ハイパーパラメータ解説編です。
各パラメータに関してまとめてみました。
中身のアルゴリズムについてはこちら
【強化学習】R2D2を実装/解説してみたリベンジ 解説編(Keras-RL)
コード全体
本記事の対象コードはgithubにあげています。
目次
- 共通パラメータ解説
- Rainbow/R2D2特有のパラメータ解説
- 学習以外の機能の解説
- NNモデルの中間層の可視化
- 動画化
- save/load
- 学習履歴のログ取得
- ハイパーパラメータ設定例
- DQN(論文)
- Keras-RL Cartpoleのサンプル
- Rainbow(論文)
- R2D2(論文)
共通パラメータ
Rainbow(DQN)とR2D2で共通のパラメータです。
env 依存関係のパラメータ
| 概要 | 型 | 例 | 備考 | |
|---|---|---|---|---|
| input_shape | 入力shape | tuple | (84,84) | env.observation_space.shape |
| input_type | 入力形式を指定 | InputType | InputType.GRAY_2ch | 独自実装 |
| image_model | 画像層のモデル形式 | ImageModel(独自実装) | DQNImageModel() | |
| nb_actions | アクション数(出力数) | int | 4 | env.action_space.n |
| processor | Gymのカスタム機能を提供するクラス | Processor(Keras-rl) | None |
-
input_shape
入力形式を tuple で指定します。
画像なら (width, height) の形式ですね。
Gym の場合は env.observation_space.shape で取得できる形式です。 -
input_type
上記 input_shape を補う指定です。
独自実装しています。
下記の4つの種類を想定しており、input_shape の内容に合わせて指定してください。
class InputType(enum.Enum):
VALUES = 1 # 画像無し
GRAY_2ch = 3 # (width, height)
GRAY_3ch = 4 # (width, height, 1)
COLOR = 5 # (width, height, ch)
-
image_model
前回の記事で解説した内容です。
ただ現状は2種類しかなく、画像じゃない場合は None、画像の場合は DQNImageModel() を指定してください。 -
nb_actions
出力形式を int で指定します。
これは agent が選択できるアクション数に相当します。
例えば左と右と止まると3個操作方法がある場合は3アクションになります。
Gym の場合は env.action_space.n で取得できます。(Discrete形式のみ) -
processor
Gym で提供されている Env に対してカスタマイズ機能を提供するクラスです。(processor(Keras-rl公式))
NN(ニューラルネットワーク)モデル関係のパラメータ
| 概要 | 型 | 例 | 備考 | |
|---|---|---|---|---|
| batch_size | バッチサイズ | int | 32 | |
| optimizer | 最適化アルゴリズム | Optimizer(Keras) | Adam(lr=0.0001) | Keras実装 |
| metrics | 評価関数 | array | [] | Keras実装 |
| input_sequence | 入力フレーム数 | int | 4 | |
| dense_units_num | Dense層のユニット数 | int | 512 | |
| enable_dueling_network | DuelingNetworkを使うかどうか | bool | True | |
| dueling_network_type | DuelingNetworkで使うアルゴリズム | DuelingNetwork | DuelingNetwork.AVERAGE | |
| lstm_type | LSTMを使用する場合の種類 | LstmType(独自実装) | LstmType.NONE | |
| lstm_units_num | LSTM層のユニット数 | int | 512 | |
| lstm_ful_input_length | 1学習あたりの入力学習回数 | int | 4 | STATEFULの場合のみ使用 |
-
batch_size
ミニバッチ学習で使用する batch サイズです。(batchについてはこちら(Keras公式))
batchサイズを増やすと学習効率および学習速度が上がるという話があります。
ただ、強化学習は教師あり学習と違い、学習データに制限がないため batch サイズを増やすと学習コストが増える(1回の学習での収束速度は上がるが時間はかかるため、新しい経験を模索する回数が減る)ため、あまり増やしすぎない方がいい気もします。
また、batchサイズは 2^n を指定するといいとかなんとか。 -
optimizer
NNモデルを compile する際に指定する Keras の Optimizer を指定します。
詳細はオプティマイザ(最適化アルゴリズム)の利用方法(Keras公式)等を参考にしてください。 -
metrics
Keras の評価関数を指定します。使ったときないのであまり分からない…。
詳細は評価関数の利用方法(Keras公式)等を参考にしてください。 -
input_sequence(以前はwindow_length)
入力に使う observation の数です。
1 で直近の1frameのみを入力とし、4だと直近から4frameまでを入力として使います。
この値を増やすと入力の表現力が増えますが、学習コストは増えます。 -
dense_units_num
Dense層のユニット数です。
この値を増やすとNNの表現力が増えますが、学習コストは増えます。 -
enable_dueling_network
DuelingNetworkを有効にするかどうかです。
DuelingNetworkは状態と行動を分けてNNに学習させることで学習効率をあげようというものです。 -
dueling_network_type
DuelingNetwork で状態と行動を分ける時に使うアルゴリズムです。
以下の3種類から指定できます。
論文では Average が一番いい結果が出たと書いてありました。
class DuelingNetwork(enum.Enum):
AVERAGE = 0
MAX = 1
NAIVE = 2
- lstm_type
LSTMを使う場合の種類を指定します。
LSTMを使用すると時系列に関する情報も学習する事が出来ますが学習コストは増えます。
使わない場合は NONE を指定してください。
STATELESS を指定するとDRQN相当のシンプルなLSTM層をNNモデルに追加します。
STATEFUL を指定するとR2D2相当の複雑な処理をするLSTM層をNNモデルに追加します。
STATEFULはSTATELESSに比べて学習効率は上がりますが、学習コストがかなり増えます。
class LstmType(enum.Enum):
NONE = 0
STATELESS = 1
STATEFUL = 2
- lstm_ful_input_length
STATEFULの学習における1学習あたりの入力学習回数です。
STATEFULで学習する場合、時系列に沿う形で学習回数を増やす事が出来ます。
その時系列に沿った学習回数の数をここで指定します。(詳細は前回の記事を参照)
数字を増やすと学習効率は(多分)上がりますが、学習コストが増えます。
Experience Replay Memory関連
| 概要 | 型 | 例 | 備考 | |
|---|---|---|---|---|
| memory/remote_memory | 使用するメモリ | Memory(独自実装) | ReplayMemory(10000) | 下記参照 |
経験を貯めるメモリの種類を指定します。
DQN では経験したデータは一度メモリに格納します。
その後、メモリの中からランダムに経験を取り出して学習を行います。
メモリから取り出す方法によっていくつか種類があるのでそれについて説明します。
ReplayMemory
DQN で使われているシンプルなメモリです。(以前の記事)
経験データをランダムに取り出します。
ReplayMemory(
capacity=10_000
)
- capacity
メモリに保存する最大容量です。
多いほうがいいですが、多すぎるとPC側の物理メモリが圧迫されるのでほどほどに。
PERGreedyMemory
優先順位付き経験再生における愚直な実装です。
ランダムではなくTD誤差が最大の経験(もっとも学習への反映率が高い)経験を取り出す方法です。
ただ、これはランダム要素がないのですぐ局所解に入る気がしてうまく学習できません…。(なぜ実装した)
PERGreedyMemory(
capacity=10_000
)
- capacity
メモリに保存する最大容量です。
PERProportionalMemory
優先順位付き経験再生におけるProportional Prioritization(比例優先順位付け)のメモリです。
ランダムではなくTD誤差の確率分布にしたがって経験を取り出す方法です。
(TD誤差が多い経験ほど取り出される確率が高くなる)
ReplayMemory(ランダム選択)よりはかなり学習効率が良くなる感じです。
PERGreedyMemory(
capacity=100000,
alpha=0.9,
beta_initial,
beta_steps,
enable_is,
)
パラメータは後述します。
PERRankBaseMemory
優先順位付き経験再生におけるRankBase(順位優先付け)のメモリです。
ランダムではなくTD誤差の順位に比例して経験を取り出します。
例えば3つ経験がある場合、1位は50%、2位は33%、3位は17%で選択されるといった感じです。
ReplayMemory(ランダム選択)よりはかなり学習効率が良くなる感じですが、
Proportional との違いはあまり分かりません。
速度的にはこちらの方が少しだけはやくなっているはず…。
PERRankBaseMemory(
capacity=100000,
alpha=0.9,
beta_initial,
beta_steps,
enable_is,
)
パラメータは後述します。
PERProportionalMemoryとPERRankBaseMemoryのパラメータ
| 概要 | 型 | 例 | 備考 | |
|---|---|---|---|---|
| capacity | メモリに保存する最大容量 | int | 1_000_000 | |
| alpha | 確率反映率 | float | 0.9 | 0.0~1.0 |
| beta_initial | IS反映率の初期値 | float | 0.0 | 0.0~1.0 |
| beta_steps | ISの反映率を1.0にするまでのstep数 | int | 100_000 | 学習回数に依存 |
| enable_is | ISを有効にするか | bool | True |
-
capacity
メモリに保存する最大容量です。 -
alpha
Priority/RankBase の反映率です。(0.0~1.0)
0.0で完全ランダム(ReplayMemoryと同様)で、1.0なら確率分布に完全に従います。
ここで重要度サンプリング(IS)の説明をします。
確率分布に従って経験を出す場合、各経験が選ばれる回数に偏りが生じます。
経験の選択回数が偏ると学習にバイアスがかかってしまうので、それを回避するのが重要度サンプリングです。
具体的には、高い確率で選ばれる経験はQ値の更新への反映率を低くし、低い確率で選ばれる経験はQ値の更新への反映率を高くするというものです。
ISを導入することで学習が安定するらしいです。
また、ISはアニーリング(徐々に反映していく)します。
-
beta_initial
ISの反映率の初期値です。(0.0 でISを使用しない状態、1.0でISを反映した状態) -
beta_steps
ISの反映率を1.0にするまでのstep数です。
学習回数を元に指定してください。 -
enable_is
ISを有効にするかどうかです。
学習関係のパラメータ
| 概要 | 型 | 例 | 備考 | |
|---|---|---|---|---|
| memory_warmup_size/ remote_memory_warmup_size | メモリに経験が貯まるまで学習しないサイズ | int | 1000 | |
| target_model_update | Targetモデルへの更新間隔 | int | 10000 | |
| gamma | Q学習の割引率 | float | 0.99 | 0.0~1.0 |
| enable_double_dqn | DoubleDQNを使用するか | bool | True | |
| enable_rescaling | rescaling関数を使用するか | bool | True | |
| rescaling_epsilon | rescaling関数で使う定数 | float | 0.001 | |
| priority_exponent | 経験の優先度を計算する際の比率 | float | 0.9 | LESTFULのみ使用 |
| burnin_length | burn-inの期間 | int | 2 | LESTFULのみ使用 |
| reward_multisteps | MultiStep Reward のstep数 | int | 3 |
-
memory_warmup_size / remote_memory_warmup_size
初期状態ではメモリに経験がなく、学習ができません。
ですのでメモリに経験が貯まるまで学習しない期間を作ります。
その期間をここで指定します。
batch_size 以上の値であまり少なすぎない値がいいと思います。
(あまり減らすと初期で偏った経験データがあった場合に局所解に陥る可能性があります) -
target_model_update
DQNにおけるTargetNetworkの更新間隔です。
DQNではTargetNetworkという更新専用のQネットワークを用いて更新します。
TargetNetworkは学習は行わず、一定間隔で今のQネットワークをコピーします。
こうすることで更新に使用するQネットワークに時差が生まれて更新が良くなるとのことです。 -
gamma
Q学習の割引率です。
報酬をどれだけ伝搬させるかを指定します。
まあ、ほぼ1.0に近い値でいいと思います。 -
enable_double_dqn
DoubleDQNは学習時に最大のQ値を選んで学習していましたが、ノイズ等の影響で過大評価されている可能性があり良くないということで提案された手法です。
DoubleDQNを使うと学習効率が上がる気がします。 -
enable_rescaling
報酬に対してrescaling関数を使用するか指定します。
rescaling関数を使用すると報酬がある程度丸められるので報酬による学習のブレが抑えられます。 -
rescaling_epsilon
rescaling関数で使う定数です。
0になるのを防ぐ定数のようでほぼ0に近い値ならいいかと思います。
(0.001は論文で使われている数字です) -
priority_exponent
R2D2相当のLSTM学習(LSTMFUL)で使っているPriority(経験の優先度)の計算で使用します。
LSTMFUL では複数の Priority を元に最終的な Priority(経験の優先度)を決定します。
その計算方法は $Priorityの最大値 + Priorityの平均値$ です。
この最大値と平均値をどれだけ反映させるかの割合が priority_exponent となります。
0.9 の場合は $Priorityの最大値0.9 + Priorityの平均値0.1$ となります。
論文では0.9ぐらいがいい結果になったと書いてありました。 -
burnin_length
R2D2相当のLSTM学習(LSTMFUL)で使っているBurn-inの回数です。
ざっくりいうと、LSTMFULでは過去の状態(経験データ格納時)と現在の状態に差異があります。
ですので、学習前に今の状態に近づける為に学習しないで経験データを流す期間を設けましょうという手法です。
burnin_length を増やすと学習はより正確になりますが、学習コストが増えます。 -
reward_multisteps
Multi-Step learningにおけるstep数となります。
通常は1step分の報酬を使うが、n-step分の報酬を使用するというもの。
感覚的には少し未来の報酬まで視野にいれて学習する感じですかね(?)
3stepは論文で使用している値です。
アクション関係
| 概要 | 型 | 例 | 備考 | |
|---|---|---|---|---|
| action_interval | アクション実行間隔 | int | 1 | 1以上 |
| action_policy | アクション実行で使用する方策 | Policy(独自実装) | 下記参照 |
-
action_interval
アクションの更新間隔です。
例えば4にすると4フレーム毎にアクションが更新されます。
(更新されない間は同じアクションを実行します) -
action_policy
アクションを実行する方策を指定します。
各方策の詳細については以前の記事を参照してください。
ε-greedy
ε-greedyは乱数(0.0~1.0)に対して $epsilon$ 以下ならランダムに行動、
それより大きければQ値が最大となるアクションを選びます。
EpsilonGreedy(
epsilon
)
ε-greedy(Annealing)
DQNで使用された方法です。
ε-greedy における $epsilon$ を学習が進むにつれて低くする(Q値に従う)にする手法です。
AnnealingEpsilonGreedy(
initial_epsilon=1,
final_epsilon=0.1,
exploration_steps=1_000_000
)
-
initial_epsilon
初期 $epsilon$ です。 -
final_epsilon
最終状態の $epsilon$ です。 -
exploration_steps
初期から最終状態になるまでの step 数を指定します。
ε-greedy(Actor)
Ape-Xで使用された方法です。
ε-greedy における $epsilon$ をActor数を基に計算したものとなります。
EpsilonGreedyActor(
actor_index,
actors_length,
epsilon=0.4,
alpha=7
)
-
actor_index
actorのindexを指定します。 -
actors_length
actorの総数です。 -
epsilon
基準となる $epsilon$ を指定します。 -
alpha
計算で使う定数です。
Softmax
Q値のSoftmax関数の確率分布でアクションを決める方法です。
要するにQ値が高いアクションほど選ばれやすくなり、低いアクションほど選ばれにくくなります。
SoftmaxPolicy()
引数はありません。
UCB(Upper Confidence Bound)1
UCB1は、Q値だけではなくそのアクションが選ばれた回数も加味してアクションを選ぶ手法です。
考え方はあまり選んでいないアクションはあまり探索が進んでおらず未知の報酬があるかもしれないので探索しようというものです。
UCB1()
引数はありません。
また、内部にNNモデルを保持して学習しているので学習コストが増えます。
UCB1-Tuned
UCB1-Tunedは、UCB1に分散も考慮して改良したアルゴリズムです。
UCB1より優れた結果を出しますが理論的な保証はないとの事です。
UCB1_Tuned()
引数はありません。
また、内部にNNモデルを保持して学習しているので学習コストが増えます。
UCB-V
UCB1-Tunedより更に分散を意識したアルゴリズムです。
UCBv()
引数はありません。
また、内部にNNモデルを保持して学習しているので学習コストが増えます。
KL-UCB
探索と報酬のジレンマの理論上の最適値を求めたアルゴリズムです。
ただ、実装がちょっとおかしいかもしれません…。
KL_UCB()
引数はありません。
また、内部にNNモデルを保持して学習しているので学習コストが増えます。
Thompson Sampling(ベータ分布)
Thompson Sampling はベイス推定を元にしたアルゴリズムです。
これも探索と報酬のジレンマの理論上の最適値になっています。
ベータ分布は0か1の2値をとる場合に適用できる分布となります。
実装では報酬が0より大きい場合は1、0以下は0として扱っています。
ThompsonSamplingBeta()
引数はありません。
また、内部にNNモデルを保持して学習しているので学習コストが増えます。
Thompson Sampling(正規分布)
Thompson Sampling はベイス推定を元にしたアルゴリズムです。
これも探索と報酬のジレンマの理論上の最適値になっています。
報酬が正規分布に従うと仮定してアルゴリズムを適用しています。
ThompsonSamplingGaussian()
引数はありません。
また、内部にNNモデルを保持して学習しているので学習コストが増えます。
Rainbow(DQN)のみ関連
| 概要 | 型 | 例 | 備考 | |
|---|---|---|---|---|
| train_interval | 学習の間隔 | int | 1 | 1以上 |
train_interval を増やすことで学習の間隔をあける事が出来ます。
R2D2のみ関連
| 概要 | 型 | 例 | 備考 | |
|---|---|---|---|---|
| actors | Actorクラスを指定 | Actor(独自実装) | 下記参照 | |
| actor_model_sync_interval | LearnerからNNモデルを同期する間隔 | int | 500 |
- actor_model_sync_interval
LearnerからActorに対してNNモデルを同期する間隔です。
数字は Learner の学習回数に対応しています。
Actor
独自実装で、Actor を表現するクラスとなります。
これを継承し、各Actorが実行する Policy と env.fit を定義します。
定義例です。
from src.r2d2 import Actor
from src.policy import EpsilonGreedy
ENV_NAME = "xxx"
class MyActor(Actor):
def getPolicy(self, actor_index, actor_num):
return EpsilonGreedy(0.1)
def fit(self, index, agent):
env = gym.make(ENV_NAME)
agent.fit(env, visualize=False, verbose=0)
env.close()
getPolicy でそのActorが使用するアクションポリシーを指定します。
fit 内で引数にある agetn に fit を実行させ学習させます。
R2D2に渡すときに気を付ける点ですが、クラス自体を渡して下さい(インスタンス化しないでください)
from src.r2d2 import R2D2
kwargs = {
"actors": [MyActor] # クラス自体を渡す
(省略)
}
manager = R2D2(**kwargs)
Actorを増やす場合は配列の要素数を増やせば増えます。
from src.r2d2 import R2D2
kwargs = {
"actors": [MyActor, MyActor, MyActor, MyActor]
(省略)
}
manager = R2D2(**kwargs)
その他
MovieLogger(Rainbow/R2D2)
動画を出力するCallbackです。
Rainbow及びR2D2両方で使えます。
from src.callbacks import MovieLogger
# test の callcacks引数に追加してください。
movie = MovieLogger()
agent.test(env, nb_episodes=1, visualize=False, callbacks=[movie])
# 保存します。
movie.save(
start_frame=0,
end_frame=0,
gifname="pendulum.gif",
mp4name="",
interval=200,
fps=30
):
-
start_frame
開始フレームを指定します。 -
end_frame
終了フレームを指定します。
0なら終わりまですべてのフレームが対象になります。 -
gifname
gif形式で出力する場合のpathです。
matplotlibのアニメーションで保存します。
"" なら出力しません。 -
mp4name
mp4形式で出力する場合のpathです。
matplotlibのアニメーションで保存します。
"" なら出力しません。 -
interval
matplotlibのFuncAnimationに渡すintervalです。 -
fps
matplotlibで動画を保存する際のfpsです。
・出力例

NNの中間層可視化(Rainbow/R2D2)
以前の記事で紹介したConv層およびAdvance層、Value層可視化のCallbackです。
Rainbow及びR2D2両方で使えます。
from src.callbacks import ConvLayerView
# 初期化で agent を指定します。
conv = ConvLayerView(agent)
# test を実施します。
# callbacks 引数に ConvLayerViewオブジェクトを指定
agent.test(env, nb_episodes=1, visualize=False, callbacks=[conv])
# 結果を保存します。
conv.save(
grad_cam_layers=["conv_1", "conv_2", "conv_3"],
add_adv_layer=True,
add_val_layer=True,
start_frame=0,
end_frame=200,
gifname="tmp/pendulum.gif",
interval=200,
fps=10,
)
-
grad_cam_layers
対象のConv層を指定します。
名前はImageModel内で指定した名前となります。 -
add_adv_layer
Advance層を追加するか -
add_val_layer
Value層を追加するか -
start_frame
開始フレームを指定します。 -
end_frame
終了フレームを指定します。
0なら終わりまですべてのフレームが対象になります。 -
gifname
gif形式で出力する場合のpathです。
matplotlibのアニメーションで保存します。
"" なら出力しません。 -
mp4name
mp4形式で出力する場合のpathです。
matplotlibのアニメーションで保存します。
"" なら出力しません。 -
interval
matplotlibのFuncAnimationに渡すintervalです。 -
fps
matplotlibで動画を保存する際のfpsです。
また、ConvLayerView は入力が画像(InputTypeが GRAY_2ch, GRAY_3ch, COLOR)のいずれかの場合のみ動作します。
・出力例

Logger2Stage(Rainbow)
以下2つの機能を提供します。
- 2段階に分けてログ取得間隔を設定
- ログ取得に当たってtest環境(学習環境ではなくQ値の最大値で動作)を使用
from src.rainbow import Rainbow
from src.callbacks import Logger2Stage
# テスト用の agent と env を別途作成します
kwargs = (省略)
test_agent = Rainbow(**kwargs)
test_env = gym.make(ENV_NAME)
# 各種設定
log = Logger2Stage(
logger_type=LoggerType.STEP,
warmup=1000,
interval1=200,
interval2=20_000,
change_count=5,
savefile="tmp/log.json",
test_agent=test_agent,
test_env=test_env,
test_episodes=10
)
# 学習時の callbacks に追加します
# Logger2Stageがログを出力するので verbose=0 としています
agent.fit(env, nb_steps=1_750_000, visualize=False, verbose=0, callbacks=[log])
# getLogs関数でログを取得できます(savefileを指定する必要があります)
history = log.getLogs()
# 簡易ですが、グラフの出力もできます(savefileを指定する必要があります)
log.drawGraph()
-
logger_type
ログの記録形式です。
LoggerType.TIME:時間で取得します。
LoggerType.STEP:step数で取得します。 -
warmup
最初の warmup 時間はログ取得をしません。
LoggerType.TIME なら秒、LoggerType.STEPならstep数になります。 -
interval1
最初のログ取得間隔です。
LoggerType.TIME なら秒、LoggerType.STEPならstep数になります。 -
interval2
2段階目のログ取得間隔です。
LoggerType.TIME なら秒、LoggerType.STEPならstep数になります。 -
change_count
1段階目から2段階目に移行する回数です。
1段階目がこの回数ログを取得したら2段階目に移ります。 -
savefile
ログを保存するファイルです。 -
test_agent
学習環境とは別にテストしたい場合は指定してください。
None だと学習環境の結果のみ出力します。 -
test_env
学習環境とは別にテストしたい場合は指定してください。
None だと学習環境の結果のみ出力します。 -
test_episodes
テスト環境でのepisode数です。
・出力例
--- start ---
'Ctrl + C' is stop.
Steps 0, Time: 0.00m, TestReward: 21.12 - 92.80 (ave: 51.73, med: 46.99), Reward: 0.00 - 0.00 (ave: 0.00, med: 0.00)
Steps 200, Time: 0.05m, TestReward: 22.06 - 99.94 (ave: 43.85, med: 31.24), Reward: 108.30 - 108.30 (ave: 108.30, med: 108.30)
Steps 1200, Time: 0.28m, TestReward: 40.99 - 73.88 (ave: 52.41, med: 47.69), Reward: 49.05 - 141.53 (ave: 87.85, med: 90.89)
(省略)
Steps 17200, Time: 3.95m, TestReward: 167.68 - 199.49 (ave: 184.34, med: 188.30), Reward: 166.29 - 199.66 (ave: 181.79, med: 177.36)
Steps 18200, Time: 4.19m, TestReward: 165.84 - 199.53 (ave: 186.16, med: 188.50), Reward: 188.00 - 199.50 (ave: 190.64, med: 188.41)
Steps 19200, Time: 4.43m, TestReward: 163.63 - 188.93 (ave: 186.15, med: 188.59), Reward: 165.56 - 188.45 (ave: 183.75, med: 188.23)
done, took 4.626 minutes
Steps 0, Time: 4.63m, TestReward: 188.37 - 199.66 (ave: 190.83, med: 188.68), Reward: 188.34 - 188.83 (ave: 188.63, med: 188.67)
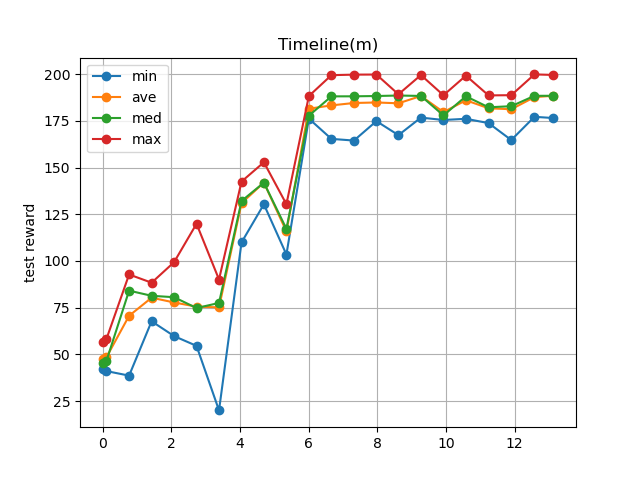
SaveManager(R2D2)
R2D2 はmultiprocessingを使用しており実装の方法がかなり特殊です。
特にモデルのsave/loadにはかなり影響が出たので別途用意しました。
from src.r2d2 import R2D2
from src.r2d2_callbacks import SaveManager
# R2D2 の作成
kwargs = (省略)
manager = R2D2(**kwargs)
# SaveManagerの作成
save_manager = SaveManager(
save_dirpath="tmp",
is_load=False,
save_overwrite=True,
save_memory=True,
checkpoint=True,
checkpoint_interval=2000,
verbose=0
)
# 学習開始、callbacks引数に追加する。
manager.train(
nb_trains=20_000,
callbacks=[save_manager],
)
# test用のAgentを作成する場合は以下を呼ぶ
# save_dirpath/last/learner.dat を指定してください。
agent = manager.createTestAgent(MyActor, "tmp/last/learner.dat")
# testを実施。
agent.test(env, nb_episodes=5, visualize=True)
-
save_dirpath
結果を保存するディレクトリです。
ディレクトリ配下にチェックポイント用のディレクトリをさらに作るのでディレクトリ形式にしています。 -
is_load
以前の学習結果をloadするかどうか -
save_overwrite
保存結果を上書きするかどうか -
save_memory
ReplyMemoryの中身も保存するか。
保存すると前回と全く同じ状況から学習を再開可能ですけどメモリのファイルサイズが大きいです(数GB程度)。
また、.mem ファイルで別保存されているので後から削除可能です。 -
checkpoint
途中経過を保存するかどうか -
checkpoint_interval
途中経過を保存する場合のintervalです。
単位はLearnerの学習回数となります。 -
verbose
0の場合はprint出力しません。
1の場合はprint出力があります。
Logger2Stage(R2D2)
以下2つの機能を提供します。
- 2段階に分けてログ取得間隔を設定
- ログ取得に当たってtest環境(学習環境ではなくQ値の最大値で動作)を使用
また、rainbowと違って、時間での取得間隔しかありません。
from src.r2d2 import R2D2
from src.r2d2_callbacks import Logger2Stage
# R2D2 の作成
kwargs = (省略)
manager = R2D2(**kwargs)
# テスト用のenvを作成
test_env = gym.make(ENV_NAME)
# Logger2Stageを作成
log = Logger2Stage(
warmup=0,
interval1=10,
interval2=60,
change_count=20,
savedir="tmp",
test_actor=MyActor,
test_env=test_env,
test_episodes=10,
verbose=1,
)
# 学習開始、callbacks引数に追加する。
manager.train(
nb_trains=20_000,
callbacks=[log],
)
# getLogsでログを取得できます。(savedirを指定している場合)
history = log.getLogs()
# 簡易にグラフ表示もできます。(savedirを指定している場合)
log.drawGraph()
-
warmup
最初に取得を始めるまでの時間です。(秒) -
interval1
最初のログ取得間隔です。(秒) -
interval2
2段階目のログ取得間隔です。(秒) -
change_count
1段階目から2段階目に移行する回数です。
1段階目がこの回数ログを取得したら2段階目に移ります。 -
savedir
ログを保存するディレクトリです。
LearnerとActorでプロセスが分かれており、各プロセスが値を保存するために競合を避けるためファイルを分けています。 -
test_actor
テスト時に使用するActorクラスを指定します。
None だとテストは実施しません。 -
test_env
学習環境とは別にテストしたい場合は指定してください。
None だとテストは実施しません。 -
test_episodes
テスト環境でのepisode数です。
・出力例
--- start ---
'Ctrl + C' is stop.
Learner Start!
Actor0 Start!
Actor1 Start!
actor1 Train 1, Time: 0.24m, Reward : 27.80 - 27.80 (ave: 27.80, med: 27.80), nb_steps: 200
learner Train 1, Time: 0.19m, TestReward: 29.79 - 76.71 (ave: 58.99, med: 57.61)
actor0 Train 575, Time: 0.35m, Reward : 24.88 - 133.09 (ave: 62.14, med: 50.83), nb_steps: 3400
learner Train 651, Time: 0.36m, TestReward: 24.98 - 51.67 (ave: 38.86, med: 38.11)
actor1 Train 651, Time: 0.41m, Reward : 22.15 - 88.59 (ave: 41.14, med: 35.62), nb_steps: 3200
actor0 Train 1249, Time: 0.51m, Reward : 22.97 - 61.41 (ave: 35.24, med: 31.99), nb_steps: 8000
(省略)
learner Train 16476, Time: 4.53m, TestReward: 165.56 - 199.57 (ave: 180.52, med: 177.73)
actor1 Train 16880, Time: 4.67m, Reward : 128.88 - 188.45 (ave: 169.13, med: 165.94), nb_steps: 117600
Learning End. Train Count:20001
learner Train 20001, Time: 5.29m, TestReward: 175.72 - 188.17 (ave: 183.21, med: 187.48)
Actor0 End!
Actor1 End!
actor0 Train 20001, Time: 5.34m, Reward : 151.92 - 199.61 (ave: 181.68, med: 187.48), nb_steps: 0
actor1 Train 20001, Time: 5.34m, Reward : 130.39 - 199.26 (ave: 170.83, med: 167.99), nb_steps: 0
done, took 5.350 minutes
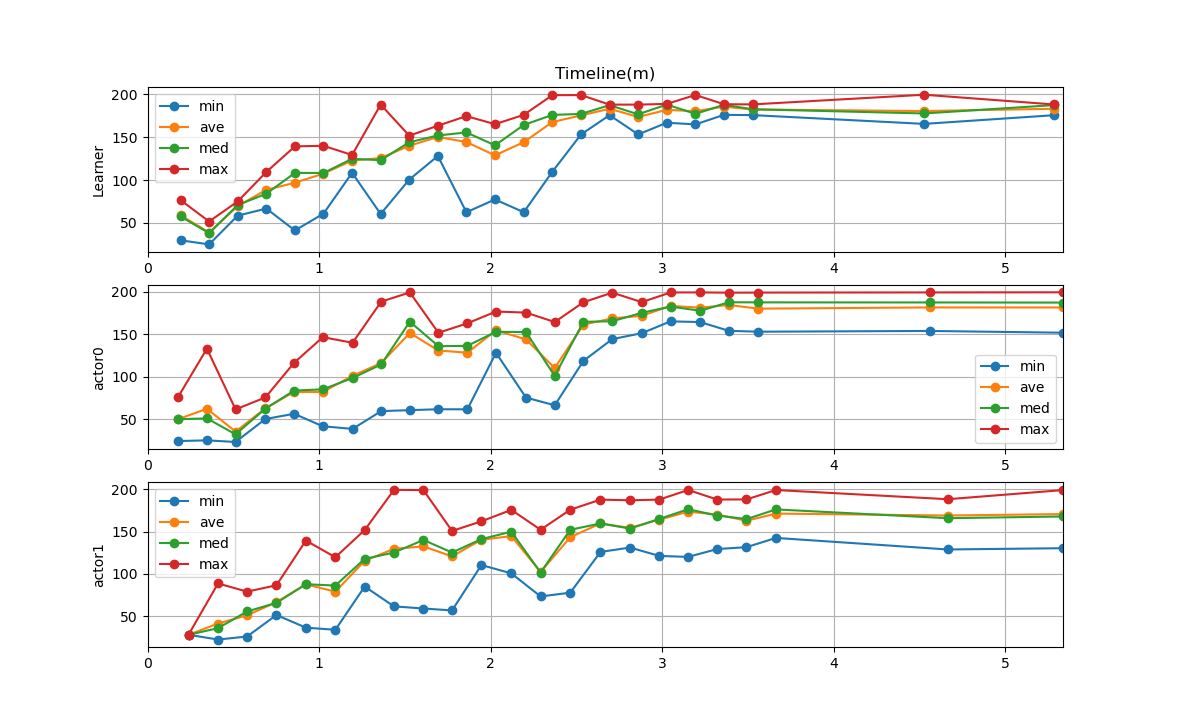
設定値サンプル
DQNの論文(Atari)
from src.rainbow import Rainbow
from src.processor import AtariProcessor
from src.image_model import DQNImageModel
from src.memory import ReplayMemory
from src.policy import AnnealingEpsilonGreedy
nb_steps = 1_750_000
# AtariProcessor がやること
# ・画像のリサイズ (84,84)
# ・報酬のclipping
processor = AtariProcessor(reshape_size=(84, 84), is_clip=True)
kwargs={
"input_shape": processor.image_shape,
"input_type": InputType.GRAY_2ch,
"nb_actions": env.action_space.n,
"optimizer": Adam(lr=0.0001),
"metrics": [],
"image_model": DQNImageModel(),
"input_sequence": 4, # 入力フレーム数
"dense_units_num": 256, # dense層のユニット数
"enable_dueling_network": False,
"lstm_type": LstmType.NONE, # 使用するLSTMアルゴリズム
# train/action関係
"memory_warmup_size": 50_000, # 初期のメモリー確保用step数(学習しない)
"target_model_update": 10_000, # target networkのupdate間隔
"action_interval": 4, # アクションを実行する間隔
"train_interval": 4, # 学習する間隔
"batch_size": 32, # batch_size
"gamma": 0.99, # Q学習の割引率
"enable_double_dqn": False,
"enable_rescaling": False, # rescalingを有効にするか
"reward_multisteps": 1, # multistep reward
# その他
"processor": processor,
"action_policy": AnnealingEpsilonGreedy(
initial_epsilon=1.0, # 初期ε
final_epsilon=0.05, # 最終状態でのε
exploration_steps=1_000_000 # 初期→最終状態になるまでのステップ数
),
"memory": ReplayMemory(capacity=1_000_000),
}
agent = Rainbow(**kwargs)
Keras-RLのサンプル(Cartpole)
from src.rainbow import Rainbow
from src.memory import ReplayMemory
from src.policy import SoftmaxPolicy
env = gym.make('CartPole-v0')
kwargs={
"input_shape": env.observation_space.shape,
"input_type": InputType.VALUES,
"nb_actions": env.action_space.n,
"optimizer": Adam(lr=0.0001),
"metrics": [],
"image_model": None,
"input_sequence": 1, # 入力フレーム数
"dense_units_num": 16, # dense層のユニット数
"enable_dueling_network": False,
"lstm_type": LstmType.NONE,
# train/action関係
"memory_warmup_size": 10, # 初期のメモリー確保用step数(学習しない)
"target_model_update": 1, # target networkのupdate間隔
"action_interval": 1, # アクションを実行する間隔
"train_interval": 1, # 学習する間隔
"batch_size": 32, # batch_size
"gamma": 0.99, # Q学習の割引率
"enable_double_dqn": False,
"enable_rescaling": False,
# その他
"processor": processor,
"action_policy": SoftmaxPolicy(),
"memory": ReplayMemory(capacity=50000)
}
agent = Rainbow(**kwargs)
Rainbowの論文(Atari)
from src.rainbow import Rainbow
from src.processor import AtariProcessor
from src.image_model import DQNImageModel
from src.memory import PERProportionalMemory
from src.policy import AnnealingEpsilonGreedy
nb_steps = 1_750_000
# AtariProcessor がやること
# ・画像のリサイズ (84,84)
# ・報酬のclipping
processor = AtariProcessor(reshape_size=(84, 84), is_clip=True)
kwargs={
"input_shape": processor.image_shape,
"input_type": InputType.GRAY_2ch,
"nb_actions": env.action_space.n,
"optimizer": Adam(lr=0.0000625, epsilon=0.00015),
"metrics": [],
"image_model": DQNImageModel(),
"input_sequence": 4, # 入力フレーム数
"dense_units_num": 512, # dense層のユニット数
"enable_dueling_network": True,
"dueling_network_type": DuelingNetwork.AVERAGE, # dueling networkで使うアルゴリズム
"lstm_type": LstmType.NONE,
# train/action関係
"memory_warmup_size": 80000, # 初期のメモリー確保用step数(学習しない)
"target_model_update": 32000, # target networkのupdate間隔
"action_interval": 4, # アクションを実行する間隔
"train_interval": 4, # 学習する間隔
"batch_size": 32, # batch_size
"gamma": 0.99, # Q学習の割引率
"enable_double_dqn": True,
"enable_rescaling": False,
"reward_multisteps": 3, # multistep reward
# その他
"processor": processor,
"action_policy": AnnealingEpsilonGreedy(
initial_epsilon=1.0, # 初期ε
final_epsilon=0.05, # 最終状態でのε
exploration_steps=1_000_000 # 初期→最終状態になるまでのステップ数
),
"memory": PERProportionalMemory(
capacity=1_000_000,
alpha=0.5, # PERの確率反映率
beta_initial=0.4, # IS反映率の初期値
beta_steps=1_000_000, # IS反映率の上昇step数
enable_is=True, # ISを有効にするかどうか
)
}
agent = Rainbow(**kwargs)
R2D2の論文(Atari)
from src.r2d2 import R2D2, Actor
from src.processor import AtariProcessor
from src.image_model import DQNImageModel
from src.memory import PERProportionalMemory
from src.policy import EpsilonGreedyActor
ENV_NAME = "xxxxx"
class MyActor(Actor):
def getPolicy(self, actor_index, actor_num):
return EpsilonGreedyActor(actor_index, actor_num, epsilon=0.4, alpha=7)
def fit(self, index, agent):
env = gym.make(ENV_NAME)
agent.fit(env, visualize=False, verbose=0)
env.close()
# AtariProcessor がやること
# ・画像のリサイズ (84,84)
# ・報酬のclipping
processor = AtariProcessor(reshape_size=(84, 84), is_clip=True)
kwargs={
"input_shape": processor.image_shape,
"input_type": InputType.GRAY_2ch,
"nb_actions": env.action_space.n,
"optimizer": Adam(lr=0.0001, epsilon=0.001),
"metrics": [],
"image_model": DQNImageModel(),
"input_sequence": 4, # 入力フレーム数
"dense_units_num": 512, # Dense層のユニット数
"enable_dueling_network": True, # dueling_network有効フラグ
"dueling_network_type": DuelingNetwork.AVERAGE, # dueling_networkのアルゴリズム
"lstm_type": LstmType.STATEFUL, # LSTMのアルゴリズム
"lstm_units_num": 512, # LSTM層のユニット数
"lstm_ful_input_length": 40, # ステートフルLSTMの入力数
# train/action関係
"remote_memory_warmup_size": 50_000, # 初期のメモリー確保用step数(学習しない)
"target_model_update": 10_000, # target networkのupdate間隔
"action_interval": 4, # アクションを実行する間隔
"batch_size": 64,
"gamma": 0.997, # Q学習の割引率
"enable_double_dqn": True, # DDQN有効フラグ
"enable_rescaling": enable_rescaling, # rescalingを有効にするか(priotrity)
"rescaling_epsilon": 0.001, # rescalingの定数
"priority_exponent": 0.9, # priority優先度
"burnin_length": 40, # burn-in期間
"reward_multisteps": 3, # multistep reward
# その他
"processor": processor,
"actors": [MyActor for _ in range(256)],
"remote_memory": PERProportionalMemory(
capacity= 1_000_000,
alpha=0.6, # PERの確率反映率
beta_initial=0.4, # IS反映率の初期値
beta_steps=1_000_000, # IS反映率の上昇step数
enable_is=True, # ISを有効にするかどうか
),
# actor 関係
"actor_model_sync_interval": 400, # learner から model を同期する間隔
}
manager = R2D2(**kwargs)
あとがき
パラメータの量が多すぎて…
何かR2D3なるものが発表されているらしく、そのうち実装します。