はじめに
この記事は DeepLearning論文紹介 Advent Calendar 2017の16日目の記事です.
Distributed Prioritized Experience Replayを読んだので解説してみようと思います.
(Under review as a conference paper at ICLR 2018 ...査読中みたいです.)
論文について
この論文は強化学習について書かれたものです.
内容についてですが,APE-Xという新しい学習モデルを利用し,Prioritized Experience Replayを効率的に分散化する事でstate-of-the-artとなる結果を出した,というものです.
分散型強化学習の他の手法として,A3CやUNREALといった手法があります.
また,強化学習の基礎的な手法としてQ学習やDQN,DDQNなどの手法が挙げられますが,今回の解説ではこれらについては割愛します.
従来手法の解説については,以下の記事がとても参考になりました.
解説
Prioritized Experience Replayとは,Networkの学習の際に,TD誤差が大きい経験を優先して利用する手法の事です.
簡単に言うと,効率よく学習出来る経験を優先的に利用しましょう,という事です.
詳しく知らない方は,以下の記事が分かりやすいと思います.
APE-Xでは,この手法を効率的に分散しています.
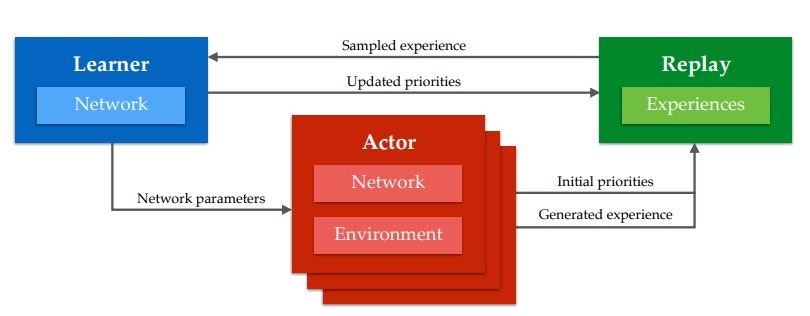
↑は,論文に乗せられていたAPE-Xの概要図になります.
APE-Xでは,学習モデルをLearnerとActor,Replay Memoryの3つに分離して考えます.以下でそれぞれ説明します.
- Actor
- Agentの役割は,学習環境で経験を集めて,それをReplayMemoryに貯めることです.Actorはマルチスレッド上で並列に動き,それぞれに学習環境や行動を決定するためのNetworkを持ちます.また,Actorが持つNetworkは学習されることはなく,一定間隔毎にLearnerのNetworkからパラメータをコピーすることで最新の状態に更新されます.
- Learner
- Learnerの役割は,ReplayMemoryに貯められた経験を利用してNetworkを学習することです.LearnerはGPU上で1つだけ動いています.
- ReplayMemory
- ReplayMemoryは,Agentから受け取った経験を貯め,それをLearnerに渡すことです.構造上,メモリサイズは結構必要になります.
従来のA3Cなどの分散型強化学習モデルでは,各Agentがパラメータを共有したNetworkを持ち,それぞれのAgentがNetworkを好き勝手に更新していきます.(多分.)
一方APE-Xでは,学習を行うのはLearnerのみとなっています.
経験を集めるタスクと学習を行うタスクを上手く分離して処理を行うことで,従来よりも高速な学習を可能にしているようです.
他にも,従来手法同様,Advantageやmulti-step bootstrap targetsなどの手法を利用し,学習効率を高めています.
結果
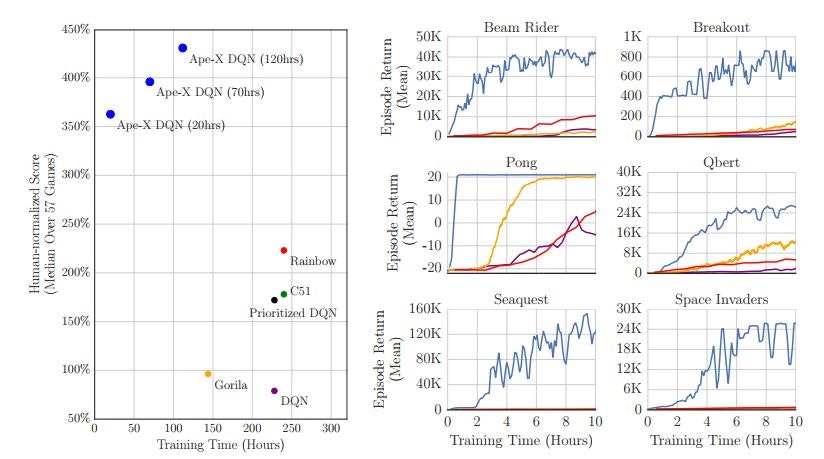
論文に掲載されていた結果の一部です.
学習効率,成果ともに半端ない進歩ですね.
Rainbowがはるか下にいますね.シュゴイ.
感想
実装もUNREALみたいな従来手法より楽そうだし,これからの主流になっていきそう.
Anonymous authors...一体誰なんだ...
(追記)
DeepMindだった.