背景・目的
私は、現在データエンジニアリングを生業としています。普段は、データ基盤の構築や、パフォーマンスチューニングなどビックデータに関する業務に従事しています。
ビックデータの収集や、蓄積、分析などの環境構築の経験はそこそこありますが、機械学習による予測や分類などのスキルは持ち合わせていませんでした。
今まで機械学習を避け続けてきましたが、一念発起し学ぼうと思います。
学び方としては、AWS Certified Machine Learning – Specialty(以降、ML試験という。)の勉強を通して、理解を深めていきます。ML試験のガイドの第3分野に、第 3 分野: モデリングから学びたいと思います。
今回は、機械学習の用途や種類について学びたいと思います。
3.1 ビジネス上の課題を機械学習の課題として捉え直す
機械学習を使用する/使用しないタイミングを判断する
教師あり学習と教師なし学習の違いを知る
なお、過去の機械学習の調べてみたシリースは下記にまとめています。
- 2.探索的データ分析
- 2.1.モデリング用のデータをサニタイズおよび準備する
- 2.2.特徴エンジニアリングを実行する
- 2.3 機械学習のデータを分析および視覚化する
- 機械学習プロセス
まとめ
| 分類と回帰 | アルゴリズム |
|---|---|
| 分類 | svm |
| K近傍法 | |
| ロジスティック回帰 | |
| 回帰 | Lasso |
| Ridge | |
| LinReg |
- scikit-learnでは、以下の特徴がある。
- アルゴリズムが豊富、使いやすい
- チートシートにより簡単に適切な手法を選択できる
- サンプルデータセットが用意されている
- 解説が丁寧
- 以下の機能がある。
- 回帰
- 分類
- クラスタリング
- 次元削減
- データの前処理
- モデルの評価と選択
概要
codaxaさんのscikit-learn 入門:6つの機能と分類・回帰の実装方法を徹底解説!を元に学びたいと思います。ありがとうございます。
ここでは、scikit-learnの4つの特徴と6つの機能について整理し、回帰と分類の実装をします。
scikit-learnとは?
- OSSの機械学習ライブラリ。
- Numpy、SciPy、matplotlibなどのPythonライブラリ上で動作する。
- 手軽に機械学習の前処理、モデリング、評価指標の算出など行える。
4つの特徴
①アルゴリズムが豊富、かつ使いやすい
- 回帰、分類、クラスタリング、次元削減など、あらゆるアルゴリズムが揃っている。
②アルゴリズムチートシートを参考に、簡単に適切な手法を選択できる。
- どのアルゴリズムを使えばよいかチートシートでわかる。
- 以下のチートシートで、スタートからYes/Noで二択の選択肢でデータにあったアルゴリズムを選択できる。
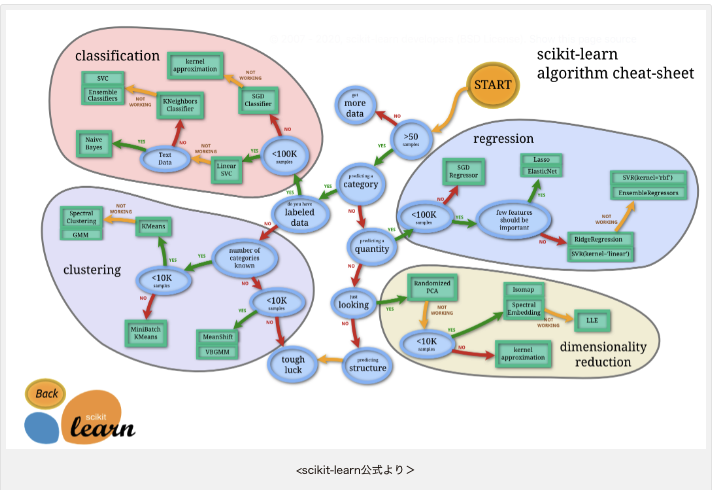
- 以下のチートシートで、スタートからYes/Noで二択の選択肢でデータにあったアルゴリズムを選択できる。
③サンプルのデータセットが用意されている
- scikit-learnにはサンプルのデータセットが用意されている。
- scikit-learnに用意されているデータセットは使いやすいように整形されているため、前処理に余計な手間がかからない。
④公式サイトの解説が丁寧で便利
- ユーザガイドは、各アルゴリズムについて、仕組み、モジュール、実装例が載っている。
scikit-learnの6つの機能
回帰
- 回帰とは、二種類ある教師あり学習のうちの一つ。
- データセットを学習して新たな入力に対する出力の数値を予測する手法。
- 例
- 過去の気象データと位置情報を学習し、その地点の翌日の気温を予測する際には回帰を行う。
- ボストンの住宅価格のデータセットを用いて、まちの犯罪率、高速道路へのアクセスの良さなどのデータから土地の住宅価格を予測する
分類
- 分類とは、回帰ともう一つの教師あり学習。
- データを学習して、新たな入力に対する出力のラベルを予測する手法。
- 例
- 気象データと位置情報を学習し、その地点の翌日の天気(晴れ、曇、雨、雪)を予測する。
- アヤメのデータセットを用いて、アヤメの花びらやがくの大きさから、そのアヤメがどの種類なのか予測する。
クラスタリング
- 教師なし学習の一つ。
- クラスタリングとは、データの特徴から関連の深いデータや似通ったデータを見つけて、クラスターに分ける(グルーピングする)手法。
- 例
- 企業の購買データの分析などに応用されて、クラスタリングの結果に基づいて顧客に商品をレコメンドする。
次元削減
- 教師なし学習の一種。
- データセットの特徴量同士の関係を学習し、より完結かつ効率的に特徴量の情報を表現することなど目的に、新たな特徴を計算で導出して特徴量の数を削減する手法。
- 次元削減することで、コンピューターの性能不足を補う。
- 主成分分析や、因子分析などで次元削減を行うことができる。
データの前処理
- データの数値変換。
- 標準化(データの平均を0、標準偏差を1にする)
モデルの評価と選択
- 各種評価指標を簡単に算出したり、ハイパーパラメータをチューニングしたりするための機能が備わっている。
実践
事前準備
ライブラリ・データセットの準備
import pandas as pd
import sklearn
from sklearn.datasets import load_iris, load_boston
- アヤメのデータセットと、ボストンの住宅価格のデータセットをインポートする。
分類の実装(アヤメのデータセット)
- アヤメの種類の予測を行う。データを読み込んで中身を確認する。
データの確認と分割
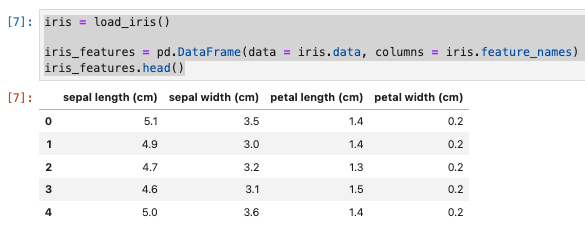
データセットの確認
iris = load_iris()
iris_features = pd.DataFrame(data = iris.data, columns = iris.feature_names)
iris_features.head()
基本統計量を確認。
iris_features.describe()
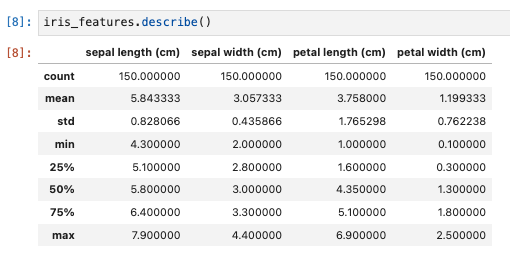
- 明らかにおかしいデータが含まれないか確認する。
- 上から順に
- データ数
- 平均値
- 標準偏差
- 最小値
- 第1四分位
- 中央値
- 第3四分位
- 最大値
特徴量に欠損値がないか確認
iris_features.isnull().sum()

- nullはない。
ラベルの確認
- ラベールをシリーズに格納し、ラベルごとのデータ数を表示する。
iris_label =pd.Series(iris.target)
iris_label.value_counts()
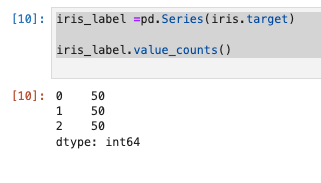
- 0〜2までのラベルで50個づつ。
データを訓練データとテストデータに分割
- model_selectionモジュールのtrain_test_splitメソッドで、データを訓練データとテストデータに分割する。
- 引数には、以下を指定する。
- 特徴量
- ラベル
- テストデータにする割合
- 再現性を持たせるための乱数生成のシードを指定するrandom_state引数
from sklearn.model_selection import train_test_split
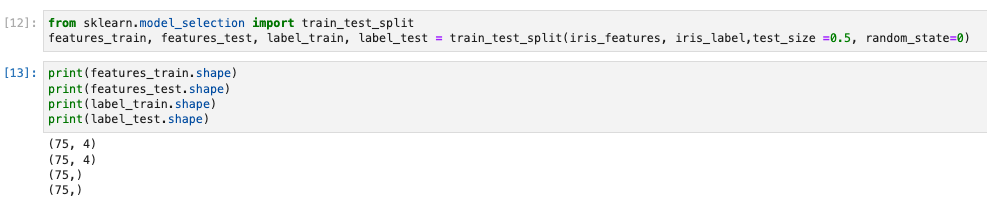
features_train, features_test, label_train, label_test = train_test_split(iris_features, iris_label,test_size =0.5, random_state=0)
- 確認する。
print(features_train.shape)
print(features_test.shape)
print(label_train.shape)
print(label_test.shape)
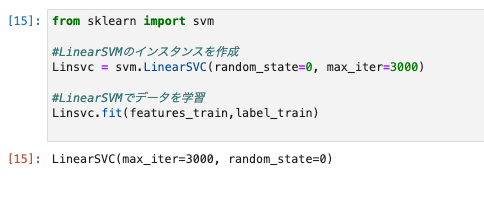
svm(サポートベクターマシン)で学習と予測
- モジュールをインポートし、学習。
from sklearn import svm
Linsvc = svm.LinearSVC(random_state=0, max_iter=3000)
Linsvc.fit(features_train,label_train)
- アヤメのデータを予測する。LinerSVCのインスタンスのpredictメソッドを用いる。
label_pred_Linsvc = Linsvc.predict(features_test)
print(label_pred_Linsvc)

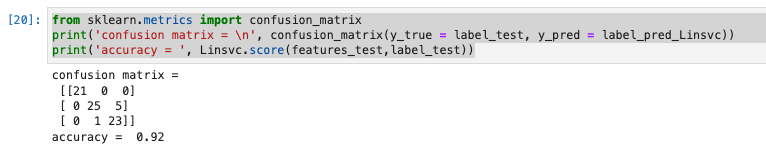
from sklearn.metrics import confusion_matrix
print('confusion matrix = \n', confusion_matrix(y_true = label_test, y_pred = label_pred_Linsvc))
print('accuracy = ', Linsvc.score(features_test,label_test))
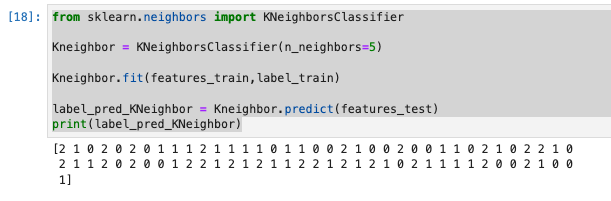
K近傍法で学習と予測
from sklearn.neighbors import KNeighborsClassifier
Kneighbor = KNeighborsClassifier(n_neighbors=5)
Kneighbor.fit(features_train,label_train)
label_pred_KNeighbor = Kneighbor.predict(features_test)
print(label_pred_KNeighbor)
from sklearn.metrics import confusion_matrix
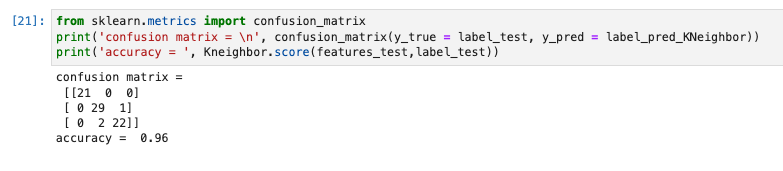
print('confusion matrix = \n', confusion_matrix(y_true = label_test, y_pred = label_pred_KNeighbor))
print('accuracy = ', Kneighbor.score(features_test,label_test))
ロジスティック回帰で学習と予測
from sklearn.linear_model import LogisticRegression
LogReg = LogisticRegression(random_state=0)
LogReg.fit(features_train,label_train)
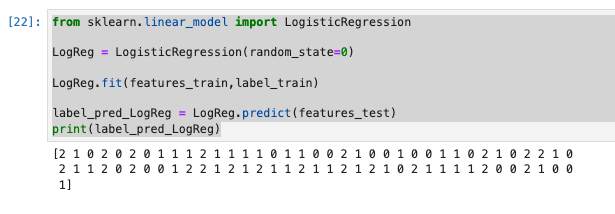
label_pred_LogReg = LogReg.predict(features_test)
print(label_pred_LogReg)
from sklearn.metrics import confusion_matrix
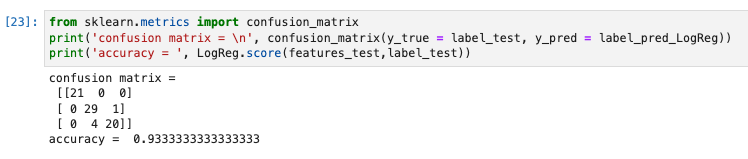
print('confusion matrix = \n', confusion_matrix(y_true = label_test, y_pred = label_pred_LogReg))
print('accuracy = ', LogReg.score(features_test,label_test))
最後に
K近傍法が96%で最も性能が良い。
回帰とモデル選択の実装(ボストン住宅価格データセット)
- ボストンの住宅価格に関するデータセットを用いて、回帰を行い、住宅価格を予測する。
事前準備
データセットの確認
boston = load_boston()
boston_features = pd.DataFrame(data = boston.data, columns = boston.feature_names)
boston_features.head()
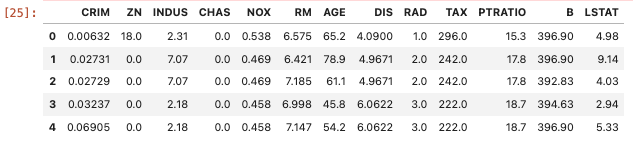
- データの意味は以下の通り。
- CRIM 町の人口あたり犯罪率
- ZN 25000平方フィート以上の住宅地の割合
- INDUS 町ごとの非小売業の土地の割合
- CHAS Charles川に関するダミー変数(川に接していたら1、そうでなければ0)
- NOX 一酸化窒素濃度(1000万分の1)
- RM 住居当たりの平均部屋数
- AGE 1940年より前に建設された物件の割合
- DIS ボストンの5つの雇用センターまでの重み付けされた距離
- RAD 放射状高速道路へのアクセスしやすさ
- TAX 10000ドル当たりの固定資産税総額
- PTRATIO 町ごとの生徒と教師の比率
- B 1000(Bk – 0.63)^2 ※Bkは町の黒人比率
- LSTAT 低所得の人々の割合
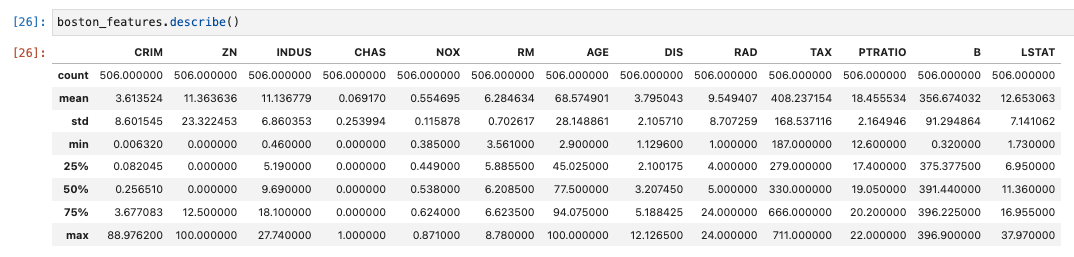
基本統計量を表示
boston_features.describe()
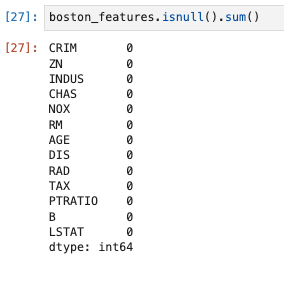
欠損値の確認
boston_features.isnull().sum()
ターゲットの基本統計量を確認
boston_target = pd.Series(data = boston.target)
boston_target.describe()
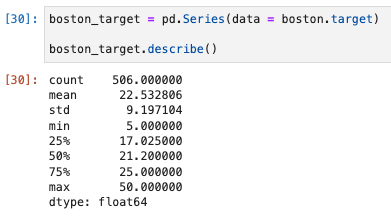
- 最小値と最大値で10倍の差がある。
データを学習データとテストデータに分割
from sklearn.model_selection import train_test_split
features_train, features_test, target_train, target_test = train_test_split(boston_features, boston_target,test_size =0.5, random_state=0)
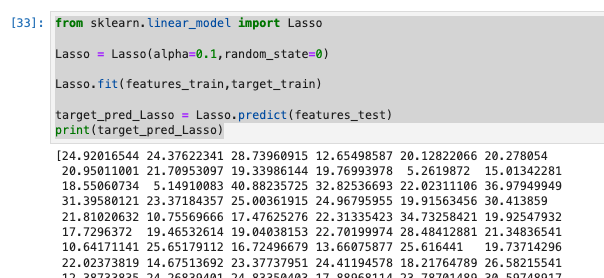
Lassoで学習と予測
from sklearn.linear_model import Lasso
Lasso = Lasso(alpha=0.1,random_state=0)
Lasso.fit(features_train,target_train)
target_pred_Lasso = Lasso.predict(features_test)
print(target_pred_Lasso)
print("R-squared : ",Lasso.score(features_test,target_test))

Ridgeで学習と予測
from sklearn.linear_model import Ridge
Ridge = Ridge(alpha=0.5,random_state=0)
Ridge.fit(features_train,target_train)
target_pred_Ridge = Ridge.predict(features_test)
print(target_pred_Ridge)
print("R-squared : ",Ridge.score(features_test,target_test))

LinRegで学習と予測
from sklearn.linear_model import LinearRegression
LinReg = LinearRegression()
LinReg.fit(features_train,target_train)
target_pred_LinReg = LinReg.predict(features_test)
print(target_pred_LinReg)
print("R-squared : ",LinReg.score(features_test,target_test))

クロスバリデーション
- モデルの評価と選択の機能
- データセットを訓練データとテストデータに分割してモデルに学習させてスコアを出すプロセスを複数回繰り返し、すべてのスコアの平均で性能を測り、より一般的な予測性能が高いモデルを選択する手法。
- たまたま、モデルに不利な形でデータセットが分割されたために性能が低くなったケースを回避できる可能性がある。
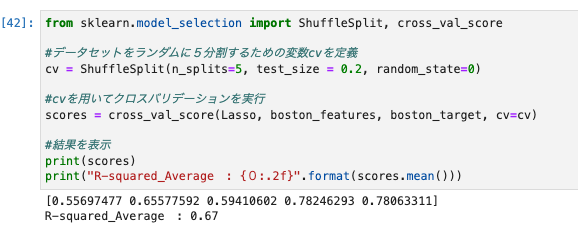
Lassoモデルでクロスバリデーションを行う
from sklearn.model_selection import ShuffleSplit, cross_val_score
cv = ShuffleSplit(n_splits=5, test_size = 0.2, random_state=0)
scores = cross_val_score(Lasso, boston_features, boston_target, cv=cv)
print(scores)
print("R-squared_Average : {0:.2f}".format(scores.mean()))
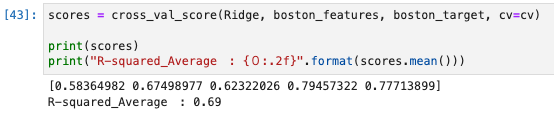
scores = cross_val_score(Ridge, boston_features, boston_target, cv=cv)
print(scores)
print("R-squared_Average : {0:.2f}".format(scores.mean()))
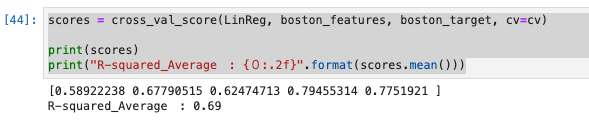
scores = cross_val_score(LinReg, boston_features, boston_target, cv=cv)
print(scores)
print("R-squared_Average : {0:.2f}".format(scores.mean()))
参考