今回は少し脱線してみてNNモデルの可視化に挑戦してみました。
ネット上の情報をかき集めて自分なりに実装しているので正確ではないところがある点はご了承ください。
本シリーズ
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(準備編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(Q学習編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(DQN編)
- 【強化学習】Keras-rlでRainbowを実装/解説
- 【強化学習】Keras-rlでApe-Xを実装/解説(並列プログラミング)
- MNISTでSaliencyMapとGrad_CAMを試してDQN(Dueling Network)を可視化してみた(実装/解説)(ここ)
- 【強化学習】2018年度最強と噂のR2D2を実装/解説してみた
- 【強化学習】複数の探索ポリシーを実装/解説して比較してみた
- 【強化学習】DQNのハイパーパラメータを3つのゲームで比較してみた
- 【強化学習】R2D2を実装/解説してみたリベンジ 解説編(Keras-RL)
- 【強化学習】R2D3を実装/解説してみた(Keras-RL)
- 【強化学習】ついに人間を超えた!?Agent57を解説/実装してみた(Keras-RL)
概要
- Kerasで勾配を取得する方法の解説
- MNIST で SaliencyMap の実装/解説
- MNIST で Grad_CAM の実装/解説
- DQN(Dueling Network)に適用
コード全体
本記事で作成したコードは以下です。
※1ファイル完結です。
※GoogleColaboratoryは実行結果付き
- MNIST可視化コード(GitHubGist)
- MNIST可視化コード(GoogleColaboratory)
- DuelingNetwork可視化コード(GitHubGist)
- DuelingNetwork可視化コード(GoogleColaboratory)
NNモデルの可視化について
ディープラーニングによる学習結果の根拠はブラックボックスと言われていますが、可視化する手法も研究されています。
参考
・ディープラーニングの判断根拠を理解する手法
・NNの予測根拠可視化をライブラリ化する
本シリーズで強化学習用の Agent を作成していますがやはり中身がどうなっているか見たい衝動があるので実装してみました。
ただ、本当に見れればいいだけなのであまり深くまで調べていません。
まずは MNIST で可視化をしてみて(グレー画像なのでちょうどいい)、その結果をDQNに反映させます。
MNIST
ディープラーニングのチュートリアルとでもいうべき有名なデータセットですね。
本記事では下記 Keras のサンプルコードを元に説明していきます。
Keras で各層の勾配を取得する方法
Debugging a Keras Neural Network が英語ですがとても分かりやすく書かれていました。
上記を参考にして本記事では解説を行っています。
Layer の名前
NN モデルは Layer に名前がついています。
model.summary() で確認できます。
※Kerasサンプルコードより
(略)
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
print(model.summary()) # model を表示
(略)
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
conv2d_2 (Conv2D) (None, 24, 24, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 12, 12, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 12, 12, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 9216) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 1179776
_________________________________________________________________
dropout_2 (Dropout) (None, 128) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 1290
=================================================================
Total params: 1,199,882
Trainable params: 1,199,882
Non-trainable params: 0
_________________________________________________________________
ここの一番左の Layer が名前です。
例えば一番最初の層は conv2d_1 になります。
この名前は自分でつけることもできます。
今回可視化する層である最後の Conv2D 層と出力層に名前を付けておきます。
※Kerasサンプルコードより
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu', name="conv"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax', name="output"))
Kerasの入力形式に関して
Kesas モデルではNNモデルの入力形式は(batch_size, 層の入力)です。
入力形式は最初の層だけ指定すれば後は自動で変換してくれます。
また、batch_size は None を指定する事もでき、その場合は可変となります。
例えばinput_shape=(3, 4)と指定した場合、(None, 3, 4)という入力になり、
batch_input_shape=(None, 3, 4)と指定した場合と同じになります。
各レイヤーについて
レイヤーの構造について見ていきます。
細かい内容は他に詳しい説明がたくさんあると思うので、ここでは Keras 上での構造を主眼に見ていきます。
今回説明するのは、Conv2D,Flatten,Dense レイヤーとなります。
Conv2D レイヤー
2次元の畳み込みレイヤーです。主に画像に対して使うレイヤーですね。
入力形式はdata_format='channels_last'(デフォルト)の場合(batch_size, rows, cols, channels)で、
data_format='channels_first'の場合(batch_size, channels, rows, cols)になります。
出力形式は、data_format='channels_last'の場合は(samples, rows, cols, channels)になります。
(channels_firstも順番が変わるだけです。)
入力形式から出力形式への変換でどういった処理が行われているかは他に解説がたくさんあるので省略します。
コードの確認は以下です。
conv_layer = model.get_layer("conv")
print(conv_layer.input.shape)
print(conv_layer.output.shape)
※出力結果
(?, 26, 26, 32)
(?, 24, 24, 64)
Flatten レイヤー
入力を平滑化するだけのレイヤーです。
特に計算はしていません。
コードの確認は以下です。
flatten_layer = model.get_layer("flatten_1") # 名前を付けていないので自動でついた名前を使用
print(flatten_layer.input.shape)
print(flatten_layer.output.shape)
※出力結果
(?, 12, 12, 64)
(?, ?)
なぜか output が ? ですけど、12*12*64の(batch_size, 9216)で出力されます。
Dense レイヤー
全結合レイヤーです。
単純に重さを掛けて和をとるだけです。
入力は(batch_size, input_dim)です。
((batch_size, ..., input_dim)もとれるらしいけどここでは説明しません)
入力層に対して指定した Units数で出力します。
(batch_size, units)
以下確認コードです。
output_layer = model.get_layer("output")
print(output_layer.input.shape)
print(output_layer.output.shape)
※出力結果
(?, 128)
(?, 10)
勾配の取得
モデルを可視化するにあたって各層の勾配を取得する必要があるのでその方法を説明します。
勾配を取得するには K.gradients を使います。
K は Keras backends です。
まずは取得する勾配を定義します。
from keras import backend as K
grads = K.gradients(loss, variables)[0]
gradients で variables の loss に関しての勾配を返します。
loss が対象の値で最終的な出力は variables と同じ形式が返ってきます。
gradientsを定義したら次はK.functionを作成します。
grads_func = K.function(inputs=[入力形式], outputs=[grads])
inputs で入力形式を定義し、それを配列で渡します。
入力形式は、レイヤーの途中から入力したい等、変わったことをしない限りmodel.inputになると思います。
outputs は出力形式となります。
勾配を取得したい場合は定義した grads を配列で渡します。
function を定義したら実際に実行します。
outputs_result = grads_func([inputs_value])
function で指定した入力形式で値を入れると、outputs_result に gradients の variables で定義した形式の勾配が返ってきます。
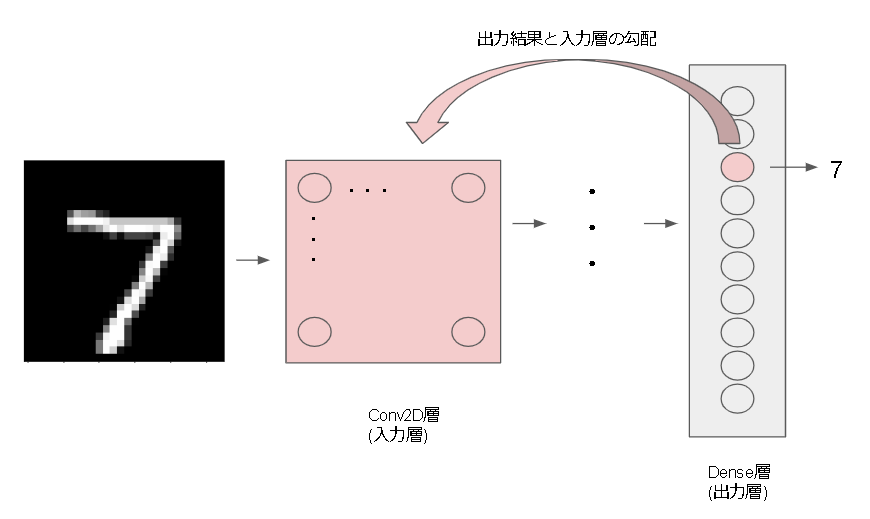
MNIST での SaliencyMap(顕著性マップ)の生成
あまり検索しても出てこないので合っているかは不安ですが、入力に対する変化量が大きい=重要な特徴量として分析する手法の1つです。(Sensitivity Analysis)
変化量は勾配(Gradient)そのものなので、これを出力したものが SaliencyMap となります。
今回は一番簡単な VanillaGrad の実装をしますが、もっと綺麗に見える SmoothGrad 等あるそうです。
勾配の取得は、最後の出力に対する入力層を取得するイメージです。
参考
・MNIST with keras (visualization and saliency map
・https://github.com/experiencor/deep-viz-keras/blob/master/Examples.ipynb
実装
Kerasサンプルコードを元に作成します。
まずは、後で必要になるのでオリジナルイメージを保存しておきます。
(省略)
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
org_img = x_test[0] # 適当に0番目の画像を保存(shape=(28,28))
if K.image_data_format() == 'channels_first':
(省略)
表示します(表示結果は後でまとめて)
import matplotlib.pyplot as plt
plt.imshow(org_img, cmap='gray')
plt.show()
次からはコードの最後に追加していく形になります。
まずは、今回の入力に対する結果を使うので予測します。
import numpy as np
input_val = x_test[0] # 入力値 shape=(28,28,1)
# 予測結果を出す
prediction = model.predict(np.asarray([input_val]), batch_size=1)[0]
prediction_idx = np.argmax(prediction)
predict 関数は (入力値, batch_size) です。
入力値は batch_size の配列を指定する必要があり、今回は1なので [input_val] としています。
また、numpy 配列にする必要があるので np.asarray で囲んでいます。
batch_size はそのまま1です。
戻り値は batch_size 分の配列が返ってくるので [0] としています。
prediction には softmax の結果が入っています。
最大値が予測のラベルになるので np.argmax(prediction) で取り出しています。
>>> print(prediction)
[8.3268287e-10 4.9389903e-10 2.0673903e-09 9.6918678e-09 7.7430857e-12
9.8081224e-11 1.4404127e-14 1.0000000e+00 4.7385915e-12 5.4265028e-09]
>>> print(np.argmax(prediction))
7
今回は正解ラベルが分かっているので予測しないで直接 y_test[0] でもいいかもしれません。
次に勾配計算で使う loss と variables を定義していきます。
まずは loss です。
# loss は出力先の結果
loss = model.get_layer("output").output[0][prediction_idx]
今回model.get_layer("output").output.shapeが(batch_size, num_classes)で
batch_sizeは 1 の予定なので、[0][正解ラベル]としています。
次に variables ですが、勾配先は入力なので入力層を指定します。
variables = model.input
次に勾配の定義です。
grads = K.gradients(loss, variables)[0]
[0]は配列で返ってくるのでつけています。
次に function です。
grads_func = K.function(
[model.input, K.learning_phase()],
[grads])
入力は model の入力層とK.learning_phase()です。
K.learning_phaseは学習かどうかのフラグを返します。
学習とテストで挙動が変わるモデルでは入力する必要がありますね。
今回ですと dropout 層が該当します。
参考:Kerasで学ぶ転移学習
次に実際に計算させて結果を取得します。
values = grads_func([np.asarray([input_val]), 0])
values = values[0] # 配列が返ってくるので[0]
入力はmodel.inputにあわせてinput_valを入力します。
0 はテストであることを示します。
values には loss と variables の勾配を計算した結果が入っています。
shape は variables の形になるので(1,28,28,1)です。(最初の1はbatch_size)
表示
参考先のコードを見ると0以上でマスクしたり、絶対値をとったりとここの処理は色々ありそうです。
とりあえず絶対値での表示にしておきます。
img = values[0] # (1,28,28,1) -> (28,28,1)
img = img.reshape((28,28)) # (28,28,1) -> (28,28)
img = np.abs(img) # 絶対値
# 表示(表示結果は後でまとめて)
plt.imshow(img, cmap='gray')
plt.show()
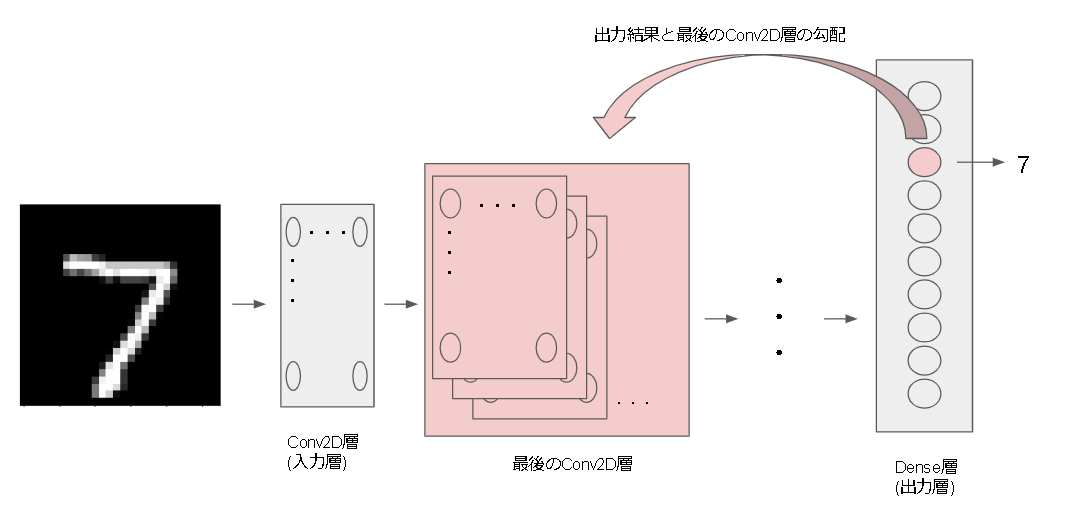
MNIST での Grad_CAM の生成
NNモデルの可視化を検索すると一番多く出てくる手法が Grad CAM ではないでしょうか。
Conv層を可視化する技術です。
詳細な解説は(自分もよく分かっていないため)省略します。
勾配計算のイメージは以下です。
参考
・https://github.com/jacobgil/keras-grad-cam
・Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization
・Grad-CAMでヒートマップを表示
・深層学習は画像のどこを見ている!? CNNで「お好み焼き」と「ピザ」の違いを検証
実装
出力する Conv レイヤーを指定します。
Grad CAM 的には一番最後の Conv レイヤーを指定するそうです。
まずは対象の Conv レイヤーの output を取得します。(これが勾配の variable になります)
conv_layer_output = model.get_layer("conv").output
次に予測結果を出し、それを loss とします。
ここは SaliencyMap と同じです。
input_val = x_test[0] # 入力値 shape=(28,28,1)
# 予測結果を出す
prediction = model.predict(np.asarray([input_val]), 1)[0]
prediction_idx = np.argmax(prediction)
loss = model.get_layer("output").output[0][prediction_idx]
勾配を定義します。
grads = K.gradients(loss, conv_layer_output)[0]
grads_func = K.function([model.input, K.learning_phase()], [conv_layer_output, grads])
ここで function の出力に conv_layer_output も加えています。
これは勾配だけではなく、conv_layer_output の実際の出力結果もほしいためです。
(conv_output, conv_values) = grads_func([np.asarray([input_val]), 0])
conv_output = conv_output[0] # (24, 24, 64)
conv_values = conv_values[0] # (24, 24, 64)
引数は SaliencyMap と同じですが戻り値が増えています。
conv_output は conv_layer_output が実際に出力する値です。
conv_values は出力層(今回は7)に対する勾配の値が入っています。
ここから Grad CAM の計算です。
weights = np.mean(conv_values, axis=(0, 1)) # 勾配の平均をとる
cam = np.dot(conv_output, weights) # 出力結果と重さの内積をとる
計算結果を画像にしていきます。
import cv2
# Conv層の画像はサイズが違うのでリサイズ。
cam = cv2.resize(cam, (28,28), cv2.INTER_LINEAR)
# heatmap?
cam = np.maximum(cam, 0)
cam = cam / cam.max()
# モノクロ画像に疑似的に色をつける
cam = cv2.applyColorMap(np.uint8(255 * cam), cv2.COLORMAP_JET)
# オリジナルイメージもカラー化
org_img = cv2.cvtColor(np.uint8(org_img), cv2.COLOR_GRAY2BGR) # (w,h) -> (w,h,3)
# 元のイメージに合成
rate = 0.4
cam = cv2.addWeighted(src1=org_img, alpha=(1-rate), src2=cam, beta=rate, gamma=0)
cam = cv2.cvtColor(cam, cv2.COLOR_BGR2RGB) # BGR -> RGBに変換
# 表示
plt.imshow(cam)
plt.show()
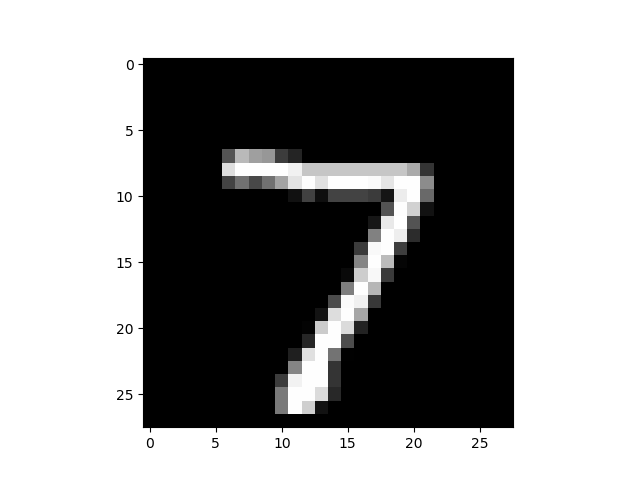
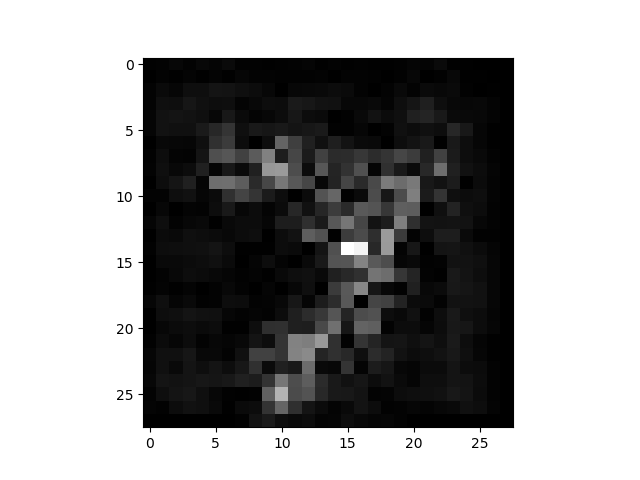
結果
| オリジナル | SaliencyMap | Grad_CAM |
|---|---|---|
 |
 |
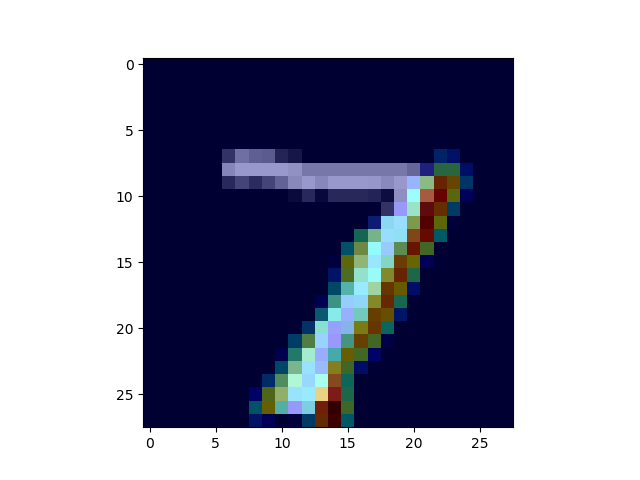 |
SaliencyMap では7っぽい所の特徴が出力されていますね。
Grad CAMでは7の右下の棒が特徴として強調されています。
Dueling Network の可視化
Dueling Network については本シリーズの Rainbow編を見てください。
Dueling Networkの論文では状態価値関数とAdvantage関数を可視化しており、たぶんその方法が SaliencyMap ではないのかと思っています。
Dueling Network の論文:https://arxiv.org/pdf/1511.06581.pdf
可視化に使われている論文:https://arxiv.org/pdf/1312.6034.pdf
入力情報の取得(Keras-rl の Callback の作成)
可視化にあたり実際の入力情報がほしいので Callback を定義して取得します。
import rl.callbacks
class ObservationLogger(rl.callbacks.Callback):
def __init__(self):
self.observations = []
def on_step_end(self, step, logs):
self.observations.append(logs["observation"])
on_step_end は step 終了時に実行され、logs には以下の情報が入っています。
step_logs = {
'action': action,
'observation': observation,
'reward': reward,
'metrics': metrics,
'episode': episode,
'info': accumulated_info,
}
これを test 実行時に渡します。
※Rainbow編のコードより、最後の部分です。
# 訓練結果を見る
processor.mode = "test" # env本来の報酬を返す
agent.test(env, nb_episodes=5, visualize=True)
↓
# 訓練結果を見る
processor.mode = "test" # env本来の報酬を返す
logger = ObservationLogger()
agent.test(env, nb_episodes=5, visualize=True, callbacks=[logger])
matplotlib の animation
動画で見たいので animation 設定します。
参考
・matplotlib でアニメーションを作る
・matplotlibでアニメーション
今回は FuncAnimation で実行するのでフレーム処理する plot 関数を作成します。
plot 関数の作成
まずは前処理です。
def plot(frame):
# global から変数を引っ張っているので注意
observations = logger.observations
window_length = agent.window_length
model = agent.model
# 入力分の frame がたまるまで待つ
if frame < window_length:
return
# 入力用の変数を作成
# 入力は window_length の長さ分必要(DQN編を参照)
input_state = observations[frame - window_length:frame]
# ついでに shape も取得
shape = np.asarray(observations[0]).shape
# 出力用のオリジナル画像を作成
# 形式は(w,h)でかつ0~1で正規化されているので画像形式に変換
img = np.asarray(observations[frame]) # (w,h)
img *= 255
img = cv2.cvtColor(np.uint8(img), cv2.COLOR_GRAY2BGR) # (w,h) -> (w,h,3)
(SaliencyMap と Grad_CAM の作成)
(plot で表示)
SaliencyMap と Grad_CAM の作成
まずは layer を取得するために名前を付けます。
RainbowAgent クラスの編集箇所のみとなります。
折角なので全ての Conv2D の結果をとりたいと思います。
class RainbowAgent(rl.core.Agent):
def build_network(self):
(省略)
if self.enable_image_layer:
(省略)
c = Conv2D(32, (8, 8), strides=(4, 4), padding="same", name="c1")(c)
c = Activation("relu")(c)
c = Conv2D(64, (4, 4), strides=(2, 2), padding="same", name="c2")(c)
c = Activation("relu")(c)
c = Conv2D(64, (3, 3), strides=(1, 1), padding="same", name="c3")(c)
c = Activation("relu")(c)
c = Flatten()(c)
if self.enable_dueling_network:
# value
v = Dense(self.dence_units_num, activation="relu")(c)
v = Dense(1, name="v")(v)
# advance
adv = Dense(self.dence_units_num, activation='relu')(c)
adv = Dense(self.nb_actions, name="adv")(adv)
(省略)
return Model(input_, c)
enable_image_layer と enable_dueling_network が両方 True であることを前提にこの記事は進めています。
plot 関数に戻ってレイヤーを取得します。
※plot関数内
c1_output = model.get_layer("c1").output
c2_output = model.get_layer("c2").output
c3_output = model.get_layer("c3").output
v_output = model.get_layer("v").output
adv_output = model.get_layer("adv").output
勾配を計算していきます。
※plot関数内
# 予測結果を出す
prediction = self.model.predict(np.asarray([input_state]), 1)[0]
class_idx = np.argmax(prediction)
class_output = self.model.output[0][class_idx]
# 各勾配を定義
# adv層は出力と同じ(action数)なので予測結果を指定
# v層はUnit数が1つしかないので0を指定
grads_c1 = K.gradients(class_output, c1_output)[0]
grads_c2 = K.gradients(class_output, c2_output)[0]
grads_c3 = K.gradients(class_output, c3_output)[0]
grads_adv = K.gradients(adv_output[0][class_idx], model.input)[0]
grads_v = K.gradients(v_output[0][0], model.input)[0]
# functionを定義、1度にすべて計算
grads_func = K.function([model.input, K.learning_phase()],
[c1_output, grads_c1, c2_output, grads_c2, c3_output, grads_c3, grads_adv, grads_v])
# 勾配を計算
(c1_output, c1_val, c2_output, c2_val, c3_output, c3_val, adv_val, v_val) =
grads_func([np.asarray([input_state]), 0])
adv_val = adv_val[0][window_length-1] # window_length あるので最後のフレーム情報を取得
v_val = v_val[0][window_length-1] # window_length あるので最後のフレーム情報を取得
# SaliencyMap
adv_val = np.abs(adv_val.reshape(shape))
v_val = np.abs(v_val.reshape(shape))
# Grad-CAMの計算と画像化、3回も書きたくないので関数化
cam1 = grad_cam(c1_output, c1_val, img, shape)
cam2 = grad_cam(c2_output, c2_val, img, shape)
cam3 = grad_cam(c3_output, c3_val, img, shape)
def grad_cam(c_output, c_val, img, shape):
c_output = c_output[0]
c_val = c_val[0]
weights = np.mean(c_val, axis=(0, 1))
cam = np.dot(c_output, weights)
cam = cv2.resize(cam, shape, cv2.INTER_LINEAR)
cam = np.maximum(cam, 0)
cam = cam / cam.max()
cam = cv2.applyColorMap(np.uint8(255 * cam), cv2.COLORMAP_JET)
rate = 0.4
cam = cv2.addWeighted(src1=img, alpha=(1-rate), src2=cam, beta=rate, gamma=0)
cam = cv2.cvtColor(cam, cv2.COLOR_BGR2RGB) # 色をRGBに変換
return cam
pltで表示します。
ここはちょっと適当かも・・・
# plot
imgs = [img, cam1, cam2, cam3, adv_val, v_val]
names = ["original", "c1", "c2", "c3", "advance", "value"]
cmaps = ["", "", "", "", "gray", "gray"]
for i in range(len(imgs)):
plt.subplot(2, 3, i+1)
plt.gca().tick_params(labelbottom="off",bottom="off") # x軸の削除
plt.gca().tick_params(labelleft="off",left="off") # y軸の削除
plt.title(names[i]).set_fontsize(12)
if cmaps[i] == "":
plt.imshow(imgs[i])
else:
plt.imshow(imgs[i], cmap=cmaps[i])
これで plot 関数は完成です。
matplotlib の実行
plt.figure(figsize=(8.0, 6.0), dpi = 100) # 大きさを指定
plt.axis('off')
# FuncAnimation で plot 関数を指定します。
ani = matplotlib.animation.FuncAnimation(plt.gcf(), plot, frames=len(logger.observations), interval=5)
# ani.save('anim.mp4', writer="ffmpeg")
# ani.save('anim.gif', writer="imagemagick", fps=60)
plt.show()
# Google Colaboratory
# from IPython.display import HTML
# HTML(ani.to_jshtml())
最後のコメントアウトですが、plt.show() だと普通に表示します。
ani.save で gif や mp4 で保存できますが、imagemagick のインストール等が必要です。
(本記事では省略します)
Pendulum の実行結果

画像は c1 レイヤーで学習されていますね。
シンプルなゲームなので Conv2D レイヤーが3層もいらなそうです。
状態価値関数と Advantage 関数も違いがあまり表れていませんね。
まあこれもシンプルなゲームなのと違いが表れるほど学習していないことが原因だと思います。
あとがき
R2D2 に苦戦中なので息抜きに可視化してみました。
思ったより大変でしたが…
次回は R2D2 で使われている LSTM に踏み込んでみます。