IBM Cloud Pak for Data の XaaS 版 as a Service の始め方をまとめました。
この記事は主に、データ利用者側の操作を説明しています。
IBM Cloud Pak for Data as a Serviceを始めてみる(4.データの前処理編)
目次
- はじめに
- Data Refinery を使ってデータの前処理をする
- NULL値の排除
- コロン(:)での文字列の分割
- グルーピングで集計
- ジョブの実行
シリーズ目次
-管理者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(1.プロビジョニング編)
-全員
IBM Cloud Pak for Data as a Serviceを始めてみる(2.ログイン編)
-データ利用者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(3.分析環境編)
IBM Cloud Pak for Data as a Serviceを始めてみる(4.データの前処理編)
IBM Cloud Pak for Data as a Serviceを始めてみる(5.モデルの自動作成)
IBM Cloud Pak for Data as a Serviceを始めてみる(6.モデルのデプロイと呼び出し)
[IBM Cloud Pak for Data as a Serviceを始めてみる(7.ダッシュボードの作成)]
(https://qiita.com/Asuka_Saito/items/79a3b9cd7f65b45d04a3)
-データ提供者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(8.カタログの作成)
IBM Cloud Pak for Data as a Serviceを始めてみる(9.ビジネス用語の作成)
IBM Cloud Pak for Data as a Serviceを始めてみる(10.メタデータのインポート)
IBM Cloud Pak for Data as a Serviceを始めてみる(11.ビジネス用語の割り当て)
-データ利用者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(12.カタログ検索してデータを見つける)
-管理者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(13.Db2のサービスを追加する)
-その他参考
IBM Cloud Pak for Data as a Serviceを始めてみる(14.GoSalesのデータを使う)
IBM Cloud Pak for Data as a Serviceを始めてみる(15.コールセンターのデータセットを使う)
IBM Cloud Pak for Data as a Serviceを始めてみる(16.Modelerフローのサンプルを使ってみる - 薬剤研究例 )
IBM Cloud Pak for Data as a Serviceを始めてみる(17.Db2のサービスへの接続情報を追加する)
IBM Cloud Pak for Data as a Serviceを始めてみる(18.機能改善やアイディアを投稿する)
IBM Cloud Pak for Data as a Serviceを始めてみる(19.Modelerフローで不良品件数予測モデルを開発する )
IBM Cloud Pak for Data as a Serviceを始めてみる(20.無償プランの枠を使い切った場合)
1. はじめに
この記事はIBM Cloud Pak for Data as a Service の分析環境であるWatson StudioのData Refineryを使って、csvファイルの前処理(NULL値の排除、コロン(:)での文字列の分割、グルーピングで集計)をするところまでを実施したいと思います。
2. Data Refinery を使ってデータの前処理をする
2-1. IBM Cloud Pak for Data as a Serviceにログインし、TOPページを表示します。
すでに、IBM Cloud Pak for Data as a Serviceを始めてみる(3.分析環境編)でプロジェクトを作成し、csvファイルをアップロードしている場合は、「最近使用したプロジェクト」にプロジェクト名が表示されますので、クリックします。
2-2. 分析プロジェクトが立ち上がります。資産タブに移動して最初にアップロードしたcsvファイルをクリックします。
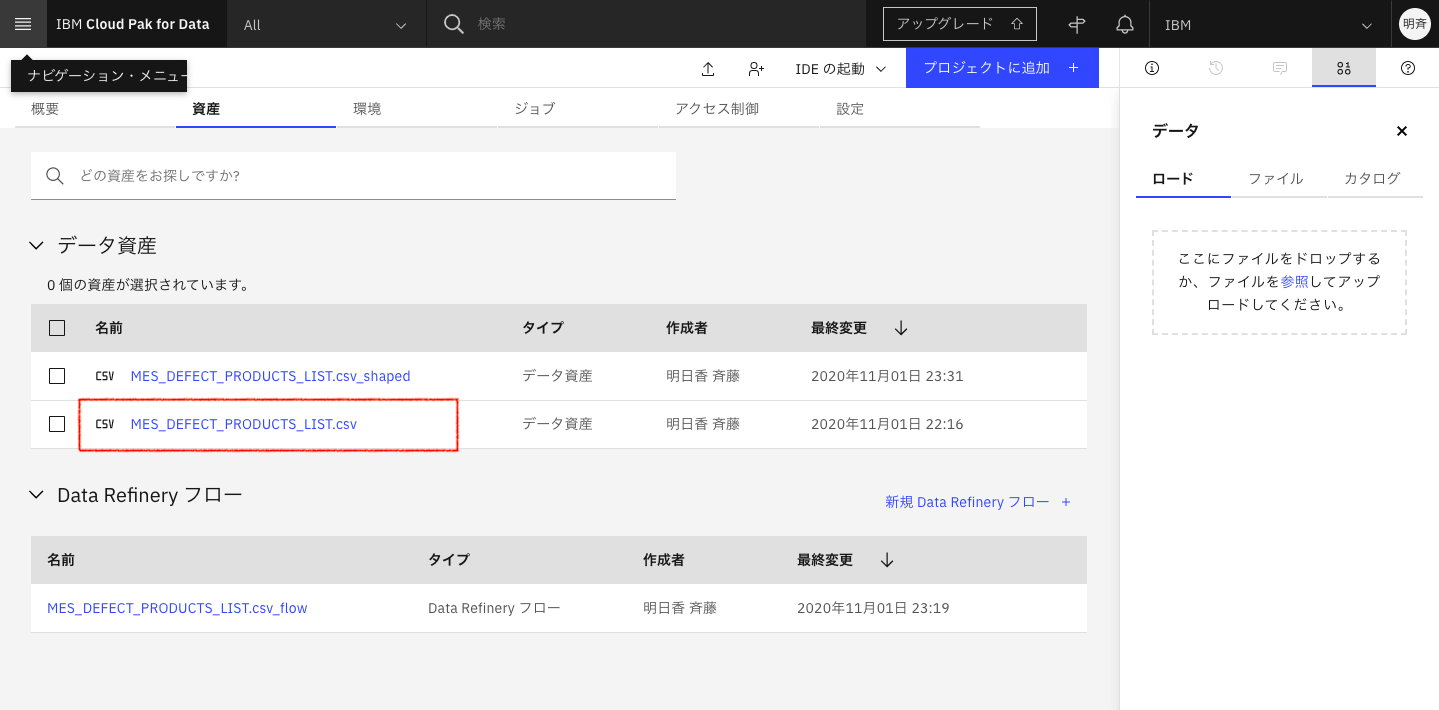
2-3. 「精製」をクリックします。
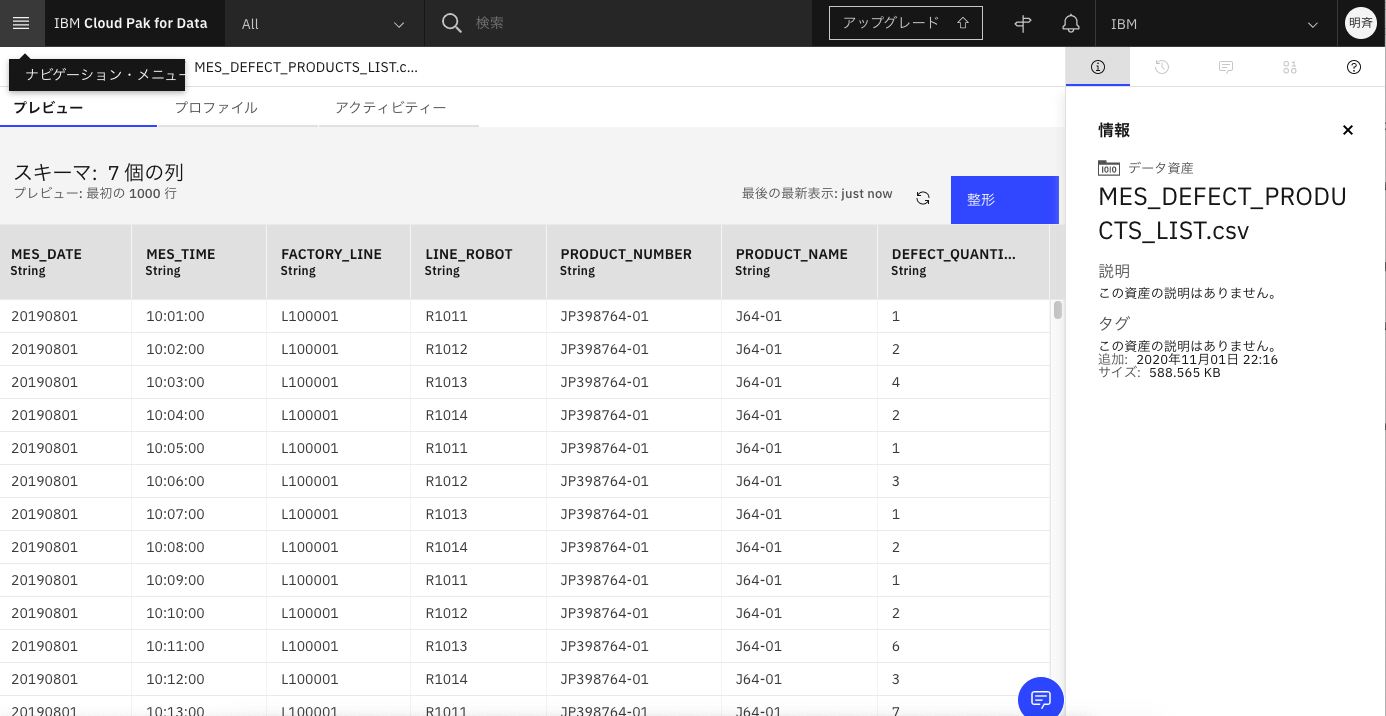
2-4. しばらく右上に「最初の50行のプレビュー中」というメッセージが表示されていますが、消えたら前処理の作業ができます。
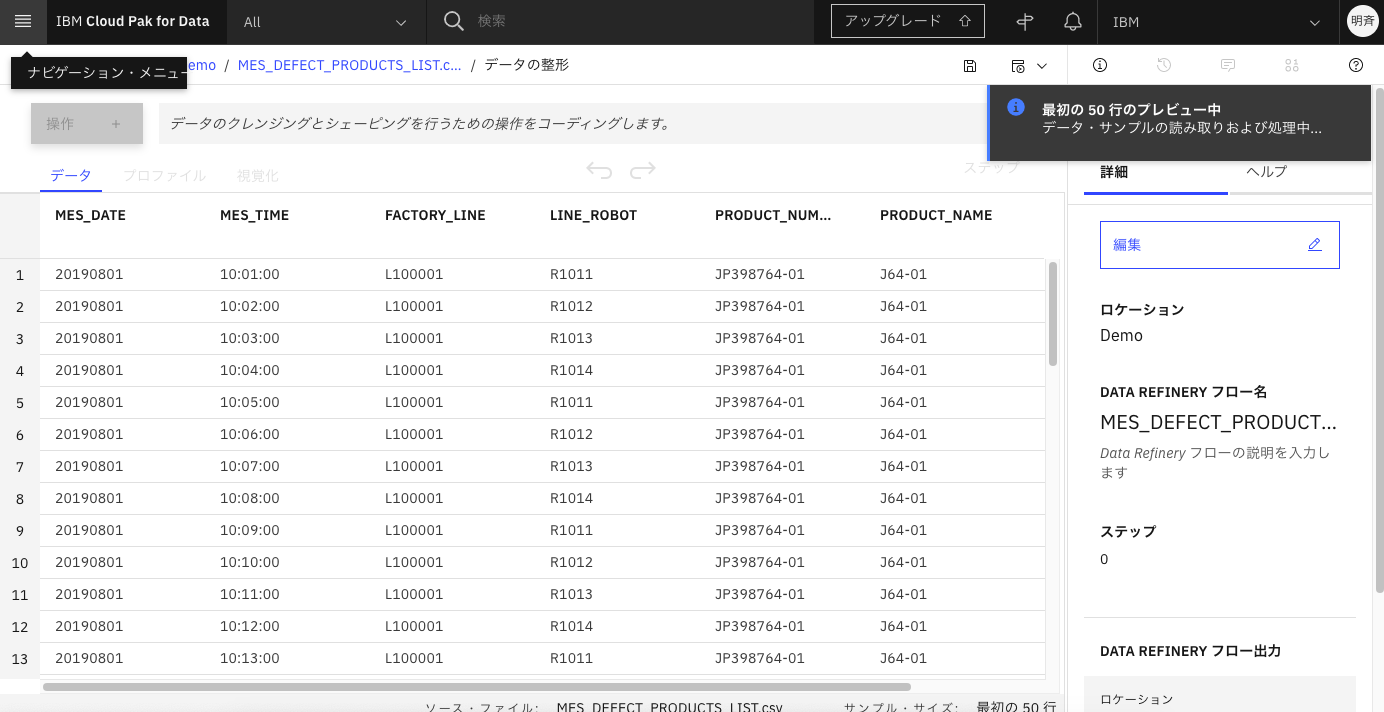
2-5. NULL値の排除
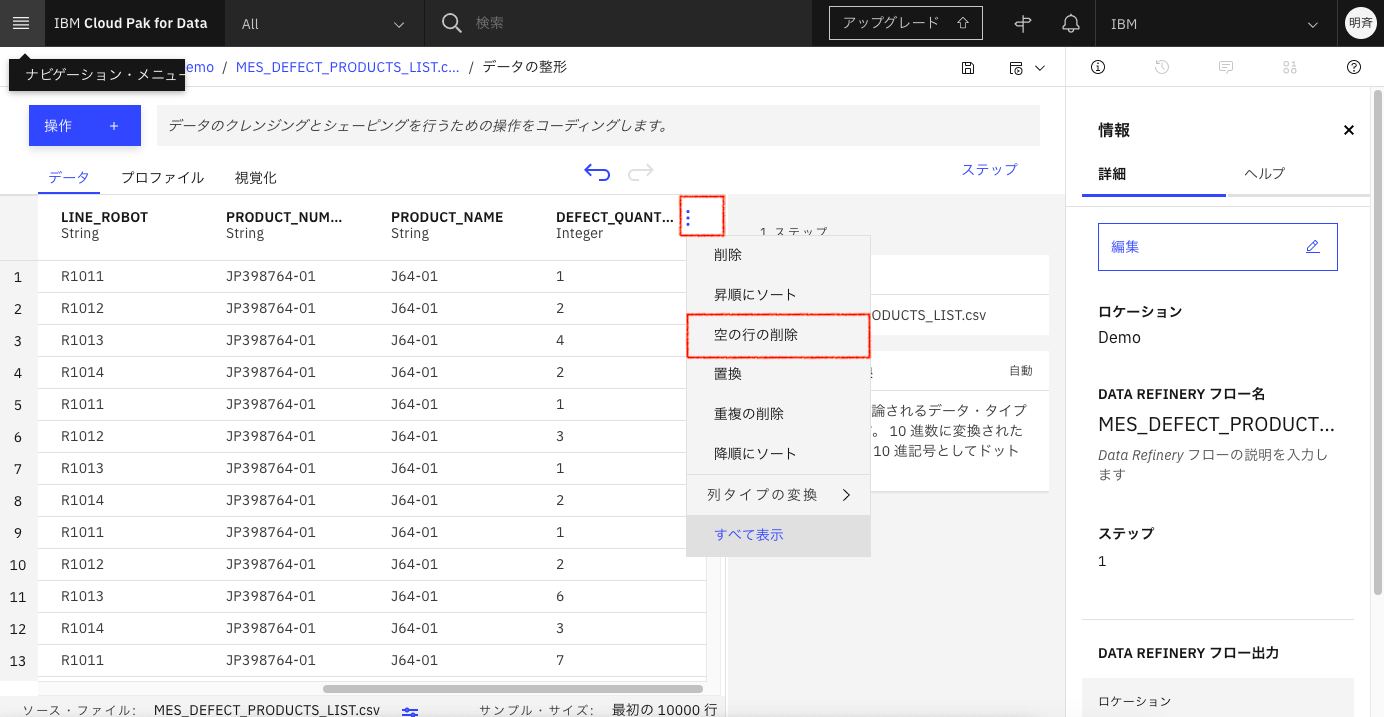
NULL値の排除は、「DEFECT_QUANTITY」列の右端を右クリックして「空の行の削除」を選択します。
2-6. コロン(:)での文字列分割
コロン(:)での文字列分割は「MES_TIME」列で実施します。データは時間分秒まで表示されているのですが、グルーピングしやすいように、最初のコロン(:)前までの文字列を取得します。
「MES_TIME」列の右端を右クリックして「すべて表示」を選択します。
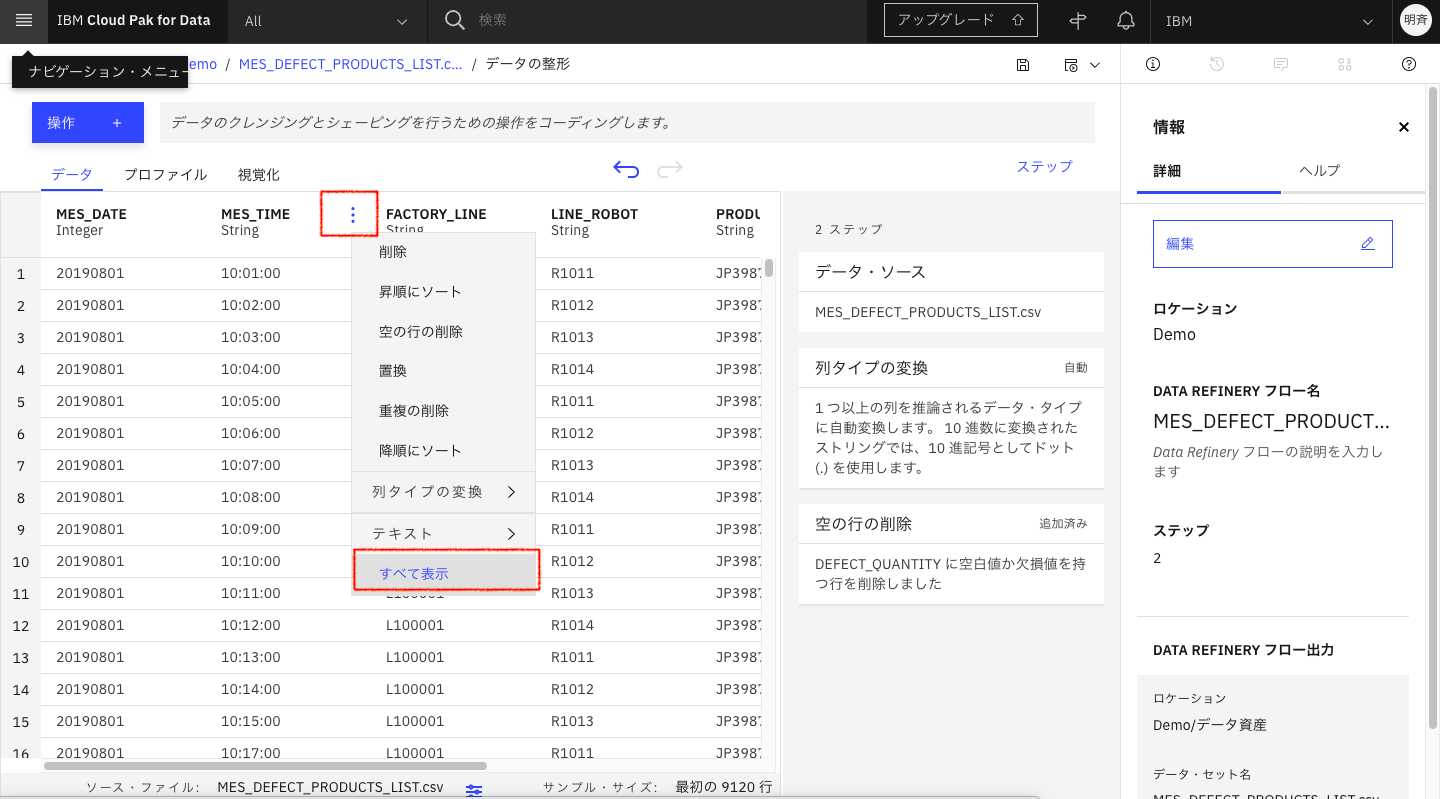
「列の分割」を選択します。
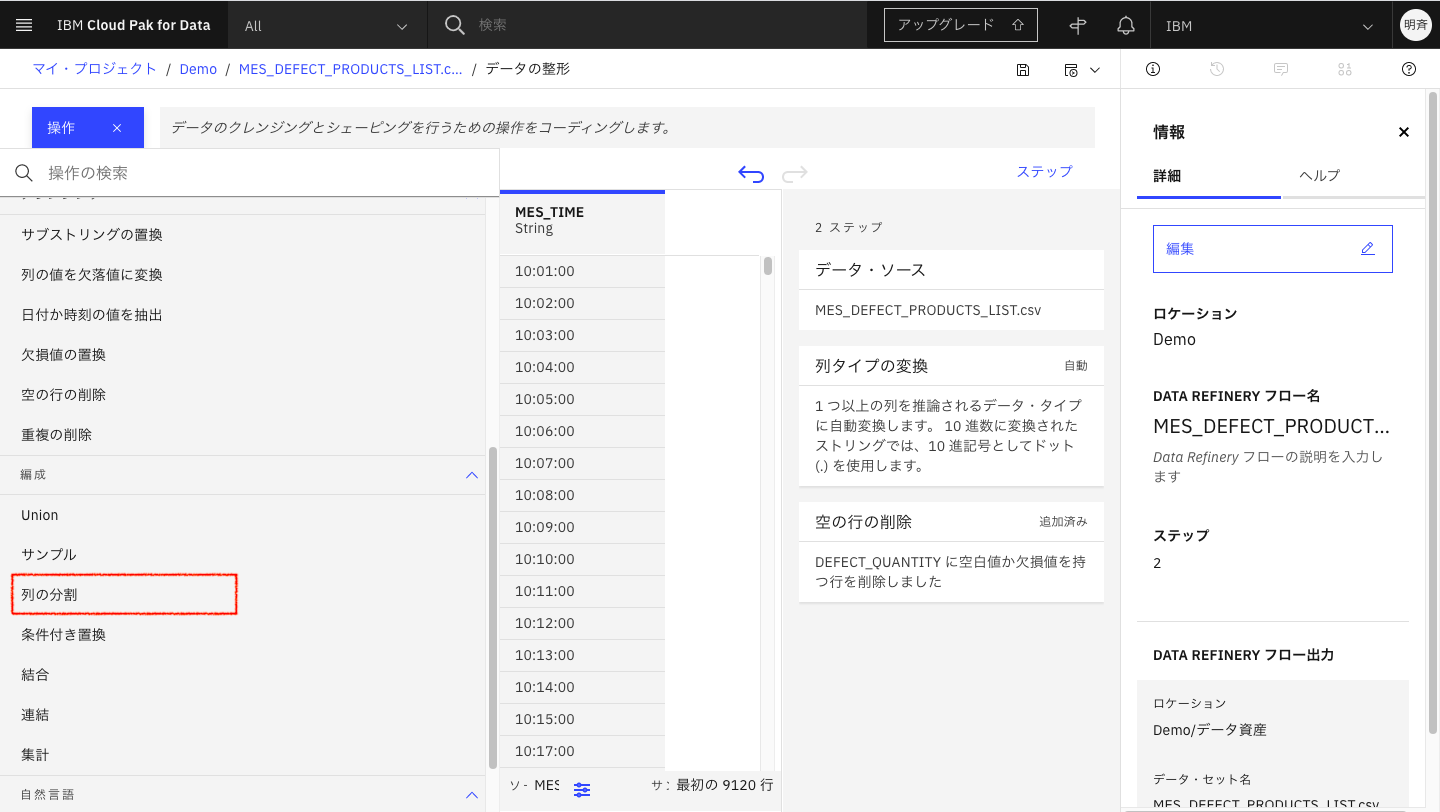
以下の図のように設定し、最後に「適用」をクリックします。
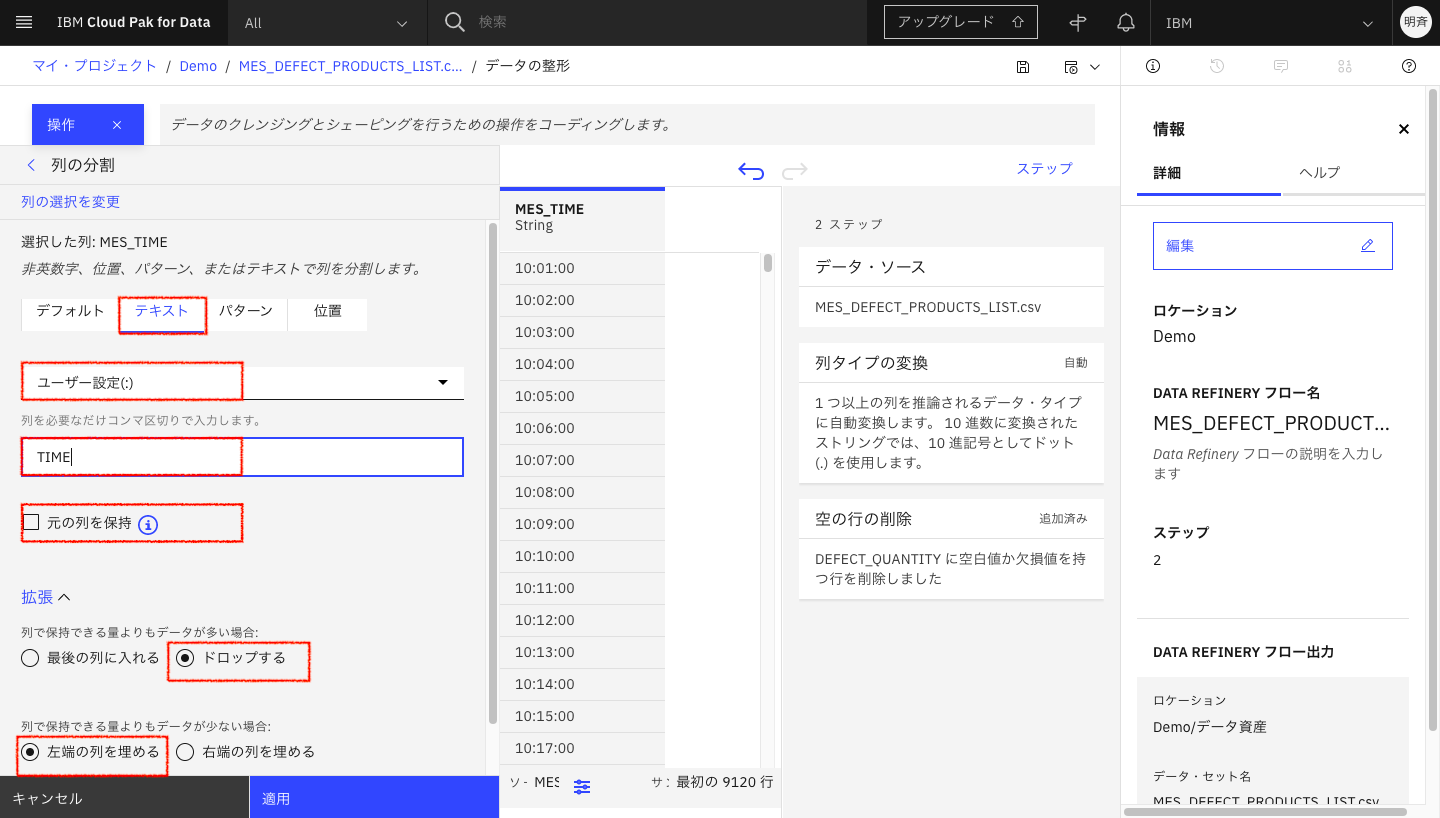
TIME列に分割された文字列が入りました。
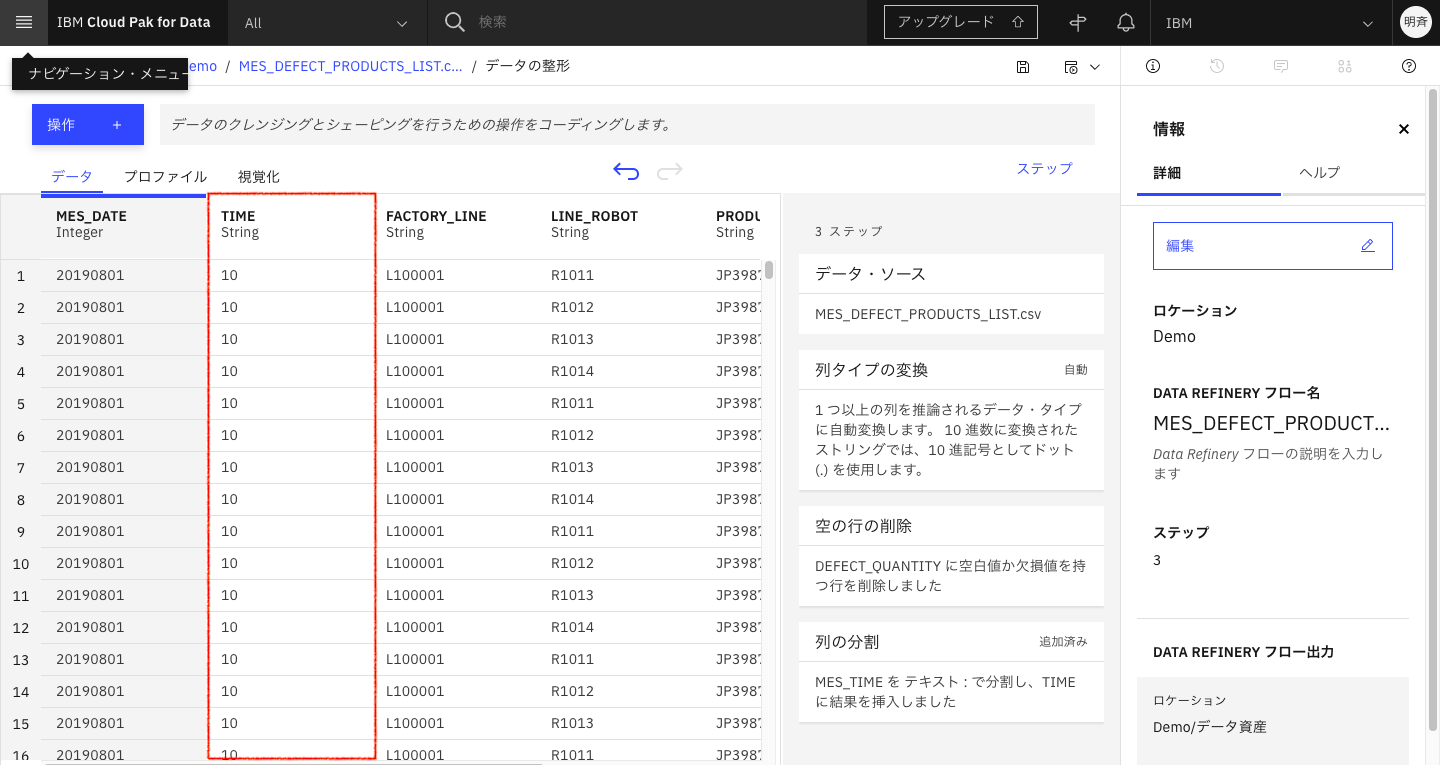
2-7. グルーピングで集計する
「MES_DATE」「TIME」「FACTORY_LINE」「LINE_ROBOT」毎にいくつ不良品「DEFECT_QUANTITY」を出しているか集計します。
「MES_DATE」列の右端を右クリックして「すべて表示」を選択します。
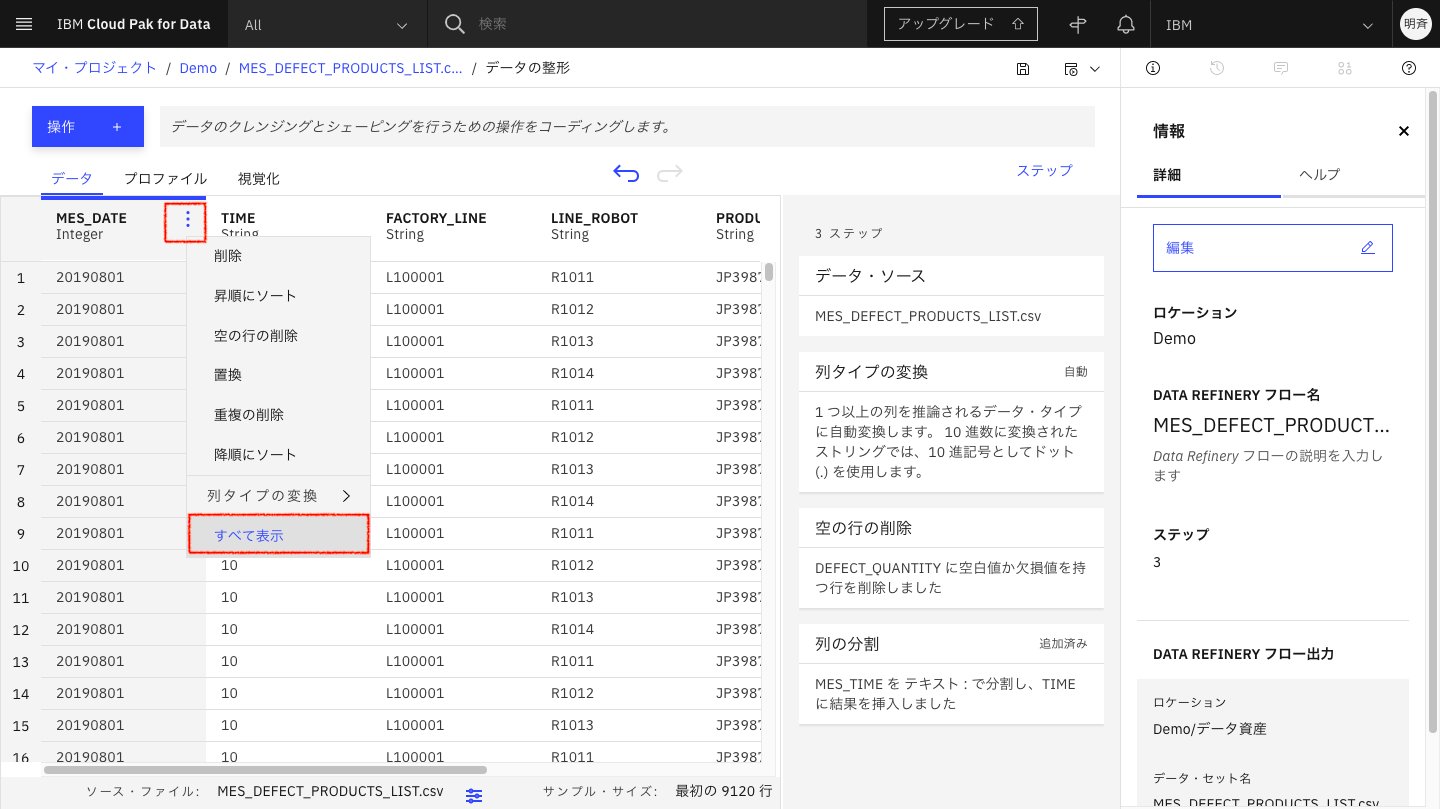
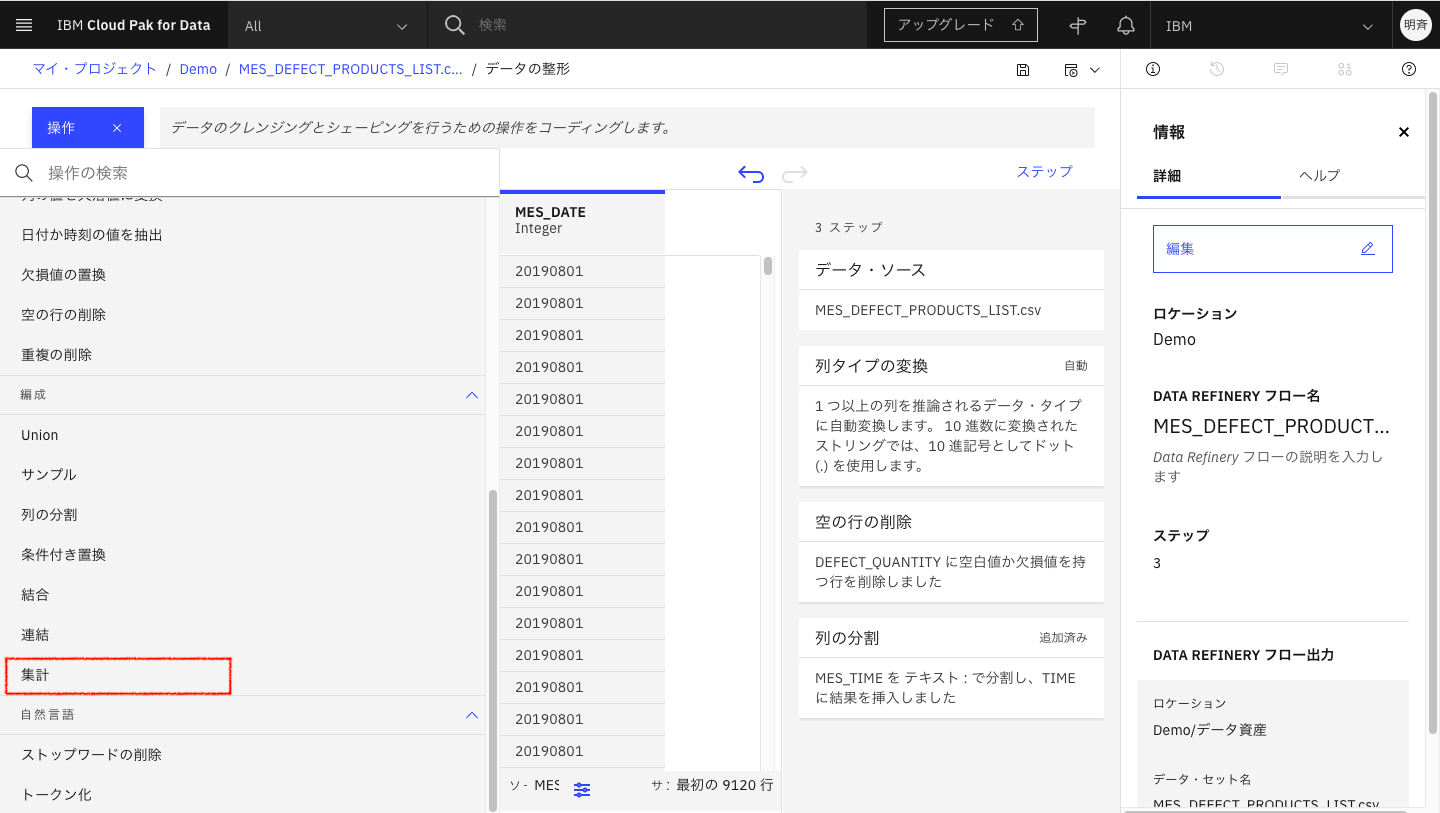
「集計」を選択します。
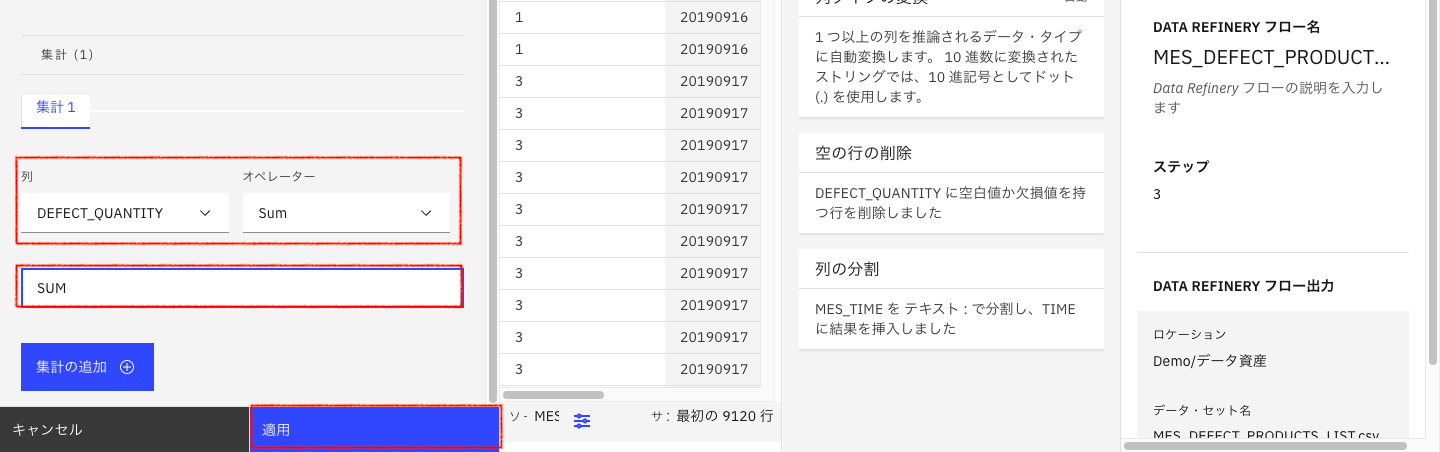
列でグループ化にチェックを入れて、「MES_DATE」「TIME」「FACTORY_LINE」「LINE_ROBOT」を順に指定します。
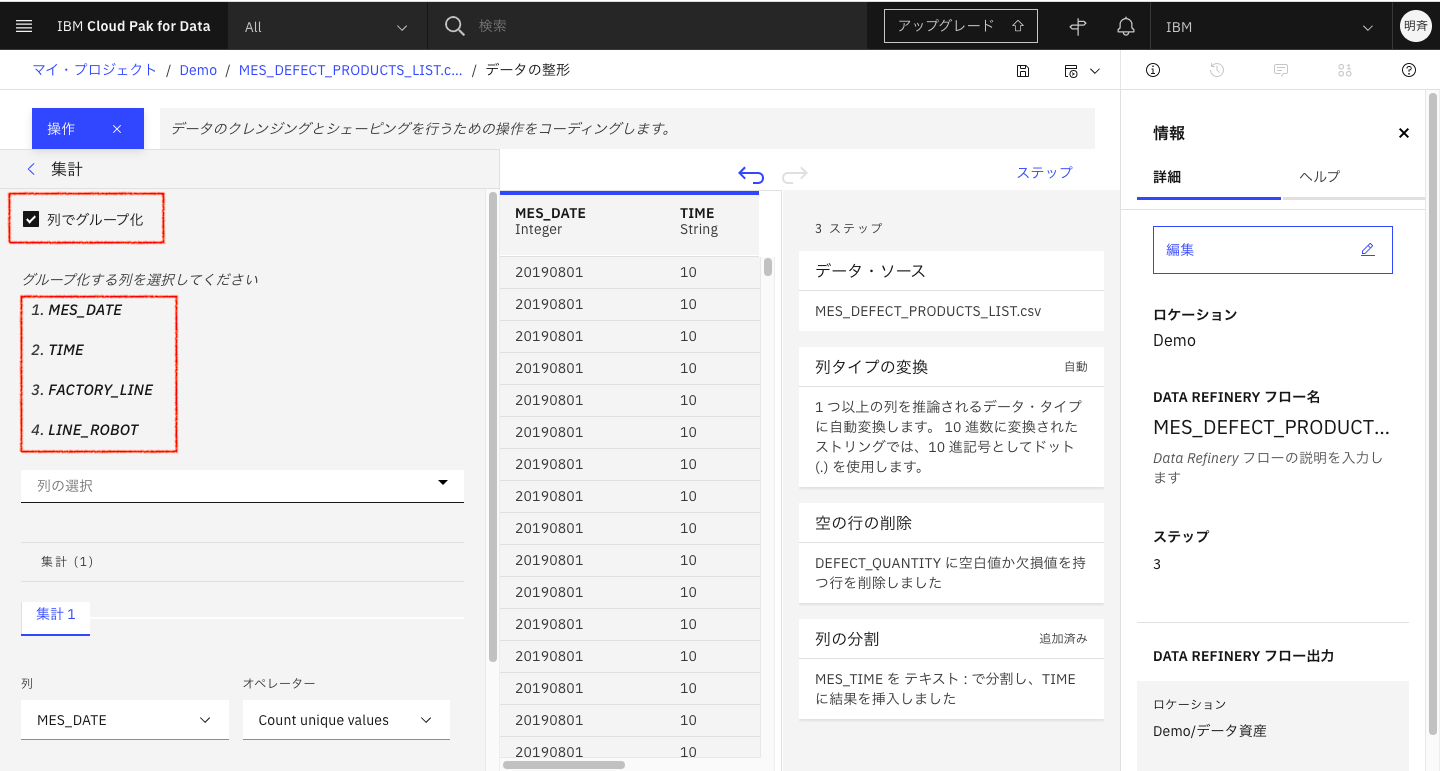
集計する列に「DEFECT_QUANTITY」をセットして「合計(Sum)」をセットします。
集計結果を入れる列名を入力して「適用」をクリックします。
「MES_DATE」「TIME」「FACTORY_LINE」「LINE_ROBOT」毎にグルーピング集計された不良品の合計数が表示されました。
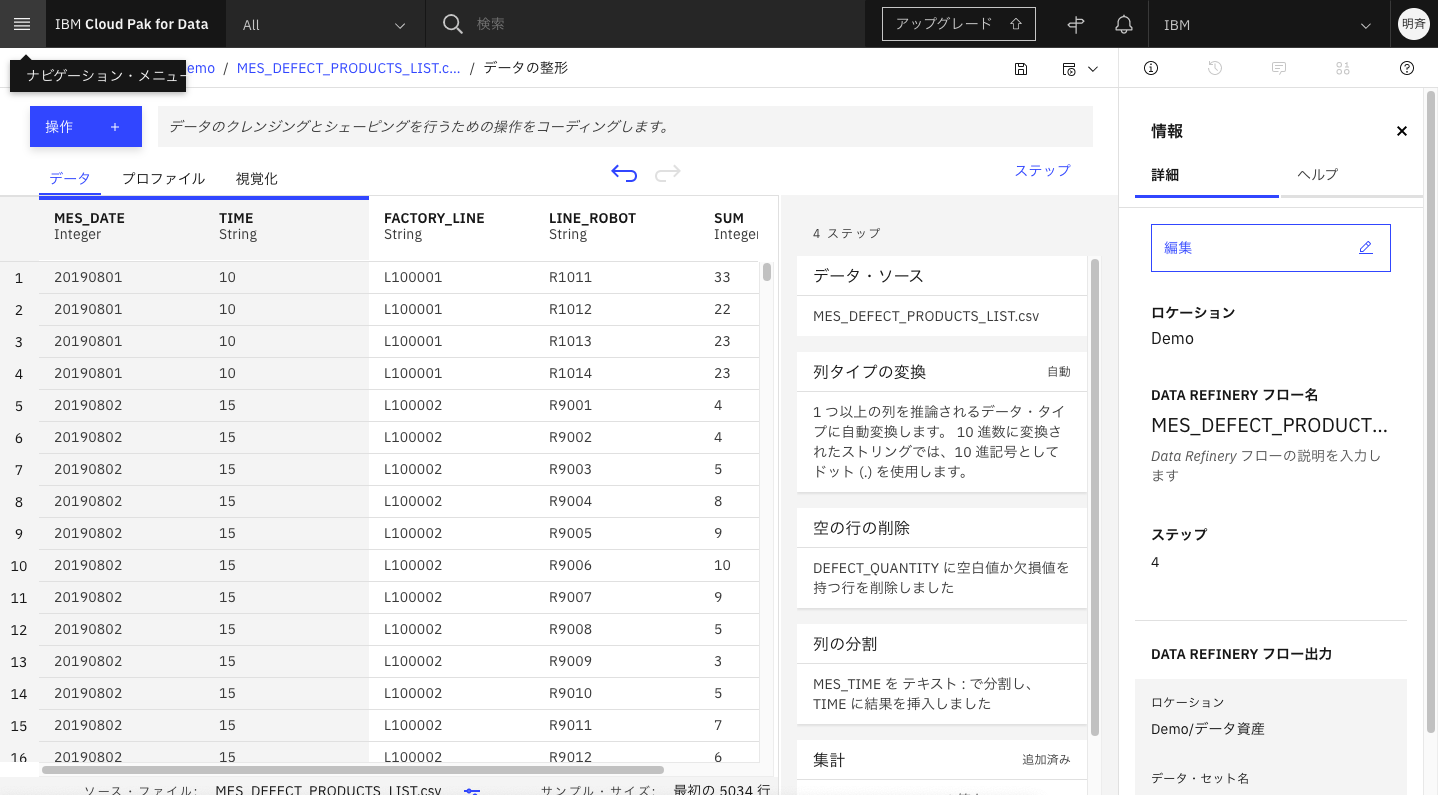
3. これまでの前処理の設定をデータ全件に適用したいので、ジョブを実行します。
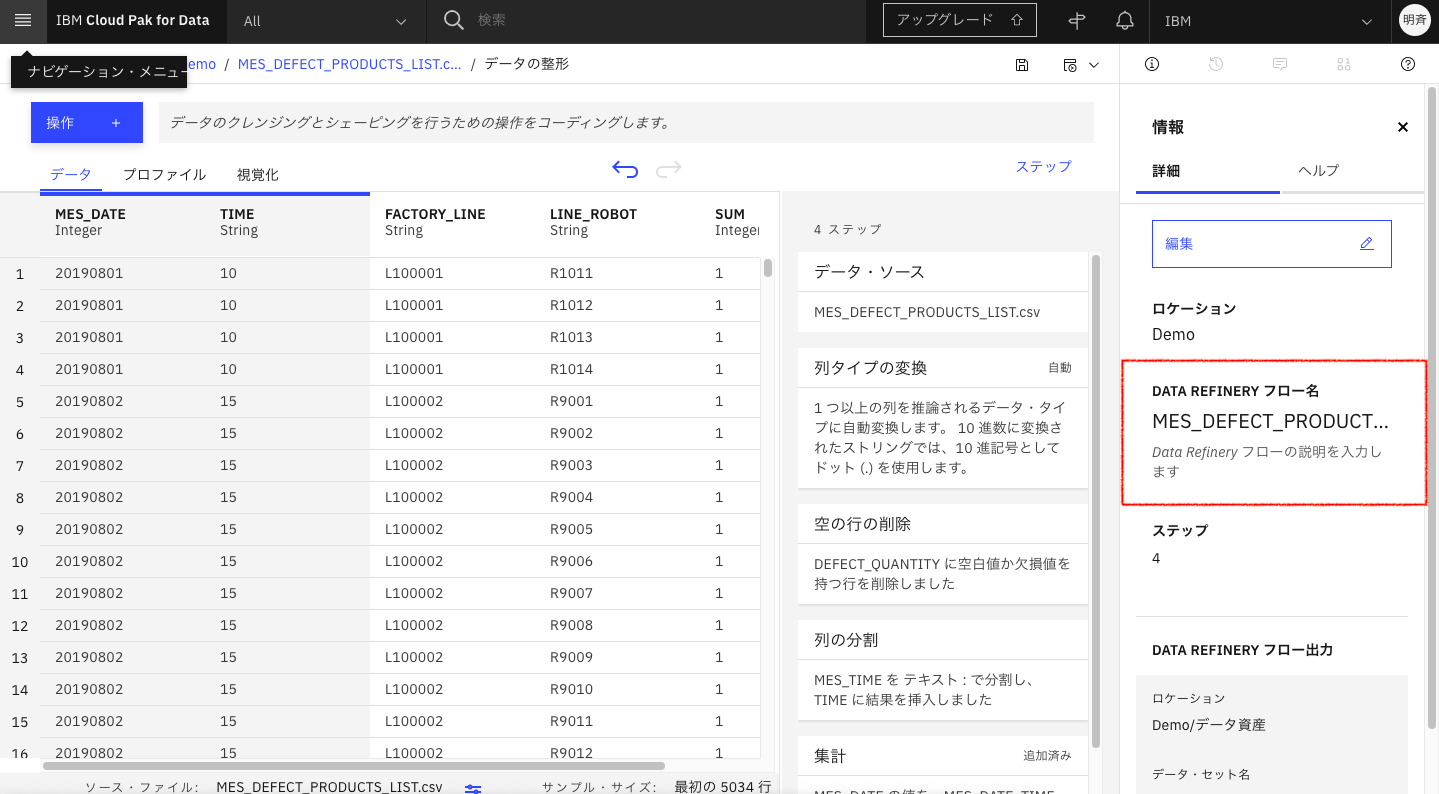
ジョブを実行するには、「ジョブを保存して作成」をクリックしますが、すでに、同じジョブのフロー名が作成されている場合、ジョブが実行できません。まずは、フロー名を変更します。
3-1. 「Deta Refinery フロー名」をクリックします。
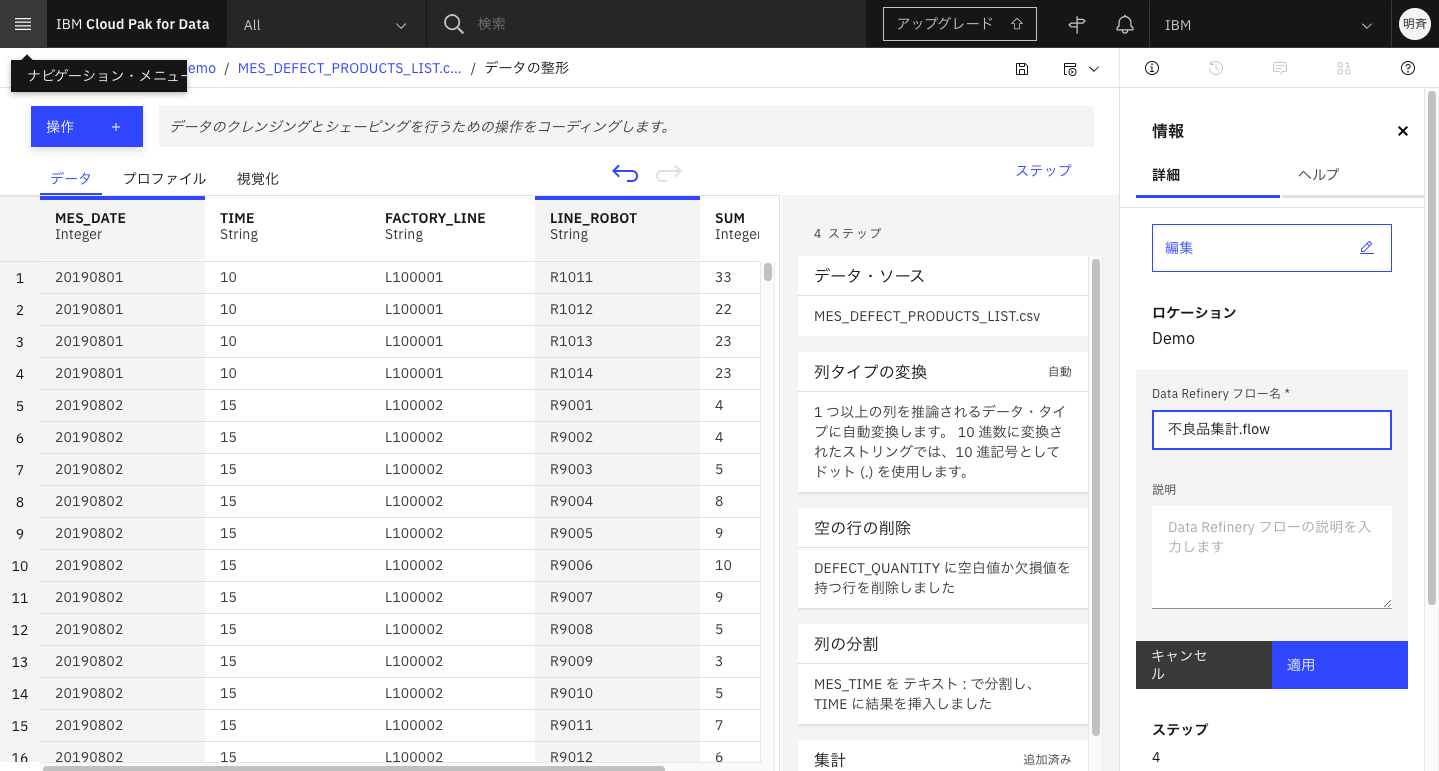
3-2. 新しいフロー名を入力し、「適用」をクリックします。
3-3. 「ジョブを保存して作成」をクリックします。
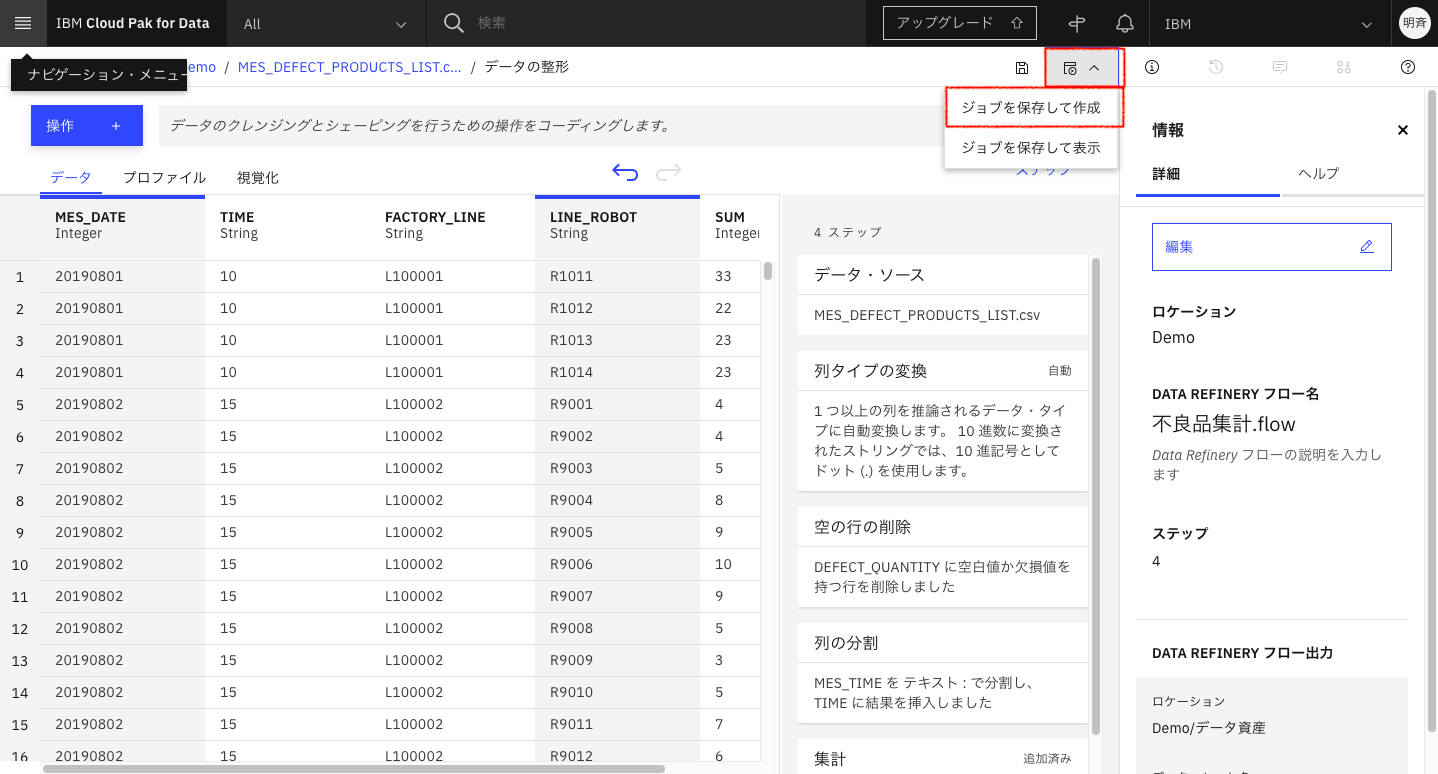
3-4. ジョブ名を入力して「次へ」をクリックします。
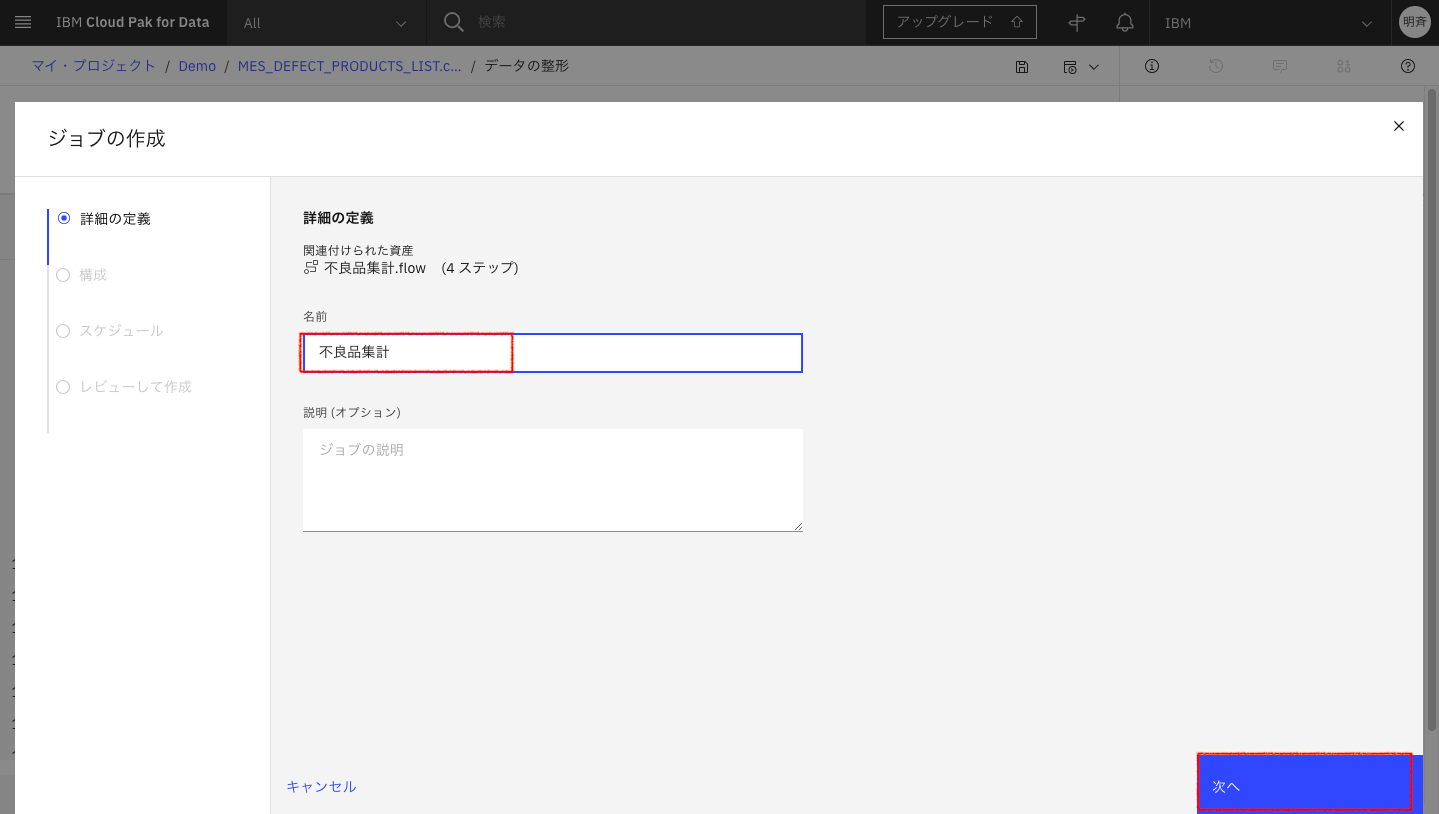
3-5. 次へをクリックします。(出力されるファイル名がすでにある場合上書きされます。)
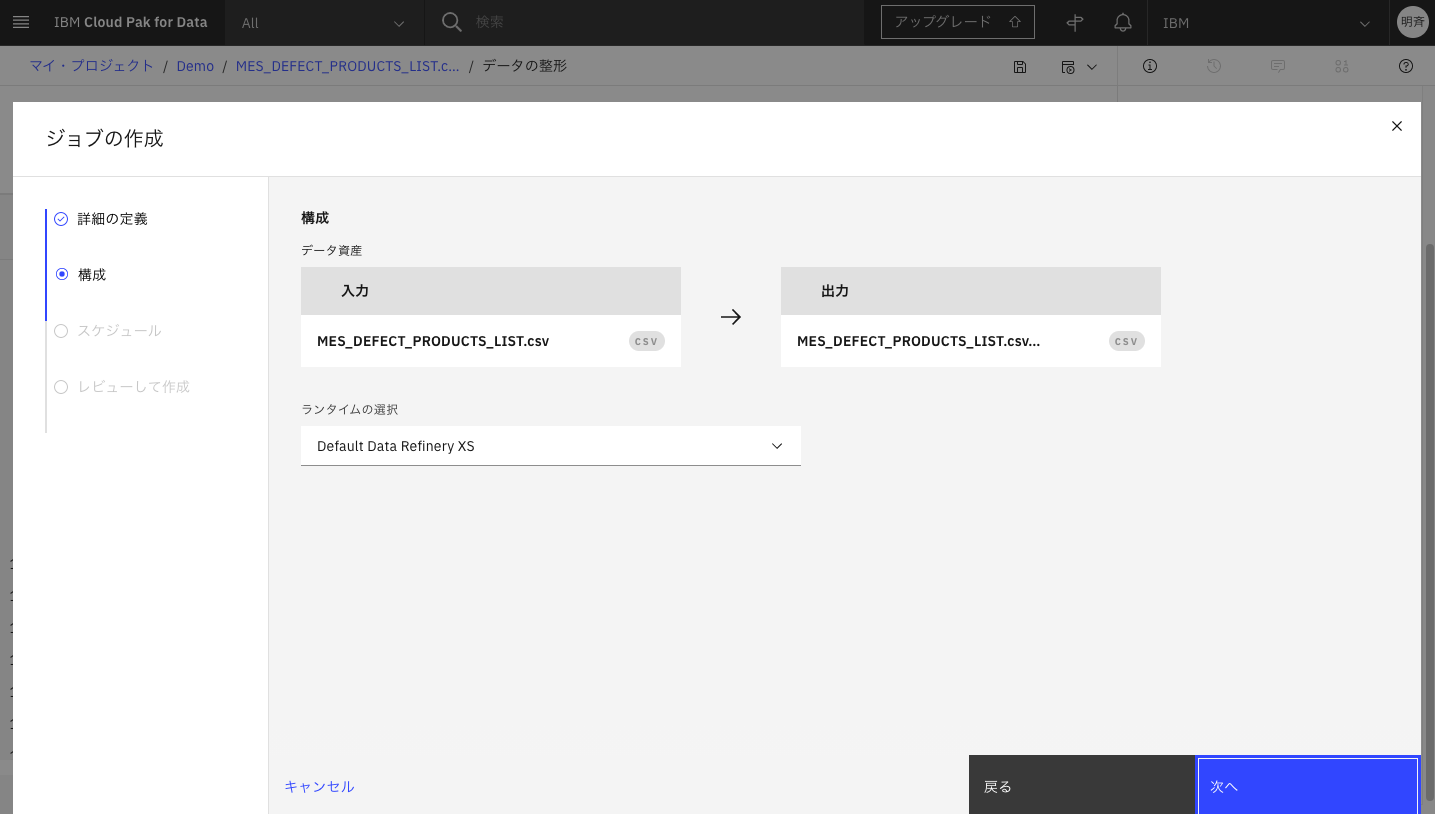
3-6. スケジュールは設定せず、「次へ」をクリックします。
3-7. 作成して実行をクリックします。
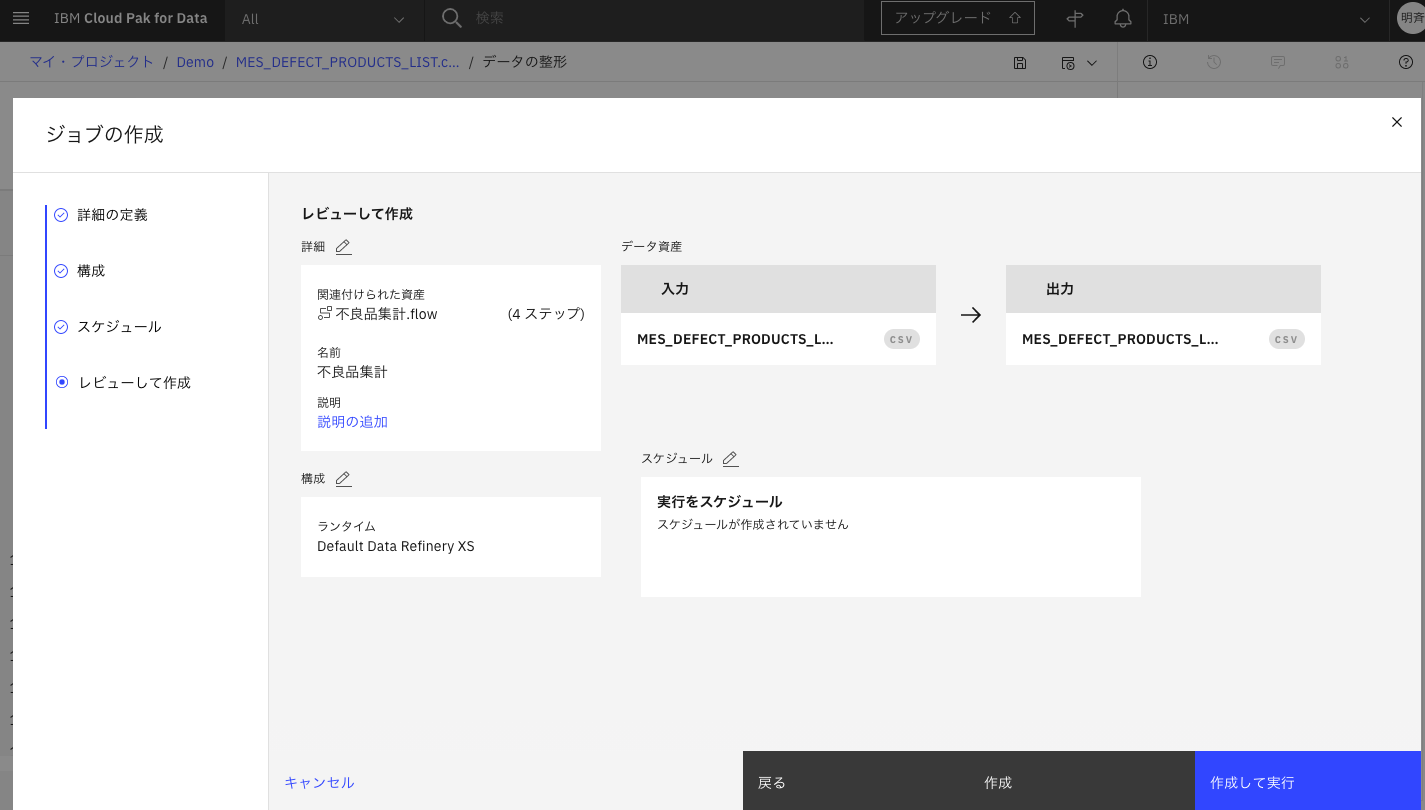
3-8. ジョブが終了するまで、しばし待ちます。
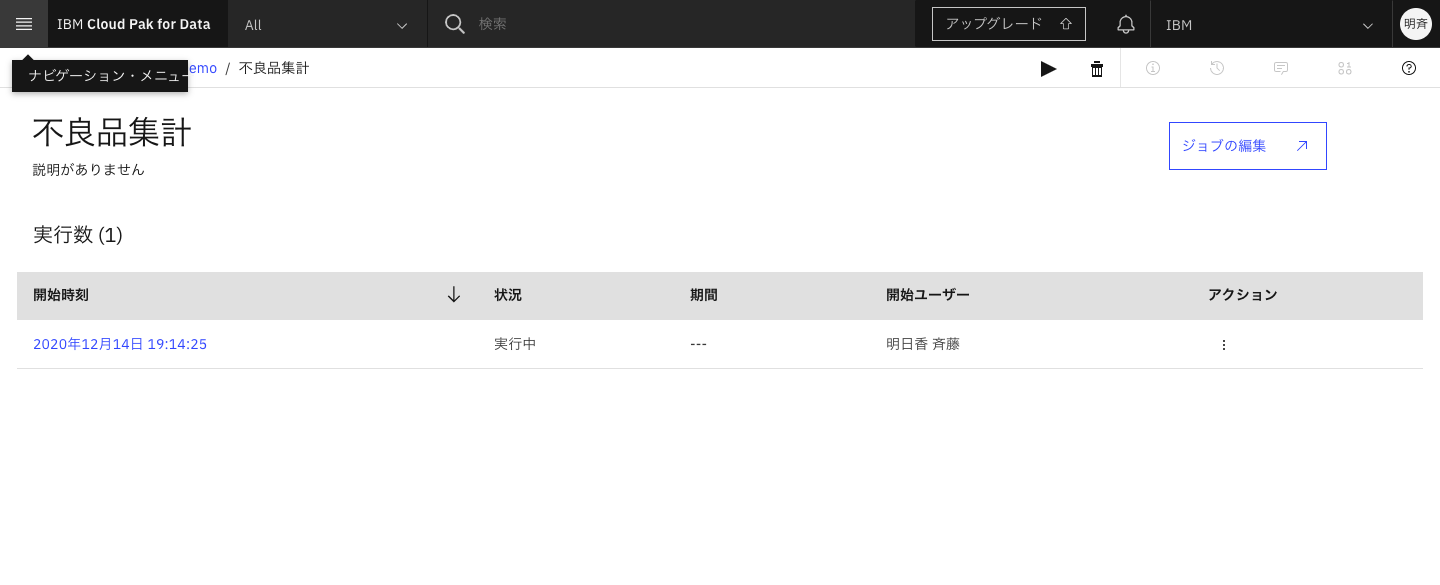
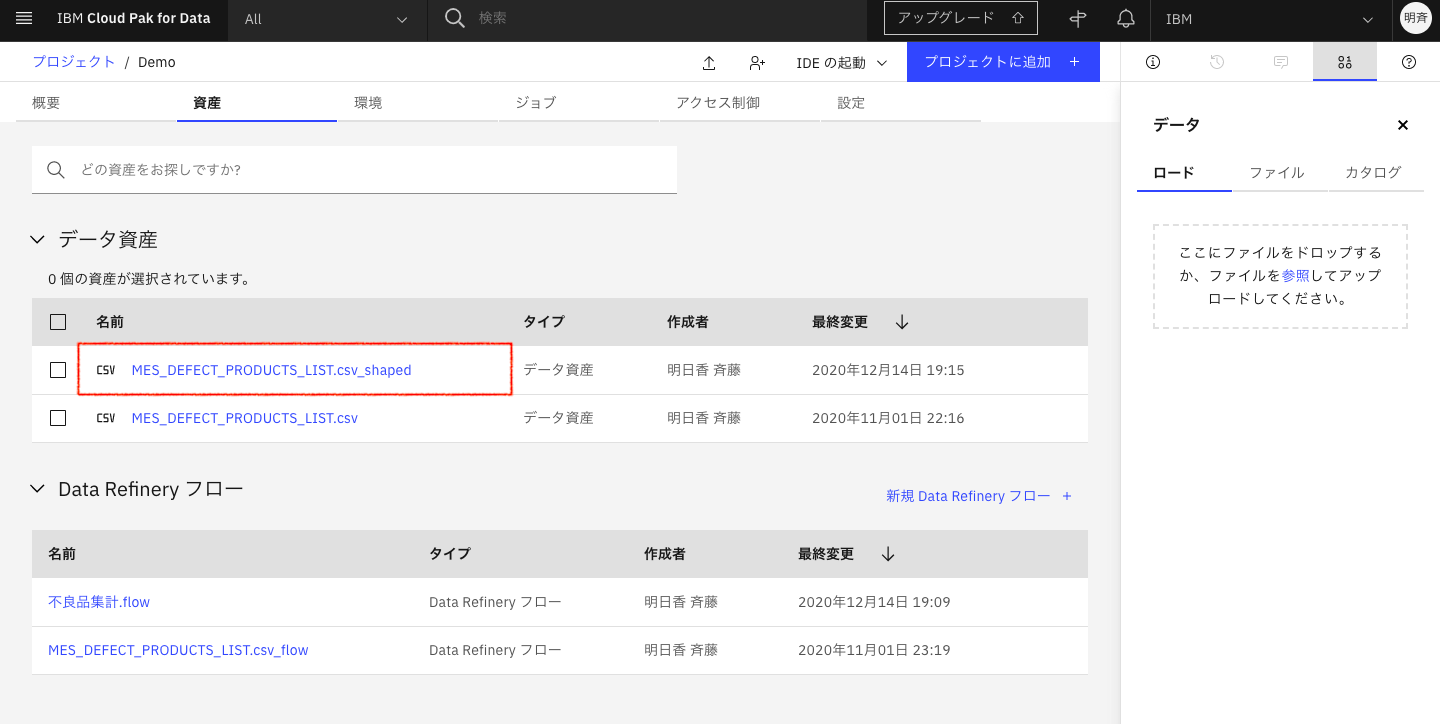
3-9. ジョブが完了したら、左上のリンクからプロジェクト名をクリックし、「資産」タブに戻り、ジョブで生成したcsvファイルが保存されていることを確認します。クリックして中身を見てみます。
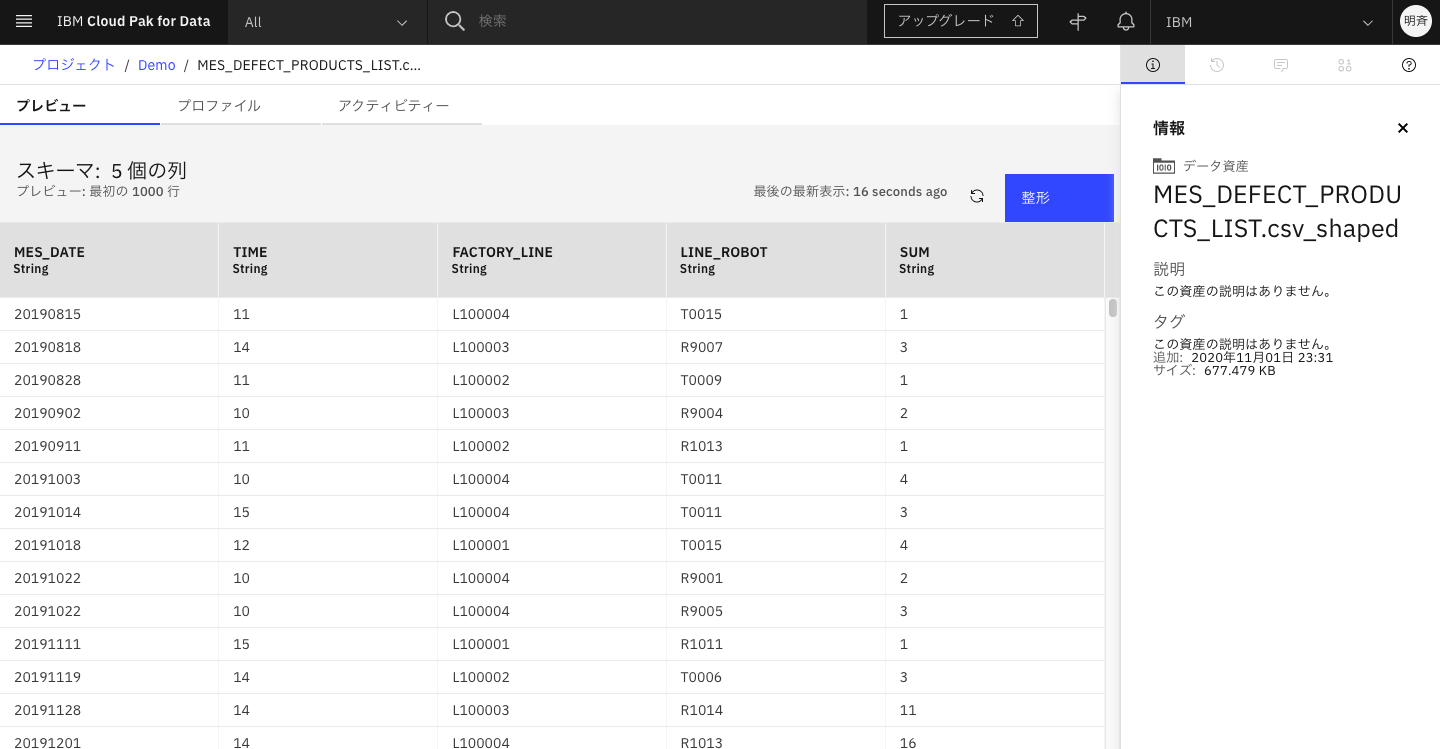
次回は今回精製したcsvファイルを使って、AutoAIで自動で不良品数の予測モデルを作成したいと思います。IBM Cloud Pak for Data as a Serviceを始めてみる(5.モデルの自動作成)(近日公開)をご参照ください。