Cloud Pak for Data as a Serviceハンズオンメニュー一覧
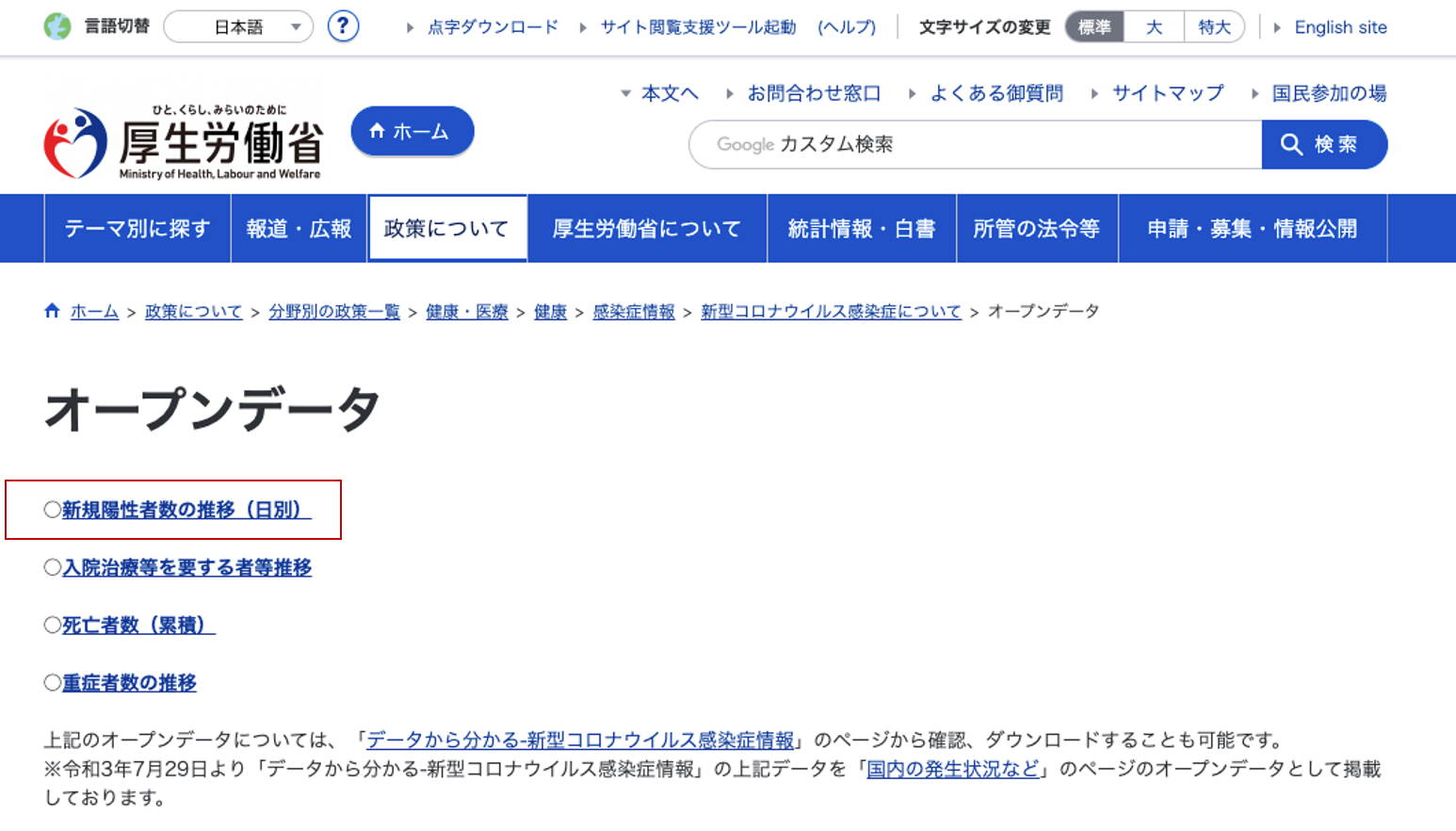
新型コロナウイルスの新規陽性者数のデータソース
このページにてグラフ化したいデータソースは、厚生労働省のオープンデータに掲載されているこちらのデータソースです。
前提事項
- 同じIDですべての操作を行いますが、
- 前半はデータ整備人の立場での操作です。
- 後半はデータ利用者としての操作です。
- 今回は2021年10月4日時点のデータを使用しています。
1.データカタログ画面上での操作
1.1.データソースをデータカタログに追加(データ整備人として)
-
まず最初にデータ整備人の立場として、外部データへの接続情報をカタログに登録しておきます。(データ利用者に幅広く利用してもらえるように)
-
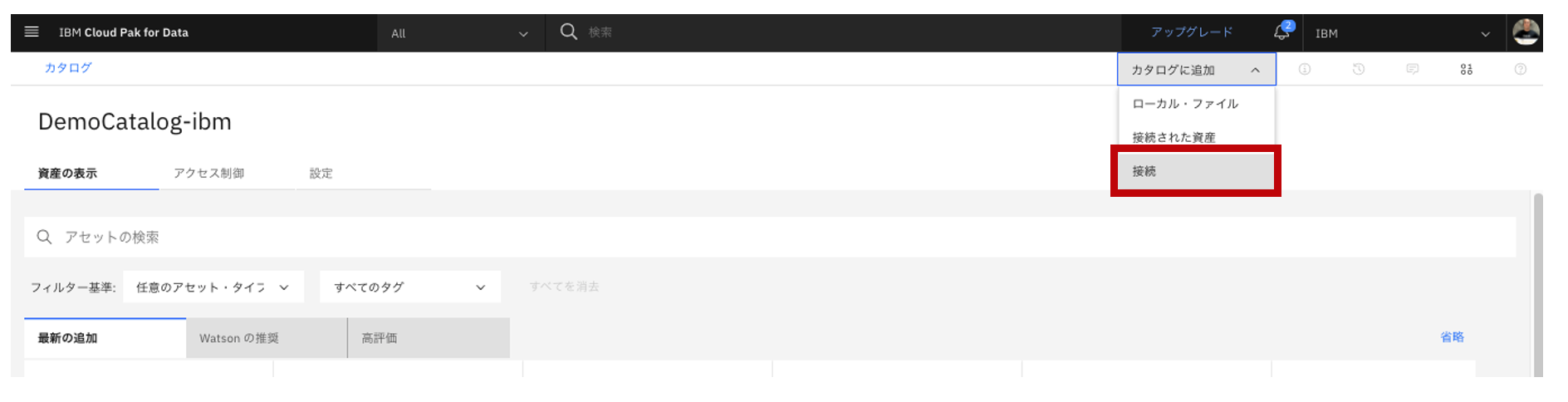
「カタログに追加」から「接続」を選択
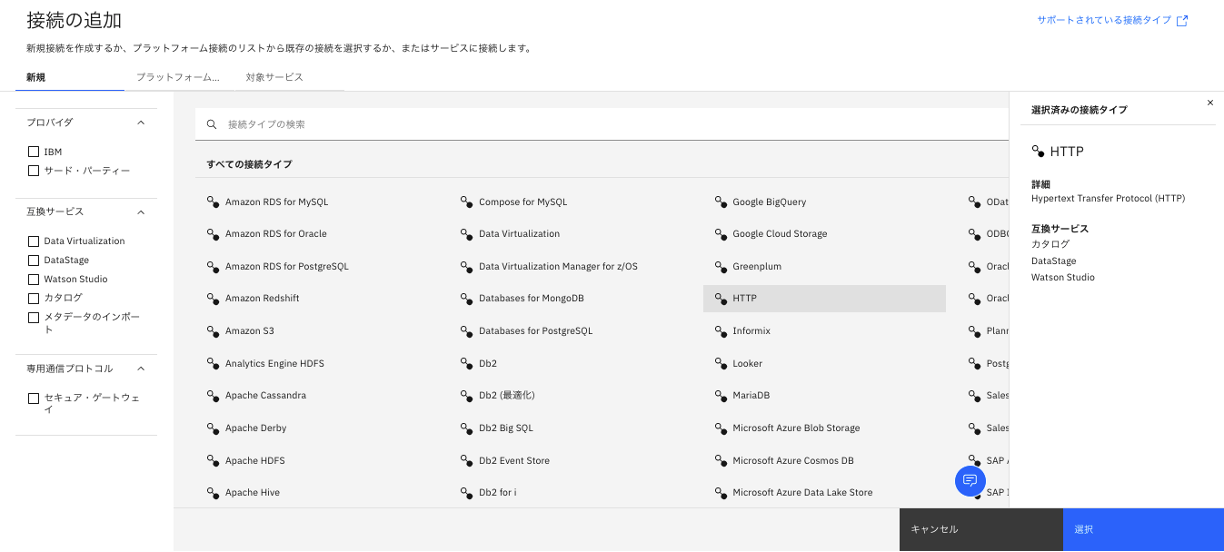
- 「接続の追加」から「HTTP」を選んで「選択」ボタンをクリック。
- 名前や説明を入力して、URL欄に先程のCSVのURLを入力。
- 念の為、接続されているかを確認するために、「接続のテスト」をクリック。
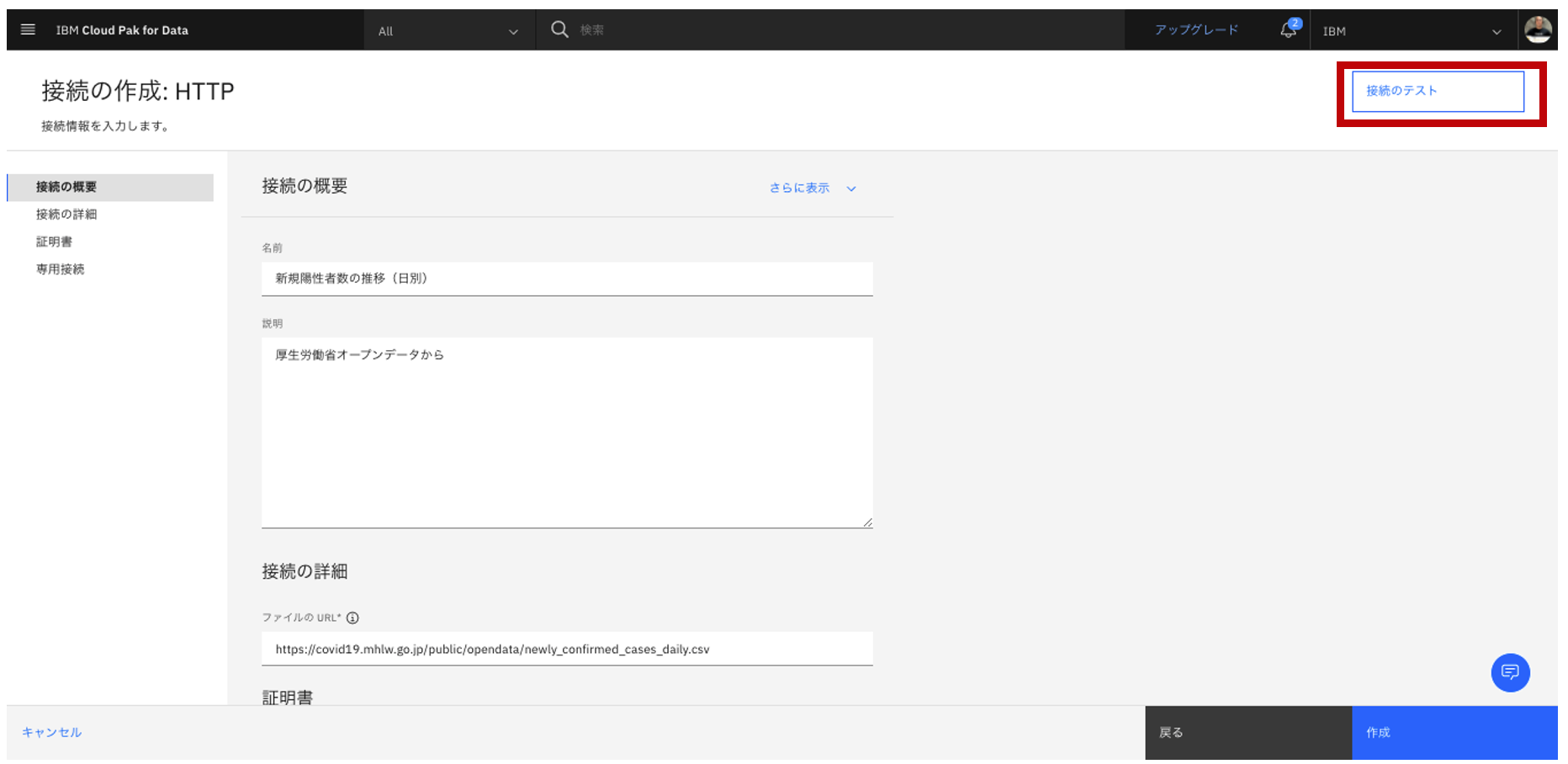
- テスト正常終了を確認し、「作成」をクリック。
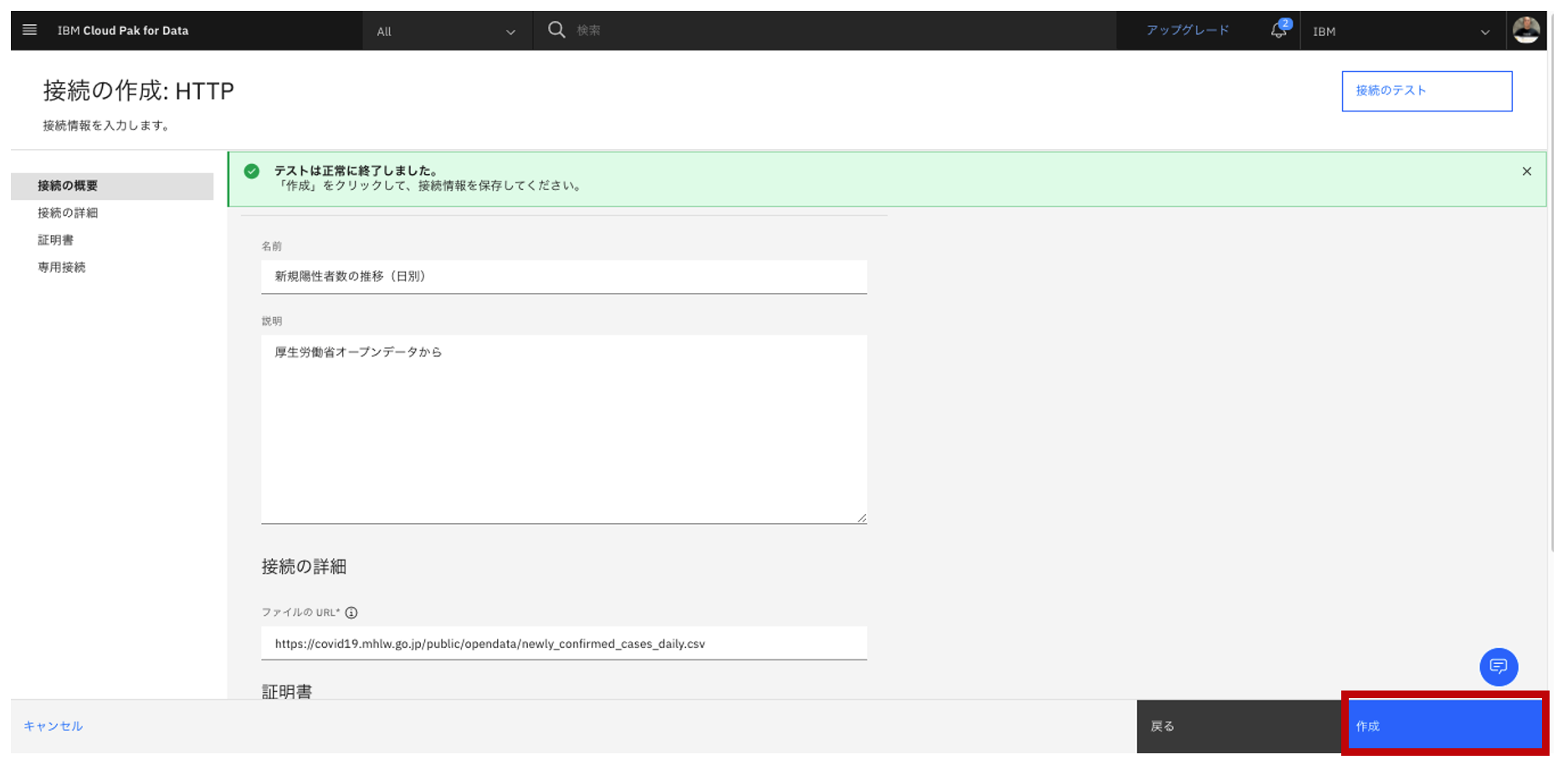
1.2.データ接続情報をプロジェクトに追加する。(データ利用者として)
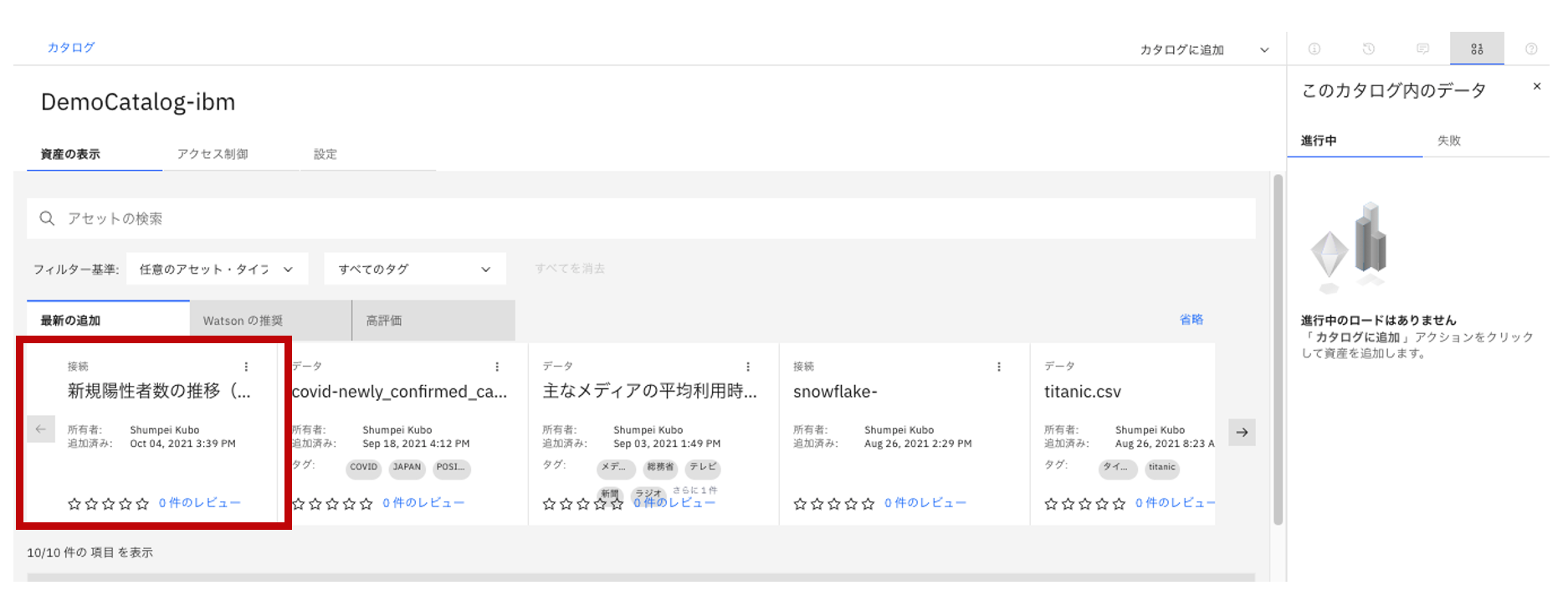
- 次に、データ利用者の立場として、カタログ上で見つけたデータ接続情報を個別のプロジェクトにコピーします。
- カタログ上でデータ接続情報をクリック。
- プロジェクトに追加、をクリック。
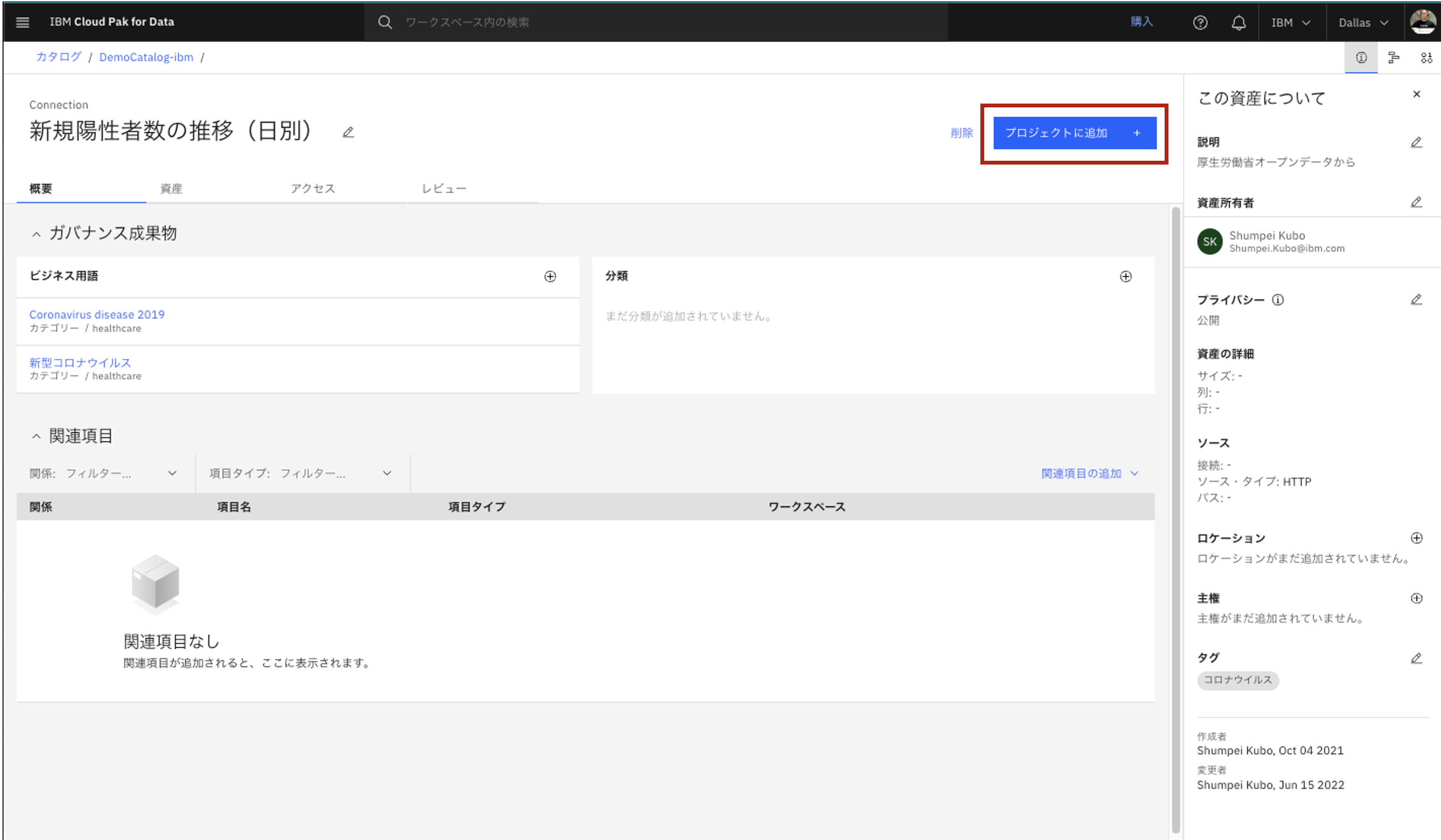
- 移動先のプロジェクトを選択し、「追加」をクリック。
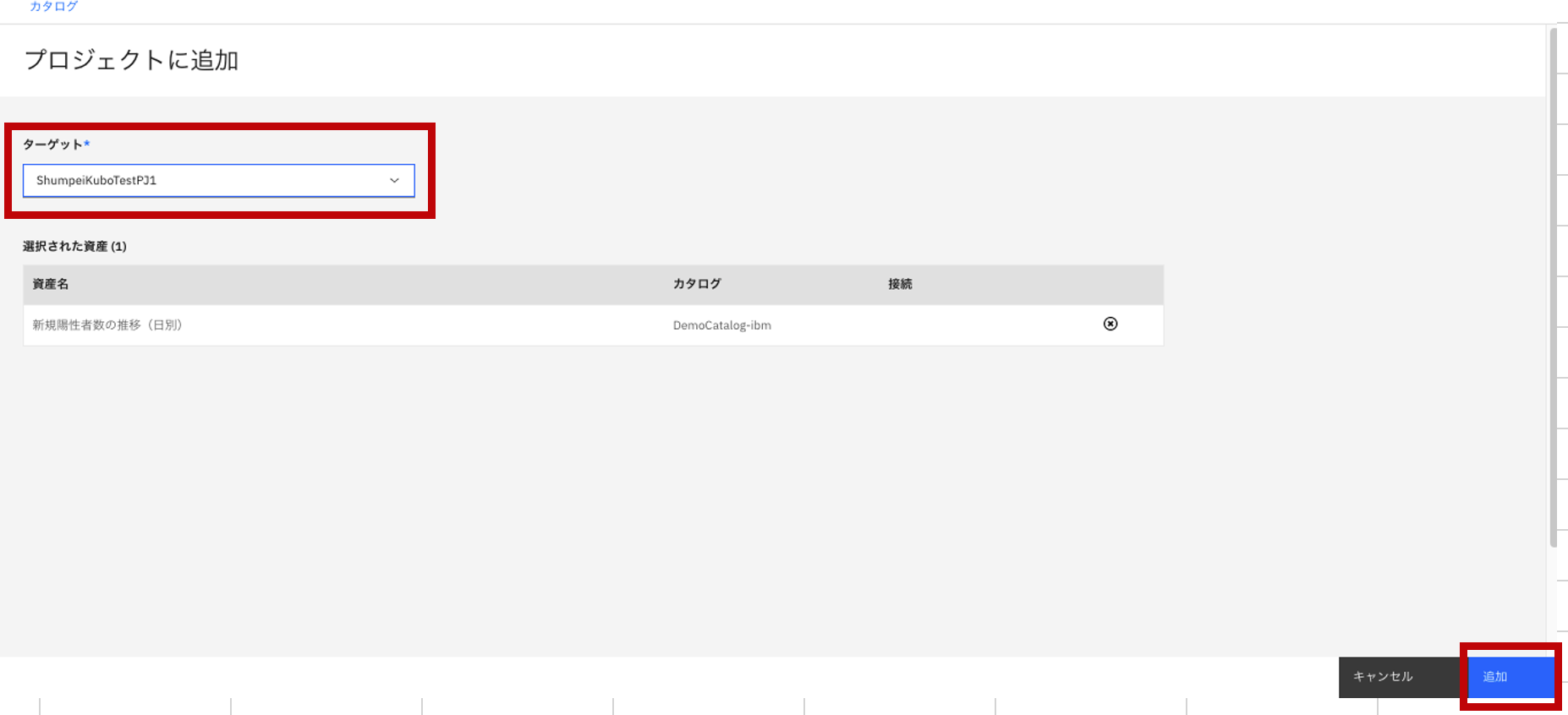
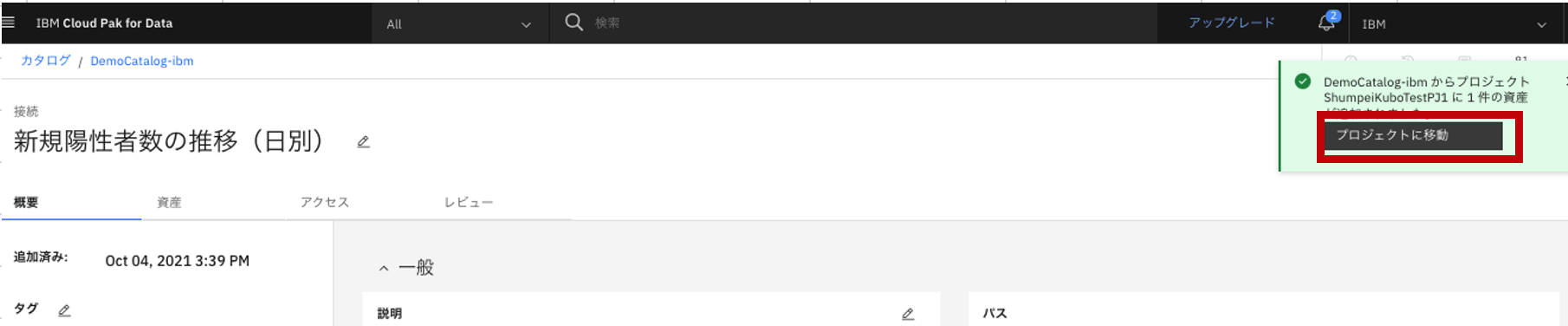
- 移動された旨のメッセージが出るので、「プロジェクトに移動」をクリック。(当該メッセージが消えてしまったら、手動で当該プロジェクトまで移動してみてください。)
2.プロジェクト画面上での操作(データ利用者として)
2.1.プロジェクトへのデータ資産の追加
-
プロジェクト上に追加された接続情報を利用して、その先にあるデータ資産をプロジェクトに追加します。
-
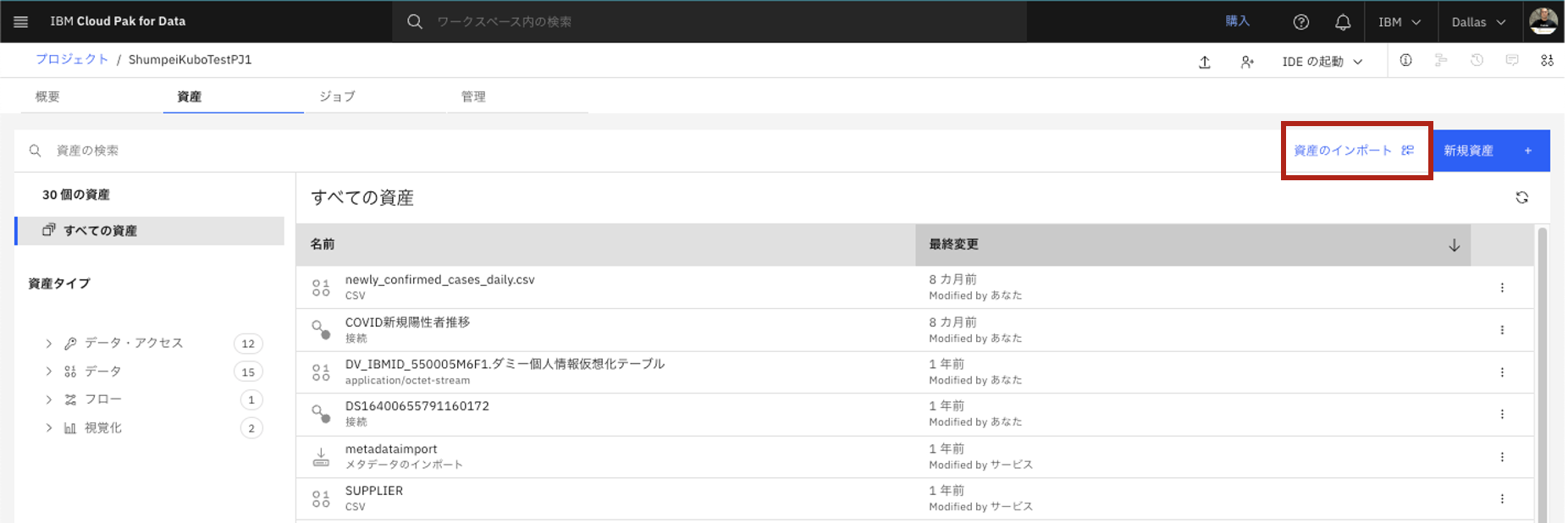
プロジェクトで接続情報がある事を確認し、「資産のインポート」をクリックします。
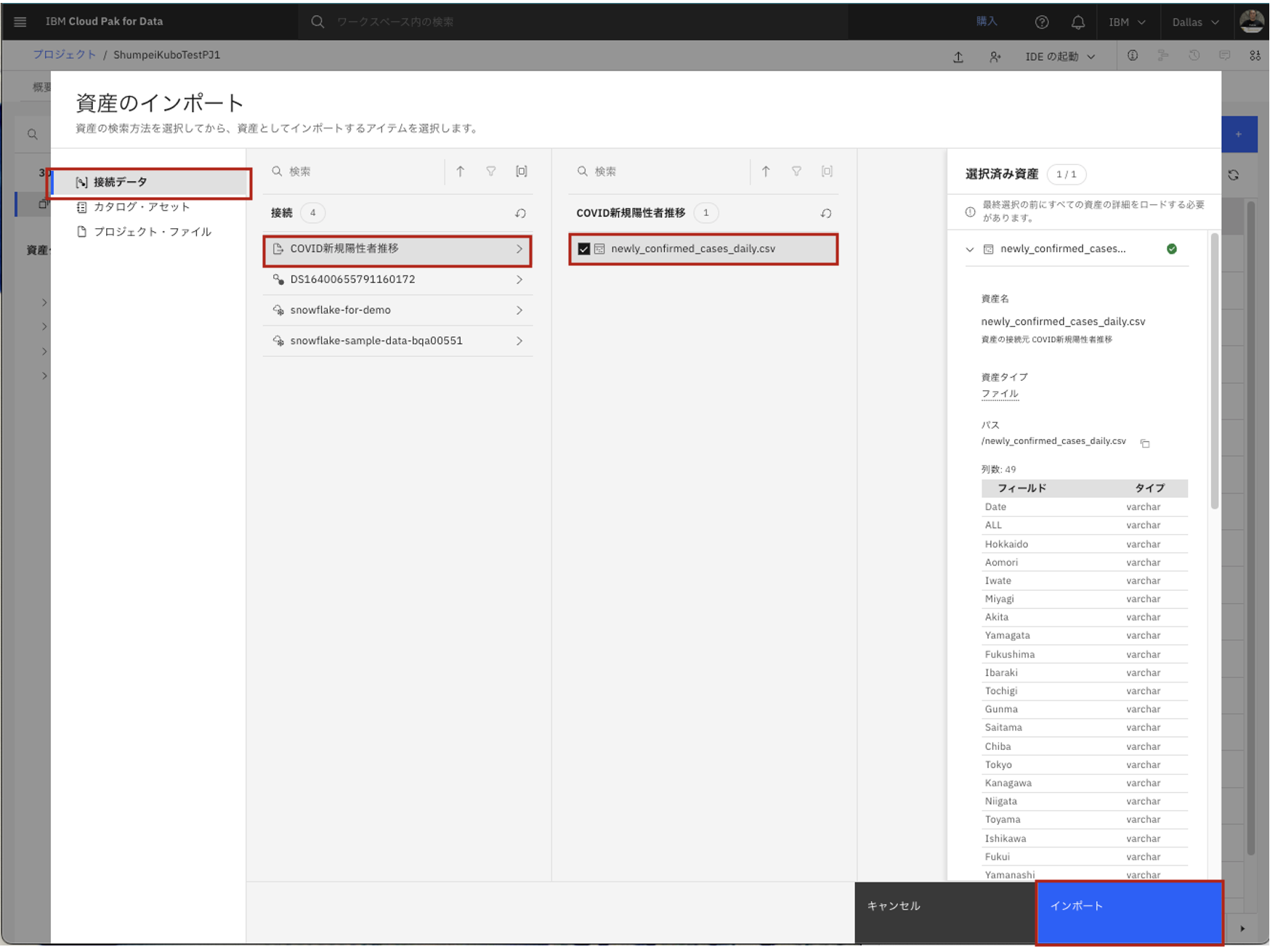
- 「接続データ」を選択し、対象となる接続情報(今回はCOVID新規陽性者推移)をクリック。
- その先の対象データ(今回はnewly_confirmed_cases_daily.csv)にチェックを入れ、
- 画面右下の「インポート」ボタンが青くなったらクリックします。
- プロジェクトにデータ資産が登録されました。データ資産をクリックします。
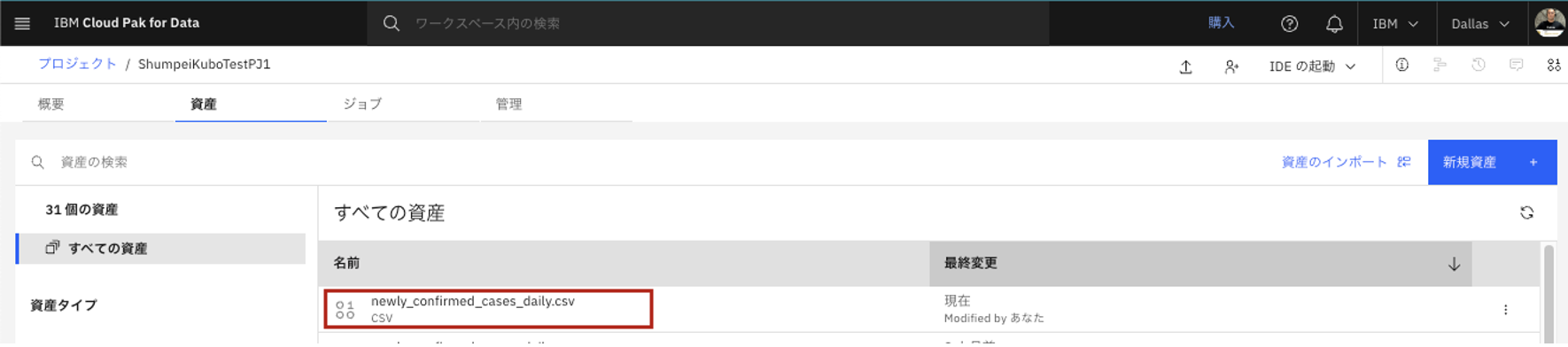
2.2.データ整形ジョブで、データの型を変更する。
2.2.1. データの型を変更するオペレーション
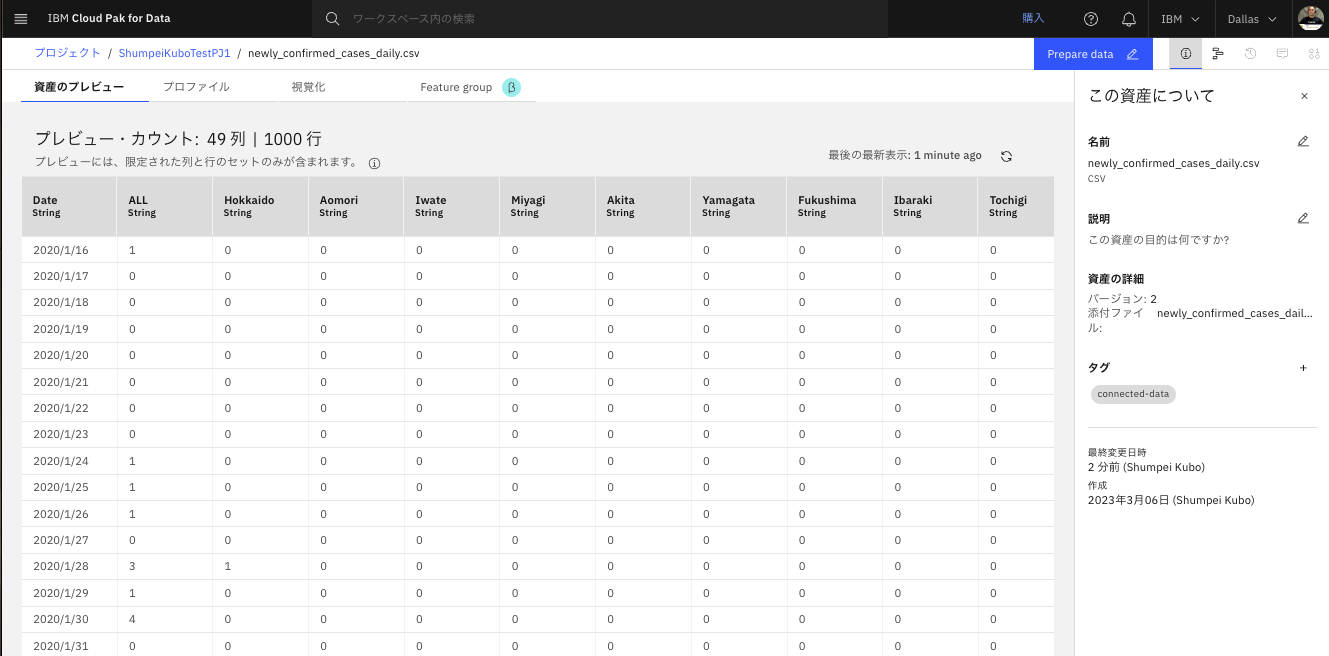
- 過去の先人の経験から、このデータのDate列が実は文字列型なので正しく時系列にならないことがわかっているので、データの変換処理を行います。
- 画面右上の青い「Preapare Data」ボタンをクリックします。
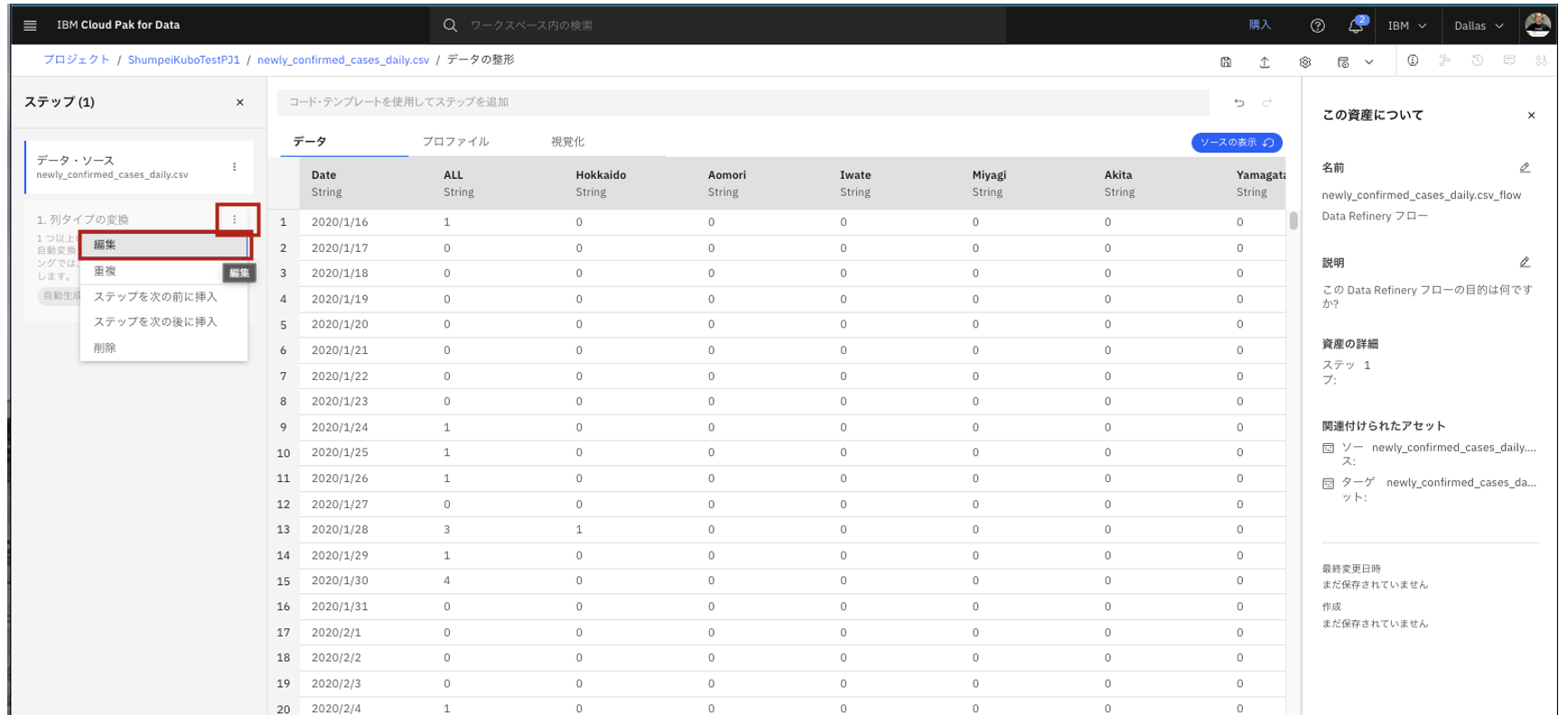
- データ整形(Data Refinery)処理が起動するまで数十秒お待ち下さい。起動し終わったら、画面左側の「1.列タイプの変換」ボタンの端にある「・・・」をクリックして表示された「編集」をクリックします。
- 編集画面が表示されます。「さらに表示」をクリックします。
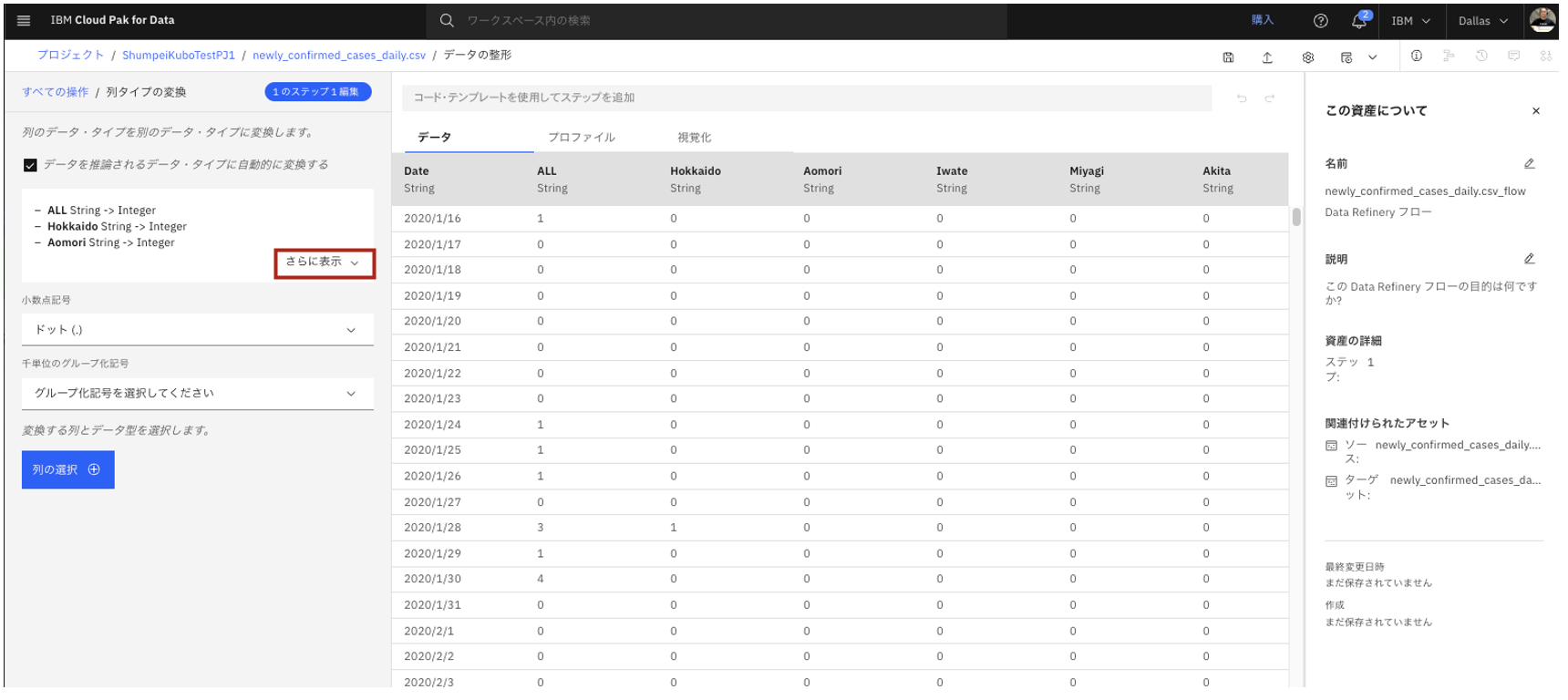
- 各列のデータ型が、StringからIntegerに変換されるように既に設定されていました。
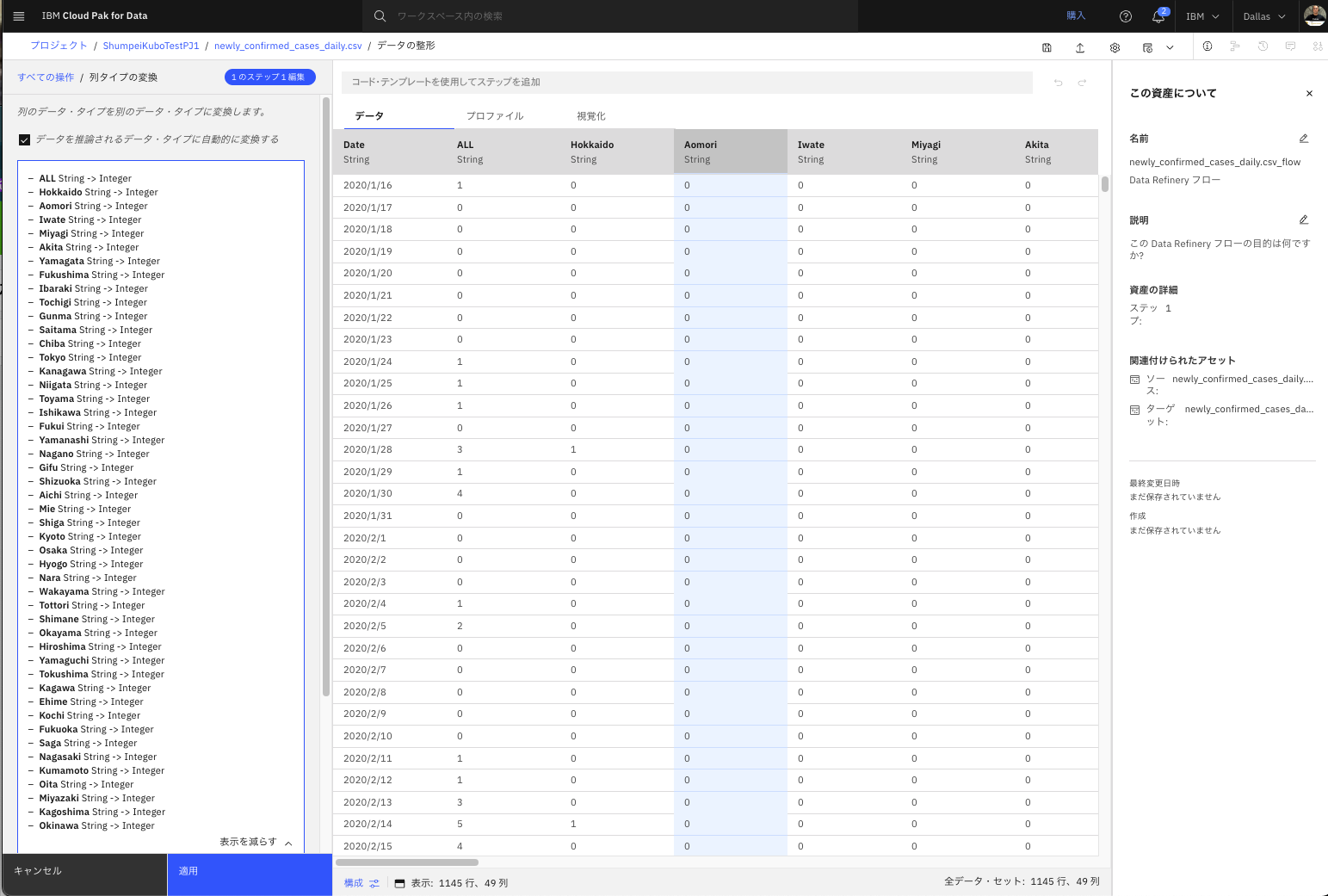
- 今回は、「Date」列に関して、String型からDate型に変換したいのですが、その設定はされていないので、画面左下の青い「列の選択(+)」ボタンをクリックして、Date列の型の変換を行います。
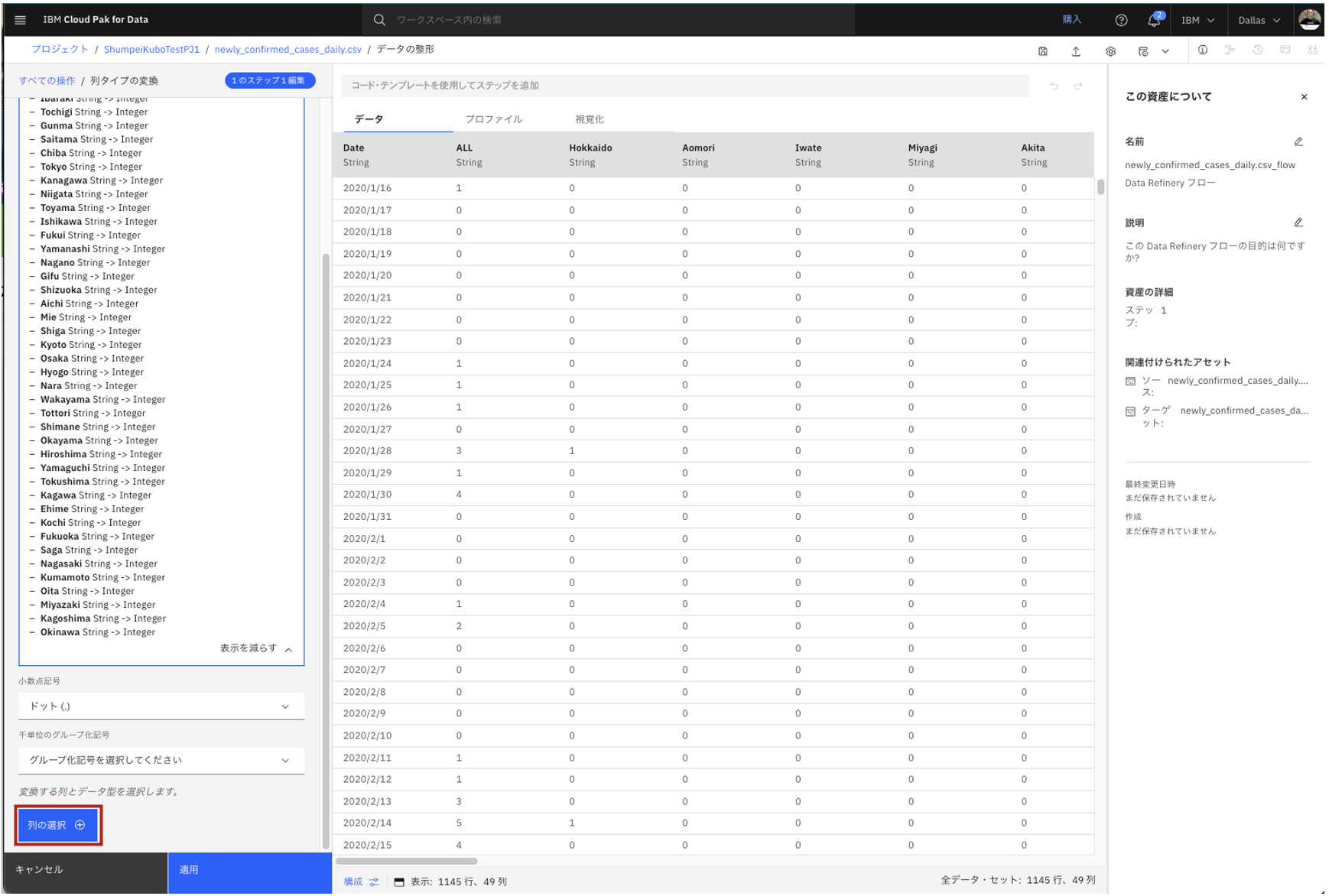
-
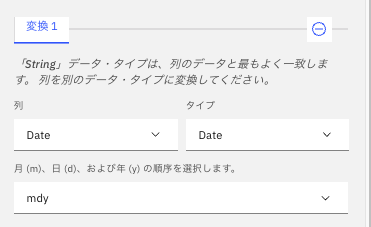
Date列について、現状String型になっていることがわかります。「String」と表示されているドロップダウンリストをクリックします。
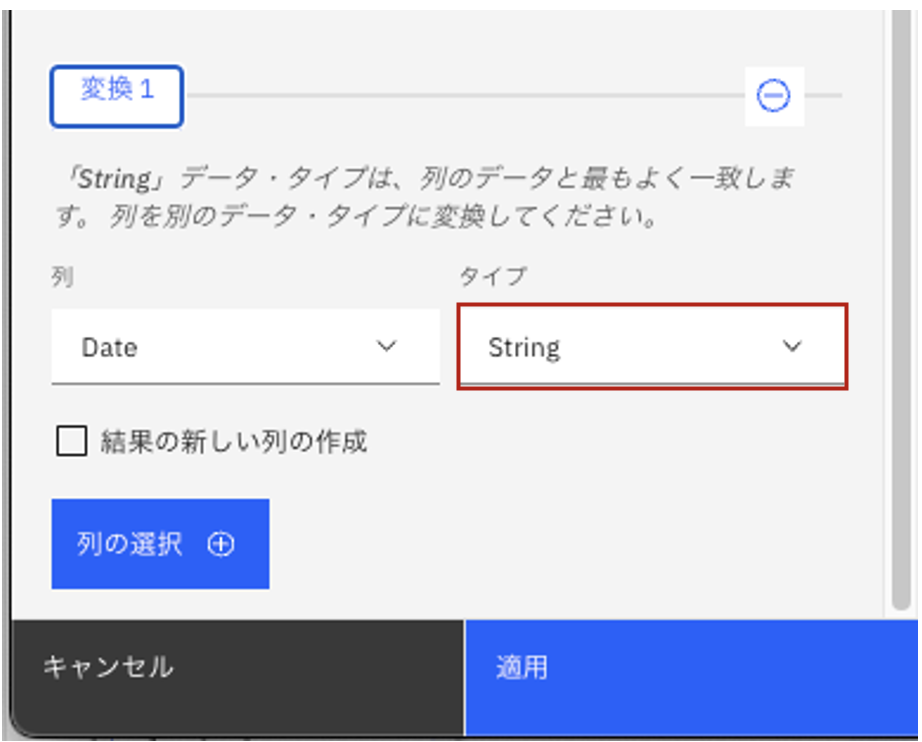
-
「Date」を選択します。
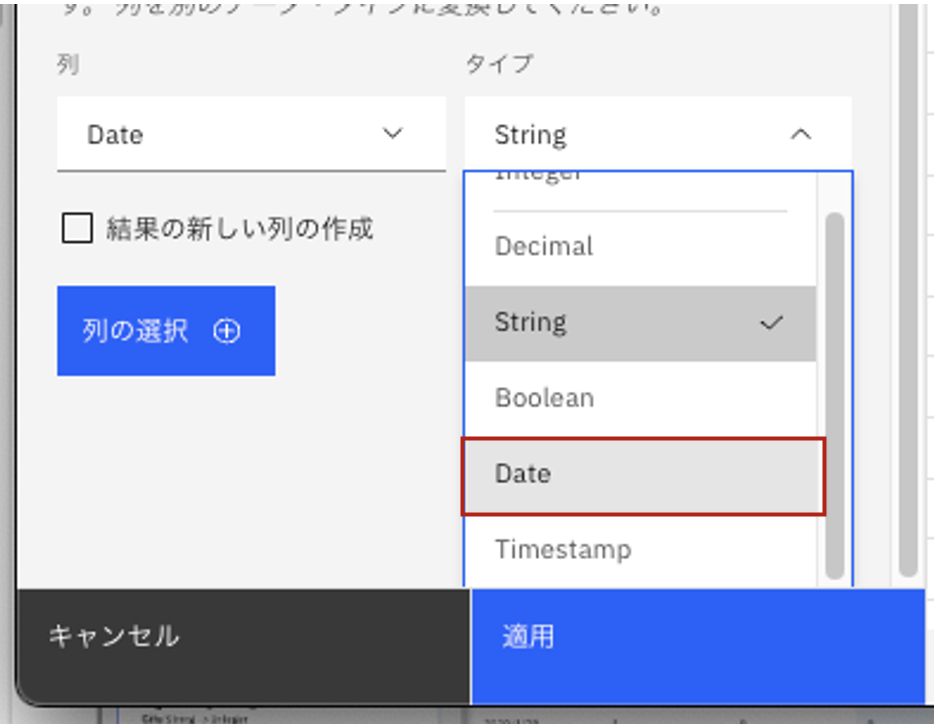
-
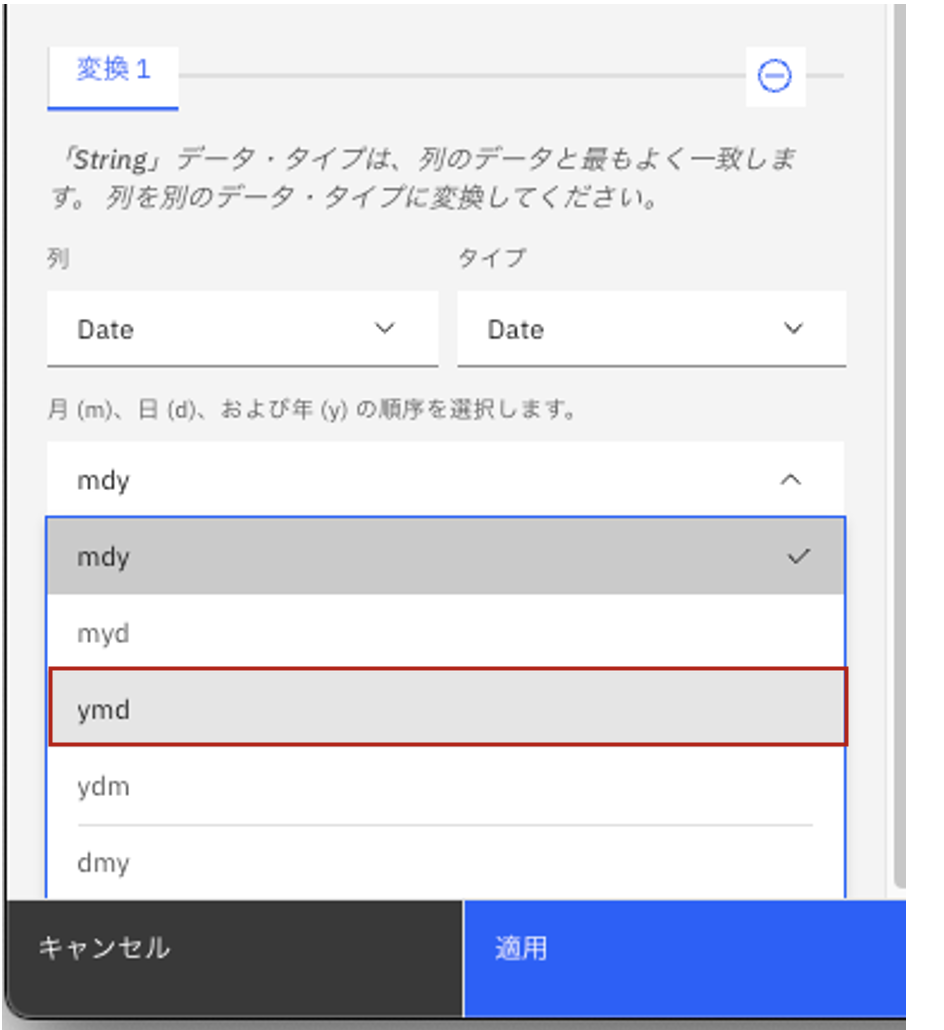
年月日の順序として、「ymd」を選択します。
-
この状態で、画面左下の青い「適用」ボタンをクリックします。
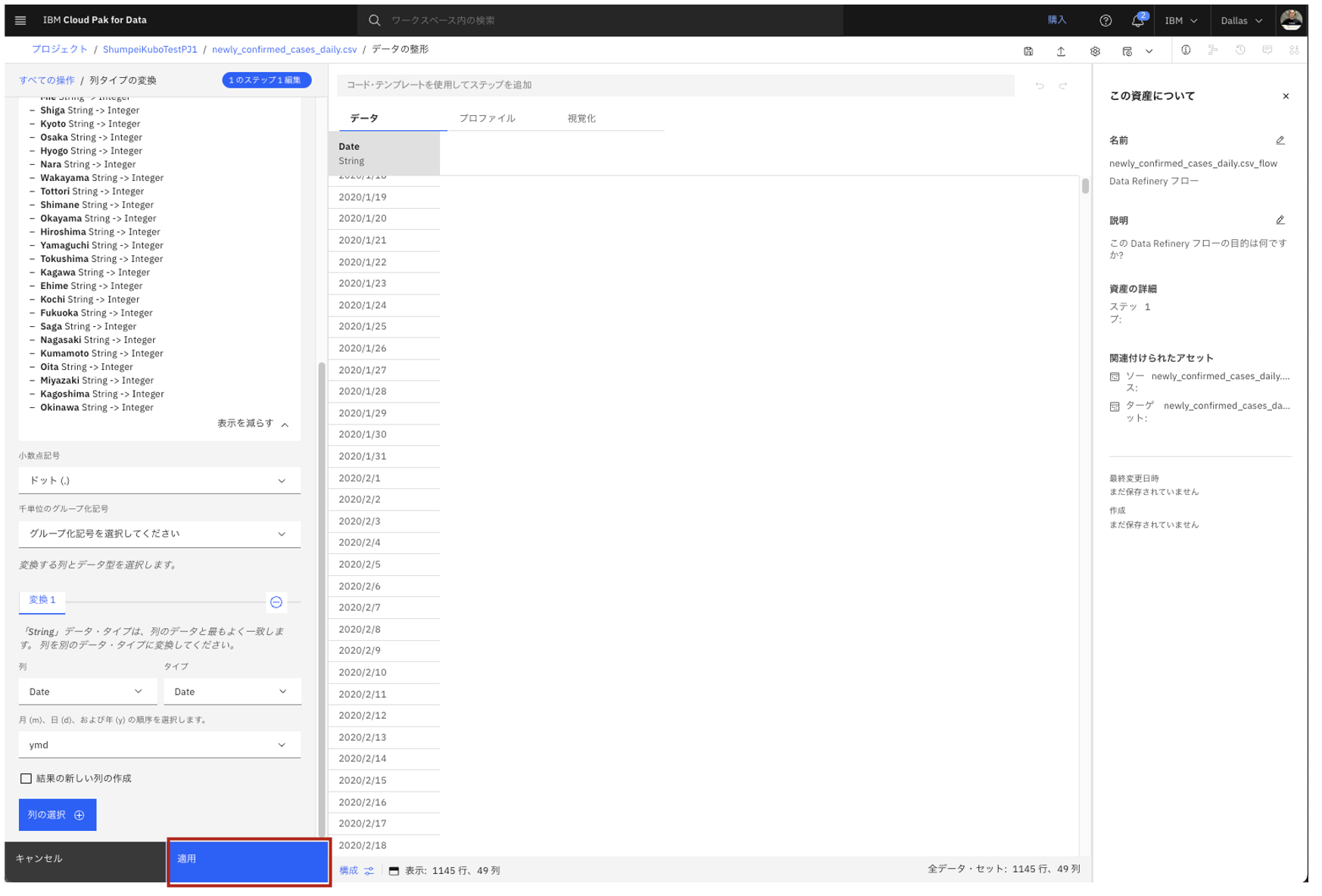
- Date列がDate型に変わっている事がわかります。
- また、その他の列もInteger型に変わっている事がわかります。
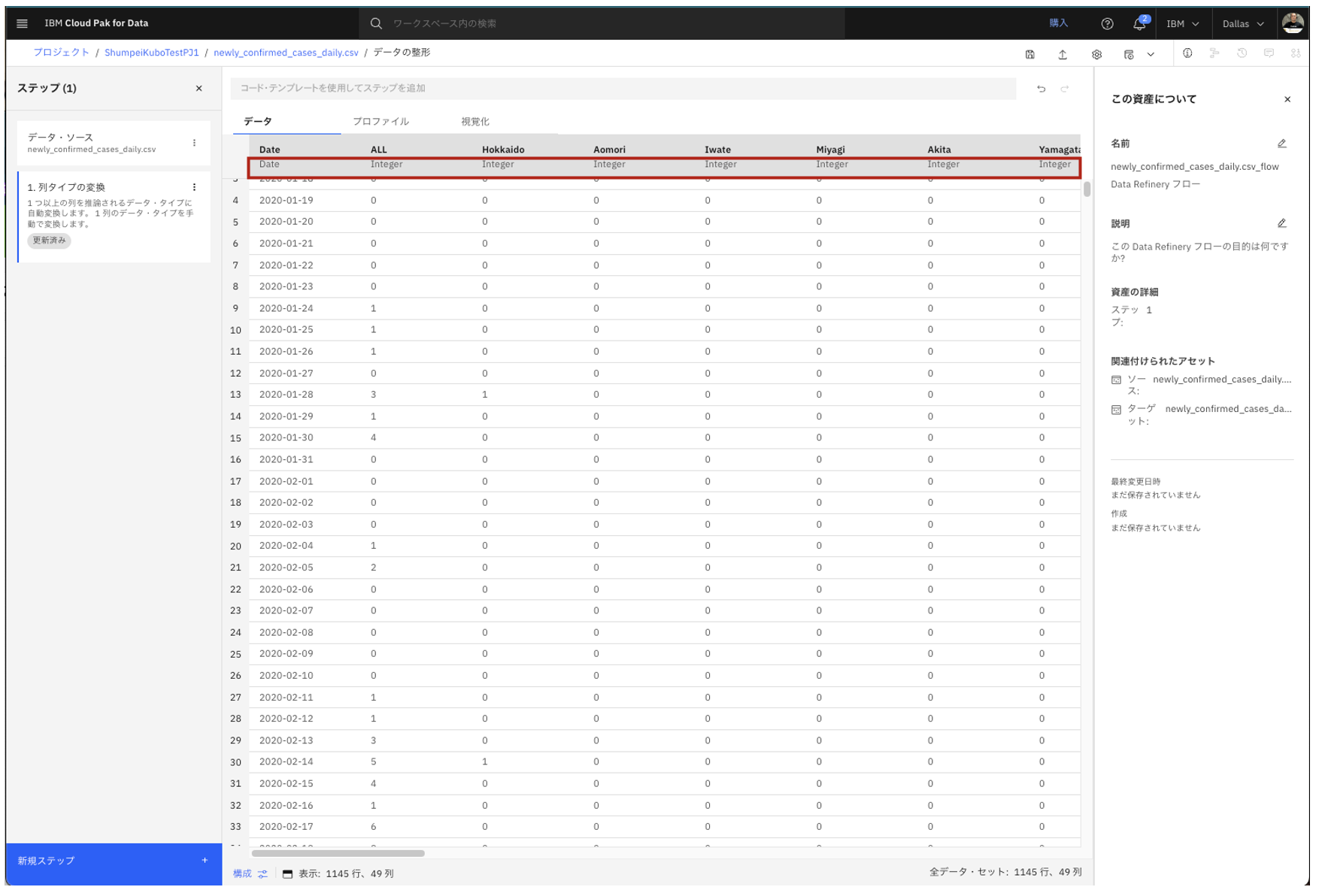
2.2.2. データフロー設定を変更(今回は確認)するオペレーション
- 画面右上の歯車のアイコン(フロー設定)をクリックします。
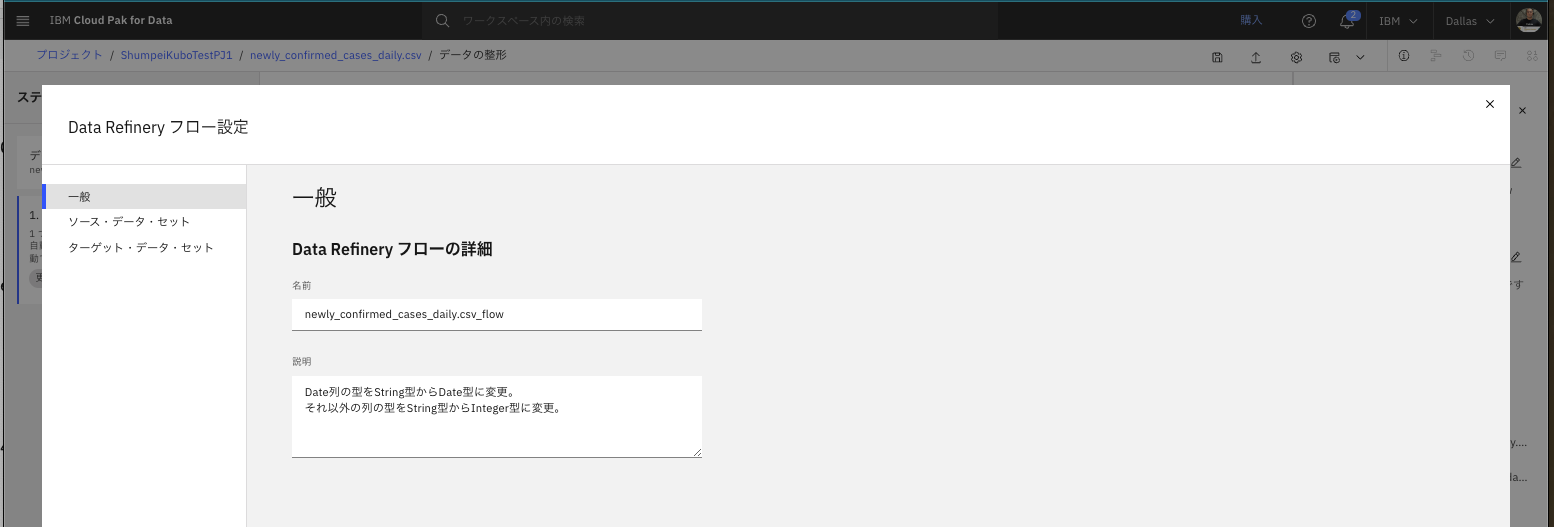
2.2.2.1. 一般 タブ
- フロー名を確認し、任意で説明を入力します。
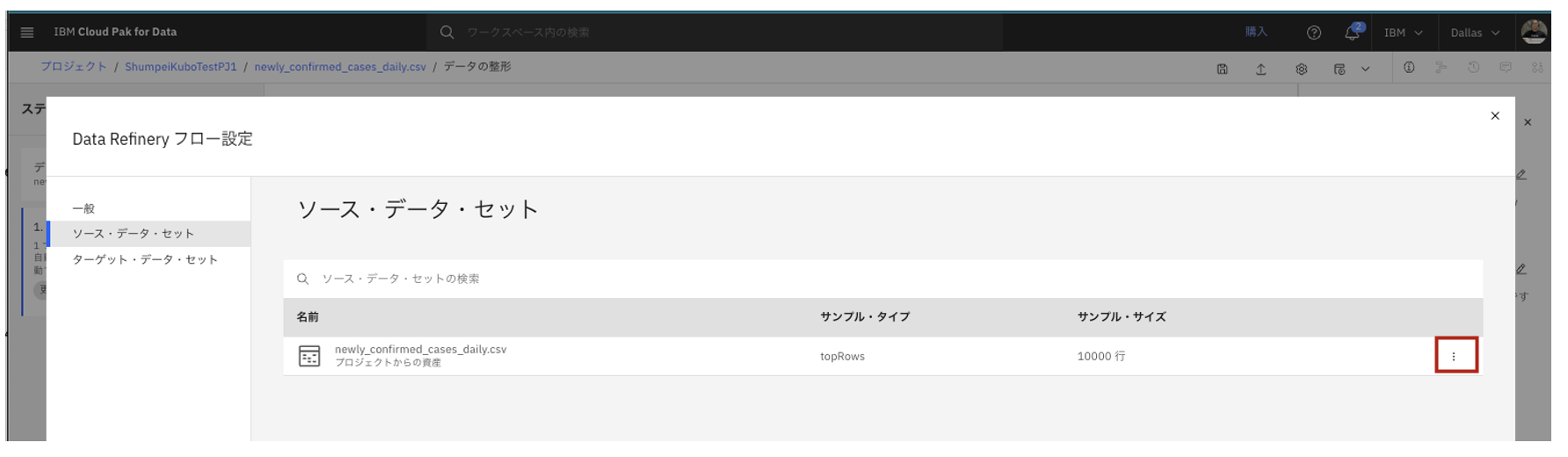
2.2.2.2. ソース・データ・セット タブ
- 元となるデータソースの情報を確認します。
- データソースの右端の三点リーダーの箇所から、各種設定の変更が出来ます。
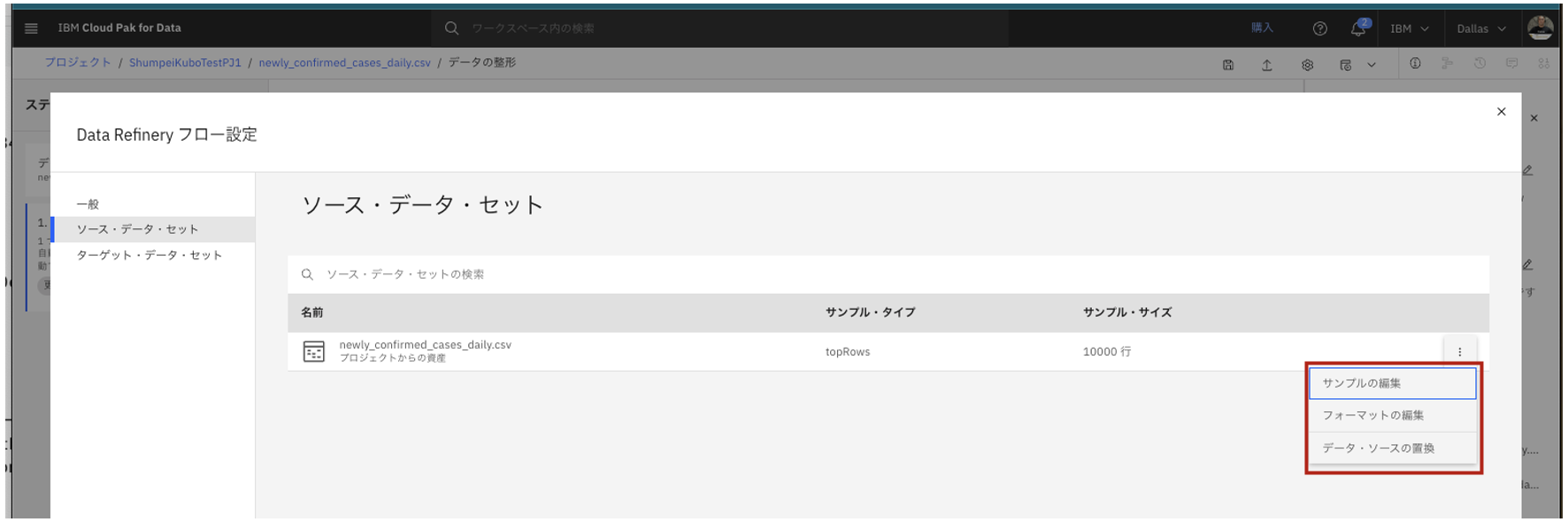
サンプルの編集
- サンプルとして使用される行数を編集出来ます。デフォルトは1万行です。
- 今回は何もせず、画面下の「キャンセル」をクリックして戻ります。
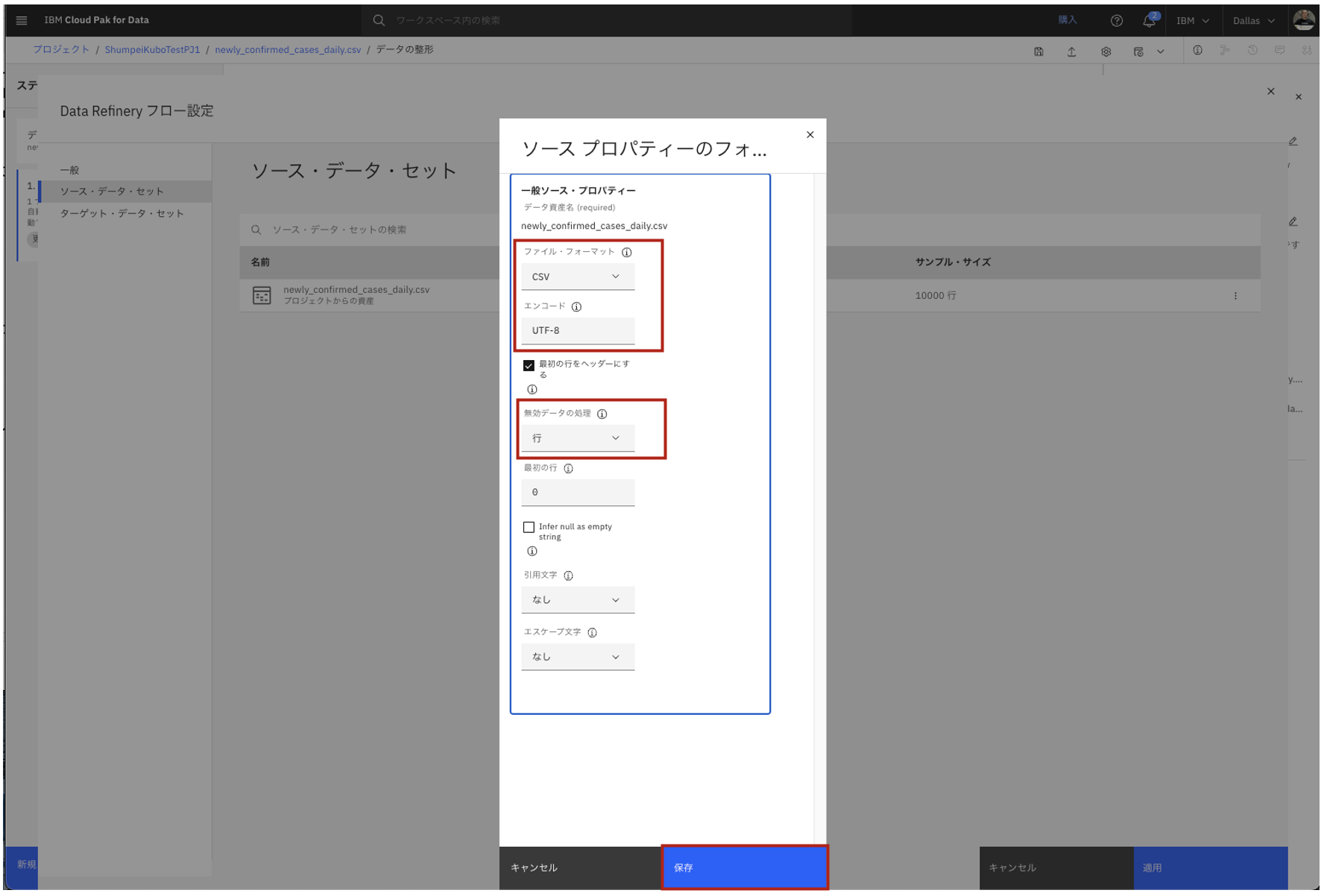
フォーマットの編集
- ファイル・フォーマットがcsv、エンコードがUTF-8であることを確認します。
- また、無効データの処理、の箇所を「失敗」から「行」に変更します。
- この場合、無効なデータがあった場合、ジョブが失敗することなく、該当データを含む行が除去されます。
- 今回は「保存」をクリックします。
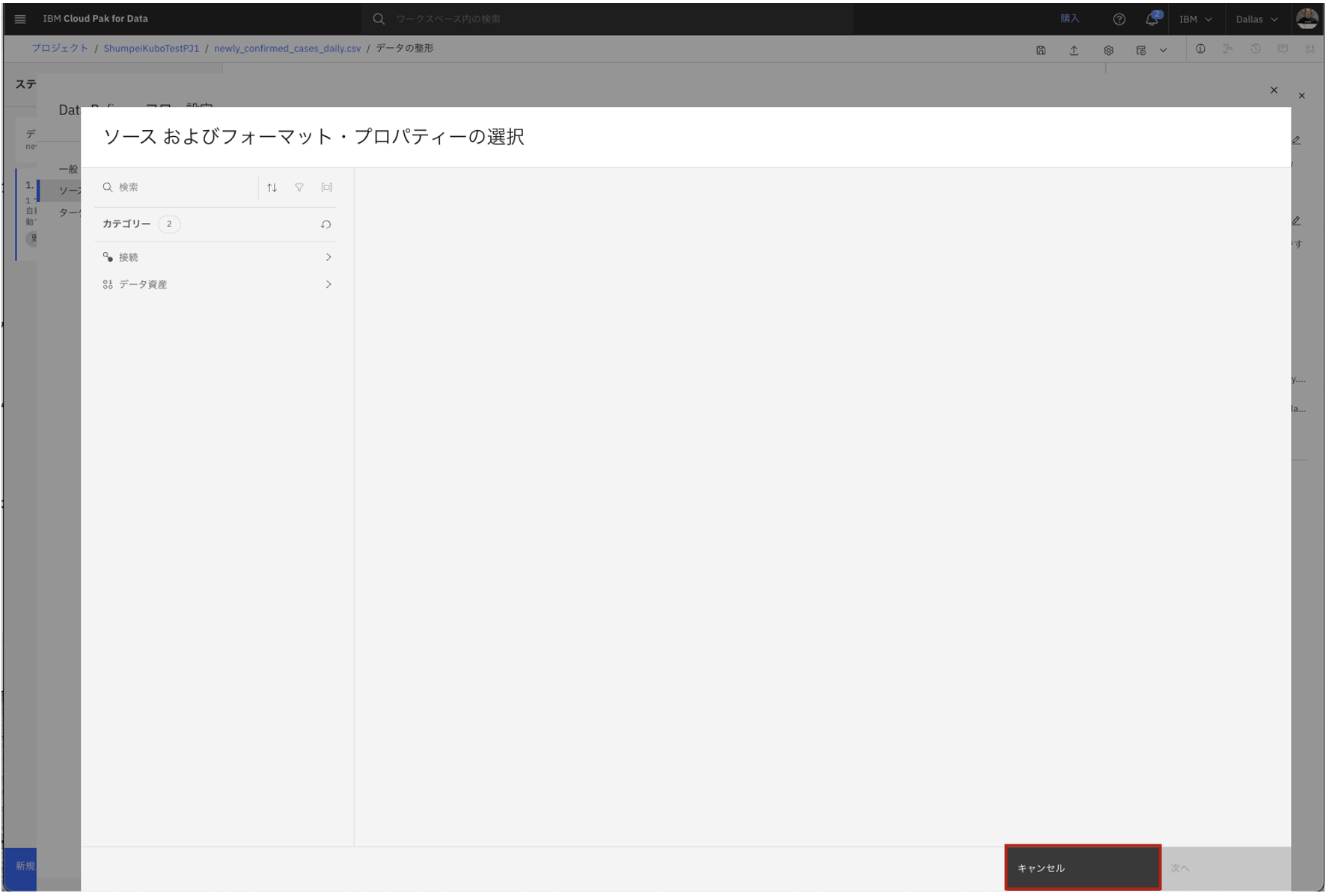
データ・ソースの置換
- ここをクリックすると、置き換える為のデータ・ソースを選択できる画面に出ますが、今回はデータ・ソースは変更しませんので、キャンセルをクリックします。
2.2.2.3. ターゲット・データ・セット タブ
- 処理した後のデータの設定です。デフォルトでは、ICOS(IBM CLoud Object Storage)上にcsvファイルとして保存されます。
- 設定を変えたい場合は、「ターゲットの選択」をクリックします。
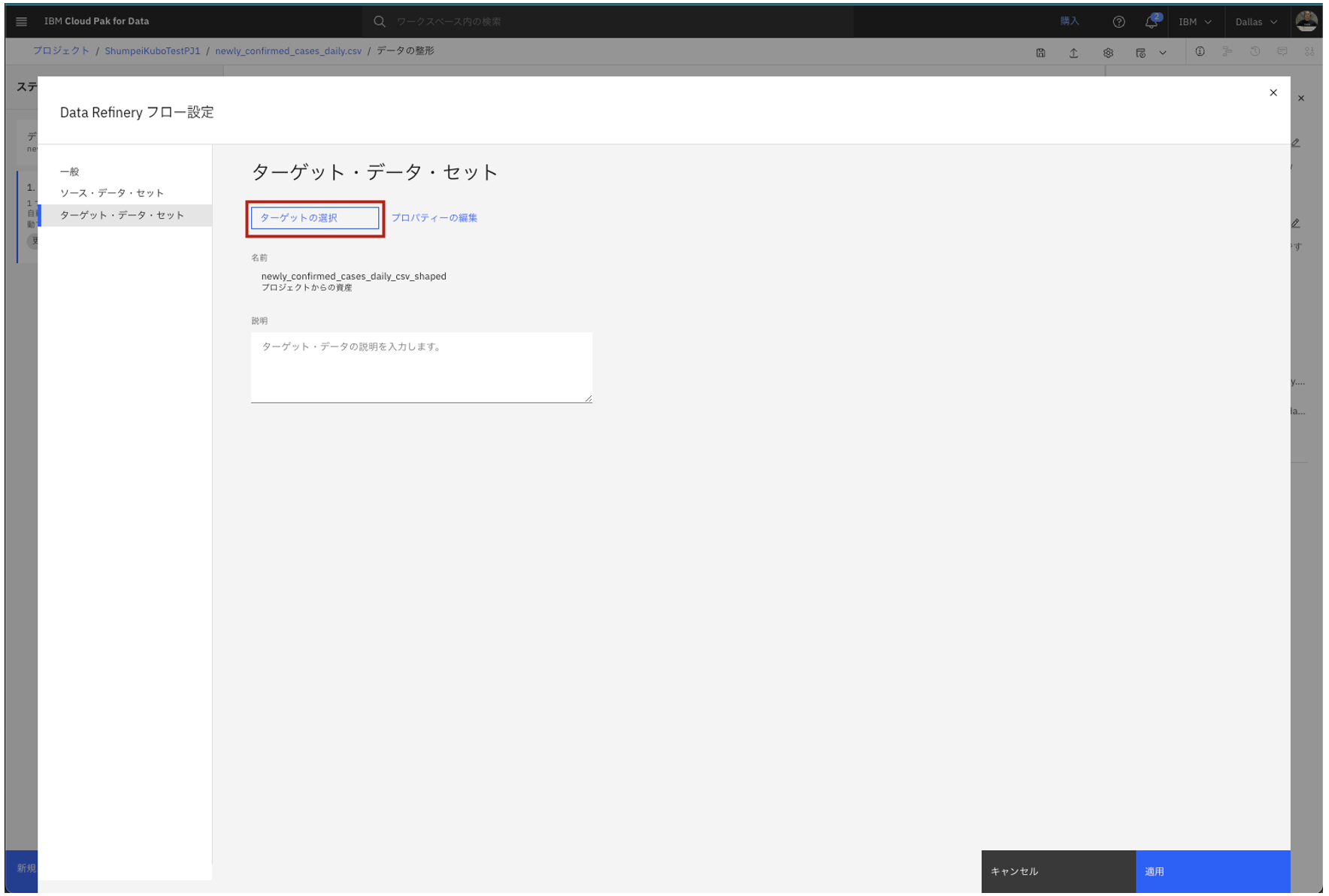
- 変更したいデータターゲットを一覧から選択出来ます。(プロジェクト内に存在している必要があります)
- ですが今回は設定は変更しない為、「キャンセル」をクリックして画面を戻ります。
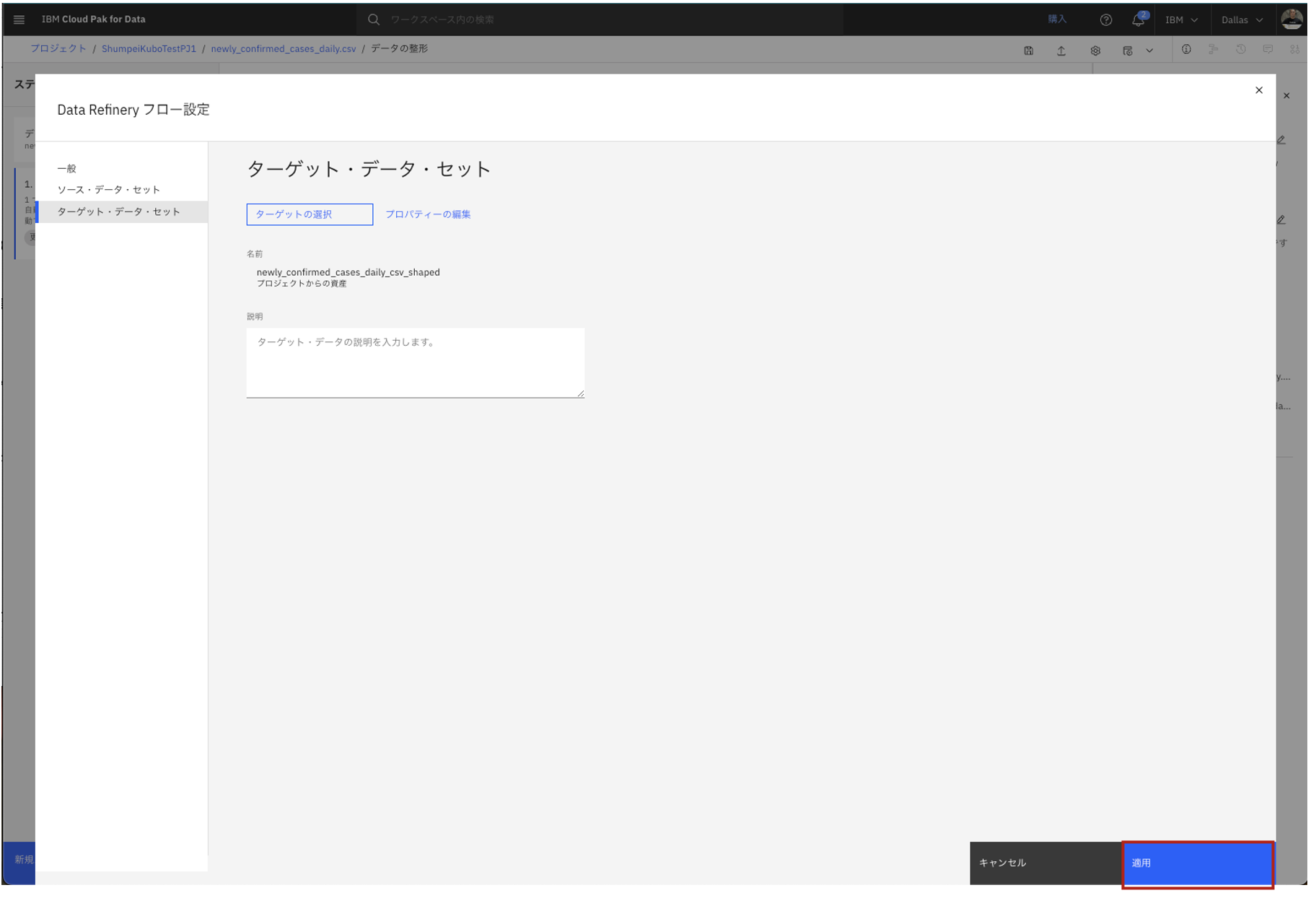
- 「一般」「ソース・データ・セット」「ターゲット・データ・セット」の設定が完了したら、画面右下の青い「適用」ボタンをクリックします。
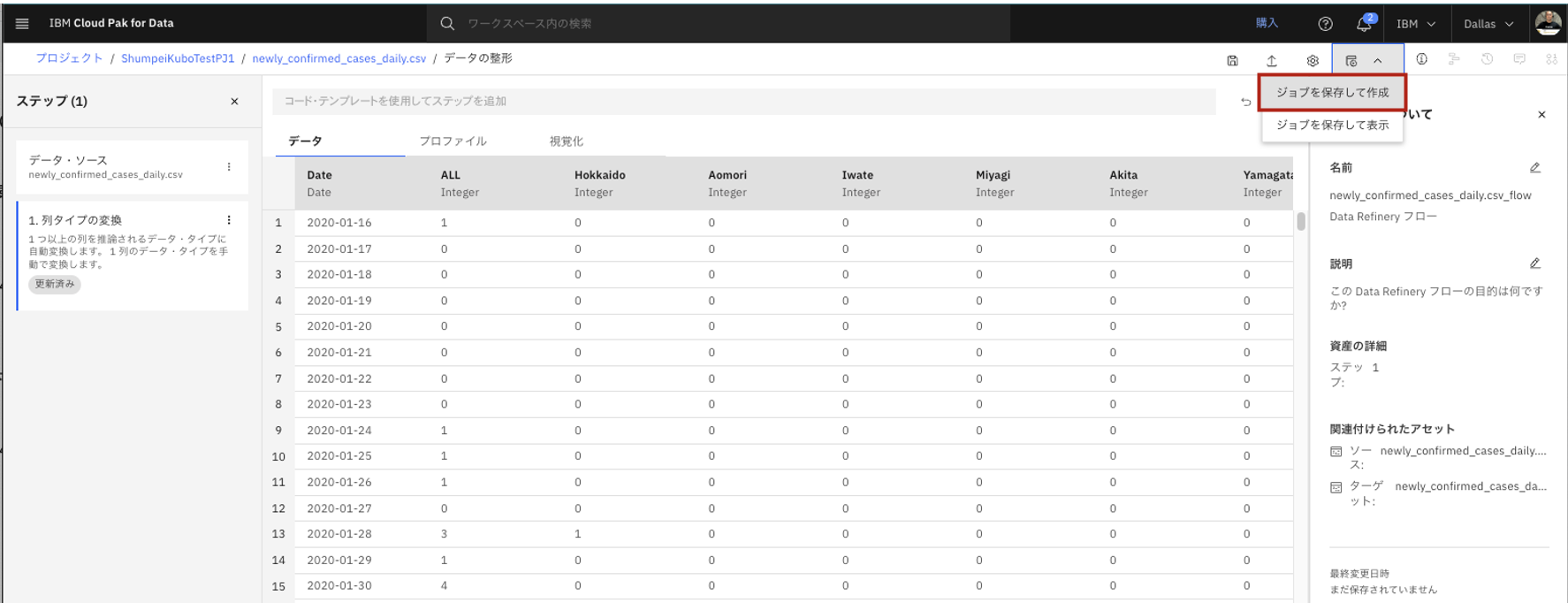
- データ修正内容が固まったので、画面右上の「ジョブを保存して作成」をクリックします。
- データ修正を実行するジョブを作成して行きます。ジョブ名および説明を入力して「次へ」をクリックします。
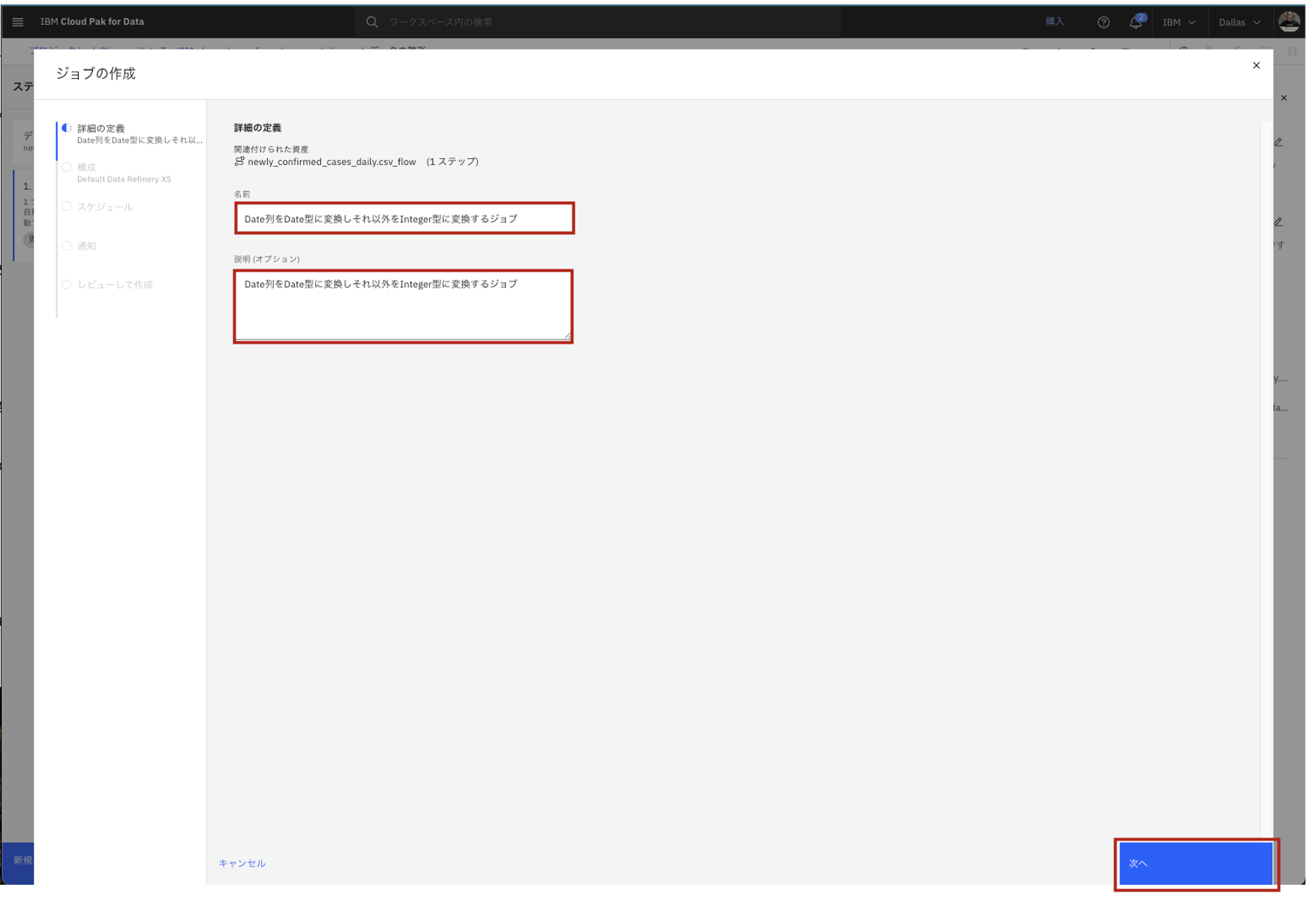
- 「構成」については表示されたままで「次へ」をクリックします。
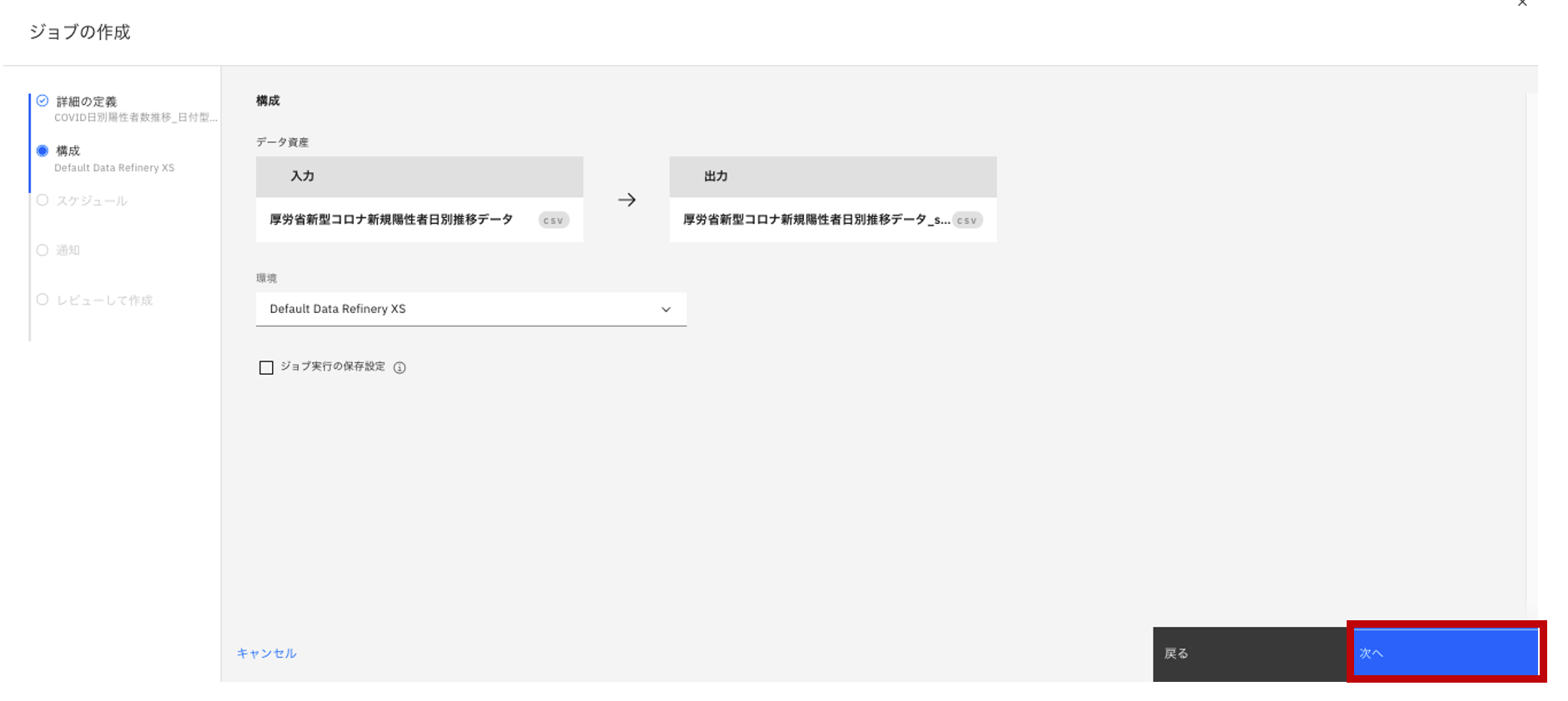
- スケジュールについては今回は設定せずに「次へ」をクリックします。
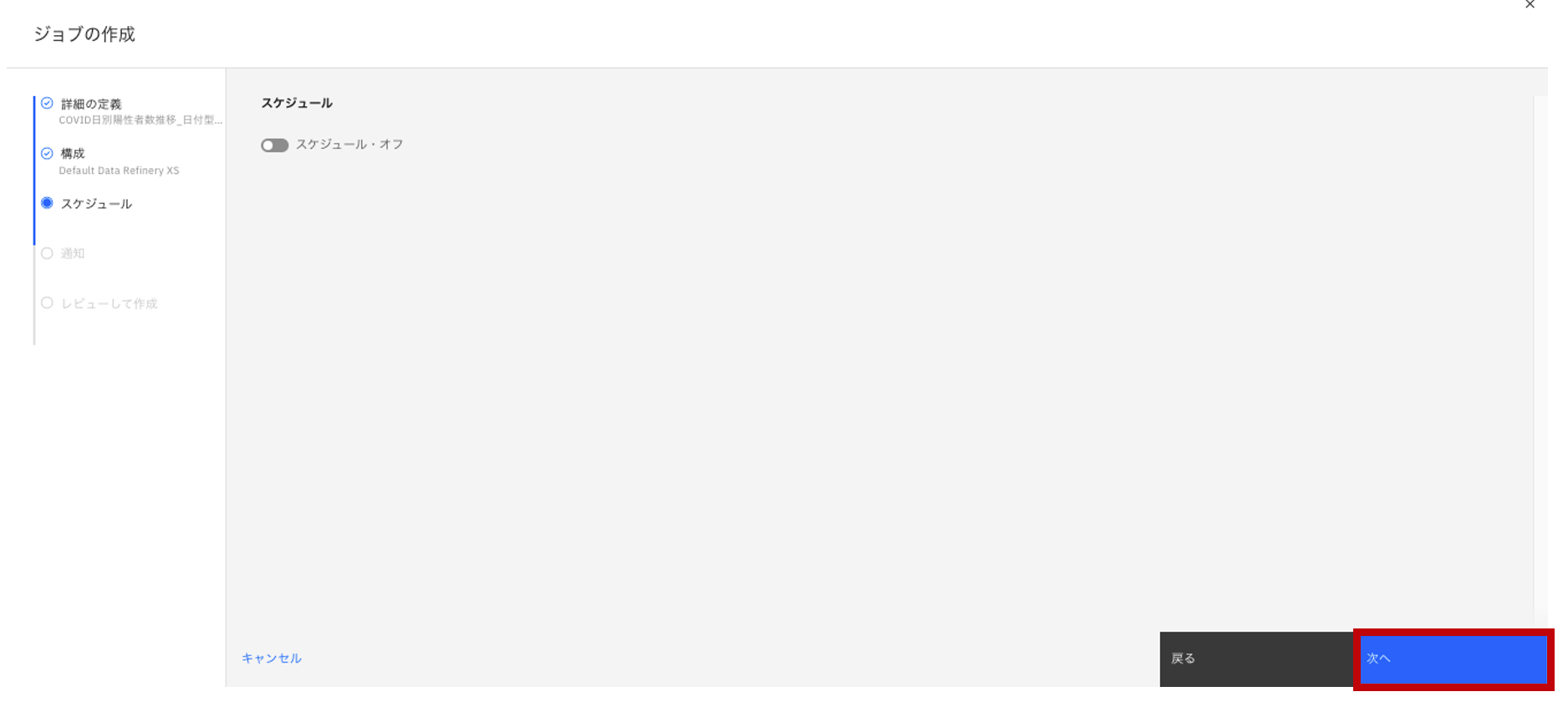
- 「通知」については、当初はOFF状態なのですが、ジョブが終わる情報がすぐわかるので、今回はONにして「次へ」をクリックします。
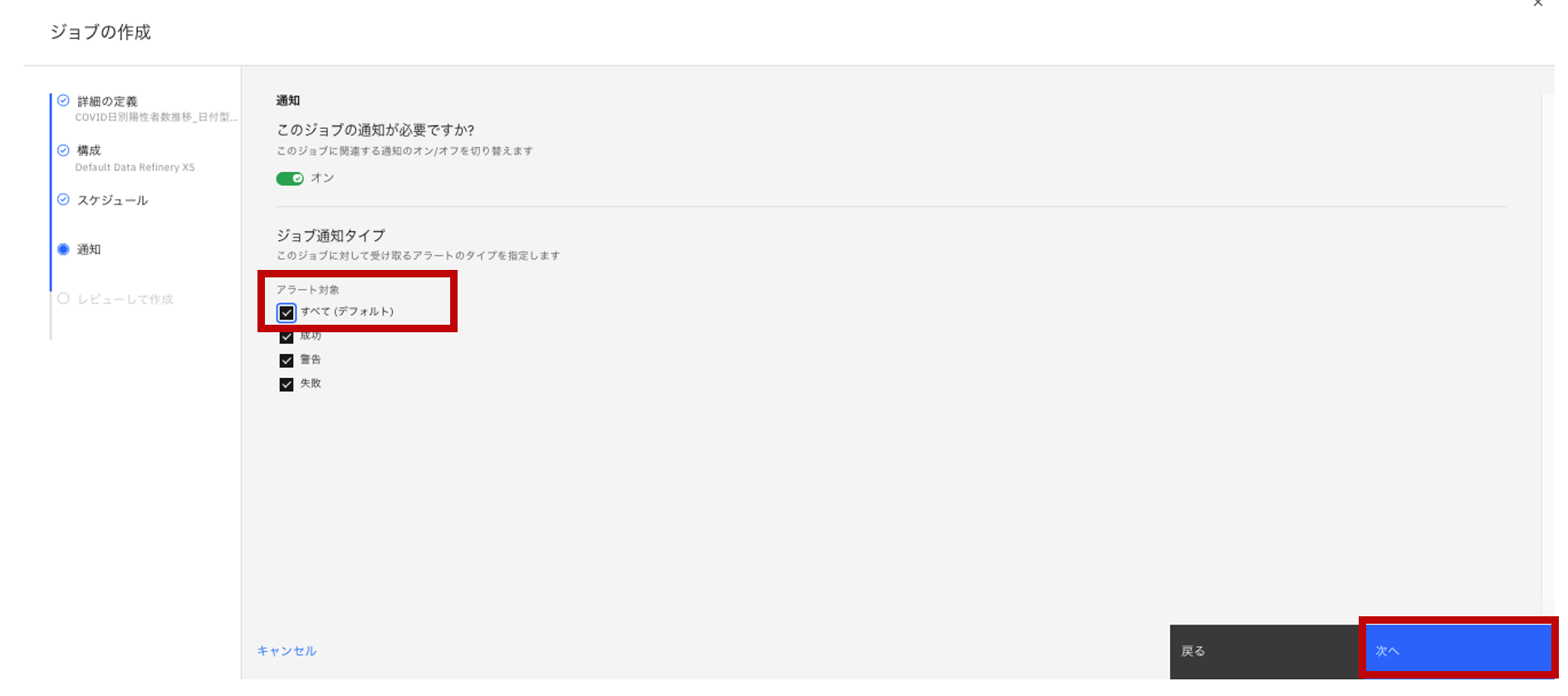
- ジョブの内容を確認して「作成して実行」をクリックします。
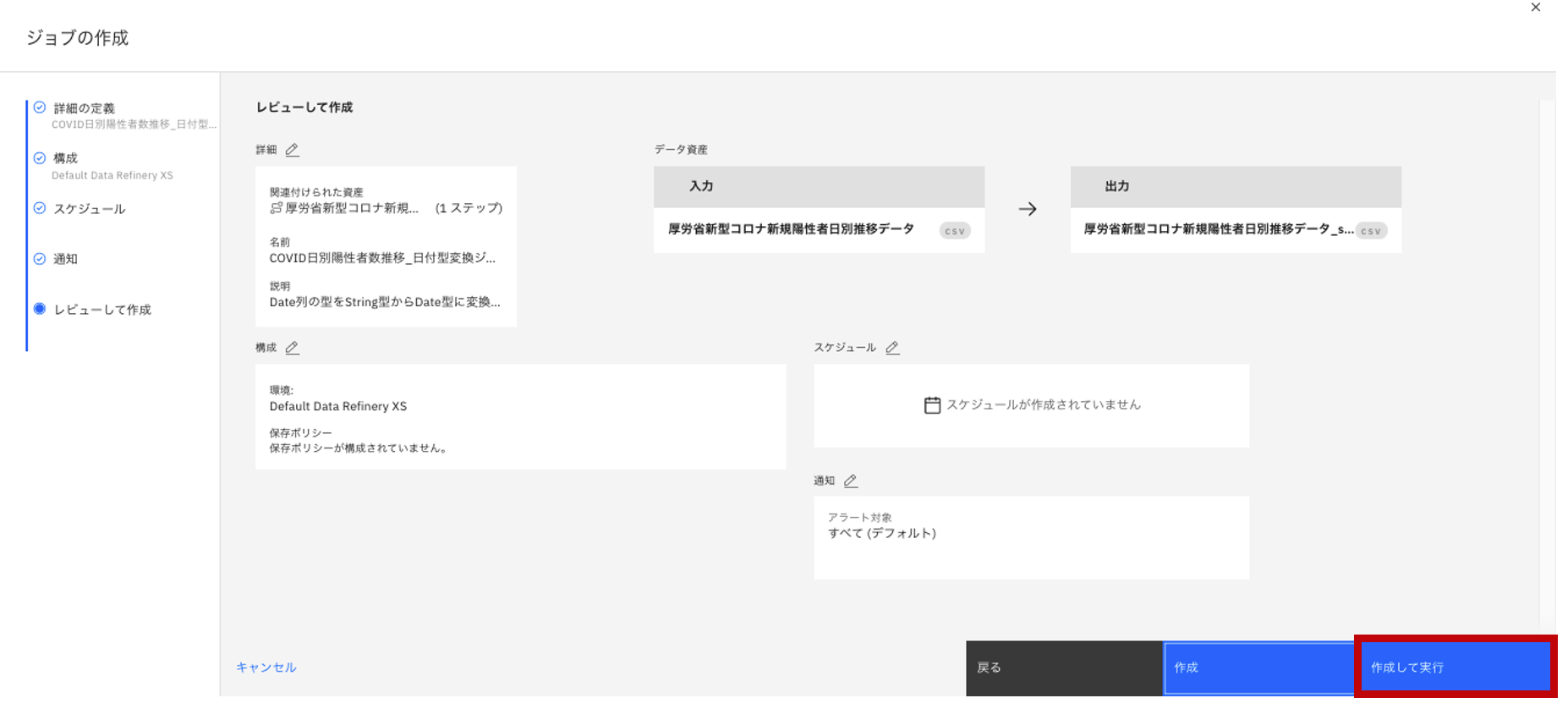
-
ジョブが作成されたのでポップアップが表示されます。「ジョブの詳細」をクリックします。
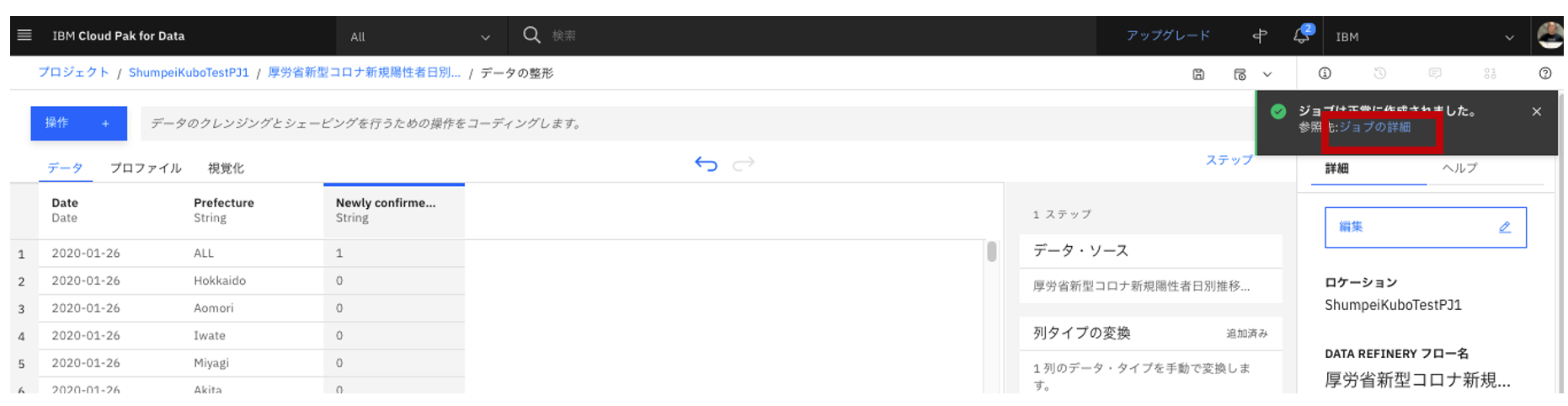
-
ジョブの一覧で、実行中のジョブが確認出来ます。

- そうこうしているうちにジョブが完了したようです。
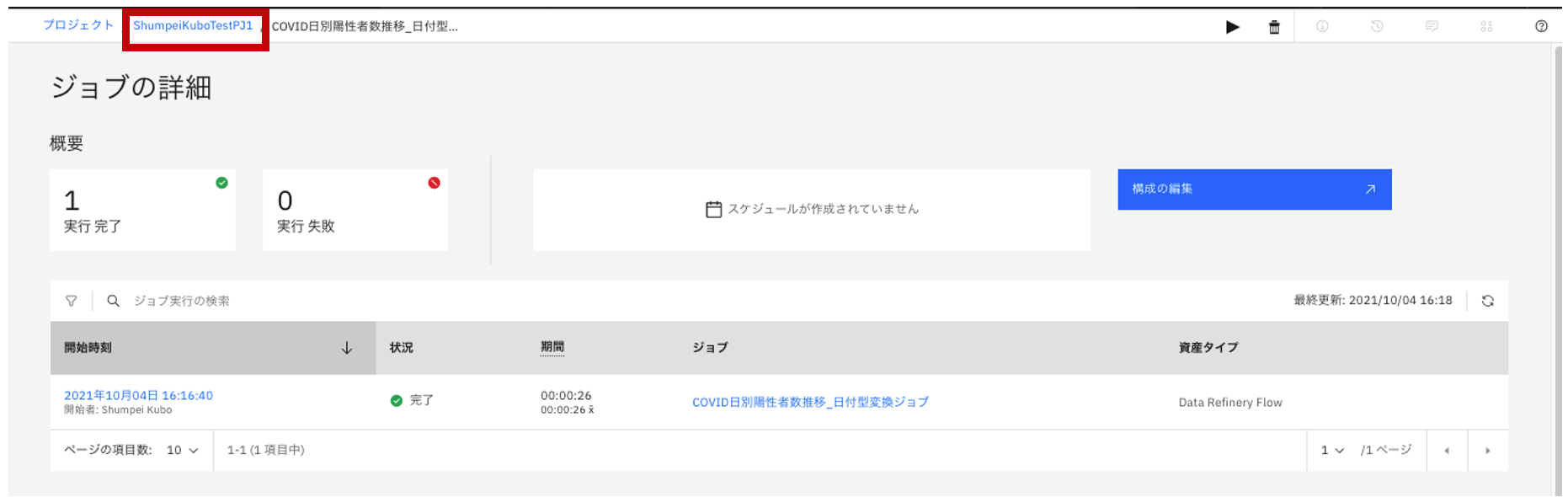
- ジョブをクリックすると、状態として「完了」していることがわかります。プロジェクトの「データ資産」タブへ戻ります。
- プロジェクト上で名前がすべて「?」になっているデータ資産があります。
- (ファイル名を日本語名称にしていた場合に限る)
- ファイル名として日本語は文字化けしてしまうようです。

- ファイルをクリックして中身を確認します。日付の表示の仕方が変更されていることがわかります。
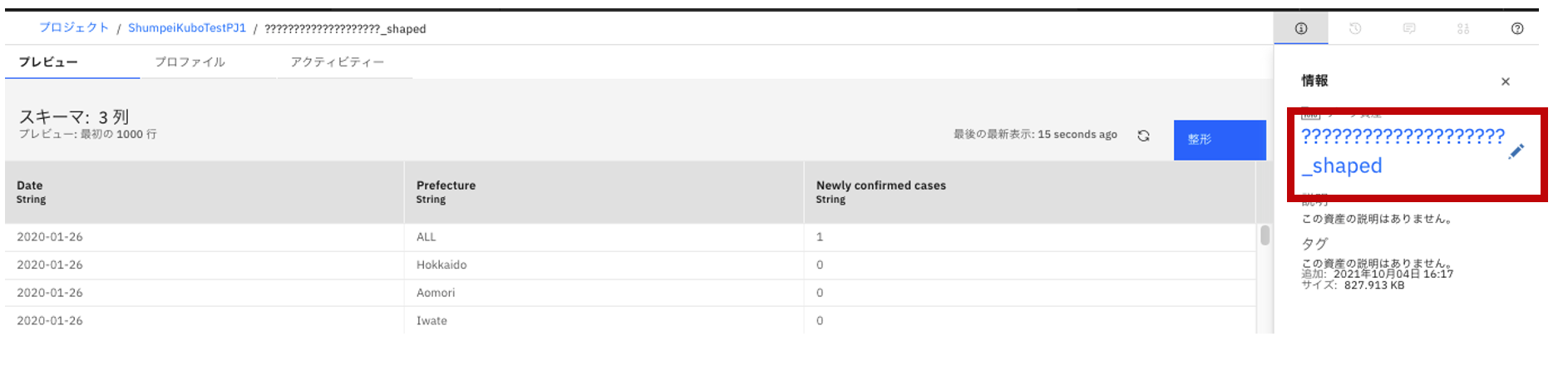
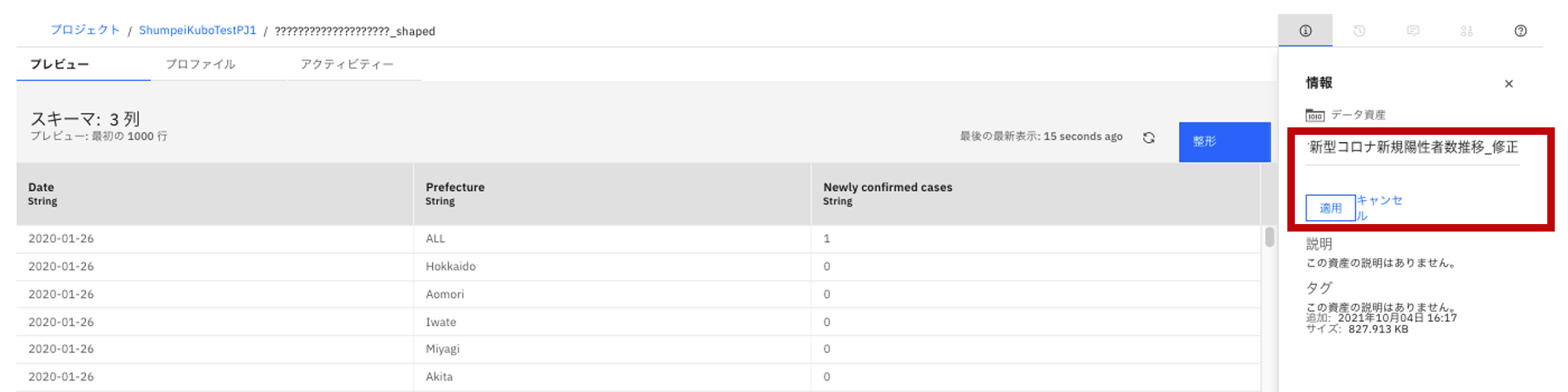
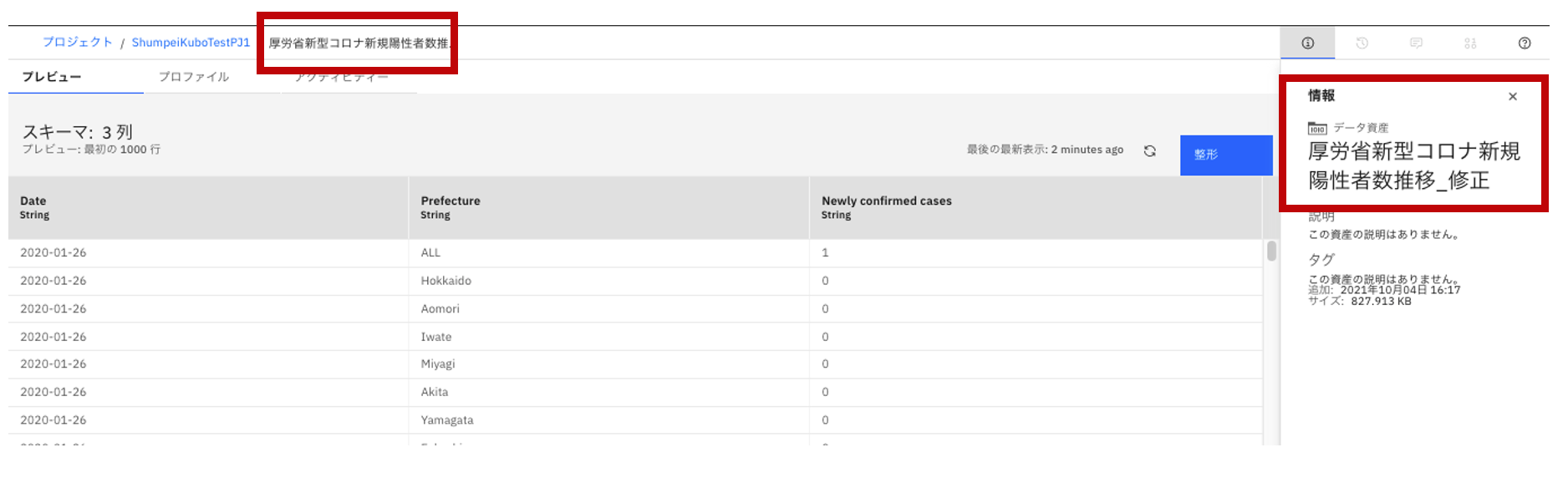
- 画面右側のファイル名の箇所をクリックして、ファイル名を修正します。
2.2.ダッシュボード作成
2.2.1.全体データのみ表示
- プロジェクトに戻ります。
- ここで、画面右上の「新規資産」ボタンをクリックします。
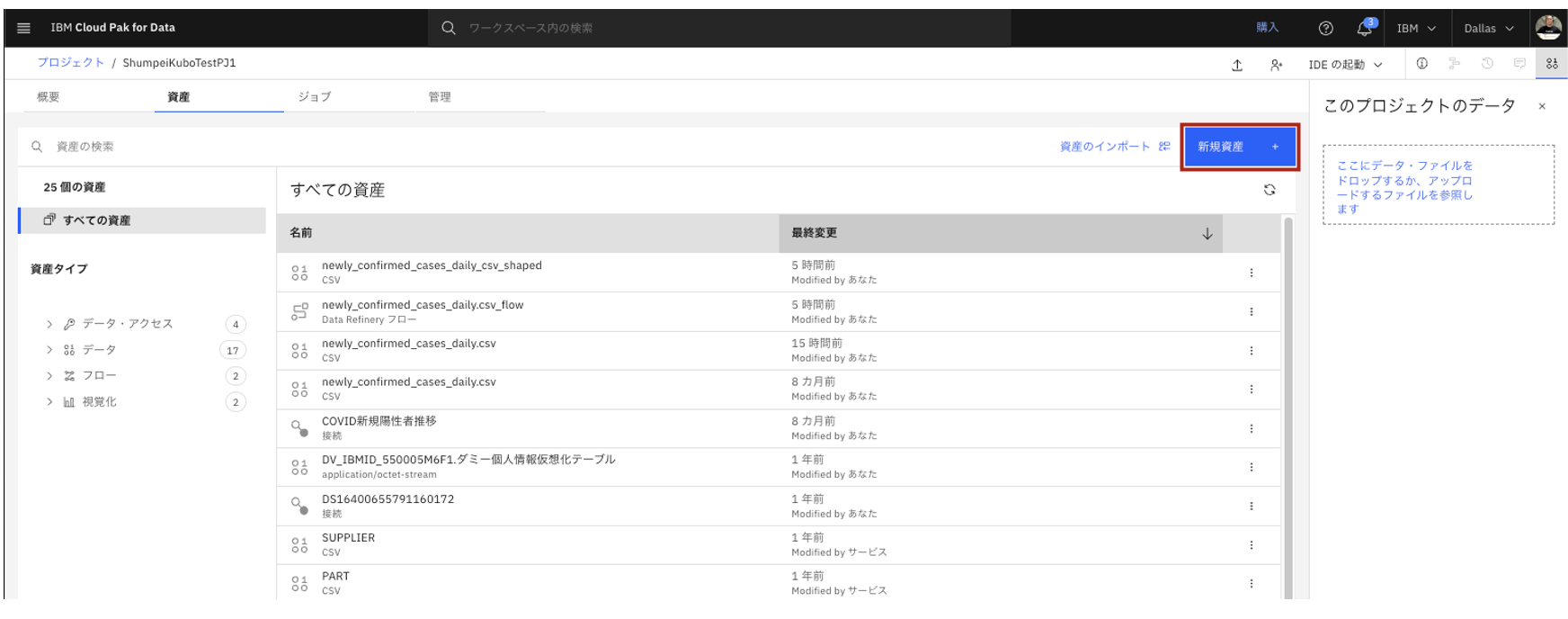
- 画面左側の「グラフィカルビルダー」を選択して、「ダッシュボード・エディター」をクリックします。
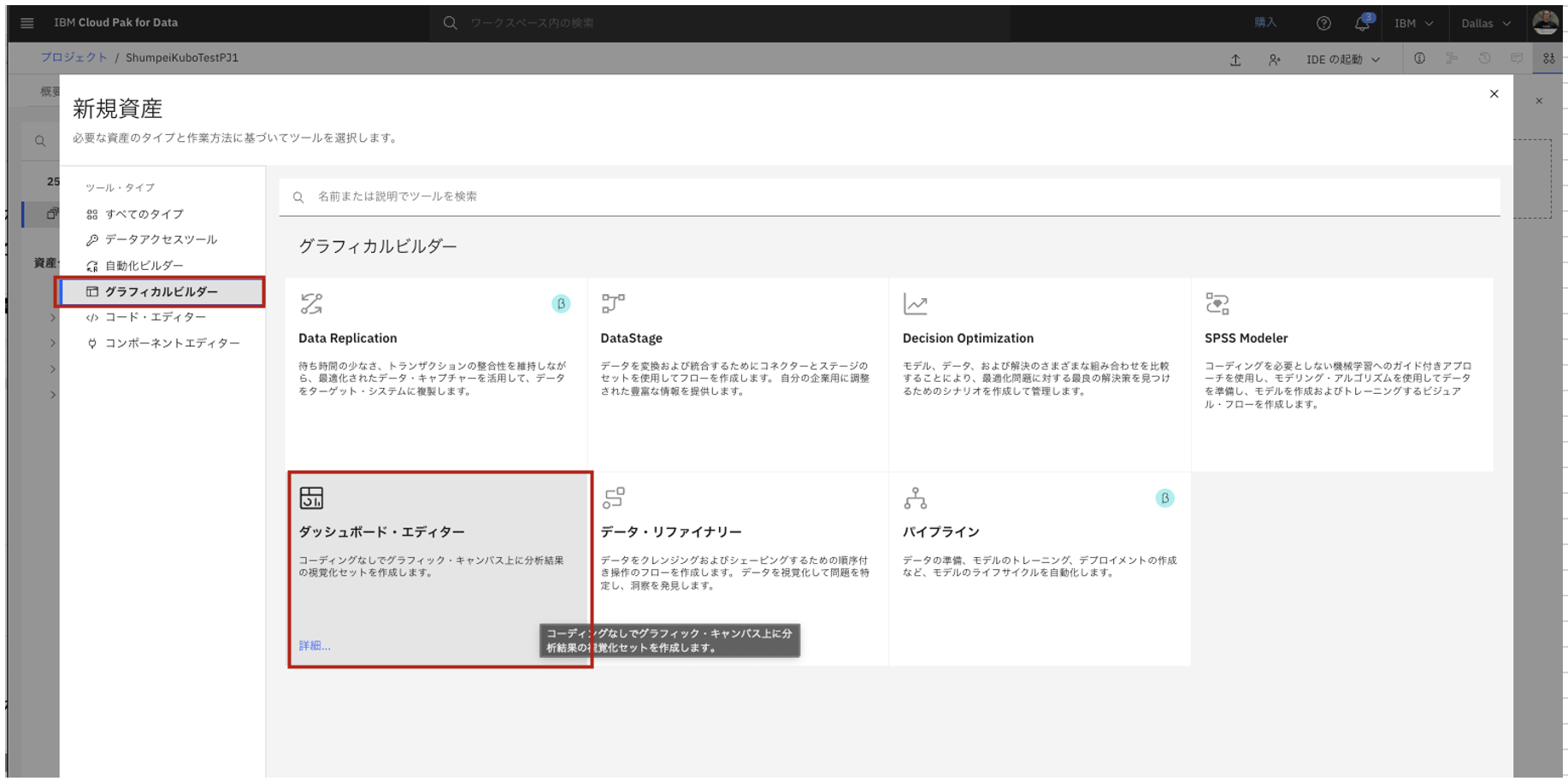
- 名前と説明を入力します。
- 「構成の定義」において、IBMloud上で現状稼働しているCognos Dashboard Embedded を選択します。(未設定の場合は新規サービスを構成してください。)
- 「作成」をクリックします。
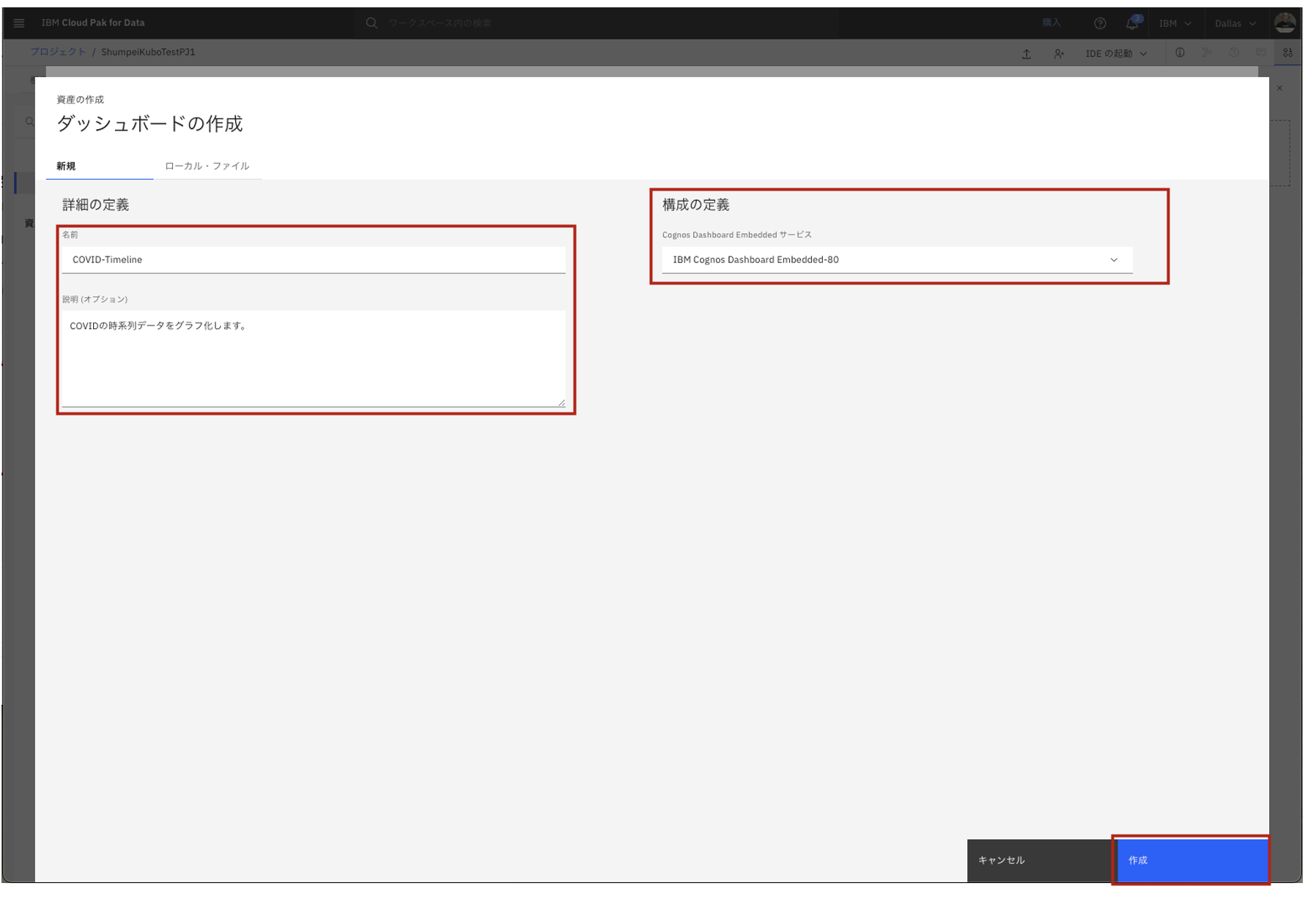
- テンプレートを選択します。ここでは最もシンプルなものを選択して、「OK」をクリックします。
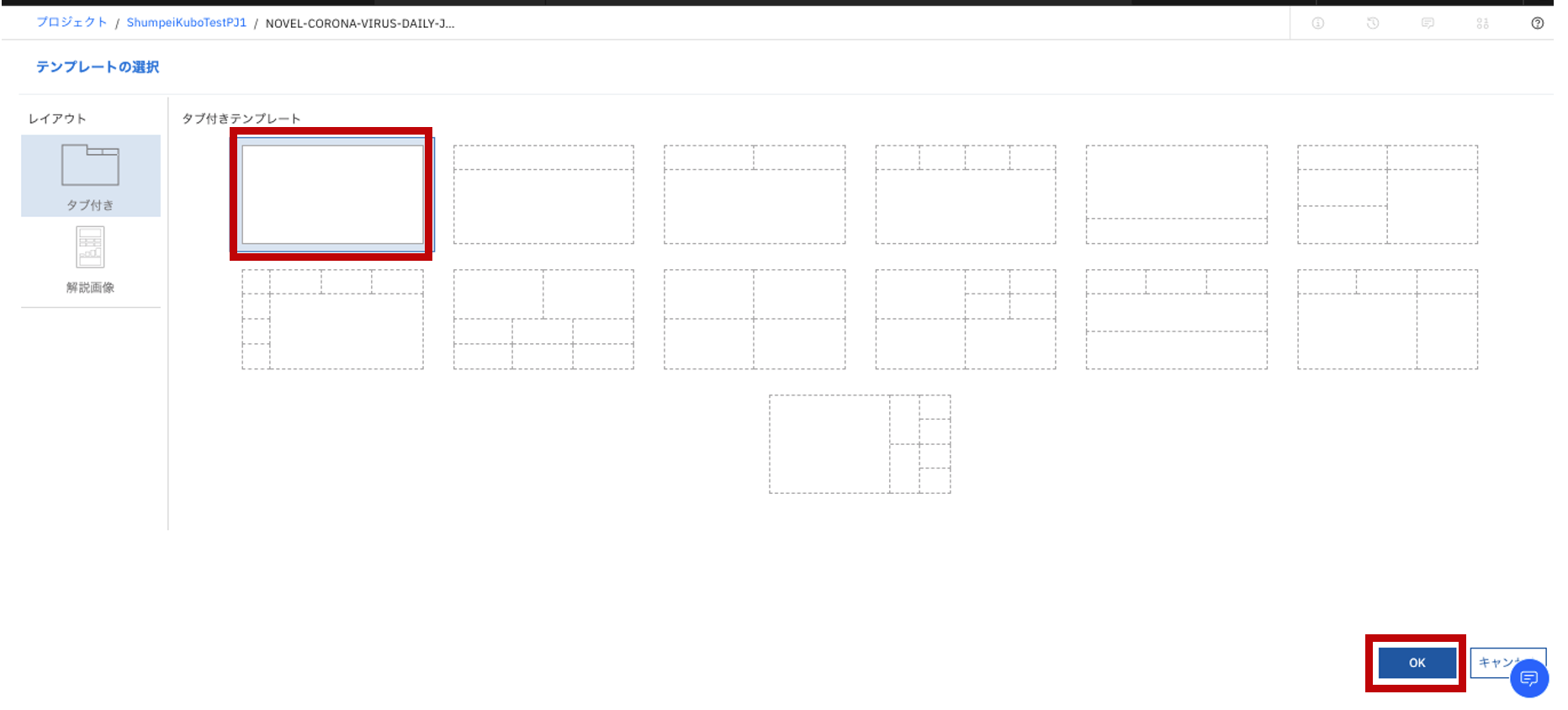
- データソースを選択するために画面左上の「+」ボタンをクリックします。
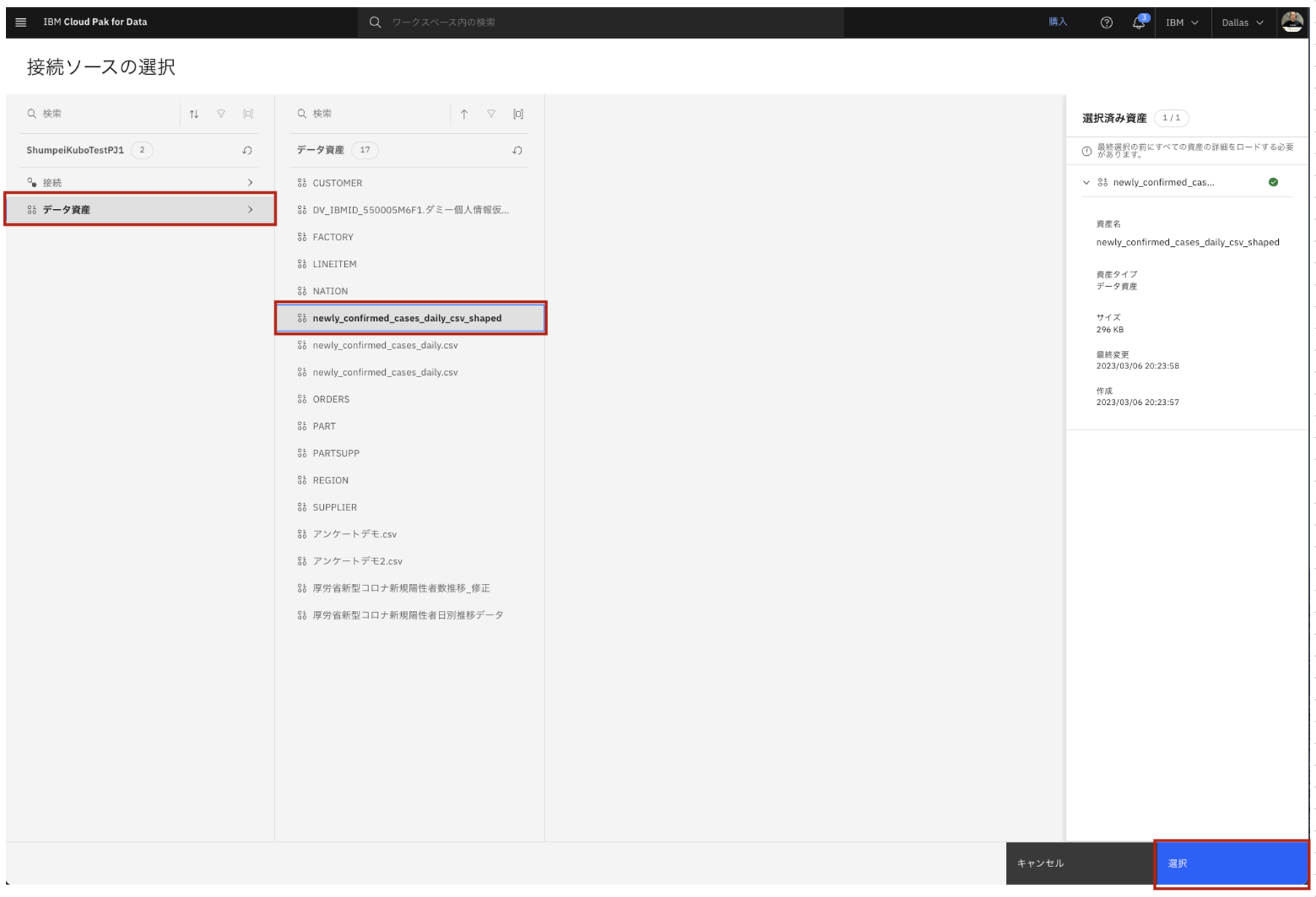
- データ資産をクリックし、先程修正したデータ資産を選択して「選択」ボタンをクリックします。
- 選択されたデータソース名をクリックします。
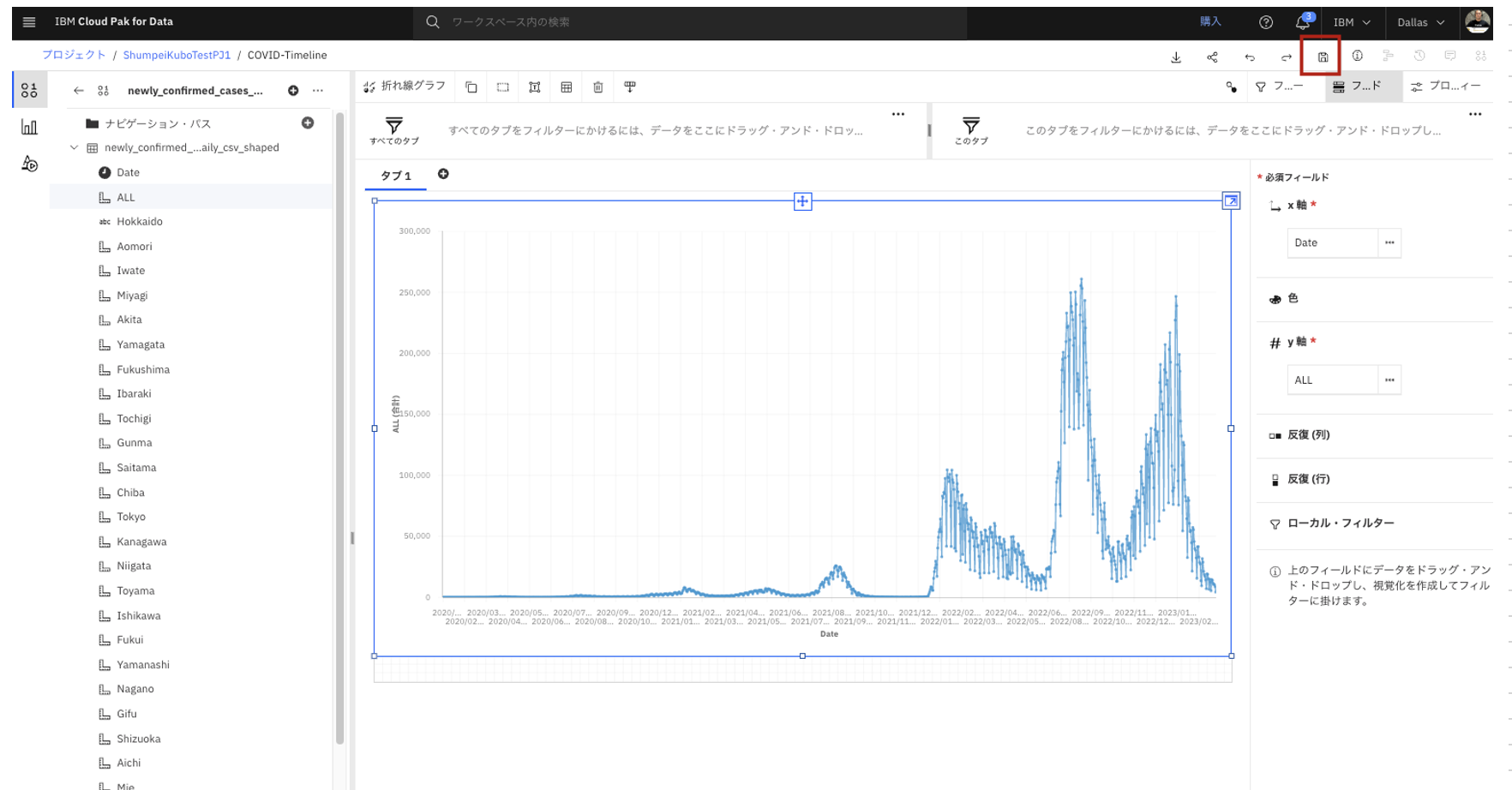
- データの列名が表示されます。画面左上のグラフのアイコンをクリックします。
- 複数表示されるグラフのうちから、「折れ線グラフ」を選択します。
- グラフのベースとなるものが表示されます。
- 「Date」を「X軸」の箇所にドラッグ&ドロップします。
- 「ALL」を「y軸」の箇所にドラッグ&ドロップします。
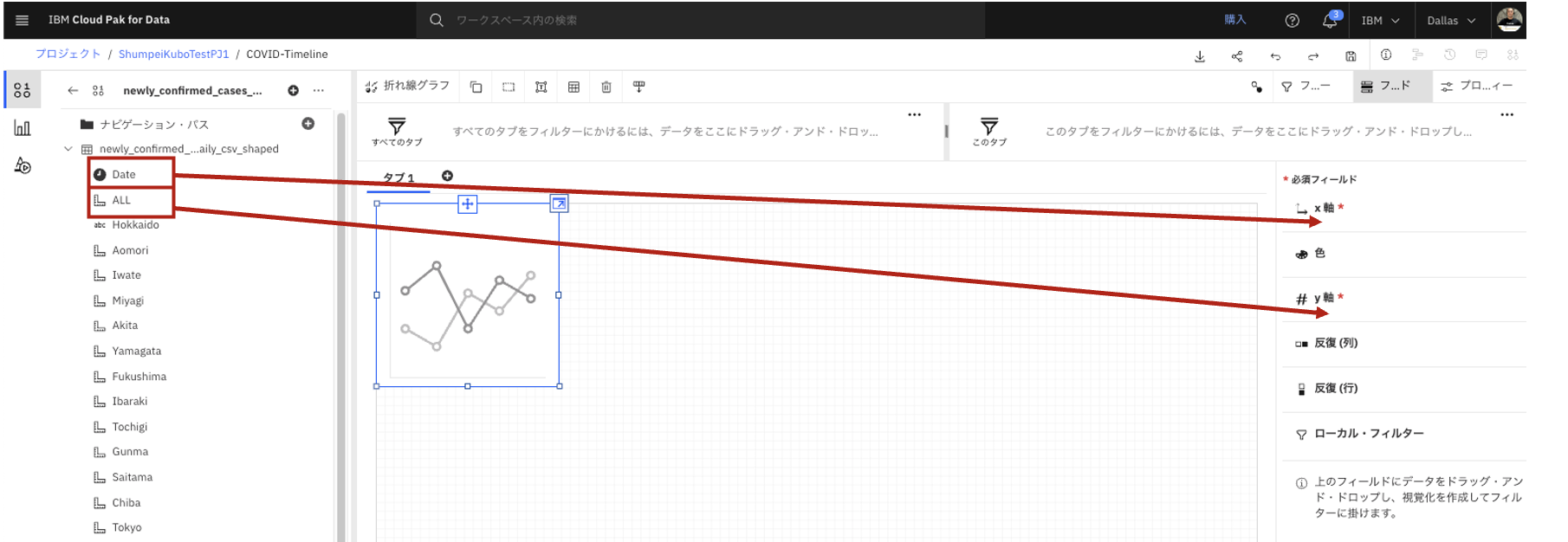
- 時系列グラフが表示されます。
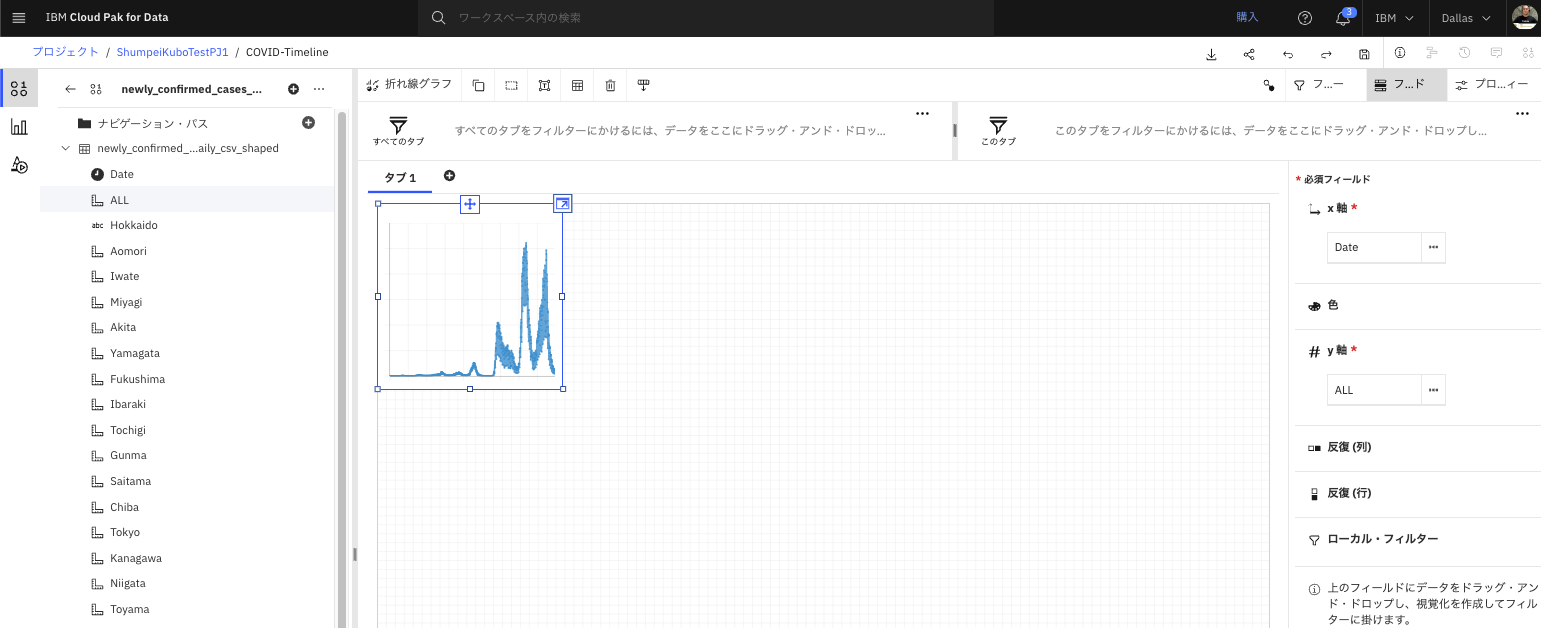
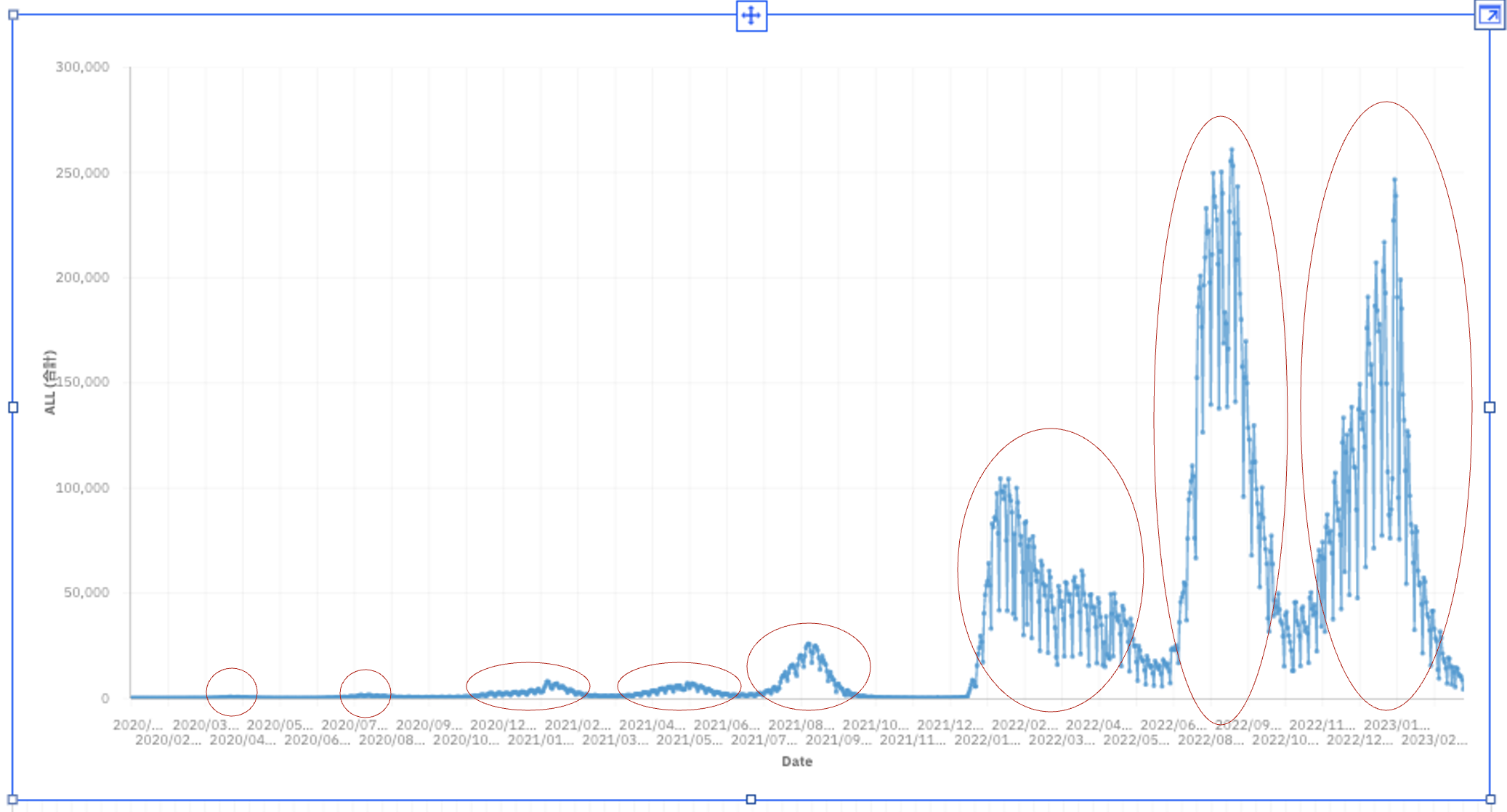
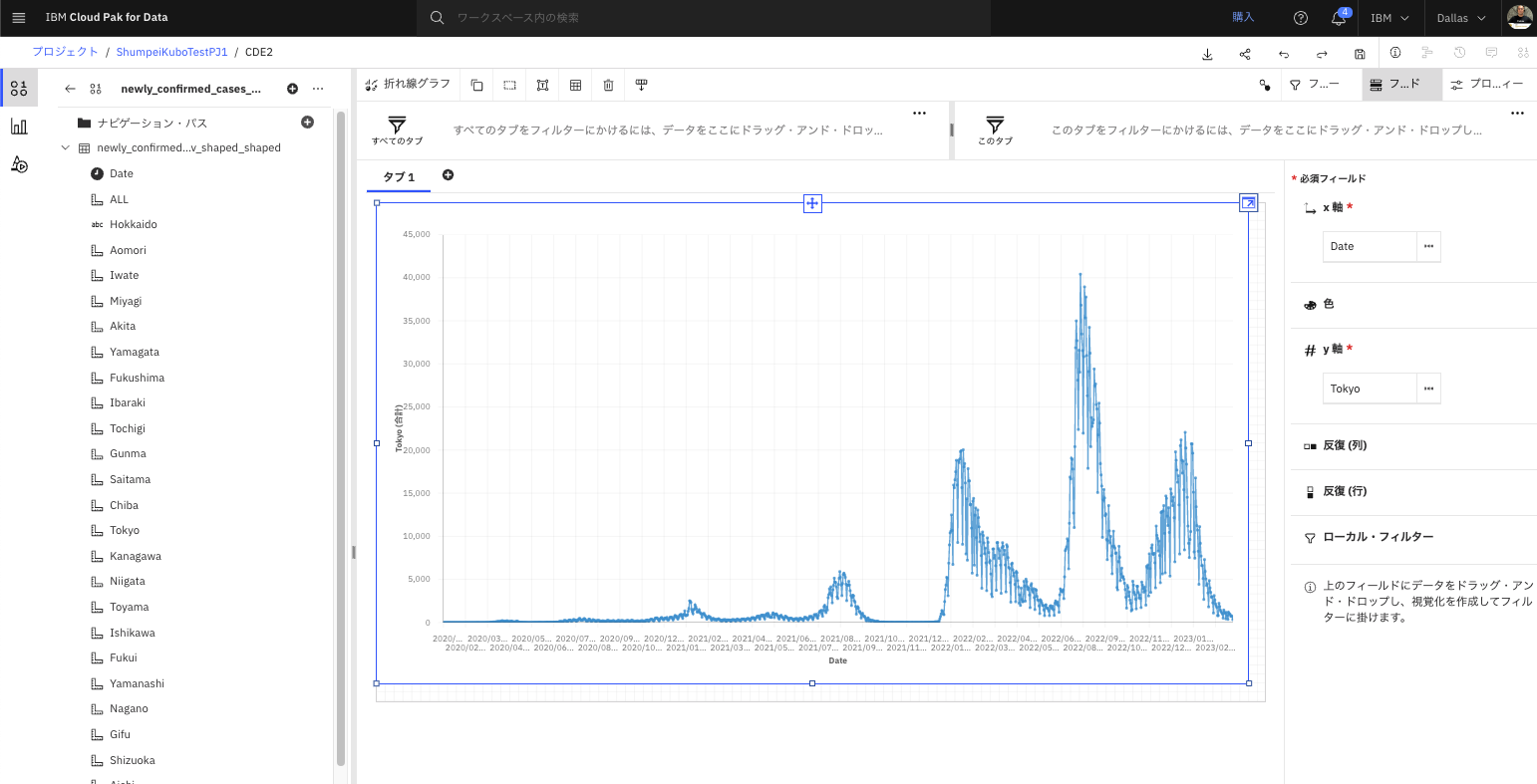
- グラフを拡大表示します。第8波までが表示されている事がわかります。(2023年3月上旬時点)
- 右上の保存ボタンをクリックして、内容を保存します。
2.2.2.都道府県別データの表示
- Y軸の欄から「ALL」を削除します。
- 「Tokyo」を「Y軸」へドラッグアンドドロップします。
- 東京のデータが表示されます。
- グラフを拡大します。
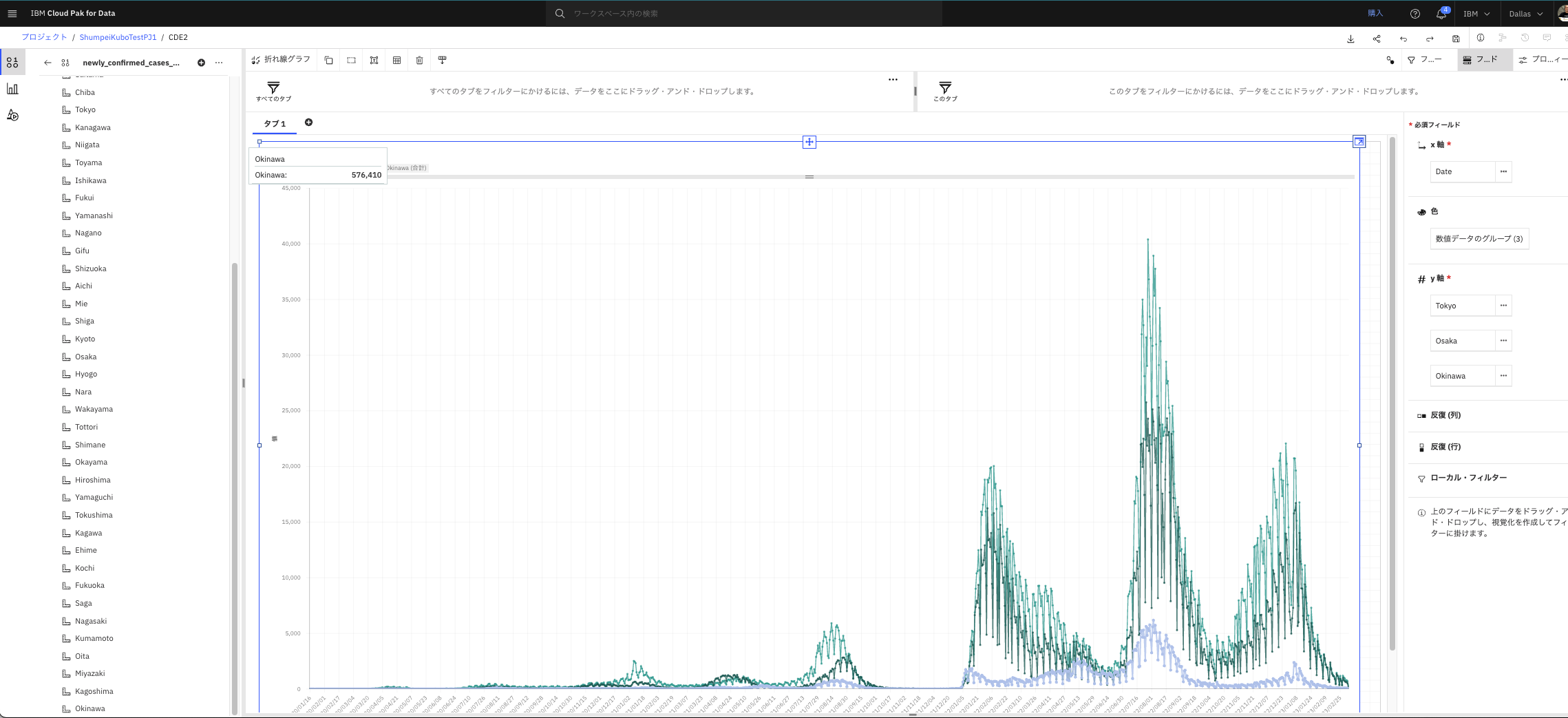
追加で、「Osaka」と「Okinawa」を、Y軸の「Tokyo」の下あたりにドラッグ&ドロップします。
- 3都道府のグラフが表示されました。
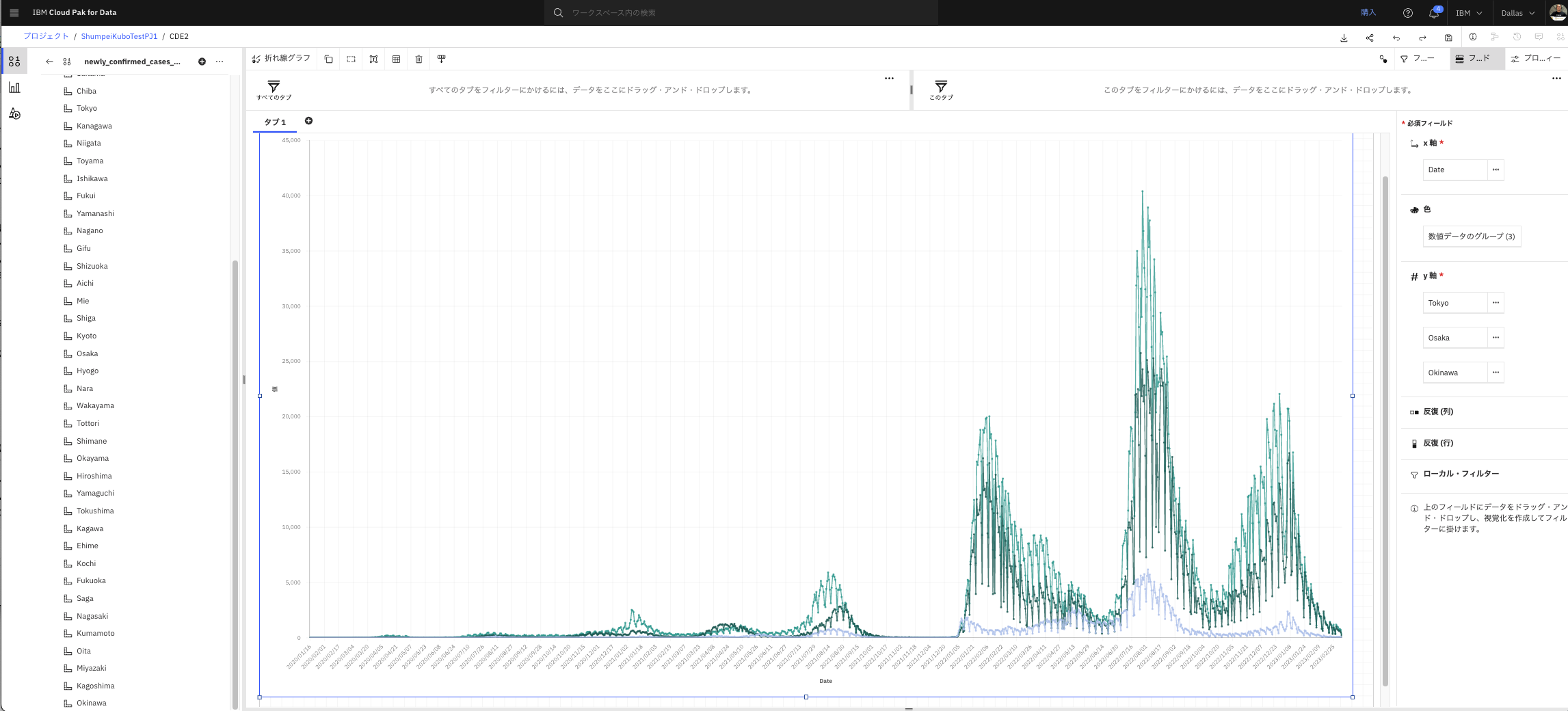
- 強調したい対象をクリックすると、ハイライトされます。
- 例えば画面上部の「Okinawa」をクリックすると、沖縄のデータのみが強調されます。