とりあえず実装したいものは実装したので性能を比較してみたいと思います。
どんな結果になることやら
本シリーズ
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(準備編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(Q学習編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(DQN編)
- 【強化学習】Keras-rlでRainbowを実装/解説
- 【強化学習】Keras-rlでApe-Xを実装/解説(並列プログラミング)
- MNISTでSaliencyMapとGrad_CAMを試してDQN(Dueling Network)を可視化してみた(実装/解説)
- 【強化学習】2018年度最強と噂のR2D2を実装/解説してみた
- 【強化学習】複数の探索ポリシーを実装/解説して比較してみた(多腕バンディット問題)
- 【強化学習】DQNのハイパーパラメータを3つのゲームで比較してみた(ここ)
- 【強化学習】R2D2を実装/解説してみたリベンジ 解説編(Keras-RL)
- 【強化学習】R2D3を実装/解説してみた(Keras-RL)
- 【強化学習】ついに人間を超えた!?Agent57を解説/実装してみた(Keras-RL)
概要
3つのゲーム(Pendulum-v0、Acrobot-v1、CartPole-v1)について性能比較してみた。
コード全体
本記事で作成したコードは以下です。
※1ファイル完結です。
※GoogleColaboratory は時間がかかりすぎるので Pendiulum だけの結果です。
※GoogleColaboratory の R2D2 はなぜか続けてゲームができなかったのでRainbowR版のみです。
比較にあたって
比較方法ですが、ある基準となるハイパーパラメータに対して何か1つの要素を減らしたり増やしたりして比較します。
2要素以上の複合的な比較はしません(組み合わせが多すぎるので…)
また、ゲームの報酬はいじります。
gymで用意されているゲームは報酬が結構いやらしい設定である事と、
最終的にやりたい事では報酬が自由に設定できる事から報酬はいじらせてもらいます。
また、時間の関係で画像なしの学習しか比較しません。
Pendulum-v0 概要
ゲームの概要はこちら

本シリーズではお馴染みですね。
棒を上で維持し続ければ報酬がもらえます。
Processorで変更している点は2点です。
・アクションの離散化
アクションを -2.0~2.0 → [0,1,2,3,4] にしています。
・報酬の正規化
報酬を -16.2736044~0 → -0.5~1.0 に正規化しています。
import rl.core
class PendulumProcessor(rl.core.Processor):
def __init__(self):
self.mode = "train"
def process_action(self, action):
ACT_ID_TO_VALUE = {
0: [-2.0],
1: [-1.0],
2: [0.0],
3: [+1.0],
4: [+2.0],
}
return ACT_ID_TO_VALUE[action]
def process_reward(self, reward):
if self.mode == "test": # testは本当の値を返す
return reward
# -16.5~0 を -0.5~1 に正規化
self.max = 0
self.min = -16.5
# min max normarization
if (self.max - self.min) == 0:
return 0
M = 1
m = -0.5
return ((reward - self.min) / (self.max - self.min))*(M - m) + m
CartPole-v0 概要
ゲームの概要はこちら

左右に台を移動させて棒を傾けないようにするゲームです。
棒が傾くとゲームが終了します。
以下、変更点です。
・報酬の正規化
報酬は常に +1 する。終了時の報酬も +1。
(長く続けるほど報酬の合計が高くなる)
↓
常に +0.01 し、終了時に -1 の報酬。
import rl.core
class CartPoleProcessor(rl.core.Processor):
def __init__(self):
self.mode = ""
self.step = 0
def process_step(self, observation, reward, done, info):
observation = self.process_observation(observation)
reward = self.process_reward(reward)
info = self.process_info(info)
if self.mode == "test":
return observation, reward, done, info
self.step += 1
if done :
reward = -1
self.step = 0
else:
reward = 0.01
return observation, reward, done, info
Acrobot-v1 概要
ゲームの概要はこちら

棒を一定の高さ(線の上)まで持ち上げるゲームです。
持ち上げた時点でゲームクリアです。
以下、変更点です。
・報酬の正規化
報酬が常に -1。
(早くクリアするほど報酬の合計が高い)
↓
報酬は常に 0 にし、クリア時に (500-step) の報酬。
(500は最大step数)
import rl.core
class AcrobotProcessor(rl.core.Processor):
def __init__(self):
self.mode = ""
self.step = 0
def process_step(self, observation, reward, done, info):
observation = self.process_observation(observation)
reward = self.process_reward(reward)
info = self.process_info(info)
if self.mode == "test":
return observation, reward, done, info
self.step += 1
if done :
reward = 500-self.step
self.step = 0
else:
reward = 0
return observation, reward, done, info
使用するコード
R2D2編のコード+探索ポリシー編コードをマージしたコードを使用します。
また、いくつか修正を行っています。
- NoisyNetを追加
- PERの RankBase O(1)の実装を追加
- Dueling Networkの結合時のアルゴリズムを 平均,最大,なし から選べるように修正
- PERの Propotional と Rankbase のアルゴリズムで乱数を出すときに区分分けを行っていたが廃止(正確な確率にならなくなりますね…)
基準となるハイパーパラメータ
ハイパーパラメータだけ抜粋します。
全体のコードはコード全体を見てください。
簡単に言うと以下です。
- input_sequenceは 8
- LSTM、Dense層のユニット数は 64
- DuelingNetwork あり
- batch_sizeは 16
- DoubleDQN あり
- ステートレスLSTM(Burn-inなし)を採用
- PERは Proportional
- ISなし
- MultistepRewardは 1
- 探索ポリシーは R2D2 のもの
- Actor は二人
- Learner 50_000 回学習するまで学習
def create_optimizer():
return Adam(lr=0.0005)
def actor_func(index, actor, callbacks):
env = gym.make(ENV_NAME)
if index == 0:
verbose = 0
else:
verbose = 0
actor.fit(env, nb_steps=999_999_999, visualize=False, verbose=verbose, callbacks=callbacks)
def main(name):
(ゲームによる初期化)
# 引数
args = {
# model関係
"input_shape": input_shape,
"enable_image_layer": False,
"nb_actions": nb_actions,
"input_sequence": 8, # 入力フレーム数
"dense_units_num": 64, # Dense層のユニット数
"metrics": [], # optimizer用
"enable_dueling_network": True, # dueling_network有効フラグ
"dueling_network_type": "ave", # dueling_networkのアルゴリズム
"enable_noisynet": False, # NoisyNet有効フラグ
"lstm_type": "lstm", # LSTMのアルゴリズム
"lstm_units_num": 64, # LSTM層のユニット数
# learner 関係
"remote_memory_warmup_size": 100, # 初期のメモリー確保用step数(学習しない)
"batch_size": 16, # batch_size
"target_model_update": 2000, # target networkのupdate間隔
"enable_double_dqn": True, # DDQN有効フラグ
"enable_rescaling_priority": False, # rescalingを有効にするか(priotrity)
"enable_rescaling_train": False, # rescalingを有効にするか(train)
"rescaling_epsilon": 0.001, # rescalingの定数
"burnin_length": 20, # burn-in期間
"priority_exponent": 0.9, # priority優先度
# memory 関係
"remote_memory_type": "per_proportional",
"remote_memory_args": {
"capacity": 500_000, # メモリサイズ
"alpha": 0.8, # PERの確率反映率
"beta_initial": 0.0, # IS反映率の初期値
"beta_steps": 100_000, # IS反映率の上昇step数
"enable_is": False, # ISを有効にするかどうか
},
# actor 関係
"local_memory_update_size": 50, # LocalMemoryからRemoteMemoryへ投げるサイズ
"actor_model_sync_interval": 500, # learner から model を同期する間隔
"gamma": 0.99, # Q学習の割引率
"multireward_steps": 1, # multistep reward
"action_interval": 1, # アクションを実行する間隔
# その他
"num_actors": 2, # actor の数
"enable_GPU": True, # GPUを使うか
"limit_train_count": 50_000, # 最大学習回数(0で制限なし)
"load_weights_path": "", # 保存ファイル名
"save_weights_path": "", # 保存ファイル名
"save_overwrite": True, # 上書き保存するか
"logger_interval": 10, # ログ取得間隔(秒)
}
act_type = "greedy_actor"
act_args = {"epsilon": 0.4, "alpha": 2 }
# actor毎の探索ポリシーを決める。配列の数はactor数と同数
action_policies = []
for _ in range(args["num_actors"]):
action_policies.append({
"type": act_type,
"args": act_args
})
args["action_policies"] = action_policies
#--- R2D2
manager = R2D2Manager(
actor_func=actor_func,
args=args,
create_processor_func=processor,
create_optimizer_func=create_optimizer,
)
結果1(Pendulum-v0)
学習過程
normal が基準となるハイパーパラメータで全ての図にいれています。
・DQN関係
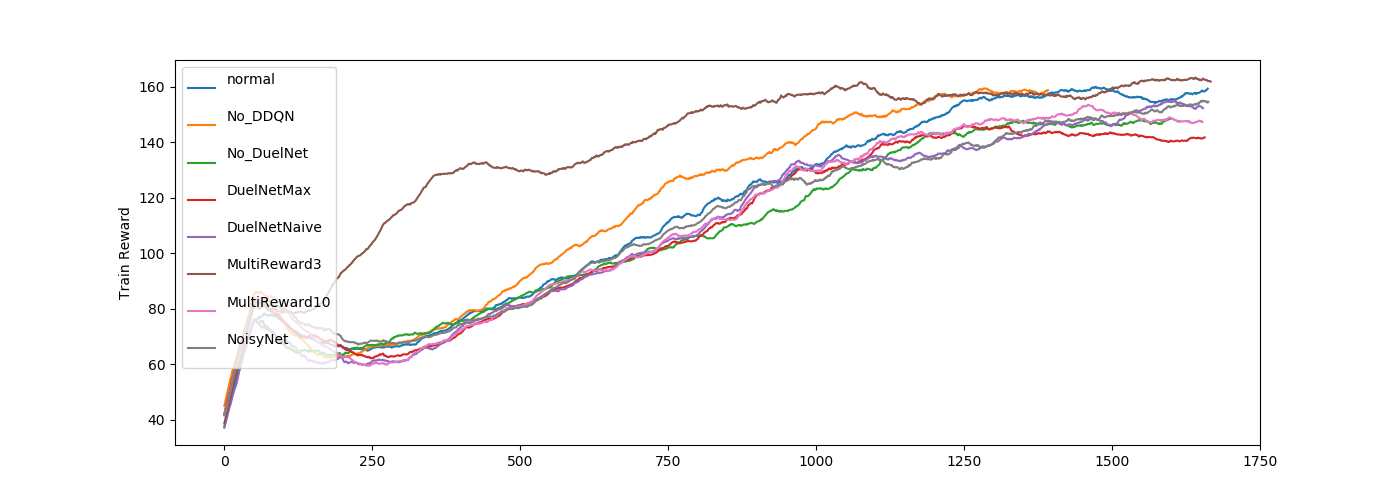
Multireward3が立ち上がりが早めですがあまり大差はなさそうですね。
・PER関係

normal は PropotionalMemory です。
ReplayMemory がランダム、PER_Greedy がTD誤差最大を選ぶ方法なので、
Pendulum の学習には、TD誤差による経験学習があまり有効ではなさそうに見えます。
・LSTM関係

normal はステートレスLSTMです。
LSTMを使わない場合の効率がいいですが、これはすでに Pendulum の環境に速度の情報も入っているので、
時系列情報の学習は余分になっているかもしれません。
・探索関係
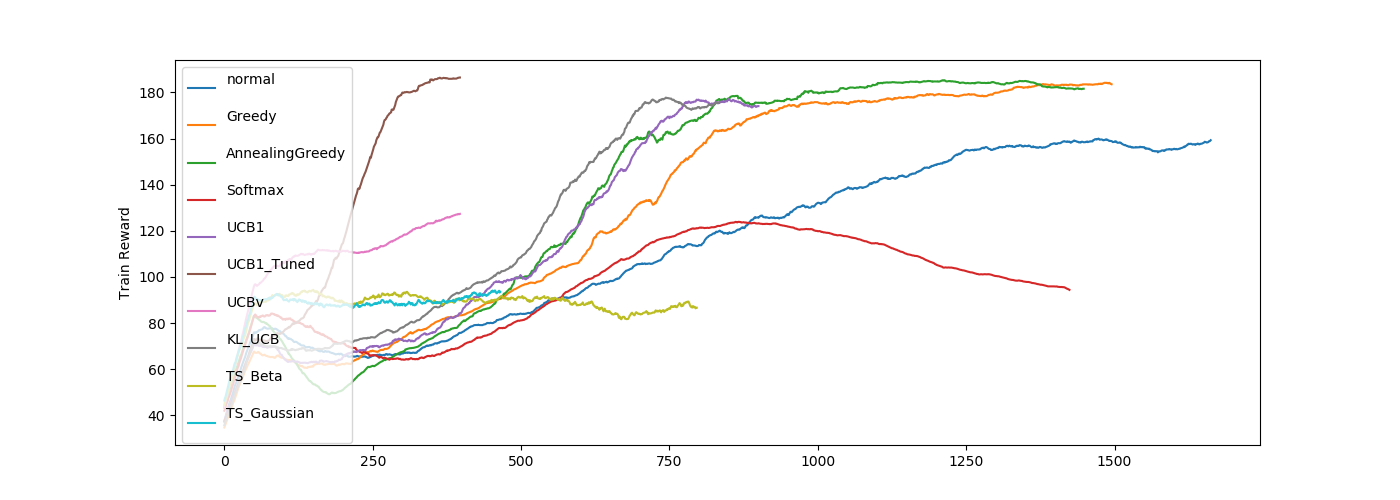
UCB1_Tuned の成績がかなりいいですね。
結構結果がばらけています。
学習時間
| グラフ | |
|---|---|
| DQN関係 |  |
| PER関係 |  |
| LSTM関係 |  |
| 探索関係 | 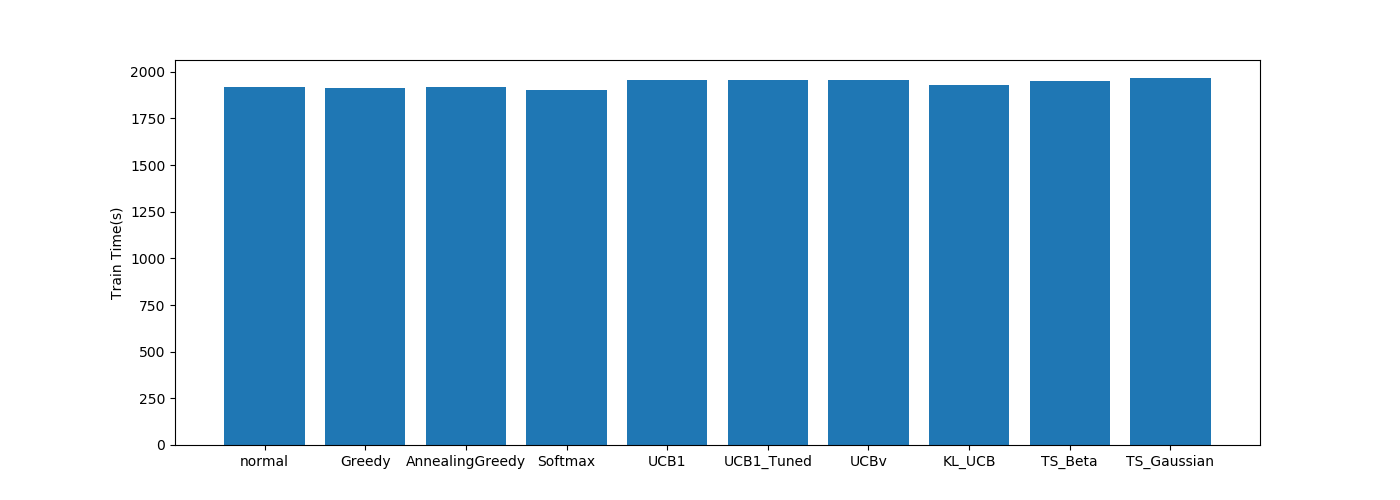 |
LSTM以外は大きな差がないですね。
LSTMは単純に層が増えているのでその影響ですね。
テスト結果
・DNQ関係
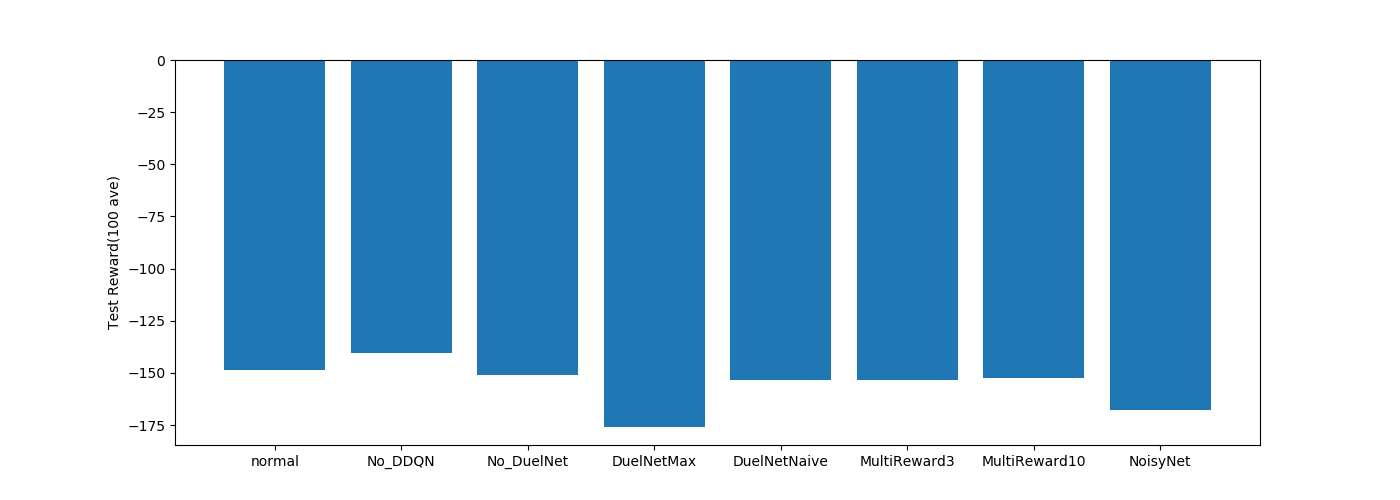
-1600あたりが最低値なのでどれもちゃんと学習できていますね。
・PER関係

TD誤差最大値を選ぶPER_GreedyとIS以外は学習できていますね。
ISの結果は…よくわかりません。
・LSTM関係
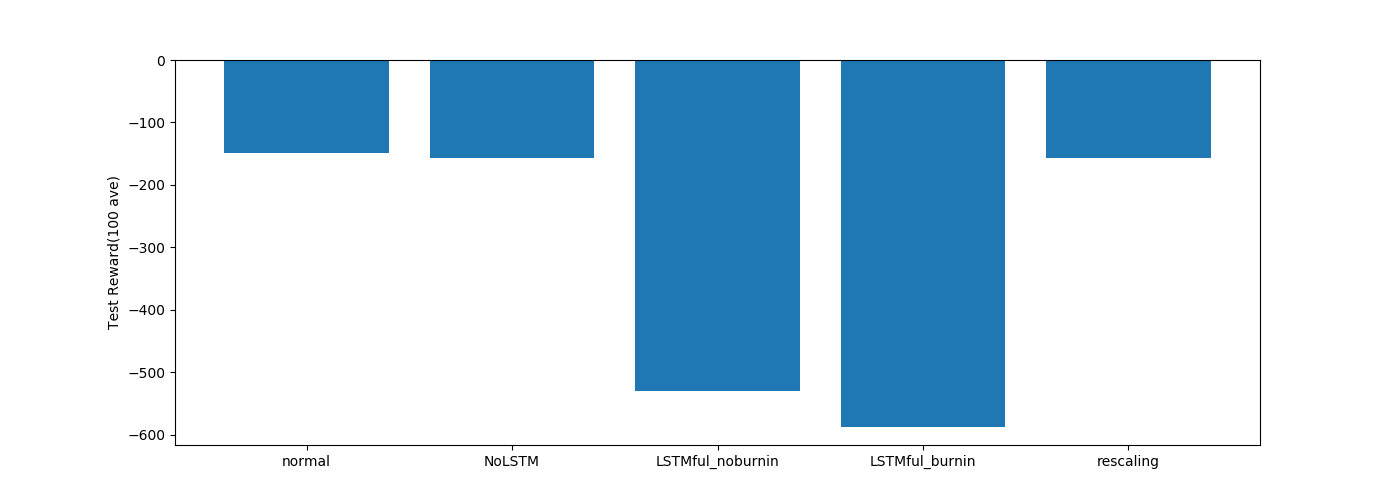
ステートフルLSTMは途中まで学習できているようにみえます。
ミニバッチ学習ができていないので学習回数がまだ足りていないのかもしれません。
・探索関係

少しの差はありますが、どの探索も学習はできていますね。
ε-Greedy系列より他の探索の方が成績がいいような気もします。
結果2(CartPole-v0)
学習過程
・DQN関係

Multireward3 だけ成績がいいですね。
他はあまり変わらない感じです。
・PER関係
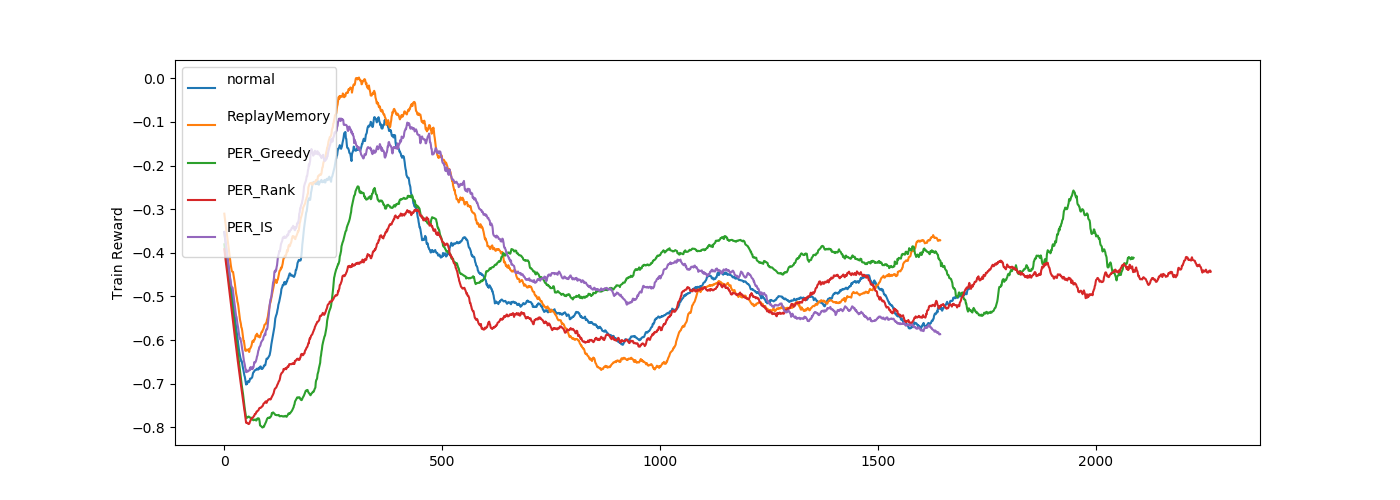
PERもあまり変わらないですね。
・LSTM関係
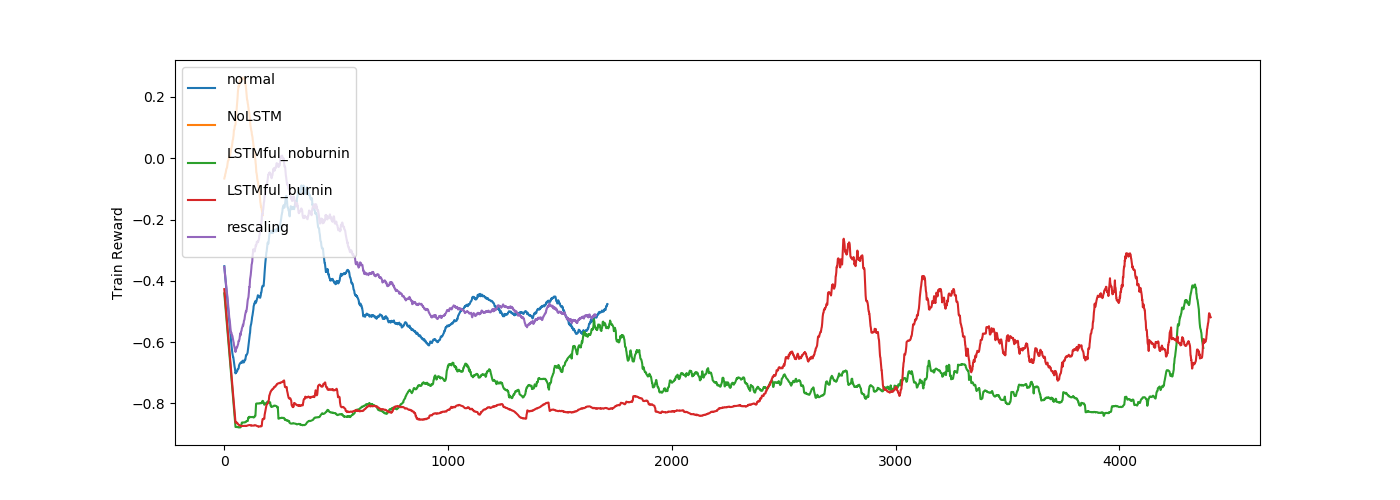
LSTMも変わらず…
・探索関係
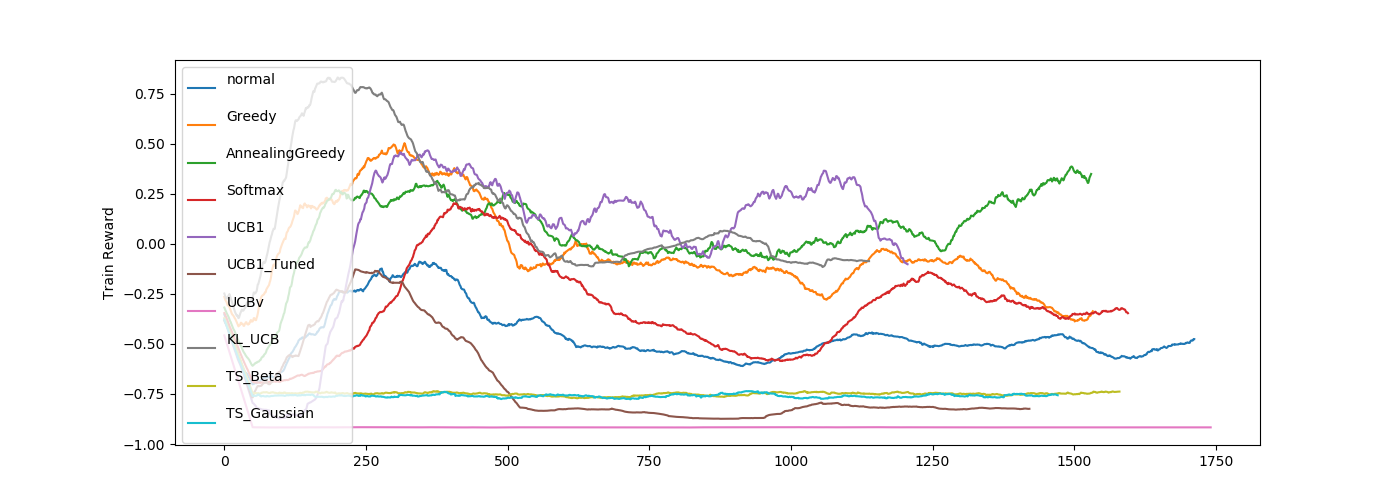
KL-UCB、UCB1、ε-Greedy系の成績がいい感じですね。
学習時間
| グラフ | |
|---|---|
| DQN関係 | 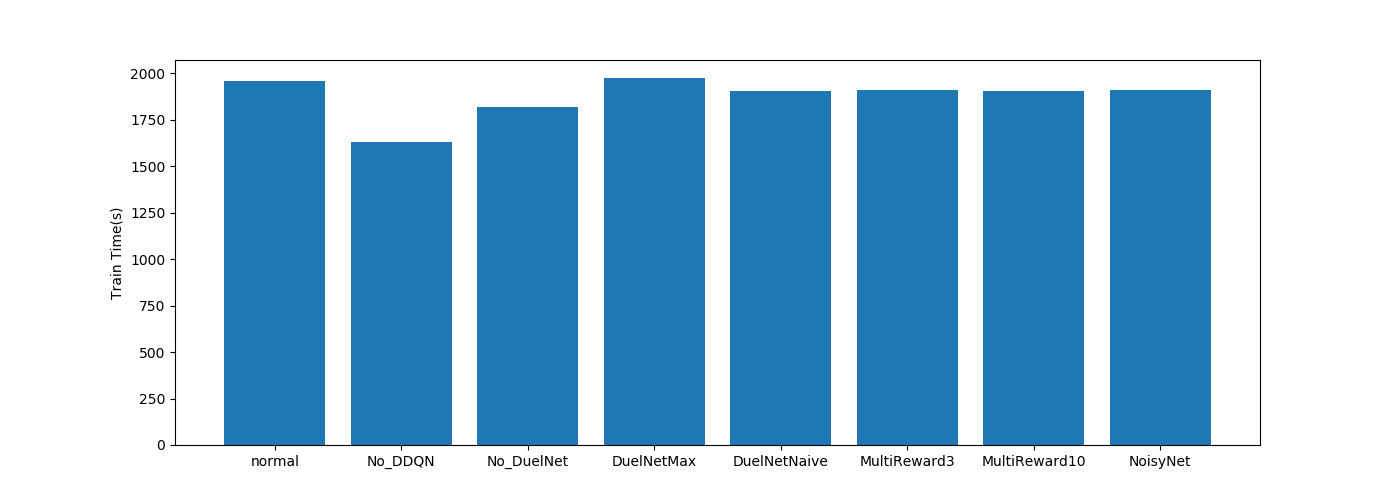 |
| PER関係 | 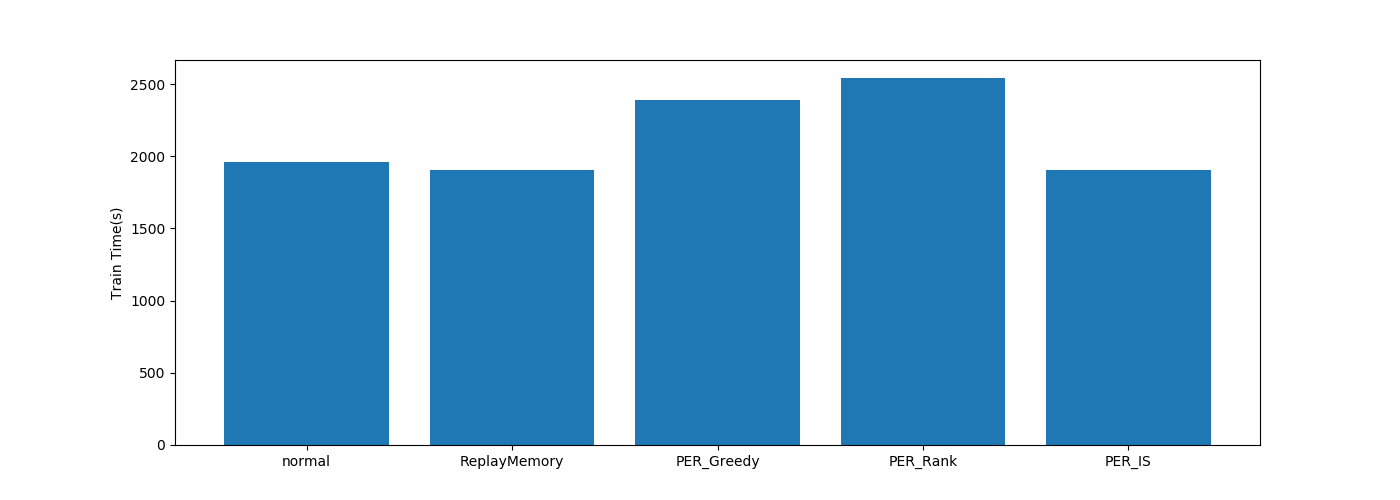 |
| LSTM関係 | 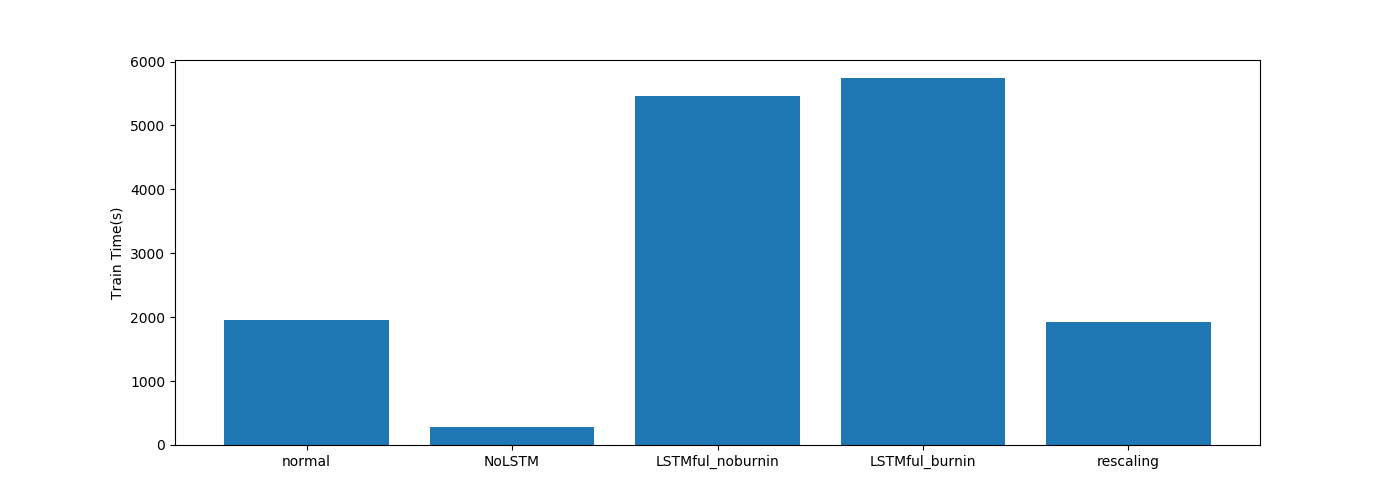 |
| 探索関係 |  |
学習時間はPendulumと変わらずですね。
テスト結果
・DQN関係
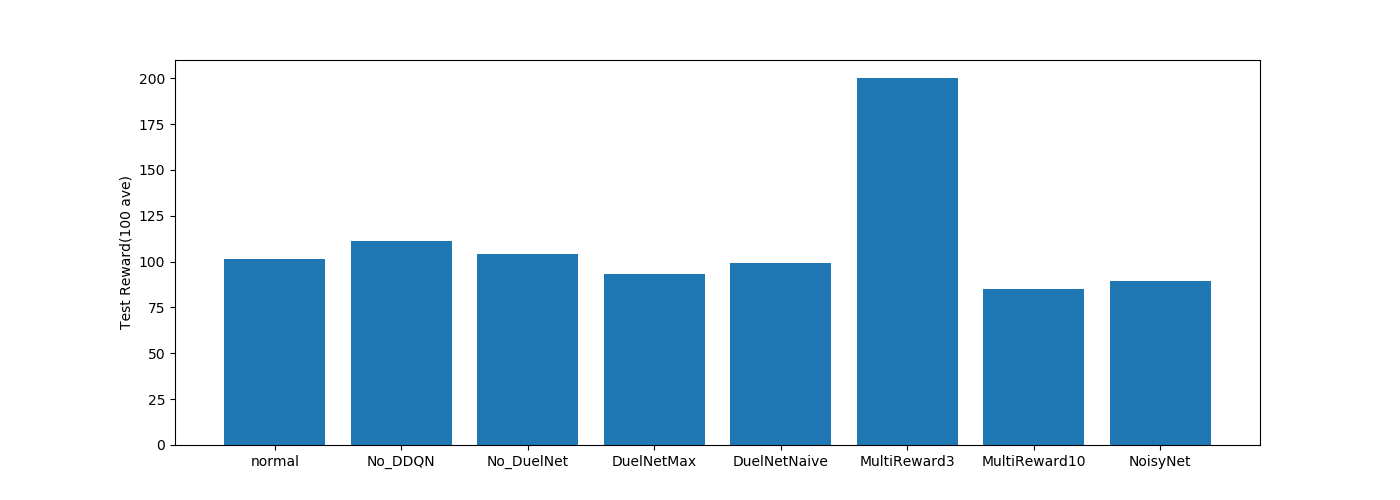
MultistepReward3 の成績がいいですね。
というか今回の比較で200点を出しているのはこれだけですね…
・PER関係
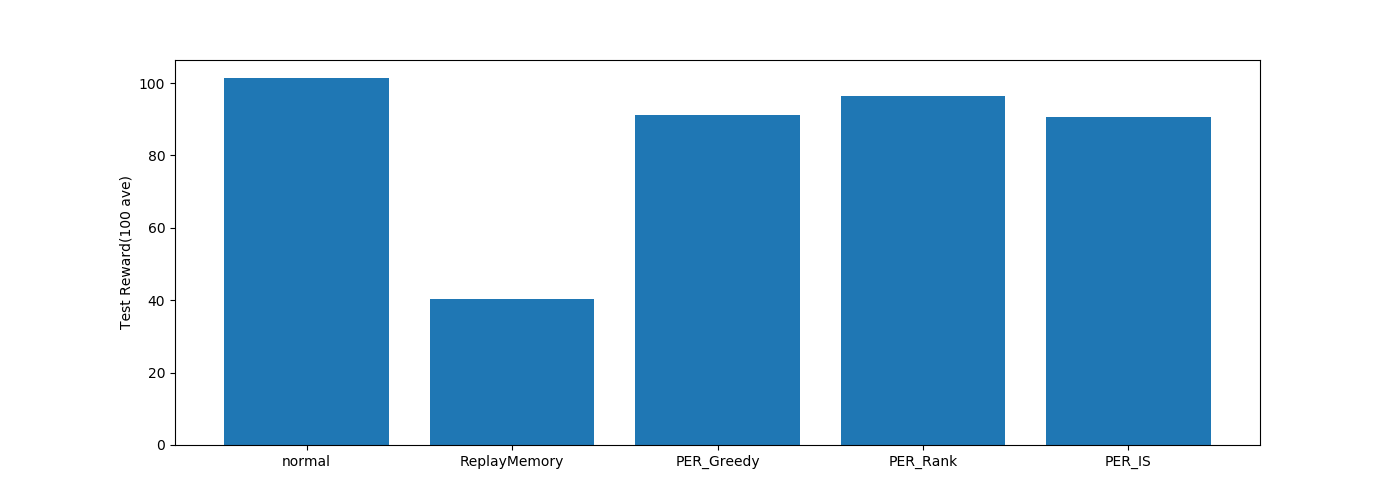
ReplayMemory(ランダム選択)の結果が悪いですね。
PER\Greedy(TD誤差最大)の結果が他と変わらないことから、TD誤差を重視する学習が CartPole には適していそうです。
・LSTM関係
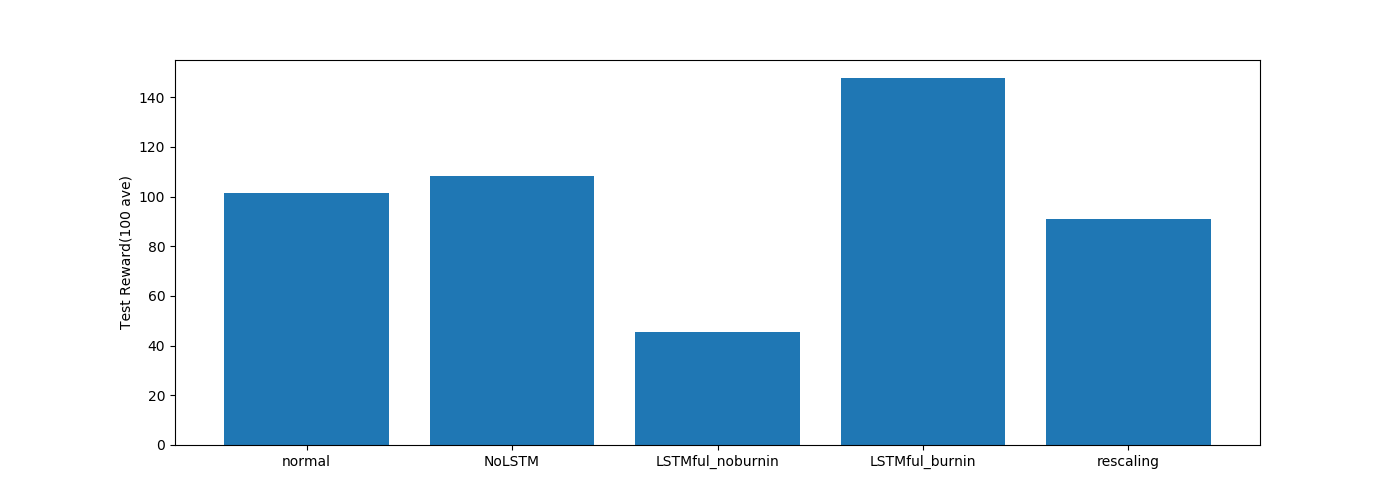
ステートフルLSTMの burn-in の結果がよさげです。
burn-in がない場合との差がすごいですね。
・探索関係

ThompsonSampling(正規分布)が学習できていませんね。
報酬の分布が正規分布とかけ離れているからでしょうか…
結果3(Acrobot-v1)
学習過程
・DQN関係
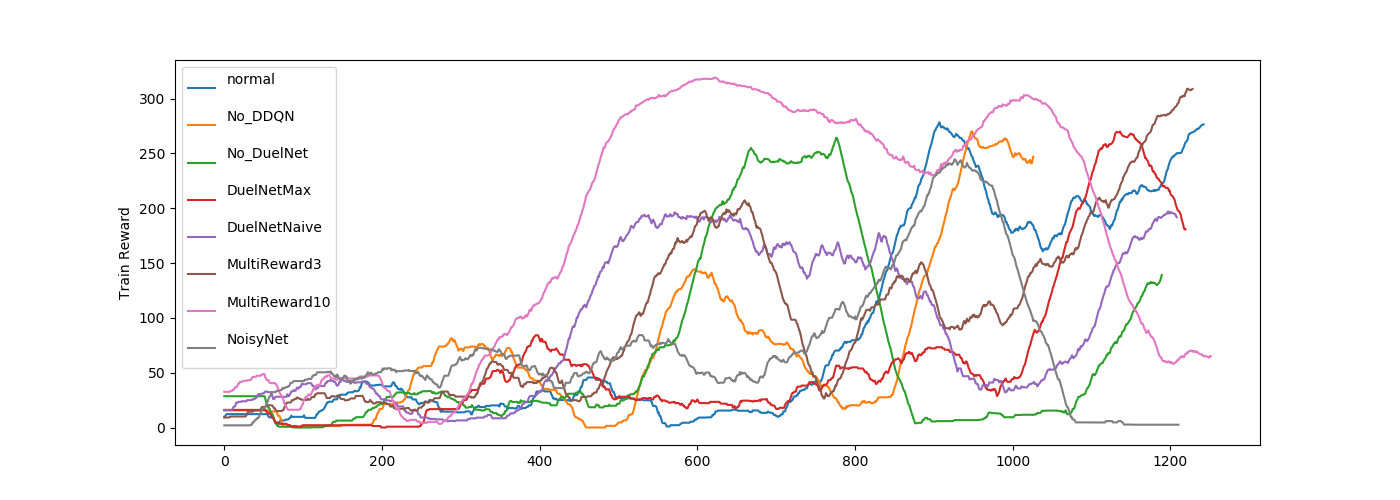
全体的に波がありますね、学習が安定しないゲームなのかもしれません。
・PER関係
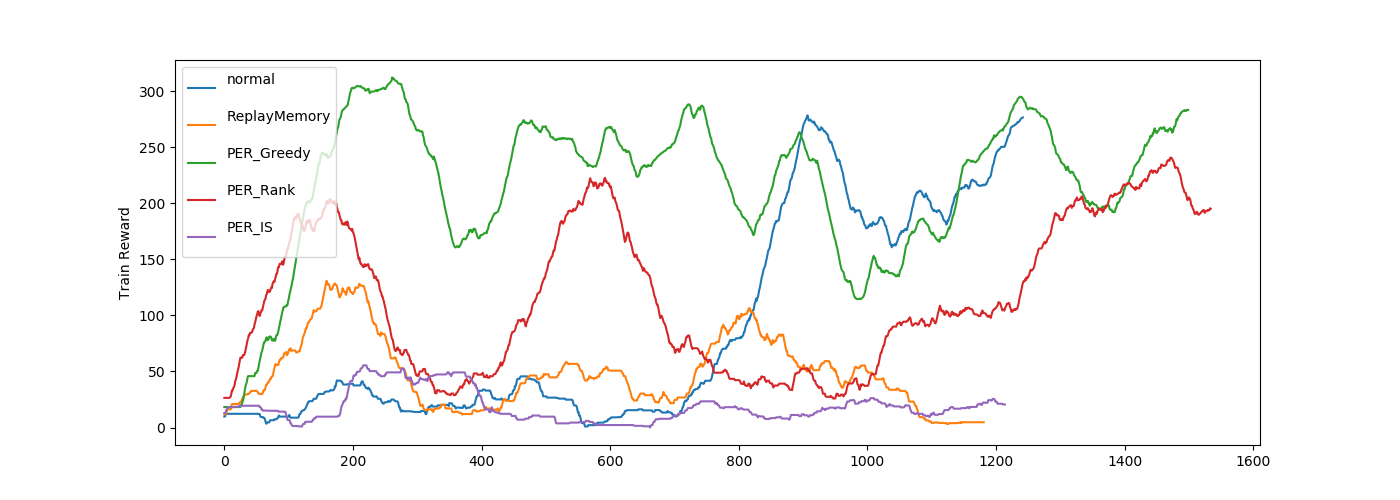
波がありますが、Propotional(normal)、Rankbase、PER_Greedy(TD誤差最大)は学習できていますね。
TD誤差が学習に重要なゲームのようです。
・LSTM関係
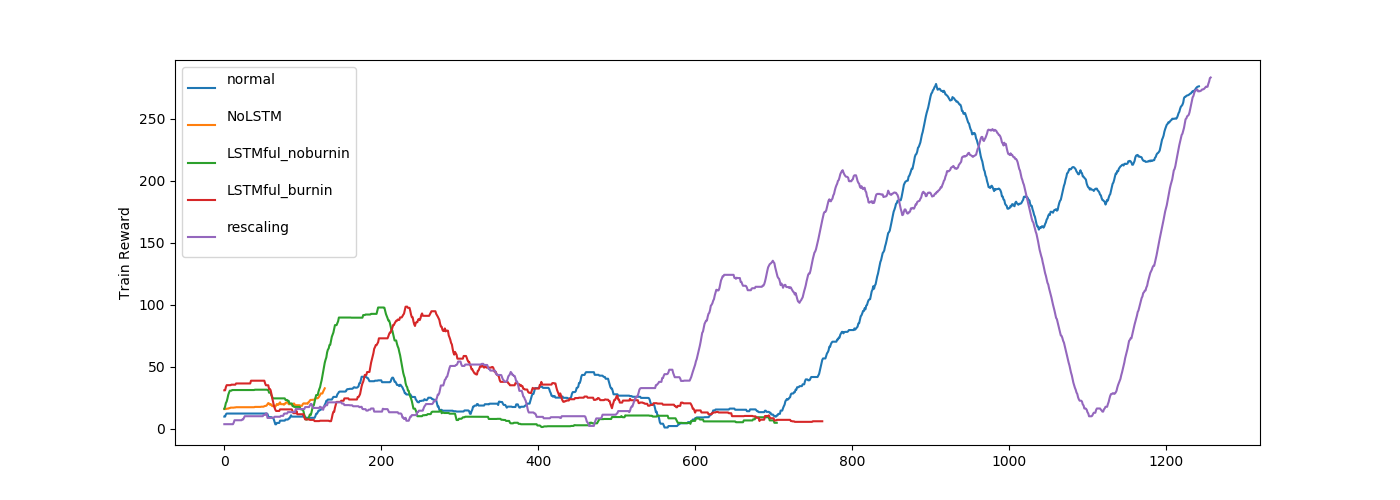
rescaling で学習が安定するかもと思いましたが、あまり変わらないですね。
・探索関係
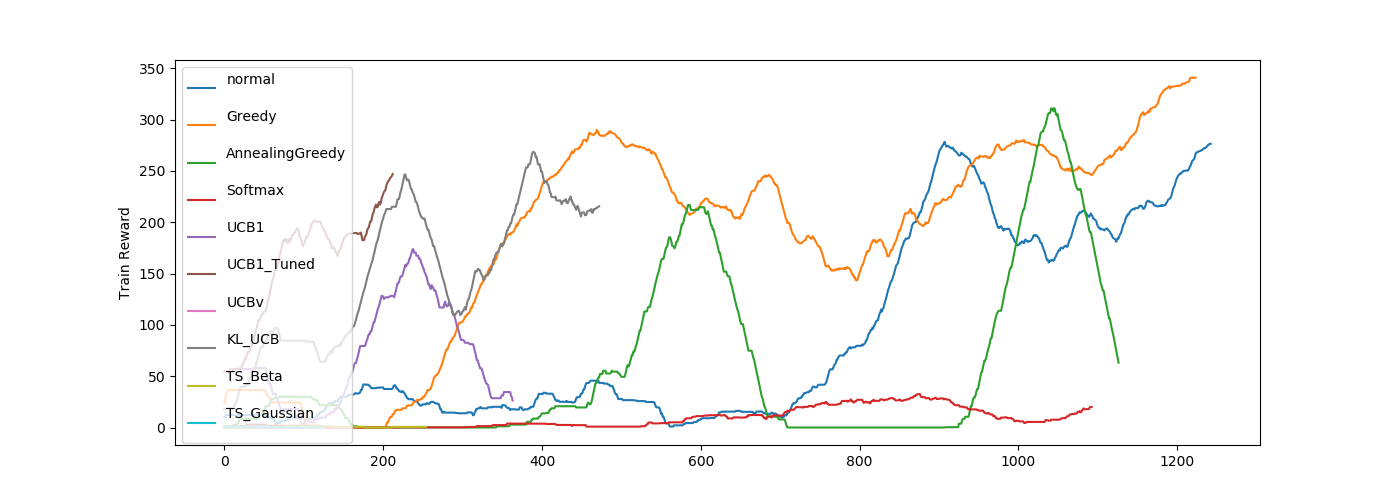
UCB_tunedとKL-UCBの結果がいいですね。
UCBvは得意なゲームとそうじゃないゲームがはっきり分かれますね。
学習時間
| グラフ | |
|---|---|
| DQN関係 |  |
| PER関係 |  |
| LSTM関係 |  |
| 探索関係 |  |
学習時間はPendulumと変わらず。
テスト結果
・DQN関係
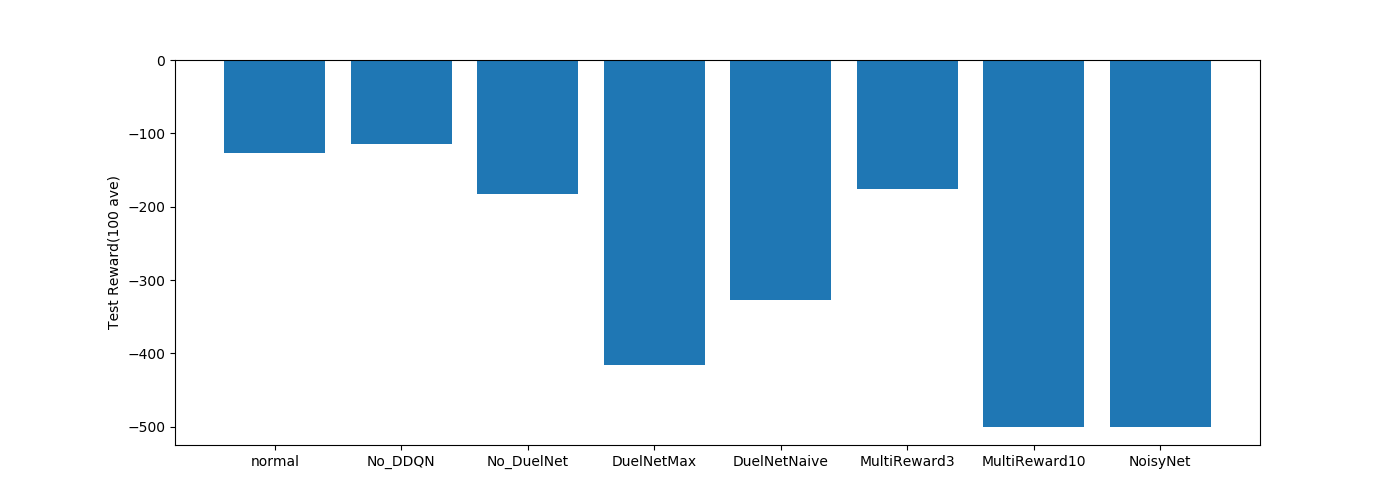
Dueling Networkは使うアルゴリズムでだいぶ違う結果になりました。
normalではave(平均)のアルゴリズムを使っています。
・PER関係

normal(Propotional)以外は学習できていませんね…
・LSTM関係
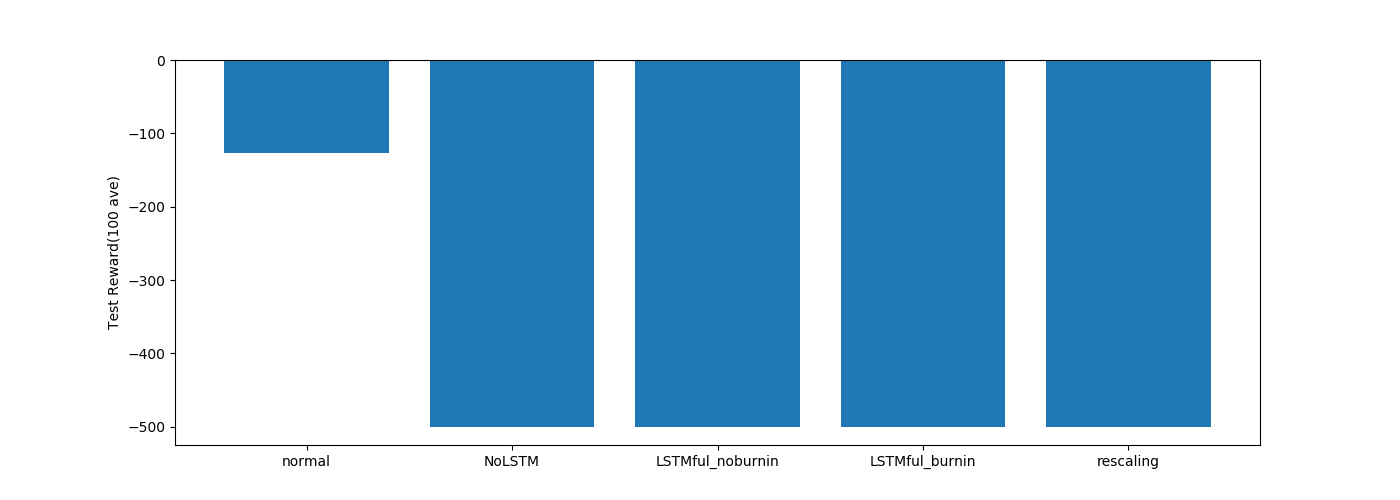
こちらもnormal(ステートレスLSTM)以外は学習できていませんね。
・探索関係

KL-UCB がいい成績です。
Greedyと焼きなましGreedyで差がかなりあります。
ゲーム自体がかなり乱数に左右されそうなゲームなので乱数の影響もかなりありそうです。
まとめ
いろいろ比較してみましたが、強化学習は比較しづらいですね。
ゲームや報酬の与え方で全然違う結果になったりします。
そのため複数のゲームをやって結果を出した方がいいんだろうけど時間が・・・
論文の学習時間を見てみるとAtariのゲームですが120hとか短くても24hなんですよね…
そこまで時間をかけて比較する予定はありません。
その他の改良
記事にする予定はないですが、アイデアだけ。
CNN関係が初期のDQNのままなのでかなり古いです。
BN層やResNet、MobileNetの検討、Dropout層なんか入れても面白いかもしれないですね。
また探索ポリシー編でもいいましたが、Actor 毎に探索ポリシーを変えていろいろな経験を取得する方法はありだと思っています。
他にも R2D2 では Actor の経験と Learner の学習の比率がすごい悪いです。
(PC性能の依存が大きいですが)
その対策として Actor が送信する経験は Priority が高いものに厳選して Learner に送り、Learnerの学習効率をあげるといった処理を入れるのはありかもしれません。
あとがき
Agent 側の実装がこれで終わりました。(長かった)
次は Env 側の実装に移りたいと思います。