ネット上の情報をかき集めて自分なりに実装しているので正確ではないところがある点はご了承ください。
(違う個所はご指摘いただけると幸いです)
本シリーズ
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(準備編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(Q学習編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(DQN編)
- 【強化学習】Keras-rlでRainbowを実装/解説
- 【強化学習】Keras-rlでApe-Xを実装/解説(並列プログラミング)(ここ)
- MNISTでSaliencyMapとGrad_CAMを試してDQN(DuelingNetwork)を可視化してみた(実装/解説)
- 【強化学習】2018年度最強と噂のR2D2を実装/解説してみた
- 【強化学習】複数の探索ポリシーを実装/解説して比較してみた
- 【強化学習】DQNのハイパーパラメータを3つのゲームで比較してみた
- 【強化学習】R2D2を実装/解説してみたリベンジ 解説編(Keras-RL)
- 【強化学習】R2D3を実装/解説してみた(Keras-RL)
- 【強化学習】ついに人間を超えた!?Agent57を解説/実装してみた(Keras-RL)
概要
- Ape-xの解説/実装
- 並列プログラミングの実装(ロギング/例外処理含む)
コード全体
本記事で作成したコードは以下です。
※1ファイル完結です。
※GoogleColaboratoryは実行結果付き
- Ape-Xのコード(画像なし学習版と画像あり学習版)(GitHubGist)
- Ape-Xのコード(画像なし学習版)(GoogleColaboratory)
- Ape-Xのコード(画像あり学習版)(GoogleColaboratory)
追記:自作フレームワークを作成しています。そちらの実装の方が正確なコードとなります。
Ape-Xについて
今はやりのバトルロワイアルゲーム…ではありません。
簡単に言うと優先順位付き経験再生(Prioritized Experience Replay)を分散学習させるというものらしいです。
具体的には以下のアルゴリズムを実装しているとのこと。
- 分散学習
- Prioritized Experience Replay
- Dueling Network
- Double Deep Q-Network
- multi-step bootstrap target
この内、分散学習以外は前回の Rainbow 編で解説しているので今回は省略します。
参考
・【深層強化学習】Ape-X 実装・解説
・Distributed Prioritized Experience Replayを読んだので解説してみる
・Ape-Xの論文
分散学習
分散学習の考えは GORILA や A3C というアルゴリズムが先行研究であるそうです。
(ゴリラ(Gorilla)とはスペルが違うので注意)
参考
・深層強化学習アルゴリズムまとめ
・これから強化学習を勉強する人のための「強化学習アルゴリズム・マップ」と、実装例まとめ
・GORILAの論文
Ape-x の分散学習の概要は以下です。
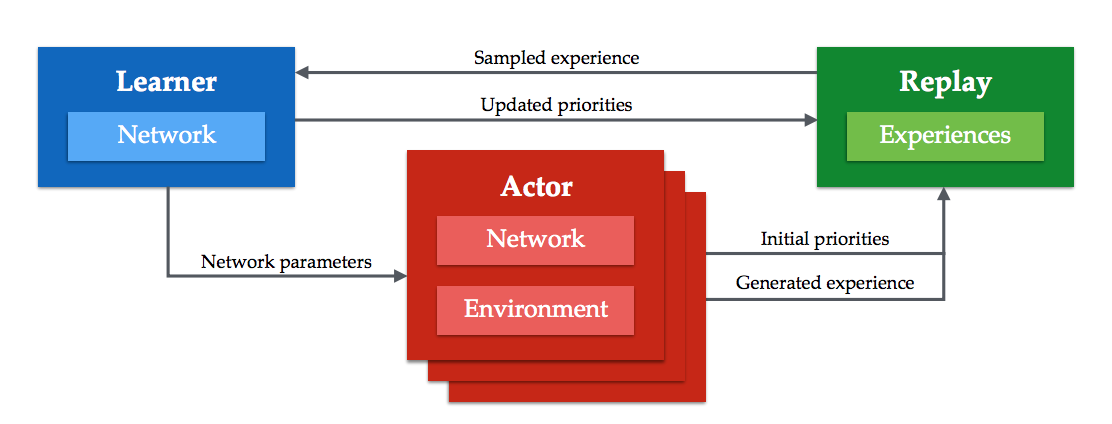
1つの Learner と複数の Actor が Replay Memory を共有しながら学習していきます。
Learner
- ReplayMemory から経験を取り出してひたすら学習します。
- Actor からQネットワークの更新要求があった場合に Actor へコピーします。
- (1つのGPU上で動く)
ReplayMemory をこの記事では RemoteMemory と呼びます。
Actor
- それぞれが Environment を持っており、実際に実行して経験をためる。
- 定期的に経験を ReplayMemory に送る。
- 定期的に Learner にQネットワークの更新要求をする。
- (1つの Actor が1つのCPUを利用して動く)
Actor 内部にも経験を貯めるメモリがあります。
こちらはこの記事では LocalMemory と呼びます。
実装/解説
並列プログラミング
Actor と Learner は python 標準ライブラリの multiprocessing で実装します。
python の並列プログラミングは初挑戦なので結構引っ掛かりました。
参考:https://docs.python.org/ja/3/library/multiprocessing.html
実装にあたり以下の制約がありました。
- 基本プロセス間は独立
- プロセス間でデータをやり取りする場合はプロセス間通信用のQueueを使う
- プロセス開始時に渡す引数は基本プリミティブ型、グローバルに定義されている関数まで可能。クラスを渡すのは難しそう。
特に引数の制約は強く、うまくまとめれていない箇所がある点はご了承ください。。。
全体概要
まずは Ape-x 全体を管理する Manager です。
class ApeXManager():
def __init__(self):
・各種引数の前処理
・プロセス間通信のためのQueueを作成
・Learner 用のプロセスを作成
・Actor 用のプロセスを作成
def train(self):
・Learner プロセスを開始
・Actor プロセスを開始
・Actor プロセスが終わるまで待つ
・Learner プロセスを止める
・Test用 Actor を作成
return Test用 Actor
Keras-rl で実装する場合、各 Actor が Agent 相当になるので全体を管理する Manager クラスを用意しています。
ここまでくると Keras-rl で実装する意味が薄れそうですが…
次に Learner です。
multiprocessing のプロセスは関数から開始するので(mainのイメージ?) Learner 開始用の関数から書いています。
def learner_run(引数):
learner = Learner(引数)
・load_weights
# learner はひたすら学習する
print("Learner Starts!")
while True:
learner.train()
・終了用のコードを別途用意
print("Learning End. Train Count:{}".format(learner.train_num))
Learner のクラスです。
class Learner():
def __init__(self):
・各引数の前処理
・RemoteMemoryの作成
self.train_num = 0 # stepの代わりに学習回数を数える
・Qネットワークの作成
・Targetネットワークの作成
def train(self):
・Actor から要求があれば Actor にQネットワークの weights を渡す
・RemoteMemory に経験を追加
# RemoteMemory が一定数貯まるまで学習しない。
if len(self.memory) <= self.memory_warmup_size:
time.sleep(1) # なんとなく
return
・modelの学習
前回のDQN編、Rainbow編の記事で作成したものをそのまま使います。
・target networkの更新
DQN編で backward 関数に書いていた内容です。
次に Actor です。
まずは Actor 側のプロセス開始関数です。
def actor_run(actor_func, actor_index, 引数):
actor = Actor(引数)
print("Actor{} Starts!".format(actor_index))
actor_func(actor_index, actor)
print("Actor{} End!".format(actor_index))
actor_func は使用者の作成を想定し、学習の仕方を指定できるようにしています。
例えば以下のような形です。
def actor_func(index, actor):
env = gym.make("Pendulum-v0")
if index == 0:
verbose = 1
else:
verbose = 0
actor.fit(env, nb_steps=100_000, visualize=False, verbose=verbose)
actor が Keras-RL の Agent になるので、actor.fit で学習させます。
また、actor_func は各 Actor 毎に独立で呼ばれるので関数内で都度ゲームを作成(gym.make)する必要があります。
verbose は全ての Actor でログが表示されると困るので index が 0 の Actor のみ表示させています。
次に Actor 本体です。
Agent で実装します。
class Actor(rl.core.Agent):
def __init__(self, **kwargs):
super(Actor, self).__init__(**kwargs)
・引数処理
・LocalMemoryの作成
# reset
self.reset_states()
・Qネットワークの作成およびcompile
self.compiled = True
def reset_states(self):
・前記事の DQN編、Rainbow編と同様
# 使いません。
def compile(self, optimizer, metrics=[]):
self.compiled = True
# save/load はここではしません。
def load_weights(self, filepath):
print("WARNING: Not Loaded. Please use 'load_weights_path' param.")
def save_weights(self, filepath, overwrite=False):
print("WARNING: Not Saved. Please use 'save_weights_path' param.")
def forward(self, observation):
・前記事の DQN編、Rainbow編とほぼ同様、違う個所のみ記載
(略)
if self.training:
・priority 計算のために TD-error を先に計算
・LocalMemoryに経験を追加
(略)
def backward(self, reward, terminal):
・前記事の DQN編、Rainbow編とほぼ同様、違う個所のみ記載
(略)
if self.training:
・一定間隔で model を learner からsyncさせる
・LocalMemory が一定量超えていれば RemoteMemory に送信
return []
@property
def layers(self):
return self.model.layers[:]
NNモデルの作成とcompile
compile ですが、Learner と Actor で同一のモデルを構築する必要があります。
Learner と Actor 両方から参照できるように別途関数を作って独立させました。
引数が大量に…
関数の中身は前記事のDQN編、Rainbow編と同じ内容です。(NoisyNetは消しています)
compile 部分も合わせて関数内で実施しています。
def build_compile_model(
input_shape, # 入力shape
enable_image_layer, # image_layerを入れるか
window_length, # window_length
nb_actions, # アクション数
enable_dueling_network, # dueling_network を有効にするか
dense_units_num, # Dense層のユニット数
create_optimizer_func,
metrics, # compile に渡す metrics
):
c = input_ = Input(shape=(window_length,) + input_shape)
(モデル作成部分、省略)
model = Model(input_, c)
# compile
model.compile(
loss=clipped_error_loss,
optimizer=create_optimizer_func(),
metrics=metrics)
return model
create_optimizer_func はユーザが指定できるように外だししています。
multiprocessing の関係上、インスタンス化された Optimizer をここまで持ってこれなかったので作成する関数を定義してもらいこの問題を回避しています。。。
(何かいい方法があればいいんですけど。。。)
create_optimizer_func の実装例は以下です。
def create_optimizer_func():
return Adam()
また、build_compile_model 関数では compile までまとめてやっています。
model の作成と compile が分かれている意味があまり分かってないので勝手にまとめていいのかちょっと不明ですが多分問題ありません。
Actor/Learnerの実行
子プロセスとして実行させます。
実行手順は mp.Process で子プロセスを定義し、start で開始、join で終わるまで待ちます。
参考:multiprocessing --- プロセスベースの並列処理
まずは子プロセスの作成です。
import multiprocessing as mp
class ApeXManager():
def __init__(self, num_actors):
self.num_actors = num_actors
# 長くなるので関数にしています。
self._create_process()
def _create_process(self, model_args, create_processor_func):
・各Queueを作成
以降の説明で Queue が必要になったらここで作成します。
# learner ps を作成
args = (Learner用の引数)
self.learner_ps = mp.Process(target=learner_run, args=args)
# actor ps を作成
self.actors_ps = []
for i in range(self.num_actors):
args = (Actor用の引数)
self.actors_ps.append(mp.Process(target=actor_run, args=args))
target で start 時に実行する関数を指定します。
args は target で実行する関数の引数になります。
実際に動かす側です。
class ApeXManager():
def train(self):
# プロセスを動かす
self.learner_ps.start()
for p in self.actors_ps:
p.start()
# Actor の終了を待つ
for p in self.actors_ps:
p.join()
# learner を終了させる
self.learner.terminate()
start で実行し、join で待ちます。
learner は終了処理がないので terminate での終了を書いています。
(この後別の方法になります)
例外等を何も気にしなければシンプルな記述になりますね…
経験の受け渡し
プロセス間通信
プロセス間通信は Queue のみで行います。
慣れていないのであまり複雑なことはしたくないためです。
経験受け渡しの概要
以下のイメージです。

ここは論文と少し違います。
論文では、Actor が直接 RemoteMemory に経験を送ります。
その関係で、RemoteMemory に上限はなく、一定時間ごとに超過分を削除するとのことでした。
その実装をしなかった理由は RemoteMemory (Prioritized Experience Replay) がクラスで定義しており、プロセス間で共有する手間がすごそうだったからです。
ですので一度経験受け渡し用 Queue でデータだけ貰い、RemoteMemory への格納は Learner が処理するという実装にしています。
経験受け渡し用Queueという実装の考え方はこの記事独自ですので注意です。
経験受け渡し用Queue の作成
まずは経験受け渡し用Queue(experience_q)を作り、各プロセスに渡します。
# Manager
class ApeXManager():
def _create_process(self):
# 経験Queueの作成
experience_q = mp.Queue()
# learner に渡す
args = (experience_q)
self.learner_ps = mp.Process(target=learner_run, args=args)
# actor に渡す
for i in range(num_actors):
args = (experience_q)
self.actors_ps.append(mp.Process(target=actor_run, args=args))
# learner関数
def learner_run(experience_q):
learner = Learner(experience_q)
# Learner
class Learner():
def __init__(self, experience_q):
self.experience_q = experience_q
※Actor側も同様に引数に追加しています。
LocalMemoryと経験受け渡し用Queue の実装(Actor)
まずは LocalMemory です。
deque で実装しています。
local_memory_update_size はハイパーパラメータで LocalMemory から RemoteMemory に送る経験データ数となります。
class Actor(rl.core.Agent):
def __init__(self, local_memory_update_size=50):
# local memory
self.local_memory = deque()
self.local_memory_update_size = local_memory_update_size
(略)
続いてTD誤差の計算と LocalMemory への格納です。
def forward(self, observation):
(略)
if self.traning:
(略)
# TD誤差の計算は actor 側で計算。
state0 = self.recent_observations[:self.window_length]
state1 = self.recent_observations[-self.window_length:]
state0_qvals = self.model.predict(np.asarray([state0]), 1)[0]
state1_qvals = self.model.predict(np.asarray([state1]), 1)[0]
maxq = np.max(state1_qvals)
td_error = reward + self.gamma * maxq
td_error = state0_qvals[self.recent_action] - td_error
# local memoryに追加
self.local_memory.append((state0, self.recent_action, reward, state1, td_error))
(略)
TD誤差は Actor 側で算出させます。
従来では初期のTD誤差は、どの経験も1度は学習に使わせるため、今までで一番大きな priority を採用していました。
しかし複数 Actor がいる場合はそれだと直近の経験ばかりが学習に使われてしまうので Actor のネットワークで計算されたTD誤差を用いてこの問題を回避しているそうです。
次に経験受け渡し用Queueへの送信です。
特に場所の指定はないと思うので、backward の最後に定義します。
# Actor 内です。
def backward(self, reward, terminal):
(略)
if self.training:
(略)
# localメモリが一定量超えていれば送信
if len(self.local_memory) > self.local_memory_update_size:
# 共有Qに1つずつ送るのは重そうなので配列化
data = []
while len(self.local_memory) > 0:
data.append(self.local_memory.pop())
# 送信
self.experience_q.put(data)
return []
RemoteMemoryと経験受け渡し用Queue の実装(Learner)
RemoteMemory ですが、Rainbow編で作成したPERメモリを使いまわします。
(ちょっとだけ変えます(後述))
class Learner():
def __init__(self):
self.memory = Rainbow編の実装
def train(self):
(略)
# experience があれば memory に追加
while not self.experience_q.empty():
exps = self.experience_q.get()
for exp in exps:
self.memory.add(exp, exp[4]) # exp[4]がTD誤差
(学習時のmemoryの使い方は同じ)
experience_q を見て入っていれば空になるまで RemoteMemory に追加します。
memory の add では、最大値ではなくTD誤差を用いて追加する必要があるのでその処理をPERに反映させます。
def add(self, experience):
self.tree.add(self.max_priority, experience)
↓
def add(self, experience, td_error)
priority = (abs(td_error) + 0.0001) ** self.alpha
self.tree.add(priority, experience)
PERProportionalMemory を例に書きましたが他のメモリも同様です。
また、初期メモリーの確保に現在のメモリーの量を取得する必要があるので len 関数を実装しておきます。
def __len__(self):
return self.tree.write
Qネットワークの同期
Queue を用いるのですが、片方向通信にしたかったので Actor→Learnerリクエスト用のQueueと Learner→Actor のQネットワークのweights送信用の Queue を作成することにしました。
# ApexManager 内
def _create_process(self):
# Qネットワーク同期用の Queue を Actor 分作成。
model_sync_q = [[mp.Queue(), mp.Queue()] for _ in range(num_actors)]
・experience_q と同じで、引数経由で Actor と Learner に渡す。
Learner 側の実装
self.model_sync_q[ActorIndex][0] が要求用のQueue、
self.model_sync_q[ActorIndex][1] が送信用のQueueです。
# Learner 内
def train():
# actor から要求があれば更新する
for q in self.model_sync_q:
if not q[0].empty():
# 空にする(念のため)
while not q[0].empty():
q[0].get()
# 送る
q[1].put(self.model.get_weights())
(略)
Actor側の実装
# Actor 内
def __init__(actor_index, model_sync_q):
# 自分のindexが自分用のQueue
self.model_sync_q = model_sync_q[actor_index]
def backward():
if self.training:
# 一定間隔で要求を送る
if self.step % self.actor_model_sync_interval == 0:
self.model_sync_q[0].put(1) # 要求
# weight が届いていれば更新
if not self.model_sync_q[1].empty():
weights = self.model_sync_q[1].get()
# 空にする(念のため)
while not self.model_sync_q[1].empty():
self.model_sync_q[1].get()
self.model.set_weights(weights) # model更新
(略)
ε-greedyの固定
従来の ε-greedy は ε を1から徐々に小さくしていましたが、今回は Actor ごとに以下の式で固定です。
$$ \epsilon_i = \epsilon^{1 + \frac{i}{N-1} \alpha }$$
# ApexManager内です。
def _create_process(self, epsilon, epsilon_alpha):
(略)
self.actors_ps = []
for i in range(num_actors):
if num_actors <= 1:
epsilon_i = epsilon ** (1 + epsilon_alpha)
else:
epsilon_i = epsilon ** (1 + i/(num_actors-1)*epsilon_alpha)
(epsilon_i を用いて actor プロセス作成処理)
(略)
```
## Optimizer
Centerd RMSPropというのを使用しているらしいが、Adamでいいよね(思考放棄)
## CPU/GPU 使い分け
今回は実装していません。(グラボ積んでるPC持ってないし…)
## test
論文や他の解説では触れられていませんが(多分)、testの実装を書いていきます。
一応最終状態の Learner のQネットワークを Actor にコピーし、その Actor が最終系としています。
まずは Lerner から最終状態を貰うための Queue を実装します。
``` python:ApexAgent.py
# ApeXManager 内
def _create_process(self):
(略)
# manager - learner 用の Queue
self.learner_end_q = [mp.Queue(), mp.Queue()]
・self.learner_end_q はlearnerの引数に追加
```
この Queue で learner に終了判定させることで、終了後に learner から最終状態を受け取ります。
``` python:ApexAgent.py
# ApeXManager 内
def train(self):
# プロセスを動かす
self.learner_ps.start()
for p in self.actors_ps:
p.start()
# 終了を待つ
for p in self.actors_ps:
p.join()
# 終了を learner に投げる
self.learner_end_q[0].put(1)
# 最後の状態を取得
weights = self.learner_end_q[1].get()
# テスト用の Actor を作成
test_actor = Actor()
test_actor.model.set_weights(weights)
# 返す
return test_actor
```
learner_run 側の実装です。
``` python:ApexAgent.py
def learner_run(引数, learner_end_q):
learner = Learner(引数)
while True:
learner.train()
# 終了qを受け取ったら終了
if not learner_end_q[0].empty():
break
# 最後の状態を投げる
learner_end_q[1].put(learner.model.get_weights())
```
## 引数の管理とユーザ側の実装
Ape-X とは関係ないですが、引数が多すぎるだけならまだしも multiprocessing で関数に渡す必要があるため管理が大変になっています。
そこで辞書型で定義して管理優先にしています。
使い方は実際に実行する時に解説しますが、args という変数に辞書型で引数を押し込んでいます。
``` python:ApexAgent.py
# Manager
class ApeXManager():
def __init__(self,
actor_func, # ユーザ指定の関数
num_actors, # 動かす Actor 数
args, # 引数群
create_processor_func, # ユーザ指定processor
create_optimizer_func, # ユーザ指定optimizer
):
# 引数整形
args["save_weights_path"] = args["save_weights_path"] if ("save_weights_path" in args) else ""
args["load_weights_path"] = args["load_weights_path"] if ("load_weights_path" in args) else ""
# building_network 関数用に引数を作成
model_args = {
(略)
}
(略)
```
引数の流れは説明が冗長になるので全体コードを見てください。
基本 args 変数を渡していっているだけです。
## Save
Save は Learner の最後の状態の model を保存します。
``` python:ApexAgent.py
def learner_run(省略):
(学習終わり)
# model save
if args["save_weights_path"] != "":
learner.model.save_weights(args["save_weights_path"], args["save_overwrite"])
(省略)
```
## Load
Load は Learner の model,target_model、全 Actor の model にて、最初に Load させます。
``` python:ApexAgent.py
def learner_run(省略):
# model load
if os.path.isfile(args["load_weights_path"]):
learner.model.load_weights(args["load_weights_path"])
learner.target_model.load_weights(args["load_weights_path"])
(学習)
# model save
(省略)
```
Actor
``` python:ApexAgent.py
def actor_run(省略):
actor = Actor(省略)
# model load
if os.path.isfile( args["load_weights_path"] ):
actor.model.load_weights(args["load_weights_path"])
(省略)
```
## logging
今回それぞれのプロセスが独立しているので今まで基準としていたstep数が使えません。
まあ、学習結果を見るだけでもいいのですが折角なので途中経過を収集する仕組みを作りました。
基準としては一定秒数毎にロギングする形です。
まずは Learner用のロギングQueueを作ります。
``` python:ApexAgent.py
# Manager内
def _create_process(self,省略):
(省略)
self.learner_logger_q = mp.Queue()
・learner用の引数に追加します。
(省略)
```
### Learnerのロギング
``` python:ApexAgent.py
def learner_run(省略):
(省略)
# logger用
t0 = time.time()
print("Learner Starts!")
while True:
learner.train()
# logger
if time.time() - t0 > args["logger_interval"]:
t0 = time.time()
logger_q.put({
"name": "learner",
"train_num": learner.train_num,
})
# 終了判定
if not learner_end_q[0].empty():
break
(省略)
```
logger_interval が経過したら Queue に追加していく感じです。
何を保存するか迷ったのですがとりあえず学習回数として learner.train_num をいれています。
### Actor のロギング
次に Actor 側です。
まずは Queue を作成。
``` python:ApexAgent.py
# Manager内
def _create_process(self,省略):
(省略)
self.actors_logger_q = mp.Queue()
・Actor用の引数に追加します。
(省略)
```
同じ Queue に入れてもらいます。
Actor でロギングするためには Keras-rl の Callback を定義して実行する必要があります。
ですので専用のロギングクラスをまずは作ります。
``` python:ApexAgent.py
class ActorLogger(rl.callbacks.Callback):
def __init__(self, index, logger_q, interval):
self.index = index
self.interval = interval
self.logger_q = logger_q
def on_train_begin(self, logs):
self.t0 = time.time()
self.reward_min = None
self.reward_max = None
def on_episode_end(self, episode, logs):
if self.reward_min is None:
self.reward_min = logs["episode_reward"]
self.reward_max = logs["episode_reward"]
else:
if self.reward_min > logs["episode_reward"]:
self.reward_min = logs["episode_reward"]
if self.reward_max < logs["episode_reward"]:
self.reward_max = logs["episode_reward"]
if time.time() - self.t0 > self.interval:
self.t0 = time.time()
self.logger_q.put({
"name": "actor" + str(self.index),
"reward_min": self.reward_min,
"reward_max": self.reward_max,
"nb_steps": logs["nb_steps"],
})
self.reward_min = None
self.reward_max = None
```
中身の説明は割愛しますが、interval 時間中のエピソード内において、最低報酬と最高報酬、それと現在の総step数を保存しています。
これを actor_run 関数内で作ってユーザ指定の actor_func の引数に渡します。
``` python:ApexAgent.py
def actor_run(省略):
actor = Actor(省略)
・model load
# logger用
callbacks = [
ActorLogger(actor_index, logger_q, args["logger_interval"])
]
# run
actor_func(actor_index, actor, callbacks=callbacks)
```
### Managerのログ取得
Queueにたまったログを吸出します。
``` python:ApexAgent.py
# Manager内です。
def train(self):
learner_logs = []
actors_logs = {}
# プロセススタート
self.learner_ps.start()
for p in self.actors_ps:
p.start()
# 終了を待つ
while True:
time.sleep(1) # polling time
# 定期的にログを吸出し
while not self.learner_logger_q.empty():
learner_logs.append(self.learner_logger_q.get())
while not self.actors_logger_q.empty():
log = self.actors_logger_q.get()
if log["name"] not in actors_logs:
actors_logs[log["name"]] = []
actors_logs[log["name"]].append(log)
# 終了判定
f = True
for p in self.actors_ps:
if p.is_alive():
f = False
break
if f:
break
# 終了後に念のためもう一度ログ吸出し
while not self.learner_logger_q.empty():
learner_logs.append(self.learner_logger_q.get())
while not self.actors_logger_q.empty():
log = self.actors_logger_q.get()
if log["name"] not in actors_logs:
actors_logs[log["name"]] = []
actors_logs[log["name"]].append(log)
```
プロセス間通信の Queue のサイズが大きくなると挙動があまり良くなかったので…定期的に吐き出す方法にしています。
それに伴って終了判定を join からポーリング方式に変更する必要がありました。
・・・ここら辺の実装は原始的です。
最後にログを return しています。
``` python:ApexAgent.py
# Manager内です。
def train(self):
(省略)
return test_actor, learner_logs, actors_logs
```
## 例外処理
不要かもしれませんが長時間学習した後に結果が出ないのはきついんですよ…
### multiprocessing Queue のデッドロック
なぜか学習後に止まることがありました。
[ここ](https://docs.python.org/ja/3/library/multiprocessing.html)の下の方にプログラミングガイドラインが書いてあり、そこで事象はわかりました。
> ・キューを使用するプロセスを join する
> 次の例はデッドロックを引き起こします:
``` python
from multiprocessing import Process, Queue
def f(q):
q.put('X' * 1000000)
if __name__ == '__main__':
queue = Queue()
p = Process(target=f, args=(queue,))
p.start()
p.join() # this deadlocks
obj = queue.get()
```
これなぜか q.put('X' * 1000000) → q.put('X' * 1000) と少ない数にするとデッドロックが起きません。
何故ですかね…
いろいろと試行錯誤したのですが、Actor も終了キューで管理して Manager が Queue 関係の処理を終えた後に子プロセスを Terminate する方法にしました。
``` python:ApexAgent.py
# Manager内
def _create_process(self, model_args, create_processor_func):
# Actor終了用Queueを作成
self.actors_end_q = [mp.Queue() for _ in range(self.num_actors)]
(略)
# actor_run
def actor_run(略):
(学習処理)
actors_end_q.put(1)
# Manager内
def train(self):
(省略)
while True:
time.sleep(1) # polling time
(定期的にログを吸出し)
#---------
# 終了判定
f = True
for p in self.actors_ps:
if p.is_alive():
f = False
break
if f:
break
#-------
↓
#---------
# 終了判定
f = True
for q in self.actors_end_q:
if q.empty():
f = False
break
if f:
break
#-------
(省略)
```
### 例外処理と Crtl+C の導入
multiprocessing で Ctrl+C(KeyboardInterrupt)の処理がよくわからなかったので実験してみました。
``` python
from multiprocessing import Process, Queue
import time
def f1():
try:
time.sleep(5)
print("f1 end")
except KeyboardInterrupt:
print("f1 KeyboardInterrupt")
def f2():
try:
try:
time.sleep(5)
print("f2 end1")
except KeyboardInterrupt:
print("f2 KeyboardInterrupt1")
time.sleep(5)
print("f2 end2")
except KeyboardInterrupt:
print("f2 KeyboardInterrupt2")
if __name__ == '__main__':
p1 = Process(target=f1, args=())
p2 = Process(target=f2, args=())
p1.start()
p2.start()
try:
p1.join()
print("main end")
except KeyboardInterrupt:
print("main KeyboardInterrupt")
```
Ctrl+C を1回押した結果は以下です。
``` python
f1 KeyboardInterrupt
f2 KeyboardInterrupt1
main KeyboardInterrupt
f2 end2
```
結果としては全プロセスに飛ぶようですね。
というわけでとりあえず途中で例外が起こっても学習結果は保存/見れるように例外設定しました。
``` python:ApexAgent.py
import traceback
class ApeXManager():
# 子プロセスが残らないようにデストラクタを設定
def __del__(self):
self.learner_ps.terminate()
for p in self.actors_ps:
p.terminate()
def train(self):
(省略)
try:
(プロセススタート)
(終了を待つ)
except KeyboardInterrupt:
pass
except Exception:
print(traceback.format_exc())
(以下学習後処理)
# learner_run
def learner_run(省略):
(省略)
try:
(学習ループ)
except KeyboardInterrupt:
pass
except Exception:
print(traceback.format_exc())
(モデルの保存)
(終了処理)
# actor_run
def actor_run(省略):
try:
(学習)
except KeyboardInterrupt:
pass
except Exception:
print(traceback.format_exc())
(終了処理)
```
# Pendiumゲームで学習
## 使用側の実装例
まずはユーザ側の実装例です。
``` python:User.py
import gym
from keras.optimizers import Adam
# 別ファイルにあると仮定
from MyApeXAgent import ApeXManager
from PendulumProcessor import PendulumProcessor
# ゲーム名だけは global で定義した方がいろいろと楽かも
ENV_NAME = "Pendulum-v0"
# Processorを使う場合は定義、不要ならNone
def create_processor():
return PendulumProcessor(enable_image=False)
# optimizer を指定
def create_optimizer():
return Adam()
# actorのメイン実行部分
# 学習するゲームを作って学習までを実施(ゲームは関数内で生成してください)
def actor_func(index, actor, callbacks):
env = gym.make(ENV_NAME)
if index == 0:
verbose = 1 # 一人目のみコンソールに表示
else:
verbose = 0
#callbacks = [] # 二人目以降の actor でロギングが不要ならコメントアウトを外す
actor.fit(env, nb_steps=100_000, visualize=False, verbose=verbose, callbacks=callbacks)
#--- ここから main ---
env = gym.make(ENV_NAME) # ゲーム情報がほしいので仮作成
# 引数
args = {
# model関係
"input_shape": env.observation_space.shape,
"enable_image_layer": False,
"nb_actions": 5,
"window_length": 1, # 入力フレーム数
"dense_units_num": 32, # Dense層のユニット数
"metrics": [], # optimizer用
"enable_dueling_network": True, # dueling_network有効フラグ
# learner 関係
"remote_memory_capacity": 500_000, # 確保するメモリーサイズ
"remote_memory_warmup_size": 1000, # 初期のメモリー確保用step数(学習しない)
"remote_memory_type": "per_proportional", # メモリの種類
"per_alpha": 0.8, # PERの確率反映率
"per_beta_initial": 0.0, # IS反映率の初期値
"per_beta_steps": 100_000, # IS反映率の上昇step数
"per_enable_is": False, # ISを有効にするかどうか
"batch_size": 16, # batch_size
"target_model_update": 500, # target networkのupdate間隔
"enable_double_dqn": True, # DDQN有効フラグ
# actor 関係
"local_memory_update_size": 50, # LocalMemoryからRemoteMemoryへ投げるサイズ
"actor_model_sync_interval": 500, # learner から model を同期する間隔
"gamma": 0.99, # Q学習の割引率
"epsilon": 0.4, # ϵ-greedy法
"epsilon_alpha": 7, # ϵ-greedy法
"multireward_steps": 3, # multistep reward
# その他
"load_weights_path": "", # 保存ファイル名
"save_weights_path": "", # 読み込みファイル名
"save_overwrite": True, # 上書き保存するか
"logger_interval": 5, # ログ取得間隔(秒)
}
manager = ApeXManager(
actor_func=actor_func,
num_actors=2, # actor数
args=args,
create_processor_func=create_processor,
create_optimizer_func=create_optimizer,
)
# 実行
# 実行後test用のactorが返ってきます。
test_actor, learner_logs, actors_logs = manager.train()
# 結果を確認
test_actor.processor.mode = "test"
test_actor.test(env, nb_episodes=5, visualize=True)
# plot例
n = len(actors_logs) + 1
train_num = [ l["train_num"] for l in learner_logs]
actor_names = []
actor_steps = []
actor_reward_min = []
actor_reward_max = []
for name, logs in actors_logs.items():
actor_names.append(name)
steps = []
reward_min = []
reward_max = []
for log in logs:
steps.append(log["nb_steps"])
reward_min.append(log["reward_min"])
reward_max.append(log["reward_max"])
actor_steps.append(steps)
actor_reward_min.append(reward_min)
actor_reward_max.append(reward_max)
plt.subplot(n,1,1)
plt.ylabel("Trains,Steps")
plt.plot(train_num, label="train_num")
for i in range(len(actor_names)):
plt.plot(actor_steps[i], label=actor_names[i])
from matplotlib.font_manager import FontProperties
plt.subplots_adjust(left=0.1, right=0.85, bottom=0.1, top=0.95)
plt.legend(bbox_to_anchor=(1.00, 1), loc='upper left', borderaxespad=0, fontsize=8)
for i in range(len(actor_names)):
plt.subplot(n,1,i+2)
plt.plot(actor_reward_min[i], label="min")
plt.plot(actor_reward_max[i], label="max")
plt.ylabel("Actor" + str(i) + " Reward")
plt.show()
```
## 学習結果
・数値による学習

・画像経由による学習

|数値|画像経由|
|---|---|
|||
ちゃんと学習できていますね。
画像経由は学習はできていますが…、Learner が遅すぎて学習が追い付いていませんね。
Actorが1なのはスペックの関係です。
(GoogleColaboratory版では 2Actor で何とか学習できています)
GPU/CPUの割り当てとマシンスペックがかなり重要なアルゴリズムだと感じました。
# まとめ
Ape-X より実装方法と並列プログラミングにやられた感じですね…
ほとんど Ape-X 関係ないような…
さて次はついに最新手法R2D2に挑戦したいと思います。
けど、ちょっと難航しています…