前回の続きです。
強化学習といえばQ学習ですね。
強化学習の実装例としてkerasの実装例はたくさんあるのですが、keras-rlの実装例はなかったので、まずはQ学習から実装してみたいと思います。
本シリーズ
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(準備編)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(Q学習編)(ここ)
- 【強化学習】OpenAI Gym×Keras-rlで強化学習アルゴリズムを実装していくぞ(DQN編)
- 【強化学習】Keras-rlでRainbowを実装/解説
- 【強化学習】Keras-rlでApe-Xを実装/解説(並列プログラミング)
- MNISTでSaliencyMapとGrad_CAMを試してDQN(DuelingNetwork)を可視化してみた(実装/解説)
- 【強化学習】2018年度最強と噂のR2D2を実装/解説してみた
- 【強化学習】複数の探索ポリシーを実装/解説して比較してみた
- 【強化学習】DQNのハイパーパラメータを3つのゲームで比較してみた
- 【強化学習】R2D2を実装/解説してみたリベンジ 解説編(Keras-RL)
- 【強化学習】R2D3を実装/解説してみた(Keras-RL)
- 【強化学習】ついに人間を超えた!?Agent57を解説/実装してみた(Keras-RL)
追記:改めて記事にしています。
概要
- ゲームの前処理としてProcessorを実装しgymの入出力を調整
- Q学習用のkeras-rlとしてAgentを実装
- keras-rlのハイパーパラメータをoptunaで最適化
コード全体
本記事で作成したコードは以下です。(GoogleColaboratoryは実行結果付き)
※1ファイル完結です。
※GoogleColaboratoryは実行結果付き
QLAgent(keras-rlのAgent)の実装
Q学習について
強化学習の歴史の中で古くからある手法の1つがTD学習という手法です。
TD学習では状態しか見ていなかった所をアクションまで見るようにしたのがQ学習(Q-Learning)という手法です。(多分…)
TD学習ではTD誤差というものを計算してある状態の評価値を更新していく学習となります。
TD誤差は以下の式となります。
$$r_{t}+\gamma V(s_{t+1}) - V(s_{t})$$
実際の更新式は以下です。
$$V(s_{t}) \leftarrow V(s_{t}) + \alpha(r_{t}+\gamma V(s_{t+1}) - V(s_{t}) )$$
$\gamma$が割引率(評価値の伝搬率)、$\alpha$が学習率(評価値の更新率)となります。
イメージとしては以下のように報酬を伝搬していく感じですね。
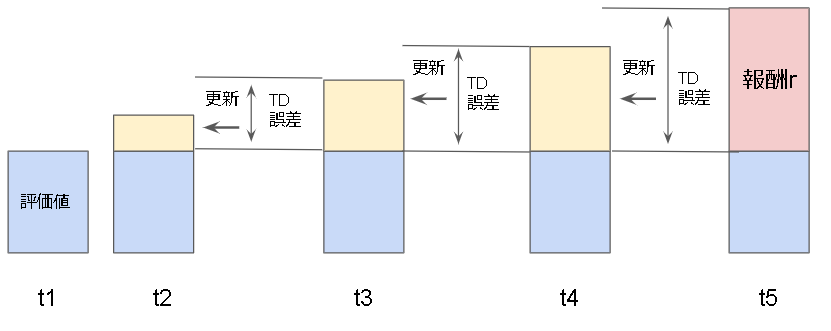
TD学習では状態だけを見ていましたが、これをアクションまで拡張したものがQ学習となります。
$$Q(s_{t},a_{t}) \leftarrow Q(s_{t},a_{t}) + \alpha(r_{t}+\gamma \max_pQ(s_{t+1,p}) - Q(s_{t},a_{t}) )$$
ゲームの前処理
今回試すゲームは棒立て(Pendulum)です。
env = gym.make("Pendulum-v0")
ただ、このゲームは直接Q学習で学習することはできないので、Q学習で学習できるように環境とアクションの離散化を行います。
Processorの実装
Q学習では、入力と出力(環境とアクション)は線形モデル(連続した数値)を扱えません。
ですが、今回のゲームは線形モデルのため1,2,3といった離散した数値に変換する必要があります。
離散化/線形化のためにProcessorクラスを継承して中身を実装していきます。
import rl.core
class PendulumProcessor(rl.core.Processor):
# アクションの再定義
# 引数は、agentから出力されたactionの値(ここでは離散値)
# 戻り値は、envに渡すactionの値
def process_action(self, action):
アクションの線形化
return action
# 環境の再定義
# 引数は、envから出力されたobservation
# 戻り値が agent へ渡すobservation
def process_observation(self, observation):
環境の離散化
return observation
アクションの線形化
Pendulumではアクションはジョイントの力として -2.0 ~ +2.0 の範囲を受け付けます。
Pendulum-v0のwiki
今回はこれを5パターンに分けます。
def process_action(self, action):
ACT_ID_TO_VALUE = {
0: [-2.0],
1: [-1.0],
2: [0.0],
3: [+1.0],
4: [+2.0],
}
return ACT_ID_TO_VALUE[action]
>>> p = PendulumProcessor()
>>> p.process_action(4)
[2.0]
環境の離散化
アクション同様に環境も離散化します。
Pendulumの環境は以下の値をとります。
| Num | Observation | Min | Max |
|---|---|---|---|
| 0 | cos(theta) | -1.0 | 1.0 |
| 1 | sin(theta) | -1.0 | 1.0 |
| 2 | theta dot | -8.0 | 8.0 |
実装では分割数が指定出来るようにしています。
def __init__(self, split_num=8):
# 各値の最小,最大値
self.env_low = np.array([-1.0, -1.0, -8.0])
self.env_high = np.array([1.0, 1.0, 8.0])
# 分割の基準となる値
self.env_dx = (self.env_high - self.env_low) / split_num
def process_observation(self, observation):
d = []
for i, v in enumerate(observation):
if v < self.env_low[i]:
v = self.env_low[i]
elif v > self.env_high[i]:
v = self.env_high[i]
d.append(int(round((v - self.env_low[i]) / self.env_dx[i])))
return d
>>> p = PendulumProcessor(split_num=8)
>>> p.process_observation((0.5, -0.1, 4.2))
[6, 4, 6]
Agentの実装
QL用のagentを実装していきます。
あまりkeras-rlのAgentを実装する資料が見つからなかったので基本は公式のソースコードを見つつ実装しています。
まずはAgentの継承からです。
import rl.core
class QLAgent(rl.core.Agent):
def __init__(self, **kwargs):
super(QLAgent, self).__init__(**kwargs)
self.compiled = False
def reset_states(self):
pass
def compile(self, optimizer=None, metrics=[]):
self.compiled = True
def load_weights(self, filepath):
pass
def save_weights(self, filepath, overwrite=False):
pass
def forward(self, observation):
action = 0
return action
def backward(self, reward, terminal):
return []
@property
def layers(self):
return []
上記が主な実装関数となり、順番に実装していきたいと思います。
self.compiled はないと怒られました。
また、reset_states関数だけは必須ではなく任意となります。
Qテーブルの実装
まずはQ値を保存するQテーブルを実装していきます。
アルゴリズムとしては状態を文字列として、ハッシュテーブルで表現しています。
速度は分からないですが、環境の形式に対してかなり幅広く対応できる点と分かりやすい点より採用しています。
以下のようなイメージです。
(1, 2, 7) # 状態(環境)
↓
"1_2_7" # 文字列にする
↓
q_actions = q_table["1_2_7"] # Qテーブルのindexになる。
↓
q_actions[0] -> 0.75
q_actions[1] -> 0.3
q_actions[2] -> 0.1
※q_actionsは、アクションがindexになり、それぞれQ値が入る。
※今回だと"1_2_7"状態の0アクションのQ値は0.75
まずはQテーブルの初期化を、コンストラクタで実装します。
また、初期化にあたりアクション数が必要なので引数に nb_actions を追加しています。
def __init__(self, nb_actions, **kwargs):
self.nb_actions = nb_actions
self.q_table = {}
self.q_table[""] = [np.random.uniform(low=-1, high=1) for _ in range(self.nb_actions)]
何もない状態""も最初に作成しています。
Q値の初期値は-1~1の間のランダムな値です。
forward関数の実装
次はforward関数を実装していきます。
学習のメインとなる場所ですね。
forwardは環境の1step(env.step)が実行される前に呼ばれる関数で、引数には状態(環境)が入ってきます。
戻り値は実行するアクションの値を返す必要があります。
forwardの実装は以下のようなフローで実装します。
def forward(self, observation):
1. Qテーブルを文字列化。
2. Qテーブルにない状態(環境)なら新規追加
if self.training:
3. Q値を更新する。
if self.training:
4. ϵ-greedy法でアクションを決める
else:
5. テスト環境なのでQ値が最大のアクションを返す。
return action
self.training変数はkeras-rl側で定義されており、トレーニング中ならTrueが入っています。
1. Qテーブルを文字列化。
strで型変換して実現しています。
# 文字列化して一意にする。
observation = "_".join([str(o) for o in observation])
2. Qテーブルにない状態(環境)なら新規追加
# Qテーブルになければ追加(無限に増えます)
if observation not in self.q_table:
# Q値の初期化
self.q_table[observation] = [ np.random.uniform(low=-1, high=1) for _ in range(self.nb_actions) ]
文字列化したobservationに対してQテーブルになければ追加しています。
何もない状態と同様にQ値は-1~1の間のランダムな値にしています。
3. Q値を更新する。
Q値に必要な値は1つ前のobservationとaction、その結果のreward(報酬)と現在のobservationです。
まずは1つ前の状態とアクションをforward関数の最後で保存します。
def forward(self, observation):
(略)
self.prev_observation = observation
self.prev_action = action
return action
rewardはbackward関数から取得します。
こちらは環境の1step(env.step)が実行された後に呼ばれる関数で、引数にはreward(報酬)が入っています。
戻り値はmetricsを返すらしいのですが…、よく分かっていません(調査を後回しにしています)
def backward(self, reward, terminal):
self.prev_reward = reward
return []
現在の状態(環境)はforwardの引数にあるのでこれで準備が整いました。
Q値の更新式を再掲しておきます。
$$Q(s_{t},a_{t}) \leftarrow Q(s_{t},a_{t}) + \alpha(r_{t}+\gamma \max_pQ(s_{t+1,p}) - Q(s_{t},a_{t}) )$$
q_val = self.q_table[self.prev_observation][self.prev_action] # Q(St,At)
next_maxq = self.q_table[observation][np.argmax(self.q_table[observation])] # MAX(Q(St+1,At))
# 更新
self.q_table[self.prev_observation][self.prev_action] = q_val + self.traning_rate * (self.prev_reward + self.gammma * next_maxq - q_val)
traning_rateとgammaはハイパーパラメータになるのでユーザが指定できるようにコンストラクタに追加しておきます。
def __init__(self, nb_actions, traning_rate=0.5, gamma=0.99, **kwargs):
self.traning_rate = traning_rate
self.gamma = gamma
最後に忘れずに初期値を設定しておきます。
初期値はreset_states関数を利用します。
def reset_states(self):
self.prev_observation = ""
self.prev_action = 0
self.prev_reward = 0
4. ϵ-greedy法でアクションを決める
ϵ-greedy法はシンプルで、確率ϵでランダムなアクションを実行し、そうじゃなければQ値に従ってアクションを決めます。
if self.epsilon > np.random.uniform(0, 1):
# ランダム
action = np.random.randint(0, self.nb_actions)
else:
# Q値が最大のアクションを取得
action = np.argmax(self.q_table[observation])
epsilonの値はハイパーパラメータとなるのでユーザが指定できるようにコンストラクタに追加しています。
デフォルトは適当に0.1(10%)としています。
def __init__(self, nb_actions, traning_rate=0.5, gamma=0.99, epsilon=0.1, **kwargs):
self.epsilon = epsilon
5. テスト環境時にQ値が最大のアクションを返す。
Qテーブルを参照し、Q値が最大のアクションを取得します。
action = np.argmax(self.q_table[observation])
save/loadの実装
Qテーブルを保存するだけです。
今回は手軽さを重視してpython標準ライブラリのpickleを使いました。
import pickle
import os
(略)
def load_weights(self, filepath):
with open(filepath, 'rb') as f:
self.q_table = pickle.load(f)
def save_weights(self, filepath, overwrite=False):
if overwrite or not os.path.isfile(filepath):
with open(filepath, 'wb') as f:
pickle.dump(self.q_table, f)
agentの使い方
実際に使ってみます。
import gym
# 別ファイルにあると仮定しています。コード全体では1つのファイルにまとめています。
from PendulumProcessor import PendulumProcessor
from QLAgent import QLAgent
env = gym.make("Pendulum-v0")
nb_actions = 5 # PendulumProcessorで5個と定義しているので5
processor = PendulumProcessor(split_num=8)
# processorはAgentのコンストラクタの引数で渡します。
agent = QLAgent(nb_actions=nb_actions, traning_rate=0.5, gamma=0.99, epsilon=0.1, processor=processor)
agent.compile()
#--- 以下、前回の記事と同様です ---
# 訓練
print("--- start ---")
print("'Ctrl + C' is stop.")
history = agent.fit(env, nb_steps=1_000_000, visualize=False, verbose=1)
# 結果を表示
plt.subplot(2,1,1)
plt.plot(history.history["nb_episode_steps"])
plt.ylabel("step")
plt.subplot(2,1,2)
plt.plot(history.history["episode_reward"])
plt.xlabel("episode")
plt.ylabel("reward")
plt.show()
# 訓練結果を見る
agent.test(env, nb_episodes=5, visualize=True)
結果
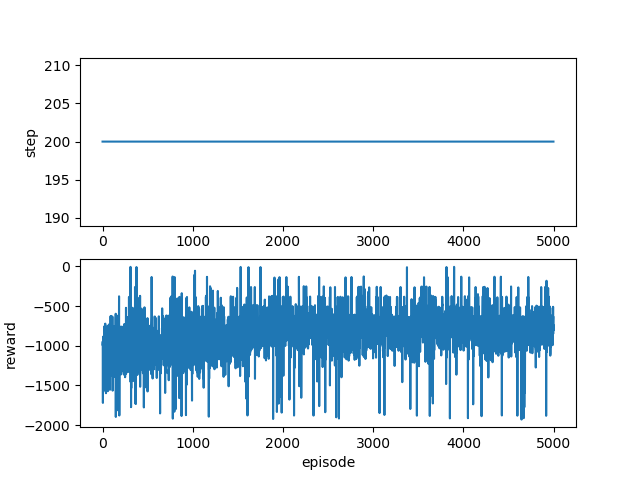

一応学習はできているようです。
Optunaによるハイパーパラメータの調整
ここからはちょっとしたおまけです。
今回ハイパーパラメータがいくつか出てきました。
今後も増えることが予想されるのでハイパーパラメータを自動で最適化してくれるOptunaを試してみたいと思います。
参考:Optuna+KerasでCNNのハイパーパラメータを最適化
インストール
pip install optuna
※GoogleColaboratory
!pip install optuna
最適化関数の準備
まずは最適化するための関数を定義します。
def objective(trial):
env = gym.make("Pendulum-v0")
nb_actions = 5 # PendulumProcessorで5個と定義しているので5
processor = PendulumProcessor(split_num=trial.suggest_int('split_num', 10, 20))
agent = QLAgent(nb_actions=nb_actions,
traning_rate=trial.suggest_uniform('traning_rate', 0.0, 1.0),
gamma=trial.suggest_uniform('gamma', 0.0, 1.0),
epsilon=0.001,
processor=processor)
agent.compile()
agent.fit(env, nb_steps=100_000, visualize=False, verbose=0)
history = agent.test(env, nb_episodes=50, visualize=False, verbose=0)
ave_reward = sum([ n for n in history.history["episode_reward"]]) / 50
return -ave_reward
最適化ポイントは、以下の3箇所です。
epsilonは乱数の要素が大きく最適化と相性が悪そうなので低めにして固定しています。
trial.suggest_int('split_num', 10, 20)
trial.suggest_uniform('traning_rate', 0.0, 1.0)
trial.suggest_uniform('gamma', 0.0, 1.0)
fitは情報が表示されないように visualize=False , verbose=0 にし、時間がかかるのでnb_stepsは少し小さい値にしています。
agent.fit(env, nb_steps=100_000, visualize=False, verbose=0)
testも同様に visualize=False , verbose=0 にし、評価用に戻り値を保存しています。
history = agent.test(env, nb_episodes=50, visualize=False, verbose=0)
最後にtestの結果からエピソードの平均報酬をだしてそれを返します。
マイナスをつけているのはOptunaが値が最小になるように最適化されるためとなります。
ave_reward = sum([ n for n in history.history["episode_reward"]]) / 50
return -ave_reward
最適化の実行
import optuna
study = optuna.create_study()
study.optimize(objective, n_trials=100)
print(study.best_params)
Optimizeで最適化が実行されます。
n_trialsは試行回数となります。
結果は study.best_params で確認できるようです。
枝刈り(Pruning)の実施
Optunaは探索しても意味がなさそうなパラメータを判断して途中で切り上げる機能があるそうです。
とりあえず作成してみましたが効果はよく分かっていません。(ちょっと早くなってる?)
参考
・Optuna+Kerasで転移学習のオプティマイザーと学習率を探してみた
・optunaでPruningする時に早すぎる枝刈りをされないようにする方法
まずは枝刈り用のcallback関数を定義します。
keras-rlのAgentなら使いまわせる実装です。
import rl.callbacks
class OptunaCallback(rl.callbacks.Callback):
def __init__(self, trial):
self.trial = trial
def on_episode_end(self, episode, logs):
episode_reward = -logs["episode_reward"]
self.trial.report(episode_reward, step=episode)
# 打ち切り判定
if self.trial.should_prune(episode):
raise optuna.structs.TrialPruned()
fitの引数に定義したcallbackを渡します。
agent.fit(env, nb_steps=100_000, visualize=False, verbose=0, callbacks=[OptunaCallback(trial)])
最後にウォームアップ期間を設定します。
不要かもしれませんが。。。
study = optuna.create_study(pruner=optuna.pruners.MedianPruner(n_warmup_steps=1000))
結果
{'split_num': 10, 'traning_rate': 0.4761866993824728, 'gamma': 0.8901017844845089}
パラメータを変更して再度学習させてみました。
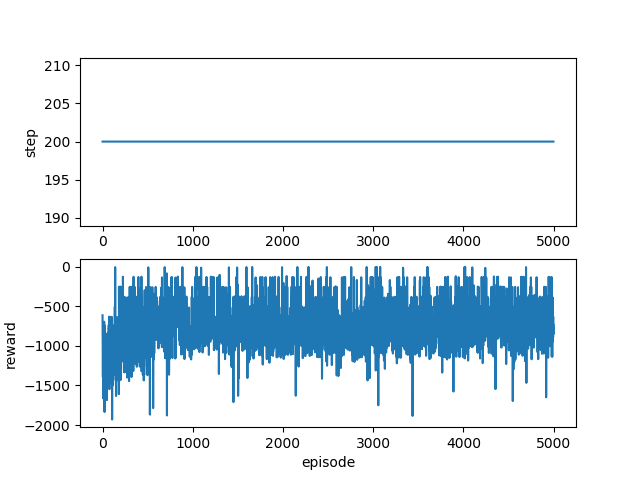
・・・悪くなってますねorz
まとめ
keras-rlでQ学習の実装ができました。
またoptunaによってハイパーパラメータの最適化もできるようになりました。
次はDQNを実装したいと思います。
参考
・TD学習の考え方
・強化学習
・TD 学習による ゲームの進行度ごとの 評価関数の調整
・これから強化学習を勉強する人のための「強化学習アルゴリズム・マップ」と、実装例まとめ
・CartPoleでQ学習(Q-learning)を実装・解説
・【3目並べで学ぶ強化学習】Q-LearningとDQNを徹底解説 (1/2)