Keras + Tensorflow で
Dueling Network + DDQN を実装しました。
全体のコードをGitHubにあげておきます。
https://github.com/omurammm/rl_implementation
Dueling Networkとは
論文:https://arxiv.org/pdf/1511.06581.pdf
こちらの記事で詳しく説明してくださっているので参考にしてください

普通のQ-networkは図(上)のように、状態を入力として受け取り、
SeaquentialなNetworkを通して行動価値関数Q(s,a)を予測する。
それに対しDueling-networkでは図(下)のように、状態を入力として受け取り、途中で状態価値関数V(s)とAdvantage( A(s,a) = Q(s,a) - V(s) )の二つの流れに別れた後、最後に足し合わせることで、行動価値関数Q(s,a)を予測する。
Dueling Networkは、DQN, DDQNなどのModel-freeなアルゴリズムと組み合わせて利用することができる。
状態価値関数V(s)が行動aに寄らずに学習できることが主な利点となっている。

行動価値関数Qはこのようにして表される。
ただ、これはNetworkを途中で2つの流れに分けて足し合わせているだけで、
その2つの流れが本当に状態価値関数、Advantage関数を推定しているとは言えない。

そこで、このようにAの平均やmaxを定数として引いてactionの相対的な良し悪し(Advantage)を評価している。
そして、評価できていることも確かめられている。
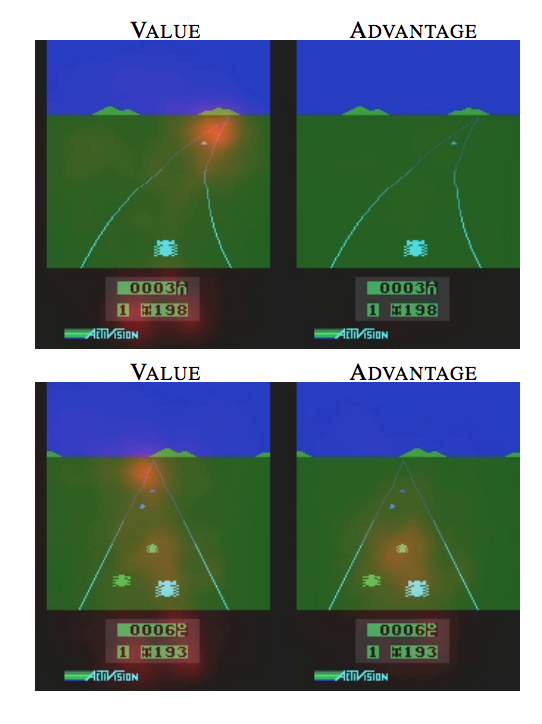
これはヤコビアンを計算することで、V,Aそれぞれの層が注意しているところをスポットしたもの。
(手法の論文: https://arxiv.org/pdf/1312.6034.pdf)
2つの状況について実行しており、
・状態価値関数
どちらもスコアと道の水平線上のあたりに注目している。
・Advantage
他の車がないときはどこにも注目せずに、近づいてきたら他の車に注目している。
これは他の車がActionの選択に関係しているからである。
識別できてる、、すごい!
実装
こちらの記事で簡単なモデルで実装しているので、それを参考にさせていただきながら論文をより忠実に実装した。
OpenAI Gym Atari 2600 gamesで学習、テストを行なった。
実装はKeras+Tensorflowで行なった。
Model
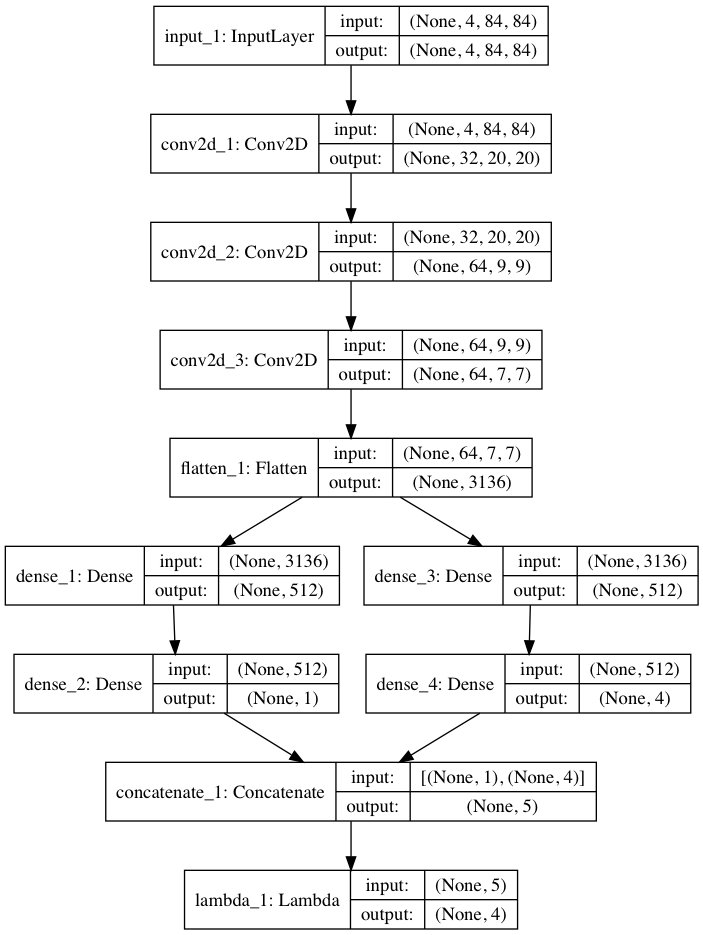
入力画像を(84, 84, 4)のサイズに加工し、入力としている。(コードではchannel-firstで(4, 84, 84)となっている)
前半は普通のDQNのようにCNNで学習。
途中でV(s)の層(dense_1、dense_2)とAdvantageの層(dense_3、dense_4)に別れる。
それぞれで一度全結合層を通して、ノード数はV : 1、A : 行動の数(この場合4) となる。
最後にConcatenate層で1つの層にまとめてから、Lambda層で足し合わせる。
※追記 それぞれの全結合層のノード数を256にしていましたが、論文を確認したところ512だったので修正しました
l_input = Input(shape=(4,84,84))
conv2d = Conv2D(32,8,strides=(4,4),activation='relu', data_format="channels_first")(l_input)
conv2d = Conv2D(64,4,strides=(2,2),activation='relu', data_format="channels_first")(conv2d)
conv2d = Conv2D(64,3,strides=(1,1),activation='relu', data_format="channels_first")(conv2d)
fltn = Flatten()(conv2d)
v = Dense(512, activation='relu')(fltn)
v = Dense(1)(v)
adv = Dense(512, activation='relu')(fltn)
adv = Dense(self.num_actions)(adv)
y = concatenate([v,adv])
l_output = Lambda(lambda a: K.expand_dims(a[:, 0], -1) + a[:, 1:] - tf.stop_gradient(K.mean(a[:,1:],keepdims=True)), output_shape=(self.num_actions,))(y)
model = Model(input=l_input,output=l_output)
コードはこんな感じ。
 *(s:状態, a:行動, θ:CNN部分のパラメータ, α,β:A(s,a),V(s)部分の全結合層のパラメータ)*
*(s:状態, a:行動, θ:CNN部分のパラメータ, α,β:A(s,a),V(s)部分の全結合層のパラメータ)*
最後のLambda層で足し合わせるところは式で表すとこんな感じ。
Modelの中でV(s)とA(s,a)をよりIdentificableにするためにAの平均を引くのが一般的。(詳しくは論文みてください)
A(s,a)の平均は tf.stop_gradientを使って勾配計算に組み込まれないように定数化しています。
DQNの大枠はこちらを参考にさせていただきました。
ここでは説明は省略させていただきます。
DDQNは、DQNのTD誤差の計算のところを
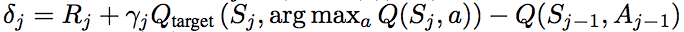
に変更するだけです
結果
OpenAI Gym Atari 2600 games のBreakout (ブロック崩し) で学習を行なった。
CPU: Intel Core i7-7700
GPU: GeForce GTX 1080
RAM: 8 GB
で12000エピソード ( だいたい丸一日 )学習させた。

メモリの都合上、replay momory の大きさを 200,000とした(論文では 106とか)
それと学習時間(論文では18日とか)が原因で、あまり学習できてないと思われる、、

Dueling-DDQN と DDQN の比較はこんな感じ
total reward は 5回球を落とすまでに壊せたブロックの数。
そのままプロットすると振れ幅が大きすぎたので、前後20回の平均を取っている。
DDQNより早く学習が進むことがわかる。
こんな感じで終わります。
優先順位付き経験再生とかも実装・解説していきたいと思います
とりあえずApe-Xまで。。