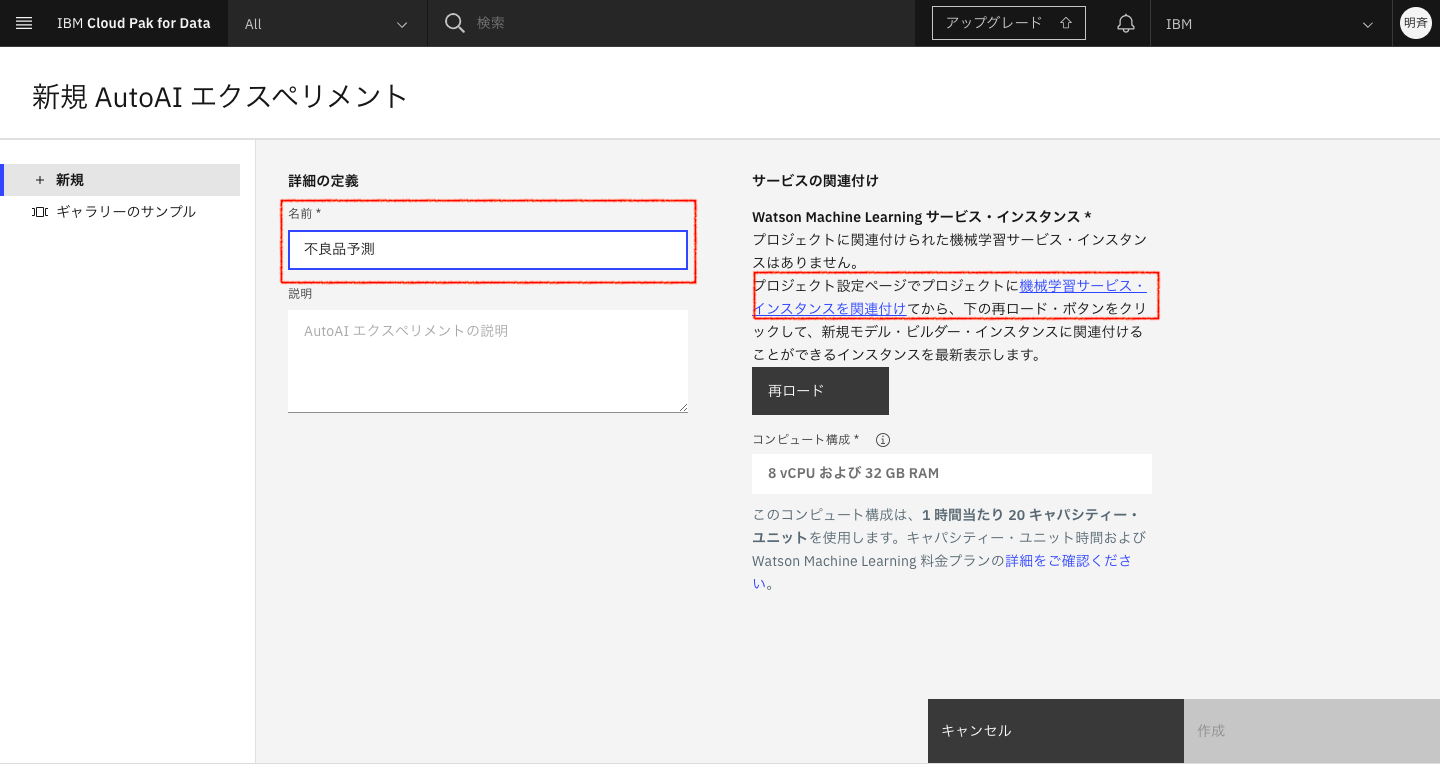
2-4. 名前を入力します。「プロジェクトに関連付けられた機械学習サービス・インスタンスはありません。」と表示された場合は、「機械学習サービス・インスタンスを関連付け」をクリックします。
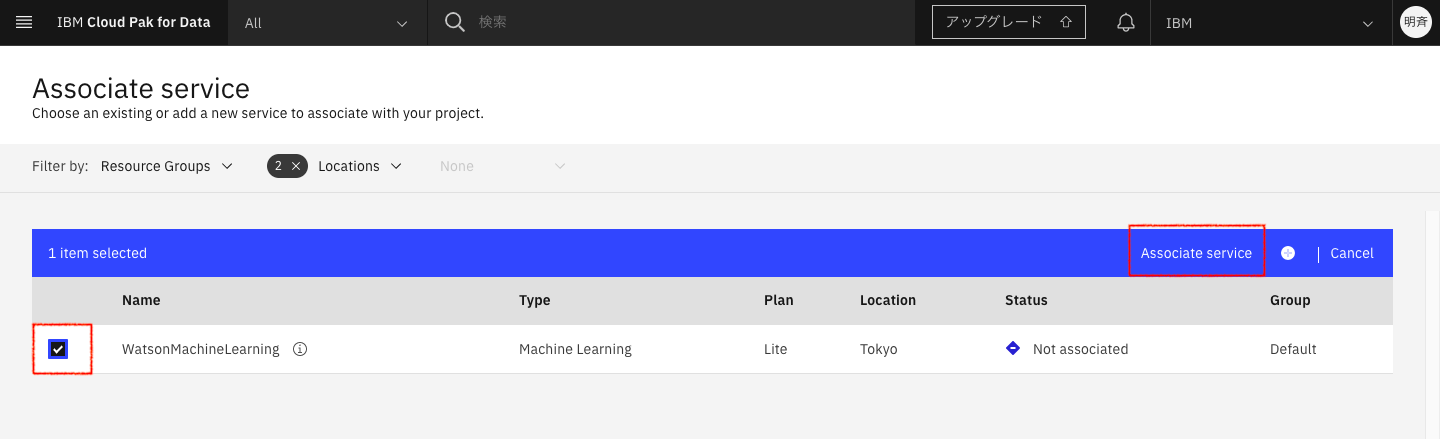
2-5. 以下の画面が表示されましたら、 Watson Machine Learningの左のチェックボックスにチェックを入れ、「Associated Services」をクリックします。
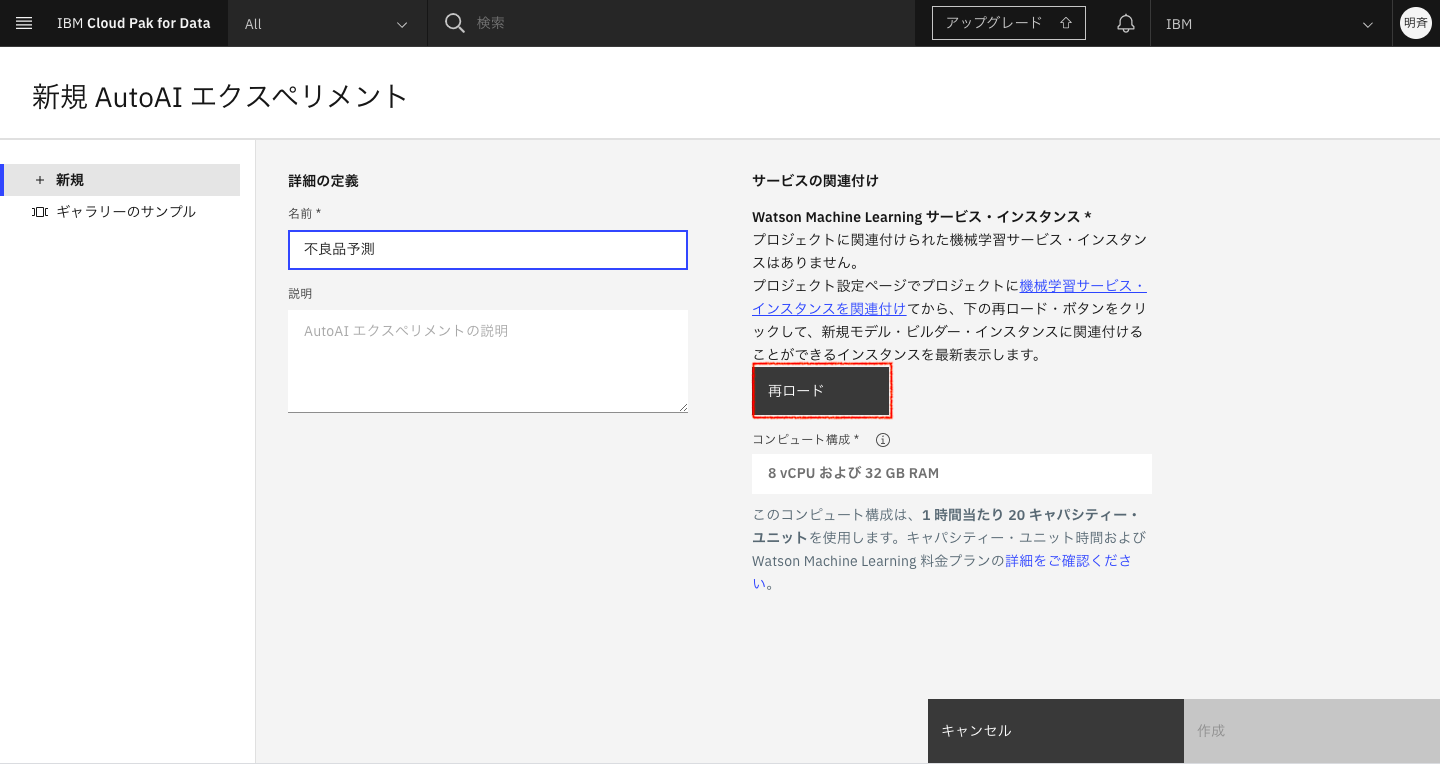
2-6. 前の画面に戻りますので「再ロード」をクリックします。
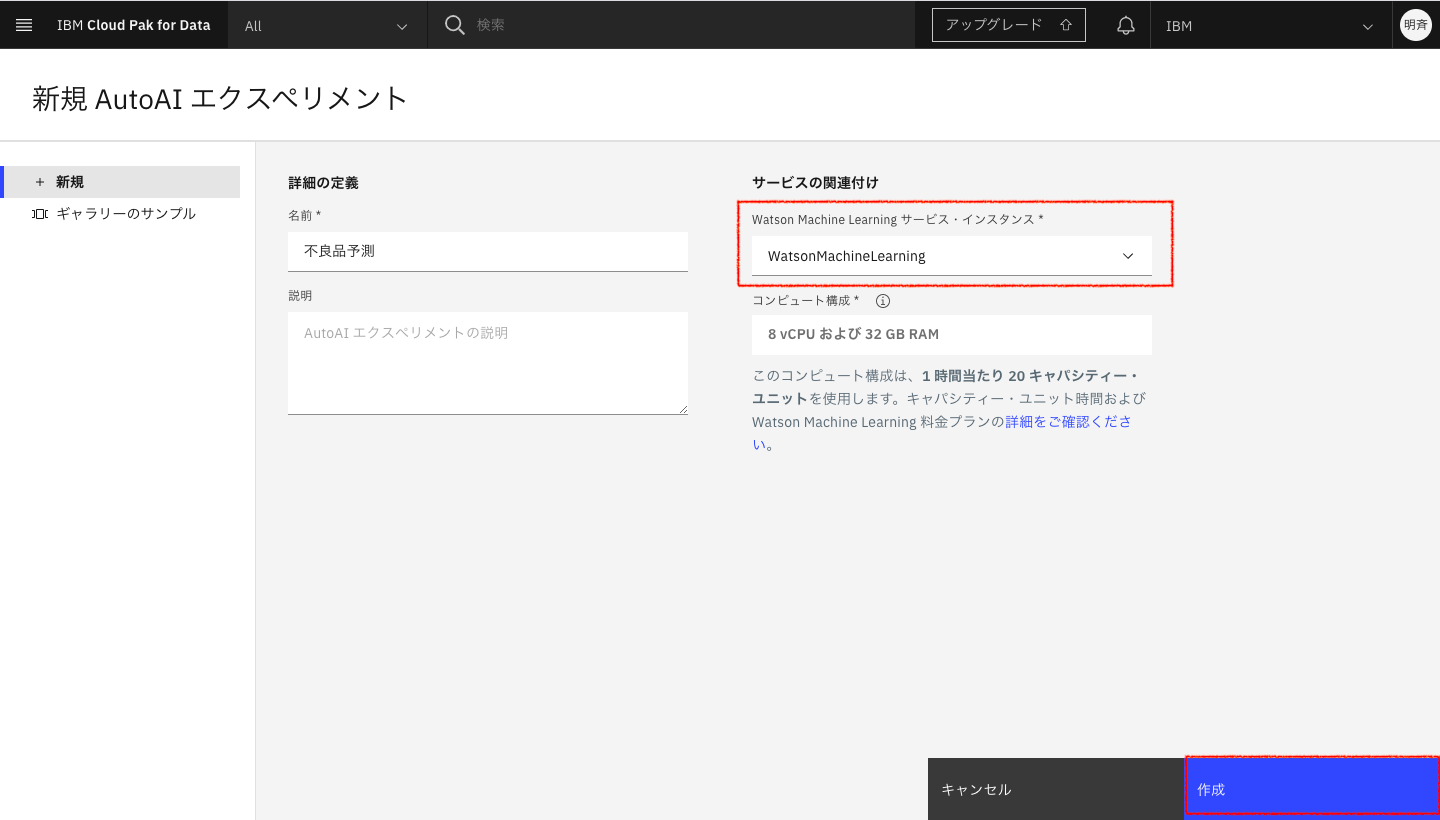
2-7. Watson Machine Learning サービスインスタンスが認識されますので、プルダウンからWatson Machine Learning を選択し、「作成」をクリックします。
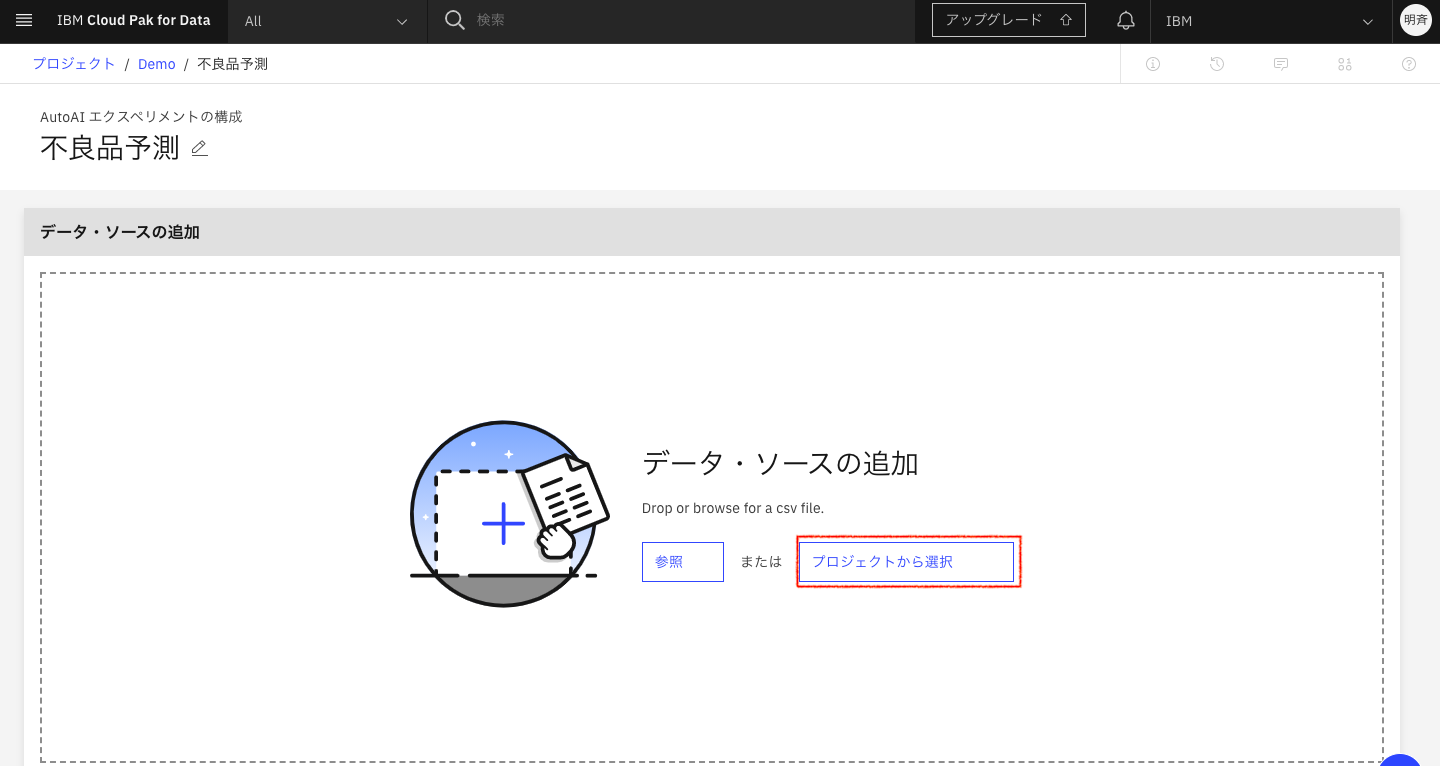
2-8. データソースの追加で「プロジェクトから選択」をクリックします。
2-9. 前処理済みのcsvファイルを選択し、「資産の選択」をクリックします。
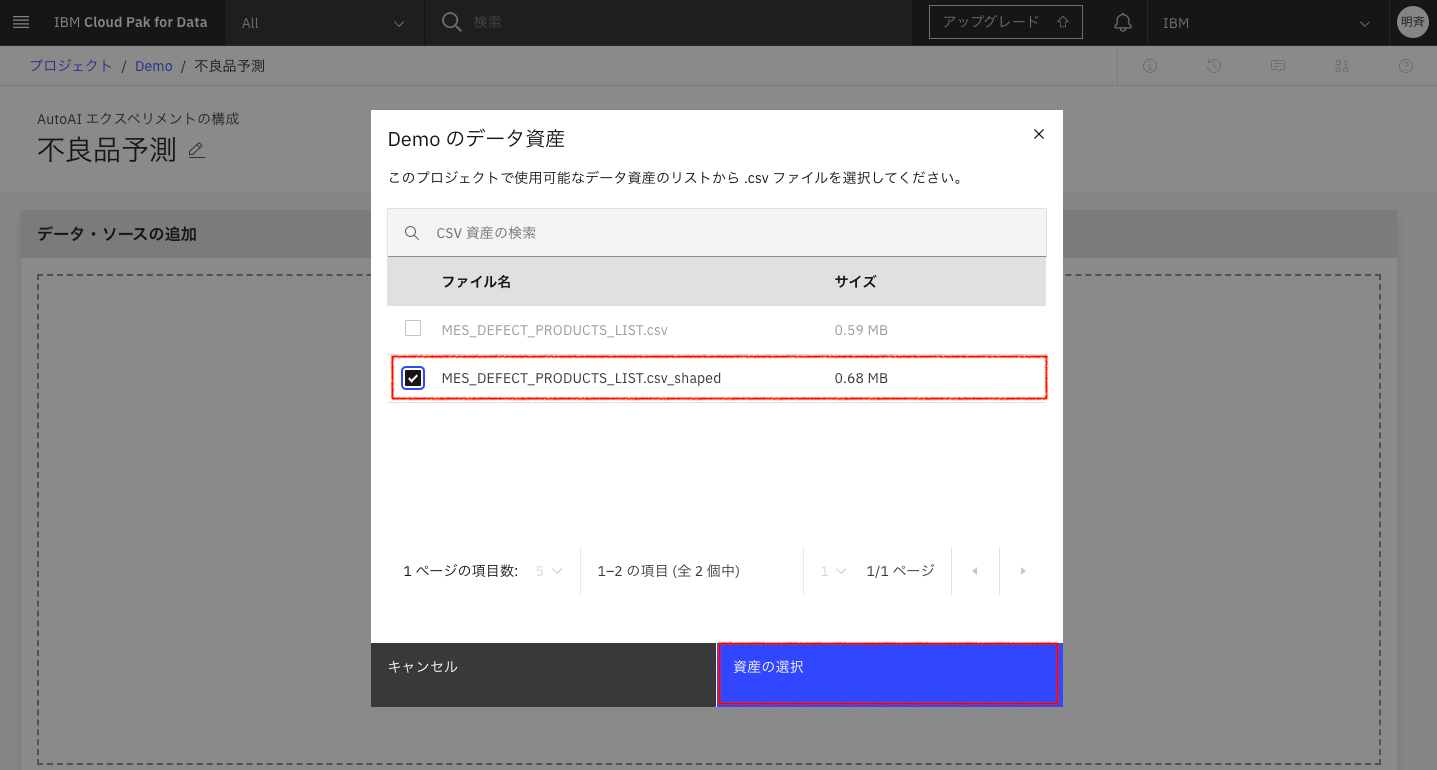
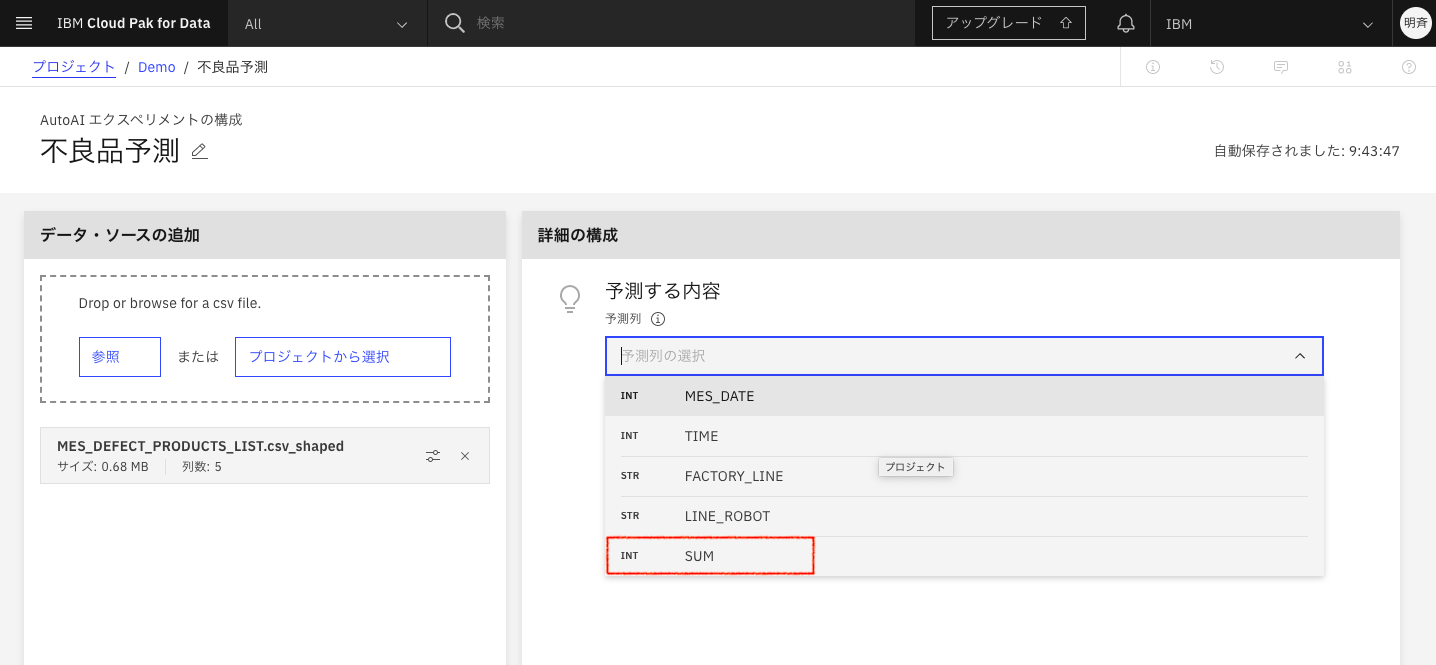
2-10. 予測する内容で「SUM」を指定します。(不良品数の予測をするため)
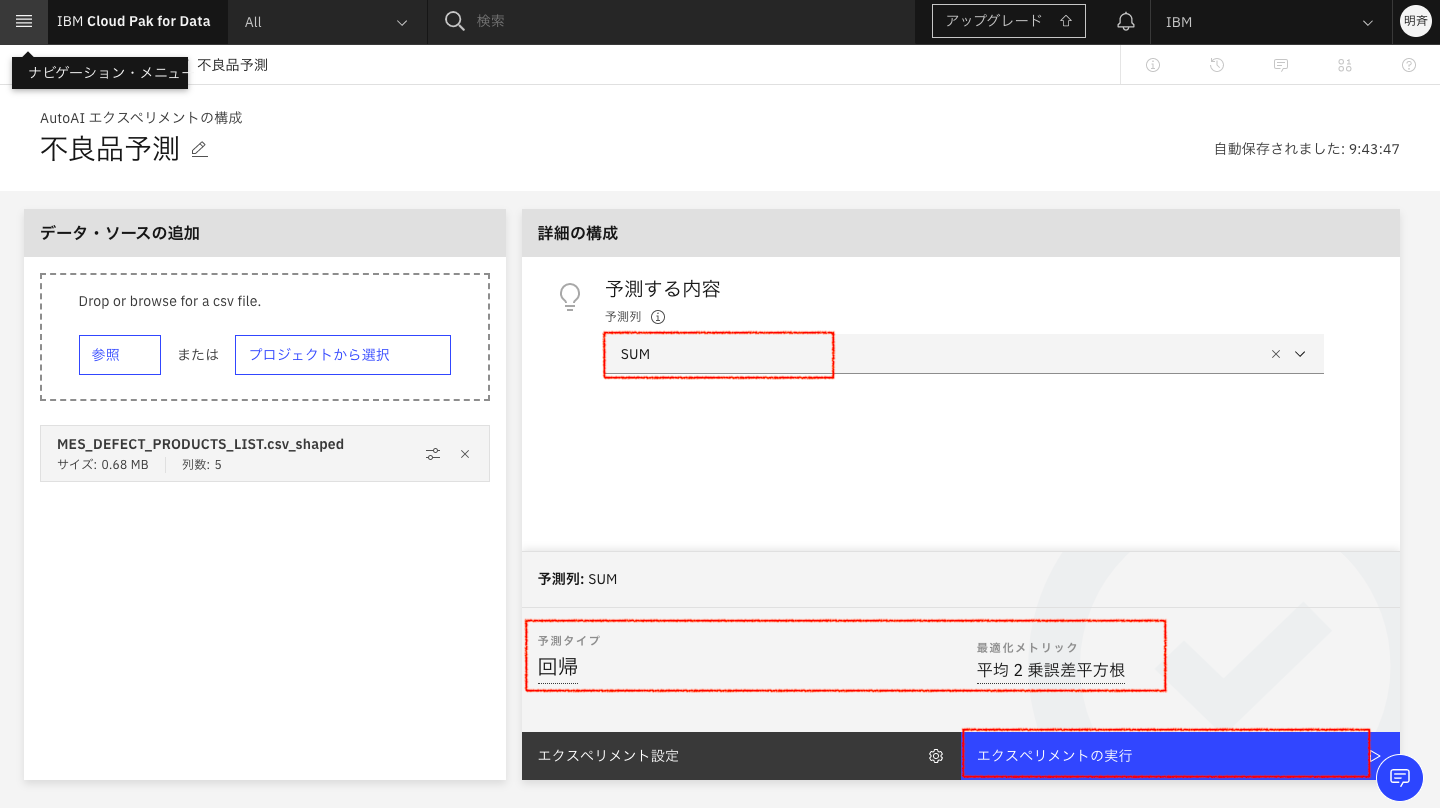
2-11. 不良品数の予測に使用する予測タイプが自動で選択されます。変更する場合は「エクスペリメント設定」を開いて詳細をカスタマイズしていくことができます。ここでは、このまま「回帰」、「平均 2 乗誤差平方根」で「エクスペリメントの実行」をクリックしモデルを作成したいと思います。
2-11. しばらくするとモデルが作成され始めます。これには少し時間がかかります。
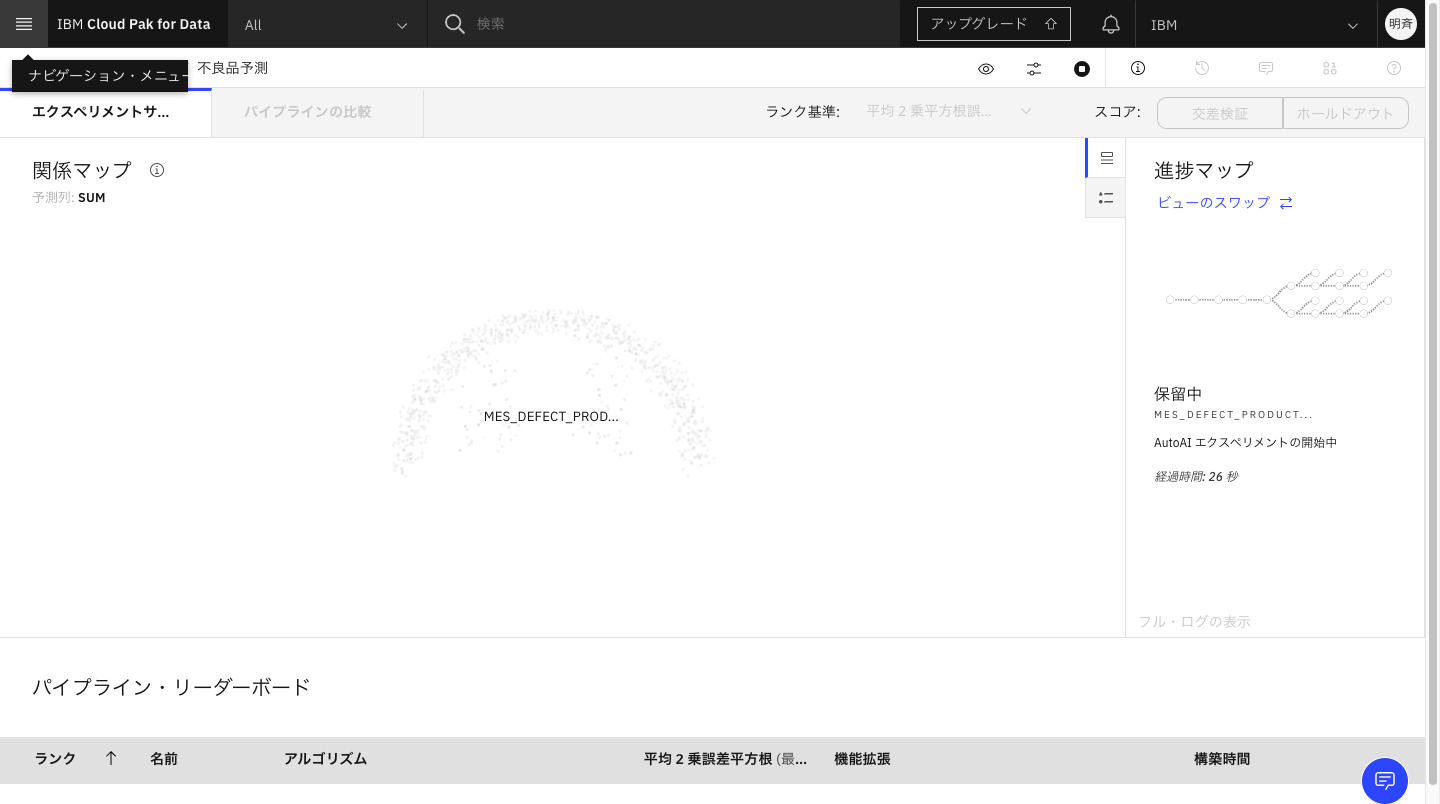
2つ作成できたところです。この設定では全部で8個のパイプライン(モデル候補)を作成します。
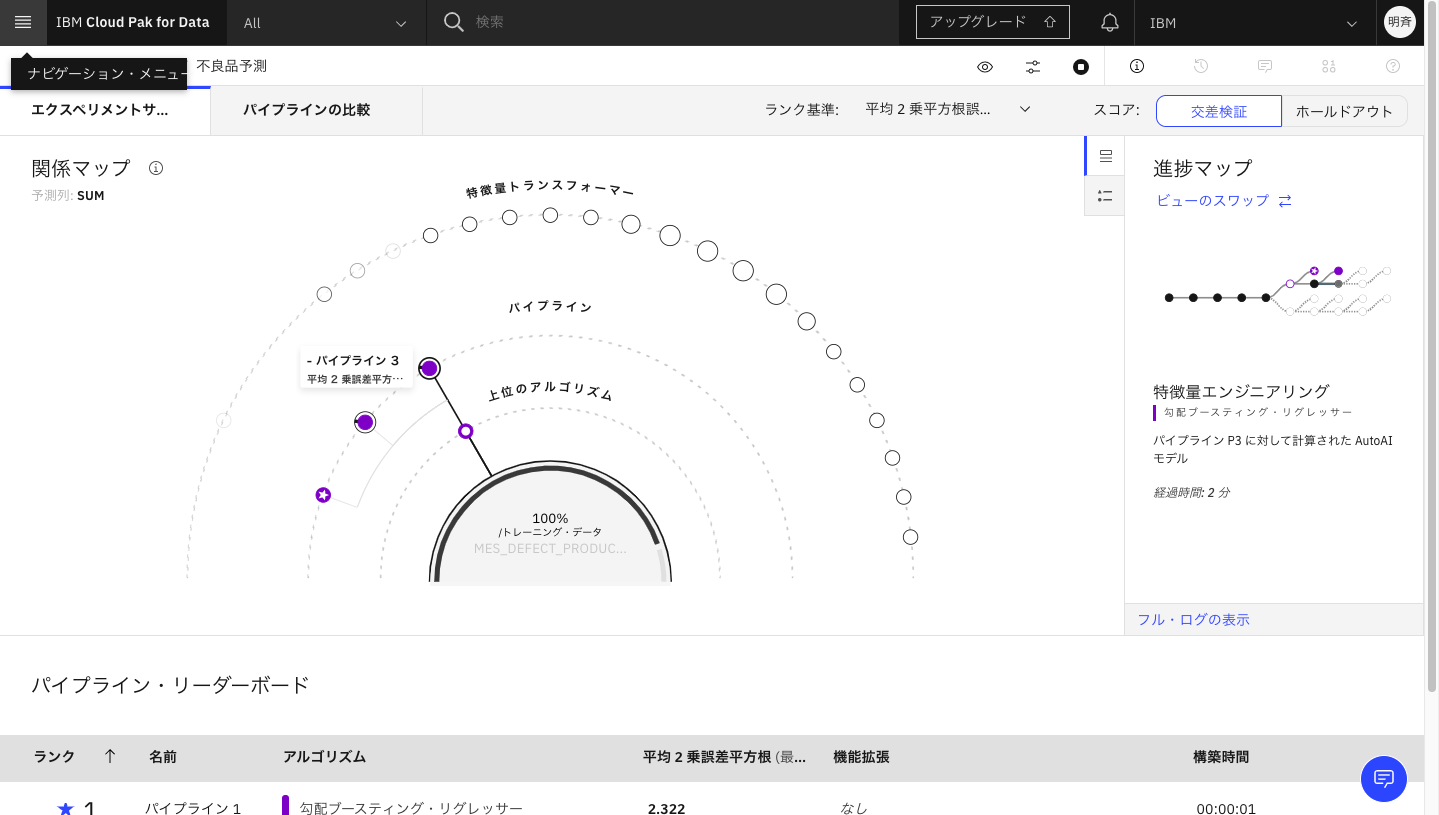
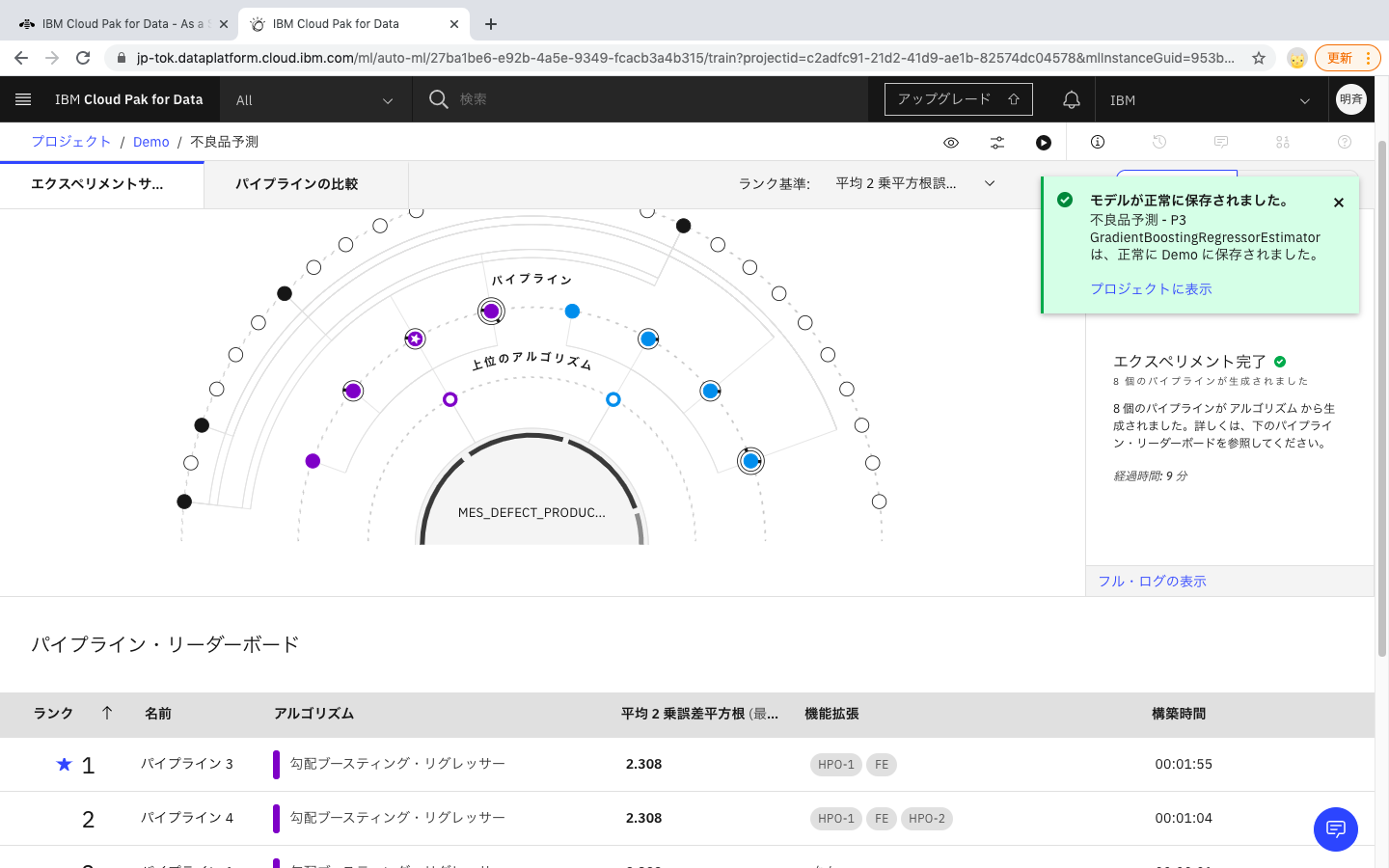
2-12. 8個のパイプラインが作成されました。
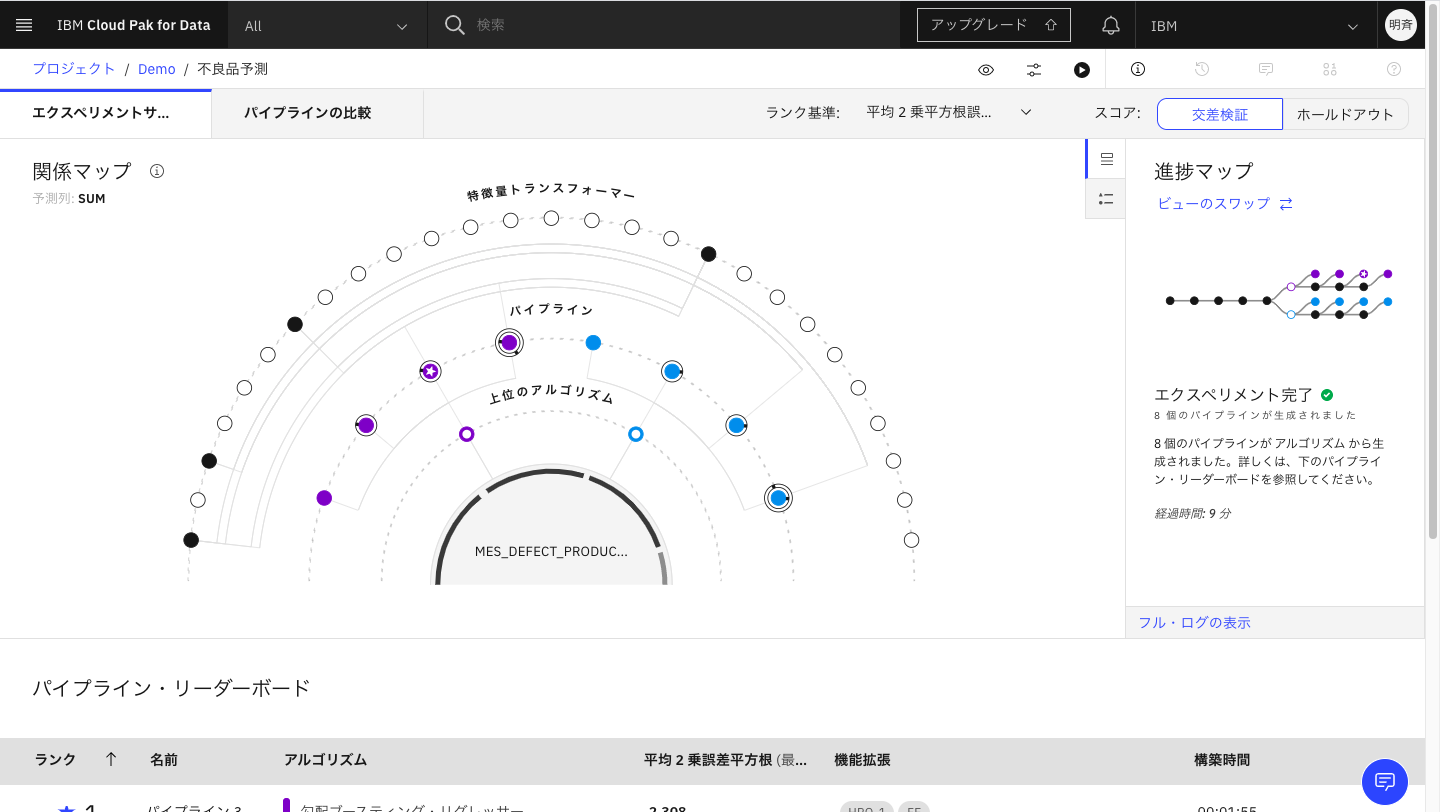
2-14. パイプライン3が最もパフォーマンスが良いということで、このパイプラインを保存してモデルとして利用していきたいと思います。「名前をつけて保存」をクリックします。
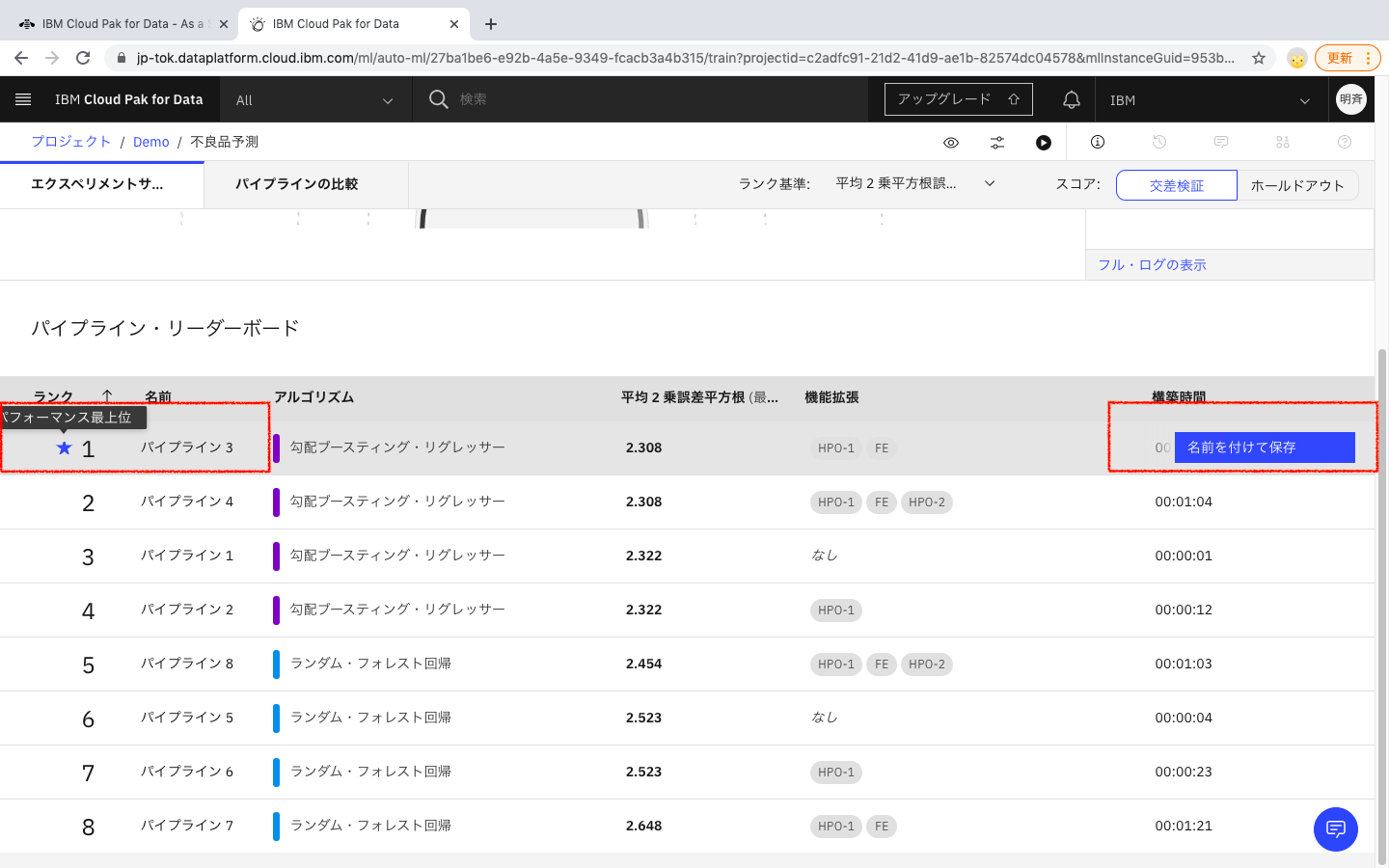
2-15 モデルとして保存するか、Notebookにコードを保存することが可能です。ここではモデルとして保存します。モデルを選択し、「作成」をクリックします。
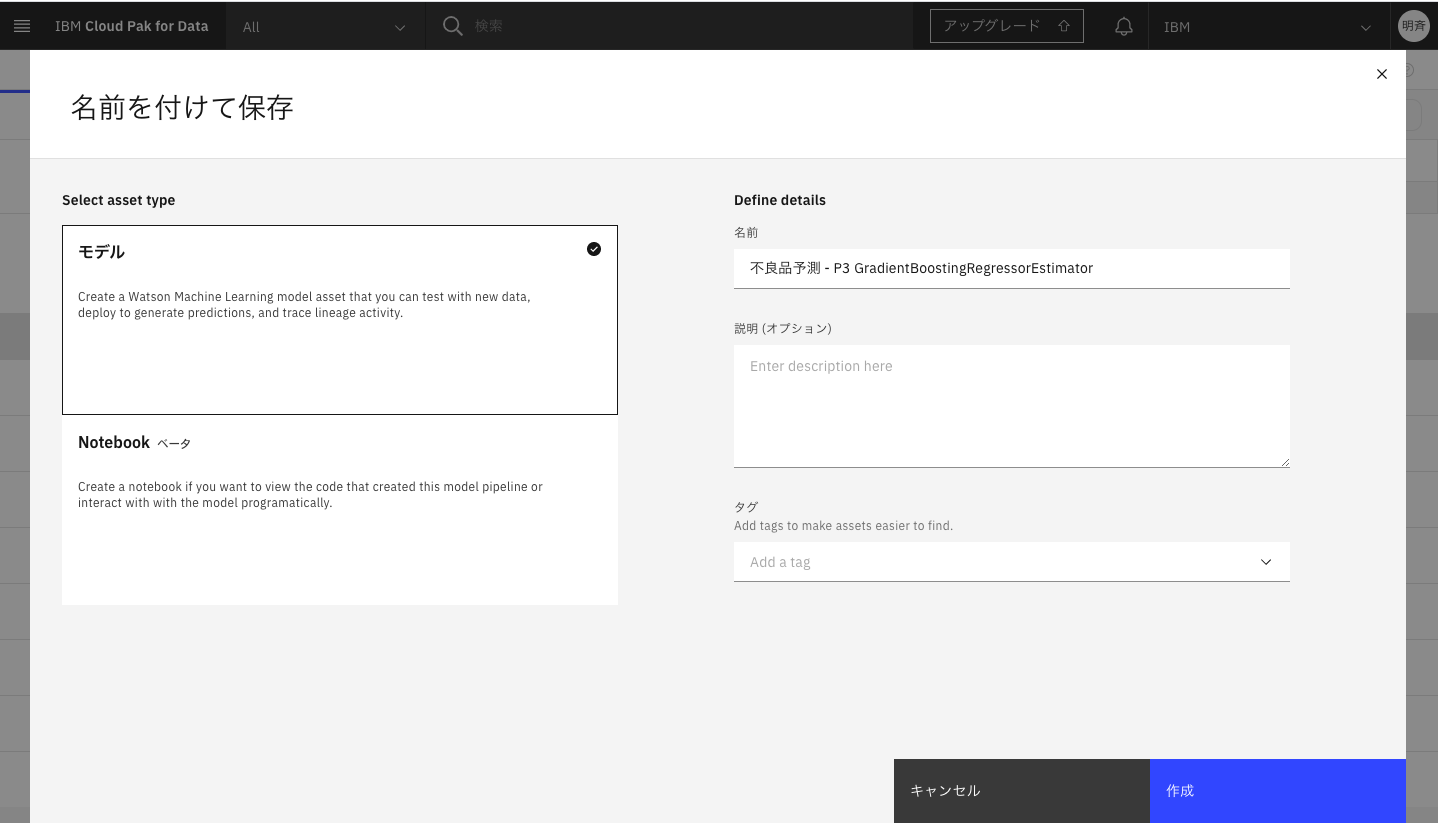
2-16. モデルが保存されると、右上にメッセージが表示され、資産タブに、保存したモデルが表示されます。
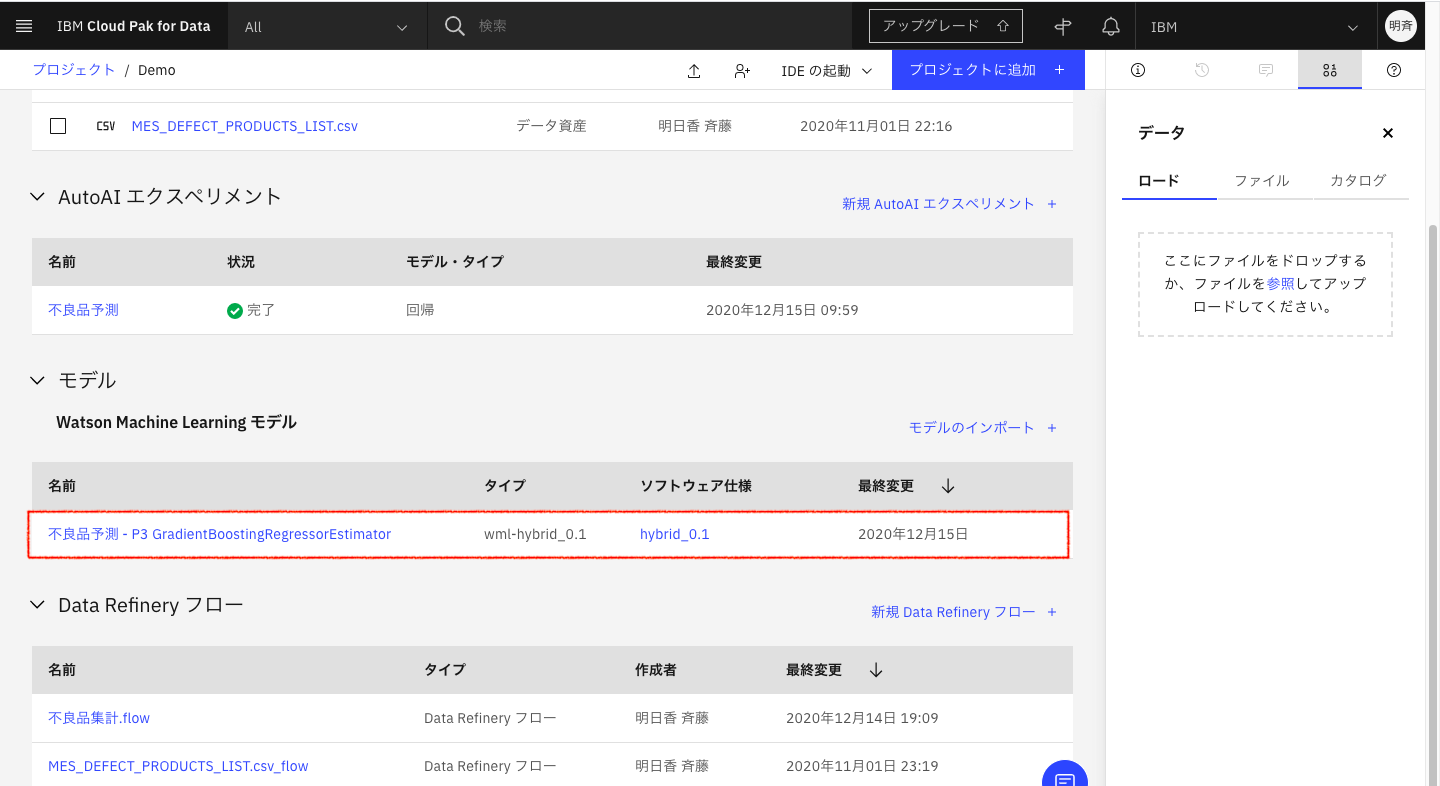
以上で、ノンコーディングで不良品数予測のモデルが作成されました。次章の「IBM Cloud Pak for Data as a Serviceを始めてみる(6.モデルのデプロイと呼び出し)」でこのモデルをデプロイして実際に動かしてみたいと思います。