背景・目的
私は、データエンジニアリングを生業としているのですが、今まで機械学習を避け続けてました。
データは活用してこそ意味があるので、機械学習は必要と考えますが、私自身、数学や統計など苦手で、避け続けてきました。
しかし、ここらで一念発起し、AWS Certified Machine Learning – Specialty(以降、ML試験という。)の勉強を通して、理解を深めていこうと思います。
まずは、ML試験のガイドを読むと、第2分野に探索的データ解析が出ていましたので、そこから学びたいと思います。
まとめ
- 探索的データ解析、データの特徴を掴む方法。
- 実際に値を見るだけではなく、グラフなど利用して可視化することで、客観的でわかりやすい。
- 対話的に探索するので、ツールはJupyterLab(Jupyter)と相性がいいと感じました。
- 今回、codexaさんの記事を参考に勧めましたがとても理解し易く便利でした。こちらを教材に今後も精進していきたいと思います。
概要
探索的データ解析とは?
たまに聞いたりしますが、何か全くわからないのでとりあえずググってみたところ、codexaさんの【データサイエンティスト入門編】探索的データ解析(EDA)の基礎操作をPythonを使ってやってみようの記事がヒットしたので、こちらを元にに整理とチュートリアルを実施したいと思います。
探索的データ解析とは、以下の特徴があります。
- 探索的データ解析を英語で、Explanatory Data Analysis(略してEDA)
- データの特徴を探求し、構造を理解することを目的としたデータサイエンスの最初の一歩
- 機械学習フェーズの最初
- 目的は、データに触れて特徴を理解すること。 そのために視覚化し、データのパターンを探し、特徴量やターゲットの関係性/相関を感じる。
探索的データ解析の重要性
データサイエンティストにとって、理解しているデータもあれば、初めてのものもある。これらのデータを利用して仮設を立てて、最終的には予測モデルを作成する。
このプロセスにおいて、探索的データ解析は重要な役割を担っており、
探索的データ解析は、データよりも価値の高いものを見つけるための作業とのことです。
探索的データ解析で使うツールとは
Pythonのライブラリである以下のツールを利用します。
- Pandas(パンダス)
- 大量データを高速に、簡単に扱うツール。
- Matplotlib(マットプロットリブ)
- グラフを作成するツール。
- NumPy(ナンパイ)
- 機械学習では複雑かつ膨大な線形代数の処理をすることが多数あり、そのような処理を、高速かつ効率的に行ってくれるツール。
実践
準備
- 練習するに当たり、アヤメ(Iris)の画像データを利用するとのこと。
- 機械学習の初心者が分類問題を練習する際に広く使われる、とても有名なデータセットらしいです。
- このデータセットは、Kaggleのサイトからダウンロードが可能です。
環境準備
pipをアップグレード
$ sudo python3 -m pip install --upgrade pip
$ pip -V
pip 22.0.4 from /home/ec2-user/.local/lib/python3.7/site-packages/pip (python 3.7)
$
Pandasのインストール
$ pip install pandas
Defaulting to user installation because normal site-packages is not writeable
Collecting pandas
Downloading pandas-1.3.5-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (11.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 11.3/11.3 MB 100.4 MB/s eta 0:00:00
Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/site-packages (from pandas) (2022.1)
Requirement already satisfied: numpy>=1.17.3 in /home/ec2-user/.local/lib/python3.7/site-packages (from pandas) (1.21.6)
Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.7/site-packages (from pandas) (2.8.2)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/site-packages (from python-dateutil>=2.7.3->pandas) (1.16.0)
Installing collected packages: pandas
Successfully installed pandas-1.3.5
$
Matplotlibのインストール
$ pip install matplotlib
Defaulting to user installation because normal site-packages is not writeable
Collecting matplotlib
Downloading matplotlib-3.5.1-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.whl (11.2 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 11.2/11.2 MB 99.6 MB/s eta 0:00:00
Collecting fonttools>=4.22.0
Downloading fonttools-4.33.3-py3-none-any.whl (930 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 930.9/930.9 KB 91.1 MB/s eta 0:00:00
Requirement already satisfied: packaging>=20.0 in /home/ec2-user/.local/lib/python3.7/site-packages (from matplotlib) (21.3)
Collecting pillow>=6.2.0
Downloading Pillow-9.1.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (4.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.3/4.3 MB 109.1 MB/s eta 0:00:00
Collecting kiwisolver>=1.0.1
Downloading kiwisolver-1.4.2-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.whl (1.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 103.1 MB/s eta 0:00:00
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.7/site-packages (from matplotlib) (2.8.2)
Collecting cycler>=0.10
Downloading cycler-0.11.0-py3-none-any.whl (6.4 kB)
Requirement already satisfied: numpy>=1.17 in /home/ec2-user/.local/lib/python3.7/site-packages (from matplotlib) (1.21.6)
Requirement already satisfied: pyparsing>=2.2.1 in /home/ec2-user/.local/lib/python3.7/site-packages (from matplotlib) (3.0.7)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.7/site-packages (from kiwisolver>=1.0.1->matplotlib) (4.1.1)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0)
Installing collected packages: pillow, kiwisolver, fonttools, cycler, matplotlib
Successfully installed cycler-0.11.0 fonttools-4.33.3 kiwisolver-1.4.2 matplotlib-3.5.1 pillow-9.1.0
$
NumPyのインストール
Admin:~/environment $ pip install numpy
Defaulting to user installation because normal site-packages is not writeable
Collecting numpy
Downloading numpy-1.21.6-cp37-cp37m-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (15.7 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 15.7/15.7 MB 89.4 MB/s eta 0:00:00
Installing collected packages: numpy
Successfully installed numpy-1.21.6
Admin:~/environment $ pip install pandas
データの準備
テストデータのダウンロード
kaggleのサイトから「Iris Dataset」をダウンロードします。
テストデータのアップロード
- JupyterLabを起動し、ファイルをアップロードします。
jupyter lab --port 8080 --ip 0.0.0.0
チュートリアル
ライブラリのインポート
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# pandasの表示数を指定
pd.options.display.max_columns = 32
%matplotlib inline
csvファイルを読み込む
- Pandasの関数でread_csvがある。これによりCSVファイルを読み込んでみます。
Iris = pd.read_csv('./csv/Iris.csv')
- 実行結果は、以下のとおりです。
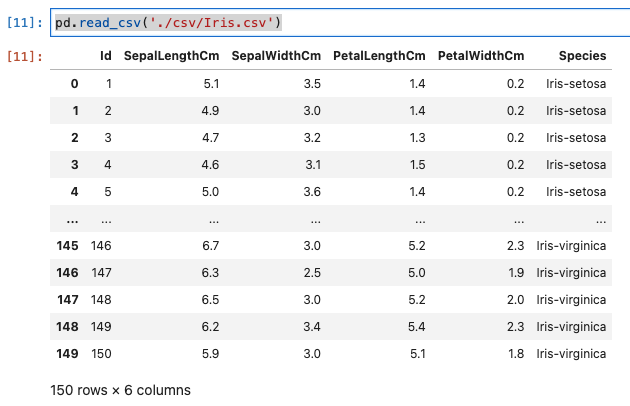
- Sepal Length – がく片の長さ(cm)
- Sepal Width – がく片の幅(cm)
- Petal Length – 花弁の長さ(cm)
- Petal Width – 花弁の幅(cm)
基本的なデータ探索
- どのようなデータが含まれているかざっくりと理解します。
- head()やtail()関数を利用して、ざっくりとデータの概要を掴む。
- データは、150行ありました。
最初の5行
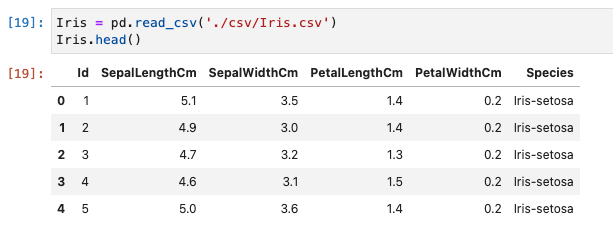
- head関数を使って、最初の5行を読み込みます。
Iris = pd.read_csv('./csv/Iris.csv')
Iris.head()
- 実行結果は、以下のとおりです。
最後の5行
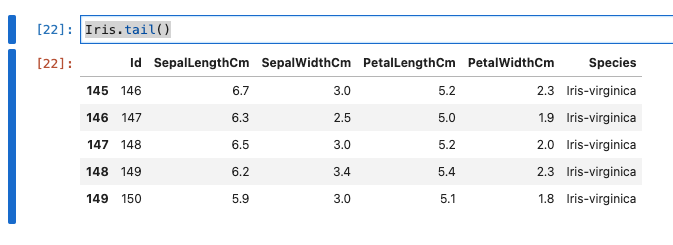
- tail関数を使って、最後の5行を読み込みます。
Iris.tail()
- 実行結果は、以下のとおりです。
任意の行数
- headとtailに引数に表示したい行数を指定すると、任意の行数のデータが確認できます。
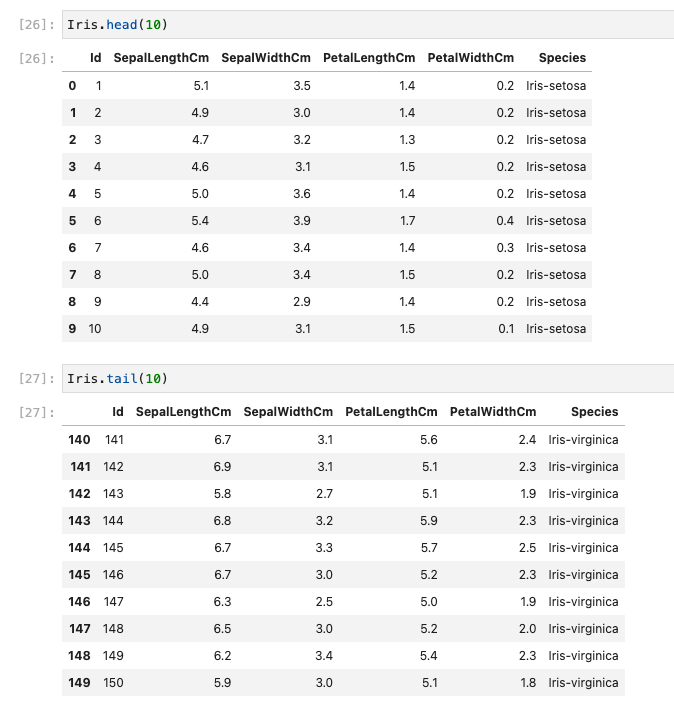
describe
- 統計値が表示され、データセットの特徴がわかります。
- 以下の値がわかる。
- 件数
- 平均、最小、最大
- 標準偏差
- 25%、50%、75%の値
特徴量とアヤメの各種類の関係性を確認
- アヤメの種類毎に特徴はあるのか確認したいと思います。
- データを見て、直感的に把握することが目的。
- 以下のコードにより、確認します。
Irisdes = Iris.groupby(['Species'])
round(Irisdes.describe(),2)
-
groupbyでアヤメの種類を指定
-
roundで、小数点第2位で四捨五入
-
実行結果は以下のとおりです。


- Sepal(がく片)の高さ、幅は大きさに違いはさほど見られない。
- Petal(花弁)の高さに違いが見られる。各項目の値を下記に記載します。
| - | Iris-setosa | Iris-versicolor | Iris-virginica |
|---|---|---|---|
| mean | 1.46 | 4.26 | 5.55 |
| min | 1.0 | 3.0 | 4.5 |
| 25% | 1.4 | 4.0 | 5.1 |
| 50% | 1.50 | 4.35 | 5.55 |
| 75% | 1.58 | 4.60 | 5.88 |
| max | 1.9 | 5.1 | 6.9 |
- Iris-setosaの高さは、最大1.9cm(最小1.0)、Iris-virginicaの高さは、最大6.9cm(最小4.5)
- Iris-setosaの最大値よりも、Iris-virginicaの最小値のほうが高い
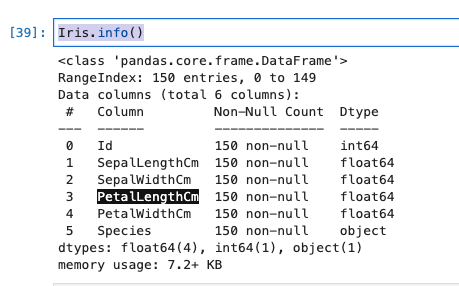
info
- データフレーム全体の要約を表示してくれます。
- これにより、レコード数、カラム毎のカラム名、Not Null(non-null) 件数、データタイプがわかります。
Iris.info()
- 実行結果は、以下のとおりです。
カラムの値を確認する
- データフレーム内のユニークな値を確認します。
Iris.Species.unique()
- 実行結果は、以下のとおりです。

- 値ごとの件数を確認します。
Iris['Species'].value_counts()
- 実行結果は、以下のとおりです。

- SQLの、group by & countのようなものですね。
カラムをデータフレームから削除する
-
機械学習では、データセットの中から使うデータと、使わないデータを判別して処理をすることがあるようです。
-
dropをつかってId列を削除します。
-
まず最初に削除前のデータを確認します。
Iris.head()
- dropにより削除し、列を削除します。なお、axis=1は列を指定。axis=0は行を指定するようです。
Iris = Iris.drop(['Id'],axis=1)
Iris.head()
- Id列が消えました。
データの可視化
- データを直接確認することも重要だが、グラフなどで可視化することで分かることもあるそうです。
- Matplotlibのhist()関数を使用することで、簡単にヒストグラムの作成が可能です。
- binsは階級(ヒストグラムのバー)の数
- figsizeは第一引数が横幅、第二引数が高さ
- colorが色
Iris.hist(bins=15,figsize=(20,10),color='teal')
- 実行結果は、以下のとおりです。
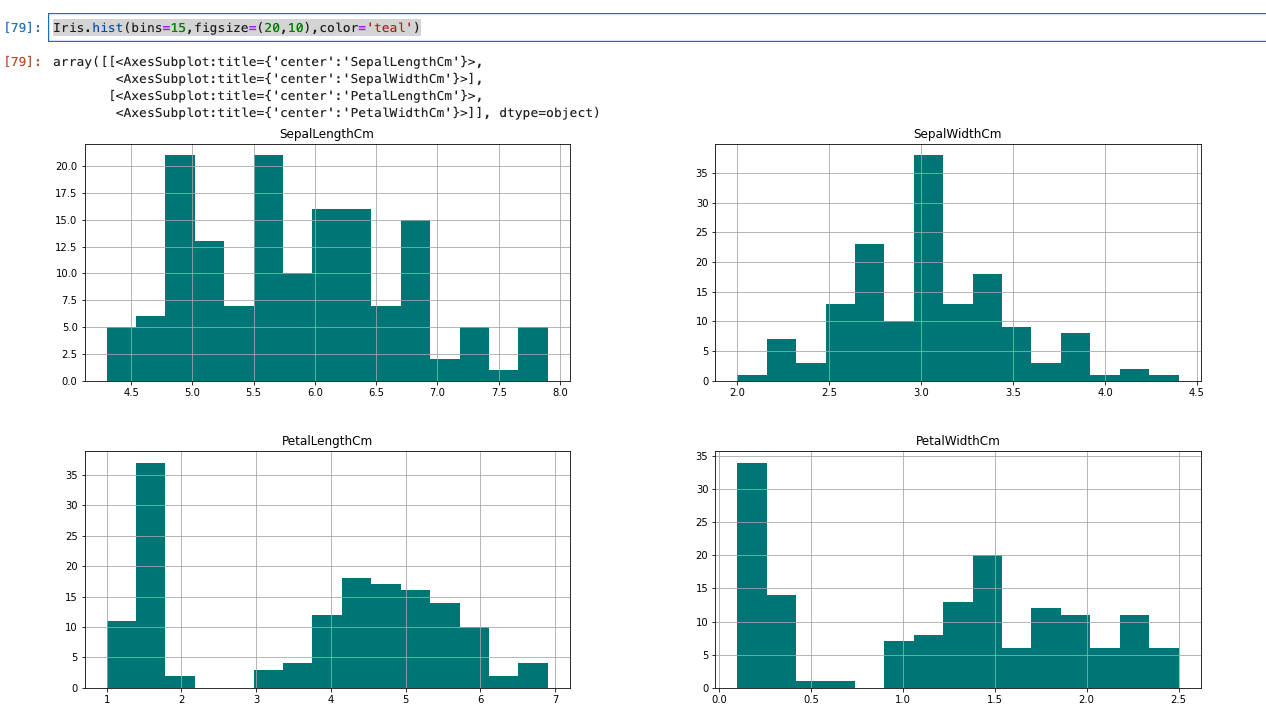
- これにより、がく片が大きく山が2つあることが分かる。
特徴量ごとに重ねたヒストグラムを作って確認
- データ解析がしやすいように、がく片と花弁の高さと幅を3種類のアヤメ毎に分けて重ねて表示します。
Petal Length(花弁の長さ)を確認
fig = plt.figure(figsize=(25,10))
# 2行、2列の1つめ
p1 = fig.add_subplot(2,2,1)
# binsは階級、alphaは透明度
# アヤメごとの値をセットしている。
p1.hist(Iris.PetalLengthCm[Iris.Species == 'Iris-setosa'], bins=10, alpha = .4)
p1.hist(Iris.PetalLengthCm[Iris.Species == 'Iris-versicolor'], bins=10, alpha = .4)
p1.hist(Iris.PetalLengthCm[Iris.Species == 'Iris-virginica'], bins=10, alpha = .4)
# グラフのタイトル
plt.title('Petal Length Cm')
# X軸のラベル
plt.xlabel('Cm Measurement')
# Y軸のラベル
plt.ylabel('Count')
# 各値のラベル名を配列に設定
labels = ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
# 凡例として登録
plt.legend(labels)
# グラフ間の間隔。この時点では、1つしかないので関係なし。
plt.subplots_adjust(wspace=.1, hspace=.3)
# 表示
plt.show()
- 実行結果は、以下のとおりです。
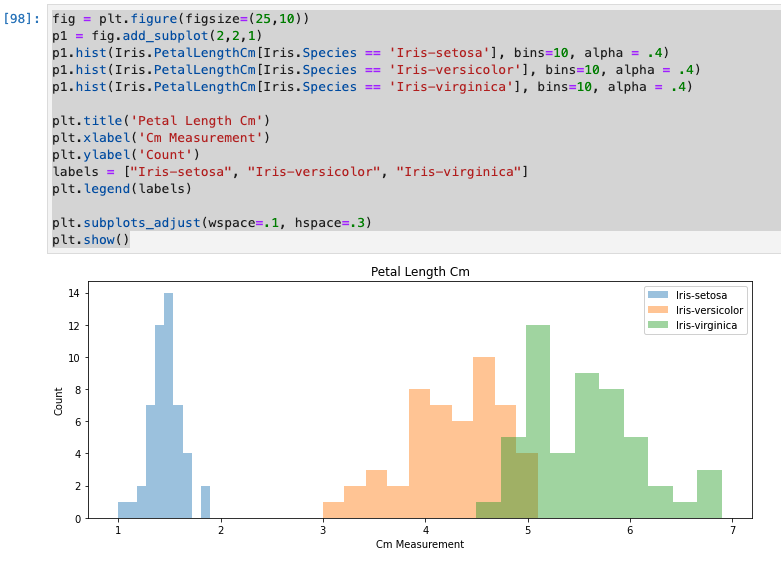
- 確かにわかりやすい。
花弁、がく片の高さと幅全て表示
fig = plt.figure(figsize=(25,10))
p1 = fig.add_subplot(2,2,1)
p1.hist(Iris.PetalLengthCm[Iris.Species == 'Iris-setosa'], bins=10, alpha = .4)
p1.hist(Iris.PetalLengthCm[Iris.Species == 'Iris-versicolor'], bins=10, alpha = .4)
p1.hist(Iris.PetalLengthCm[Iris.Species == 'Iris-virginica'], bins=10, alpha = .4)
plt.title('Petal Length Cm')
plt.xlabel('Cm Measurement')
plt.ylabel('Count')
labels = ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
plt.legend(labels)
p2 = fig.add_subplot(2,2,2)
p2.hist(Iris.PetalWidthCm[Iris.Species == 'Iris-setosa'], bins=10, alpha = .4)
p2.hist(Iris.PetalWidthCm[Iris.Species == 'Iris-versicolor'], bins=10, alpha = .4)
p2.hist(Iris.PetalWidthCm[Iris.Species == 'Iris-virginica'], bins=10, alpha = .4)
plt.title('Petal Width Cm')
plt.xlabel('Cm Measurement')
plt.ylabel('Count')
plt.legend(labels)
p3 = fig.add_subplot(2,2,3)
p3.hist(Iris.SepalLengthCm[Iris.Species == 'Iris-setosa'], bins=10, alpha = .4)
p3.hist(Iris.SepalLengthCm[Iris.Species == 'Iris-versicolor'], bins=10, alpha = .4)
p3.hist(Iris.SepalLengthCm[Iris.Species == 'Iris-virginica'], bins=10, alpha = .4)
plt.title('Sepal Length Cm')
plt.xlabel('Cm Measurement')
plt.ylabel('Count')
labels = ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
plt.legend(labels)
plt.title('Sepal Length Cm')
p4 = fig.add_subplot(2,2,4)
p4.hist(Iris.SepalWidthCm[Iris.Species == 'Iris-setosa'], bins=10, alpha = .4)
p4.hist(Iris.SepalWidthCm[Iris.Species == 'Iris-versicolor'], bins=10, alpha = .4)
p4.hist(Iris.SepalWidthCm[Iris.Species == 'Iris-virginica'], bins=10, alpha = .4)
plt.title('Sepal Width Cm')
plt.xlabel('Cm Measurement')
plt.ylabel('Count')
labels = ["Iris-setosa", "Iris-versicolor", "Iris-virginica"]
plt.legend(labels)
plt.subplots_adjust(wspace=.1, hspace=.3)
plt.show()
- 実行結果は、以下のとおりです。
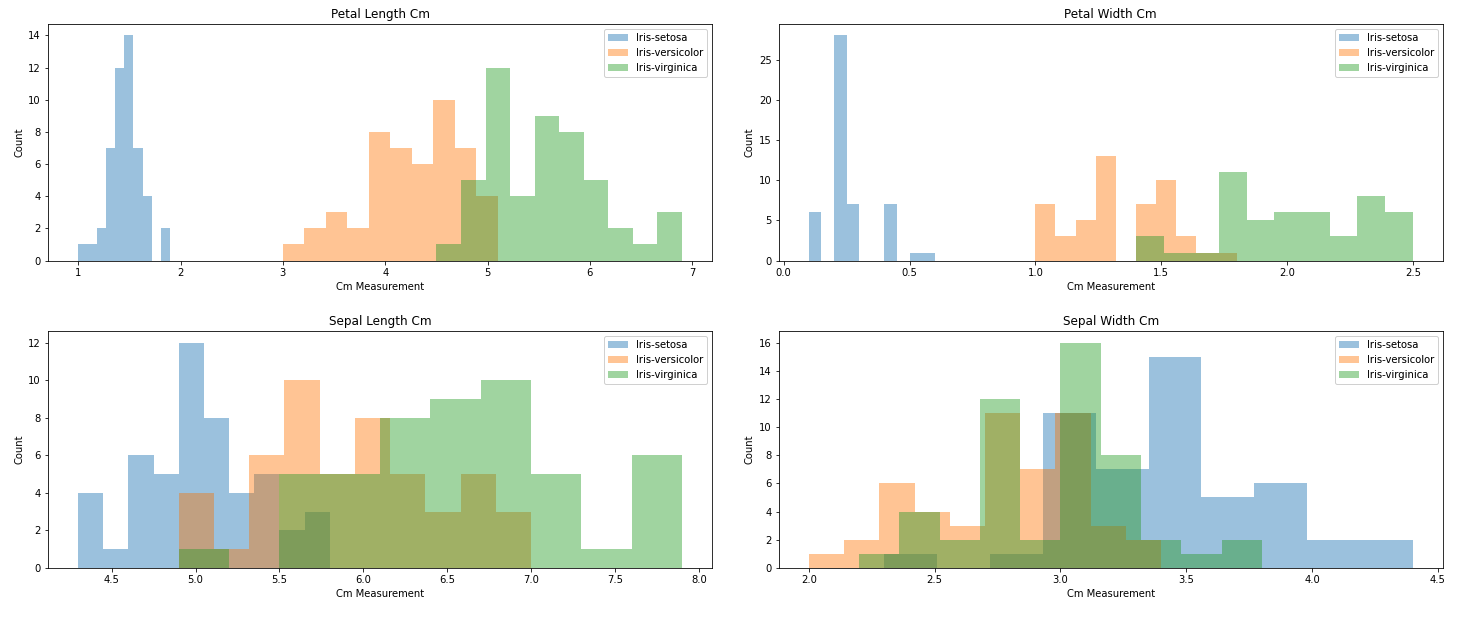
- こう見ると、各アヤメのPetalの長さと幅の範囲が別れていることが分かりました。
- 可視化すると一発で分かりますね。
散布図(スキャタープロット)で相関関係を可視化する
- 散布図により、2つの特徴量の相関関係を可視化することができます。
from pandas.plotting import scatter_matrix
# alphaは透明度。matplotlib.pyplotと同じ。
# figsizeは、第一引数が幅、第二引数が長さ。
# diagonalは、対角線上のヒストグラムプロットをヒストグラムを指定している。
x = scatter_matrix(Iris, alpha=1, figsize=(20, 10), diagonal='hist')
- 実行結果は、以下のとおりです。
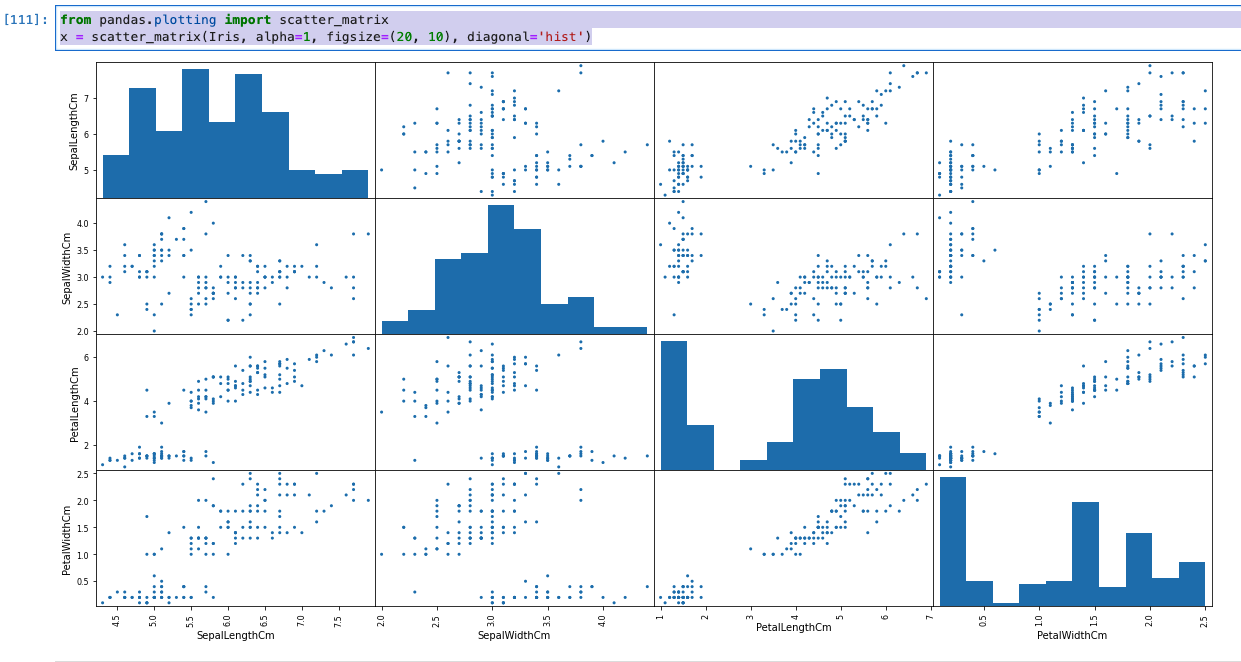
- やはり、PetalWidthとPetalLengthには強い相関があることが分かる。
- 一方、SepalWidthとSpealLengthにはそれほど、強い相関はない。
データフレームのフィルタリングとSELECT
- 詳細を確認する場合に、フィルタリングをかけることがあるようです。
行インデックスが6-20までを表示
Iris[6:20]
- 実行結果は、以下のとおりです。

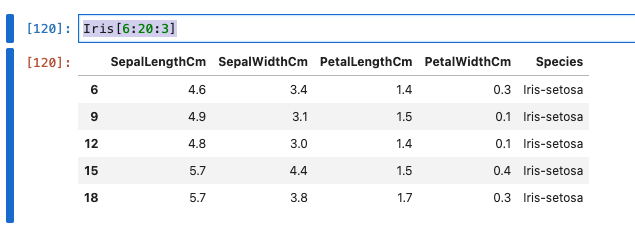
行インデックスが6-20までを3間隔で表示
Iris[6:20:3]
- 実行結果は、以下のとおりです。
カラムに値を指定してフィルタリング
Iris[Iris.Species=='Iris-setosa'][0:100:10]
- 実行結果は、以下のとおりです。
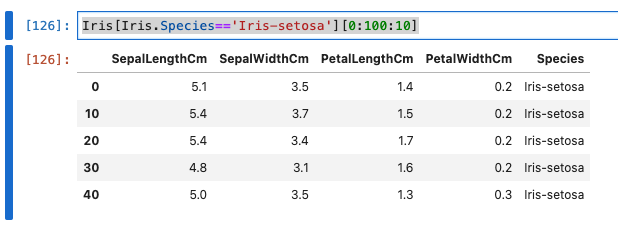
- 一つのアヤメの種類は50個までなので、10間隔で表示した場合、5行しか表示されませんね。
詳細なフィルタリング
- 条件を組み合わせます。
Iris[(Iris.Species=='Iris-setosa') & (Iris.SepalLengthCm > 5.5)]
- 実行結果は、以下のとおりです。
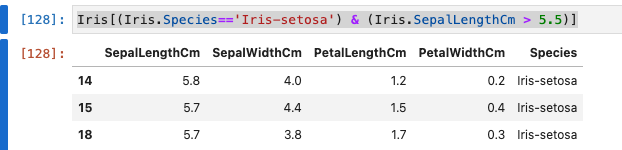
必要なカラムだけ絞る
- 上記のフィルタリングに加えて、カラムを絞り込んでみます。
Iris[['Species','SepalLengthCm','SepalWidthCm']][(Iris.Species=='Iris-setosa') & (Iris.SepalLengthCm > 5.5)]
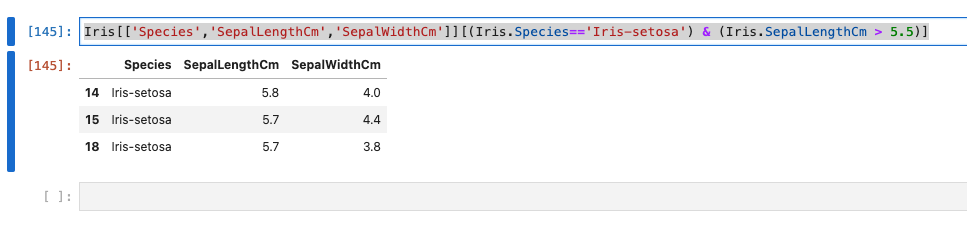
ソート
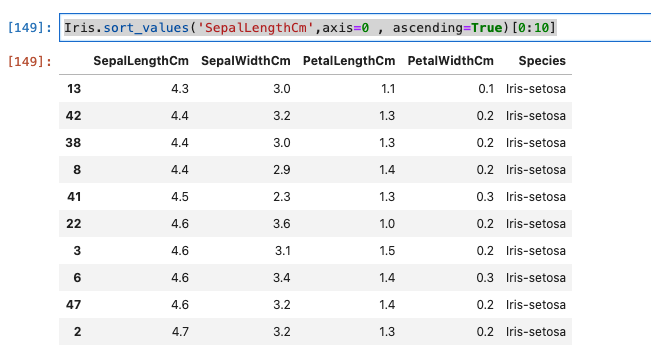
昇順
Iris.sort_values('SepalLengthCm',axis=0 , ascending=True)[0:10]
- 実行結果は、以下のとおりです。
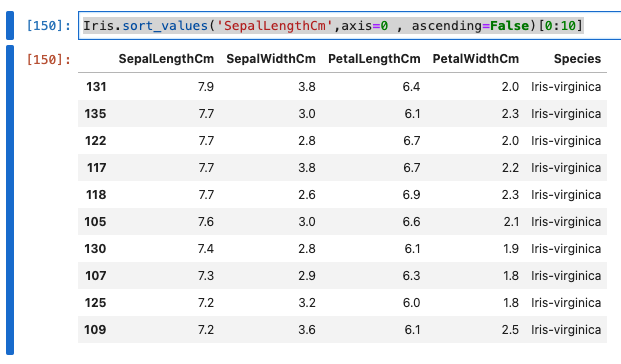
降順
Iris.sort_values('SepalLengthCm',axis=0 , ascending=False)[0:10]
- 実行結果は、以下のとおりです。
外れ値の確認
メモ
機械学習で使うアルゴリズムでほとんどのケースで、データに欠損があると正常または、全く動かないらしいです。
モデル構築する際には、データセットの欠損を探して、何かしらの値で代入したり、データを削除したりするそうです。
- 欠損を確認します。データセットでnullを探す場合、isnull()関数を使います。
- 実際の仕事では、データに欠損がないのは珍しいとのこと。
Iris.isnull().any()
- 実行結果は、以下のとおりです。

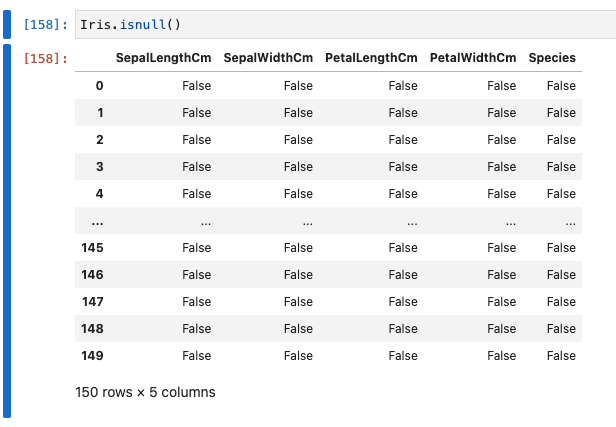
- 今回のケースでは、nullは有りませんでした。
考察
- データの特徴を深く理解するために、探索的データ解析が有効だと感じました。
- 特に可視化では、自分は普段データエンジニアとして、パフォーマンスチューニングのためのテストデータの作成なども行うのですが、そのデータを可視化してプレゼンするなどにも利用できそうだと感じました。
- Jupyterは、対話的にデータ探索のような調査したり可視化するのに適したツールとも感じました。
参考