「ディープラーニングを実装から学ぶ」をテーマに掲載してきましたが、記事が多くなり、どこに記載したか分からなくなってきたため、索引としてまとめを作成しました。
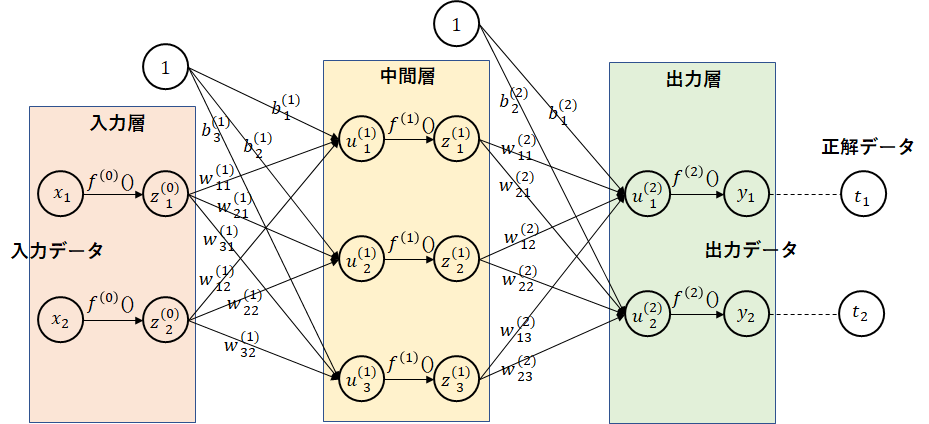
1. 活性化関数
1.1 中間層
1.1.1 ReLU
(関数)
f(x) = \left\{
\begin{array}{ll}
x & (x \gt 0) \\
0 & (x \leq 0)
\end{array}
\right.
(グラフ)
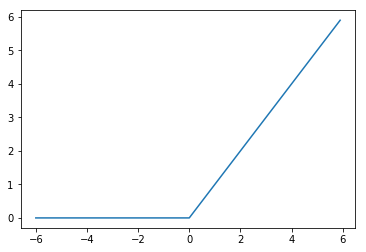
(参考)
ディープラーニングを実装から学ぶ(2)ニューラルネットワーク ReLU
ディープラーニングを実装から学ぶ(4-2)学習(誤差逆伝播法2) 活性化関数
1.1.2 Sigmoid
(関数)
f(x) = \frac{1}{1+e^{-x}}
(グラフ)
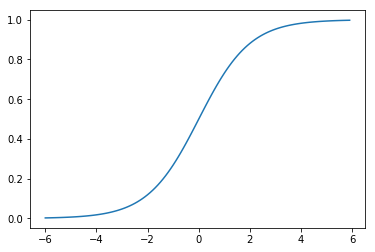
(参考)
ディープラーニングを実装から学ぶ(2)ニューラルネットワーク シグモイド関数
ディープラーニングを実装から学ぶ(5)学習(パラメータ調整) sigmoid
1.1.3 Tanh
(関数)
f(x) = \tanh(x)
(グラフ)
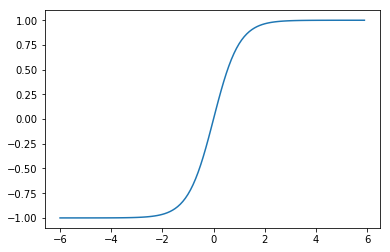
(参考)
ディープラーニングを実装から学ぶ(2)ニューラルネットワーク 双曲線正接関数
ディープラーニングを実装から学ぶ(5)学習(パラメータ調整) tanh
1.1.4 identity(恒等関数)
(関数)
f(x) = x
(参考)
ディープラーニングを実装から学ぶ(5)学習(パラメータ調整) identity
1.1.5 softplus
(関数)
f(x) = \log(1 + e^x)
(グラフ)

青がsoftplus、オレンジがReLU
(参考)
ディープラーニングを実装から学ぶ(5)学習(パラメータ調整) softplus
1.1.6 softsign
(関数)
f(x) = \frac{x}{1 + |x|}
(グラフ)

青がsoftsign、オレンジがtanh
(参考)
ディープラーニングを実装から学ぶ(5)学習(パラメータ調整) softsign
1.1.7 step
(関数)
f(x) = \left\{
\begin{array}{ll}
1 & (x \gt 0)\\
0 & (x \leq 0)
\end{array}
\right.
(参考)
ディープラーニングを実装から学ぶ(5)学習(パラメータ調整) step
1.1.8 Leaky ReLU
(関数)
f(x) = \left\{
\begin{array}{ll}
x & (x \gt 0) \\
\alpha x & (x \leq 0)
\end{array}
\right.
(グラフ)

($ \alpha = 0.1 $)
(参考)
ディープラーニングを実装から学ぶ(5)学習(パラメータ調整) Leaky ReLU
1.1.9 PReLU(Parametrized ReLU)
(関数)
f(x_i) = \left\{
\begin{array}{ll}
x_i & (x_i \gt 0) \\
\alpha_i x_i & (x_i \leq 0)
\end{array}
\right.
($ \alpha_i $は、学習パラメータ)
(参考)
ディープラーニングを実装から学ぶ(7-1)その他(活性化関数~MaxOut、ReLU関連) PReLU(Parametrized ReLU)
1.1.10 RReLU(Randomized Leaky ReLU)
(関数)
f(x_i) = \left\{
\begin{array}{ll}
x_i & (x_i \gt 0) \\
\alpha_i x_i & (x_i \leq 0)
\end{array}
\right.
($ \alpha_i $は、乱数で決定)
(参考)
ディープラーニングを実装から学ぶ(7-1)その他(活性化関数~MaxOut、ReLU関連) RReLU(Randomized Leaky ReLU)
1.1.11 一定の値以上を定数とするReLU(ReLU6など)
(関数)
f(x) = \left\{
\begin{array}{ll}
n & (x \gt n) \\
x & (n \ge x \gt 0) \\
0 & (x \leq 0)
\end{array}
\right.
(グラフ)
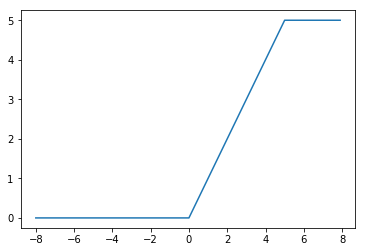
($n=5$)
(参考)
ディープラーニングを実装から学ぶ(7-1)その他(活性化関数~MaxOut、ReLU関連) 一定の値以上を定数とするReLU
1.1.12 SReLU(Shifted ReLU)
(関数)
f(x) = \left\{
\begin{array}{ll}
x & (x \gt \alpha) \\
\alpha & (x \leq \alpha)
\end{array}
\right.
(グラフ)
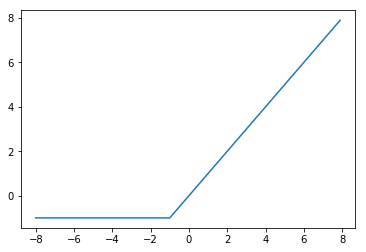
($\alpha=-1$)
(参考)
ディープラーニングを実装から学ぶ(7-1)その他(活性化関数~MaxOut、ReLU関連) SReLU(Shifted ReLU)
1.1.13 ELU
(関数)
{f(x) = \left\{
\begin{array}{ll}
x & (x \gt 0) \\
\alpha(e^x-1) & (x \leq 0)
\end{array}
\right.
}
(グラフ)
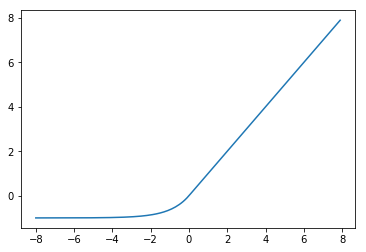
(参考)
ディープラーニングを実装から学ぶ(7-1)その他(活性化関数~MaxOut、ReLU関連) ELU
1.1.14 Swish
(関数)
f(x) = x\cdot\mathrm{sigmoid}(x)
(グラフ)

(参考)
ディープラーニングを実装から学ぶ(8-2)活性化関数(Swish,Mish) Swish
1.1.15 Mish
(関数)
f(x) = x\cdot\mathrm{tanh}(\mathrm{softplus}(x))
(グラフ)
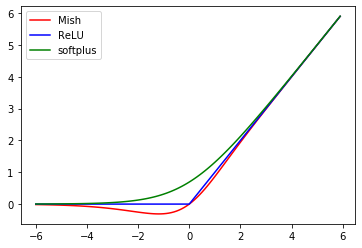
(参考)
ディープラーニングを実装から学ぶ(8-2)活性化関数(Swish,Mish) Mish
1.1.16 h-swish
(関数)
f(x) = x\cdot\frac{\mathrm{ReLU6}(x+3)}{6}
(グラフ)
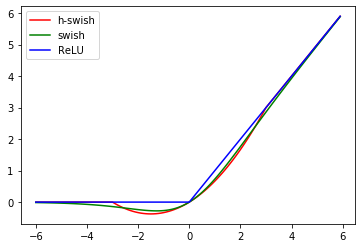
(参考)
ディープラーニングを実装から学ぶ(8-3)h-swish,TanhExp,Flooding,Nesterov h-swish
1.1.17 TanhExp
(関数)
f(x) = x\cdot\mathrm{tanh}(e^x)
(グラフ)
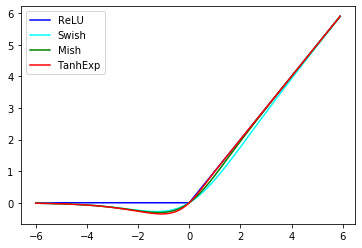
(参考)
ディープラーニングを実装から学ぶ(8-3)h-swish,TanhExp,Flooding,Nesterov TanhExp
1.2 出力層
1.2.1 identity(恒等関数)
回帰分析時の出力層の活性化関数
(関数)
f(x) = x
(参考)
ディープラーニングを実装から学ぶ(5)学習(パラメータ調整) 恒等関数+二乗和誤差
1.2.2 Sigmoid
2値分類時の出力層の活性化関数
(関数)
f(x) = \frac{1}{1+e^{-x}}
(参考)
ディープラーニングを実装から学ぶ(2)ニューラルネットワーク シグモイド関数
ディープラーニングを実装から学ぶ(5)学習(パラメータ調整) sigmoid
1.2.3 Softmax
多値分類時の出力層の活性化関数
(関数)
f(x_i) = \frac{e^{x_i}}{\sum_{k=1}^{n}e^{x_k}}
(参考)
ディープラーニングを実装から学ぶ(4-2)学習(誤差逆伝播法2) 出力層+損失関数
2. 結合
2.1 全結合
2.1.1 affine
\begin{pmatrix}
w_{11} & w_{12}\\
w_{21} & w_{22}\\
w_{31} & w_{32}
\end{pmatrix}
\begin{pmatrix}
x_1\\
x_2
\end{pmatrix}
+
\begin{pmatrix}
b_1\\
b_2\\
b_3
\end{pmatrix}
=
\begin{pmatrix}
w_{11}x_1+w_{12}x_2+b_1\\
w_{21}x_1+w_{22}x_2+b_2\\
w_{31}x_1+w_{32}x_2+b_3
\end{pmatrix}
(参考)
ディープラーニングを実装から学ぶ(2)ニューラルネットワーク アフィン変換
2.1.2 MaxOut
affine変換をn個用意し、そのうち最大の値を採用
(参考)
ディープラーニングを実装から学ぶ(7-1)その他(活性化関数~MaxOut、ReLU関連) MaxOut
2.2 CNN
2.2.1 convolution2d
畳み込み
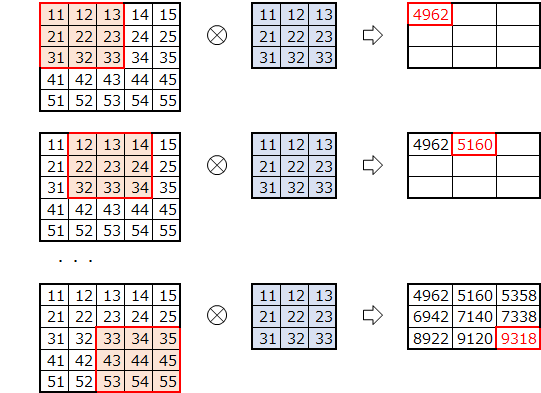
(参考)
ディープラーニングを実装から学ぶ(9-1)CNNの実装 畳み込み
2.2.2 max_pooling2d
マックスプーリング
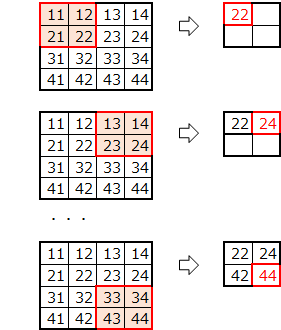
(参考)
ディープラーニングを実装から学ぶ(9-1)CNNの実装 マックスプーリングの実装
2.2.3 average_pooling2d
平均プーリング
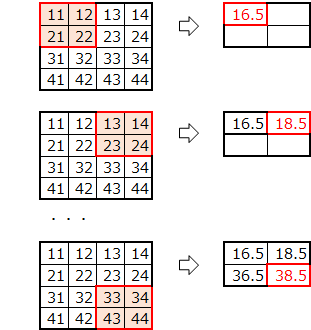
(参考)
ディープラーニングを実装から学ぶ(9-1)CNNの実装 平均プーリングの実装
2.2.4 flatten2d
flatten
(参考)
ディープラーニングを実装から学ぶ(9-1)CNNの実装 flatten
2.3 RNN
2.3.1 RNN
シンプルRNN

(参考)
ディープラーニングを実装から学ぶ(10-1)RNNの実装(RNN,LSTM,GRU) シンプルRNN
2.3.2 LSTM
LSTM(Long short-term memory)

(参考)
ディープラーニングを実装から学ぶ(10-1)RNNの実装(RNN,LSTM,GRU) LSTM(Long short-term memory)
2.3.3 GRU
GRU

(参考)
ディープラーニングを実装から学ぶ(10-1)RNNの実装(RNN,LSTM,GRU) GRU
2.3.4 双方向RNN
双方向シンプルRNN、双方向LSTM、双方向GRU

(参考)
ディープラーニングを実装から学ぶ(10-2)RNNの実装(双方向RNN・orthogonal(重みの初期値)) 双方向RNN
2.3.5 Self-Attention
注意機構を用いたRNN

(本来は、Attentionの値は、RNNの各時刻からの出力で決定されますが、簡略化して図示しています。)
(参考)
ディープラーニングを実装から学ぶ(10-3)RNNの実装(Self-Attention(可視化)) Self-Attention
3. 損失関数
3.1 mean_squared_error
回帰分析時の損失関数
E = \frac{1}{2}\sum_k(y_k-t_k)^2
(参考)
ディープラーニングを実装から学ぶ(3)学習(勾配降下法) 二乗和誤差
3.2 cross_entropy_error
2値分類、多値分類時の損失関数
(2値分類)
E= -t\log{y} + (1-t)\log{(1-y)}
(多値分類)
E= -\sum_kt_k\log{y_k}
(参考)
ディープラーニングを実装から学ぶ(3)学習(勾配降下法) 交差エントロピー誤差
4. 正則化
4.1 早期終了
早期終了
(参考)
ディープラーニングを実装から学ぶ(6-1)学習手法(正則化) 早期終了
4.2 重み減衰
4.2.1 L1ノルム
\tilde{E} = E + \lambda\sum_{k}\sum_{i}\sum_{j}|w_{ij}^{(k)}|
(参考)
ディープラーニングを実装から学ぶ(6-1)学習手法(正則化) L1ノルム
4.2.2 L2ノルム
\tilde{E} = E + \frac{\lambda}{2}\sum_{k}\sum_{i}\sum_{j}(w_{ij}^{(k)})^2
(参考)
ディープラーニングを実装から学ぶ(6-1)学習手法(正則化) L2ノルム
4.3 ドロップアウト
ドロップアウト
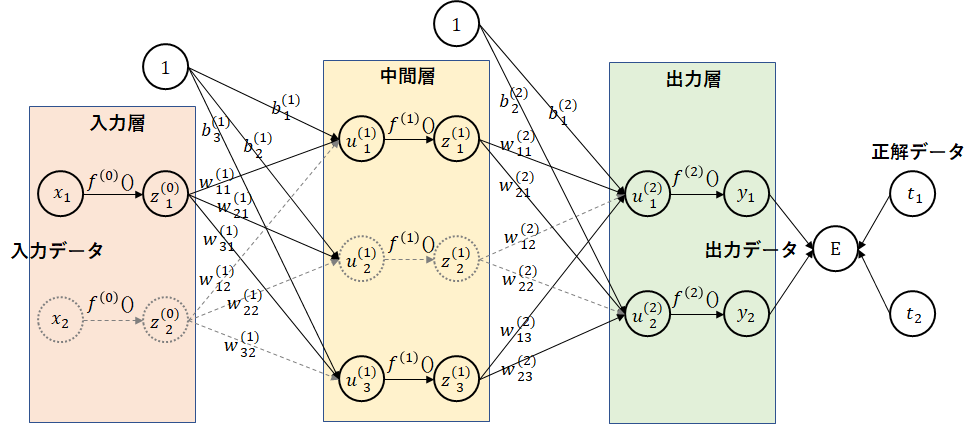
(参考)
ディープラーニングを実装から学ぶ(6-1)学習手法(正則化) ドロップアウト
4.4 バッチ正規化
バッチ正規化
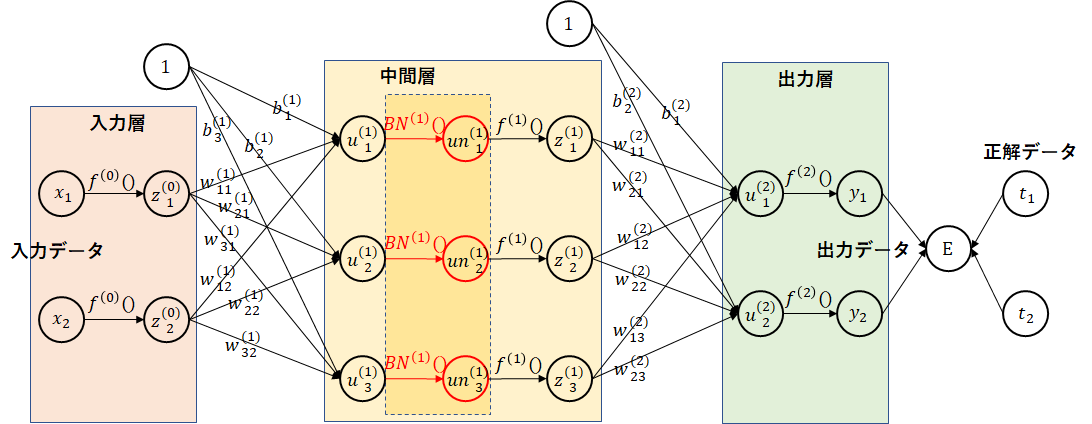
(参考)
ディープラーニングを実装から学ぶ(6-1)学習手法(正則化) バッチ正規化
4.5 ドロップコネクト
ドロップコネクト
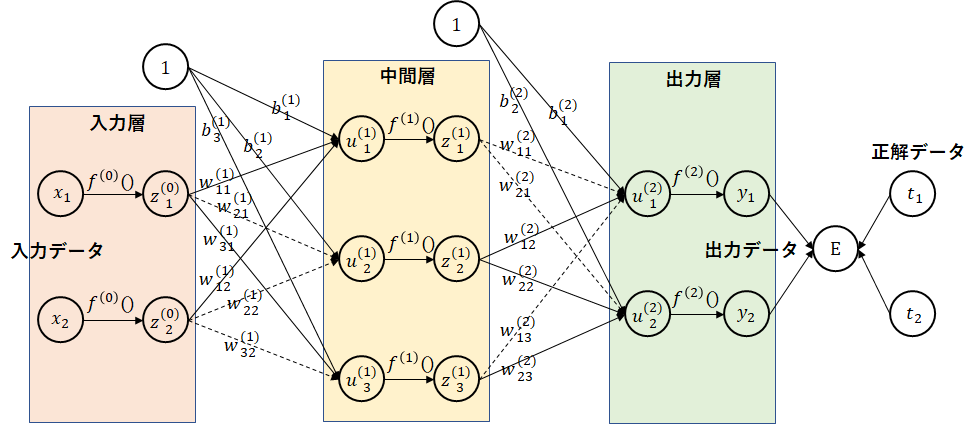
(参考)
ディープラーニングを実装から学ぶ(7-3)ドロップコネクト・宝くじ仮説 ドロップコネクト
5. 正則化
5.1 SGD
w_{k+1} = w_k - \eta E^{'}(w_k)
(参考)
ディープラーニングを実装から学ぶ(6-2)学習手法(最適化) SGD
5.2 Momentum
\begin{align}
v_{k+1} &= \mu v_k - \eta E^{'}(w_k), v_0 = 0\\
w_{k+1} &= w_k + v_{k+1}
\end{align}
(参考)
ディープラーニングを実装から学ぶ(6-2)学習手法(最適化) Momentum
5.3 Nesterovの加速勾配法
\begin{align}
v_{k+1} &= \mu v_k - \eta E^{'}(w_k + \mu v_k), v_0 = 0\\
w_{k+1} &= w_k + v_{k+1}
\end{align}
(参考)
ディープラーニングを実装から学ぶ(6-2)学習手法(最適化) Nesterovの加速勾配法
ディープラーニングを実装から学ぶ(8-3)h-swish,TanhExp,Flooding,Nesterov Nesterovの加速勾配法
5.4 AdaGrad
\begin{align}
g_{k+1} &= g_k + (E^{'}(w_k))^2, g_0 = 0\\
w_{k+1} &= w_k - \frac{\eta}{\sqrt{g_{k+1}}} E^{'}(w_k)
\end{align}
(参考)
ディープラーニングを実装から学ぶ(6-2)学習手法(最適化) AdaGrad
5.5 RMSProp
\begin{align}
g_{k+1} &= \gamma g_k + (1 - \gamma)(E^{'}(w_k))^2, g_0 = 0\\
w_{k+1} &= w_k - \frac{\eta}{\sqrt{g_{k+1}}} E^{'}(w_k)
\end{align}
(参考)
ディープラーニングを実装から学ぶ(6-2)学習手法(最適化) RMSProp
5.6 Adadelta
\begin{align}
g_{k+1} &= \gamma g_k + (1 - \gamma)(E^{'}(w_k))^2, g_0 = 0\\
w_{k+1} &= w_k - \frac{\eta \sqrt{s_k}}{\sqrt{g_{k+1}}} E^{'}(w_k)\\
s_{k+1} &= \gamma s_k + (1 - \gamma)(w_{k+1} - w_k)^2, s_0=0
\end{align}
(参考)
ディープラーニングを実装から学ぶ(6-2)学習手法(最適化) Adadelta
5.7 Adam
\begin{align}
m_{k+1} &= \beta_1 m_k + (1 - \beta_1)E^{'}(w_k),m_0 = 0\\
v_{k+1} &= \beta_2 v_k + (1 - \beta_2)(E^{'}(w_k))^2,v_0 = 0\\
\hat{m}_k &= \frac{m_k}{1 - \beta_1^k}\\
\hat{v}_k &= \frac{v_k}{1 - \beta_2^k}\\
w_{k+1} &= w_k - \frac{\eta \hat{m}_{k+1}}{\sqrt{\hat{v}_{k+1}}}
\end{align}
(参考)
ディープラーニングを実装から学ぶ(6-2)学習手法(最適化) Adam
6.重み・バイアスの初期値
6.1 LeCunの初期化
平均を 0 、標準偏差を $ \frac{1}{\sqrt{d^{(l-1)}}} $とする正規分布、または、$ -\sqrt{\frac{3}{d^{(l-1)}}} $~$ \sqrt{\frac{3}{d^{(l-1)}}} $の一様分布
(参考)
ディープラーニングを実装から学ぶ(2)ニューラルネットワーク LeCunの初期化
6.2 Glorotの初期化
平均を 0 、標準偏差を $ \sqrt{\frac{2}{d^{(l-1)}+d^{(l)}}} $とする正規分布、または、$ -\sqrt{\frac{6}{d^{(l-1)}+d^{(l)}}} $~$ \sqrt{\frac{6}{d^{(l-1)}+d^{(l)}}} $の一様分布
(参考)
ディープラーニングを実装から学ぶ(2)ニューラルネットワーク Glorotの初期化
6.3 Heの初期化
平均を 0 、標準偏差を $ \sqrt{\frac{2}{d^{(l-1)}}} $とする正規分布、または、$ -\sqrt{\frac{6}{d^{(l-1)}}} $~$ \sqrt{\frac{6}{d^{(l-1)}}} $の一様分布
(参考)
ディープラーニングを実装から学ぶ(2)ニューラルネットワーク Heの初期化
6.4 orthogonal
直交行列を用いた初期化
(参考)
ディープラーニングを実装から学ぶ(10-2)RNNの実装(双方向RNN・orthogonal(重みの初期値)) orthogonal(重みの初期値)
7. その他
7.1 データ拡張
画像の水増し
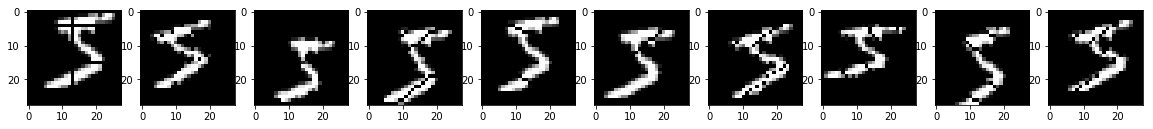
(参考)
ディープラーニングを実装から学ぶ(7-2)データ拡張
7.2 宝くじ仮説
重みの値の小さい接続をマスク
(参考)
ディープラーニングを実装から学ぶ(7-3)ドロップコネクト・宝くじ仮説 宝くじ仮説
7.3 Flooding
損失関数の値を一定の値以上にキープし、さらに学習を進めようとする。
(参考)
ディープラーニングを実装から学ぶ(8-3)h-swish,TanhExp,Flooding,Nesterov Flooding
参考
ネットワーク図の書き方
f(x) = ax^2 + bx +c
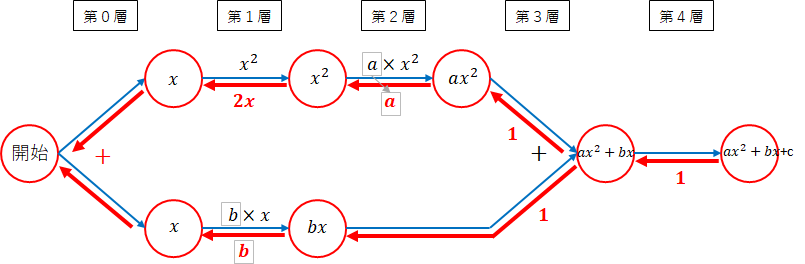
** 法則1:勾配は、ネットワークの各線の勾配の積となる。**
** 法則2:分岐の場合は、それぞれの勾配の和となる。**
** 法則3:複雑な関数は分解し、法則1、法則2を利用し勾配を求める。**
** ($ + $定数):定数を加えた場合の勾配 $ = 1 $**
** ($ \times $定数):定数を掛けた場合の勾配 $ = $定数**
** ($ \sum $):$ \sum $の勾配 $ = 1 $**
** ($ \times $):2つの変数の掛け算の勾配は、それぞれ逆の変数となる**
** (関数):関数の勾配は、数学の力を借りる**