qiita初投稿です。
少しやりたいことがあり最近の強化学習を実装したく調べてみました。
強化学習を行うための要素を自分なりにかみ砕いて記事にしていく予定で、その備忘録の意味合いが強い記事となります。
また、ネット情報を元に勝手に解釈して書いている部分があるので理解不足・不正確な情報があることはご容赦ください。
本シリーズ
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(準備編)(ここ)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(Q学習編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(DQN編)
- 【強化学習】Keras-rlでRainbowを実装/解説
- 【強化学習】Keras-rlでApe-Xを実装/解説(並列プログラミング)
- MNISTでSaliencyMapとGrad_CAMを試してDQN(DuelingNetwork)を可視化してみた(実装/解説)
- 【強化学習】2018年度最強と噂のR2D2を実装/解説してみた
- 【強化学習】複数の探索ポリシーを実装/解説して比較してみた
- 【強化学習】DQNのハイパーパラメータを3つのゲームで比較してみた
- 【強化学習】R2D2を実装/解説してみたリベンジ 解説編(Keras-RL)
- 【強化学習】R2D3を実装/解説してみた(Keras-RL)
- 【強化学習】ついに人間を超えた!?Agent57を解説/実装してみた(Keras-RL)
概要
- 環境構築(windows10でgymとkeras-rl)
- 動作する最小コード(gym)
- 動作する最小コード(keras-rl)
- keras-rl の学習過程の簡単な可視化
- gym を GoogleColaboratoryで描画
コード全体
本記事で作成したコードは以下です。
※1ファイル完結です。
※GoogleColaboratoryは実行結果付き
環境構築
本記事の環境
- windows10
- Google Colaboratory
最終的にやりたいことがwindows上で動かすことなのでwindows実装がメインです。
ただ、無料でGPU資源が使える Google Colaboratory はとても魅力的なのでこちらでも実装していきます。
各種インストール(windows10)
python
python公式 から python3.6 の最新版をインストールします。
最初 python3.7 で試したら tensorflow が対応していませんでした。(2019/4/10頃)
また、anacondaと同時に入れると相性が悪いようです。
(anaconda だけ or python3.6 のみが良さそうです。本記事は python3.6.8 を入れています)
git
こちらも git公式 からインストールしておきます。
この後のインストール作業で必要になります。
tensorflow
今回使用する keras-rl で必要になります。
pipでインストールを行います。(CPU版をいれています)
> pip install tensorflow
OpenAI Gym
強化学習のシミュレーション用プラットフォームを提供するpythonライブラリです。
参考:OpenAI Gym 入門(qiita)
環境側はこのgymを用いて用意する予定です。
> pip install gym
※ atari関係のゲームを試したいなら以下も実行
> pip install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py
参考:windowsにOpenAIgym[atari]を入れる
Keras-rl
機械学習ライブラリの tensorflow を書きやすくしたライブラリとして有名な Keras ですが、それを強化学習として提供しているのが Keras-rl です。
OpenAI Gym にも対応しています。
参考:Keras-RLを用いた深層強化学習コト始め(qiita)
pipでインストールします。
> pip install keras
> git clone https://github.com/matthiasplappert/keras-rl.git
> pip install ./keras-rl
scikit-learn
データの分割やスコアの表示などのライブラリを使う場合があるので入れておくといいかも。
> pip install scikit-learn
画像出力関係のライブラリ
画像処理もいろいろするので入れておきます。
> pip install matplotlib
> pip install pillow
> pip install opencv-python
Google Colaboratory
グーグルアカウントを持っていれば以下にアクセスするだけです。
https://colab.research.google.com/notebooks/welcome.ipynb
ただ、実行するにあたって90分/12時間ルールというものが存在します。
機械学習では一晩放置して結果を見ることもあるので、そういう時は90分ルールの方は対策しておいた方がいいでしょう。
参考:Google Colaboratoryの90分セッション切れ対策【自動接続】
動作テスト OpenAI Gym(windows10)
まずはゲームを選択します。
かなりたくさんのゲームがあります。詳細は公式へ。
例としてCartPoleという振り子ゲームを試してみます。
まずはゲームを作成します。
import gym
env = gym.make('CartPole-v0') # ゲームを選択
ゲームの各種情報は以下で見る事が出来ます。
>>> # アクション(入力)の形式
>>> env.action_space
Discrete(2)
>>> # 環境(出力)の形式
>>> env.observation_space
Box(4,)
>>> # 報酬の取りうる範囲(未定義の場合は(-inf,inf))
>>> env.reward_range
(-inf, inf)
Discrete は離散値を表し Discrete(2) なら0か1です。
Box は次元?を表し、Box(4,) は [1,2,3,4] みたいな1次元要素4の値を返します。
Box(2,2)なら[[0,1],[1,2]]みたいな2次元要素2です。
次はゲームのメインループ部分です。
フローとしてはゲームループと、1ゲーム内のループの2重ループ構造となります。
for i in range(5): # 5回ゲーム
env.reset() # ゲームの初期化
env.render() # ゲームの描画
# 1ゲームのループ、今回は最大 200 step実行。
for step in range(200):
# アクションを取得
action = env.action_space.sample()
# 1step 実行する。
# 戻り値は、環境,報酬,終了判定(done),情報?
observe, reward, done, _ = env.step(action)
env.render() # 描画
# 終了判定がTrueなら1ゲーム終了
if done:
break
アクションの所ですが、
env.action_space.sample()
はアクションの値(今回ですと0か1)をランダムで返してくれます。
動作テスト OpenAI Gym + keras-rl
解説
keras-rl には標準でDQNを実装したagentがあるのでそれを用いて先ほどのゲームを学習させていきます。
まずはDQN用のNNモデルを作成します。
NNモデルを作るにあたって重要なのが入力と出力の形(shape)です。(これが合わずにエラーが何回吐かれたことか…)
まずは入力部分です。
import gym
env = gym.make('CartPole-v0')
window_length = 1
input_shape = (window_length,) + env.observation_space.shape)
env.observation_space.shape で環境から入力の shape が取得できます。(今回は(4)です)
それに window_length の (1) を足して、今回入力するshapeは (1,4) になります。
この (1) はフレーム数となり、keras-rl の DQNAgent 内で使用している値となります。
ですので DQNAgent を使わなければ不要です。
次に出力です。
nb_actions = env.action_space.n
nb_actions はシンプルに2(整数)が入ります。
次にNNモデル全体を定義していきます。
from keras.models import Sequential
from keras.layers import *
model = Sequential()
model.add(Flatten(input_shape=input_shape))
model.add(Dense(16, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(nb_actions, activation='linear'))
各層の詳細については今回は省略します。(多分別の記事で書くと思います)
重要な点は入力層と出力層です。
入力層は Flatten で入力の(1,4)を(4)と平滑化し、
最後の層(出力層)は nb_actions にして出力の数と同じにしています。
このモデルを出力すると以下のようになります。
>>> print(model.summary())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 4) 0
_________________________________________________________________
dense_1 (Dense) (None, 16) 80
_________________________________________________________________
dense_2 (Dense) (None, 16) 272
_________________________________________________________________
dense_3 (Dense) (None, 16) 272
_________________________________________________________________
dense_4 (Dense) (None, 2) 34
=================================================================
Total params: 658
Trainable params: 658
Non-trainable params: 0
_________________________________________________________________
ちなみにこのモデルは以下のように書いても同じです。
今後の事もあるので基本は以下のようにSequentialは使わずに定義していきます。
from keras.models import Model
from keras.layers import *
c = input_ = Input(input_shape)
c = Flatten()(c)
c = Dense(16, activation='relu')(c)
c = Dense(16, activation='relu')(c)
c = Dense(16, activation='relu')(c)
c = Dense(nb_actions, activation='linear')(c)
model = Model(input_, c)
さて、次にDQNAgentの定義をします。
細かい数値の意味は別の記事で書く予定です。(今回は省略)
from rl.agents.dqn import DQNAgent
from rl.policy import BoltzmannQPolicy
from rl.memory import SequentialMemory
from keras.optimizers import Adam
memory = SequentialMemory(limit=50000, window_length=window_length)
policy = BoltzmannQPolicy()
agent = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10, target_model_update=1e-2, policy=policy)
agent.compile(Adam())
これでトレーニングができます。
agentのfitを実行すると上記のgym動作テストのような一連のフローを実行して学習してくれます。
agent.fit(env, nb_steps=10000, visualize=False, verbose=1)
nb_steps は試行回数なので好きな値をどうぞ。
途中でやめたい場合はCrtl+Cで中断できます。
学習が終わったら次にテストをします。
agent.test(env, nb_episodes=5, visualize=True)
nb_episodes はゲーム回数となります。
こちらも好きな値をどうぞ、5にすると5回ゲームを実行します。
Keras-rlの使い方は以上となります。
参考:https://github.com/keras-rl/keras-rl/blob/master/examples/dqn_cartpole.py
keras-rl の学習過程の可視化サンプル
fit 関数の戻り値には学習過程の履歴が入っています。
matplotlib で表示する例を記載しておきます。
import matplotlib.pyplot as plt
# fit の結果を取得しておく
history = agent.fit(env, nb_steps=10000, visualize=False, verbose=1)
# 結果を表示
plt.subplot(2,1,1)
plt.plot(history.history["nb_episode_steps"])
plt.ylabel("step")
plt.subplot(2,1,2)
plt.plot(history.history["episode_reward"])
plt.xlabel("episode")
plt.ylabel("reward")
plt.show() # windowが表示されます。
各episodeでのstep数と報酬の推移が以下のように表示されます。
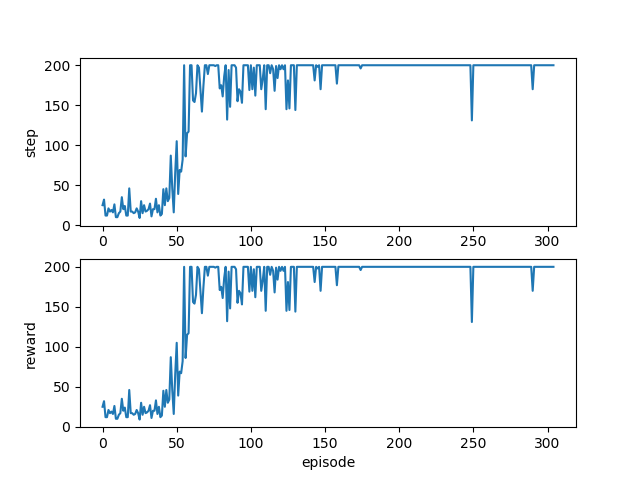
GoogleColaboratory で実行して表示する。
GoogleColaboratory上はHTMLなため、gym の render による描画が行えません。
実行すると以下のようなエラーが出ます。
NoSuchDisplayException Traceback (most recent call last)
<ipython-input-5-01266f628c54> in <module>()
4
5 # 訓練結果を見る
----> 6 dqn.test(env, nb_episodes=5, visualize=True)
13 frames
/usr/local/lib/python3.6/dist-packages/pyglet/canvas/xlib.py in __init__(self, name, x_screen)
84 self._display = xlib.XOpenDisplay(name)
85 if not self._display:
---> 86 raise NoSuchDisplayException('Cannot connect to "%s"' % name)
87
88 screen_count = xlib.XScreenCount(self._display)
NoSuchDisplayException: Cannot connect to "None"
とか
/usr/local/lib/python3.6/dist-packages/pyglet/gl/__init__.py in <module>()
225 else:
226 from .carbon import CarbonConfig as Config
--> 227 del base
228
229 # XXX remove
NameError: name 'base' is not defined
など…
色々調べてここのコードがすごい参考になりました。
https://colab.research.google.com/drive/1GLlB53gvZaUyqMYv8GmZQJmshRUzV_tg#scrollTo=ObsNH6K6l6ZI
以下、GoogleColaboratory用のコードです。
まずはおまじないで以下を書きます。(自分もよくわかっていない)
# installing dependencies
!apt-get -qq -y install libcusparse8.0 libnvrtc8.0 libnvtoolsext1 > /dev/null
!ln -snf /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so.8.0 /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so
!apt-get -qq -y install xvfb freeglut3-dev ffmpeg> /dev/null
!pip -q install gym
!pip -q install pyglet
!pip -q install pyopengl
!pip -q install pyvirtualdisplay
# Start virtual display
from pyvirtualdisplay import Display
display = Display(visible=0, size=(1024, 768))
display.start()
import os
os.environ["DISPLAY"] = ":" + str(display.display) + "." + str(display.screen)
keras-rl が入っていないので入れます。
!pip install keras-rl
結果を表示するためにcallback関数を自作しました。
agent.test()関数のcallbackでの使用を想定しています。
import rl.callbacks
import matplotlib.pyplot as plt
import matplotlib.animation
import time
class ViewLogger(rl.callbacks.Callback):
def __init__(self):
self.frames = []
# Callback から継承しています。
def on_action_end(self, action, logs):
self.frames.append(self.env.render(mode='rgb_array'))
# 表示用
def view(self, interval=5, start_frame=0, end_frame=0):
assert start_frame<len(self.frames)
if end_frame == 0:
end_frame = len(self.frames)
elif end_frame > len(self.frames):
end_frame = len(self.frames)
self.start_frame = start_frame
self.t0 = time.time()
# 表示サイズをここで指定しています。
plt.figure(figsize=(2.5,2.5), dpi = 200)
self.patch = plt.imshow(self.frames[0])
plt.axis('off')
ani = matplotlib.animation.FuncAnimation(plt.gcf(), self._plot, frames=end_frame - start_frame, interval=interval)
return ani.to_jshtml()
def _plot(self, frame):
if frame % 200 == 0:
print("{}f {}m".format(frame, (time.time()-self.t0)/60))
self.patch.set_data(self.frames[frame + self.start_frame])
time周りは必要ないのですが、処理に時間がかかる場合があり動いているかわからなかったので入れています。
使い方は以下です。
testのcallbacks引数に追加する形です。
view = ViewLogger()
agent.test(env, nb_episodes=5, visualize=False, callbacks=[view])
from IPython.display import HTML
HTML(view.view(interval=10, start_frame=0, end_frame=0))
intervalは描画速度(1frameの間隔)です。
start_frameとend_frameで描画範囲を指定できます。(0なら全てです)
注意点ですが、HTML()を呼び出した後の同じセル内でprintは使わないでください。(なぜかうまく表示されません)
また、複数のセッションを実行している場合もうまく描画できない気がします。
まとめ
準備編として環境構築からとりあえず動くところまでと可視化部分を実装してみました。
gym + keras-rlによる最低限の学習+結果の可視化を windows10 と GoogleColaboratory で実行できました。
次は最新のアルゴリズムに追いつくためにまずはQ学習の実装から始めたいと思います。