なにやらR2D3というR2D2の次の手法が発表されているようです。
気になったので実装してみました。
コード全体
本記事で作成したコードは以下です。
目次
- R2D3について
- デモンストレーション環境の実装
- DemoReplayメモリの実装
- EpisodeMemoryについて(独自実装)
- 従来手法との比較
はじめに
R2D3はいわゆるDQN系列の強化学習の手法となります。
それまでの技術解説に関しては以下シリーズで解説していますのでよかったらどうぞ
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(準備編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(Q学習編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(DQN編)
- 【強化学習】Keras-rlでRainbowを実装/解説
- 【強化学習】Keras-rlでApe-Xを実装/解説(並列プログラミング)
- 【強化学習】2018年度最強と噂のR2D2を実装/解説してみた
- 【強化学習】R2D2を実装/解説してみたリベンジ 解説編(Keras-RL)
追記:Agent57も記事をあげました。
R2D3について
2019年9月にGoogle DeepMind社より発表された強化学習の手法で、
ざっくりいうと R2D2 と DQfD を合わせた手法です。
DQfDはざっくりいうとうまい人のプレイ(デモンストレーション)を参考により良い学習(DQNベース)を行い、
最終的にはデモンストレーション以上の優れたパフォーマンスを学習する手法です。
ちなみに略さない名称は Recurrent Replay Distributed DQN from Demonstrations (R2D3) らしいです。
・参考
- 【DQfD】人間のプレイを参考にして学習する強化学習アルゴリズムを実装してみる【前半】
- 【DQfD】デモンストレーションから事前学習するDQNの論文を読む
- 論文で理解するR2D3の概要|論文で理解する深層強化学習の研究トレンド #3
- DQfD論文
- R2D3論文
学習の全体フロー

上記がR2D3の全体図です。(※論文より引用)
図の右側(紫と青い部分)はR2D2と変わらず、違う点は左側の赤色の部分です。
まず、前提として demo replay には参考となるプレイデータがあらかじめ入っています。
R2D2 までは学習する際に使用する batch データは、agent replay データを元に batch サイズ分作成していました。
R2D3 ではこの batch データを demo-ratio に従って demo replay と agent replay から作成しています。
demo-ratio について
論文では固定値で 1/16, 1/32, 1/64 1/128, 1/256 を比較し、
1/256 が1部のタスクで一番精度がいいと記載がありました。
ここからは私の考えですが、実際の人の感覚ではデモプレイは最初は参考にするけど、慣れてくると見なくなります。
ですので、私の実装ではここの demo-ratio はアニーリングできるように実装しました。
(アニーリングは設定を変えれば固定の場合と同様になりますし)
デモンストレーション環境の実装
まずはデモンストレーション用のデータを用意しないといけません。
以下のOpenAIが提供している手動プレイ用のコードを参考に作成しました。
デモプレイのデータ構造
保存するデータ構造は学習用と再生用の2つに分けて以下の形にしました。
・学習用(フレーム毎に保存)
| 名前 | 内容 |
|---|---|
| action | アクション |
| observation | 状況 |
| reward | 報酬 |
| done | 終了かどうか |
・再生用(全体情報)
| 名前 | 内容 |
|---|---|
| episode | エピソード番号 |
| rgb_size | 画像のサイズ |
| states | 各フレーム情報の配列(下記の情報が入る) |
・再生用(フレーム毎に保存)
| 名前 | 内容 |
|---|---|
| step | フレーム番号 |
| reward_total | 現状での合計報酬 |
| info | フレームのinfo情報(gym) |
| rgb | 画像 |
デモプレイデータの memory への追加
(コードは env_play.py 内の add_memory 関数となります)
デモプレイのデータを memory に追加する際は実際のagentと同じ手順を踏んで格納する必要があります。
(参考:DQN(Rainbow)の実装解説)
少し冗長ですが、同じ仕組みを別途作成しメモリに追加していきます。
以下疑似コードでのフローとなります。
(複雑になるのでステートフルLSTMの場合は記載していません)
def add_memory(episode_file, memory, agent):
・episode_file からデモプレイ情報を取得
# 経験データ作成用の変数を作成
recent_actions = 保存するaction数の配列
recent_rewards = 保存する報酬の配列
recent_rewards_multistep = Multistep計算用
recent_observations = 保存する状況の配列
for step in エピソード:
observation = フレーム情報[step]["observation"]
action = フレーム情報[step]["action"]
reward = フレーム情報[step]["reward"]
# 状況を追加
recent_observations.pop(0)
recent_observations.append(observation)
# 経験を作成
exp = (
recent_observations[:agent.input_sequence], # 前の状態
recent_actions[0], # 前の状態のaction
recent_rewards_multistep, # 報酬
recent_observations[-agent.input_sequence:]) # 次の状態
)
# memory に経験をを追加
memory.add(exp)
# actionとrewardの追加
recent_actions.pop(0)
recent_actions.append(action)
recent_rewards.pop(0)
recent_rewards.append(reward)
recent_rewards_multistep = Multi step learningの計算
プレイ環境の実装
(コードは env_play.py 内の EpisodeSave クラスとなります)
実際にプレイするクラスです。
以下の機能を持っています。
- OpenAI gym に対応
- Processor によるカスタマイズにも対応
- 実際にプレイする
- キーボードでプレイ(任意のキーも設定可能)
- サイズ変更
- Pause/Unpause
- fps change
- frameadvance
- プレイしたエピソードを保存(エピソード毎にキャンセル可能)
以下のような画面です。

実行コード例
実行する際のコードは以下みたいな感じになります。
import gym
from src.env_play import EpisodeSave
def run_play():
env = gym.make("MountainCar-v0")
processor = None # あれば任意で指定
es = EpisodeSave(
env,
episode_save_dir="tmp",
processor=processor
)
es.play()
env.close()
run_play()
ゲームのキーバインド
ゲームのキーバインドを Processor で指定できるようにしました。
Processor で get_keys_to_action メソッドがあるとそちらを読み込みます。
import rl
class MyProcessor(rl.core.Processor):
def get_keys_to_action(self):
return {
():0, # 押されていない場合は 0
(ord('d'),):1, # d キーは 1
(ord('a'),):2, # a キーは 2
}
保存したプレイデータの再生
(コードは env_play.py 内の EpisodeReplay クラスとなります)
EpisodeSave で保存したエピソードを再生する仕組みも作っておきました。
主に確認用です。
コード実行例
from src.env_play import EpisodeReplay
def replay():
r = EpisodeReplay(episode_save_dir="tmp")
r.play()
replay()
DemoReplay メモリの実装
Rainbow への実装
いつも通り並列処理がなく分かりやすい Rainbow 版から実装していきます。
1.新しく以下のパラメータを追加します。
| 名前 | 内容 |
|---|---|
| demo_memory | メモリの型(replay memoryと同様) |
| demo_episode_dir | 上記EpisodeSaveで保存したディレクトリパス |
| demo_ratio_initial | demoの初期レート |
| demo_ratio_final | demoの最終状態のレート |
| demo_ratio_steps | 最終状態のレートになるまでのstep数 |
demo_memory は ReplayMemory と同じく、ReplayMemory,PERGreedyMemory,PERProportionalMemory,PERRankBaseMemory から選択できます。
2.初期化の段階で DemoReplay メモリにデモプレイの経験を追加します。
def __init__(self):
(省略)
# add_memory 関数で demo_memory にデモプレイを追加
add_memory(demo_episode_dir, self.demo_memory, self)
# demo_ratio のアニーリング用の変数を設定
self.demo_ratio_initial = demo_ratio_initial
if demo_ratio_final is None:
self.demo_ratio_final = self.demo_ratio_initial
else:
self.demo_ratio_final = demo_ratio_final
self.demo_ratio_step = (self.demo_ratio_initial - self.demo_ratio_final) / demo_ratio_steps
(省略)
3.replay_memory と demo_memory からバッチデータを取得します。
その後、Priority を更新します。
import random
def forward(self, observation):
# 学習時のタイミングです
(省略)
# demo ratio の比率を計算
ratio_demo = self.demo_ratio_initial - self.local_step * self.demo_ratio_step
if ratio_demo < self.demo_ratio_final:
ratio_demo = self.demo_ratio_final
# 比率に従ってbatchの個数を出す
batch_replay = 0
batch_demo = 0
for _ in range(self.batch_size):
r = random.random()
if r < ratio_demo:
batch_demo += 1
continue
batch_replay += 1
# 比率に基づき batch を作成
indexes = []
batchs = []
weights = []
memory_types = [] # 取得したメモリの種類を保存
if batch_replay > 0:
(i, b, w) = self.memory.sample(batch_replay, self.local_step)
indexes.extend(i)
batchs.extend(b)
weights.extend(w)
# 0 は replay_memory
memory_types.extend([0 for _ in range(batch_replay)])
if batch_demo > 0:
(i, b, w) = self.demo_memory.sample(batch_demo, self.local_step)
indexes.extend(i)
batchs.extend(b)
weights.extend(w)
# 1 は demo_memory
memory_types.extend([1 for _ in range(batch_demo)])
(省略)
for i in range(self.batch_size):
(学習)
# priorityを更新
if memory_types[i] == 0:
# replay_memoryを更新
self.memory.update(indexes[i], batchs[i], priority)
elif memory_types[i] == 1:
# demo_memoryを更新
self.demo_memory.update(indexes[i], batchs[i], priority)
else:
assert False
(省略)
R2D3 への実装
Rainbow と全く同じ実装でできます。
Learner 側に実装していくだけです。
EpisodeMemory
ここは私の独自実装です。
デモプレイを見て思いついたのですが、デモプレイが有意義ならこれを学習中に取得すればいいのでは?と思いました。
具体的には Episode の合計報酬が一番高いプレイを別途メモリに保存し、
これを今回と同じ方法でバッチに混ぜればいいという考えです。
イメージとしてはたまたまうまくいったプレイは別途覚えておき、何回も見直す感じですね。
以下実装です。
EpisodeMemory の定義
ReplayMemory を包含する形で EpisodeMemory を作成します。
これは ReplayMemory に Episode 単位で経験を追加する wrapper クラスです。
class EpisodeMemory():
def __init__(self, memory):
self.max_reward = None
self.memory = memory
def add_episode(self, episode, total_reward):
# max_reward が更新された場合に episode を memory に追加する
if self.max_reward is None:
self.max_reward = total_reward
elif self.max_reward <= total_reward: # 一応同列の場合もmemoryに追加
self.max_reward = total_reward
else:
return
# 実際の memory 追加処理
for e in episode_recent:
if len(e) == 5: # priority がある場合の処理
self.memory.add(e, e[4])
else:
self.memory.add(e)
EpisodeMemory の実装
Rainbow への実装
1.追加パラメータは以下です。
デモリプレイと違い、アニーリングはしていません。
| 名前 | 内容 |
|---|---|
| episode_memory | メモリの型(replay memoryと同様) |
| episode_ratio | EpisodeMemory のレート |
2.EpisodeMemoryの初期化です
from src.memory.EpisodeMemory import EpisodeMemory
def __init__(self):
(省略)
# EpisodeMemory クラスで wrap します
self.episode_memory = EpisodeMemory(episode_memory)
self.episode_ratio = episode_ratio
(省略)
3.episode用に経験を保存
# episode の最初に呼ばれます
def reset_states(self):
(省略)
# episode の経験保存用
self.episode_exp = []
self.total_reward = 0
# 終了状態確認用
self.recent_terminal = False
# 各stepでaction実行前に呼ばれます
def forward(self, observation):
(省略)
# 終了していたら episode_memory に追加する
if self.recent_terminal:
self.episode_memory.add_episode(self.episode_exp, self.total_reward)
(省略)
exp = (経験データを作成)
self.memory.add(exp) # replay_memoryの追加
self.episode_exp.append(exp) # episode_memory用に経験を追加
(省略)
# 各stepでaction実行後に呼ばれます
def backward(self, reward, terminal):
(省略)
# 経験の合計を計算
self.total_reward += reward
# 終了状態を保存
self.recent_terminal = terminal
(省略)
4.バッチデータ作成に episode_memory も混ぜます
import random
def forward(self, observation):
# 学習時のタイミングです
(省略)
ratio_demo = (demo ratioの計算)
# episode_memory にメモリがあればバッチに混ぜる
if len(self.episode_memory) < self.batch_size:
ratio_epi = 0
else:
ratio_epi = self.episode_ratio
# 比率に従ってbatchの個数を出す
batch_replay = 0
batch_demo = 0
batch_episode = 0
for _ in range(self.batch_size):
r = random.random()
if r < ratio_demo:
batch_demo += 1
continue
r -= ratio_demo
if r < ratio_epi:
batch_episode += 1
continue
batch_replay += 1
# 比率に基づき batch を作成
indexes = []
batchs = []
weights = []
memory_types = [] # 取得したメモリの種類を保存
if batch_replay > 0:
(replay_memory のバッチ作成)
if batch_demo > 0:
(demo_memory のバッチ作成)
if batch_episode > 0:
(i, b, w) = self.episode_memory.sample(batch_episode, self.local_step)
indexes.extend(i)
batchs.extend(b)
weights.extend(w)
# episode_memory は 2
memory_types.extend([2 for _ in range(batch_episode)])
(省略)
for i in range(self.batch_size):
(学習)
# priorityを更新
if memory_types[i] == 0:
(replay_memoryを更新)
elif memory_types[i] == 1:
(demo_memoryを更新)
elif memory_types[i] == 2:
# episode_memoryを更新
self.episode_memory.update(indexes[i], batchs[i], priority)
else:
assert False
(省略)
R2D3 への実装
Rainbow への実装とほぼ変わりません。
ただ、エピソードデータが各Actor毎に作成されますが、
プロセス間通信の量を減らすために Learner 側で管理しています。
class Learner():
def __init__():
(省略)
# Learner の初期化で Actor 毎のエピソード管理用の変数を作成
self.episode_exp = [ [] for _ in range(self.actors_num)]
self.total_reward = [ 0 for _ in range(self.actors_num)]
def train(self):
(省略)
# Actor → Learner への経験追加
for _ in range(self.exp_q.qsize()):
exp = self.exp_q.get(timeout=1)
# add memory
self.memory.add(exp[0], exp[0][4])
# add episode_exp
self.total_reward[exp[1]] += exp[0][2]
self.episode_exp[exp[1]].append(exp[0])
if exp[2]: # terminal
self.episode_memory.add_episode(
self.episode_exp[exp[1]],
self.total_reward[exp[1]]
)
self.episode_exp[exp[1]] = []
self.total_reward[exp[1]] = 0
(省略)
class Actor():
def forward(self, observation):
(省略)
# Learner に送信
# actor_index と terminal 情報も渡す
self.exp_q.put((exp, self.actor_index, self.recent_terminal))
(省略)
従来手法との比較結果
MountainCar
今回は MountainCar で試します。
MountainCarは左と右で Car を動かし右上のある旗を目指すゲームです。
報酬は常に -1 です。
要するに早く旗までたどり着くと得点が高くなるわけです。
Q学習として考えると、ゴールするまで報酬が取得できない(いいか悪いかが不明)タスクで、そこそこ難しいタスクになります。
従来の結果
Processor は定義せず gym で提供されている純粋な MountainCar での学習です。
ログは 2000 step毎に取得しています。(Rainbow での動作です)
最初の5万ステップを warmup にしておりその後10万回学習させています。
・結果
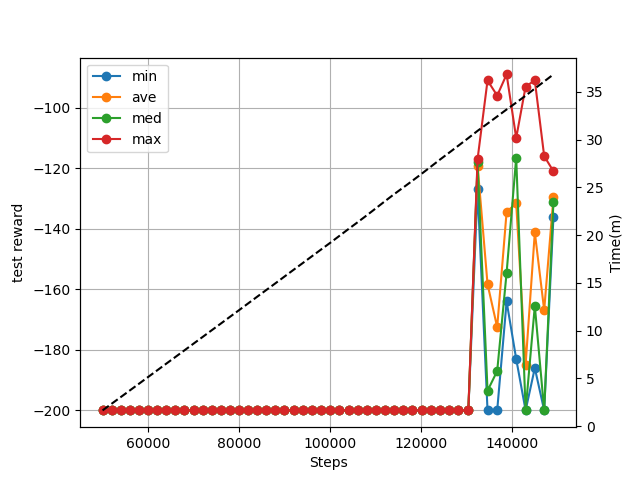
ゴールに到達したプレイがある程度メモリに貯まるまではなかなか学習できていませんね。
だいたい13万stepを超えたあたりから結果が出始めていますね。
DemoReplayメモリ有効時の結果
DemoReplay メモリ以外のパラメータは従来の結果と同じです。
デモは以下のエピソードを1つだけ用意しました。
DemoReplayメモリのパラメータは以下です。
- Proportionalメモリを使用
- ISはオフに
- レートは 1.0 から 1/512 にアニーリング
demo_memory = PERProportionalMemory(100_000, alpha=0.8)
demo_episode_dir = episode_save_dir
demo_ratio_initial = 1.0
demo_ratio_final = 1.0/512.0
demo_ratio_steps = warmup + 50_000
・結果
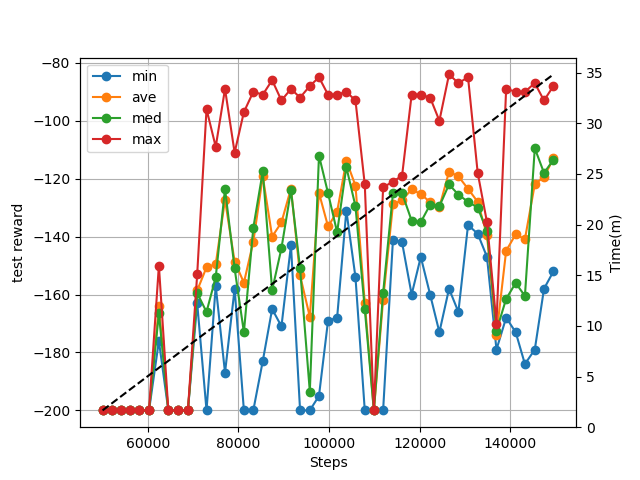
7万ごろにはもう結果が出始めていますね。
EpisodeMemory有効時の結果
EpisodeMemory 以外のパラメータは従来の結果と同じです。
EpisodeMemory のパラメータは以下の通り。
- Proportionalメモリを使用
- ISはオフに
- メモリのサイズは小さめにしています(数エピソードが入る程度)
- レートは EpisodeMemory の影響を強めにするためにわざと高めに設定しています
episode_memory = PERProportionalMemory(2_000, alpha=0.8),
episode_ratio = 1.0/8.0,
・結果
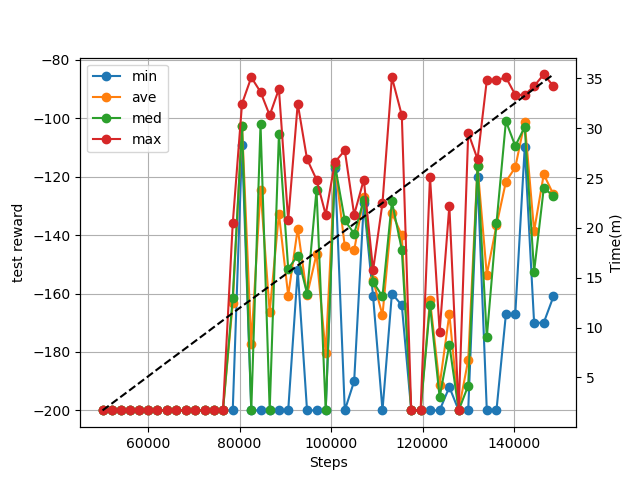
8万あたりから結果が出始めています。
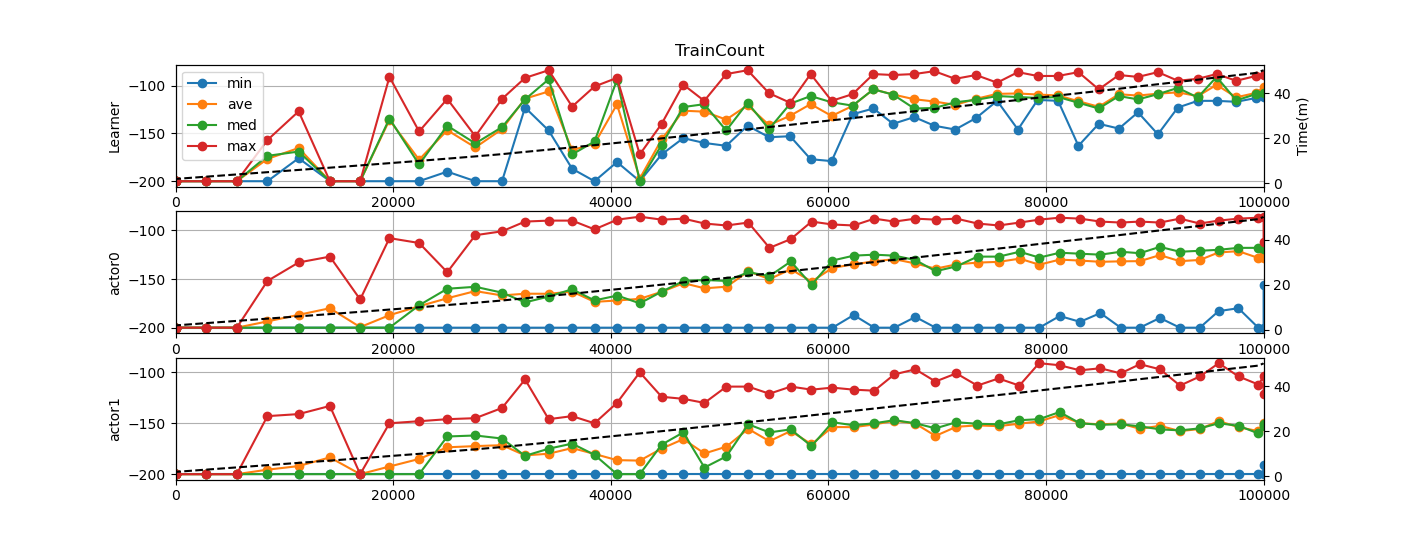
おまけ(DemoReplayメモリとEpisodeMemory両方有効)
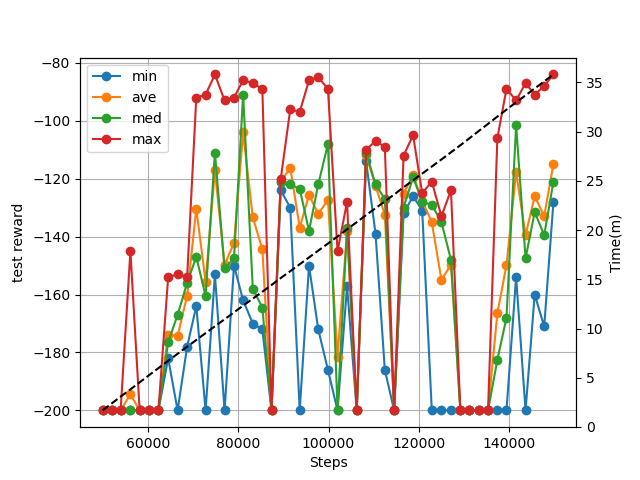
おまけ2(R2D3)
DemoReplayメモリとEpisodeMemoryは両方有効です。
(x軸は warmup の回数は含まれていません)
あとがき
思ったより簡単に実装できました。
学習するにあたってデモプレイがないタスクというのはあまりないのでとても有効な手法だと思います。
強化学習の進化はまだ止まりませんね。
次は何が出てくるか楽しみです。