この記事は BrainPad AdventCalendar 2017 23日目の記事です。
今回は深層強化学習を取り上げてみようと思います。
ビジネス課題と強化学習
BrainPadでは、データ分析に基づいて様々なビジネス課題に取り組んでいますが、時間的な制約や網羅性の制約などから、機械学習に必要となる最終的に得たい結果(目的変数)と打ち手となる要因(説明変数)の組みを事前にすべて揃えることが出来ない課題において検討されるのが強化学習のアプローチです。そこでは、実際に打ち手を局所的に試行しデータを集めながら、得たい結果との関係性(予測モデル/判断モデル)を動的に学習していきます。そのような意味で、教師あり学習と教師なし学習の中間に位置する手続きと解釈される枠組みで、より現実世界の時間の流れに沿った動的な課題に適用が検討されます。
具体的には、立上げた新規Webページでの広告の出し分けロジックの構築、機械学習モデルのハイパーパラメタの調整、仮想環境(ゲームや物理シミュレーション)や現実環境(ロボット制御)下での攻略手続きの学習などが挙げられます。
今回はそのような課題の基本例として、物理シミュレーションの一つとしてOpenAI Gymから提供されている”Pendulum”という簡単な課題を取り上げ、強化学習、特に深層強化学習の手続を紹介できればと思います。
深層強化学習の発展
強化学習の数理的枠組みや手続きやについては、様々なQiita記事([ゼロからDeepまで学ぶ強化学習]など)や、以下の弊社ブログに挙げられていますので今回は割愛したいと思います。
基本的には、エージェントと呼ばれる学習者が、現在の状態に応じて実際に打ち手を環境に与えて、その結果としての次の状態を環境から得ます(下図)。現在の状態($s_t$)や選択した打ち手($a_t$)を、強化学習の様々な数理的な枠組みを用いて都度評価し、得たい結果を実現するための効率的な打ち手は何かを学習していきます。

数ある強化学習の枠組みの中で基本的なものはQ学習と呼ばれている手続きで、**行動価値関数(Q関数)と呼ばれる、「現在の状態$s_t$の中で打ち手$a_t$を選択した際の価値を定量化した関数$Q(s_t, a_t)$」**をデータを徐々に集めながら学習していくものです。Q関数が学習されていくと、各状態でその打ち手を取る価値(その打ち手をとるべきか)が定量的に与えられるので、学習されたQ関数モデルに基づく状況判断によって、得たい結果が効率的に得られるようになります。
Q関数は、対象とする課題が複雑であればあるほど状態$s_t$や$a_t$の組合せが膨大になり、この関数をモデル化、学習・評価するのが難しくなります。このような状況や打ち手を評価する関数のモデル化に対して、近年著しい発展を遂げている深層学習を当てはめたものが深層強化学習です。
強化学習と深層学習の組み合わせによって、より複雑な課題に対しても、状況を判断する関数の効率的な学習・評価を通してアプローチできるようになってきています。DeepMindによるAlphaGo([Mastering the game of Go with deep neural networks and tree search]、[Mastering the game of Go without human knowledge])が大きなインパクトを与えたのはご存知の通りです。
最近では、このような発展著しい深層強化学習のアルゴリズムを様々なシミューレーション内で試行出来る環境がオープンソースで整えられてきています。以下では具体的な課題への取り組みを通して、それらの具体的な紹介をさせていただこうと思います。
試行環境(OpenAI Gym、Keras-RL)
シミュレーション環境と強化学習 -- OpenAI Gym
アルゴリズムの適用先のシミュレーションとしてはOpenAI Gymの枠組みが提供されています。OpenAI Gymのインストールと実行についてはBrainPad AdventCalendar 2017 4日目に既に詳しく取り上げられていますので、詳細は割愛させていただきます。
今回の取組課題としては、Gymに初めから用意されている、「Pendulum」という振り子の物理シミュレーションを取り上げてみます。Pendulumでは、”状態($s_t$)"としては振り子の(x座標, y座標, 振り子の角速度)の3次元、"打ち手($a_t$)"としては振り子を捻るトルクの大きさを表す1次元の連続値になっています。
実際に適当に動かしてみるとこんな感じ。

軸回りの矢印が与えているトルク(向きと大きさ)を表しています。
この環境下で実現したい結果として、振り子を高い位置に振り上げ、(バランスを取りながら)高い位置を保つことを考えてみましょう。強化学習を用いた状況判断(各状態で打ち手をどう取るべきか)の学習を通して、この状況の実現を目指します。
強化学習の枠組みの中でどのようにシミュレーションが用いられるかは、下を参照いただくのがよいかと思います。
import gym
# シミュレーション環境のオブジェクト生成と設定
env = gym.make("Pendulum-v0")
# 試行(episode)のループ
for episode in range(n_episode):
# シミュレーション環境の初期化
env.reset()
state, reward, done, _ = env.step(env.action_space.sample())
# 試行内の打ち手のステップ
for t in range(n_step):
# **現在の状態(s_t)などから、評価関数(Q関数など)を通して、取るべき打ち手(a_t)を決定**
action = get_action(state)
# シミュレーション環境に打ち手を与え、次の状態(s_t+1)を得る
next_state, reward, done, _ = env.step(action)
# **現在の状態、打ち手、得られた次の状態などから、評価関数を学習・更新**
evaluation(state, action, reward, next_state)
# 試行の終了判断
if judge_done():
break
この大きな流れのうち、
- get_action: 現在の状態(s_t)などから、状態や打ち手の評価関数(Q関数など)を通して、取るべき打ち手(a_t)を決定
-
evaluation: 現在の状態、打ち手、得られた次の状態などから、現在の評価関数を評価、学習・更新
の手続きを如何に構築していくかが「強化学習のアルゴリズム」になります。
強化学習アルゴリズムと統合強化学習環境 -- Keras-RL
強化学習の各アルゴリズムの紹介や発展については、
- [強化学習(Richard S.Sutton)]
-
[これから強化学習を勉強する人のための「強化学習アルゴリズム・マップ」と、実装例まとめ]
などが大変よく纏まっており、これらを参考にしていただくのが良いかと思います。
様々なアルゴリズムが発展している只中ではありますが、Gymなどのシミュレーション環境を内包しながら、上記の強化学習の基本的な手続きの枠組みを整理し、アルゴリズムやモデルの試行錯誤をより簡単に行える以下のような統合環境が整備され始めています。
- Keras-RL
-
OpenAI Lab
これらの枠組みを用いることで、上記のような強化学習の基本手続きの実装を省略でき、学習アルゴリズムやモデルの試行錯誤に注力することが出来ます。
今回は、Keras-RLを用いてみることにします。Keras-RLでは、深層強化学習の典型的アルゴリズムである、DQN、Dual−DQN、DDPGなどが枠組みに沿って既に実装されており、それらを活用することができます。(Keras-RLの枠組みや実装の詳細については上記Gitを実際に参照いただくのが良いかと思います。好みはあるかと思いますが、個人的には分かりやすく纏められていると感じます。)
Keras-RLでは、上記の強化学習の基礎概念・手続きから明らかな通り、基本的なクラスとして、
- Envクラス:OpenAI Gymと同様の基本関数(reset, stepなど)を持つ、適用課題の環境をシミュレートする”学習環境”クラス
-
Agentクラス:アルゴリズムの適用(forward)や更新(backward)、それらを伴った試行の繰り返し(fit)の関数を持つ、強化学習のアルゴリズムを与える”学習者”クラス
があり、またこれらの2つを結びつけるクラスとして -
Processorクラス:適用する環境に応じて、アルゴリズムから環境への入出力を調整する”課題適応用”クラス
が用意されています。(また、必要な情報を格納・出力するためのCallback関数なども準備されています。)
課題やアルゴリズムに合わせて、これらのクラスを継承・改訂しながら、学習を実行することになります。
以上、前置きが長くなりましたが、以下ではKeras-RL環境を用いて、上記「Pendulum」の課題に対しての実際の実装と結果をご紹介します。
Keras-RLを用いた実装
今回は、"学習者"のアルゴリズムとしては、DQNの最近の発展版である、Duel-DQNを用いてみます。Duel-DQNアルゴリズムはKeras-RLにAgentクラスとして準備されており、アルゴリズムの基本手続きはそちらをそのまま活用することにします。(Duel-DQNの詳細については[【強化学習中級者向け】実装例から学ぶDueling Network DQN 【CartPoleで棒立て:1ファイルで完結】]や元論文[Dueling Network Architectures for Deep Reinforcement Learning]などを参照ください。)
さて、まずは課題環境(Envクラス)の準備です。
import gym
# GymのPendulum環境を作成
env = gym.make("Pendulum-v0")
# 取りうる”打ち手”のアクション数と値の定義
nb_actions = 2
ACT_ID_TO_VALUE = {0: [-1], 1: [+1]}
OpenAI GymのEnvクラスオブジェクトは、Keras-RLのEnvクラスのオブジェクトとしてそのまま用いる事ができます。また、今回は簡単のため、環境に対して取りうる”打ち手”としては、”右に回す”、”左に回す”の2状態のみ考えることにします。
次に課題環境とアルゴリズムを仲介・調整するProcessorクラスの準備です。
from rl.core import Processor
class PendulumProcessor(Processor):
# Duel-DQNの出力と、Gym環境の入力の違いを吸収
def process_action(self, action):
return ACT_ID_TO_VALUE[action]
# Gym環境の報酬の出力と、Duel-DQNの報酬の入力との違いを吸収
def process_reward(self, reward):
if reward > -0.2:
return 1
elif reward > -1.0:
return 0
else:
return 0
processor = PendulumProcessor()
ここでは、アルゴリズムと環境の入出力の違いを吸収すると共に、今回の課題の目的である”振り子を高い位置に保つこと”に合わせて、振り子が高い位置に小さい角速度で位置した場合のみ報酬を与え、それ以外は報酬を与えないよう、課題に沿った報酬を設定しています。
最後にアルゴリズムに沿った学習ネットワークの準備です。
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation("relu"))
model.add(Dense(16))
model.add(Activation("relu"))
model.add(Dense(nb_actions, activation="linear"))
今回のDuel-DQNアルゴリズムでは、行動価値関数($Q(s_t, a_t)$)をDNNを用いて近似、学習します。上記では、Pendulumの3次元”状態($s_t$)”を入力に、定義した2つの打ち手($a_t[0], a_t[1]$)毎のQ値を与えるネットワークになっています。今回は簡便的に、2層16ノードのFCネットワークとしています。
これらの準備を経て、上記ネットワークに基づいた状況判断アルゴリズムを持つ学習Agentクラスの作成と、課題環境に対してのそのネットワークの学習を実行します。
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import BoltzmannQPolicy
from rl.memory import SequentialMemory
# Duel-DQNアルゴリズム関連の幾つかの設定
memory = SequentialMemory(limit=50000, window_length=1)
policy = BoltzmannQPolicy()
# Duel-DQNのAgentクラスオブジェクトの準備 (上記processorやmodelを元に)
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10,
enable_dueling_network=True, dueling_type="avg", target_model_update=1e-2, policy=policy,
processor=processor)
dqn.compile(Adam(lr=1e-3), metrics=["mae"])
print(dqn.model.summary())
# 定義課題環境に対して、アルゴリズムの学習を実行 (必要に応じて適切なCallbackも定義、設定可能)
# 上記Processorクラスの適切な設定によって、Agent-環境間の入出力を通して設計課題に対しての学習が進行
dqn.fit(env, nb_steps=100000, visualize=False, verbose=2)
# 学習後のモデルの重みの出力
dqn.save_weights("duel_dqn_{}_weights.h5f".format("Pendulum-v0"), overwrite=True)
# 学習済モデルに対して、テストを実行 (必要に応じて適切なCallbackも定義、設定可能)
dqn.test(env, nb_episodes=100, visualize=True)
Duel-DQNのAgentクラスの詳細についてはKeras-RLの実装や元論文などを参照いただくとして、基本的な学習手続きは、Kerasの深層学習モデルの学習と同様に準備、実行されることが分かります。
実行結果
実行によって試行錯誤と学習ネットワークの更新が繰り返され、(学習が正しく進めば)より尤もらしい判断を与える行動価値関数が学習されて行きます。したがって、学習の進行によって、どのような初期状態に対しても”振り子を高い位置に保つこと”を実現させ高い報酬が安定して得られることが期待されます。
適当なCallbackの設定を通して、横軸に学習における試行回数、縦軸に得られた報酬を記録、プロットしたものが以下です。
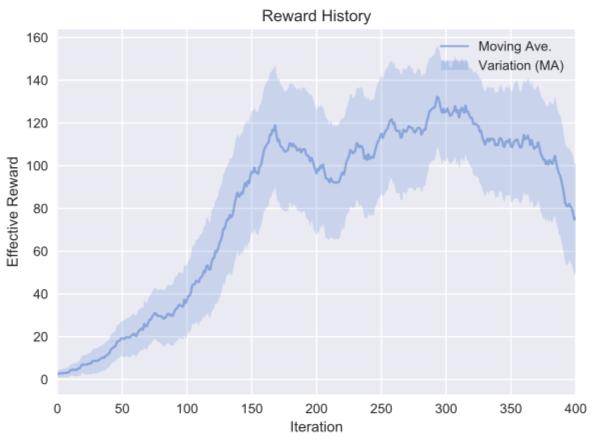
初期では低かった報酬が、試行錯誤を通して高い報酬を安定して実現できるようになっていることが分かります。(400試行を超えた辺りから局所解に陥り(過学習を)始めていることも伺えます。)今回はDuel-DQNというアルゴリズムを用いましたが、この報酬の向上をより効率的にしたり、より高い報酬を安定して実現するための工夫が、様々なアルゴリズムの開発によって現在も精力的に模索されています。
学習後の評価関数モデルを用いた、1試行内の状態推移の例は以下のようになりました。
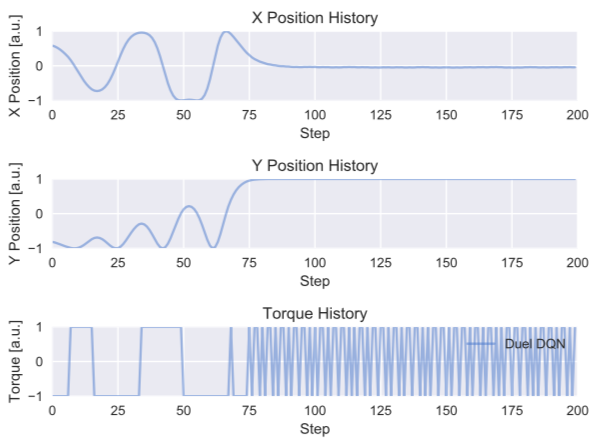
$X$が正から負に動く際に正(右回り)のトルクが、負から正に動く際に負(左回り)のトルクが適切に加わることで、到達する$Y$座標が徐々に向上し、登頂部付近で、勢いを打ち消す逆トルクが一度加わったのち、登頂位置を保つように左右のトルクが交互に細かく加わっていることが分かります。
可視化してみるとしてみるとこんな感じです。

試行錯誤を通じた評価関数の学習によって、このように直感的にも正しく感じられる、状況に応じた適切な打ち手の(評価と)選択が実現されたことが分かっていただけたかと思います。
画像を用いた入力への変更
最後に、上記実装のちょっとした変更例を示したいと思います。
上記例では、学習ネットワークの入力”状態($s_t$)”としては、(x座標, y座標, 振り子の角速度)の3次元を取りました。深層学習の発展とともに、画像を直接入力として、画像の特徴量をネットワーク内で一気通貫で学習出来るようになってきていることはご存知の通りです。実際、AlphaGoでは盤面の状態を画像として入力し、深層強化学習の学習を進めています。今回の課題例でも、入力"状態($s_t$)"として、上記の3次元の情報でなく、各状態の画像を直接用いた場合でも、同様に学習が出来るかを試みてみましょう。
画像の取得は様々な方法が可能(Gymのrenderingなど)ですが、今回はPillowのImageDraw Moduleを用いて、都度直接描画してしまいましょう。必要な実装としてはほとんど上記と変更はありません。変更する部分としては、上記の”Processor”と”学習ネットワーク”の部分だけで、それぞれ主に以下を追加、変更することで実現できます。
”Proessor”については、主に以下のように関数を加えます。
from PIL import Image, ImageDraw
img_size = 128
channel = 3
class PendulumProcessor(Processor):
def __init__(self):
self.rgb_state = np.zeros((img_size, img_size, channel))
# 状態(x,y座標)から対応画像を描画する関数
def _get_rgb_state(self, state):
h_size = img_size/2.0
img = Image.new("RGB", (img_size, img_size), (255, 255, 255))
dr = ImageDraw.Draw(img)
# 棒の長さ
l = img_size/4.0 * 3.0/ 2.0
# 棒のラインの描写
dr.line(((h_size - l * state[1], h_size - l * state[0]), (h_size, h_size)), (0, 0, 0), 1)
# 棒の中心の円を描写(それっぽくしてみた)
buff = img_size/32.0
dr.ellipse(((h_size - buff, h_size - buff), (h_size + buff, h_size + buff)),
outline=(0, 0, 0), fill=(255, 0, 0))
# 画像の一次元化(GrayScale化)とarrayへの変換
pilImg = img.convert("L")
img_arr = np.asarray(pilImg)
# 画像の規格化
img_arr = img_arr/255.0
return img_arr
# Gym環境の出力と、Duel-DQNアルゴリズムへの入力との違いを吸収
def process_step(self, observation, reward, done, info):
old_rgb_state = self.rgb_state.copy()
# アルゴリズムの状態入力として、画像を用いる(過去3フレームを入力する)
# 直近の状態に対応する画像を作成
self.rgb_state[:, :, 0] = self.self._get_rgb_state(observation)
# 過去2フレームも保持
for i in range(1, channel):
self.rgb_state[:, :, i] = old_rgb_state[:, :, i-1] # shift old state
# アルゴリズムへの報酬として、設定課題に沿った報酬を用いる(上記通り)
reward = self.process_reward(reward)
return self.rgb_state, reward, done, info
...
ここでは、状態更新のたびに、その状態に対応する画像を(x、y)座標から生成し、画像を入力情報としてアルゴルズムに与えるように変更を加えています。また、角速度に相当する情報の必要を考慮して、直近3フレームを3チャンネルとしてアルゴリズムに入力するようにしてみています。
一方Duel-DQNアルゴリズムの学習ネットワークは、入力の変更に伴って、以下の用に変更してみます。
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
# 画像の特徴量抽出ネットワークのパラメタ
n_filters = 32
kernel = (3, 3)
strides = (2, 2)
model = Sequential()
# 畳込み層による画像の特徴量抽出ネットワーク
model.add(Reshape((img_size, img_size, channel), input_shape=(1, img_size, img_size, channel)))
model.add(Conv2D(n_filters, kernel, strides=strides, padding="same", activation="relu"))
model.add(Conv2D(n_filters, kernel, strides=strides, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(n_filters, kernel, strides=strides, padding="same", activation="relu"))
model.add(Conv2D(n_filters, kernel, strides=strides, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
# 以前と同様の2層FCのQ関数ネットワーク
model.add(Dense(16, activation="relu"))
model.add(Dense(16, activation="relu"))
model.add(Dense(nb_actions, activation="linear"))
ネットワークの入力”状態”として3チャネルを持つ画像を取り、畳込み層を前段に加えることで、学習に沿った適切な特徴量を画像から自動抽出することを期待します。アルゴリズムとしては、以前と同様、このネットワークを用いて強化学習の行動価値関数の近似を行います。
このネットワークを用いて学習を進めた報酬変化の推移は以下のようになりました。
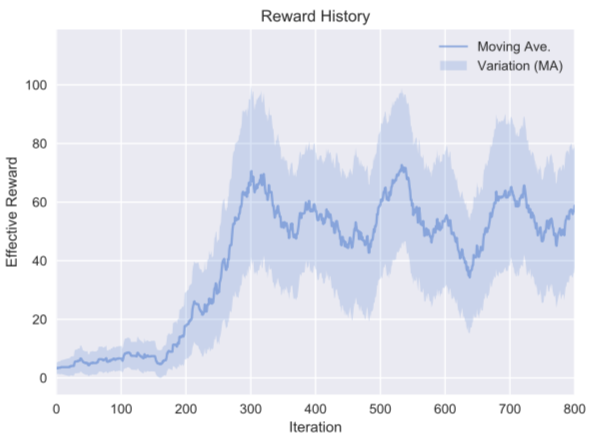
確かに、画像を状態として用いた今回の場合でも試行錯誤を通して、高い報酬を安定して実現し、”振り子を高い位置に保つこと”を実現させていることが分かります。また以前の直接入力の場合と比較し、報酬の収束過程全体に比して、報酬の上昇が(200試行辺りで)急激な変化をしていることも画像を用いた深層強化学習の特徴となっています。
先と同様、学習後のモデルを用いた1試行内の状態推移の例は以下の様になりました。
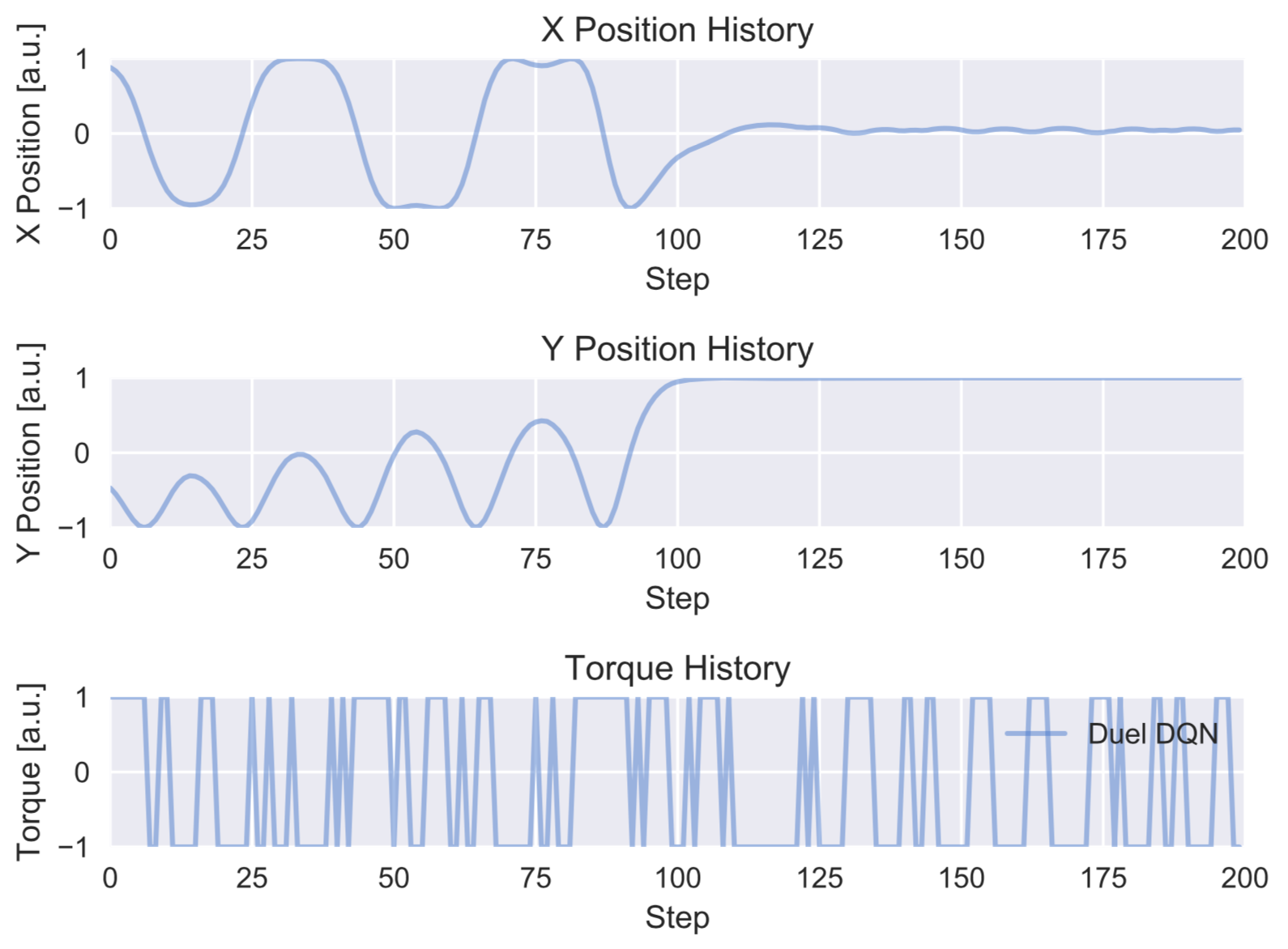
以前見られた、$X$が正から負(負から正)に動く際に正(負)のトルクが加わる傾向が見られていますが、以前ほど明確でないことが分かります。それにともなって、$Y$座標の向上が緩慢になっています。また登頂位置保持の交互トルクの切り替えもより低頻度になっています。以前の直接入力に比してのこの学習の不十分さは、学習の報酬推移における収束値の違い(以前:100付近、今回:60付近)からも明確です。
以上のように、画像を入力に用いた場合でも、試行錯誤を通じた評価関数の学習によって、ある程度状況に応じた適切な打ち手の選択が実現されることが確かめられました。一方、今回の学習環境については、(学習ネットワークや学習過程、入力情報の構成の改善などによる)改善の余地が残っていることも、以前の結果との比較を通して分かりました。
最後に、画像を直接入力にした際には、画像分析の周辺技術が適用でき、例えば
- 深層学習は画像のどこを見ている!? CNNで「お好み焼き」と「ピザ」の違いを検証
-
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
に紹介されているような可視化技術を用いて、実際に学習したネットワークが入力画像のどの部分を見て、価値関数を算出しているかが分かったりします。
詳細は省きますが、Callback関数にGrad-CAMのKeras実装例を適用して得られた結果が以下です。左がオリジナルの(0チャンネルの)入力画像、右がネットワークの出力評価値に基づいたGrad-CAMによる可視化結果です。赤く色づいている部分が、価値関数に強く影響を与えている画像領域です。


確かに、画像中の棒の部分(やその過去フレームの位置)に着目して、価値関数の算出を行っていることが分かります。学習の十分さに課題は残しつつも、ざっくり実装した割には当初期待通り学習が進んでおり、興味深い結果となりました。
まとめ
今回は、ビジネス課題の解決においても、より現実世界の時間の流れに沿った動的な課題に対して度々適用が検討される、強化学習、特に深層強化学習を取り上げてみました。最近の統合環境の整備に伴って、まさに現在発展しているアルゴリズムへのキャッチアップにとどまらず、その実装や実際の課題に対しての適用や試行錯誤が身近に行えるようになってきていることが分かっていただければ幸いです。
もし、各種アルゴリズムの詳細にご興味がありましたら、本文中にご紹介した様々な書籍やレビュー記事、元論文を参照いただくと良いかと思います。
深層強化学習の技術は、より複雑で動的な課題への機械学習適用の需要や、深層学習とその周辺技術の発展とともに、今後もより一層発展していくと思われますので、引き続き注意深く見守っていきたいと思っています。