4.ETL編
Cloud Pak for Data as a Serviceハンズオンメニュー一覧
-
本記事出は、サンプルのETLジョブを作成して処理する手順を記載しています。
-
ETL機能であるDatastageの公式ドキュメントとしてはこちらを参考にして下さい。
-
また、本記事ではこちらのチュートリアル(英語版)に従って実施します。
1.サンプルプロジェクトを作成
-
プロジェクトの一覧画面(すべてのプロジェクトを表示)から、「新規プロジェクト」をクリック。
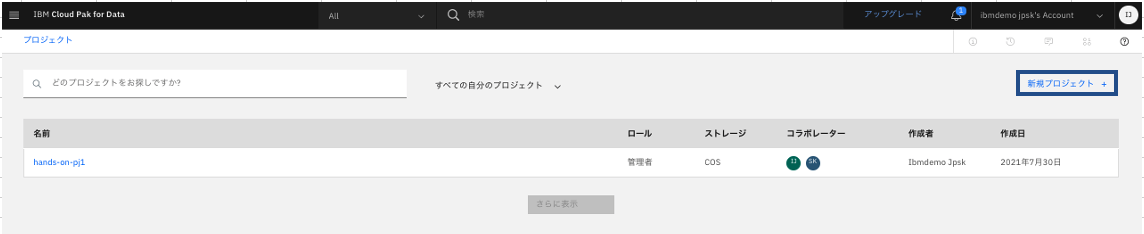
-
「サンプルまたはファイルからプロジェクトを作成」を選択。
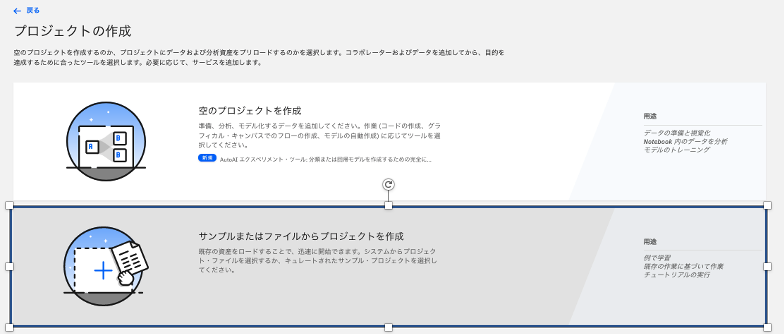
-
「サンプルから」タブをクリックし、「COVID-19 Tracking with IBM Datastage」を選択。

-
「作成」ボタンをクリック。
-
なお、作成ボタンが青くない場合は、「コラボレーターになれるユーザーを制限する」のチェックボックスをオフにしてからオンにすると、青くなるかもしれません。
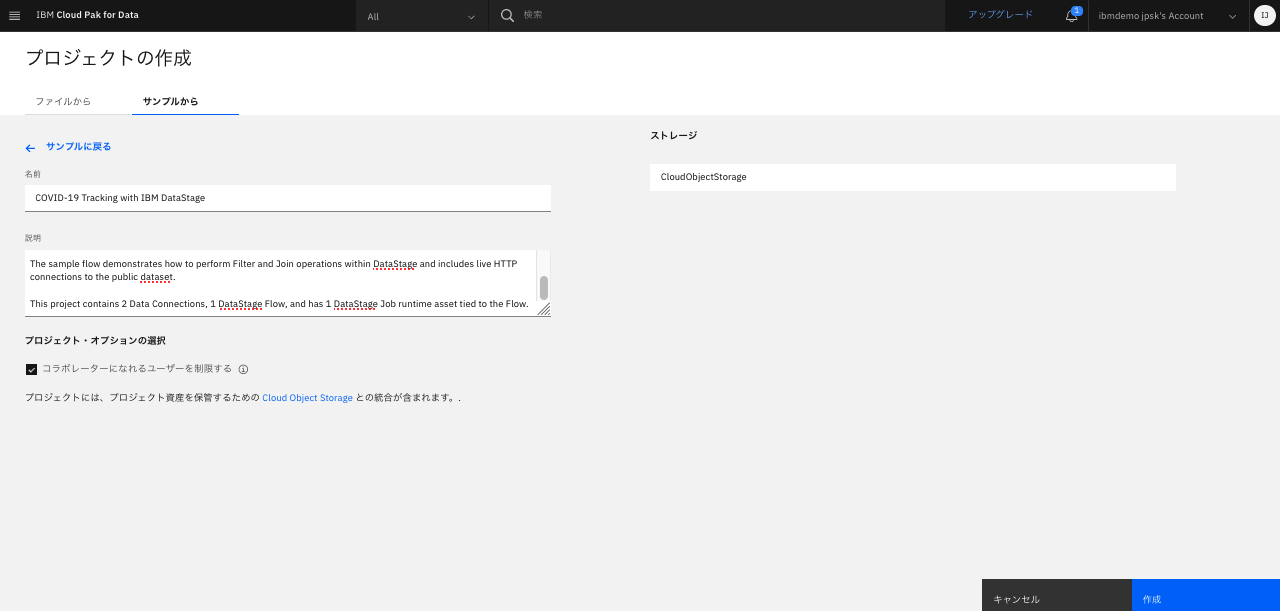
-
作成を待ちます。
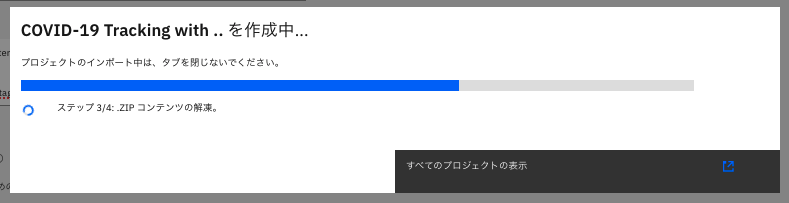
-
作成されたようなので、「新規プロジェクトの表示」をクリックします。

-
サンプルプロジェクトが表示されました。これは「概要」タブです。

-
すべて英語ですし長いですが、時間があればREADME を読んで概要を理解してみましょう。
-
要約すると以下のようなことが記載されています。
- DatastageはETL/ELTを実現します。
- COVID19の2つの症例データを使用します。
- 大学でのCOVIDの症例数のデータ:colleges.csv
- 郡レベルでの症例数の時系列データ:counties.csv
- これらを結合して、その結果をジョブログで確認する、というのがこのフローの内容です。
- 参考までに、サポートされるデータソースのリンクも記載されていました。これもちょっと見てみましょう。
2.Datastageフローを確認
-
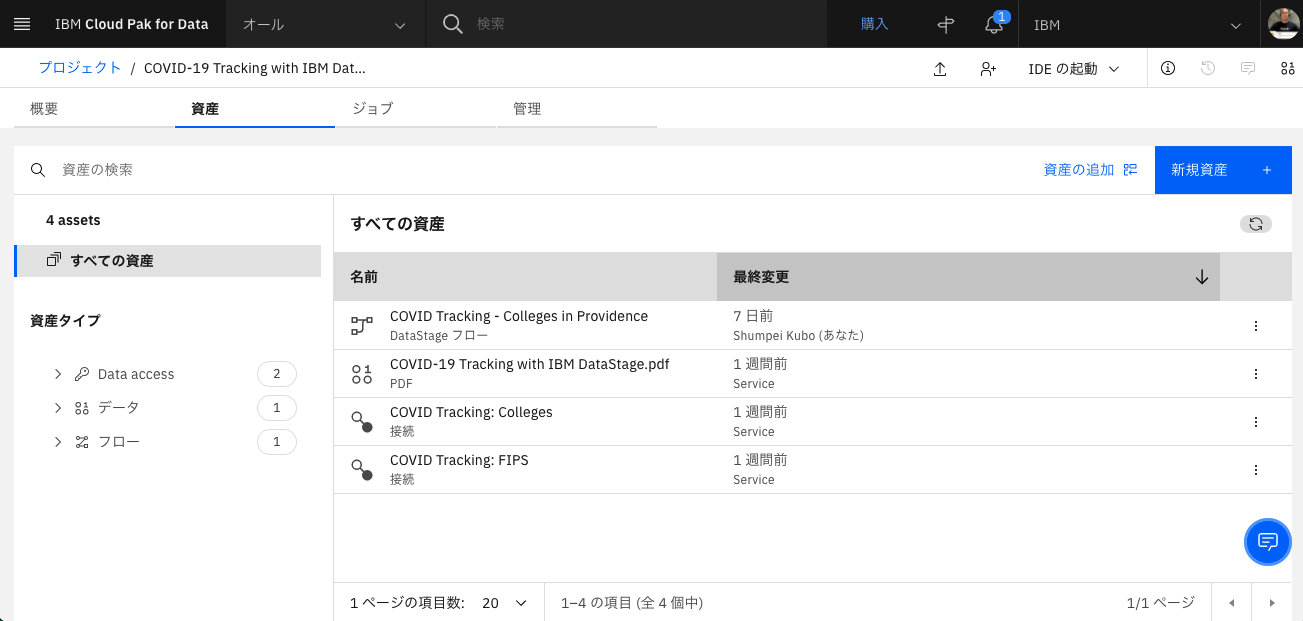
「資産」タブには「接続」が2つと「DataStageフロー」、あと説明用のPDFが保存されています。
- 2つの「接続」は、すでにDatastageフローの中に組み込まれています。
-
PDFは、時間があるときに読んでみましょう。
-
ここでは「Datastageフロー」をクリックして中身を見てみましょう。

2.1.接続先データ(コネクター)確認
2.1.1.Colleges アイコン確認
-
まず、個別の中身を見ていきます。左上の「Colleges」アイコンをダブルクリックしてみます。
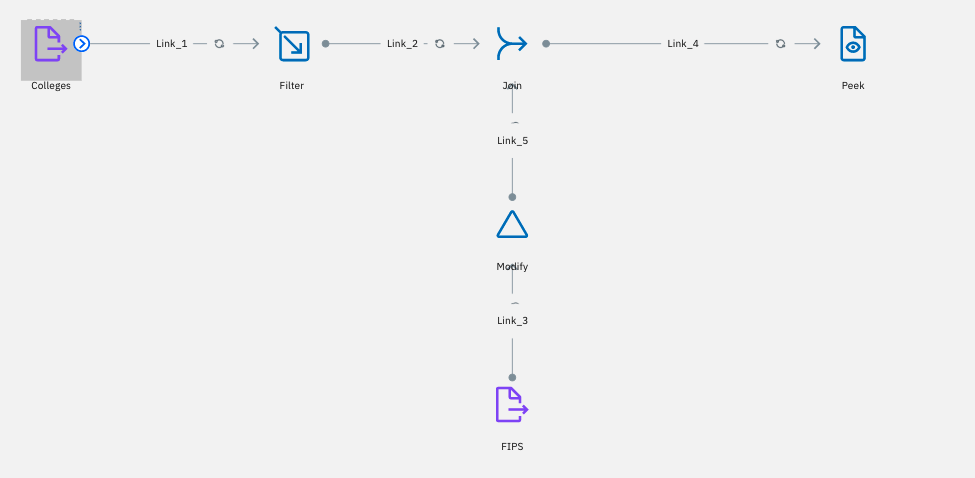
-
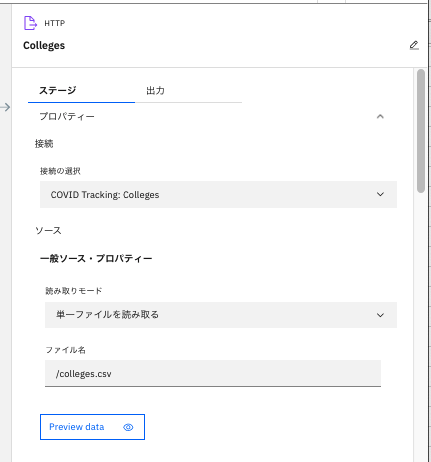
画面右側のCollegesの「ステージ」タブのプロパティーをクリックし、「接続の選択」が「COVID Tracking Colleges」になっていることを確認。
-
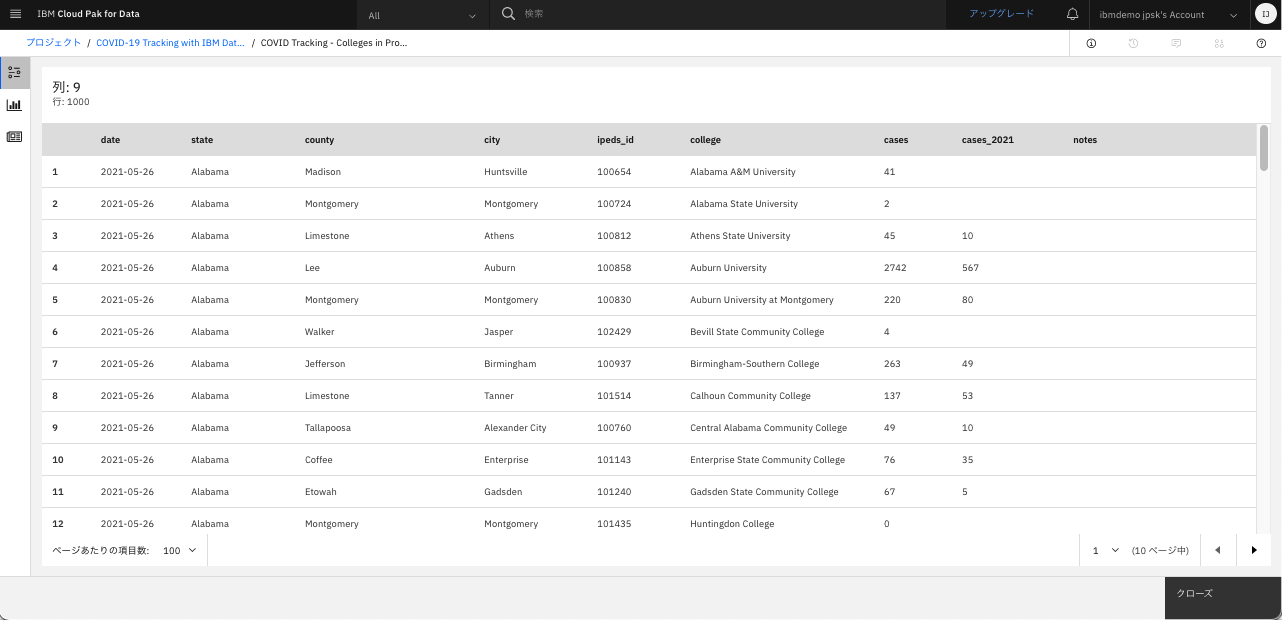
「Preview data」をクリックし、データの中身を確認。「クローズ」をクリックして閉じる。
-
各列の意味については、こちらのサイトの「Data」の箇所から引用しますが、以下のとおりです。
- date: The date of the last update.
- state: The state where the college is located.
- county: The county where the college is located.
- city: The city where the college is located.
- ipeds_id: The Integrated Postsecondary Education Data System (IPEDS) ID number for the college.
- college: The name of the college or university.
- cases: The total number of reported Covid-19 cases among university students and employees in all fields, including those whose roles as doctors, nurses, pharmacists or medical students put them at higher risk of contracting the virus, since the beginning of the pandemic.
- cases_2021: The total number of newly reported Covid-19 cases since Jan. 1, 2021 only. notes: Specific methodological notes that apply to the institution, for example if the count includes cases from a medical unit, and if there is a possibility that duplicate cases have been counted due to the manner in which the institution reports data.
-
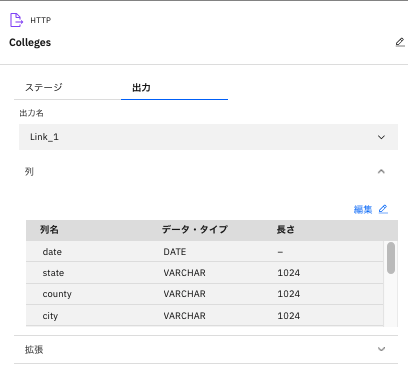
続いて、「出力」タブをクリックし、「列」をクリック。出力される列が確認できます。
2.1.2.FIPS アイコン確認
-
同じく画面中央下部の「FIPS」アイコンをクリックします。
-
「接続の選択」で「COVID Tracking :FIPS」が選択されていることを確認します。
-
なお、FIPSとは、Federal IOnformation Processing Standards の略で、FIPSコードはアメリカの地域を表すコードです。counties.csvでは郡レベルのコードまで確認できます。

-
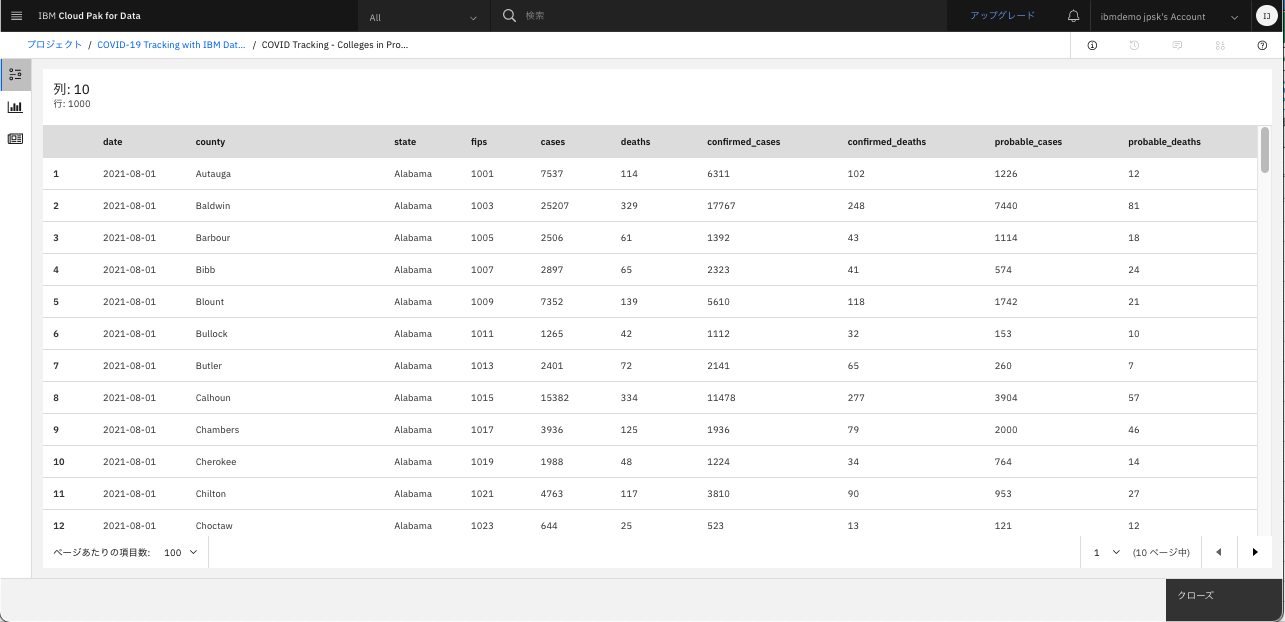
「Preview data」をクリックし、データの中身を確認。「クローズ」をクリックして閉じる。
-
各列の意味については、こちらのサイトの「Live Data」の箇所から引用しますが、以下のとおりです。
- cases: The total number of cases of Covid-19, including both confirmed and probable.
- deaths: The total number of deaths from Covid-19, including both confirmed and probable.
- confirmed_cases: The number of laboratory confirmed Covid-19 cases only, or blank if not available.
- confirmed_deaths: The number of laboratory confirmed Covid-19 deaths only, or blank if not available.
- probable_cases: The number of probable Covid-19 cases only, or blank if not available.
- probable_deaths: The number of probable Covid-19 deaths only, or blank if not available.
-
続いて、「出力」タブをクリックし、「列」をクリック。出力される列が確認できます。

2.2.ステージ確認
- 続いて、データソースからのデータを処理する各ステージの中身を確認します。
2.2.1.Filter アイコン確認
- 続いて、「College」アイコンの先にある「Filter」アイコンをクリックして中身を確認します。「ステージ」タブの「プロパティー」をクリックします。
- フィルターの基準がcity='Providence'であることが確認できます。これはRhode Island州の州都であるProvidence市に結果を絞り込むという意味です。
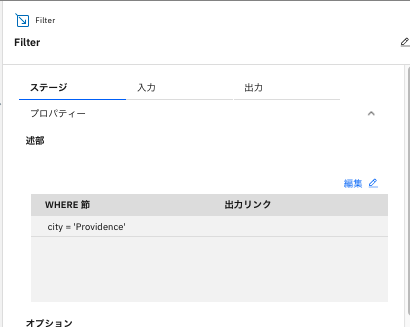
2.2.2.Modify アイコン確認

- 続いて、「FIPS」アイコンの先にある「Modiry」アイコンをクリックして中身を確認します。「ステージ」タブの「プロパティー」をクリックします。
-
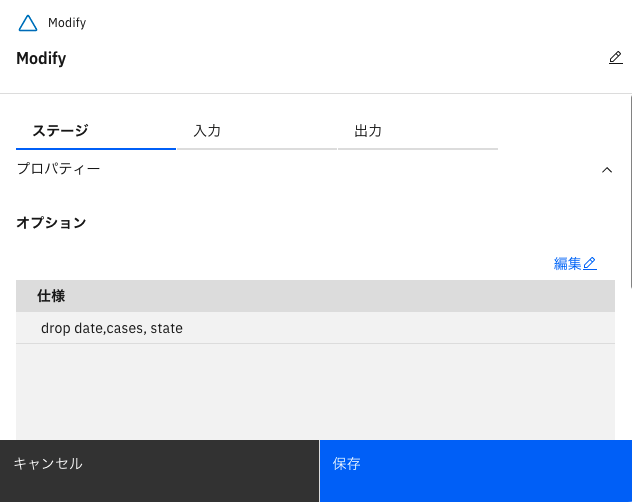
「仕様」欄に、このステージでの処理内容が記載されています。「date」「cases」「state」列を削除していることがわかります。
-
「入力」タブを見てみると、「date」「cases」「state」列が記載されていますが、

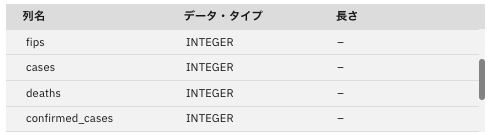
-
「出力」タブを見てみると、「date」「cases」「state」列が削除されています。

2.2.3.Join アイコン確認
-
「ステージ」タブの「プロパティー」をクリック。結合キーとして、「country」が設定されていることが確認できます。
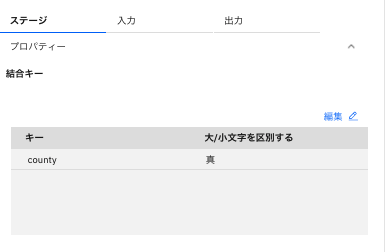
-
Joinの方法として左上部(Left Outer Join )の設定になっています。
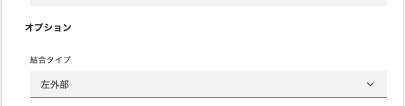
-
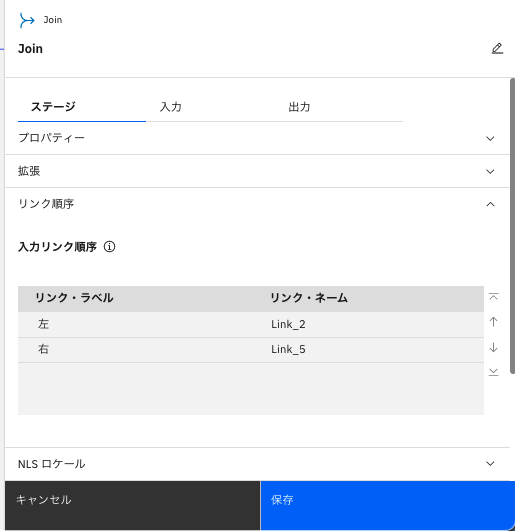
「ステージ」タブの「リンク順序」をクリックすると、どちらの入力が右か左かが確認できます。
-
今回、左側にあるのは、「Link_2」つまり「College」を修正した「Filter」からのリンクになります。

2.3.ジョブの保存・コンパイル・実行
-
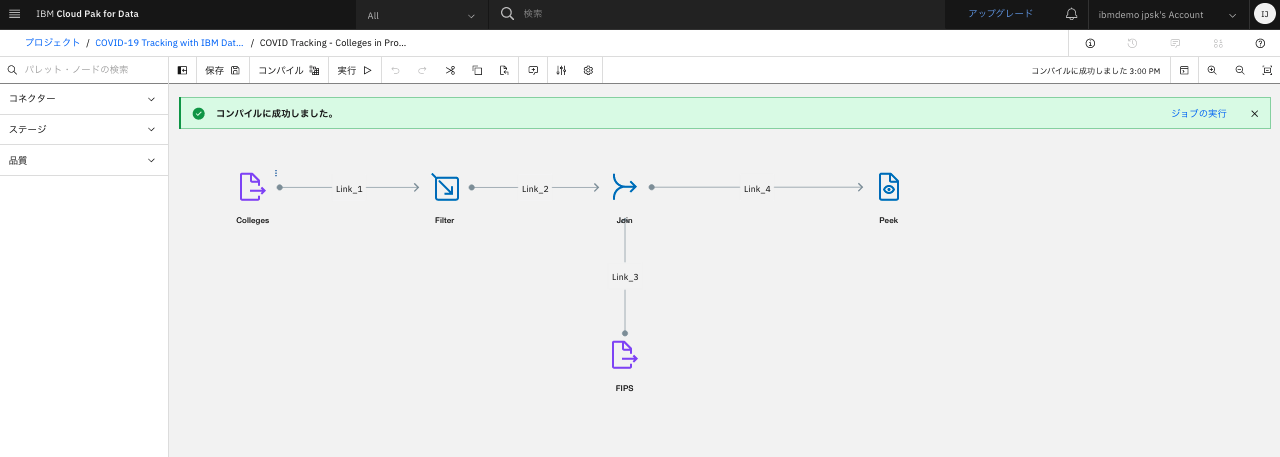
画面左上の「保存」ボタンでジョブを保存します。
-
画面左上の「コンパイル」ボタンでジョブをコンパイルします。

-
(コンパイルに成功した旨のメッセージが出たら)画面左上の「実行」ボタンでジョブを実行します。
-
画面右上に実行状況が出ます。(実行依頼済)
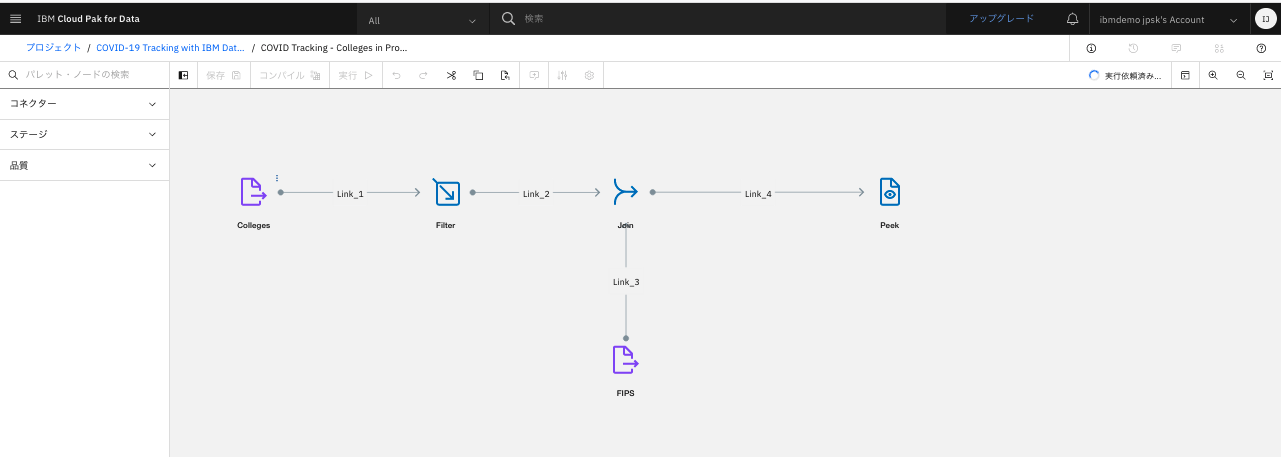
-
(実行中)
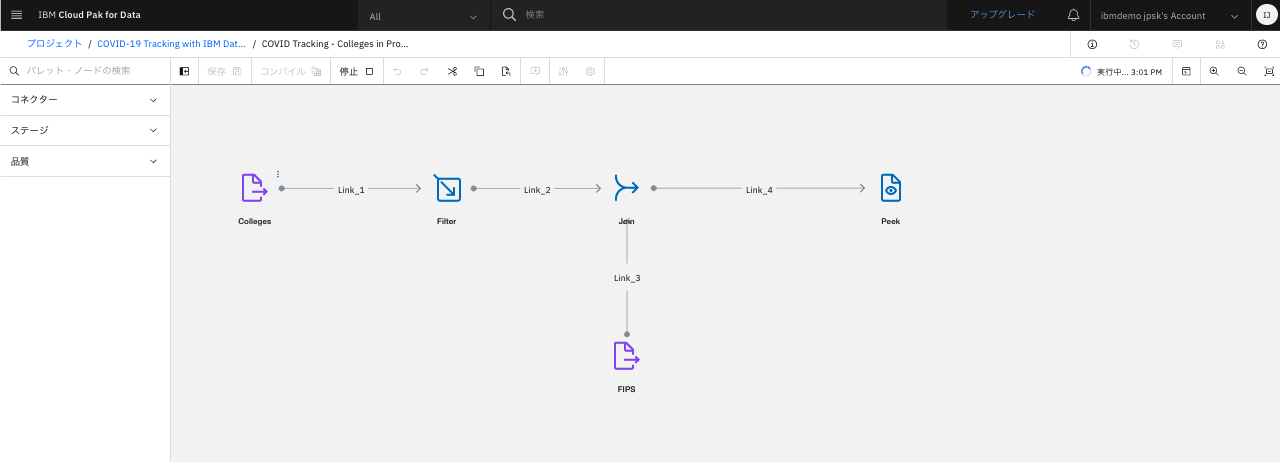
-
実行が完了しました。
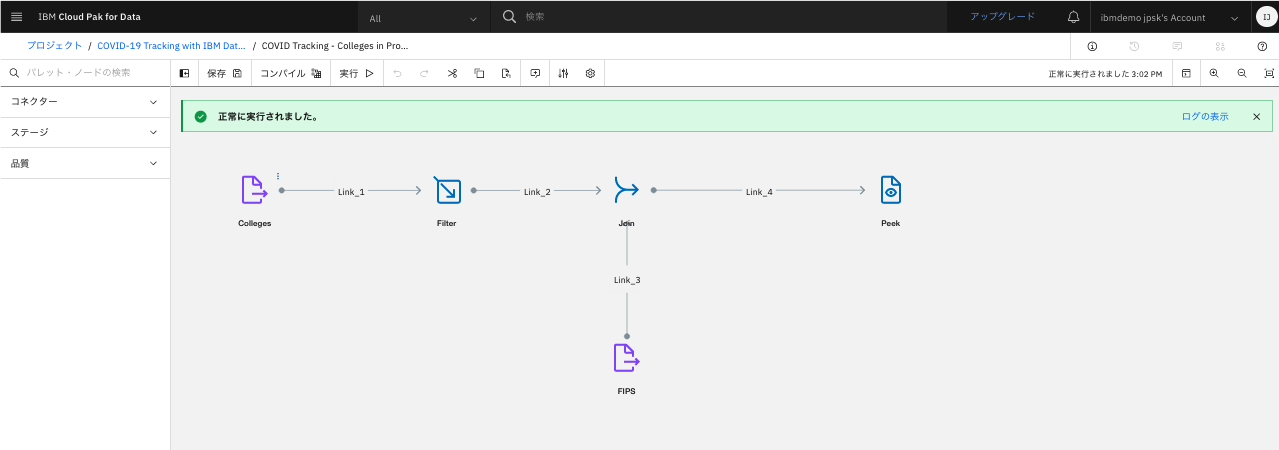
-
「ログの表示」をクリックすると、ログが表示されます。下方へスクロールしてみましょう。

-
「Peek,1」のログの箇所で、Left Outer Joinされた結果が出力されています。

2.4.ジョブの修正・コンパイル・実行
2.4.1.削除する列を追加する
-
「Join」ステージでは、今回、Collegeが左、Countiesが右で、Left Outer Joinしていました。
-
つまり主なデータをCollegeとして、FIPS側にある、条件に合致するデータを付与する形です。
-
College側に、Counties側の情報「FIPS」を付与する、と考えた場合、余分な列は、「date」「cases」「state」以外にも有る為、ここでは削除する列を、以下の通り追加したいと思います。
-
編集する箇所は、「Modify」ステージです。ダブルクリックして、「プロパティ」の「オプション」→「仕様」箇所の「編集」をクリックします。
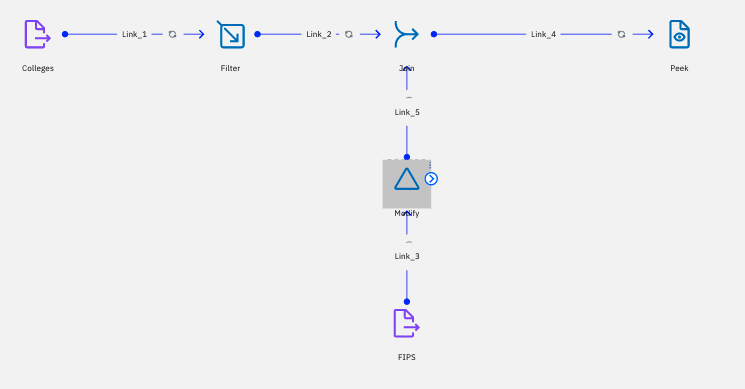
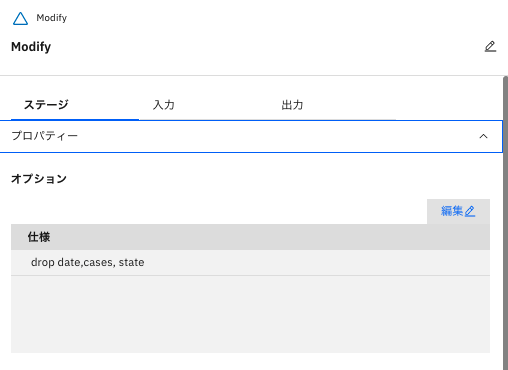
-
「Modify」ステージにて、以下が、元々の記載(date,cases,state をdropする)ですが、
- 「drop date, cases, state」
-
今回、以下のように削除対象の列を追記します。
- 「drop date, cases, state, deaths, confirmed_cases, confirmed_deaths, probable_cases, probable_deaths」

- 「drop date, cases, state, deaths, confirmed_cases, confirmed_deaths, probable_cases, probable_deaths」
-
編集後、「適用して戻る」をクリックします。

-
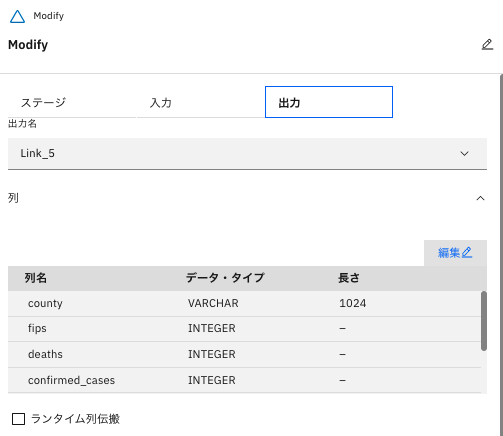
続いて、「出力」タブをクリックし、「列」の箇所の「編集」をクリックして、出力対象の列を修正します。
-
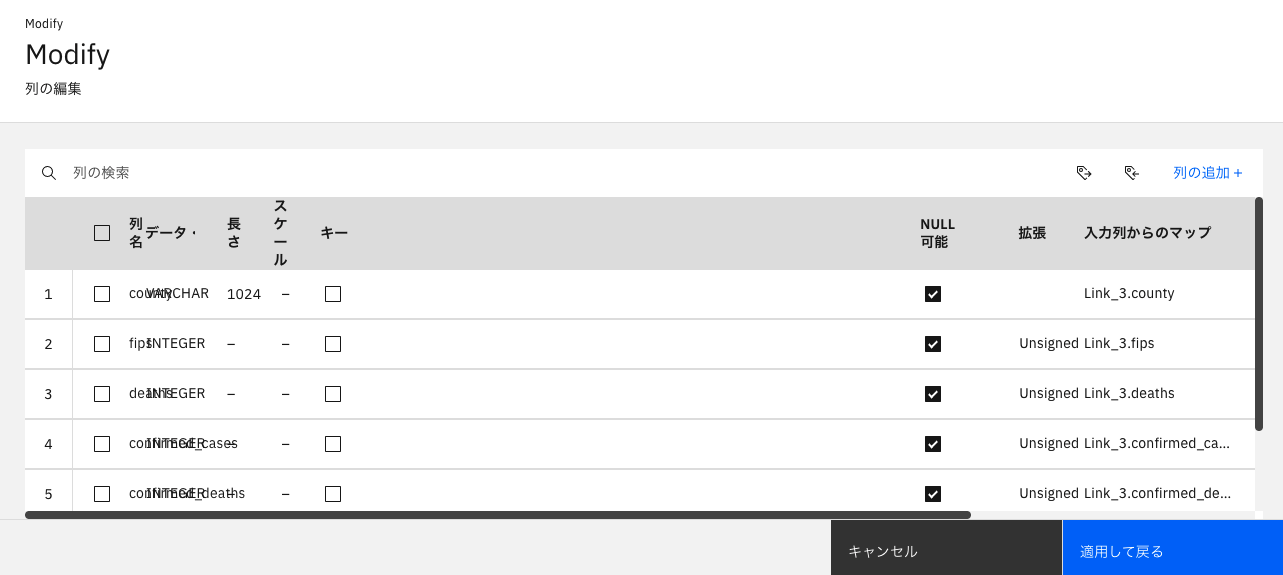
列名のあたりがごちゃごちゃしていますので、ブラウザのズームでひとまず調整しましょう。50%くらいまでズームアウトするときれいには表示されます。
- 100%の場合
- 50%の場合
- 100%の場合
-
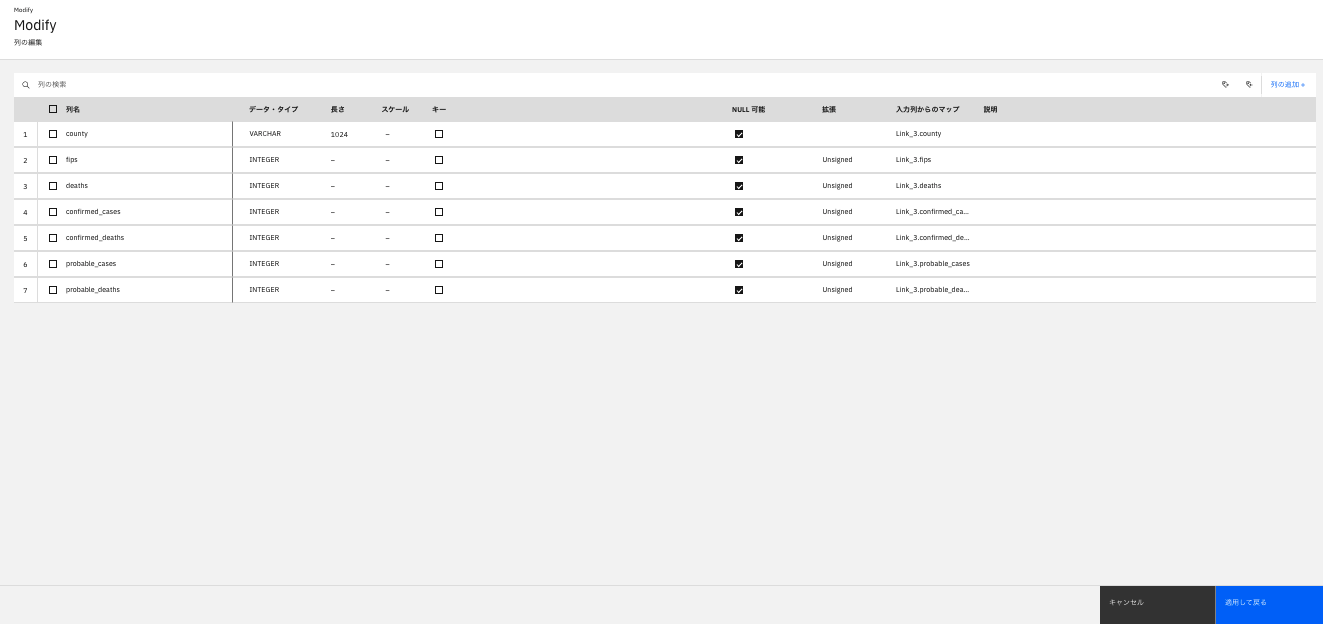
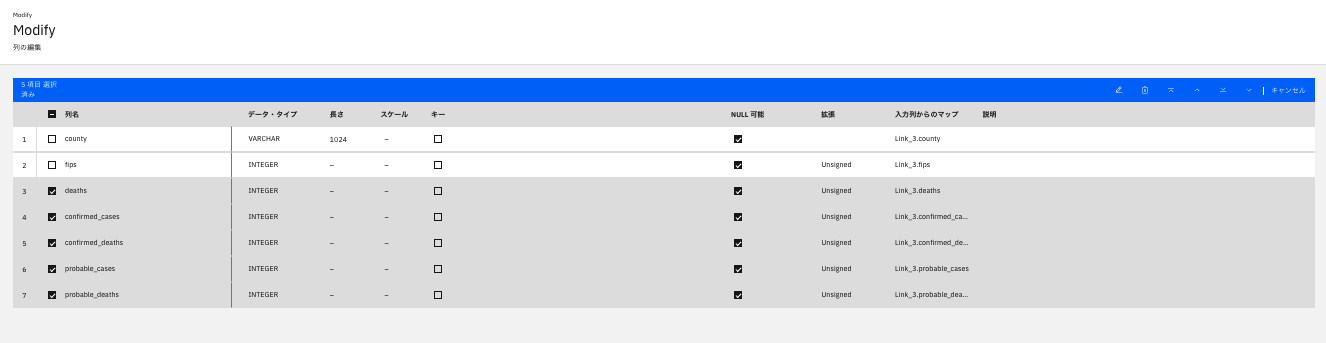
今回、必要な列としては「county」「FIPS」のみですので、それ以外の「deaths」「confirmed_cases」「confirmed_deaths」「probable_cases」「probable_deaths」を削除するために、チェックボックスをクリックします。
-
画面右上のゴミ箱のボタンをクリックし、対象の列を削除します。

-
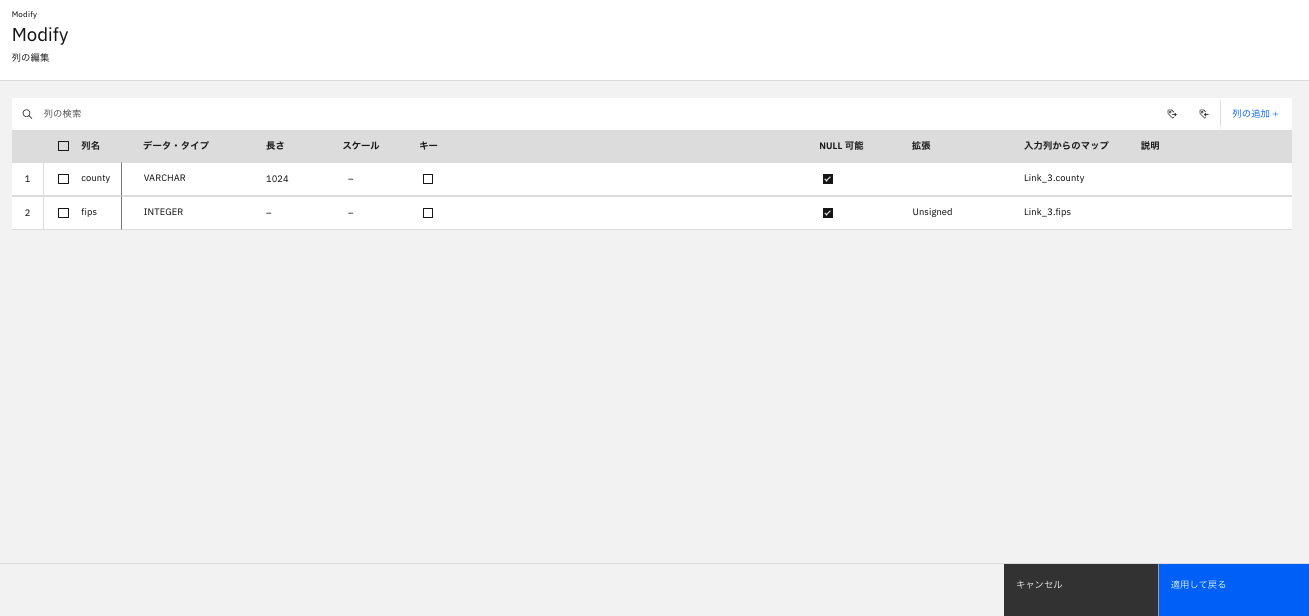
選択した列が削除されました。「適用して戻る」ボタンをクリックします。
-
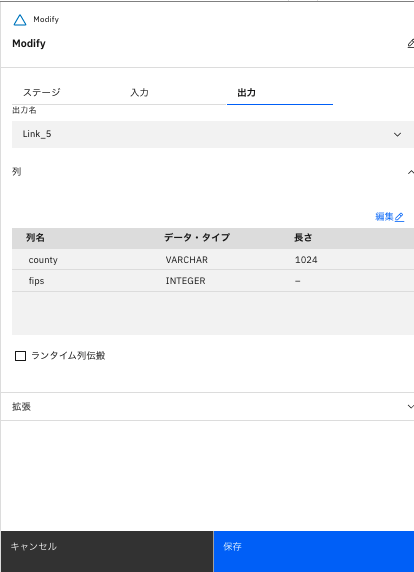
「Modify」ステージの「出力」タブの列が、「county」「FIPS」以外が削除されていることを確認し、「保存」をクリックします。
-
画面右上で「保存中」と表示されていることを確認します。
-
保存完了後、画面上部の「コンパイル」ボタンをクリックして、編集後の設定を実行可能な状態にします。
-
コンパイルが正常に完了したことを確認し、画面上部左側の「実行」ボタン(あるいは薄緑色のメッセージ右側の「ジョブの実行」)をクリックして、設定したジョブを実行します。
- ジョブの実行中です。
- ジョブが完了しました。ジョブのログを確認してみます。「ログの表示」或いは、画面右上の「ログ」ボタンをクリックします。

-
なお、参考までに、「Modify」ステージで出力列を編集せずにコンパイル・実行した場合にも正常に終了しますが、(警告有り)表示となります。
-
これは、出力列が定義されていながら、実際にはその列がDropされている為です。

-
ジョブログ画面が表示されます。
-
画面を下の方へスクロールさせていきます。
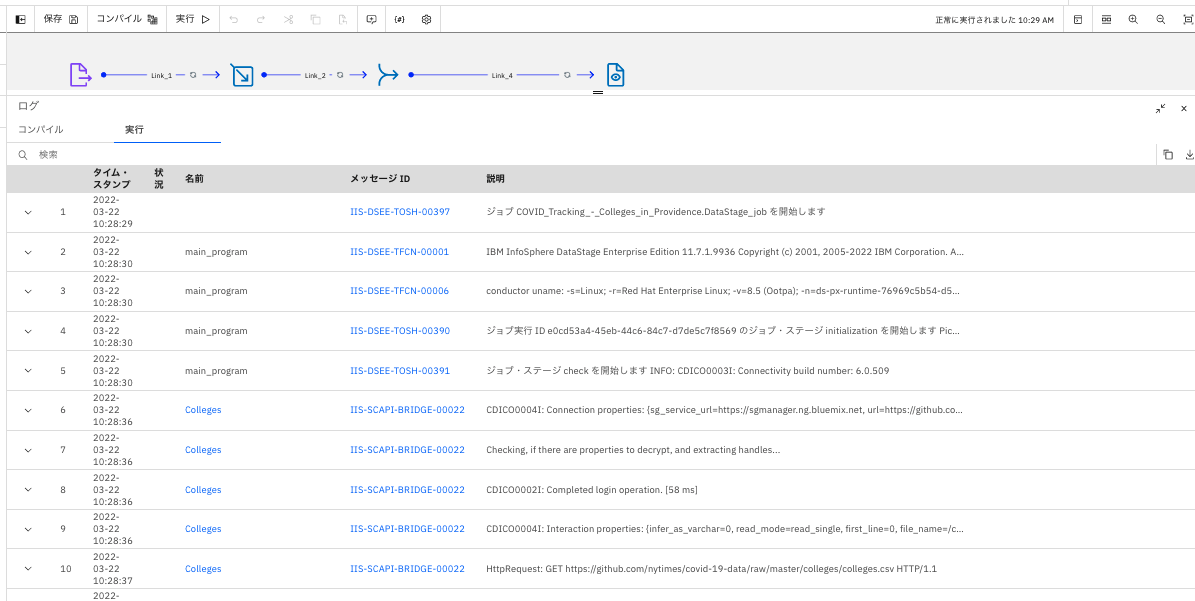
-
「Peek,1」という名前のログを確認します。右へスクロールすると、「FIPS」も付与されていることがわかります。

2.4.2.アウトプット先の変更
2.4.2.1.csvファイルへの書き出し
- コネクターの中から、「Sequential File」 を選択してキャンバスへ引っ張ってきます。
- 画面左上の検索窓に、「Sequential」と入力しようとすると、表示されてきます。

- キャンバスへドラッグ&ドロップします。
- キャンバス上では「Sequential_file_1」として表示されます。名前は自由に変更できますが、ここではそのままにしておきます。

- 「Peek 1」から線を引っ張って「Sequential_file_1」へひっつけます。

- 「Sequential_file_1」をダブルクリックして、内容を表示させます。

- 「入力」タブに移動し、入力名が「Link_6」(このSequential_Fileを向いている矢印)であることを確認します。
- 「プロパティー」欄の下矢印をクリックします。

- 入力対象となるファイルを設定していきます。

- ファイル名を入力します。(この例では「demo_seq_file1.csv」としています。)
- 「データ・アセットの作成」にチェックボックスを入れます。
- 「ファイル更新モード」は、今回は「上書き」から「追加」に変更してみます。
- 「書き込み方式」は「特定のファイル」を選択します。
- 以降の項目は、そのままで構いません。

- 画面を下にスクロールすると、列情報も編集できますが、今回はそのままにしておきます。
- 「保存」をクリックします。

- キャンバスでは自動的に保存されます。(画面右上に「保存中・・・」の表示あり)

- 画面上部の「実行」ボタンをクリックします。実行の前提となる「保存」「コンパイル」も併せてフローが実行されます。




- 処理が終了しました。一部警告があるようです。
- 警告内容については、「ログの表示」をクリックしてみてみましょう。

- 画面右下に、黄色い三角の警告マークがあります。これをクリックして警告内容を確認します。

- 警告箇所が表示されます。
- 警告内容は以下の通りでした。
- 「2023-01-24 11:19:31 WARNING IIS-DSEE-TFIG-00122 オペレーター・チェックで以下が検出されました: エクスポート・スキーマの検証時: フィールド "date": "null_field" 長さ (4) は、フィールドの固定幅(10)に一致する必要があります」

- 作成されたファイルを確認します。
- 画面左上のプロジェクト名称のリンクをクリックして、プロジェクトの画面に戻ります。
- 作成したファイル(今回の例では「demo_seq_file1.csv」)が作成されていることがわかります。

- ファイル名をクリックして、ファイルが作成されていることを確認します。

- ファイルの実体がどこにあるのかを確認します。
- ファイルとしては、IBM Cloud 上のCloud Object Storage 上に格納されているのですが、それを確認してみます。
- プロジェクト画面に戻り、「管理」タブをクリックします。
- 「一般」をクリックし、画面右側の「ストレージ」の箇所を確認します。
- 「バケット」の名称を、ここでコピーしておきます。
- 「IBM Cloudで管理」をクリックします。

- IBMCloud のCloud Object Storage 画面が表示されますので、ここで先程コピーしたバケット名称を検索窓に貼り付けます。


- 表示されたバケットをクリックし、内容を確認していきます。
- 先程作成したcsvファイル(demo_seq_file1.csv)があることが確認できます。

- ファイル名をクリックします。

- 「オブジェクトのダウンロード」をクリックします。

- ファイルがダウンロードされるので開いてみます。

- ファイルが表示されました。

以降、編集中です。
2.4.2.1.1.警告内容の解消
2.4.2.2.データベースへの書き出し
2.5.スケジューラ設定
- 今回のハンズオンはこちらで終了です。
追加手順
- 上記Datastageのフロー画面にcsvファイルをUploadする手順を、以下に記載しました。
- Datastage as a Service にローカルのcsvファイルをアップロードする。
Solution BlogでのDatastageハンズオン紹介