Keras + Tensorflow で
PER + DDQN を実装しました。
全体のコードをGitHubにあげておきます。
https://github.com/omurammm/rl_implementation
優先順位付き経験再生 ( Prioritized Experience Replay) とは
論文: https://arxiv.org/pdf/1511.05952.pdf
優先度
通常のDQNでは、replay memory からランダムに遷移をサンプリングし、学習に使用していた。
PERでは、学習がより早く進む遷移を優先的にサンプリングする。
その指標としてTD誤差を使用する。

( DDQNのTD誤差 )
優先度の付け方には2通りある
・Proportinal

(εはpiが0になってサンプリングされる確率が0になるのを防ぐため)
・Rank-based

上記の優先度を用いて、遷移 i がサンプリングされる確率を下記で定義する。

今回は、論文でもより良い結果を残していたProportinalな優先度で実装する。
Replay Memoryは二分木で最も効率よくサンプリングできる。(詳しくは実装)
重要度サンプリング
サンプリングに優先順位をつけることで、サンプリングの分布に偏りが生じてしまう。
それによって収束する値も変わってしまう。
そこでその偏りを修正するのが、重要度サンプリング(IS: Importance Sampling)
これは重みの更新の際、TD誤差 δi ではなく、重み付けした wi・δi を使うことで実装される。
wiは下記で定義される。

(N : replay memory size)
βは修正の度合いを決める指数で、β=1でP(i)の不均一性を完全に埋めあわせる。
また、偏りのない更新は学習の終わりで収束するときに最も重要になってくる。
そのため、βが学習の終わりで1になるように線形に大きくしていく。
また、安定性のため、1 / max wi で正規化する。
これにより、w < 1 となり、下方にしか修正されなくなる。
実装
学習の流れ

学習の流れは上の図の通りで
今回重要なところを説明すると
学習開始前
・p = 1でreplay momoryに一定数の遷移(s, a, r, terminal, s') を格納
学習開始
・遷移を今までの最大のpと共に格納
(どの遷移も一度は再生されるようにするため)
・優先順位に基づきbatch sizeの数だけ遷移をサンプリング
・重要度サンプリングの重みを計算。
(バッチの最大の重みで割ることで, wiの最大が毎回1になるようにする)
・TD誤差δを計算
・TD誤差に基づいて、優先度pを更新する
・w,δを使って勾配計算
・その勾配でモデルのパラメータ更新
・ISに使うβを線形に更新
Replay Memory
Replay Memoryの実装に関してこちらが非常に参考になります。
Memoryからのサンプリングが少しわかりにくいので追加で解説する。
二分木の構造
二分木の定義に
https://github.com/jaara/AI-blog/blob/master/SumTree.py
を使わせていただきました。
まず、今回 replay memory に使う二分木の説明をする。
構造は下の図(まあまあ下)のようになっており、子ノードの値の和が親ノードの値となっている。
葉ノードに優先度の値が格納されている。
遷移の情報(s, a, r, terminal, s')はmemory sizeと同じ大きさをもつarrayで別で定義し、indexで対応させている。
np.arrayで定義しており、コードではこんな感じ
# 二分木
self.tree = numpy.zeros( 2*capacity - 1 ) # capacityはreplay memoryの大きさ
# 遷移
self.data = numpy.zeros( capacity, dtype=object )
self.tree[0]に優先度pの合計(根)が格納されており、
後ろのN個にそれぞれの優先度pが格納されている
(二分木の配列での定義はこちらが参考になると思います。)
サンプリング
二分木をもとにbatch sizeの数だけサンプリングを行う。
まず、ptotalの値(下の図では42)をbatch sizeの数の区分に均一に分ける。
そしてそれぞれの区分の中からランダムに整数を一つ取り出し、それをsとして下の図のようにサンプリングを行う。
(例えば、ptotal = 100, batch_size = 5 とすると、
まず5つの区分(0~20,21~40,41~60,61~80, 81~100)にわけ、
それぞれの区分からランダムに整数を抽出する(s_batch=(11,34,43,78,91)のような感じ)。
そしてそれぞれのsに対して下の図のように葉ノードを決定し、それに対応する遷移のdataをサンプリングする.)

この図はs = 24のサンプリングを表しており、イメージとしては葉のノードの値(優先度)を左から足していき、合計が 24を超えたところのノードを抽出する感じ。そして、それに対応する遷移をサンプリングする。
コードではこんな感じ ( get(s)でサンプリングできる )
class SumTree:
def get(self, s):
idx = self._retrieve(0, s)
dataIdx = idx - self.capacity + 1
return (idx, self.tree[idx], self.data[dataIdx])
def _retrieve(self, idx, s):
left = 2 * idx + 1
right = left + 1
if left >= len(self.tree):
return idx
if s <= self.tree[left]:
return self._retrieve(left, s)
else:
return self._retrieve(right, s-self.tree[left])
DDQN
DQNの大枠はこちらを参考にさせていただきました。
ここでは説明は省略させていただきます。
DQNのTD誤差の計算のところを
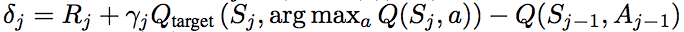
に変更するだけです
結果
OpenAI Gym Atari 2600 games のBreakout (ブロック崩し) で学習を行なった。
CPU: Intel Core i7-7700
GPU: GeForce GTX 1080
RAM: 8 GB
で12000エピソード ( だいたい丸一日 )学習させた。

メモリの都合上、replay momory の大きさを 200,000とした(論文では 106とか)
それと学習時間(論文では18日とか)が原因で、あまり学習できてないと思われる、、
PERではreplay memory sizeが重要な気がする。。
それが原因かはわかりませんが、
重要度サンプリングをつけるとなぜか全然学習しなかったので、重要度サンプリングはつけていない。
(何かわかる方、コメントで教えてください。。)

DDQN、Dueling-DDQN、PER-DDQNの比較。
PERがBreakoutをあまり得意ではないのもあってあまりよくない。
それとPERは学習の立ち上がりは早いが早期に収束して最終成績が悪化することがあるらしい。
こんな感じで終わります。
次でApe-X実装します。。
追記
replay memoryに格納していくところで小さいミスがあったのでコードを修正しました。