今回はDQN(Deep Q Network)の実装です。
これはすでに公式で実装されているのですが、理解のために自分なりに実装してみました。
本シリーズ
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(準備編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(Q学習編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(DQN編)(ここ)
- 【強化学習】Keras-rlでRainbowを実装/解説
- 【強化学習】Keras-rlでApe-Xを実装/解説(並列プログラミング)
- MNISTでSaliencyMapとGrad_CAMを試してDQN(DuelingNetwork)を可視化してみた(実装/解説)
- 【強化学習】2018年度最強と噂のR2D2を実装/解説してみた
- 【強化学習】複数の探索ポリシーを実装/解説して比較してみた
- 【強化学習】DQNのハイパーパラメータを3つのゲームで比較してみた
- 【強化学習】R2D2を実装/解説してみたリベンジ 解説編(Keras-RL)
- 【強化学習】R2D3を実装/解説してみた(Keras-RL)
- 【強化学習】ついに人間を超えた!?Agent57を解説/実装してみた(Keras-RL)
追記:改めて記事にしています。
概要
- keras-rlにて、DQN用のAgentを実装
- Pendiumゲームで画像なしによる学習を実施
- Pendiumゲームで画像版による学習を実施
コード全体
本記事で作成したコードは以下です。
※1ファイル完結です。
※GoogleColaboratoryは実行結果付き
DQN(Deep Q Network)について
DQNはQ学習にて状態が非線形だと取りうる値が多すぎて学習が間に合わないというアイデアが基本となっている気がします(勝手な想像)
QテーブルをNNで近似するというのが基本アイデアですが、それ以外にもかなりたくさんの手法を取り入れていることが特徴です。
DQNを実装しつつ、各手法を解説していきたいと思います。
DQNAgent(keras-rlのAgent)の実装概要
まずは全体像です。
実装する keras-rl の Agent を元に概要を書きます。
import rl.core
class DQNAgent(rl.core.Agent):
def __init__(self, **kwargs):
super(DQNAgent, self).__init__(**kwargs)
self.compiled = False
(各ハイパーパラメータの初期化)
・NNモデル(model)の作成
・NNモデル(target_model)の作成
def reset_states(self):
(各種初期化)
def compile(self, optimizer=None, metrics=[]):
self.compiled = True
・NNモデル(model)のコンパイル
・NNモデル(target_model)のコンパイル
def load_weights(self, filepath):
(modelのload)
def save_weights(self, filepath, overwrite=False):
(modelのsave)
def forward(self, observation):
・複数フレームの入力処理
・ミニバッチ学習
・フレームスキップ条件
if self.training:
・ϵを減少させるϵ-greedy法でアクションを決定
else:
・Q値が最大のアクション
return action
def backward(self, reward, terminal):
・一定間隔でtarget_modelを更新
return []
@property
def layers(self):
return []
DQNの各種手法の実装
Qネットワークの定義
以下となります。NNモデルは参考文献をもとにしています。
実装が終わったら改良していきたいですが、とりあえずそのまま実装します。
| Layer | Filter | NumFilters | Stride | Activation |
|---|---|---|---|---|
| Conv2D | 8×8 | 32 | 4 | ReLU |
| Conv2D | 4×4 | 64 | 2 | ReLU |
| Conv2D | 3×3 | 64 | 1 | ReLU |
| fc | 512 | ReLU | ||
| Output | nb_actions | Liner |
from keras.layers import * #*はめんどくさいだけです
from keras.models import Model
def build_network(self):
# 入力層(window_length, width, height)
c = input_ = Input(shape=(self.window_length,) + self.input_shape)
if self.enable_image_layer:
c = Permute((2, 3, 1))(c) # (window,w,h) -> (w,h,window)
c = Conv2D(32, (8, 8), strides=(4, 4), padding="same")(c)
c = Activation("relu")(c)
c = Conv2D(64, (4, 4), strides=(2, 2), padding="same")(c)
c = Activation("relu")(c)
c = Conv2D(64, (3, 3), strides=(1, 1), padding="same")(c)
c = Activation("relu")(c)
c = Flatten()(c)
c = Dense(512, activation="relu")(c)
c = Dense(self.nb_actions, activation="linear")(c) # 出力層
return Model(input_, c)
window_length は後述します。
enable_image_layer を True にすると input_shape が画像になります。
input_shape(width, height) のグレー画像の入力を想定しておりサイズはコンストラクタで指定予定です。
((width,height,channel) 形式には対応していません)
enable_image_layer が False の場合は input_shape はデータになります。
入力後すぐに Flatten(平滑化) されるので特に形式の指定はありません(多分。。。)
def __init__(self, input_shape, enable_image_layer):
self.input_shape = input_shape
self.enable_image_layer = enable_image_layer
Target Network
Target Network という更新用のQネットワークを用意して一定間隔で今のQネットワークをコピーします。
Target Network は一定間隔更新が行われないので古いパラメータを使って更新が行われることとなります。
これによってQ値の更新に時差が生まれて学習がよくなるらしいです。
Q networkと Target Networkの作成
先ほど作成した build_network 関数を使って同じネットワークをそれぞれ作成します。
def __init__(self):
self.model = self.build_network() # Q network
self.target_model = self.build_network() # target network
コンパイル
optimaizer はユーザが指定する形なので省略します。
論文では独自の RMSProp を使っていますが… まあ RMSProp を改良した Adam が keras で実装されているのでそちらを使います。
また、Target Network のほうは更新しないので oprimizer と損失関数は何でも大丈夫です。
def compile(self, optimizer, metrics=[]):
# target networkは更新がないので optimizerとlossは何でもいい
self.target_model.compile(optimizer='sgd', loss='mse')
def clipped_error_loss(y_true, y_pred):
・損失関数の定義
self.model.compile(loss=clipped_error_loss, optimizer=optimizer, metrics=metrics)
self.compiled = True
損失関数は後述します。
エラークリップ(損失関数)
Huber損失関数を導入しているとの事。
ここあまりよく分かっていませんが、実装は以下のようです。
import tensorflow as tf
from keras import backend as K
def clipped_error_loss(y_true, y_pred):
err = y_true - y_pred # エラー
L2 = 0.5 * K.square(err)
L1 = K.abs(err) - 0.5
# エラーが[-1,1]区間ならL2、それ以外ならL1を選択する。
loss = tf.where((K.abs(err) < 1.0), L2, L1) # Keras does not cover where function in tensorflow :-(
return K.mean(loss)
参考:https://github.com/jaromiru/AI-blog/blob/master/CartPole-DQN.py
TargetNetworkの更新
更新するタイミングに違いはない気がするので backward 内で更新しています。
更新は簡単で、keras の model に set_weights/get_weights 関数が定義されています。
def backward(self, reward, terminal):
# 一定間隔でtarget modelに重さをコピー
if self.step % self.target_model_update == 0:
self.target_model.set_weights(self.model.get_weights())
return []
step は keras-rl 側で定義されており、1step で1づつ増えます( episode を跨いでも増えていきます)
target_mode_update はハイパーパラメータで TargetNetwork の更新間隔です。
Experience Replay
過去の遷移を覚えておき、学習はその中からランダムで選んだ遷移で学習を行います。
Experience Replay用のメモリを作成
deque がランダムアクセスに対して遅いらしいので自作しました。(今後のこともあるので…)
参考:https://github.com/y-kamiya/machine-learning-samples/blob/7b6792ce37cc69051e9053afeddc6d485ad34e79/python3/reinforcement/dqn/agent.py
import random
class ReplayMemory():
def __init__(self, capacity):
self.capacity= capacity
self.index = 0
self.memory = []
def add(self, experience):
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.index] = experience
self.index = (self.index + 1) % self.capacity
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
リングバッファ構造です。
capacity を超えるデータが来た場合、古いものから消えていきます。
データの取得は random.sample 関数でランダムに重複なしで取得します。
Experience Replayの初期化
コンストラクタで初期化します。
保存サイズはハイパーパラメータです。
def __init__(self, memory_capacity=1_000_000):
self.memory = ReplayMemory(capacity=memory_capacity)
連続フレームの保存
直近の数フレームを環境(状態)とするために保存します。
ここはReplayメモリと被るのでうまく実装すればメモリが節約できそうですがとりあえず愚直に実装します。
直近のフレーム数は window_length としてハイパーパラメータ化とし、window_length + 1 のサイズの変数を作成します。
+1は1つ先の状態の保存用です。
def __init__(self, window_length=4):
self.window_length = window_length
def reset_states(self):
self.recent_observations = [np.zeros(self.input_shape) for _ in range(self.window_length+1)]
更新は forward 関数の先頭で行います。
def forward(self, observation):
self.recent_observations.append(observation) # 最後に追加
self.recent_observations.pop(0) # 先頭を削除
取得する場合は以下の通り、
0~window_length までが現在の状態、1~window_length+1 までが次の状態です。
# 現在の状態
self.recent_observations[:self.window_length]
# 次の状態
self.recent_observations[1:]
actionとrewardの保存
actionとrewardはQ学習と同様です。
# 初期化
def reset_states(self):
self.recent_action = 0
self.recent_reward = 0
# 1つ前を保持
def forward(observation):
(省略)
self.recent_action = action
return action
def backward(self, reward, terminal):
self.recent_reward = reward
ミニバッチ学習
学習箇所をまとめた関数を作成します。
forward内に直接書いてもいいのですが、長くなるので分けています。
まずは概要です。
def forward_train(self):
if not self.training:
return
・ReplayMemoryに追加
# ReplayMemory確保のため一定期間学習しない。
if self.step <= self.nb_steps_warmup:
return
# 学習の更新間隔
if self.step % self.train_interval != 0:
return
・ReplayMemory からバッチデータを取得
・バッチデータと target_model を元に model を更新(学習)
nb_steps_warmup と train_interval はハイパーパラメータです。
def __init__(self, nb_steps_warmup=50000, train_interval=4):
self.nb_steps_warmup = nb_steps_warmup
self.train_interval = train_interval
ReplayMemoryに追加
(現在の状態, アクション, 報酬, 次の状態) の形で追加します。
self.memory.add((
self.recent_observations[:self.window_length],
self.recent_action,
self.recent_reward,
self.recent_observations[1:]
))
ReplayMemoryからバッチデータを取得
ReplayMemoryから取り出した後、この後使いやすいように成形します。
batchs = self.memory.sample(self.batch_size)
state0_batch = []
action_batch = []
reward_batch = []
state1_batch = []
for batch in batchs:
state0_batch.append(batch[0])
action_batch.append(batch[1])
reward_batch.append(batch[2])
state1_batch.append(batch[3])
batch_size はハイパーパラメータです。
def __init__(self, batch_size=32):
self.batch_size = batch_size
バッチデータを用いてQネットワークを更新
まず更新用に現在のQ値を取得します。
outputs = self.model.predict(np.asarray(state0_batch), self.batch_size)
predict 関数で NN モデルの結果を取得できます。
引数には numpy 型をとる必要があります。
shapeとしては、(batch_size, window_length, input_shape) で入力され、(batch_size, nb_actions) で返ってきます。
同様に更新用のQ値を取得します。
こちらは TargetNetwork から取得します。
target_qvals = self.target_model.predict(np.asarray(state1_batch), self.batch_size)
Q学習と同じ計算式で各バッチデータに対して更新をかけます。
for i in range(self.batch_size):
maxq = np.max(target_qvals[i])
td_error = reward_batch[i] + self.gamma * maxq
outputs[i][action_batch[i]] = td_error
Q学習のα相当はがないですが、optimizer側で処理するのでなくなっていると思います。(多分…)
最後に学習させます。
self.model.train_on_batch(np.asarray(state0_batch), np.asarray(outputs))
こういうバッチ処理で学習する場合は fit より train_on_batch の方がいいらしいです。
追記:いろいろ見ていたら fit でも問題なさそうです。
フレームスキップ
毎フレーム学習するのはコストが高くなるので、一定間隔毎に学習させる方法です。
実装ではフレームスキップ中は同じactionを実行し続ける形となります。
まずはフレームスキップ用の変数を初期化し、スキップ間隔をハイパーパラメータとします。
def __init__(self, action_interval=4):
self.action_interval = action_interval
def reset_states(self):
self.repeated_action = 0
forward内のactionを決定する箇所の実行を一定フレーム間隔にします。
def forward(self, observation):
(省略)
action = self.repeated_action
if self.step % self.action_interval == 0:
・アクションの決定
self.repeated_action = action
self.recent_action = action
return action
アクションの決定
Q学習とほとんど同じです。(epsilon の算出は後述)
if self.training:
epsilon を算出
# ϵ-greedy法
if epsilon > np.random.uniform(0, 1):
# ランダム
action = np.random.randint(0, self.nb_actions)
else:
# 現在の状態を取得し、最大Q値から行動を取得。
state0 = self.recent_observations[1:]
q_values = self.model.predict(np.asarray([state0]), batch_size=1)[0]
action = np.argmax(q_values)
else:
# 現在の状態を取得し、最大Q値から行動を取得。
state0 = self.recent_observations[1:]
q_values = self.model.predict(np.asarray([state0]), batch_size=1)[0]
action = np.argmax(q_values)
ϵ-greedy法の改善
ϵ-greedy法にて ϵ を最初は高い数字(ランダムで移動)にし、後半になるほど低い値(Q値に従う)にします。
ハイパーパラメータとして初期ε値の initial_epsilon、最後のε値の final_epsilon、何フレームかけて減らすかの exploration_steps を追加します。
def __init__(self, initial_epsilon=1.0, final_epsilon=0.1, exploration_steps=1000000):
self.initial_epsilon = initial_epsilon
self.epsilon_step = (initial_epsilon - final_epsilon) / exploration_steps
self.final_epsilon = final_epsilon
算出は以下。
epsilon = self.initial_epsilon - self.step*self.epsilon_step
if epsilon < self.final_epsilon:
epsilon = self.final_epsilon
save/load
model を保存するだけです。
def load_weights(self, filepath):
self.model.load_weights(filepath)
def save_weights(self, filepath, overwrite=False):
self.model.save_weights(filepath, overwrite=overwrite)
Processor側の実装
報酬の固定
報酬をマイナスなら-1、プラスなら+1にする手法です。
報酬の設定は学習するゲームにかなり依存するのでこの手法は何とも言えませんが…
実装する場合はAgentではなくProcessorで定義する方がいいでしょう。
import rl.core
class PendulumProcessorForDQN(rl.core.Processor):
def process_reward(self, reward):
return np.clip(reward, -1., 1.)
画像の前処理
3点あるらしいです。
- 210×160 → 84×84 にリサイズ
- 2フレームから最大値をとる。(atariは奇数フレームと偶数フレームで片方しか表示されなかったりするらしいです)
- グレー化
今回は1つ目と3つめのみ実装しています。
2つ目はあまりにも atari に依存しすぎている気はするので…
こちらも実装はProcessorですね。
import rl.core
from PIL import Image
class PendulumProcessorForDQN(rl.core.Processor):
def __init__(self, enable_image=False, reshape_size=(84, 84)):
self.shape = reshape_size
self.enable_image = enable_image
def process_observation(self, observation):
if not self.enable_image:
return observation
img = Image.fromarray(observation)
img = img.resize(self.shape).convert('L') # resize and convert to grayscale
return np.array(img) / 255 # DQNに渡しやすいように正規化
コンストラクタで入力が画像かどうかを指定できるようにしています。
アクション
線形モデルを出力する形ではないのでQ学習と変わらず離散化します。
def process_action(self, action):
ACT_ID_TO_VALUE = {
0: [-2.0],
1: [-1.0],
2: [0.0],
3: [+1.0],
4: [+2.0],
}
return ACT_ID_TO_VALUE[action]
Pendiumゲームで学習
##画像なしによる学習
Q学習とほぼ一緒です。
まずは画像なしバージョンです。
import gym
from keras.optimizers import Adam
# 別ファイルにあると仮定しています。コード全体では1つのファイルにまとめています。
from PendulumProcessorForDQN import PendulumProcessorForDQN
from DQNAgent import DQNAgent
env = gym.make("Pendulum-v0")
nb_actions = 5 # PendulumProcessorで5個と定義しているので5
processor = PendulumProcessorForDQN(enable_image=False)
# 引数が多いので辞書で定義して渡しています。
args={
"input_shape": env.observation_space.shape,
"enable_image_layer": False,
"nb_actions": nb_actions,
"window_length": 1, # 入力フレーム数
"memory_max_size": 10_000, # 確保するメモリーサイズ
"nb_steps_warmup": 200, # 初期のメモリー確保用step数(学習しない)
"target_model_update": 100, # target networkのupdate間隔
"action_interval": 1, # アクションを実行する間隔
"train_interval": 1, # 学習する間隔
"batch_size": 64, # batch_size
"gamma": 0.99, # Q学習の割引率
"initial_epsilon": 1.0, # ϵ-greedy法の初期値
"final_epsilon": 0.1, # ϵ-greedy法の最終値
"exploration_steps": 5000, # ϵ-greedy法の減少step数
"processor": processor,
}
agent = DQNAgent(**args)
agent.compile(optimizer=Adam()) # optimizerはAdamを指定
# 訓練
print("--- start ---")
print("'Ctrl + C' is stop.")
history = agent.fit(env, nb_steps=50_000, visualize=False, verbose=1)
# 結果を表示
plt.subplot(2,1,1)
plt.plot(history.history["nb_episode_steps"])
plt.ylabel("step")
plt.subplot(2,1,2)
plt.plot(history.history["episode_reward"])
plt.xlabel("episode")
plt.ylabel("reward")
plt.show()
# 訓練結果を見る
agent.test(env, nb_episodes=5, visualize=True)
結果
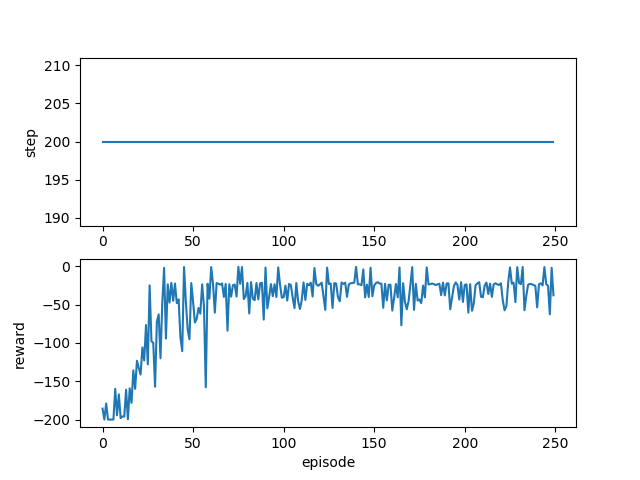

ちゃんと学習できていますね。
画像ありによる学習
画像への変換は以下を参考にしました。
Keras-RLを用いた深層強化学習コト始め
Processorの変更
from PIL import Image, ImageDraw
def process_observation(self, observation):
if not self.enable_image:
return observation
img = self._get_rgb_state(observation)
img = Image.fromarray(img)
img = img.resize(self.shape).convert('L') # resize and convert to grayscale
return np.array(img) / 255 # DQNに渡しやすいように正規化
# 状態(x,y座標)から対応画像を描画する関数
def _get_rgb_state(self, state):
img_size = 84
h_size = img_size/2.0
img = Image.new("RGB", (img_size, img_size), (255, 255, 255))
dr = ImageDraw.Draw(img)
# 棒の長さ
l = img_size/4.0 * 3.0/ 2.0
# 棒のラインの描写
dr.line(((h_size - l * state[1], h_size - l * state[0]), (h_size, h_size)), (0, 0, 0), 1)
# 棒の中心の円を描写(それっぽくしてみた)
buff = img_size/32.0
dr.ellipse(((h_size - buff, h_size - buff), (h_size + buff, h_size + buff)), outline=(0, 0, 0), fill=(255, 0, 0))
# 画像の一次元化(GrayScale化)とarrayへの変換
pilImg = img.convert("L")
img_arr = np.asarray(pilImg)
# 画像の規格化
img_arr = img_arr/255.0
return img_arr
こちらは変更部分のみ
(省略)
processor = PendulumProcessorForDQN(enable_image=True, reshape_size=(84, 84))
(省略)
# 引数が多いので辞書で定義して渡しています。
args={
"input_shape": (84, 84),
"enable_image_layer": True,
(省略)
"window_length": 3, # 入力フレーム数
(省略)
"batch_size": 8, # batch_size
"exploration_steps": 50000, # ϵ-greedy法の減少step数
}
(省略)
history = agent.fit(env, nb_steps=100_000, visualize=False, verbose=1)
(省略)
window_length は角速度に相当する情報の必要を考慮して3フレームにしています。
また batch_size を小さくしたのは時間の関係です。
batch_size や nb_steps、exploration_steps は時間との兼ね合いで微調整しており、GoogleColaboratory で値が違います。
(やはりGPUは早いですね)
結果
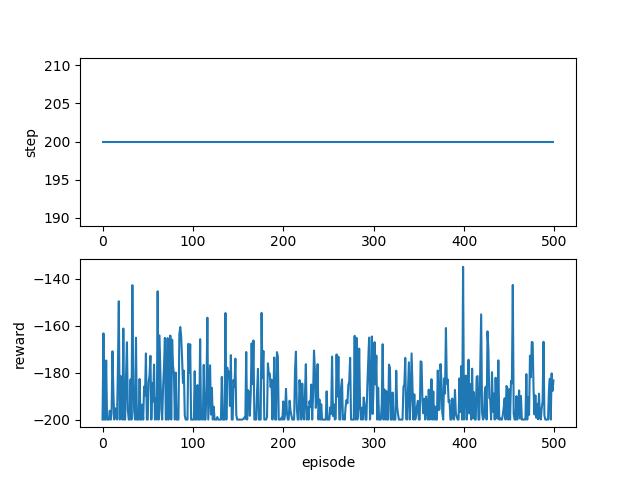

学習できていないですね…、試行回数が少ないという事にしましょう。(コードに間違いがあったらすいません)
まとめ
想像以上に使われてる手法が多くて…
説明が漏れている所もあるかも知れません。
ただ、DQN系列の強化学習はこれがベースとなるのでいい勉強になりました。
次はDoubleDQN、DurlingNetwork、(できればPrioritizedExperienceReplay)を実装したいと思います。
参考
・Optimizer : 深層学習における勾配法について
・https://github.com/keras-rl/keras-rl/blob/master/rl/agents/dqn.py
・DQNをKerasとTensorFlowとOpenAI Gymで実装する
・DQNからRainbowまで 〜深層強化学習の最新動向〜