今回は、ドロップコネクト、宝くじ仮説について確認します。
順番は、前後しますが、「ディープラーニングを実装から学ぶ(8)実装変更」のプログラムを利用します。
【2020/5/25改版】
逆伝播の実装に誤りがありました。
ドロップコネクトについて実装を変更するとともに、結果および考察を改めます。
【2020/5/26改版】
ドロップアウト・ドロップコネクト実装変更追加
【2020/5/31改版】
宝くじ仮説について逆伝播の実装を変更しました。結果および考察を変更しました。
結果について、大きな差はありませんでしたが、ご迷惑をおかけしました。
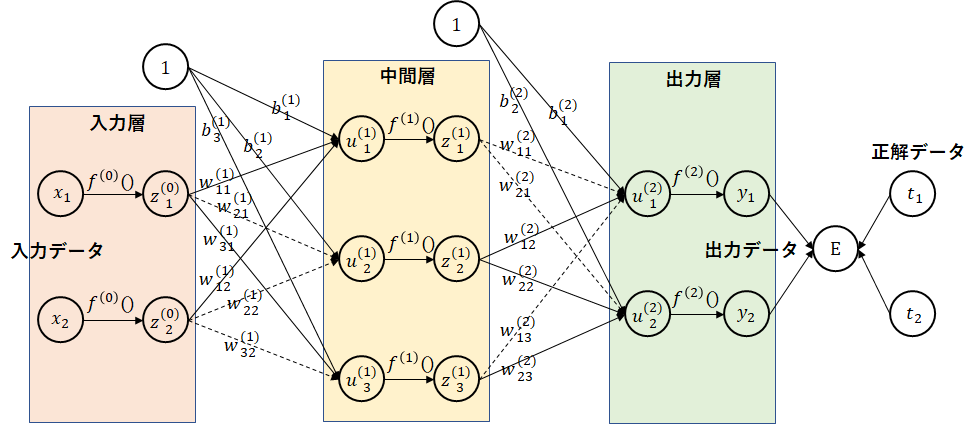
ドロップコネクト
ドロップアウトと異なり、ノード間の結合を一定の割合で断ち切ります。
実装
「ディープラーニングを実装から学ぶ(8)実装変更」のプログラムをベースに変更します。
順伝播
順伝播は、全結合時にdrop_connect_ratioで指定した割合のデータのみ結合するようにします。
set_drop_connect_maskで、ランダムに結合を決定します。
def set_drop_connect_mask(d, dropout_ratio):
mask = np.zeros(d)
mask = mask.flatten()
size = mask.shape[0]
mask_idx = np.random.choice(size, round(dropout_ratio*size), replace=False) # 通すindexの配列
mask[mask_idx] = 1
mask = mask.reshape(d)
return mask
ネットワーク図を描きます。
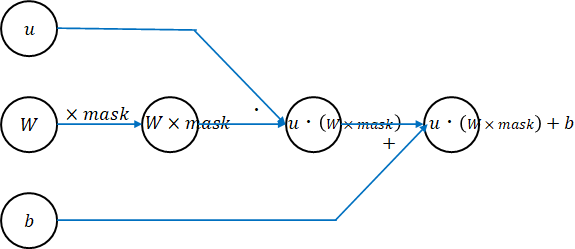
affine_propagationで、set_drop_connect_maskで決定したmaskを掛けることにより、結合されていない重みは0とします。予測時には、drop_connect_ratioを掛けます。
def affine_propagation(func, u, weights, weight_decay, learn_flag, drop_connect_ratio=None, **params):
# drop connect対応
drop_connect_mask = None
if drop_connect_ratio is not None:
if learn_flag: # 学習時
drop_connect_mask = set_drop_connect_mask( weights["W"].shape, drop_connect_ratio)
z = func(u, weights["W"] * drop_connect_mask, weights["b"])
else: # 予測時
z = func(u, weights["W"] * drop_connect_ratio, weights["b"])
else:
z = func(u, weights["W"], weights["b"])
# 重み減衰対応
weight_decay_r = 0
if weight_decay is not None:
weight_decay_r = weight_decay["func"](W, **weight_decay["params"])
return {"u":u, "z":z, "drop_connect_mask":drop_connect_mask}, weight_decay_r
逆伝播
ネットワーク図から勾配を計算します。勾配を赤字で書きました。後ろから順に掛けていけばよいのでした。
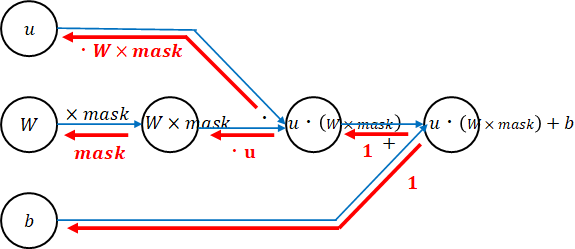
def affine_back_propagation(back_func, dz, us, weights, weight_decay, calc_du_flag, **params):
if us["drop_connect_mask"] is not None:
# drop connect対応
du, dW, db = back_func(dz, us["u"], weights["W"] * us["drop_connect_mask"], weights["b"], calc_du_flag)
dW = dW * us["drop_connect_mask"]
else:
du, dW, db = back_func(dz, us["u"], weights["W"], weights["b"], calc_du_flag)
# 重み減衰対応
if weight_decay is not None:
dW = dW + weight_decay["back_func"](weights["W"], **weight_decay["params"])
return {"du":du, "dW":dW, "db":db}
【2020/5/25改版】逆伝播の実装不正修正
あとは、初期化関数にパラメータを追加しておきます。
# affine
def affine_init_layer(d_prev, d, weight_init_func=he_normal, weight_init_params={}, bias_init_func=zeros_b, bias_init_params={}, drop_connect_ratio=None):
W = weight_init_func(d_prev, d, **weight_init_params)
b = bias_init_func(d, **bias_init_params)
return d, {"W":W, "b":b}
実行
入力層と一つ目の中間層の間の結合とその他の結合でドロップコネクト率を変更して確認します。
learn_info = {}
in_drop_connect_ratios = [1.0,0.9,0.8,0.7,0.6,0.5]
md_drop_connect_ratios = [1.0,0.9,0.8,0.7,0.6,0.5]
for in_drop_connect_ratio in in_drop_connect_ratios:
for md_drop_connect_ratio in md_drop_connect_ratios:
name = "in_drop_connect_ratio=" + str(in_drop_connect_ratio) + " md_drop_connect_ratio=" + str(md_drop_connect_ratio)
print(name)
model = create_model(nx_train.shape[1]) # 28*28
model = add_layer(model, "affine1", affine, 100, drop_connect_ratio=in_drop_connect_ratio)
model = add_layer(model, "relu1", relu)
model = add_layer(model, "affine2", affine, 50, drop_connect_ratio=md_drop_connect_ratio)
model = add_layer(model, "relu2", relu)
model = add_layer(model, "affine3", affine, 10, drop_connect_ratio=md_drop_connect_ratio)
model = set_output(model, softmax)
model = set_error(model, cross_entropy_error)
epoch = 50
batch_size = 100
np.random.seed(10)
model, optimizer, learn_info[name] = learn(model, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch)
実行結果
入力層からのドロップコネクト率を1.0~0.5、中間層からのドロップコネクト率を1.0~0.5に変化させ確認しました。
テスト正解率が98%を超えた場合は、太字にしています。
参考までに、ドロップアウトの場合(DOテスト正解、DOテスト最大)も表に載せます。
概ねドロップアウトと同等かそれ以上の精度が出ました。ドロップコネクトもドロップアウト相当の効果があると言えます。
| 入力層率 | 中間層率 | 学習正解 | テスト正解 | テスト最大 | DOテスト正解 | DOテスト最大 |
|---|---|---|---|---|---|---|
| 1.0 | 1.0 | 100.00 | 97.78 | 97.94 | 97.89 | 98.00 |
| 1.0 | 0.9 | 99.55 | 98.07 | 98.07 | 97.99 | 98.11 |
| 1.0 | 0.8 | 99.41 | 97.96 | 98.13 | 98.10 | 98.10 |
| 1.0 | 0.7 | 98.94 | 98.00 | 98.06 | 97.80 | 97.80 |
| 1.0 | 0.6 | 98.37 | 97.84 | 97.90 | 97.48 | 97.67 |
| 1.0 | 0.5 | 97.59 | 97.57 | 97.70 | 96.96 | 97.09 |
| 0.9 | 1.0 | 99.50 | 98.01 | 98.09 | 98.11 | 98.26 |
| 0.9 | 0.9 | 99.03 | 98.24 | 98.24 | 98.18 | 98.25 |
| 0.9 | 0.8 | 98.76 | 98.08 | 98.14 | 97.98 | 98.05 |
| 0.9 | 0.7 | 98.38 | 98.00 | 98.02 | 97.71 | 97.86 |
| 0.9 | 0.6 | 97.78 | 97.76 | 97.94 | 97.48 | 97.57 |
| 0.9 | 0.5 | 97.04 | 97.69 | 97.69 | 97.08 | 97.17 |
| 0.8 | 1.0 | 99.17 | 98.26 | 98.34 | 98.25 | 98.38 |
| 0.8 | 0.9 | 98.63 | 98.17 | 98.21 | 98.27 | 98.27 |
| 0.8 | 0.8 | 98.34 | 98.12 | 98.15 | 97.92 | 97.99 |
| 0.8 | 0.7 | 97.87 | 97.97 | 98.05 | 97.74 | 97.78 |
| 0.8 | 0.6 | 97.35 | 97.88 | 97.89 | 97.34 | 97.49 |
| 0.8 | 0.5 | 96.48 | 97.54 | 97.60 | 96.86 | 96.95 |
| 0.7 | 1.0 | 98.71 | 98.24 | 98.38 | 98.32 | 98.42 |
| 0.7 | 0.9 | 98.22 | 98.19 | 98.23 | 98.13 | 98.20 |
| 0.7 | 0.8 | 97.83 | 98.02 | 98.08 | 97.77 | 97.80 |
| 0.7 | 0.7 | 97.48 | 97.94 | 97.99 | 97.51 | 97.60 |
| 0.7 | 0.6 | 96.83 | 97.74 | 97.77 | 97.34 | 97.34 |
| 0.7 | 0.5 | 96.09 | 97.44 | 97.44 | 96.78 | 96.79 |
| 0.6 | 1.0 | 98.33 | 98.30 | 98.30 | 98.15 | 98.54 |
| 0.6 | 0.9 | 97.73 | 98.15 | 98.18 | 98.15 | 98.15 |
| 0.6 | 0.8 | 97.44 | 97.84 | 97.87 | 97.50 | 97.65 |
| 0.6 | 0.7 | 97.05 | 97.74 | 97.74 | 97.24 | 97.36 |
| 0.6 | 0.6 | 96.28 | 97.56 | 97.58 | 97.01 | 97.08 |
| 0.6 | 0.5 | 95.44 | 97.04 | 97.19 | 96.46 | 96.63 |
| 0.5 | 1.0 | 97.82 | 98.12 | 98.13 | 98.09 | 98.37 |
| 0.5 | 0.9 | 97.06 | 97.90 | 97.91 | 97.87 | 97.92 |
| 0.5 | 0.8 | 96.80 | 97.72 | 97.79 | 97.16 | 97.39 |
| 0.5 | 0.7 | 96.30 | 97.49 | 97.52 | 96.91 | 97.10 |
| 0.5 | 0.6 | 95.68 | 97.29 | 97.34 | 96.46 | 96.64 |
| 0.5 | 0.5 | 94.61 | 96.71 | 96.89 | 95.95 | 96.12 |
入力層が1.0,0.9の場合の正解率グラフです。
入力層のドロップコネクト率: 1.0
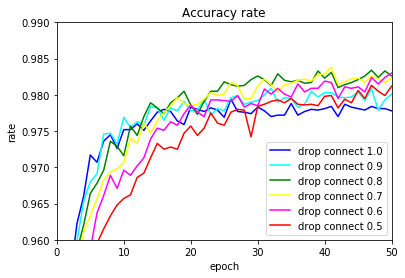
入力層のドロップコネクト率: 0.9
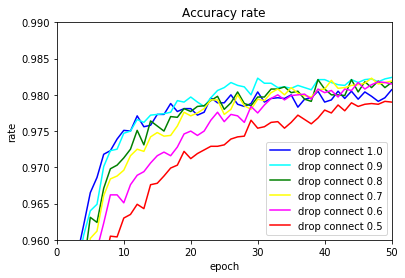
ドロップコネクトも使えそうです。
ドロップアウト・ドロップコネクト実装変更
【2020/5/26 追加】
ドロップアウト・ドロップコネクトの学習時と予測時の重みへの重みづけに関して別の方法で試してみたいと思います。
今までは、例えば、ドロップアウト率が0.8の場合は、予測時に重みを0.8倍していました。これは、学習時にはドロップアウトした80%の重みを利用して計算しているため、学習時に全部の重みを用いて計算する場合、予測値が大きな値になることを防ぐためです。
今後は、逆に学習時に0.8で割りことにより、予測時には重みづけることなく予測を行います。
具体的にみてみましょう。
今までは、予測時にdropout_ratioを掛けていました。
if learn_flag:
dropout_mask = set_dropout_mask(u[-1].shape, dropout_ratio)
z = func(u, dropout_mask)
else:
z = u * dropout_ratio
今後は、学習時にdropout_ratioで割ります。
if learn_flag:
dropout_mask = set_dropout_mask(u[-1].shape, dropout_ratio)
z = func(u, dropout_mask / dropout_ratio)
else:
z = u
同様の処理をドロップコネクトについても行います。
ドロップアウト
実装変更
ドロップアウトの順伝播、逆伝播部分の実装です。
# dropout
def dropout_propagation(func, u, weights, weight_decay, learn_flag, dropout_ratio=0.9):
dropout_mask = None
if learn_flag:
dropout_mask = set_dropout_mask(u[-1].shape, dropout_ratio)
z = func(u, dropout_mask / dropout_ratio)
else:
z = u
return {"u":u, "z":z, "dropout_mask":dropout_mask}, 0
def dropout_back_propagation(back_func, dz, us, weights, weight_decay, calc_du_flag, dropout_ratio=0.9):
du = back_func(dz, us["dropout_mask"] / dropout_ratio)
return {"du":du}
結果
現状の結果と実装変更後の結果を示します。
実装変更前の学習結果 - 学習正解、テスト正解、テスト最大
実装変更後の学習結果 - 新学習正解、新テスト正解、新テスト最大
| 入力層率 | 中間層率 | 学習正解 | テスト正解 | テスト最大 | 新学習正解 | 新テスト正解 | 新テスト最大 |
|---|---|---|---|---|---|---|---|
| 1.0 | 1.0 | 100.00 | 97.89 | 98.00 | 100.00 | 97.89 | 98.00 |
| 1.0 | 0.9 | 99.17 | 97.99 | 98.11 | 99.20 | 97.83 | 98.00 |
| 1.0 | 0.8 | 98.34 | 98.10 | 98.10 | 98.57 | 97.88 | 98.03 |
| 1.0 | 0.7 | 97.57 | 97.80 | 97.80 | 97.73 | 97.58 | 97.77 |
| 1.0 | 0.6 | 96.42 | 97.48 | 97.67 | 96.82 | 97.51 | 97.56 |
| 1.0 | 0.5 | 95.00 | 96.96 | 97.09 | 95.29 | 97.17 | 97.23 |
| 0.9 | 1.0 | 99.46 | 98.11 | 98.26 | 99.45 | 98.17 | 98.33 |
| 0.9 | 0.9 | 98.51 | 98.18 | 98.25 | 98.59 | 98.11 | 98.19 |
| 0.9 | 0.8 | 97.72 | 97.98 | 98.05 | 97.74 | 97.98 | 98.13 |
| 0.9 | 0.7 | 96.84 | 97.71 | 97.86 | 97.00 | 97.85 | 97.85 |
| 0.9 | 0.6 | 95.59 | 97.48 | 97.57 | 95.88 | 97.59 | 97.66 |
| 0.9 | 0.5 | 94.07 | 97.08 | 97.17 | 94.13 | 96.88 | 97.12 |
| 0.8 | 1.0 | 98.98 | 98.25 | 98.38 | 99.06 | 98.14 | 98.37 |
| 0.8 | 0.9 | 97.85 | 98.27 | 98.27 | 97.92 | 98.18 | 98.28 |
| 0.8 | 0.8 | 97.09 | 97.92 | 97.99 | 97.22 | 97.98 | 98.02 |
| 0.8 | 0.7 | 96.25 | 97.74 | 97.78 | 96.23 | 97.57 | 97.82 |
| 0.8 | 0.6 | 94.94 | 97.34 | 97.49 | 95.09 | 97.44 | 97.57 |
| 0.8 | 0.5 | 93.32 | 96.86 | 96.95 | 93.24 | 97.04 | 97.04 |
| 0.7 | 1.0 | 98.49 | 98.32 | 98.42 | 98.51 | 98.38 | 98.47 |
| 0.7 | 0.9 | 97.23 | 98.13 | 98.20 | 97.39 | 98.19 | 98.34 |
| 0.7 | 0.8 | 96.44 | 97.77 | 97.80 | 96.54 | 97.83 | 97.92 |
| 0.7 | 0.7 | 95.41 | 97.51 | 97.60 | 95.55 | 97.51 | 97.63 |
| 0.7 | 0.6 | 94.21 | 97.34 | 97.34 | 94.22 | 97.26 | 97.40 |
| 0.7 | 0.5 | 92.25 | 96.78 | 96.79 | 92.54 | 96.72 | 96.94 |
| 0.6 | 1.0 | 97.85 | 98.15 | 98.54 | 97.90 | 98.32 | 98.33 |
| 0.6 | 0.9 | 96.54 | 98.15 | 98.15 | 96.73 | 97.92 | 98.12 |
| 0.6 | 0.8 | 95.60 | 97.50 | 97.65 | 95.85 | 97.76 | 97.76 |
| 0.6 | 0.7 | 94.46 | 97.24 | 97.36 | 94.67 | 97.44 | 97.51 |
| 0.6 | 0.6 | 93.18 | 97.01 | 97.08 | 93.40 | 97.12 | 97.18 |
| 0.6 | 0.5 | 91.38 | 96.46 | 96.63 | 91.42 | 96.46 | 96.53 |
| 0.5 | 1.0 | 96.90 | 98.09 | 98.37 | 97.12 | 97.99 | 98.25 |
| 0.5 | 0.9 | 95.75 | 97.87 | 97.92 | 95.80 | 97.61 | 97.92 |
| 0.5 | 0.8 | 94.55 | 97.16 | 97.39 | 94.65 | 97.38 | 97.53 |
| 0.5 | 0.7 | 93.32 | 96.91 | 97.10 | 93.53 | 96.97 | 97.11 |
| 0.5 | 0.6 | 91.86 | 96.46 | 96.64 | 92.06 | 96.71 | 96.97 |
| 0.5 | 0.5 | 89.69 | 95.95 | 96.12 | 89.94 | 96.16 | 96.16 |
ほぼ同程度の精度になりました。
ドロップアウト率が大きい場合は既存の方が良い傾向にあります。逆にドロップアウト率が小さいと新しい実装が良い傾向にあります。
ドロップコネクト
実装変更
ドロップコネクトの順伝播、逆伝播部分の実装です。
def affine_propagation(func, u, weights, weight_decay, learn_flag, drop_connect_ratio=None, **params):
# drop connect対応
drop_connect_mask = None
if drop_connect_ratio is not None:
if learn_flag: # 学習時
drop_connect_mask = set_drop_connect_mask( weights["W"].shape, drop_connect_ratio)
z = func(u, weights["W"] * drop_connect_mask / drop_connect_ratio, weights["b"])
else: # 予測時
z = func(u, weights["W"], weights["b"])
else:
z = func(u, weights["W"], weights["b"])
# 重み減衰対応
weight_decay_r = 0
if weight_decay is not None:
weight_decay_r = weight_decay["func"](W, **weight_decay["params"])
return {"u":u, "z":z, "drop_connect_mask":drop_connect_mask}, weight_decay_r
def affine_back_propagation(back_func, dz, us, weights, weight_decay, calc_du_flag, drop_connect_ratio=None, **params):
if us["drop_connect_mask"] is not None:
du, dW, db = back_func(dz, us["u"], weights["W"] * us["drop_connect_mask"] / drop_connect_ratio, weights["b"], calc_du_flag)
dW = dW * us["drop_connect_mask"] / drop_connect_ratio
else:
du, dW, db = back_func(dz, us["u"], weights["W"], weights["b"], calc_du_flag)
# 重み減衰対応
if weight_decay is not None:
dW = dW + weight_decay["back_func"](weights["W"], **weight_decay["params"])
return {"du":du, "dW":dW, "db":db}
結果
現状の結果と実装変更後の結果を示します。
実装変更前の学習結果 - 学習正解、テスト正解、テスト最大
実装変更後の学習結果 - 新学習正解、新テスト正解、新テスト最大
| 入力層率 | 中間層率 | 学習正解 | テスト正解 | テスト最大 | 新学習正解 | 新テスト正解 | 新テスト最大 |
|---|---|---|---|---|---|---|---|
| 1.0 | 1.0 | 100.00 | 97.78 | 97.94 | 100.00 | 97.78 | 97.94 |
| 1.0 | 0.9 | 99.55 | 98.07 | 98.07 | 99.62 | 97.94 | 98.09 |
| 1.0 | 0.8 | 99.41 | 97.96 | 98.13 | 99.48 | 98.15 | 98.15 |
| 1.0 | 0.7 | 98.94 | 98.00 | 98.06 | 99.27 | 97.94 | 97.99 |
| 1.0 | 0.6 | 98.37 | 97.84 | 97.90 | 98.95 | 97.82 | 97.91 |
| 1.0 | 0.5 | 97.59 | 97.57 | 97.70 | 98.28 | 97.43 | 97.51 |
| 0.9 | 1.0 | 99.50 | 98.01 | 98.09 | 99.57 | 98.08 | 98.13 |
| 0.9 | 0.9 | 99.03 | 98.24 | 98.24 | 99.16 | 98.06 | 98.15 |
| 0.9 | 0.8 | 98.76 | 98.08 | 98.14 | 98.88 | 98.32 | 98.32 |
| 0.9 | 0.7 | 98.38 | 98.00 | 98.02 | 98.66 | 97.95 | 98.04 |
| 0.9 | 0.6 | 97.78 | 97.76 | 97.94 | 98.27 | 97.83 | 97.88 |
| 0.9 | 0.5 | 97.04 | 97.69 | 97.69 | 97.55 | 97.53 | 97.73 |
| 0.8 | 1.0 | 99.17 | 98.26 | 98.34 | 99.18 | 98.12 | 98.32 |
| 0.8 | 0.9 | 98.63 | 98.17 | 98.21 | 98.75 | 98.17 | 98.27 |
| 0.8 | 0.8 | 98.34 | 98.12 | 98.15 | 98.41 | 98.40 | 98.40 |
| 0.8 | 0.7 | 97.87 | 97.97 | 98.05 | 98.13 | 98.22 | 98.22 |
| 0.8 | 0.6 | 97.35 | 97.88 | 97.89 | 97.75 | 97.98 | 97.98 |
| 0.8 | 0.5 | 96.48 | 97.54 | 97.60 | 96.88 | 97.54 | 97.60 |
| 0.7 | 1.0 | 98.71 | 98.24 | 98.38 | 98.86 | 98.25 | 98.45 |
| 0.7 | 0.9 | 98.22 | 98.19 | 98.23 | 98.35 | 98.27 | 98.36 |
| 0.7 | 0.8 | 97.83 | 98.02 | 98.08 | 97.95 | 98.18 | 98.21 |
| 0.7 | 0.7 | 97.48 | 97.94 | 97.99 | 97.66 | 97.94 | 98.12 |
| 0.7 | 0.6 | 96.83 | 97.74 | 97.77 | 97.22 | 97.84 | 97.84 |
| 0.7 | 0.5 | 96.09 | 97.44 | 97.44 | 96.18 | 97.35 | 97.46 |
| 0.6 | 1.0 | 98.33 | 98.30 | 98.30 | 98.37 | 98.08 | 98.27 |
| 0.6 | 0.9 | 97.73 | 98.15 | 98.18 | 97.74 | 98.17 | 98.23 |
| 0.6 | 0.8 | 97.44 | 97.84 | 97.87 | 97.41 | 98.08 | 98.08 |
| 0.6 | 0.7 | 97.05 | 97.74 | 97.74 | 97.14 | 97.93 | 97.93 |
| 0.6 | 0.6 | 96.28 | 97.56 | 97.58 | 96.63 | 97.52 | 97.68 |
| 0.6 | 0.5 | 95.44 | 97.04 | 97.19 | 95.56 | 97.22 | 97.38 |
| 0.5 | 1.0 | 97.82 | 98.12 | 98.13 | 97.93 | 98.08 | 98.12 |
| 0.5 | 0.9 | 97.06 | 97.90 | 97.91 | 97.22 | 98.01 | 98.03 |
| 0.5 | 0.8 | 96.80 | 97.72 | 97.79 | 96.90 | 97.80 | 97.94 |
| 0.5 | 0.7 | 96.30 | 97.49 | 97.52 | 96.50 | 97.50 | 97.72 |
| 0.5 | 0.6 | 95.68 | 97.29 | 97.34 | 95.90 | 97.24 | 97.34 |
| 0.5 | 0.5 | 94.61 | 96.71 | 96.89 | 94.76 | 96.95 | 97.04 |
ドロップアウト同様に、ほぼ同程度の精度になりました。
ドロップアウト率が大きい場合は既存の方が良い傾向にあります。逆にドロップアウト率が小さいと新しい実装が良い傾向にあります。
宝くじ仮説
考え方は、ドロップコネクトと同じですが、ランダムに接続をマスクするのではなく、重みの値の小さい接続をマスクします。
実装
全結合時に、マスクを設定し、結合をマスクします。drop_maskをパラメータに追加します。
ドロップコネクトでは、順伝播時に、重みをドロップコネクト率で割って学習時と予測時の重みの数の違いを吸収していました。宝くじ仮説では、基本的に重みの小さな値を無視するためこの調整は行いません。また、学習時、予測時とも同じマスクを使うため学習時と予測時での差異はありません。
def affine_propagation(func, u, weights, weight_decay, learn_flag, drop_connect_ratio=None, drop_mask=None, **params):
drop_connect_mask = None
# 宝くじ仮説対応
if drop_mask is not None:
z = func(u, weights["W"] * drop_mask, weights["b"])
# drop connect対応
elif drop_connect_ratio is not None:
if learn_flag: # 学習時
drop_connect_mask = set_drop_connect_mask( weights["W"].shape, drop_connect_ratio)
z = func(u, weights["W"] * drop_connect_mask / drop_connect_ratio, weights["b"])
else: # 予測時
z = func(u, weights["W"], weights["b"])
else:
z = func(u, weights["W"], weights["b"])
# 重み減衰対応
weight_decay_r = 0
if weight_decay is not None:
weight_decay_r = weight_decay["func"](W, **weight_decay["params"])
return {"u":u, "z":z, "drop_connect_mask":drop_connect_mask, "drop_mask":drop_mask}, weight_decay_r
def affine_back_propagation(back_func, dz, us, weights, weight_decay, calc_du_flag, **params):
# 宝くじ仮説対応
if us["drop_mask"] is not None:
du, dW, db = back_func(dz, us["u"], weights["W"] * us["drop_mask"], weights["b"], calc_du_flag)
dW = dW * us["drop_mask"]
# drop connect対応
elif us["drop_connect_mask"] is not None:
du, dW, db = back_func(dz, us["u"], weights["W"] * us["drop_connect_mask"] / drop_connect_ratio, weights["b"], calc_du_flag)
dW = dW * us["drop_connect_mask"] / drop_connect_ratio
else:
du, dW, db = back_func(dz, us["u"], weights["W"], weights["b"], calc_du_flag)
# 重み減衰対応
if weight_decay is not None:
dW = dW + weight_decay["back_func"](weights["W"], **weight_decay["params"])
return {"du":du, "dW":dW, "db":db}
# affine
def affine_init_layer(d_prev, d, weight_init_func=he_normal, weight_init_params={}, bias_init_func=zeros_b, bias_init_params={}, drop_connect_ratio=None, drop_mask=None):
W = weight_init_func(d_prev, d, **weight_init_params)
b = bias_init_func(d, **bias_init_params)
return d, {"W":W, "b":b}
【2020/5/31改版】逆伝播の実装不正修正
実行
マスクする重みを確認するタイミングにより確認します。
(1) 重みの初期化直後
(2) 一度学習後
モデルから重みを取得する関数を用意しておきます。
def getWeight(model, name, weight):
return model['layer'][name]['weights'][weight]
重みの初期化直後
いつものモデルを作成し、モデルを初期化します。
# モデル作成
model_init = create_model(nx_train.shape[1]) # 28*28
model_init = add_layer(model_init, "affine1", affine, 100)
model_init = add_layer(model_init, "relu1", relu)
model_init = add_layer(model_init, "affine2", affine, 50)
model_init = add_layer(model_init, "relu2", relu)
model_init = add_layer(model_init, "affine3", affine, 10)
model_init = set_output(model_init, softmax)
model_init = set_error(model_init, cross_entropy_error)
# 重みの初期化
np.random.seed(10)
model_init = init_model(model_init)
重みの分布を確認します。
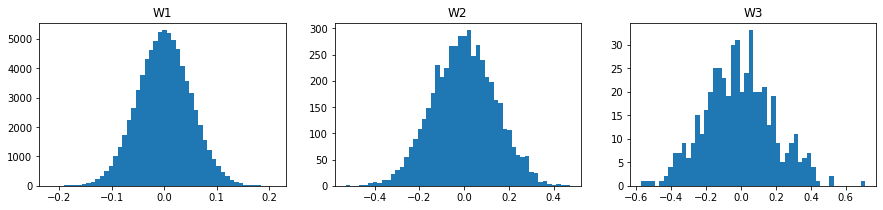
重みの絶対値が0.01~0.10以下まで、0.01ごとに個数を確認します。
# 重みの取得
W1 = getWeight(model_init, "affine1", "W")
W2 = getWeight(model_init, "affine2", "W")
W3 = getWeight(model_init, "affine3", "W")
# 重みのカットラインを0.00~0.10まで0.01刻みで確認
for i in range(11):
print(i*0.01)
print("W1 ",((W1<i*0.01) & (W1>i*-0.01)).sum(), ((W1<i*0.01) & (W1>i*-0.01)).sum()/(784*100))
print("W2 ",((W2<i*0.01) & (W2>i*-0.01)).sum(), ((W2<i*0.01) & (W2>i*-0.01)).sum()/(100*50))
print("W3 ",((W3<i*0.01) & (W3>i*-0.01)).sum(), ((W3<i*0.01) & (W3>i*-0.01)).sum()/(50*10))
カットされる各層の重みの個数、割合です。
| カットライン | W1個数 | W1割合 | W2個数 | W2割合 | W3個数 | W3割合 |
|---|---|---|---|---|---|---|
| 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 |
| 0.01 | 12354 | 15.76 | 283 | 5.66 | 22 | 4.40 |
| 0.02 | 24106 | 30.75 | 587 | 11.74 | 37 | 7.40 |
| 0.03 | 35145 | 44.83 | 863 | 17.26 | 60 | 12.00 |
| 0.04 | 44823 | 57.17 | 1133 | 22.66 | 78 | 15.60 |
| 0.05 | 53086 | 67.71 | 1375 | 27.50 | 101 | 20.20 |
| 0.06 | 60001 | 76.53 | 1635 | 32.70 | 128 | 25.60 |
| 0.07 | 65497 | 83.54 | 1914 | 38.28 | 148 | 29.60 |
| 0.08 | 69556 | 88.72 | 2159 | 43.18 | 161 | 32.20 |
| 0.09 | 72545 | 92.53 | 2380 | 47.60 | 177 | 35.40 |
| 0.10 | 74651 | 95.22 | 2597 | 51.94 | 199 | 39.80 |
中央値は、W1が、0.034、W2が、0.096、W3が0.131程度でした。
np.median(np.abs(W1)),np.median(np.abs(W2)),np.median(np.abs(W3))
(0.034020809693469864, 0.09577020500172803, 0.13077362236139803)
それぞれのカットラインで確認します。
learn_info = {}
for i in range(11):
name = "lottery init " + str(i*0.01)
print(i*0.01)
mask1 = (W1>i*0.01) | (W1<i*-0.01)
mask2 = (W2>i*0.01) | (W2<i*-0.01)
mask3 = (W3>i*0.01) | (W3<i*-0.01)
model = create_model(nx_train.shape[1]) # 28*28
model = add_layer(model, "affine1", affine, 100, drop_mask=mask1)
model = add_layer(model, "relu1", relu)
model = add_layer(model, "affine2", affine, 50, drop_mask=mask2)
model = add_layer(model, "relu2", relu)
model = add_layer(model, "affine3", affine, 10, drop_mask=mask3)
model = set_output(model, softmax)
model = set_error(model, cross_entropy_error)
epoch = 50
batch_size = 100
np.random.seed(10)
model, optimizer, learn_info[name] = learn(model, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch)
結果です。
| カットライン | 学習正解 | テスト正解 | テスト最大 |
|---|---|---|---|
| 0.00 | 100.00 | 97.85 | 97.88 |
| 0.01 | 100.00 | 97.86 | 97.95 |
| 0.02 | 100.00 | 98.04 | 98.13 |
| 0.03 | 99.99 | 97.72 | 97.84 |
| 0.04 | 99.98 | 97.66 | 97.75 |
| 0.05 | 99.93 | 97.35 | 97.66 |
| 0.06 | 99.73 | 97.29 | 97.42 |
| 0.07 | 99.28 | 97.09 | 97.23 |
| 0.08 | 98.68 | 96.92 | 96.92 |
| 0.09 | 98.04 | 96.42 | 96.63 |
| 0.10 | 97.22 | 95.99 | 96.08 |
カットラインが0.02の場合、少し精度が向上しました。もともと値の小さな重みだったので、カットしても大きな影響がなかったのかもしれません。
一度学習後
いつものモデルで一度学習します。
# モデルの作成
model_org = create_model(nx_train.shape[1]) # 28*28
model_org = add_layer(model_org, "affine1", affine, 100)
model_org = add_layer(model_org, "relu1", relu)
model_org = add_layer(model_org, "affine2", affine, 50)
model_org = add_layer(model_org, "relu2", relu)
model_org = add_layer(model_org, "affine3", affine, 10)
model_org = set_output(model_org, softmax)
model_org = set_error(model_org, cross_entropy_error)
# 学習
epoch = 50
batch_size = 100
np.random.seed(10)
model_org, optimizer, learn_info = learn(model_org, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch)
重みの分布を確認します。
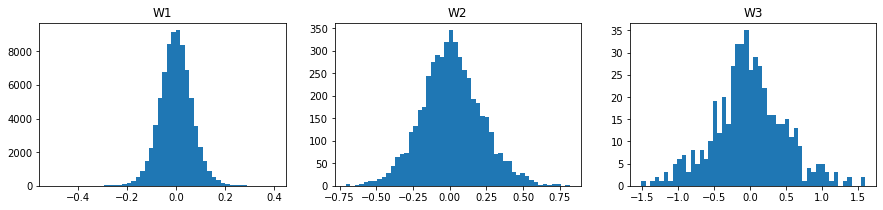
重みの絶対値が0.01~0.15以下まで、0.01ごとに個数を確認します。
# 重みの取得
W1 = getWeight(model_org, "affine1", "W")
W2 = getWeight(model_org, "affine2", "W")
W3 = getWeight(model_org, "affine3", "W")
# 重みのカットラインを0.00~0.15まで0.01刻みで確認
for i in range(16):
print(i*0.01)
print("1 ",((W1<i*0.01) & (W1>i*-0.01)).sum(), ((W1<i*0.01) & (W1>i*-0.01)).sum()/(784*100))
print("2 ",((W2<i*0.01) & (W2>i*-0.01)).sum(), ((W2<i*0.01) & (W2>i*-0.01)).sum()/(100*50))
print("3 ",((W3<i*0.01) & (W3>i*-0.01)).sum(), ((W3<i*0.01) & (W3>i*-0.01)).sum()/(50*10))
| カットライン | W1個数 | W1割合 | W2個数 | W2割合 | W3個数 | W3割合 |
|---|---|---|---|---|---|---|
| 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 |
| 0.01 | 10204 | 13.02 | 210 | 4.20 | 8 | 1.60 |
| 0.02 | 20011 | 25.52 | 435 | 8.70 | 20 | 4.00 |
| 0.03 | 29477 | 37.60 | 680 | 13.60 | 33 | 6.60 |
| 0.04 | 38025 | 48.50 | 879 | 17.58 | 39 | 7.80 |
| 0.05 | 45563 | 58.12 | 1065 | 21.30 | 52 | 10.40 |
| 0.06 | 52151 | 66.52 | 1258 | 25.16 | 62 | 12.40 |
| 0.07 | 57733 | 73.64 | 1453 | 29.06 | 75 | 15.00 |
| 0.08 | 62161 | 79.29 | 1635 | 32.70 | 79 | 15.80 |
| 0.09 | 65981 | 84.16 | 1837 | 36.74 | 92 | 18.40 |
| 0.10 | 68823 | 87.78 | 2007 | 40.14 | 100 | 20.00 |
| 0.11 | 71023 | 90.59 | 2195 | 43.90 | 107 | 21.40 |
| 0.12 | 72857 | 92.93 | 2334 | 46.68 | 117 | 23.40 |
| 0.13 | 74166 | 94.60 | 2513 | 50.26 | 122 | 24.40 |
| 0.14 | 75221 | 95.95 | 2675 | 53.50 | 135 | 27.00 |
| 0.15 | 75978 | 96.91 | 2823 | 56.46 | 145 | 29.00 |
中央値を確認します。初期値より若干、値が大きくなっています。
np.median(np.abs(W1)),np.median(np.abs(W2)),np.median(np.abs(W3))
(0.04140729938323314, 0.1295552535824006, 0.2845111140408029)
それぞれのカットラインで学習します。
learn_info = {}
for i in range(16):
name = "lottery " + str(i*0.01)
print(name)
mask1 = (W1>i*0.01) | (W1<i*-0.01)
mask2 = (W2>i*0.01) | (W2<i*-0.01)
mask3 = (W3>i*0.01) | (W3<i*-0.01)
model = create_model(nx_train.shape[1]) # 28*28
model = add_layer(model, "affine1", affine, 100, drop_mask=mask1)
model = add_layer(model, "relu1", relu)
model = add_layer(model, "affine2", affine, 50, drop_mask=mask2)
model = add_layer(model, "relu2", relu)
model = add_layer(model, "affine3", affine, 10, drop_mask=mask3)
model = set_output(model, softmax)
model = set_error(model, cross_entropy_error)
#optimizer = create_optimizer(SGD, lr=0.1)
epoch = 50
batch_size = 100
np.random.seed(10)
model, optimizer, learn_info[name] = learn(model, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch)
結果です。
| カットライン | カット率 | 学習正解 | テスト正解 | テスト最大 |
|---|---|---|---|---|
| 0.00 | 0.00 | 100.00 | 97.85 | 97.88 |
| 0.01 | 12.42 | 100.00 | 97.97 | 98.00 |
| 0.02 | 24.39 | 100.00 | 98.06 | 98.09 |
| 0.03 | 35.98 | 100.00 | 98.04 | 98.13 |
| 0.04 | 46.42 | 100.00 | 97.99 | 98.07 |
| 0.05 | 55.64 | 100.00 | 98.08 | 98.15 |
| 0.06 | 63.73 | 100.00 | 98.03 | 98.05 |
| 0.07 | 70.63 | 100.00 | 97.97 | 98.04 |
| 0.08 | 76.13 | 100.00 | 98.04 | 98.08 |
| 0.09 | 80.94 | 100.00 | 97.93 | 97.96 |
| 0.10 | 84.54 | 100.00 | 97.83 | 97.98 |
| 0.11 | 87.40 | 99.97 | 97.80 | 97.82 |
| 0.12 | 89.76 | 99.89 | 97.79 | 97.80 |
| 0.13 | 91.54 | 99.66 | 97.56 | 97.67 |
| 0.14 | 93.00 | 99.35 | 97.49 | 97.63 |
| 0.15 | 94.10 | 98.86 | 97.30 | 97.45 |
なんと、0.01~0.09の間では、元より精度が向上しました。
カットラインが、0.09の場合、重みは、約81%カットされます。
すなわち、約19%の重みだけで、精度が良くなったということです。残りの81%の重みは何をしているのか、
カットライン0.12で見てみると、精度は元とほぼ同等です。約90%カットされ、約10%のみ利用し学習しています。
1億円の当選のような当たりくじではありませんが、確かに、当たりくじはありそうです。
カット率と正解率をグラフにしてみます。
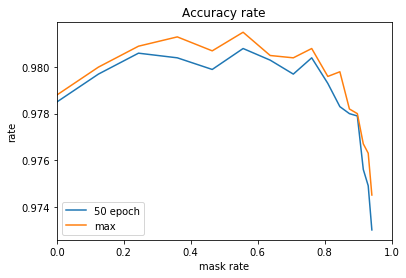
9割程度の重みは、マスクしてもほぼ同等の精度が出ます。1割程度の当たりの重みだけで十分ということでしょう。
マスクを0.02単位で学習時の正解率、誤差をグラフ化します。
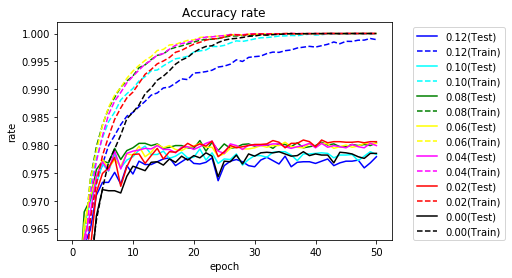
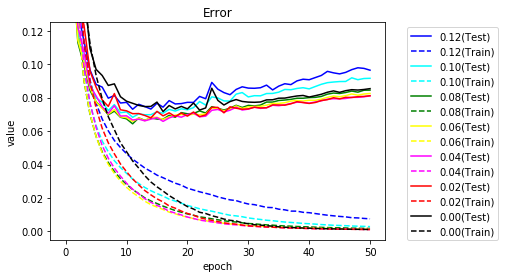
正解率を10エポックまで拡大してみます。
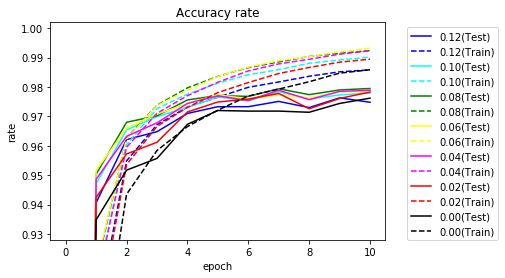
黒のマスクなしに比べてマスクすると学習が早く進むことがわかります。
参考までに、テストデータの5エポックまでの正解率の推移です。
| カットライン | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 0.00 | 8.38 | 93.48 | 95.17 | 95.57 | 96.73 | 97.20 |
| 0.01 | 9.70 | 93.74 | 95.45 | 95.97 | 96.79 | 97.31 |
| 0.02 | 11.39 | 94.24 | 95.72 | 96.12 | 97.15 | 97.49 |
| 0.03 | 15.52 | 94.76 | 96.10 | 96.59 | 97.20 | 97.64 |
| 0.04 | 19.07 | 94.86 | 96.32 | 96.78 | 97.44 | 97.70 |
| 0.05 | 16.53 | 95.02 | 96.44 | 96.93 | 97.42 | 97.76 |
| 0.06 | 22.93 | 95.16 | 96.60 | 97.08 | 97.43 | 97.74 |
| 0.07 | 25.58 | 95.10 | 96.72 | 97.07 | 97.40 | 97.65 |
| 0.08 | 24.69 | 95.03 | 96.80 | 97.02 | 97.56 | 97.71 |
| 0.09 | 27.84 | 94.96 | 96.73 | 97.02 | 97.35 | 97.67 |
| 0.10 | 28.73 | 94.71 | 96.54 | 96.99 | 97.31 | 97.66 |
| 0.11 | 27.22 | 94.38 | 96.38 | 96.82 | 97.20 | 97.40 |
| 0.12 | 26.59 | 94.06 | 96.21 | 96.48 | 97.10 | 97.33 |
| 0.13 | 26.17 | 93.79 | 96.08 | 96.45 | 97.03 | 97.19 |
| 0.14 | 25.11 | 93.09 | 95.48 | 96.00 | 96.66 | 97.01 |
| 0.15 | 22.30 | 92.32 | 94.76 | 95.47 | 96.25 | 96.63 |
0エポックが学習前を表します。ランダムであれば1/10の正解率になるはずです。
マスクしないと8.4%とほぼその通りですが、0.10の場合、28.7%と3割近い正解率となります。
学習しなくても正解率が高く、まさしく当たり券と言えます。
その後も早く学習が進んでいることがわかります。
当たりくじの分布を確認してみます。
各ピクセルごとに、カットライン以上で残るW1の重みの数を確認します。
import matplotlib.pyplot as plt
# 重みのカットラインを0.01~0.15まで0.01刻みで確認
for i in range(1,16):
print(i*0.01)
plt.imshow(np.sum((W1>i*0.01) | (W1<i*-0.01), axis=1).reshape(28,28), "gray")
plt.show()
0.08の場合の図です。

白いほど大きな値です。やはり関係ない周りの方は黒く、ほとんどがカットされていることがわかります。中央に近い方は白く、カットされていません。
次に、当たりくじが別の初期値にも通じるか試してみます。
もとの重みは、seed値10の場合です。seed値を変更し試してみましたが、結果は良くなりませんでした。当たりくじは、その重みの初期値にしか効果がないようです。
ドロップアウトとの併用
宝くじ仮説をドロップアウトと併用してみます。
入力層のドロップアウト率を0.7とし、中間層はドロップアウトしません。
| カットライン | カット率 | 学習正解 | テスト正解 | テスト最大 |
|---|---|---|---|---|
| 0.00 | 0.00 | 98.51 | 98.38 | 98.47 |
| 0.01 | 12.09 | 98.58 | 98.30 | 98.45 |
| 0.02 | 23.63 | 98.56 | 98.43 | 98.54 |
| 0.03 | 34.76 | 98.59 | 98.37 | 98.51 |
| 0.04 | 44.93 | 98.69 | 98.45 | 98.57 |
| 0.05 | 54.07 | 98.71 | 98.46 | 98.57 |
| 0.06 | 62.03 | 98.72 | 98.45 | 98.63 |
| 0.07 | 68.83 | 98.71 | 98.44 | 98.59 |
| 0.08 | 74.45 | 98.65 | 98.51 | 98.55 |
| 0.09 | 79.18 | 98.53 | 98.50 | 98.55 |
| 0.10 | 82.87 | 98.42 | 98.43 | 98.53 |
| 0.11 | 85.81 | 98.20 | 98.44 | 98.51 |
| 0.12 | 88.24 | 98.00 | 98.33 | 98.41 |
| 0.13 | 90.18 | 97.72 | 98.06 | 98.24 |
| 0.14 | 91.74 | 97.42 | 97.86 | 98.13 |
| 0.15 | 93.00 | 97.27 | 97.89 | 97.89 |
ドロップアウトとの併用でも精度が向上しました。
ノード数変更
中間層2層で、ノード数を500-100に変更してみます。
マスクする重みの割合と正解率のグラフです。
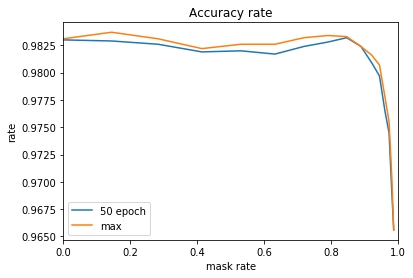
精度は維持できますが、精度の向上はありませんでした。
ただ、この確認で特筆すべきことがありました。学習前の精度です。
0.06以下の重みをカットすると、初期値の乱数だけで未学習にも関わらす、なんと、テストデータで85%の正解率を超えました。信じられない結果となりました。
カットラインごとの5エポックまでの正解率の推移です。
0が未学習の正解率です。未学習だと0~9までの数字のため10%の正解率になるはずです。カットしない場合は、その通り、約10%の正解率です。しかし、小さな重みをカットすると、未学習でも最高で85%を超える正解率になっています。
| カットライン | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 0.00 | 9.14 | 94.59 | 95.89 | 96.60 | 96.66 | 97.41 |
| 0.01 | 33.63 | 95.48 | 96.37 | 97.06 | 97.07 | 97.57 |
| 0.02 | 62.82 | 96.02 | 96.81 | 97.29 | 97.25 | 97.73 |
| 0.03 | 73.91 | 96.38 | 96.98 | 97.39 | 97.31 | 97.81 |
| 0.04 | 79.97 | 96.55 | 97.12 | 97.56 | 97.43 | 97.89 |
| 0.05 | 83.69 | 96.70 | 97.20 | 97.50 | 97.48 | 97.82 |
| 0.06 | 85.16 | 96.58 | 97.19 | 97.46 | 97.50 | 97.84 |
| 0.07 | 80.33 | 96.33 | 97.06 | 97.48 | 97.43 | 97.73 |
| 0.08 | 70.17 | 96.04 | 96.95 | 97.39 | 97.43 | 97.70 |
| 0.09 | 64.81 | 95.54 | 96.57 | 96.99 | 97.33 | 97.49 |
| 0.10 | 58.32 | 94.79 | 96.08 | 96.55 | 96.84 | 97.27 |
| 0.11 | 45.14 | 93.88 | 95.38 | 96.15 | 96.51 | 97.03 |
| 0.12 | 31.46 | 92.60 | 94.45 | 95.39 | 95.71 | 96.47 |
| 0.13 | 26.69 | 91.47 | 93.62 | 94.69 | 95.03 | 95.71 |
| 0.14 | 23.27 | 89.44 | 92.13 | 93.31 | 93.70 | 94.68 |
| 0.15 | 27.07 | 87.00 | 90.21 | 91.55 | 92.39 | 93.15 |
層数の変更
中間層の数を1層の場合、3層の場合を試してみました。
中間層を1層とし、ノード数100の場合です。
95%のマスクでもほぼ精度が落ちませんでした。
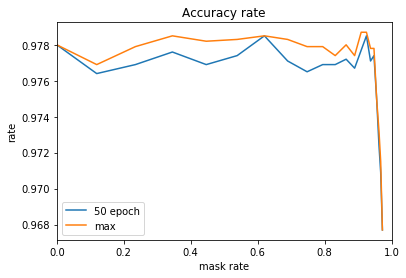
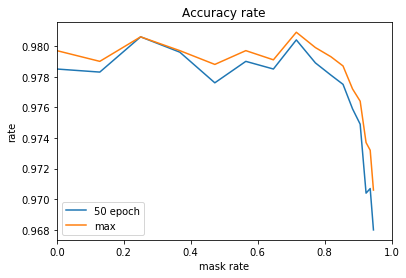
中間層を3層とし、各層のノード数を100,50,25として確認しました。
やはり同じような結果となりました。
まとめ
学習後に値の小さい重みをマスクすれば、精度が向上する場合があることがわかりました。
特に、8割~9割程度マスクしても精度が落ちないどころか向上することにはびっくりです。また、未学習でも80%以上の正解率となる場合もありました。学習が早く進むことにも価値があります。
重みの数が膨大なため、すべての重みの値を適切な値に調整することは困難なのだと思われます。効果のありそうな重みに絞ることで精度を落とさずに学習できるのではないでしょうか、
今回試した範囲では、一度学習する必要があり時間がかかりますが、宝くじの効果はあるようです。