前回
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (16)
https://github.com/legacyworld/sklearn-basic
課題 8.7 主成分分析の例
Youtubeでの解説:第9回(1) 30分あたり
課題 8.3はCluster3をうまく再現できなかったので諦めた。
いつものアヤメデータを主成分分析する問題。
プログラムとしてはscikit-learnは簡単。グラフの部分だけpandasのscatter_matrixを使うのが今までと少し違うだけ。
# 課題 8.7 主成分分析の例
# Youtubeでの解説:第9回(1) 30 分あたり
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
iris = load_iris()
pca = PCA()
X = iris['data']
y = iris['target']
# 主成分分析
pca.fit(X)
transformed = pca.fit_transform(X)
# 寄与率
print(pca.explained_variance_ratio_)
# 描画
fig, ax = plt.subplots()
iris_dataframe = pd.DataFrame(transformed, columns=[0,1,2,3])
Axes = pd.plotting.scatter_matrix(iris_dataframe, c=y, figsize=(50, 50),ax=ax)
plt.savefig("8.7.png")
寄与率
[0.92461872 0.05306648 0.01710261 0.00521218]
グラフ
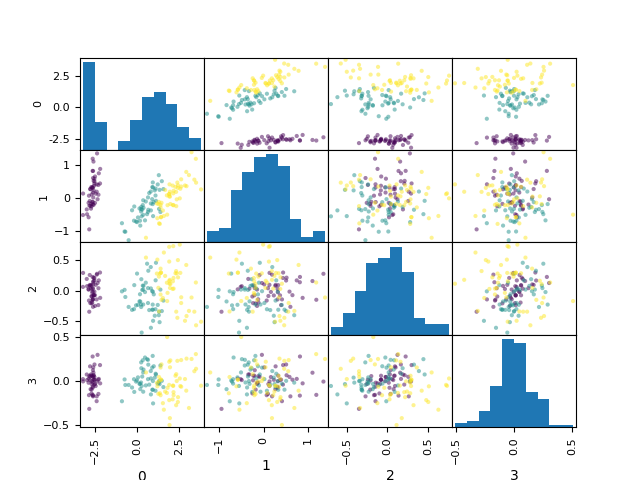
第一主成分の寄与率が0.92で、グラフを見ても左端(第一主成分)はクリアに分かれているのがわかる。
なのでsetosaの分類器は第一主成分だけで92.5%分類出来て、4成分にしてもさして上がらないので、第一主成分だけで良いということ。
過去の投稿
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (1)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (2)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (3)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (4)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (5)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (6)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (7) 最急降下法を自作
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (8) 確率的最急降下法を自作
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (9)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (10)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (11)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (12)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (13)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (14)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (15)
https://github.com/legacyworld/sklearn-basic
https://ocw.tsukuba.ac.jp/course/systeminformation/machine_learning/