背景・目的
私は、現在データエンジニアリングを生業としています。普段は、データ基盤の構築や、パフォーマンスチューニングなどビックデータに関する業務に従事しています。
ビックデータの収集や、蓄積、分析などの環境構築の経験はそこそこありますが、機械学習による予測や分類などのスキルは持ち合わせていませんでした。
今まで機械学習を避け続けてきましたが、一念発起し学ぼうと思います。
学び方としては、AWS Certified Machine Learning – Specialty(以降、ML試験という。)の勉強を通して、理解を深めていきます。ML試験のガイドの第2分野に、探索的データ解析が登場しましたのでそこから学びたいと思います。
過去に以下について、学習を進めてきました。今回は機械学習レンズについて学びたいと思います。
- 2.探索的データ分析
- 2.1.モデリング用のデータをサニタイズおよび準備する
- 2.2.特徴エンジニアリングを実行する
まとめ
- AWS機械学習レンズは、Well−Architected フレームワーク + 機械学習ワークロードを指す。
- 機械学習ワークフローの、各ステップでのベストプラクティスの定義や、どのようなAWSサービスを利用すればよいか指針を示しています。
- どのAWSスタックを選ぶかは、スキルと時間、カスタム化を鑑みて決定する。
- CRISP-DMを元にしている。
- 機械学習レンズとCRISP-DMの関係性、機械学習レンズのアクティビティ、AWSでの実現方法を整理してみました。(対応関係など誤っているかもしれません。)
| AWS機械学習レンズのフェーズ | アクティビティ | AWSでの実現方法 | CRISP-DMのフェーズとの関係性 |
|---|---|---|---|
| ビジネス目標の特定 | ・ビジネス要件の理解 ・プロジェクトにおける ML の実行可能性とデータ要件を判断 |
N/A | Business Understanding |
| ML 問題のフレーミング | ・ビジネス問題を機械学習の問題として定義する。 ・プロジェクトの良好な成果に対する基準を定義 ・データソーシングおよびデータアノテーションの目標を作成し、それを達成するための戦略を策定 ・ダウンストリームでの消費のためにデータを準備する前に、データを総合的に理解 |
N/A | Data Understanding |
| データ収集 | ・数量と品質の両方について、データの可用性を確認 データ系列を追跡して、後続の処理においてその場所とデータソースが追跡され、把握されるようにする |
・Amazon SageMaker ・Amazon SageMaker Ground Truth ・AWS Glue ・Amazon EMR |
Data Understanding |
| データの準備 | ・データ収集後のデータの統合、アノテーション、準備、処理が重要 ・小型の統計的に有効なサンプルから初めて、データの整合性を継続的に維持しながら、異なるデータ準備戦略を用いて繰り返し、改善する。 |
・Amazon SageMaker ・Amazon SageMaker Ground Truth ・AWS Glue ・Amazon EMR ・Amazon SageMaker Inference Pipeline |
Data Preparation |
| データの視覚化と分析 | ・ユースケース (データサイズ、データの複雑性、およびリアルタイム vs. バッチなど) に適したツール、またはツールの組み合わせを選択する ・データ分析パイプラインを監視する ・データに関する仮定を検証する |
・Amazon SageMaker ・Amazon Athena ・Amazon Kinesis Data Analytics ・Amazon QuickSight |
Data Understanding |
| 特徴量エンジニアリング | 既存のデータから、モデルのインプットに必要なデータを新たに生成する | ・SageMaker ・SageMaker Processing |
Data Preparation |
| モデルのトレーニング | ・モデルをトレーニングする前にモデルのテスト計画を策定 ・トレーニングする必要があるアルゴリズムのタイプを明確に理解する ・トレーニングデータがビジネスに関する問題を表現するものであることを確認する ・増分トレーニング、または転移学習戦略を適用する ・評価指標によって測定された結果が大幅に改善されていない場合は、過学習を避け、コストを削減するために、早い時期にトレーニングジョブを中止する ・モデルのパフォーマンスは時間の経過とともに劣化する可能性があるため、トレーニングメトリクスを注意深く監視する |
・Amazon SageMaker ・Amazon SageMaker Debugger ・Amazon SageMaker Autopilot ・AWS Deep Learning AMI と AWS Deep Learning Containers |
Modeling |
| モデルの評価とビジネスの評価 | ・成功を測定する方法を明確に理解する ・プロジェクトに対するビジネス面での期待に照らしてモデルメトリクスを評価する ・本番環境へのデプロイメント (モデルのデプロイメントとモデルの推論) を計画して実行する |
・Amazon SageMaker ・Amazon SageMaker Inference Pipeline ・Amazon SageMaker Model Monitor ・Amazon SageMaker Neo ・Amazon Elastic Inference |
Evaluation Deployment |
概要
機械学習レンズとは
AWSの「機械学習レンズ」のドキュメントには、以下のように記載がありました。
機械学習レンズでは、AWS クラウドでの機械学習ワークロードのデザイン、デプロイメント、および設計方法に焦点を当てます。このレンズは、Well-Architected フレームワークに含まれるベストプラクティスに追加されるものです。説明を簡潔にするため、このレンズには機械学習 (ML) ワークロードに固有の詳細のみが記載されています。ML ワークロードを設計するときは、AWS Well-Architected フレームワークのホワイトペーパーから、該当するベストプラクティスと質問を使用するようにしてください。
Well−Architected フレームワーク + 機械学習ワークロードらしいです。主に、MLワークフロードのデザイン、デプロイ、設計方法にフォーカスしているようです。
定義
以下を柱にしているとのこと。
- 運用上の優秀性
- セキュリティ
- 信頼性
- パフォーマンス効率
- コスト最適化
機械学習ワークロードを考える際には、機械学習スタックと、MLワークロードを評価する必要があるとのことです。
機械学習スタック
AWSでMLワークロードを構築する際には、以下の要素を鑑みて、異なる抽象化レベルを選択できる。
- スキル
- 市場投下までのスピード
- カスタム化
AIサービス
フルマネージド型で、事前に学習済み、もしくは自動で学習される機械学習モデル、深層学習モデルに基づいている。
APIコールで、ワークロードに簡単に組み込める。
MLサービス
デベロッパー、データサイエンティスト、および研究者に対して機械学習のためのマネージドサービスとリソースを提供するとのことです。インフラを心配することなく、データのラベル付けを行い、カスタム ML モデルを構築、トレーニング、デプロイ、および運用にフォーカスできます。
Amazon SageMaker を使用することで、デベロッパーとデータサイエンティストがあらゆる規模の ML モデルを迅速かつ簡単に構築、トレーニング、およびデプロイできるようになります。
ML フレームワークとインフラストラクチャ
熟達した機械学習プラクティショナーを対象としている。
このプラクティショナーは、モデルを構築、トレーニング、チューニング、およびデプロイするための独自のツールとワークフローの設計をスムーズに行い、フレームワークレベルとインフラストラクチャレベルでの作業にも慣れているとのこと。(無敵ですね・・)
AWSでは、TensorFlow、PyTorch、および Apache MXNetなどのオープンソースのMLフレームワークが利用可能。
深層学習 AMI と深層学習コンテナには、パフォーマンスのために最適化された複数の ML フレームワークが事前にインストール済みとのこと。
ML ワークロードのフェーズ
典型的な MLワークロードの構築と運用は反復的なプロセスであり、複数のフェーズで構成されるとのことです。
一般的な指針として、これらのフェーズは、Cross Industry Standard Process Data Mining (CRISP-DM) のオープン標準プロセスモデルを大まかな基準として特定されています。CRISP-DM がベースラインとして使用されているのは、これが業界で実証済みのツールであり、アプリケーションに依存しないため、さまざまな ML パイプラインとワークロードに適用できる、使用しやすい手法であることが理由です。
- CRISP-DMを元にしている。
- エンドツーエンドの機械学習プロセスには、以下のフェーズが含まれます。
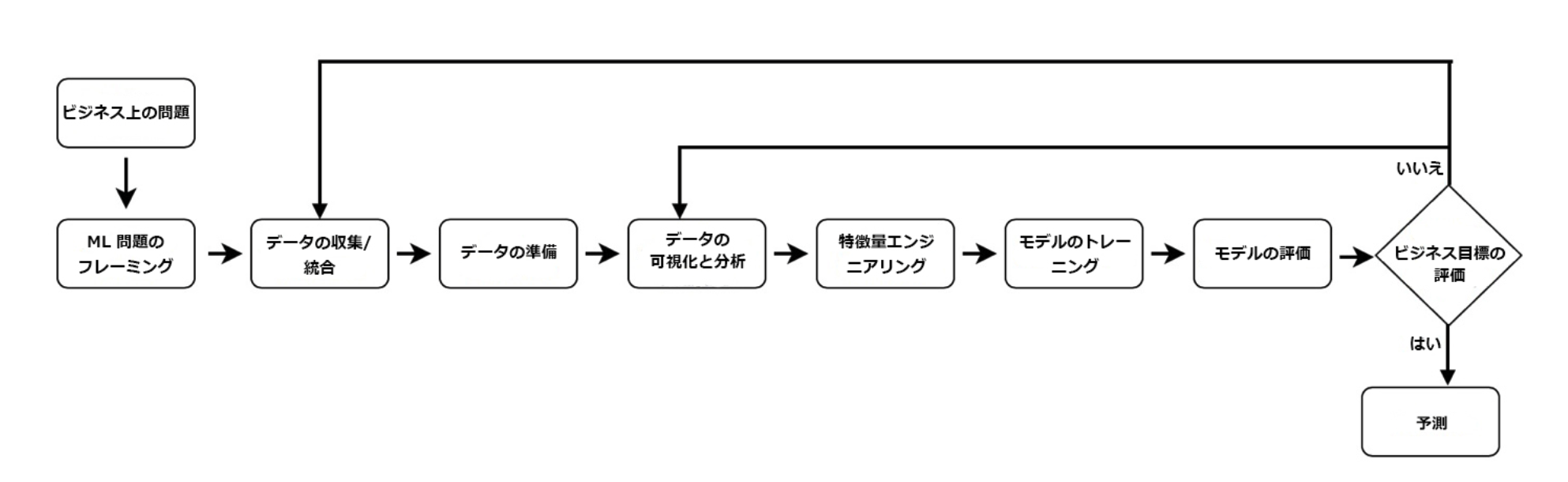
※出典 AWSの「MLワークロードのフェーズ」ページから抜粋。
CRISP-DMとは?
Wikipediaを元に整理します。
- Cross-industry standard process for data miningの略。
- データマイニングの業界横断的な標準プロセス。データマイニングの専門家が使用する一般的なアプローチを説明するオープンスタンダードプロセスモデル。
- データマイニング業界の既存の問題を解決する様々な利点があるため、最も広く普及しているデータマイニングモデル。
- 業界、ツール、アプリケーションに中立。
- 以下6つのフェーズに分割されている。
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
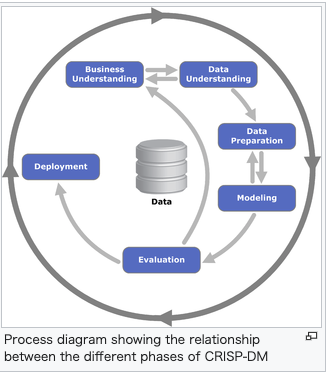
※出典 Wikipediaの「Cross-industry standard process for data mining」から抜粋。
ビジネス目標の特定
ビジネス目標の特定は、最も重要なフェーズです。ML を検討している組織は、解決すべき問題と、その問題を ML で解決することで得られるビジネス価値を明確に把握する必要があります。具体的なビジネス目的や成功の基準に対して、ビジネス価値を測定できることが求められます。これはどのような技術的ソリューションにも当てはまることですが、ML は破壊的な技術であるため、ML ソリューションを検討する場合には、このステップがとりわけ困難になります。
以下は、IT導入でも一緒ですね。
- 解決すべき問題と、その問題をMLで解決することで得られるビジネス価値を明確にすることが重要。
- ビジネス目的や成功の基準に対して、ビジネス価値を測定できることが求めれる。
成功の基準を決定した後は、組織がその目標に向かって実際に物事を遂行するための能力を評価します。目標は達成可能で、本稼働への明確な過程を示すものにする必要があります。
- 達成可能な目標と、能力を評価し、ロードマップなどを明らかにする。
ML がビジネス目標を達成するために適切なアプローチであることを検証してください。アプローチを決定するときは、目標を達成するために利用できるすべてのオプションと、結果として得られる成果に期待される精度、および各アプローチのコストとスケーラビリティを評価します。
- 各種オプションの一つとして、MLが最適化を検証すること。
- ありがちなのは、How先行ですすまないこと。
ML ベースのアプローチを成功させるには、トレーニングしようとしているアルゴリズムに適用できる、高品質の関連データを十分に保有していることが必要不可欠です。このデータの利用可能性を慎重に評価して、適切なデータソースが利用可能かつアクセス可能であることを確認してください。例えば、ML モデルのトレーニングとベンチマークの実施にはトレーニングデータが必要ですが、ML ソリューションの価値を評価するにはビジネスからのデータも必要です。
- 高品質なデータが存在すること、また利用可能であることを確認すること。
ベストプラクティスは以下の通りです。
- ビジネス要件を理解する
- ビジネスに関する質問を形成する
- プロジェクトにおける ML の実行可能性とデータ要件を判断する
- データ取得、トレーニング、推論、および誤った予測にかかるコストを評価する
- 同様の分野における実証済み、または公開済みの業績をレビューする (利用できる場合)
- 許容可能なエラーを含めた主要パフォーマンスメトリクスを決定する
- ビジネスに関する質問に基づいて機械学習のタスクを定義する
- 重要かつ必須の機能を特定する
ML 問題のフレーミング
このフェーズでは、ビジネス問題が機械学習問題として定義されます。つまり、何が観測され、何が予測されるべきかということです (これらは、ラベルまたはターゲット変数として知られています)。ML では、何を予測し、パフォーマンスとエラーのメトリクスをどのように最適化する必要があるかを決定することが重要なステップとなります。
例えば、製造業社が利益を最大化する製品を特定したいというシナリオを考えてみてください。このビジネス目標を達成するには、生産する製品の適切な数量を判断することがひとつの鍵となります。このシナリオでは、過去と現在の売上に基づいて、製品の将来の売上を予測します。すると、将来の売上を予測することが解決する問題となります。ML の使用はこの問題の解決に利用できるアプローチのひとつです。
- ビジネス問題位を機械学習の問題として定義する。
- 何が観測され、何が予測されるかパフォーマンスとエラーのメトリクスをどの様に最適化するかを決定することが重要。
ベストプラクティスは以下の通りです。
- プロジェクトの良好な成果に対する基準を定義する
- 精度、予測レイテンシー、またはインベントリ値の最小化など、プロジェクトに関する観測可能で数量化可能なパフォーマンスメトリクスを確立する
- 入力、目的の出力、および最適化されるパフォーマンスメトリクスに関する ML 問題を策定する
- ML が実現可能で適切なアプローチであるかどうかを評価する
- データソーシングおよびデータアノテーションの目標を作成し、それを達成するための戦略を策定する
- 解釈しやすいことから、デバッグも処理しやすくなるシンプルなモデルから始める
データ収集
ML ワークロードでは、データ (入力とそれに対応する目的の出力) が以下の 3 つの重要な役割を果たします。
・システムの目標を定義する: 出力表現と、入力/出力ペアによる各出力と各入力との関係
・入力を出力に関連付けるアルゴリズムのトレーニングを行う
・トレーニングされたモデルのパフォーマンスを測定し、パフォーマンス目標が達成されたかどうかを評価する
最初のステップは、ML モデルに必要なデータを特定して、モデルをトレーニングするためのデータの収集に利用できるさまざまな手段を評価することです。
組織が増加し続ける大量のデータを収集して分析するにつれて、データストレージ、データ管理、および分析のための従来のオンプレミスソリューションはそれらに対応できなくなります。クラウドベースのデータレイクは、データの規模にかかわらず、構造化データと非構造化データのすべてを保存することを可能にする、一元化されたリポジトリです。データは、構造化してからではなく、そのまま保存でき、ダッシュボードと視覚化からビッグデータ処理、リアルタイム分析、および ML におよぶ異なるタイプの分析を実行して、より良い意思決定を導き出します。
AWS は、静的なリソースから、またはウェブサイト、モバイルアプリ、およびインターネット接続デバイスなどの新しい動的に生成されたリソースからデータを取り込むための方法を多数提供しています。例えば、Amazon Simple Storage Service (Amazon S3) を使用して拡張性に優れたデータレイクを構築することが可能です。データレイクを簡単にセットアップするには、AWS Lake Formation を使用できます。
- データレイクにとりあえず溜めようとという話。
データの取り込みには、AWS Direct Connect を使用して、データセンターを AWS リージョンに直接プライベートに接続できます。ペタバイト規模のデータを一括で物理的に転送するには、AWS Snowball を使用できます。エクサバイト規模のデータがある場合は、AWS Snowmobile を使ってこれを実行できます。AWS Storage Gateway を使用して既存のオンプレミスストレージを統合する、または AWS Snowball Edge を使用してクラウド機能を追加することも可能です。また、複数のストリーミングデータを収集して取り込むには、Amazon Kinesis Data Firehose を使用できます。
- 取得方法は、サイズや期間によって様々。
ベストプラクティスは、以下のとおりです。
- データを抽出するために必要なさまざまなソースとステップを詳述する
- 数量と品質の両方について、データの可用性を確認する
- ダウンストリームでの消費のためにデータを準備する前に、データを総合的に理解する
- データガバナンスを定義する: データの所有者、アクセス権の保有者、データの適切な使用方法、およびオンデマンドで特定のデータにアクセスし、削除する能力
- データ系列を追跡して、後続の処理においてその場所とデータソースが追跡され、把握されるようにする
- データの収集と統合に AWS のマネージドサービスを使用する
- データレイクなど、データの保存に一元的なアプローチを使用する
上記は、MLだけに関わらずデータマネジメントの観点でも重要。
データの準備
ML モデルの善し悪しは、トレーニングに使用するデータに左右されます。データを収集した後は、そのデータの統合、アノテーション、準備、および処理が重要になります。本質的に、適切なトレーニングデータは、学習や一般化のために最適な方法で提供されるという特徴を持っています。データの準備は、小型の統計的に有効なサンプルから始めて、データの整合性を継続的に維持しながら、異なるデータ準備戦略を用いて繰り返し改善される必要があります。
AWS は、大規模なデータのアノテーションと ETL (抽出、変換、ロード) のために使用できるサービスを複数提供しています。
- データ収集後のデータの統合、アノテーション、準備、処理が重要
- 準備は、小型の統計的にゆうこうなサンプルから初めて、データの整合性を継続的に維持しながら、異なるデータ準備戦略を用いて繰り返し、改善する。
AWSは、下記のサービスを提供している。
- Amazon SageMaker
- データのラベル付けと準備、アルゴリズムの選択、モデルのトレーニング、デプロイメントのためのモデルのチューニングと最適化、および予測を実行するための ML ワークフロー全体が含まれる完全マネージド型サービス。
- Amazon SageMaker Ground Truth
- 公的機関および民間企業のヒューマンラベラーを簡単に利用できる。
- 一般的なラベリングタスクのための組み込みワークフローとユーザーインターフェイスを提供する。
- これは、機械学習モデルを使用して raw データに自動でラベルを付け、手動によるラベル付けの何分の 1 かのコストで高品質なトレーニングデータセットをすばやく作成します。
- データがヒューマンラベラーに送られるのは、アクティブラーニングモデルが確信を持ってラベル付けできない場合だけです
- このサービスは、動的なカスタムワークフロー、ジョブの連鎖、およびジョブの追跡機能を提供し、以前のラベリングジョブからの出力を新しいラベリングジョブの入力として使用することによって、後続の ML ラベリングジョブにかかる時間を短縮します。
- AWS Glue
- ETL パイプラインを自動化するために使用できる完全マネージド型の ETL (抽出、変換、ロード) サービス
- AWS Glue は Glue Data Catalog を使用してデータを自動的に検出してプロファイリングし、ソースデータをターゲットスキーマに変換するための ETL コードの推奨と生成を行って、完全マネージド型のスケールアウトされた Apache Spark 環境で ETL ジョブを実行してデータをその宛先にロードします。また、複雑なデータフローのセットアップ、オーケストレーション、およびモニタリングの実行も可能にします。
- Amazon EMR
- 動的にスケールできる Amazon EC2 インスタンス全体での大量のデータの処理を簡単かつ迅速に実行できるようにする、マネージド Hadoop フレームワークを提供。
- Apache Spark、HBase、Presto、および Flink などのその他の一般的な分散型フレームワークを EMR で実行し、Amazon S3 および Amazon DynamoDBなどのその他の AWS データストアにあるデータとやりとりすることも可能。
データの準備は、機械学習モデルを構築するために使用されるトレーニングデータだけでなく、モデルのデプロイ後にモデルに対する推論を行うために使用される新しいビジネスデータにも適用されます。通常、トレーニングデータに適用するものと同じ一連のデータ処理ステップが、推論リクエストにも適用されます。
-
データ準備は、トレーニングデータだけではなく推論に使用されるビジネスデータにも適用される。
-
トレーニングデータと同じ一連のデータ処理ステップが推論リクエストにも適用される。
-
Amazon SageMaker Inference Pipeline
- パイプラインをデプロイして、リアルタイム推論とバッチ推論リクエストの両方で未処理の入力データを渡し、事前処理、予測、および事後処理を実行することを可能にします。
- 推論パイプラインを使用することにより、既存のデータ処理機能を再利用できるようになります。
ベストプラクティスは、以下のとおりです。
- データの準備は、小型の統計的に有効なサンプルデータセットから始める
- 異なるデータ準備戦略を使って繰り返し実験する
- データクリーニングプロセス中に、データ準備ステップの全体を通じて異常に対するアラートを提供するフィードバックループを実装する
- データの整合性を継続的に強化する
- マネージド ETL サービスを活用する
データの視覚化と分析
データを理解するための重要な側面のひとつは、パターンの識別です。通常、これらのパターンは、表内のデータを見ているだけではわかりません。適切な視覚化ツールは、データに対する理解をすばやく深めるために役立ちます。表やグラフを作成する前に、何を表示するかを決めなければなりません。例えば、グラフによって、主要業績評価指標 (KPI)、関係性、比較、分布、または構成などの情報を伝達することができます。
-
データ理解のためには、可視化ツールが有効。
-
Amazon SageMaker
- データの視覚化と分析に利用できる、ホストされた Jupyter ノートブック環境を提供
- Project Jupyter はオープンソースのウェブアプリケーションで、ビジュアライゼーションと説明テキストの作成だけでなく、データクリーニング、データ変換、数値シミュレーション、統計的モデリング、およびデータ視覚化の実行も可能にする。
-
Amazon Athena
- ANSI SQL 演算子と関数を使用して Amazon S3 内のデータをクエリするために使用可能
- 完全マネージド型のインタラクティブなクエリサービス
- サーバーレスで、クエリの需要を満たすためにシームレスにスケールできます。
-
Amazon Kinesis Data Analytics
- ストリーミングデータを分析して実用的なインサイトを得ることによって、リアルタイムの分析機能を提供する。
- このサービスは、受信データの量とスループットに合わせて自動的にスケールします。
-
Amazon QuickSight
- ダッシュボードと視覚化を提供するクラウド駆動のビジネスインテリジェンス (BI) サービス。
- このサービスは、数百人ものユーザーをサポートするために自動的にスケールし、ストーリーボーディングのためのセキュアな共有とコラボレーションを実現する。
- これに加えて、このサービスには、追加設定が不要な異常検出、予測、および What-if 分析を提供する ML 機能が組み込まれています。
ベストプラクティスは、以下のとおりです。
- データのプロファイリングを行う (分類別 vs. 序数的 vs. 定量的視覚化)
- ユースケース (データサイズ、データの複雑性、およびリアルタイム vs. バッチなど) に適したツール、またはツールの組み合わせを選択する
- データ分析パイプラインを監視する
- データに関する仮定を検証する
特徴量エンジニアリング
【初心者】特徴量エンジニアリングについて調べてみたで、整理したので、そちらを参照。
モデルのトレーニング
このフェーズでは、問題に適した機械学習アルゴリズムを選択して、ML モデルをトレーニングします。このトレーニングの一環として、学習するためのトレーニングデータをアルゴリズムに提供し、トレーニングプロセスを最適化するモデルパラメータを設定します。
通常、トレーニングアルゴリズムは、トレーニングエラーや予測精度などのいくつかのメトリクスを計算します。これらのメトリクスは、モデルが効率的に学習しているか、および未見のデータについての予測を行うために適切な一般化を行うかどうかを判断するために役立ちます。アルゴリズムによって報告されるメトリクスは、ビジネスに関する問題と、使用した ML 手法に応じて異なります。例えば、分類アルゴリズムは、真陽性または偽陽性、および真陰性または偽陰性をキャプチャする混同行列による測定が可能で、回帰アルゴリズムは、RMSE (二乗平均平方根誤差) による測定が可能です。
ML アルゴリズムと、その結果として得られるモデルアーキテクチャの動作を制御するために調整できる設定は、ハイパーパラメータと呼ばれます。ML アルゴリズムにおけるハイパーパラメータの数や種類は、モデルごとに異なります。一般的に使用されるハイパーパラメータの例としては、学習率、エポック数、隠れ層、隠れユニット、活性化関数などがあります。ハイパーパラメータのチューニング、または最適化とは、最適なモデルアーキテクチャを選択するプロセスのことです。
-
ハイパーパラメータ=モデルアーキテクチャの動作を制御するもの
-
ハイパーパラメータのチューニング、最適化とは、最適なモデルアーキテクチャを選択するプロセスを指す。
-
Amazon SageMaker
- ユーザーが準備して Amazon S3 に保存したトレーニングデータを使ってトレーニングすることができる、一般的な組み込みアルゴリズムをいくつか提供。
- 独自のカスタムアルゴリズムを持ち込んで Amazon SageMaker でトレーニングすることも可能。
- カスタムアルゴリズムは、Amazon ECS と Amazon ECR を使ってコンテナ化する必要があります。
- アルゴリズムを選択したら、API コールを使用して Amazon SageMaker でのトレーニングを開始できる。
- トレーニングは、単一のインスタンス、またはインスタンスの分散クラスターでの実行を選択できる。
- トレーニングプロセスに必要なインフラストラクチャ管理は Amazon SageMaker が実行するため、「差別化につながらない重労働」の負担が排除される。
- ハイパーパラメータチューニングジョブを通じたモデルの自動チューニングも可能にする。
- 設定が完了すると、ハイパーパラメータチューニングジョブは、アルゴリズムとユーザー指定のハイパーパラメータ範囲を使用してデータセットで多数のトレーニングジョブを実行することによって、モデルの最適バージョンを見つけ出す。
- 次に、選択されたメトリクスで測定し、最高パフォーマンスのモデルを得たハイパーパラメータを選択する。
- Amazon SageMaker の自動モデルチューニングは、組み込みアルゴリズム、カスタムアルゴリズム、および ML フレームワーク用の Amazon SageMaker の事前構築済みコンテナで使用可能。
-
Amazon SageMaker Debugger
- 定期的な間隔でトレーニングジョブの状態をキャプチャするデータを監視、記録、および分析することによって、ML トレーニングプロセスに対する可視性を提供。
- トレーニング中にキャプチャされたデータの対話型探索を実行する機能と、トレーニング中に検出されたエラーに対するアラート送信機能も提供。
- 例えば、勾配値が大きくなりすぎている、または小さくなりすぎているなどの一般的に発生するエラーを自動的に検出して、アラートを送信することができます。
-
Amazon SageMaker Autopilot
- データの事前処理、アルゴリズムの選択、およびハイパーパラメータチューニングを自動的に処理することで、ML のトレーニングプロセスを簡素化する。
- トレーニングデータを表形式で提供するだけで、分類モデルや回帰モデルを構築できるようにしてくれる。
- この機能では、データプリプロセッサ、アルゴリズム、アルゴリズムパラメータ設定のさまざまな組み合わせで複数の ML ソリューションを調査し、最も正確なモデルを見つけ出す。
- ネイティブにサポートされる高性能アルゴリズムの中から最適なアルゴリズムを選択する。
- モデル品質を最適にするため、これらのアルゴリズムのさまざまなパラメータ設定を自動で試行する。
- その後、本番環境に最適モデルを直接デプロイする、または複数の候補を評価して、精度、レイテンシー、およびモデルサイズなどのメトリクスをトレードオフすることができます。
-
AWS Deep Learning AMI と AWS Deep Learning Containers
- インフラストラクチャでのトレーニングに複数のオープンソース ML フレームワークを利用できるようにする。
- AWS 深層学習 AMI には、TensorFlow、PyTorch、Apache MXNet、Chainer、Gluon、Horovod、および Keras などの一般的な深層学習フレームワークとインターフェイスが事前にインストールされてる。
- AMI またはコンテナは、ML パフォーマンス用に最適化された強力なインフラストラクチャで起動できる。
-
Amazon EMR には分散クラスター機能があり、クラスター上にローカルに保存されたデータ、または Amazon S3 に保存されたデータでトレーニングジョブを実行するためのオプションでもある。
ベストプラクティスは、以下のとおりです。
- モデルをトレーニングする前にモデルのテスト計画を策定する
- トレーニングする必要があるアルゴリズムのタイプを明確に理解する
- トレーニングデータがビジネスに関する問題を表現するものであることを確認する
- トレーニングのデプロイメントにマネージドサービスを使用する
- 増分トレーニング、または転移学習戦略を適用する
- 評価指標によって測定された結果が大幅に改善されていない場合は、過学習を避け、コストを削減するために、早い時期にトレーニングジョブを中止する
- モデルのパフォーマンスは時間の経過とともに劣化する可能性があるため、トレーニングメトリクスを注意深く監視する
- 自動モデルチューニングのマネージドサービスを活用する
モデルの評価とビジネスの評価
モデルのトレーニングが完了したら、モデルを評価して、そのパフォーマンスと精度がビジネス目標の達成を可能にするかどうかを判断します。異なる方法を使用して複数のモデルを生成し、各モデルの有効性を評価するとよいかもしれません。例えば、モデルごとに異なるビジネスルールを適用し、さまざまな対策を適用して各モデルの適合性を判断できます。また、モデルに特異度ではなくより高い感度が必要かどうか、またはその逆であるかどうかを評価することもできます。マルチクラスモデルの場合は、各クラスのエラー率を個別に評価します。
モデルは、履歴データ (オフライン評価) またはライブデータ (オンライン評価) を使用して評価できます。オフライン評価では、ホールドアウトセットとして確保しておいたデータセットの一部を使ってトレーニングされたモデルを評価します。このホールドアウトデータは、モデルのトレーニングや検証には一切使用されず、最終的なモデルでのエラーの評価のみに使用されます。ホールドアウトデータのアノテーションには、評価を理解可能なものとするためにも、高い精度が必要です。追加のリソースを割り当てて、ホールドアウトデータの精度を検証してください。
このフェーズには、モデルトレーニングに使用される AWS のサービスが担う役割もあります。モデルの検証は、Amazon SageMaker、AWS 深層学習 AMI、または Amazon EMR を使用して実行できます。
評価結果に基づいて、データ、アルゴリズム、またはそれら両方を微調整できます。データを微調整するときには、データクレンジング、準備、および特徴量エンジニアリングの概念を適用します。
-
ベストプラクティスは、以下のとおりです。
- 成功を測定する方法を明確に理解する
- プロジェクトに対するビジネス面での期待に照らしてモデルメトリクスを評価する
- 本番環境へのデプロイメント (モデルのデプロイメントとモデルの推論) を計画して実行する
- モデルのトレーニング、チューニング、およびテストが完了したら、モデルを本番環境にデプロイし、モデルに対して推論 (予測) を行うことが可能。
-
Amazon SageMaker
- デプロイメントと推論のための幅広いオプションを提供し、本番環境 ML モデルのホスティングに推奨される
- モデルのトレーニングと同様に、API コールを使用して Amazon SageMaker でモデルをホスト可能
- モデルは、1 つのインスタンスで、または複数のインスタンスにまたがってホストすることを選択可能。
- 同じ API を使用して自動スケーリングを設定できるため、ML モデルにおけるさまざまな推論需要に対応可能。
- モデルのホストに必要なインフラストラクチャ管理は Amazon SageMaker が完全に管理するため、「差別化につながらない重労働」の負担が排除される。
-
Amazon SageMaker Inference Pipeline
- 推論パイプラインをデプロイできるため、リアルタイム推論とバッチ推論リクエストで未処理の入力データを渡し、事前処理、予測、および完全な事後処理を実行することが可能
- 推論パイプラインは、任意の ML フレームワーク、組み込みアルゴリズム、または Amazon SageMaker で使用できるカスタムコンテナで構成可能
- SparkML で利用できる機能トランスフォーマー一式と Scikit-learn のフレームワークコンテナを使って、機能のデータ処理および特微量エンジニアリングのパイプラインを構築したり、これらを推論パイプラインの一部としてデプロイしてデータ処理コードを再利用したりできるなど、ML の処理の管理が簡単になる。
- これらの推論パイプラインは完全マネージド型で、データサイエンスプロセスの一部として事前処理、予測、および事後処理を組み合わせることが可能
-
Amazon SageMaker Model Monitor
- 番環境の ML モデルを継続的に監視する
- MLモデルが本番環境にデプロイされた後は、実際のデータとモデルのトレーニングに使用されたデータとの間に相違が生じ始める場合がある。
- これはモデル品質の逸脱につながり、最終的にはモデルの精度が低くなる
- Model Monitor は、時間の経過とともにモデルのパフォーマンスを劣化させる可能性のあるデータドリフトなどの逸脱を検出し、修復措置を実行するように警告するアラートを送信する。
-
Amazon SageMaker Neo
- ML モデルを 1 度だけトレーニングして、それらをクラウドの任意の場所、またはエッジで実行することを可能にする
- コンパイラとランタイムで構成される。
- compilation API は、さまざまなフレームワークからエクスポートされたモデルを読み取ってフレームワークに依存しない表現に変換し、最適化されたバイナリコードを生成する
- 次に、各ターゲットプラットフォームのランタイムがコンパイルされたモデルをロードして実行します。
-
Amazon Elastic Inference
- Amazon EC2 と Amazon SageMaker のインスタンスに低コストの GPU 駆動のアクセラレーションをアタッチして、深層学習推論の実行コストを削減することを可能にする。
- スタンドアロンの GPU インスタンスはモデルのトレーニング用に設計されている、通常、推論用にはサイズが大きすぎる。
- トレーニングジョブは数百個のデータサンプルを並行的に一括で処理しますが、ほとんどの推論はリアルタイムで単一の入力に対して行われ、わずかな量の GPU コンピューティングしか消費しない。
- Amazon Elastic Inference は、コードを変更することなく、適切な量の GPU 駆動の推論アクセラレーションを任意の Amazon EC2 または Amazon SageMaker のインスタンスタイプにアタッチできるようにします。
- Elastic Inference は、TensforFlow と Apache MXNet などのいくつかの深層学習フレームワークでネイティブにサポートされていますが、Open Neural Network Exchange (ONNX) を使用してモデルをエクスポートし、MXNet にインポートすることによって、他の深層学習フレームワークで使用することもできます。
ベストプラクティスは、以下の通りです。
- 本番環境でのモデルパフォーマンスを監視し、ビジネス面での期待と比較する
- トレーニング中と本番環境におけるモデルパフォーマンスの違いを監視する
- モデルパフォーマンスにおける変化が検出された場合は、モデルを再トレーニングする。例えば、売上面の期待と今後の予測は、新しい競合他社の出現によって変化する可能性があります
- データセット全体の推論を取得したい場合は、ホスティングサービスに代わるものとしてバッチ変換を使用する
- 本番環境バリアントを活用して、A/B テストを使ってさまざまな新しいモデルをテストする
考察
- 今回は、AWSの機械学習レンズを学びました。たまたま特徴量エンジニアリングの整理の最中に見つけましたが、本当はこのようなワークフローをざっくりと始めに理解するのが良かったかもしれません。
参考