Keras + TensorFlow で Ape-X を実装しました。
コードはgithubにあげてあります。
https://github.com/omurammm/apex_dqn
強化学習の知識として、
DQNまでは知っているとわかりやすいと思います。
DQNまでの勉強では以下のサイトが非常に参考になります。
・ゼロからDeepまで学ぶ強化学習
・強化学習について学んでみた。(その1)
Ape-Xとは
論文:DISTRIBUTED PRIORITIZED EXPERIENCE REPLAY
簡単にいうと、論文のタイトルにもあるように,
優先順位付き経験再生(Prioritized Experience Replay)を分散学習で行おうというやつです。
その性能は・・・
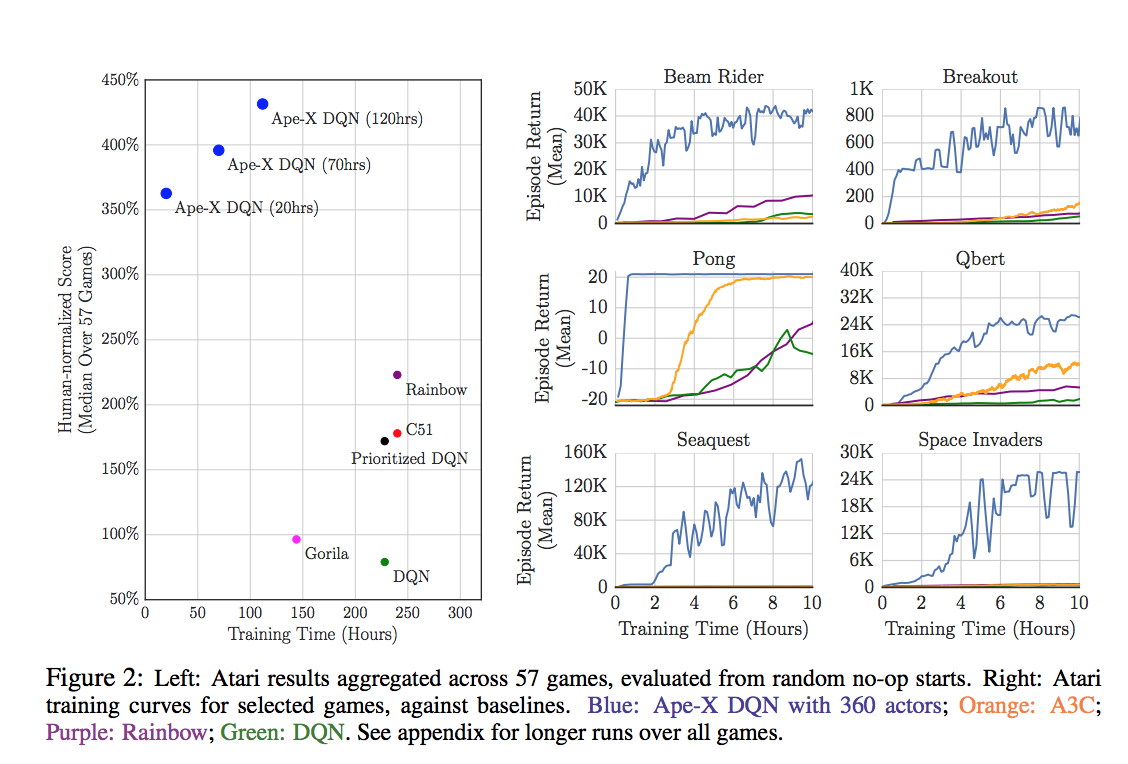
これらのグラフはOpenAI Gym Atari 2600 gamesでテストした結果です。
すごい。。。
学習時間もスコアも圧倒的です。。。
Ape-Xを少し詳しく説明すると、
上でいったように、分散学習+優先順位付き経験再生、
それに諸々の修正を加えたものを Ape-X と言います。
具体的には、
・分散学習
・Prioritized Experience Replay
・Dueling Network
・Double Deep Q-Network
・multi-step bootstrap target
これらを組み合わせて Ape-X DQN としています。
(論文ではApe-X DPGというのも少し説明していますが、ここでは触れません。)
学習アルゴリズムとして
・DDQN + multi-step bootstrap target
Q関数の近似器として
・Dueling Network
データのサンプリングで
・Prioritized Experience Replay
を利用して分散学習させている感じです。
それぞれ、軽く説明していきます。
分散学習

Ape-Xでは、1つのLeanerと複数のActorが1つのReplay Memoryを共有しながら学習していきます。
それぞれの役割は
Learner
・Replay Memory から優先順位をもとに遷移をサンプリングして、学習を行う。
・Actorがパラメータ更新のリクエストを出したら、LeanerがもつNetworkのパラメータをコピーさせる。
・1つのGPU上で動いている。
Actor
・それぞれのActorがそれぞれのNetwork, Environmentをもっている。
・それぞれのEnvironmentで遷移を観測し、初期priorityを計算してReplay Memoryに送る。
・定期的にLeanerのパラメータをコピーする。
・1つのアクターが1つのCPUを利用して動いている。
(論文では360のCPUを使用して、360のActorを動かしている。)
(もちろん360もCPUを持っていないので非常に困ります、、)
従来の手法と違う点は
-
A3Cなど従来の分散学習では、各AgentがそれぞれのNetworkに対して勾配を計算し、それを共有している1つのNetworkに送ってパラメータを更新しているが、
Ape-Xでは、それぞれが遷移を生成するだけである。
遷移は勾配に比べて、共有するネットワークに対して古くても問題がないので、バッチ処理をして効率をよくすることができる。 -
従来の優先順位付き経験再生では、それぞれの遷移の初期priorityは、どの遷移も一度は学習に使わせるために、今までで一番大きなpriorityとしている。
しかし、複数のActorがいるApe-Xでは、それだと再生されるのが直近の遷移ばかりになってしまう。なので、それぞれのActorがローカルのネットワークでpriorityを計算してからReplay Memoryに送る。
などです。
実装では、
・pythonのmultiprocessingを利用してLeanerとActorを並列で動かしています。
・learnerがReplay memoryを持ち、multiprocessing.Queueで遷移を共有しています。
・LeanerとActor間のパラメータの共有もmultiprocessing.Queueを利用しています。
(tf.Serverがうまくいかない、、)
参考
Distributed Prioritized Experience Replayを読んだので解説してみる
Dueling Network
【深層強化学習】Dueling Network 実装・解説
ここで実装・解説しているので参考にしてください。

普通のQ-networkは図(上)のように、状態を入力として受け取り、
SeaquentialなNetworkを通して行動価値関数Q(s,a)を予測する。
それに対しDueling-networkでは図(下)のように、状態を入力として受け取り、途中で状態価値関数V(s)とAdvantage( A(s,a) = Q(s,a) - V(s) )の二つの流れに別れた後、最後に足し合わせることで、行動価値関数Q(s,a)を予測する。
モデルはこんな感じです。
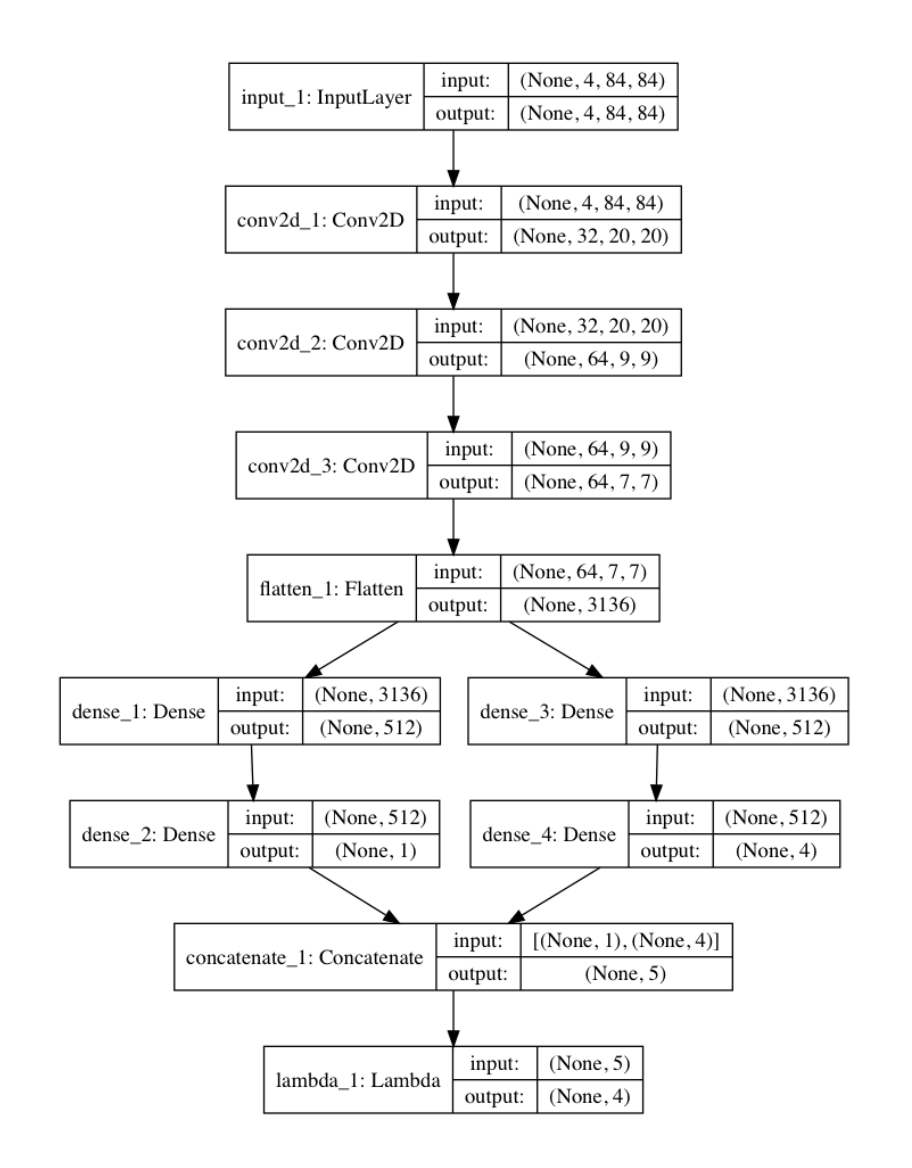
コードはこんな感じです。
l_input = Input(shape=(4,84,84))
conv2d = Conv2D(32,8,strides=(4,4),activation='relu', data_format="channels_first")(l_input)
conv2d = Conv2D(64,4,strides=(2,2),activation='relu', data_format="channels_first")(conv2d)
conv2d = Conv2D(64,3,strides=(1,1),activation='relu', data_format="channels_first")(conv2d)
fltn = Flatten()(conv2d)
v = Dense(512, activation='relu')(fltn)
v = Dense(1)(v)
adv = Dense(512, activation='relu')(fltn)
adv = Dense(self.num_actions)(adv)
y = concatenate([v,adv])
l_output = Lambda(lambda a: K.expand_dims(a[:, 0], -1) + a[:, 1:] - tf.stop_gradient(K.mean(a[:,1:],keepdims=True)), output_shape=(self.num_actions,))(y)
model = Model(input=l_input,output=l_output)
詳しくは【深層強化学習】Dueling Network 実装・解説をみてください。
DDQN + multi-step bootstrap target
それぞれの場合のTD誤差の式を説明します。
TD誤差は、上記のDueling Networkなどで推定されるQ値の誤差を定義したものです。
参考:TD学習 - kajisatoの日記
DDQN
\begin{align}
&DQN&&δ_{t} = R_{t+1} + γ\:max_{a}Q_{target}(S_{t+1}, a)- Q(S_{t},A_{t})
\\
&DDQN&&δ_{t} = R_{t+1} + γQ_{target}(S_{t+1}, arg max_{a}Q(S_{t+1},a))- Q(S_{t},A_{t})
\end{align}
DDQNでは、$Q_{target}$とは別でmainのQ関数を使ってActionを選択することで、Actionの推定誤差の影響を抑制している。
multi-step bootstrap target
\begin{align}
&DQN&&δ_{t} = R_{t+1} + γ\:max_{a}Q_{target}(S_{t+1}, a)- Q(S_{t},A_{t})
\\
&n\:step\;DQN &&δ_{t} = R_{t+1}+γ^{2}R_{t+2}+..+γ^{n-1}R_{t+n-1} + γ^{n}\:max_{a}Q_{target}(S_{t+n}, a)-Q(S_{t},A_{t})
\end{align}
通常のDQNでは、次の状態へのstepで得られる報酬と次の状態でのQ値の和が、その状態でのQ値の目標値としていた。
それをn-step先までの累積報酬とn-step先でのQ値の和にしたものが multi-step bootstrap target
DDQN + multi-step bootstrap target
δ_{t} = R_{t+1}+γ^{2}R_{t+2}+..+γ^{n-1}R_{t+n-1} + γ^{n}Q_{target}(S_{t+n}, arg max_{a}Q(S_{t+n},a))-Q(S_{t},A_{t})
上の2つを組み合わせたのが今回使うTD誤差です。
論文では、n = 3 で実装しています。
multi-step bootstrap targetの実装では
【強化学習】実装しながら学ぶA3C【CartPoleで棒立て:1ファイルで完結】
のAdvantageの部分を参考にさせていただきました。(厳密にはAdvantageはQ(s,a)-V(s)のことです。)
nステップ先までの遷移を格納するBufferを作成し、nステップ先まで溜まったら累積報酬を計算してローカルメモリにpushするという感じです。
DQNの学習の部分の実装は
DQNをKerasとTensorFlowとOpenAI Gymで実装する
を参考にさせていただきました。
優先順位付き経験再生
【深層強化学習】優先順位付き経験再生 ( Prioritized Experience Replay ) 実装・解説
ここで実装、解説しているので参考にしてください。
ここでは重要度サンプリングの話は省略します。
優先度
Ape-Xでは、それぞれの遷移の優先度をTD誤差の絶対値で定義している。
\;p_{i} = |\,δ_{i}\,|
そして遷移iがサンプリングされる確率を下の式で定義する。
P(i) = \frac{p^{α}_{i}}{Σ_{k}p^{α}_{i}}
遷移が観測されてからサンプリングされるまでの手順は
Actor側
・ローカルのバッファに格納される。
・nステップ先まで観測されたら累積報酬を計算してバッファから吐き出され、ローカルメモリに入れられる。
・ローカルメモリが一定量を超えたら、それらの優先度を計算して、まとめてリモートメモリに送られる。
Learner側
・リモートメモリから優先度に基づいてサンプリングする。
・学習後、学習に使った遷移の優先度を更新する。
・遷移の数がリモートメモリのサイズを超えていたら超過分だけ古い遷移を取り除く。(定期的に)
といった感じです。
実装
【深層強化学習】優先順位付き経験再生 ( Prioritized Experience Replay ) 実装・解説
ここでは、replay memoryは二分木で定義していたが、
今回は、古い遷移を定期的に超過分捨てており、メモリのサイズは固定ではないので、リモートメモリ、ローカルメモリともにdequeで定義している。
リモートメモリのクラスはこんな感じです。
class Memory:
def __init__(self):
self.transition = deque()
self.priorities = deque()
self.total_p = 0
def _error_to_priority(self, error_batch):
priority_batch = []
for error in error_batch:
priority_batch.append(error**MEMORY_ALPHA)
return priority_batch
def length(self):
return len(self.transition)
def add(self, transiton_batch, error_batch):
priority_batch = self._error_to_priority(error_batch)
self.total_p += sum(priority_batch)
self.transition.extend(transiton_batch)
self.priorities.extend(priority_batch)
def sample(self, n):
batch = []
idx_batch = []
segment = self.total_p / n
idx = -1
sum_p = 0
for i in range(n):
a = segment * i
b = segment * (i + 1)
s = random.uniform(a, b)
while sum_p < s:
sum_p += self.priorities[idx]
idx += 1
idx_batch.append(idx)
batch.append(self.transition[idx])
return batch, idx_batch
def update(self, idx_batch, error_batch):
priority_batch = self._error_to_priority(error_batch)
for i in range(len(idx_batch)):
change = priority_batch[i] - self.priorities[idx_batch[i]]
self.total_p += change
self.priorities[idx_batch[i]] = priority_batch[i]
def remove(self):
print("Excess Memory: ", (len(self.priorities) - NUM_REPLAY_MEMORY))
for _ in range(len(self.priorities) - NUM_REPLAY_MEMORY):
self.transition.popleft()
p = self.priorities.popleft()
self.total_p -= p
確率に基づいてサンプリングする手法は
LET’S MAKE A DQN: DOUBLE LEARNING AND PRIORITIZED EXPERIENCE REPLAY
ここを参考にしてださい。
実装上のポイント
説明できていないポイントをざっくり説明していきます。
・ε-greedy
従来のε-greedyはεを1から徐々に小さくしていくが、今回はActorごとに固定。以下の式で定義
ε_{i} = ε^{1+\frac{i}{N-1}α}
これによって多様な遷移を獲得できる。
ε=0.4, α=7で実装している。
また、Actionを決定するとき、Q値をもとに決定するので、そこで使ったQ値を初期priorityの計算にも利用する。
・最適化
Centerd RMSProp使用
学習率 0.00025/4, decay 0.95, epsilon 1.5e-7, momentumなし
勾配はノルムが40以下になるようにクリッピング
LEARNING_RATE = 0.00025 / 4
optimizer = tf.train.RMSPropOptimizer(LEARNING_RATE, decay=0.95, epsilon=1.5e-7, centered=True)
grads_and_vars = optimizer.compute_gradients(loss, var_list=q_network_weights)
capped_gvs = [(grad if grad is None else tf.clip_by_norm(grad, clip_norm=40), var) for grad, var in grads_and_vars]
grad_update = optimizer.apply_gradients(capped_gvs)
・学習開始まで
リモートメモリに遷移が50000溜まるまではLeanerは待機している。
・CPU, GPU使い分け
sess = tf.InteractiveSession()
with tf.device("/gpu:0"):
threads = [Learner(sess)]
with tf.device("/cpu:0"):
for i in range(NUM_ACTORS):
threads.append(Actor(number=i, sess=sess))
for worker in threads:
job = lambda: worker.run()
t = threading.Thread(target=job)
t.start()
Leaner, Actorクラスのインスタンスを生成するときにtf.deviceでcpu,gpuを指定できます。
cpuが同じマシン上に複数ある場合は、for文の中でそれぞれをtf.deviceで指定すればできると思います。
ただ、指定しないほうが効率よく処理してくれて早かったので実装では指定していません。
・パラメータ
論文で記述してあるパラメータのデフォルト値をまとめておきます。
| Parameters | Value |
|---|---|
| Number of Actors | 360 |
| Target Network の更新間隔 | every 2500 training batches |
| Actorsがnetwork parametersをコピーする間隔 | every 400 frames |
| n (n-step target) | 3 |
| Traing Batch Size | 512 |
| localからremote memoryに送るBatch Size | 50 |
| Replay Memory Size | 2 million ( soft-limited*) |
| 超過分のメモリを捨てる間隔 | every 100 learning steps |
| α (priority) | 0.6 |
| β (Importance Sampling) | 0.4 |
| ε (ε-greedy) | 0.4 |
| α (ε-greedy) | 7 |
| 学習率 | 0.00025 / 4 |
| decay (RMSProp) | 0.95 |
| ε (RMSProp) | 1.5e-7 |
*Replay Memoryは一定期間ごとに超過分を捨てるのでReplay Memory Sizeは2 million より大きくなりうる。中央値は 2035050。
実行結果
OpenAI Gym Atari 2600 games のAlien で実行しました。
論文のように360のCPUで360のActorを立てて実行したかったんですが、もちろんできないので 4, 8 Actorで実行しました。
PCのスペックは
CPU: Intel Core i7-7700 (4コア)
GPU: GeForce GTX 1080
RAM: 40 GB

10,000エピソード学習させました。それなりに学習できてます。
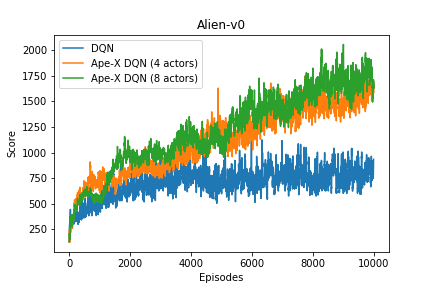
学習曲線です。DQNと比べてみました。
学習時間を伸ばせばまだ伸びそう。
以上で終わります。
ありがとうございました。