IBM Cloud Pak for Data の XaaS 版 as a Service の始め方をまとめました。
この記事は主に、データ利用者側の操作を説明しています。
データ分析をしたい!と思い立った時に、セルフサービスで、データの分析環境をWebに立ち上げて、前処理やノンコーディングで機械学習モデルを作成するなどが可能です。クイックにデータを活用できるので、データの利用を促進していくことができます。
IBM Cloud Pak for Data as a Serviceを始めてみる(3.分析環境編)
目次
- はじめに
- 分析環境(Watson Studio)に作業スペース(分析プロジェクト)を追加する
- 分析プロジェクト解説
- csvファイルをアップロードする
- Data Refinery を使ってデータの前処理をする
シリーズ目次
-管理者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(1.プロビジョニング編)
-全員
IBM Cloud Pak for Data as a Serviceを始めてみる(2.ログイン編)
-データ利用者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(3.分析環境編)
IBM Cloud Pak for Data as a Serviceを始めてみる(4.データの前処理編)
IBM Cloud Pak for Data as a Serviceを始めてみる(5.モデルの自動作成)
IBM Cloud Pak for Data as a Serviceを始めてみる(6.モデルのデプロイと呼び出し)
[IBM Cloud Pak for Data as a Serviceを始めてみる(7.ダッシュボードの作成)]
(https://qiita.com/Asuka_Saito/items/79a3b9cd7f65b45d04a3)
-データ提供者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(8.カタログの作成)
IBM Cloud Pak for Data as a Serviceを始めてみる(9.ビジネス用語の作成)
IBM Cloud Pak for Data as a Serviceを始めてみる(10.メタデータのインポート)
IBM Cloud Pak for Data as a Serviceを始めてみる(11.ビジネス用語の割り当て)
-データ利用者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(12.カタログ検索してデータを見つける)
-管理者向け
IBM Cloud Pak for Data as a Serviceを始めてみる(13.Db2のサービスを追加する)
-その他参考
IBM Cloud Pak for Data as a Serviceを始めてみる(14.GoSalesのデータを使う)
IBM Cloud Pak for Data as a Serviceを始めてみる(15.コールセンターのデータセットを使う)
IBM Cloud Pak for Data as a Serviceを始めてみる(16.Modelerフローのサンプルを使ってみる - 薬剤研究例 )
IBM Cloud Pak for Data as a Serviceを始めてみる(17.Db2のサービスへの接続情報を追加する)
IBM Cloud Pak for Data as a Serviceを始めてみる(18.機能改善やアイディアを投稿する)
IBM Cloud Pak for Data as a Serviceを始めてみる(19.Modelerフローで不良品件数予測モデルを開発する )
IBM Cloud Pak for Data as a Serviceを始めてみる(20.無償プランの枠を使い切った場合)
1. はじめに
この記事はIBM Cloud Pak for Data as a Service の分析環境であるWatson Studioを使って、csvファイルの前処理をするところまでを説明したいと思います。
2. 分析環境(Watson Studio)に作業スペース(分析プロジェクト)を追加する
2-1. IBM Cloud Pak for Data as a Serviceにログインし、TOPページを表示します。

2-2. 左上のナビゲーション・メニューをクリックし、メニューを表示させます。「プロジェクト」>「すべてのプロジェクトの表示」をクリックします。
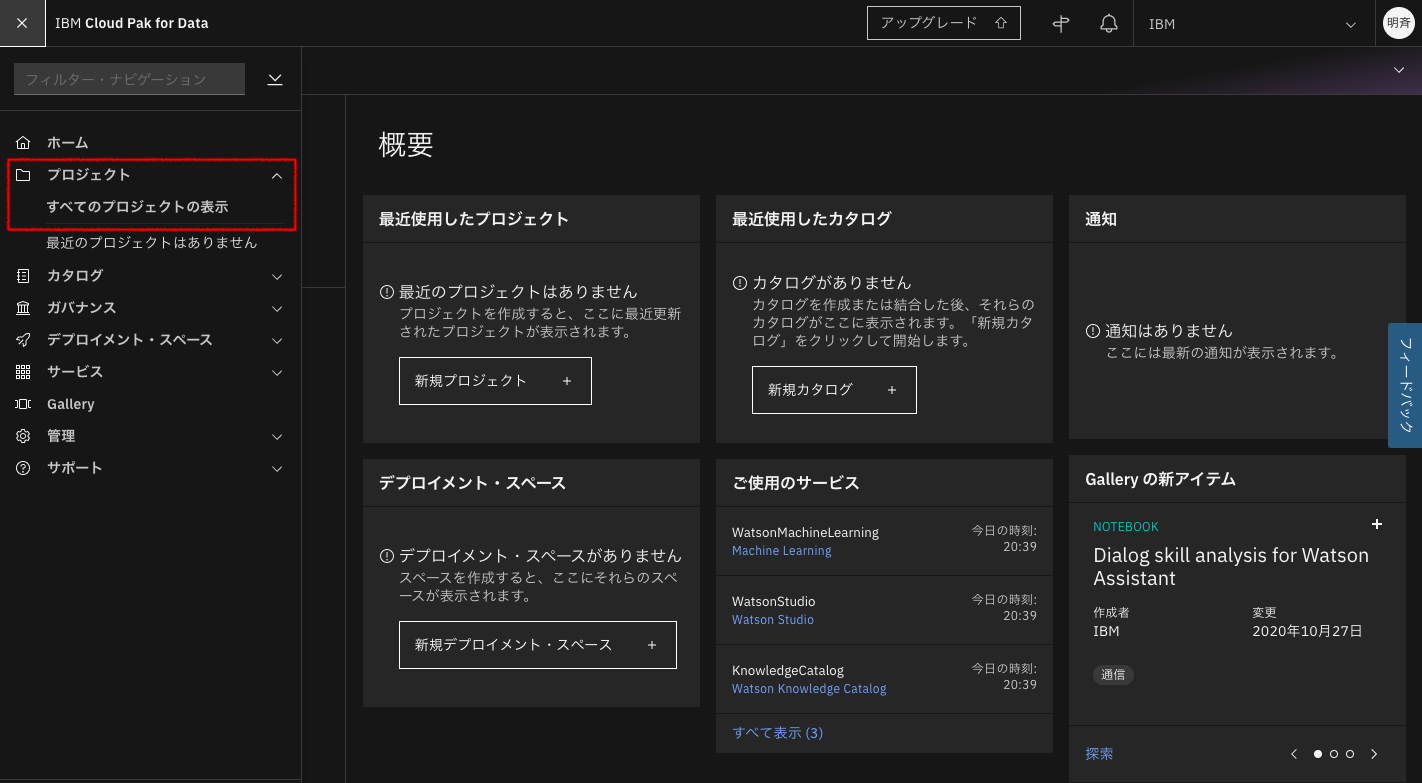
2-3. 「新規プロジェクト」をクリックします。
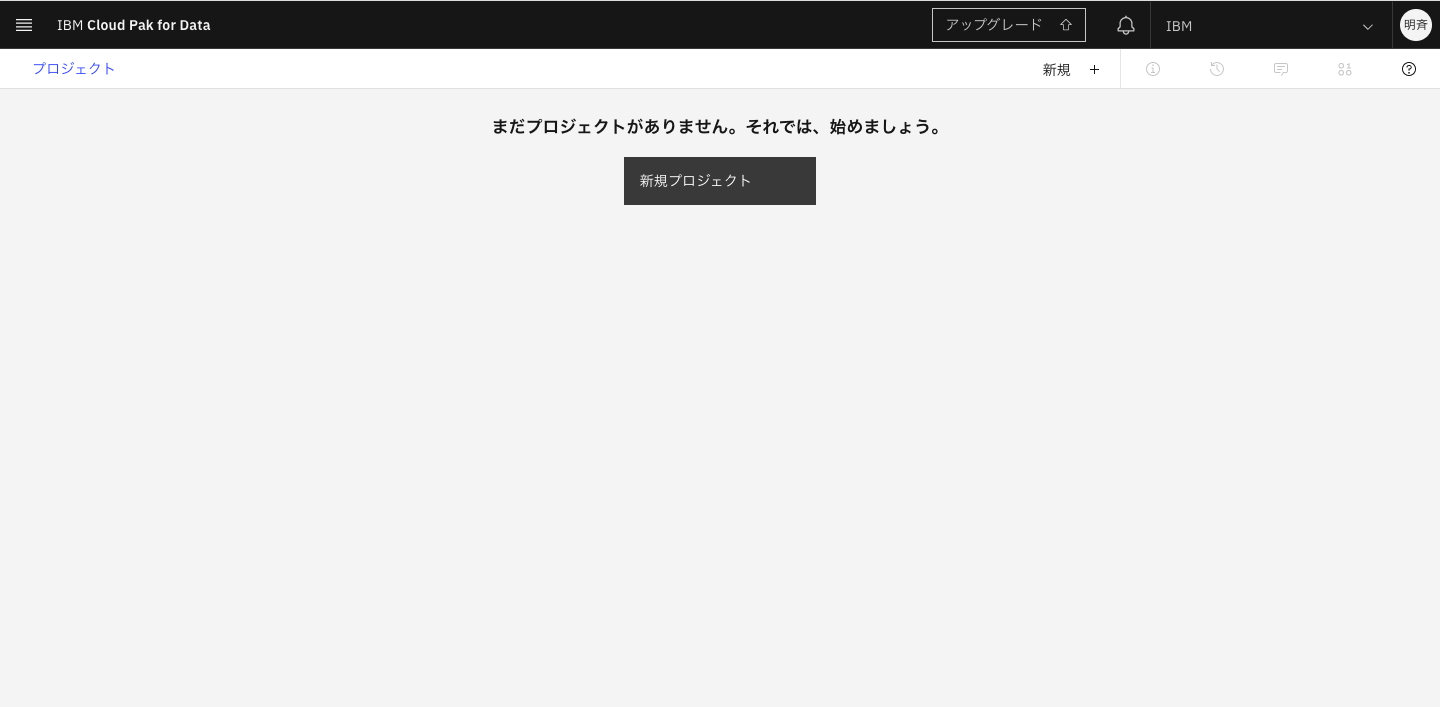
2-4. 「空のプロジェクトの作成」をクリックします。
2-5. プロジェクトの名前を入力し、右側のストレージの定義から「追加」をクリックします。
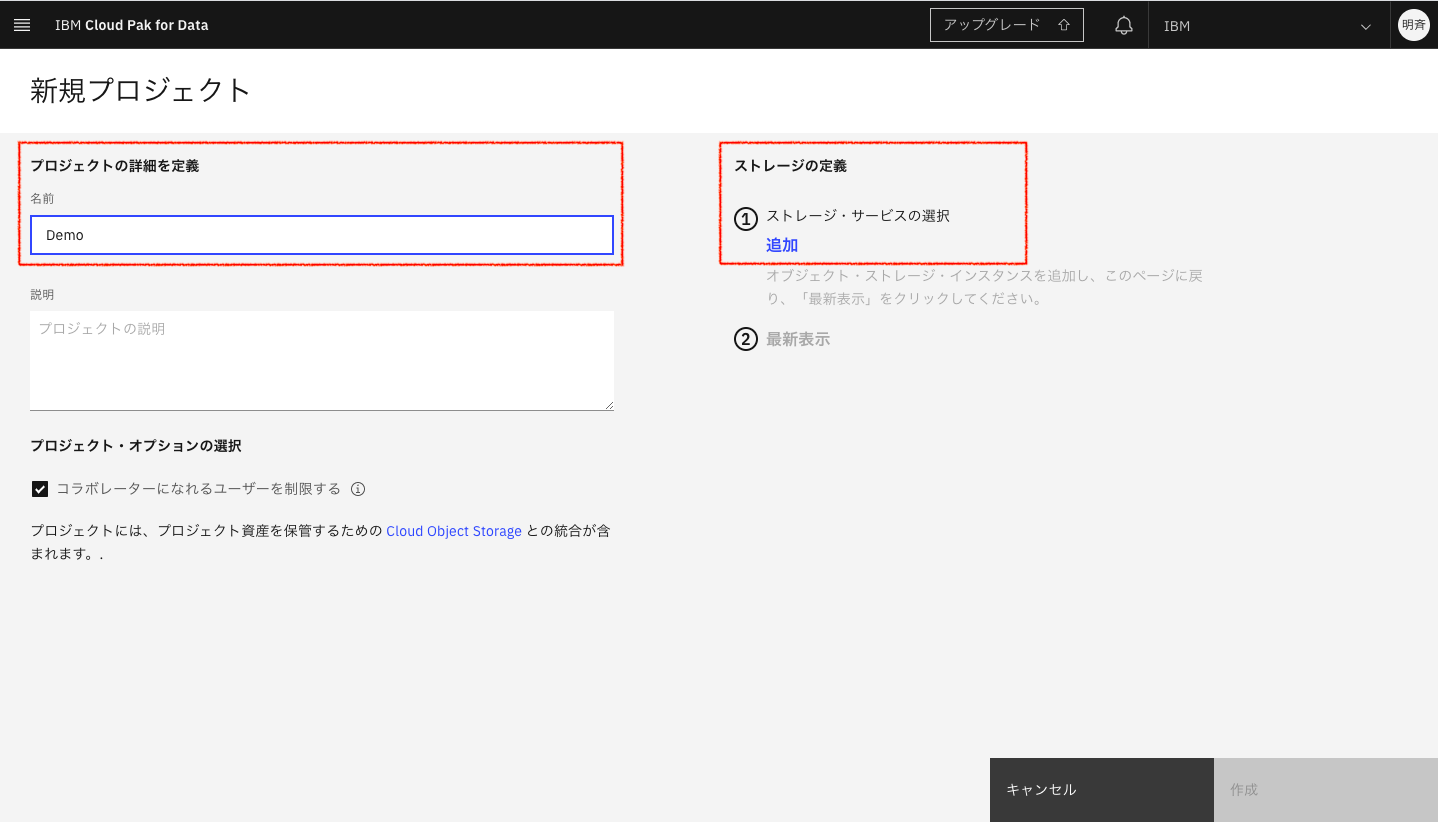
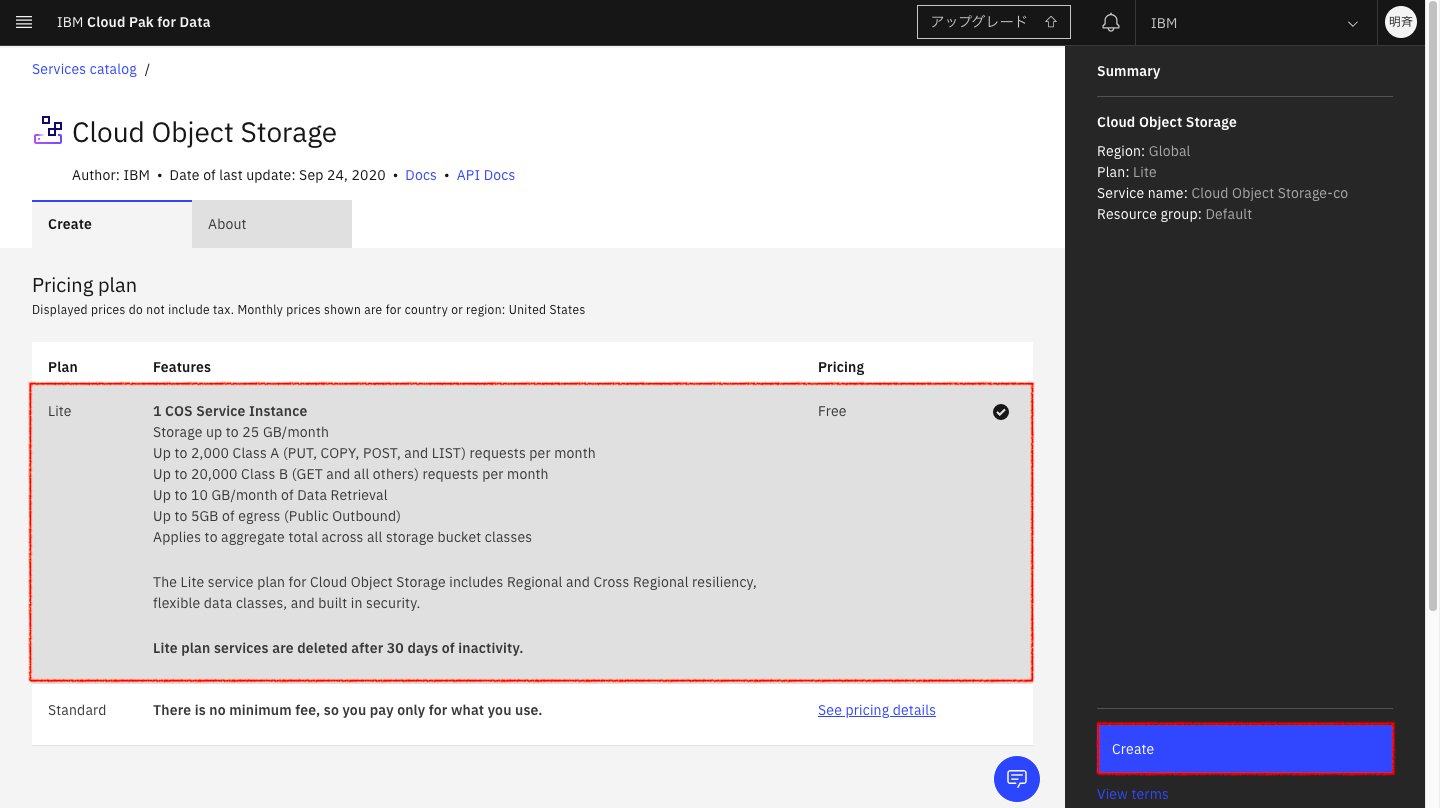
2-6. Cloud Object Storageを追加する画面になります。任意のプランを選択し「Create」をクリックします。
(このページは鋭意日本語翻訳中です。)
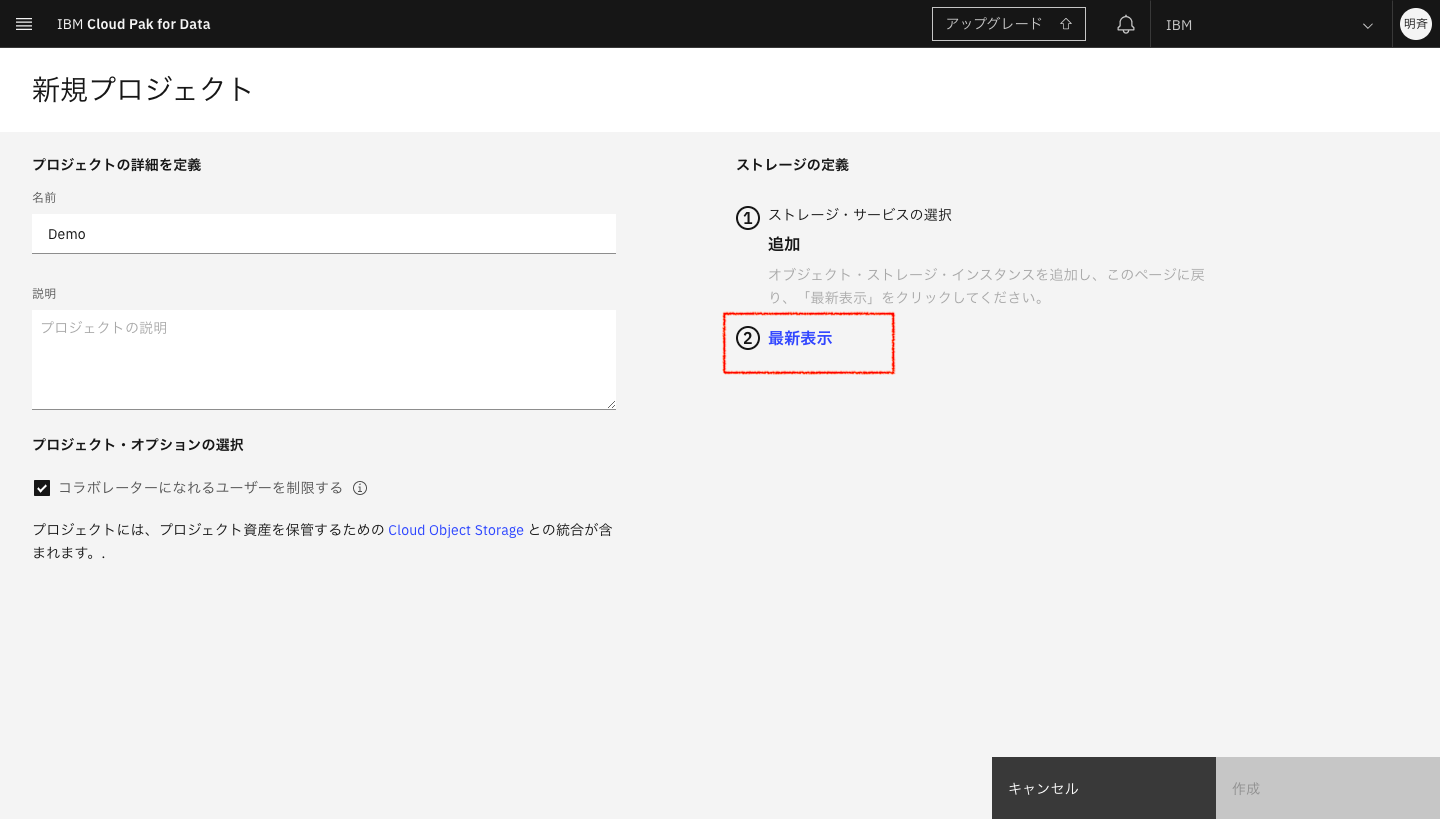
2-7. 「最新表示」をクリックします。
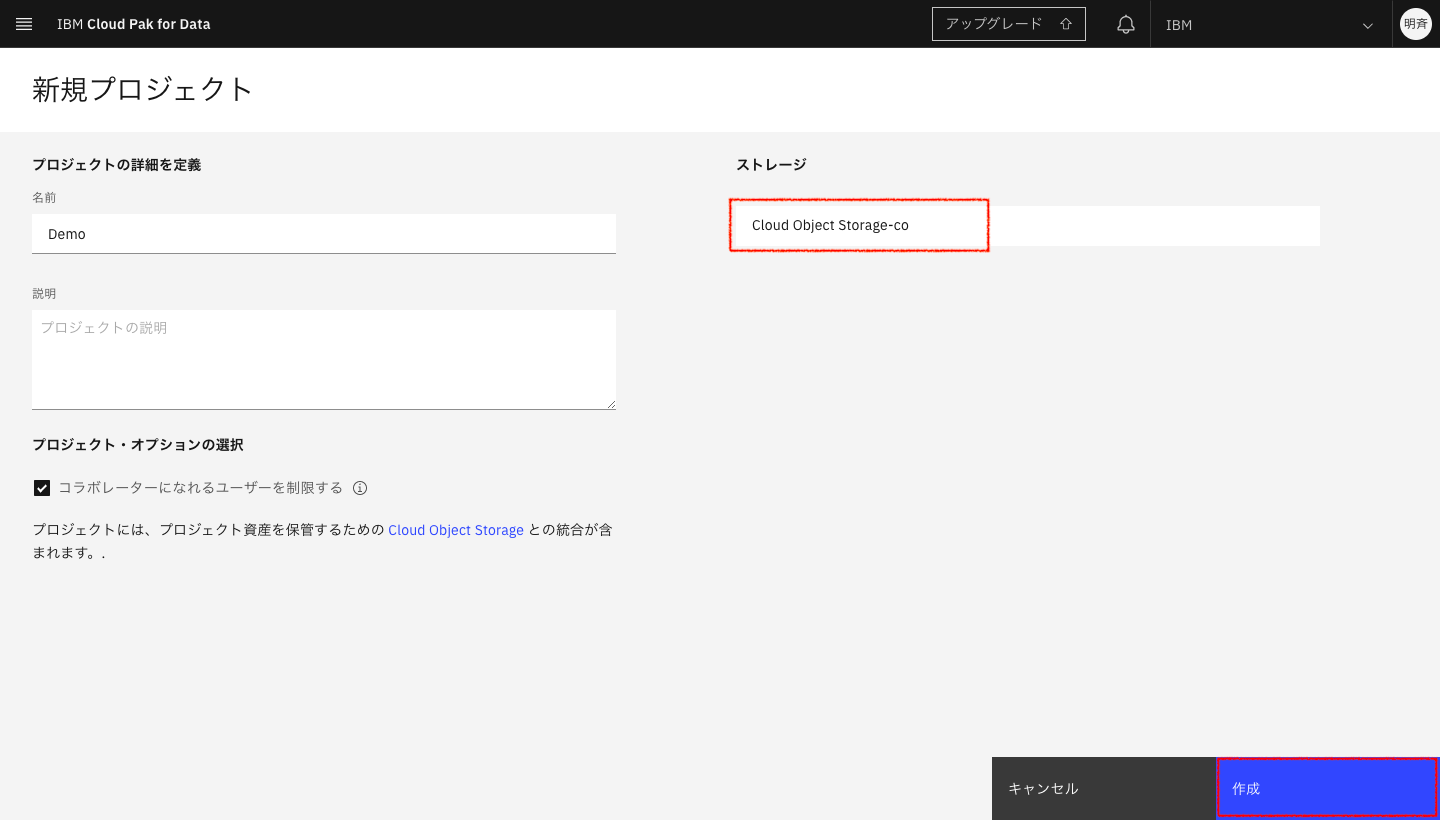
2-8. Cloud Pbject Storageが追加されたら、「作成」をクリックします。
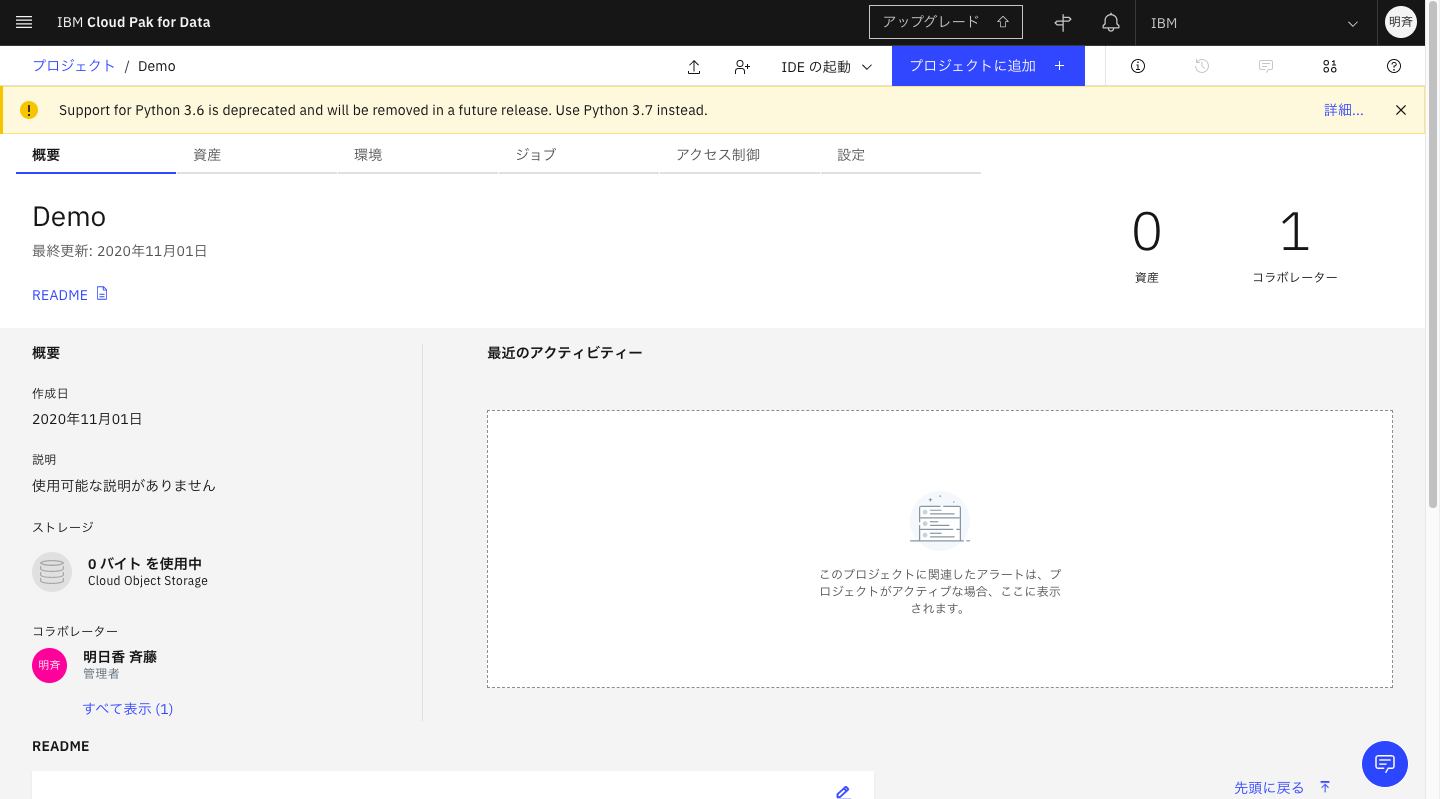
2-9. 分析環境(Watson Studio)に分析用のスペースが作成できました。
3. 分析プロジェクトの中身解説
3-1. 「資産」タブ
分析プロジェクトに追加したcsvファイルやデータベースへのConnectionなどが表示されます。「プロジェクトに追加」をクリックしてNotebookやSPSS Modelerなども追加することができます。
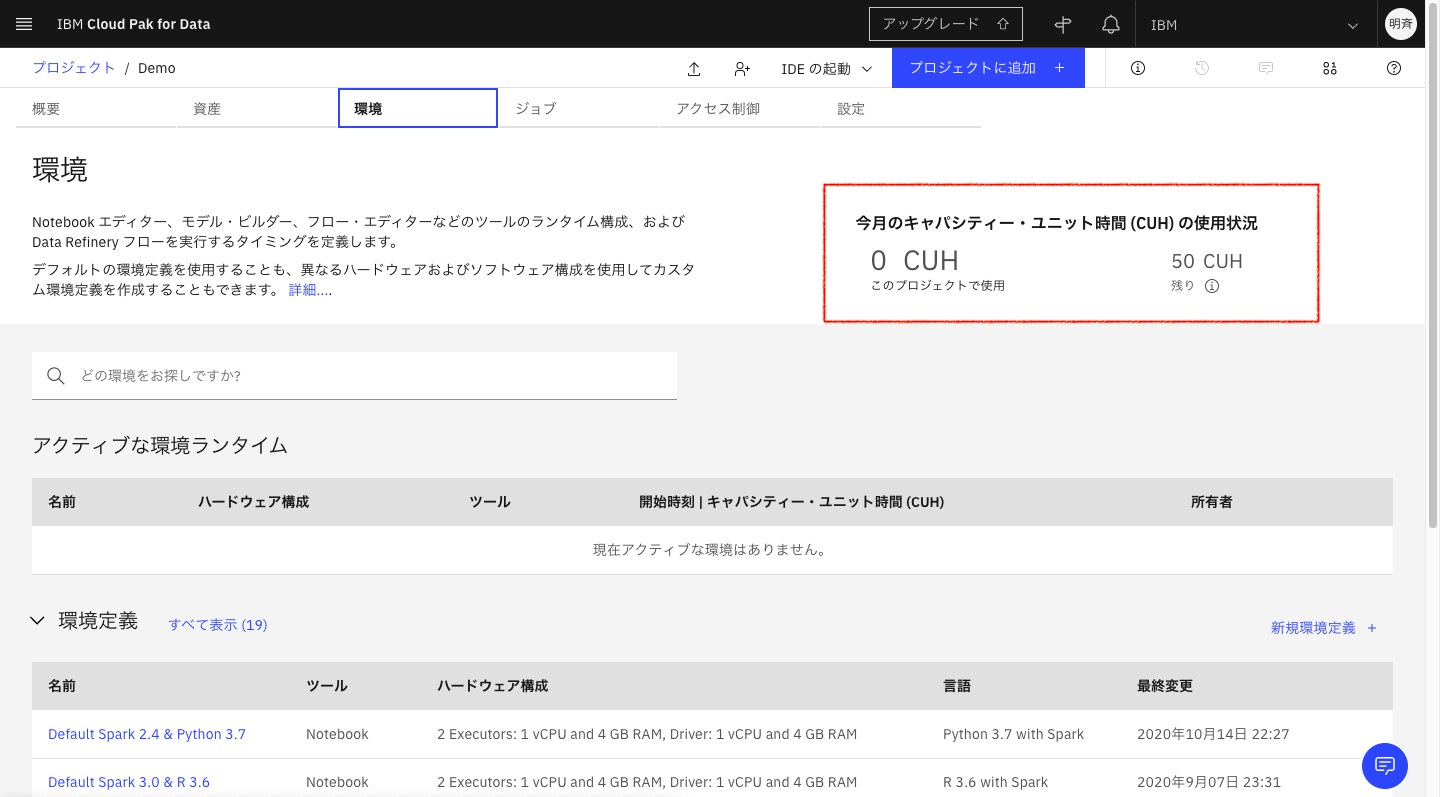
3-2. 「環境」タブ
「今月のキャパシティー・ユニット時間 (CUH) の使用状況」で使用状況を確認できます。契約しているプランによって月当たりの使用できるCHUが異なります。
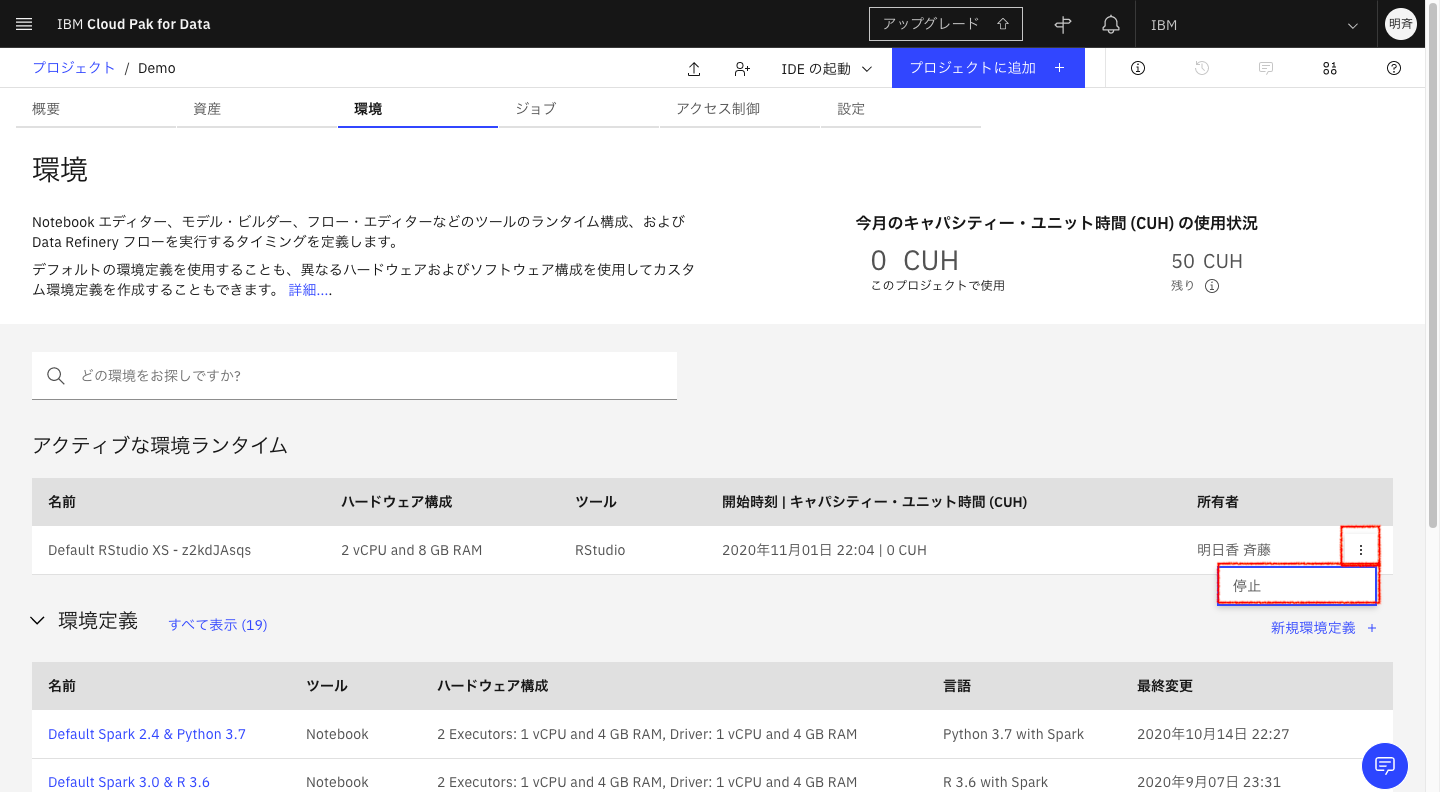
ランタイムを明示的に停止するには、「アクティブな環境ランタイム」からランタイムを選択して「停止」します。
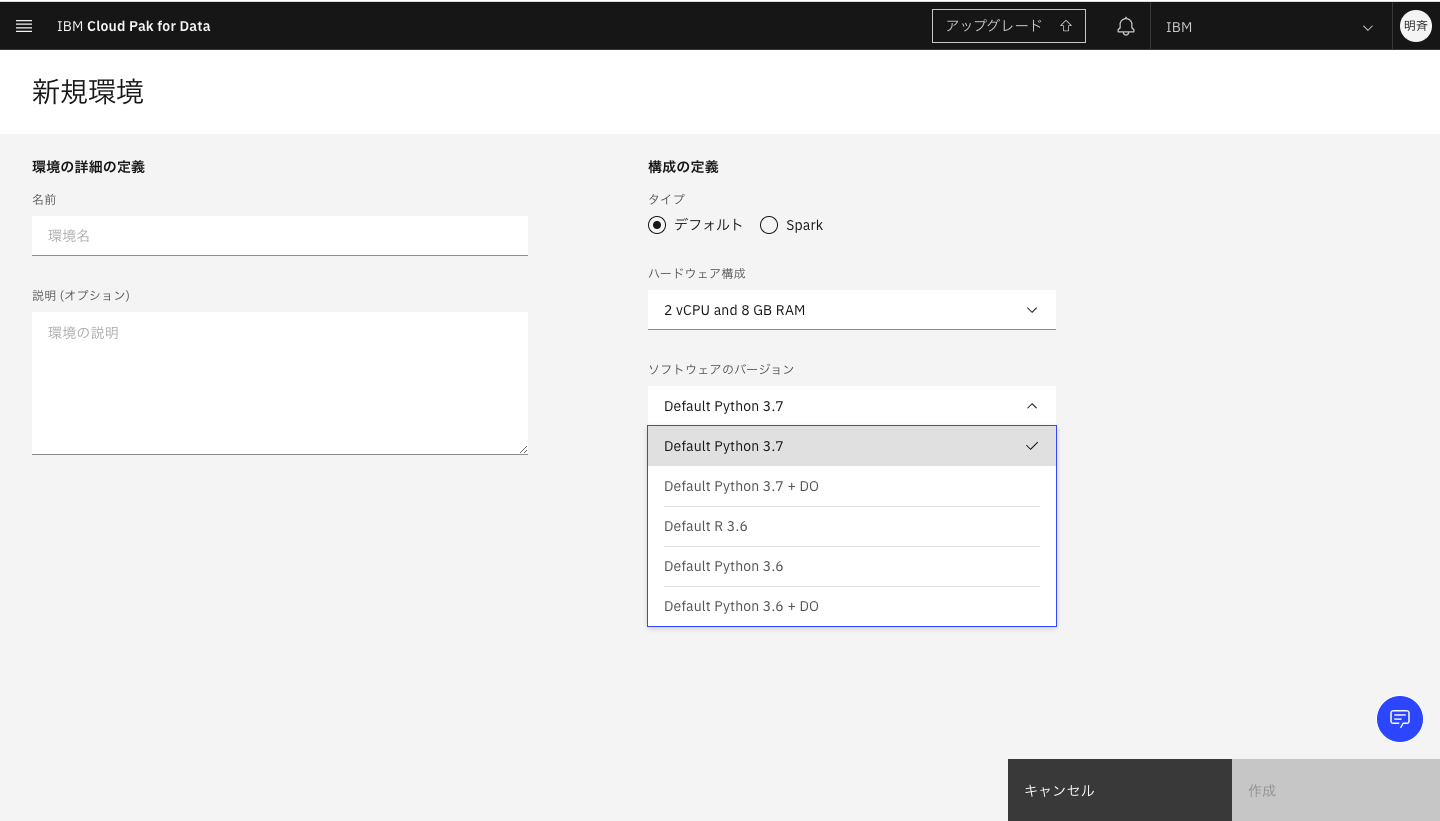
また、実行するランタイムやCPU、メモリのセットをカスタマイズして追加が可能です。「環境定義」から「新規環境定義」をクリックし、表示される設定画面で、実行環境のランタイムやCPU等を指定します。
3-3. 「ジョブ」タブ
NotebookやAutoAI、Data Refineryといったツールはジョブを実行してデータを生成します。ジョブを実行した場合このタブに表示されます。
3-4. 「アクセス制御」
分析プロジェクトはチームで作業できるように設計されています。コラボレーターを追加することで、分析プロジェクトそのものを共有して一緒に作業することが可能です。(契約しているプランがLiteの場合はできません。)
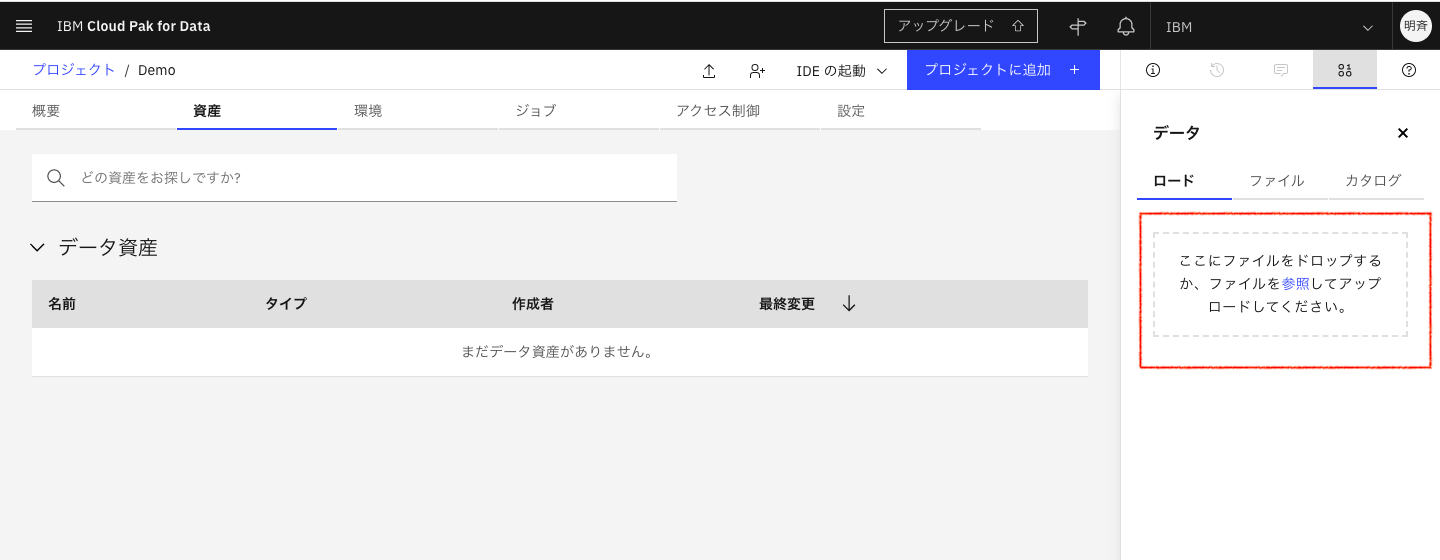
4. csvファイルをアップロードする
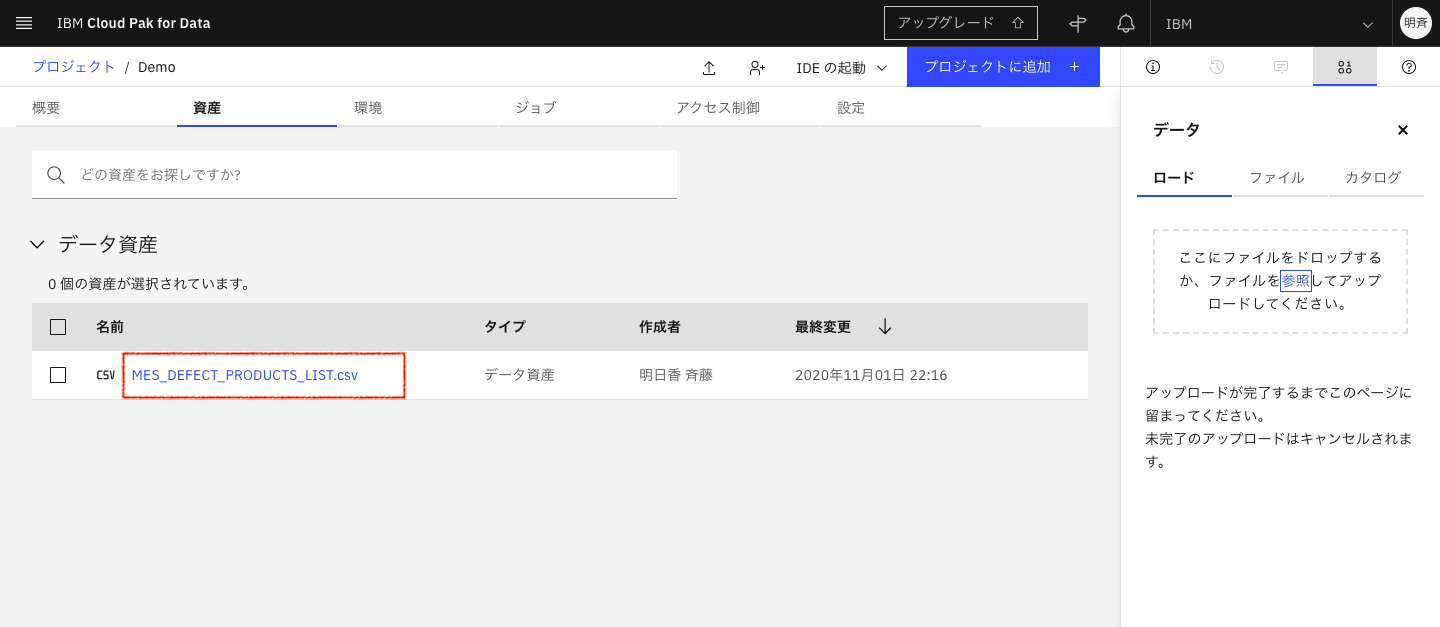
4-1. 「資産」タブに戻って、右側の「ロード」からローカルのPCにあるcsvファイルをアップロードします。
こちらの記事と同じcsvファイルをこちらのGithubからダウンロード可能です。
5. Data Refinery を使ってデータの前処理をする
Data Refinery を使うと、分析者自身がデータの前処理を簡単に行うことができます。
5-1. アップロードしたファイルのファイル名をクリックします。
5-2. ファイルの中身の最初の1000件が表示されます。
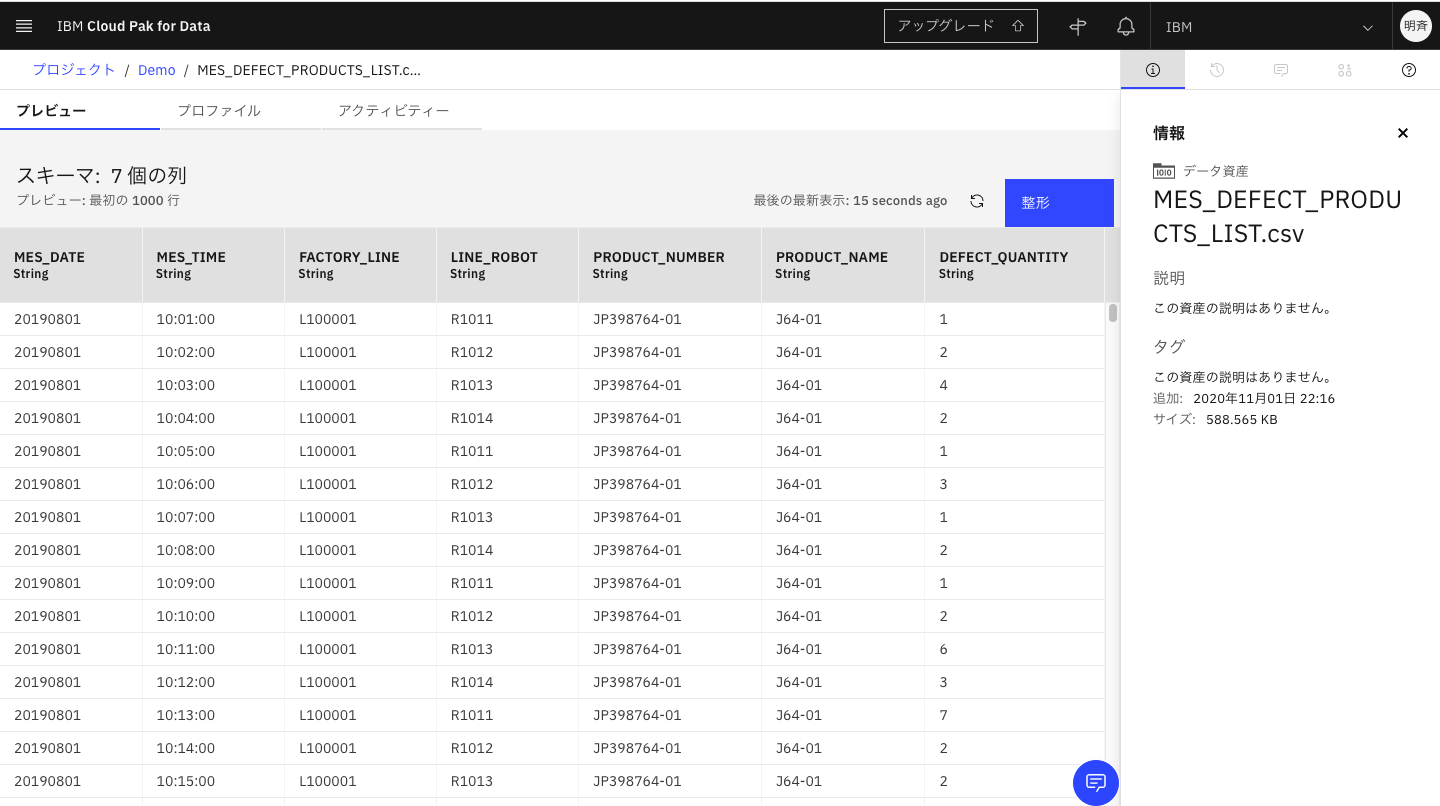
5-3. 「整形」をクリックします。データの整形ができるツール(Data Refinery)が起動します。
5-4. 「プロファイル」タブをクリックします。列に入っているデータの傾向が確認できます。DEFECT_QUANTITYには「欠陥」(NULL)が結構あることがわかります。

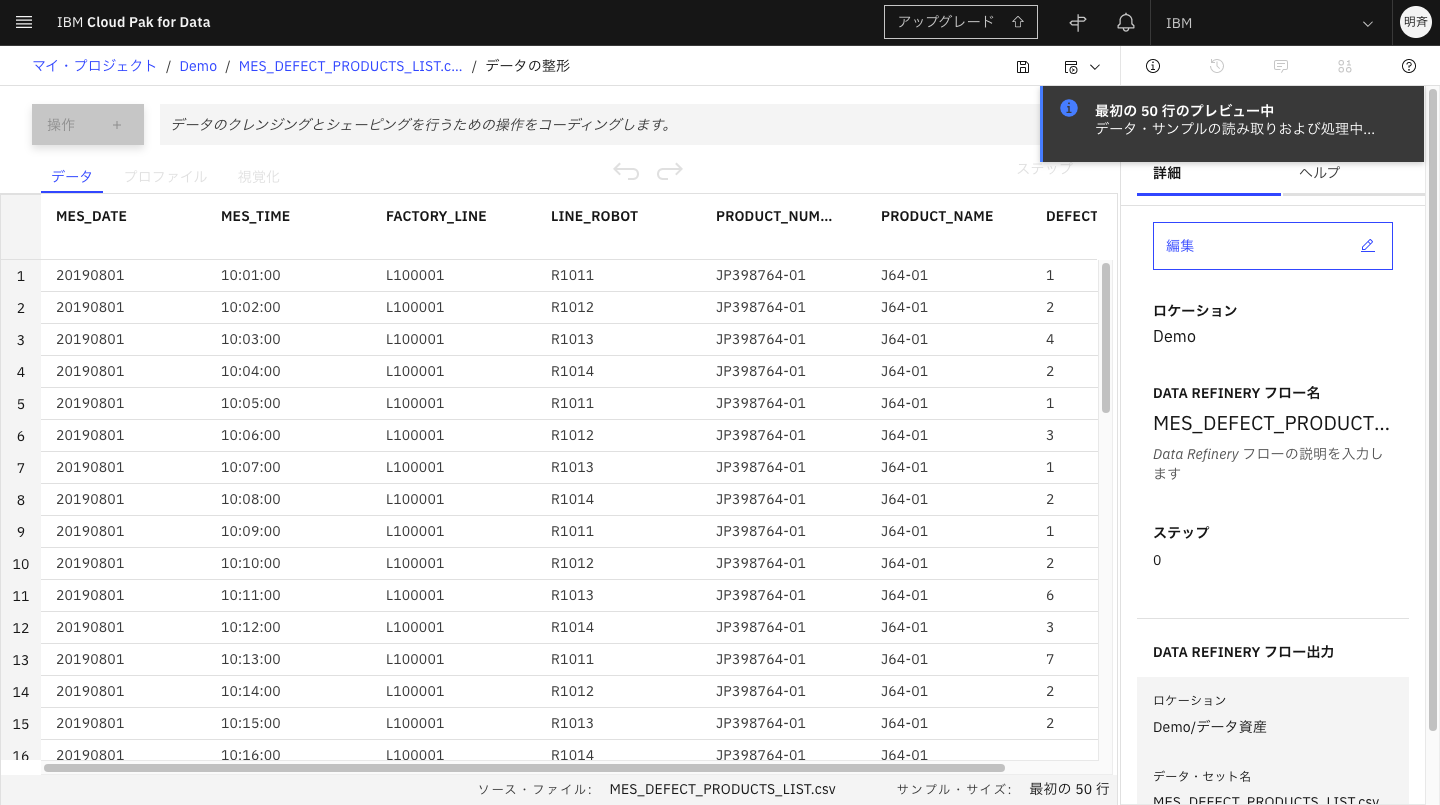
5-5. 「データ」タブに戻ります。先ほどのDEFECT_QUANTITYの「欠陥」(NULL)は分析の邪魔になるので除いておきたい場合、「空の行の削除」を実施します。この操作は、画面上は最初の10000件に適用されます。データ全件に適用し、ファイルやデータベースに出力するには、ジョブを実行します。
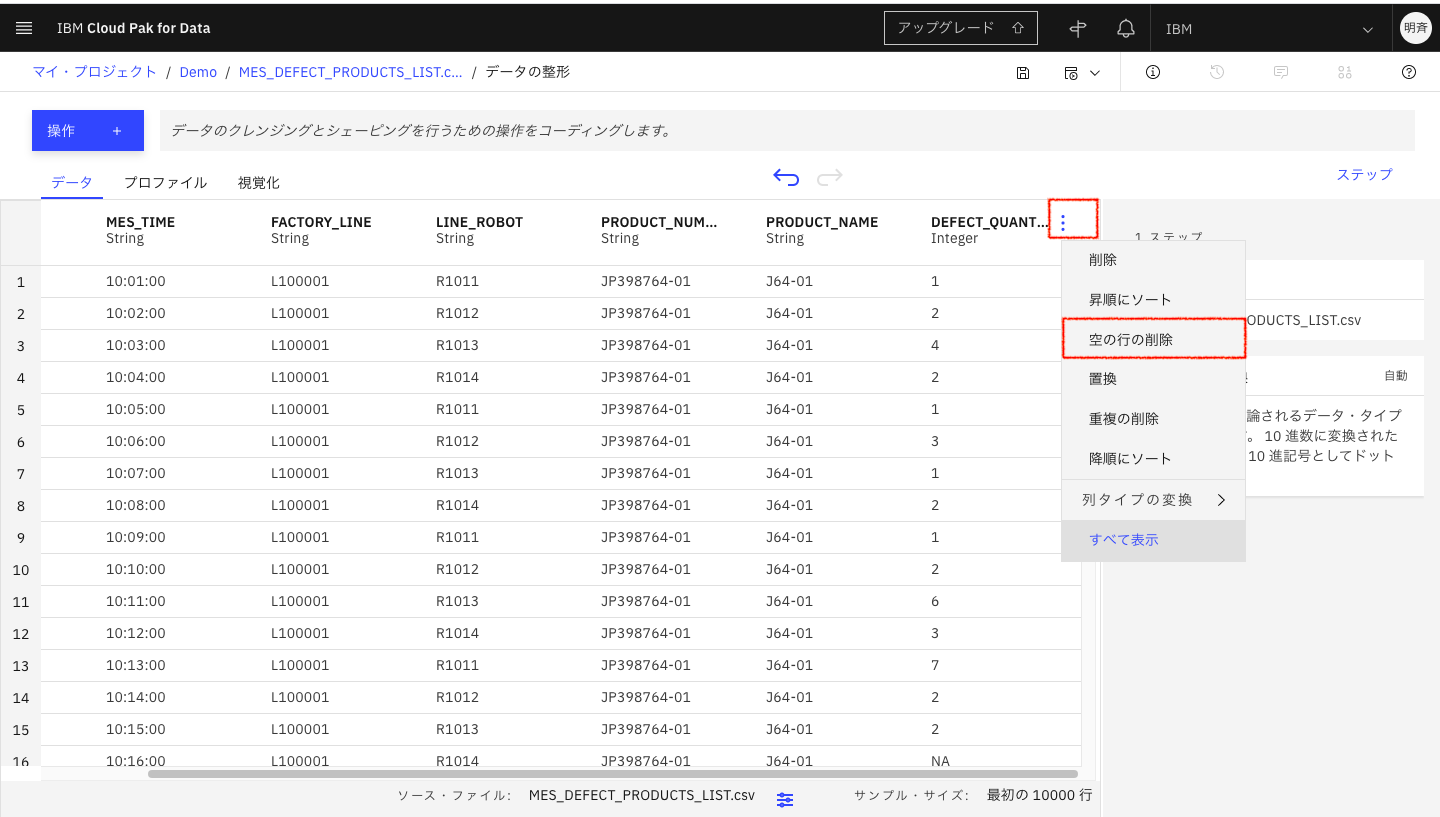
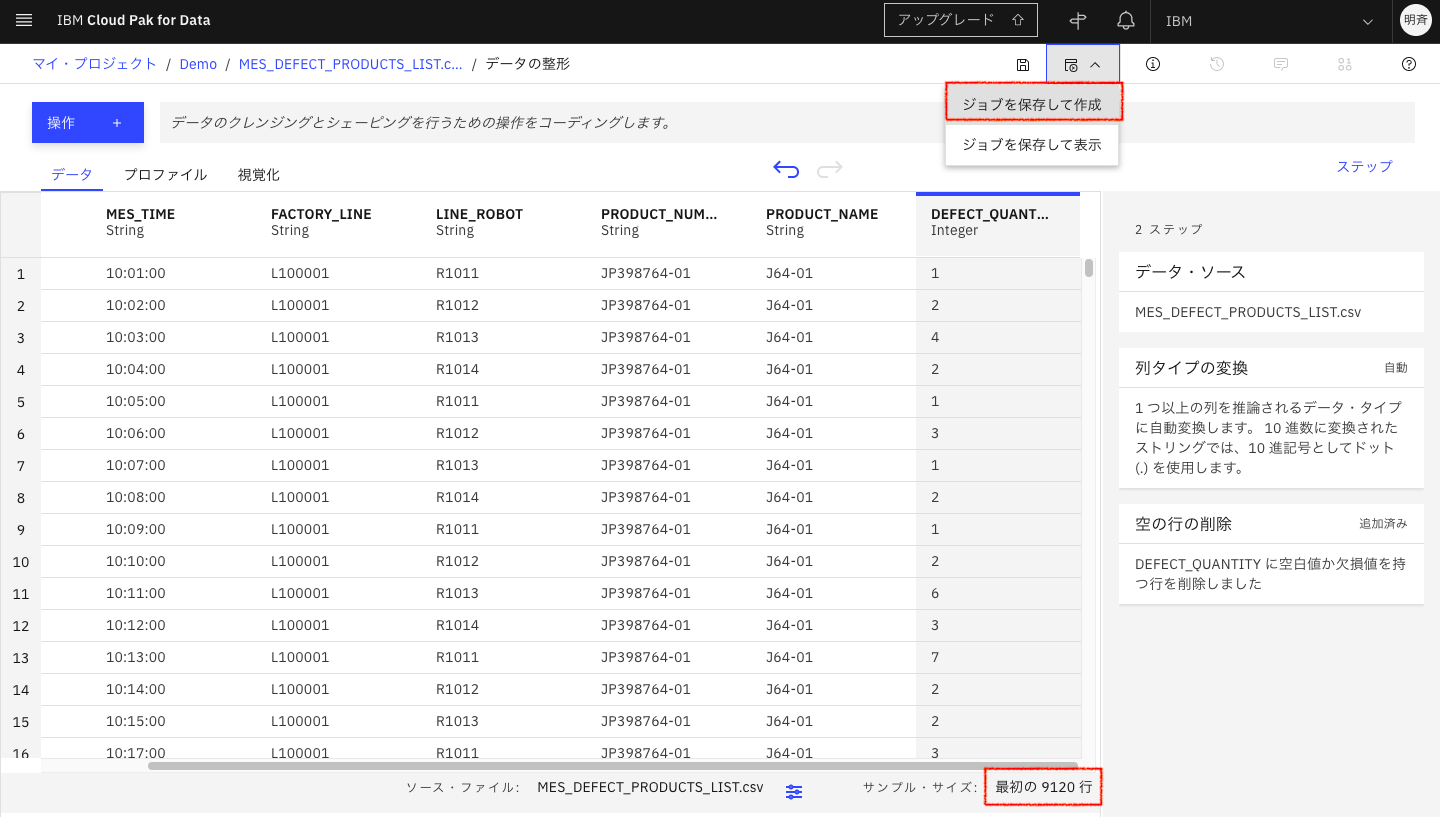
5-6. ジョブを実行するには、「ジョブを保存して作成」をクリックします。
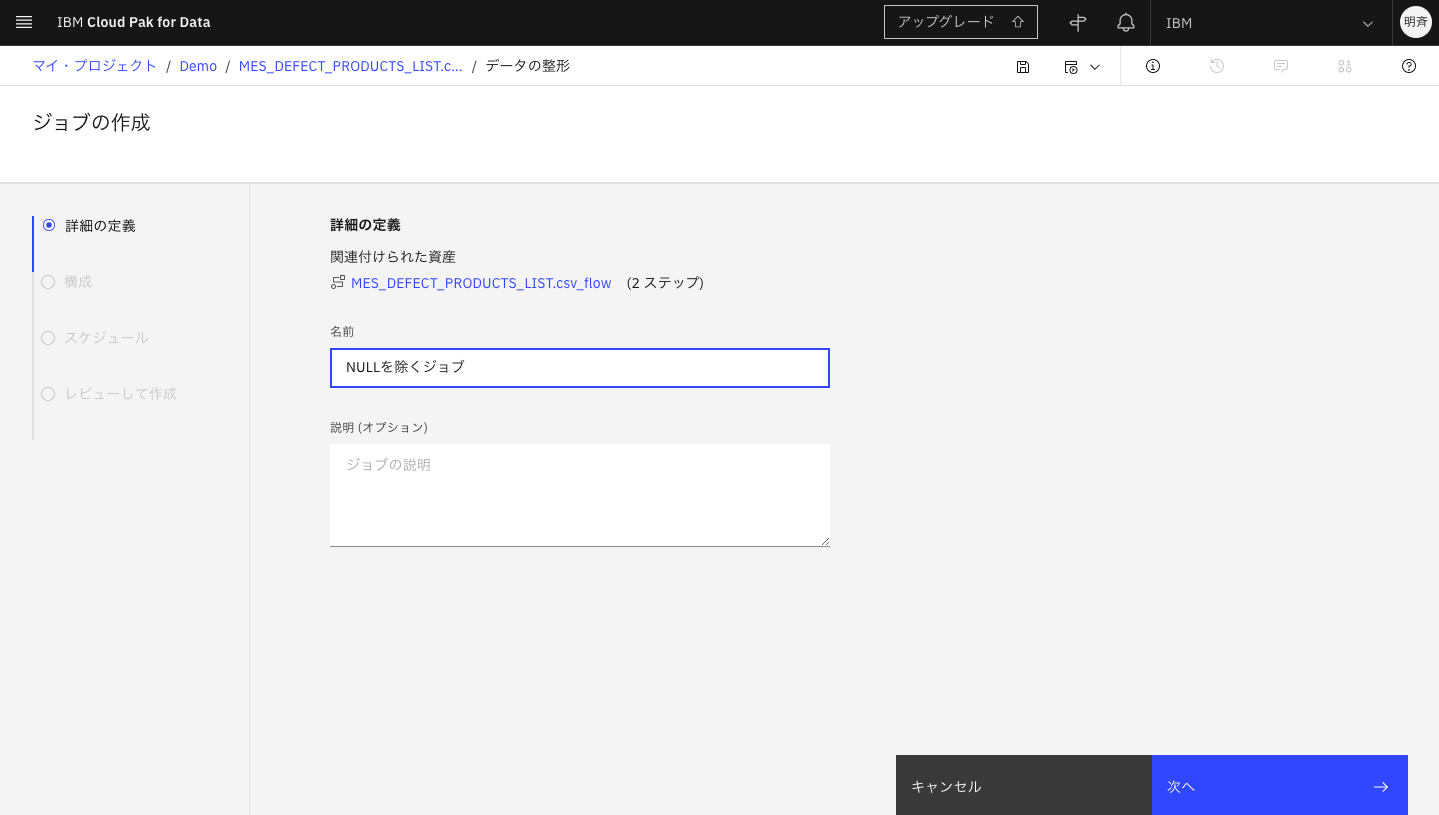
5-7. ジョブ名を入力して「次へ」をクリックします。
5-8. ランタイムを指定して「次へ」をクリックします。
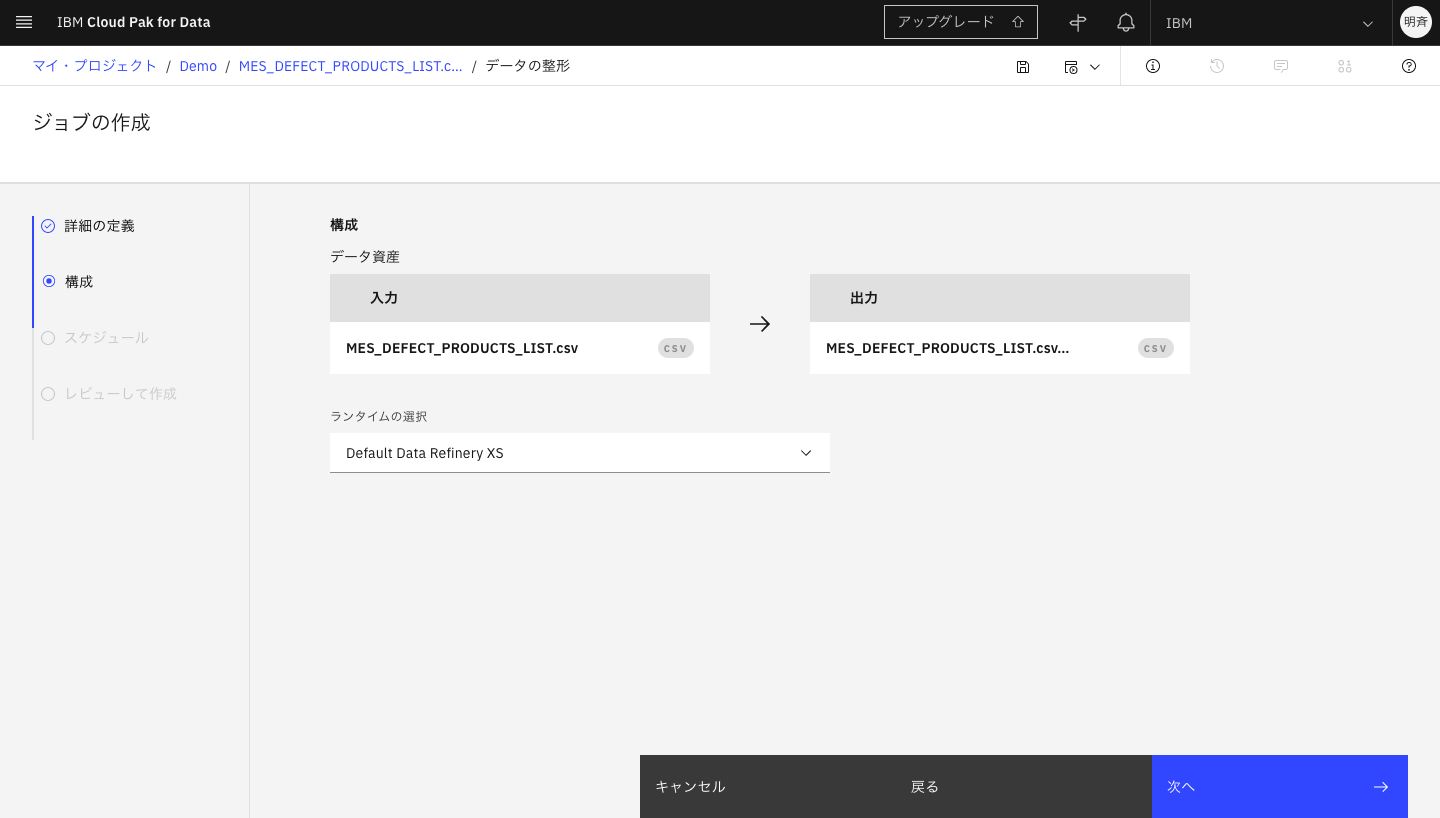
5-9. スケジュールを設定することも可能です。
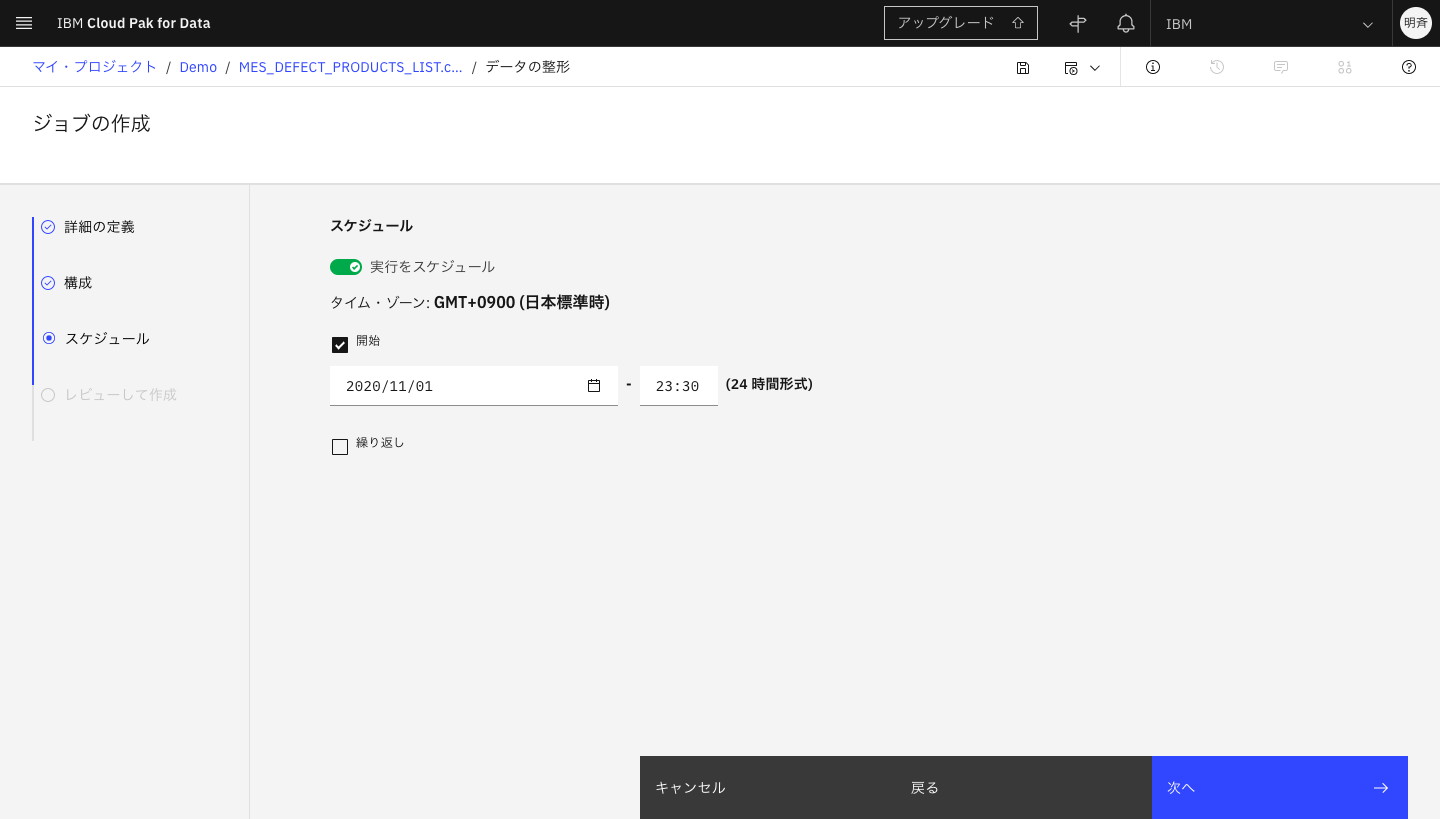
5-10. 最後に設定をレビューします。「作成」または「作成して実行」をクリックします。(スケジュール実行の場合は「作成」のみがクリックできます。)
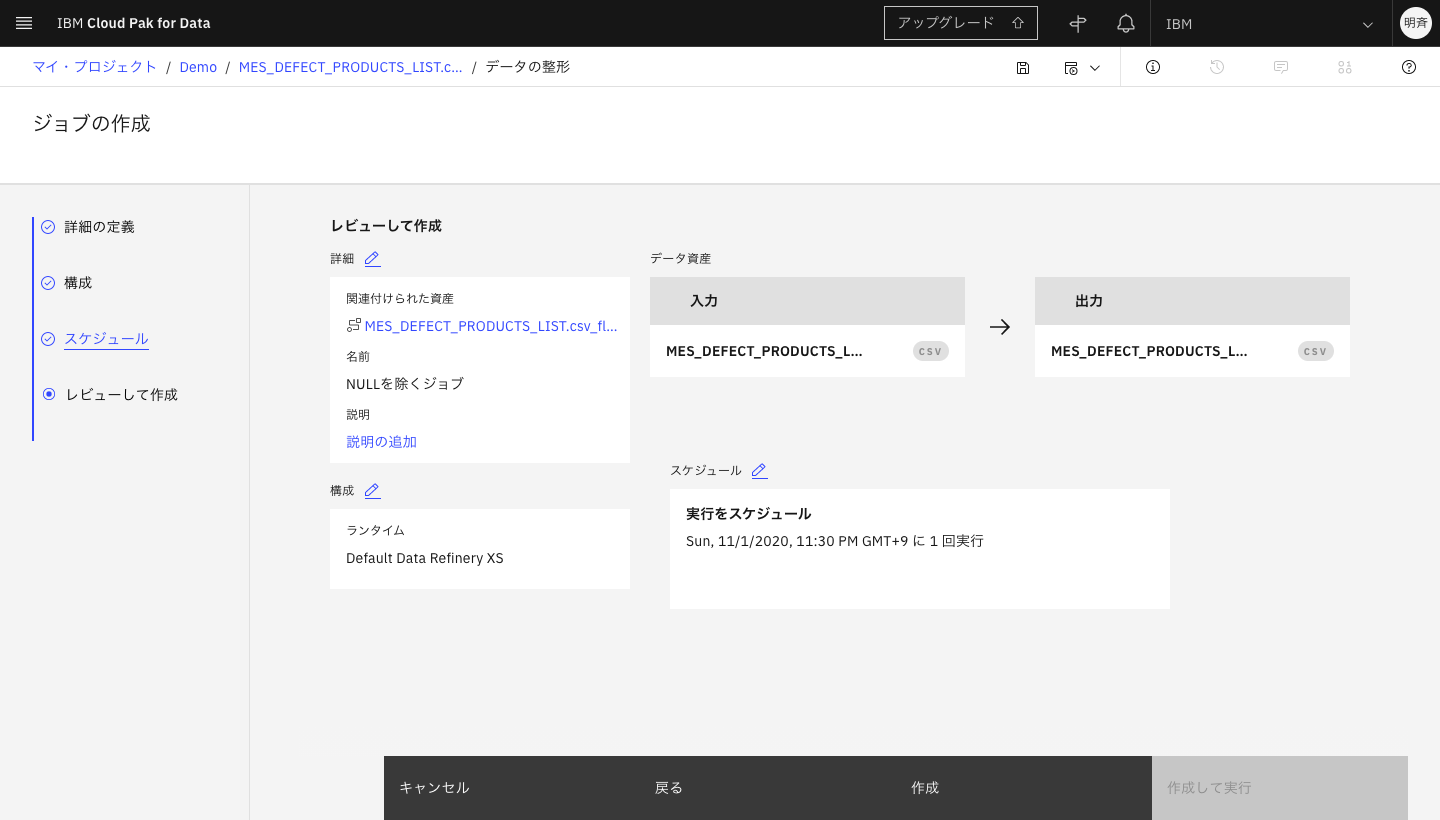
5-11. この記事では、スケジュール起動にしたので、今しばらく待ちます。
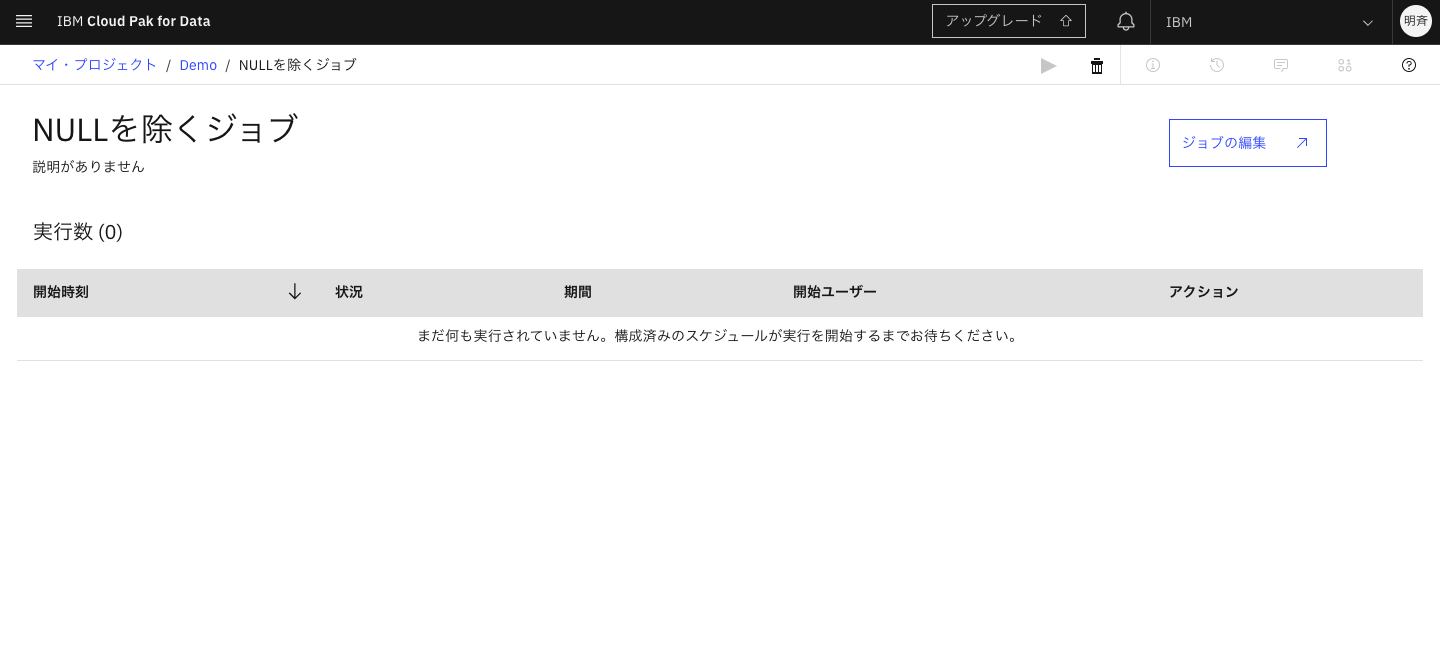
5-12. 時間になるとジョブが起動します。
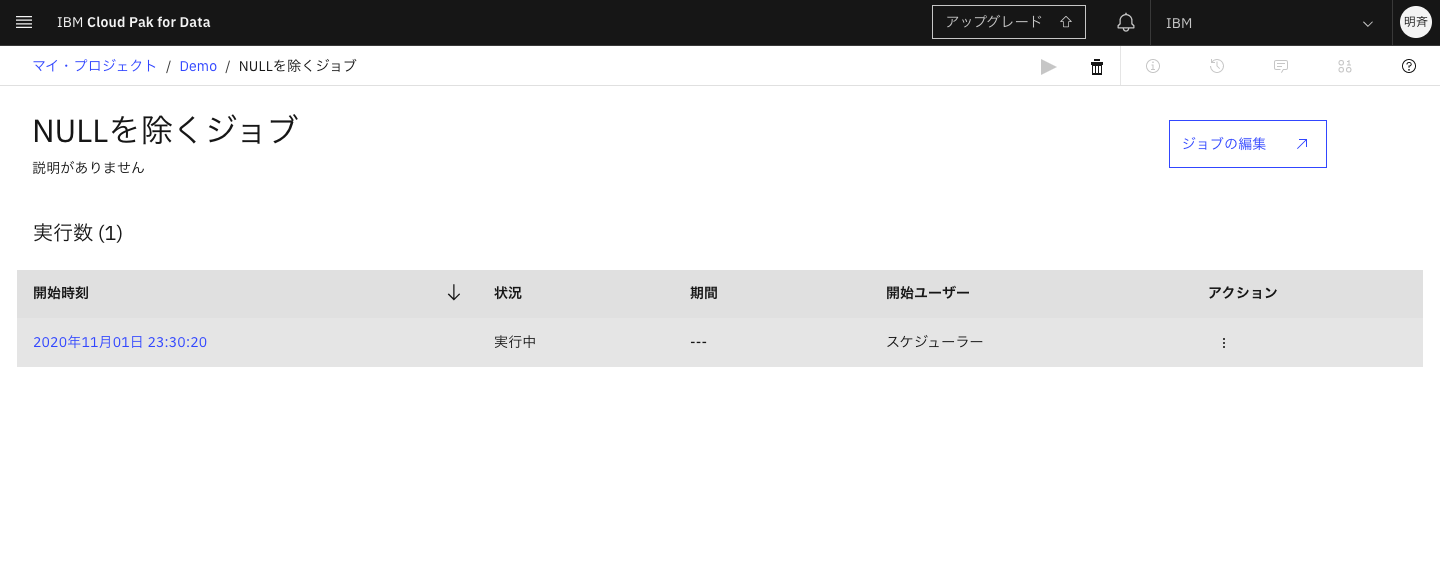
開始時刻をクリックするとログを確認できます。
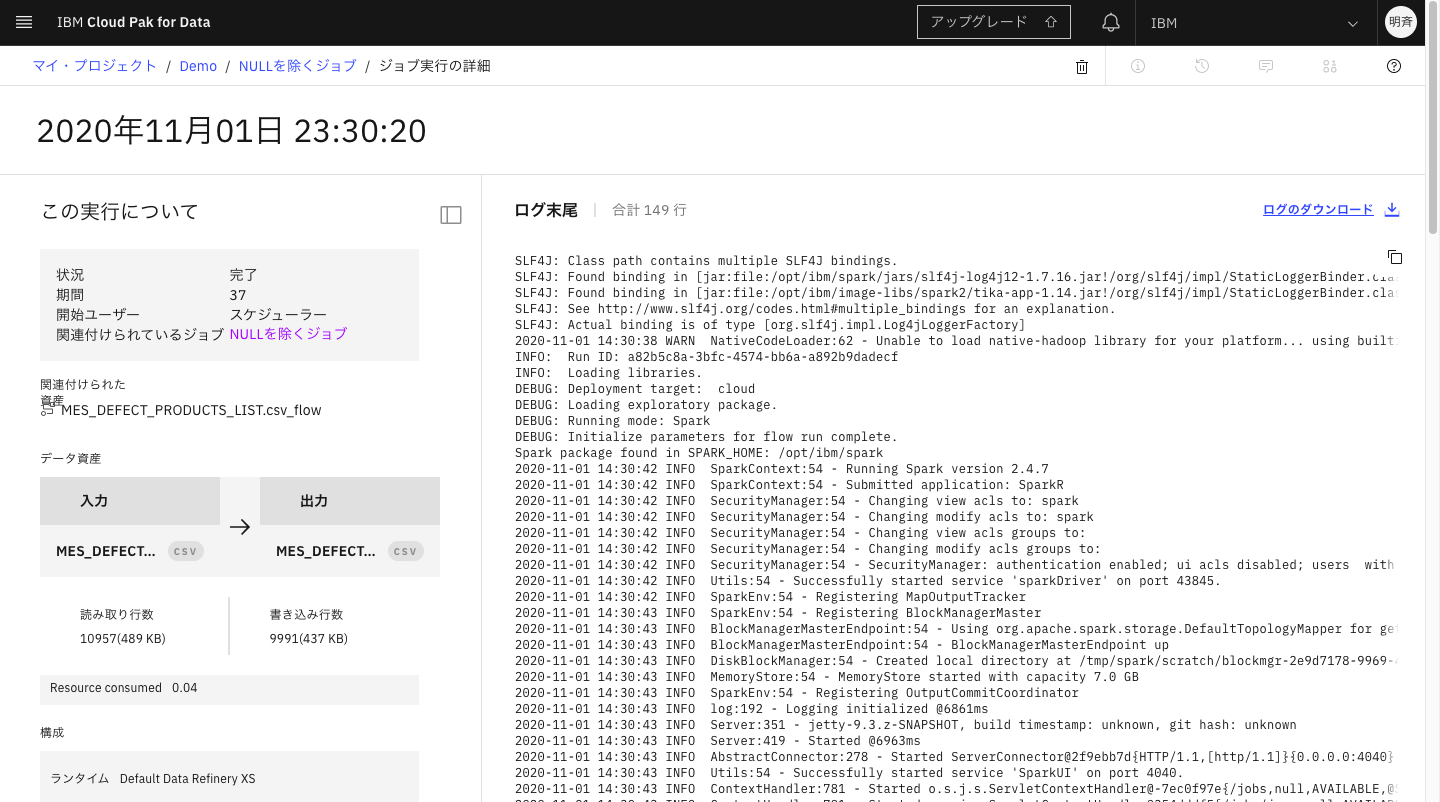
5-13. ジョブが完了したら、左上のリンクからプロジェクト名をクリックし、「資産」タブに戻り、ジョブで生成したscvファイルが保存されていることを確認します。このように、分析者自身がデータの前処理を簡単に行うことができます。
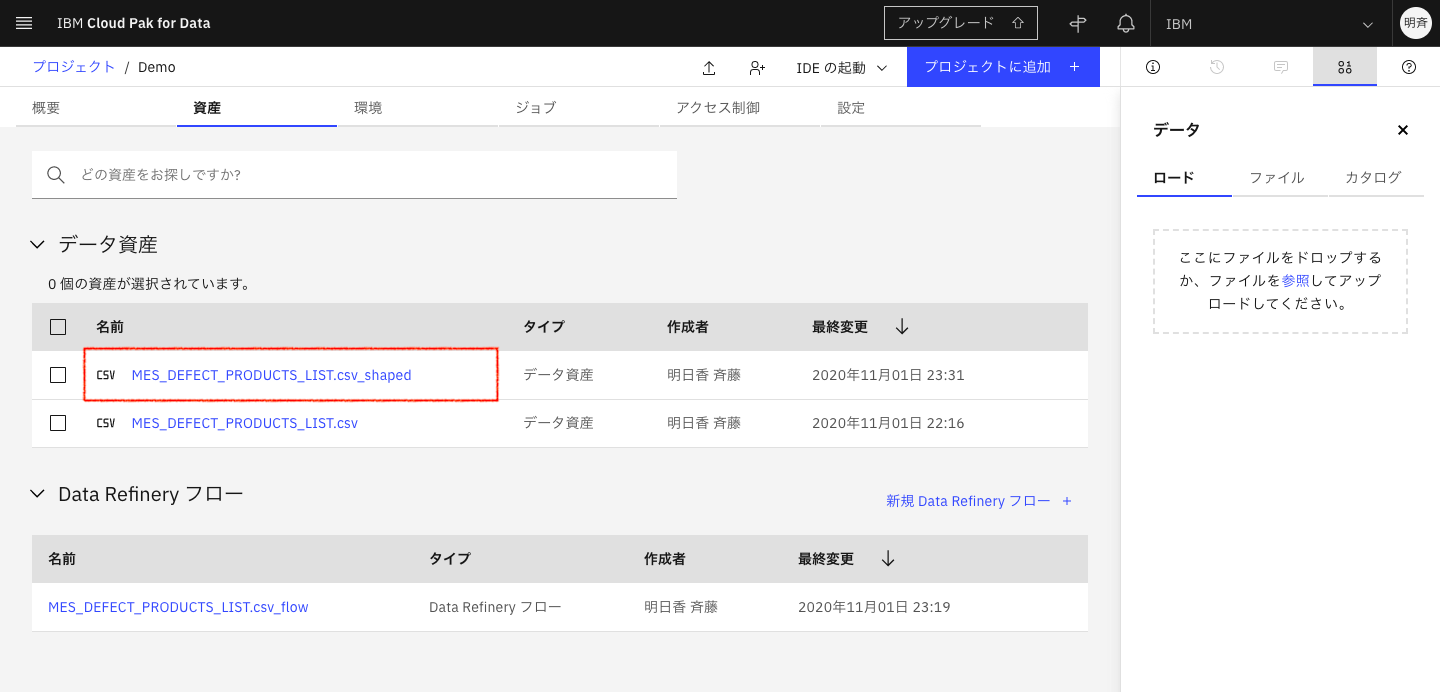
Deta Refineryのより詳細な使い方は
IBM Cloud Pak for Data as a Serviceを始めてみる(4.データの前処理編)をご参照ください。