背景・目的
私は、現在データエンジニアリングを生業としています。普段は、データ基盤の構築やパフォーマンスチューニングなどに従事しています。
ビックデータの収集や、蓄積、分析などの環境構築の経験はそこそこありますが、機械学習による予測や分類などのスキルは持ち合わせていませんでした。
今まで機械学習を避け続けてきましたが、一念発起し学ぼうと思います。
学び方としては、AWS Certified Machine Learning – Specialty(以降、ML試験という。)の勉強を通して、理解を深めていこうと思います。
ML試験のガイドを読むと、第2分野に探索的データ解析が出ていましたので、そこから学びたいと思います。
以前、以下について学習を進めてきましたが、今回はデータの拡張について学びたいと思います。
まとめ
- 画像認識の機械学習には、大量の画像が必要になりますが、一般的に大量の画像を用意するのは難しいです。
- そのため、大量の学習データ(画像)を用意する技法として、データ拡張があります。
- また、偏ったデータによる機械学習が適合しすぎる「過学習」の課題を解決する手段としても用いられるとのこと。
- ただし、やみくもにデータ拡張すればよいかというものでもなく、ありえない拡張や、異なる画像同士の過学習を引き起こさないように注意が必要。
- データ拡張では、オフライン拡張とオンライン拡張があり、データ容量の問題などからオンライン拡張が一般的に利用されているとのことでした。
データ拡張の種類
- kerasを使ったデータ拡張の種類について、以下に整理します。
| 拡張種類 | 説明 | パラメータ |
|---|---|---|
| 画像の回転 | 説明省略 | rotation_range |
| 左右平行移動 | 画像を左右に、指定された値の範囲で移動させます。 | width_shift_range |
| 上下平行移動 | 上記の左右版 | height_shift_range |
| 拡大と縮小 | 説明省略 | zoom_range |
| 画像のせん断 | 平行四辺形に変形させます。 | shear_range |
| 画像の補間 | 枠内に合わない場合に、補完します。全部で4種類あり。詳細は本文参照。 | fill_mode |
| 左右反転 | 説明省略 | horizontal_flip |
| 上下反転 | 説明省略 | vertical_flip |
| 明るさの調整 | 説明省略 | Brightness_range |
| チャンネルシフト | 画像のRGBを変更します。 | channel_shift_range |
| 画素値のリスケーリング | 上記のチャンネルシフトと似ている。 | rescale |
| データセット全体の平均を0にする | 画素数の平均を0にします。 | featurewise_center |
| 各サンプルの平均を0にする | 各サンプルの入力の画素値平均を0にします。 | samplewise_center |
| データセット全体の標準偏差を1にする | データセット全体の入力の標準偏差を1にします。 | featurewise_std_normalization |
| 各サンプルの標準偏差を1にする | 上記とほぼ同じ。 | samplewise_std_normalization |
概要
過去と同様に、codexaさんの記事で学んでいきたいと思います。今回は、「データ拡張(Data Augmentation)徹底入門!Pythonとkerasでデータ拡張を実装しよう」を参考に学習していきます。
大変わかりやすく勉強になります。助かっています。
データ拡張入門
- 機械学習では、特にディープラーニングでは、大量の画像が必要になります。しかし、数百枚、数千枚の画像を収集するとなると容易ではありません。
有名なCelebAのデータセットには202,599枚もの有名人の顔画像が用意されています。
- 知りませんでしたが、CelebA(CelebFace Attributes)というサイトがあるんですね。
一般的には、このサイトほど大量のデータセットを保有しているわけではないので、手持ちでどうにか増やす手段を考える必要があるとのことです。 - データを増やす手段の一つとして、Data Augumation(データ拡張)というものがあるようです。
前提知識
- 機械学習で画像を扱う上で、データ拡張の一部分でしかなく、可能なら画像認識の知識などがあることが望ましいようです。
- 私はなんとなくでしかしりませんが、一旦このまま進めます。なお、codexaさんの記事で以下を紹介していました。
Data Augmentationとは
- 学習用の画像データに対して「変換」を施すことでデータを水増しする手法とのことです。
- codexaさんのサイトでは、パンケーキを使った例で、1枚の写真を全体が写っているもの、左半分に移動したもの、拡大、回転、上移動など、同一画像を水増ししていました。これが、Data Agumentationによる画像の水増しとのこと。
- なお使用されている画像は、フリー写真素材ぱくたそのものを使用しているとのこと。
Data Agumentationの種類
- 変換だけではなく、生成もあるとのことです。生成はGAN(Generative Adversarial Networks)の技術を利用するようです。
- 参考:敵対的生成ネットワーク
Data Augmentationの必要性
データ数の増加
近年のニューラルネットワーク(特にCNN)による画像認識技術はとても進歩しています。同時に、開発されたモデルの中にはとても深い層をもつものもあります。そういったモデルの中には多くのパラメータを有するものもあり、学習のために大量のデータが必要とされる場合があります。
- CNNに代表される画像認識技術では、モデルにより深い層をもつものがあり、多くのパラメータを有し学習のために大量データが必要とのことです。
- しかし、プライバシーに関わるようなデータなど、簡単に集めることが出来ないため、Data Agumentationの技術が必要になるとのことです。
過学習への対策
- 「学習用データに機械学習モデルが適合しすぎることにより、テストデータに対する適合率が下がる」ことを指すようです。
- どれだけ学習用データに対して高精度のモデルが完成したとしても、テストデータに対して精度が低ければ意味がないとのこと。
- codexaさんの記事では、犬と猫を画像から識別する例で、以下の懸念がありました。
- それぞれの画像では、左向きが猫、右向きが犬となっており、すべての画像がそれぞれの向きだった場合の学習により、向いている方向により、予測時には犬と猫を識別してしまう可能性がある。
- テスト時に、それぞれ反対の画像が与えられると、間違った判断をする可能性がある。
- 解決策として、画像を反転させて学習させることにより、テスト時にどちらの向きの画像を与えられても正しく分類できる可能性が高まる。
- 数が多いこと、データの質が高いことは別。データが多くても偏ったデータの場合がある。
Data Augmentationの注意点
- 万能ではなく、有効でないData Augmentationとしては以下の点が挙げられます。
- データセットに合わない変換
- 過学習
データセットに合わない変換
- Data Augmentationは画像に対して様々な変換を施すことで、データを水増しするが、考えなしで闇雲に変換すれば良いわけでは無いとのこと。
- 変換によっては逆にモデルの精度を下げる可能性もあるようです。
- codexaさんの記事では、電車と数字の「4」の画像を例に上げており、ありえない画像を水増しすることでの悪影響を示していました。
- 電車が上下逆さまの画像。(電車が逆さになるのは、事故以外でありえない。)
- 数字の4の反転の画像。(4として成立しない。)
過学習
- 上述した、「Data Augmentationの必要性」ではData Augmentationは過学習を防ぐために有効であると記載したが、逆もありえるとのことです。
学習用データに「似た特徴」を与えてしまう可能性があることです。画像の変換によって増えた画像はある程度似た画像になります。そのため、モデルがそれらの画像に過剰に適合すると、過学習を引き起こす可能性があります
- これは、具体的にはイメージが出来なかったが、増やすことで別々の画像でも同一として判断されやすいということか?
- 過学習を避けながら、複雑なモデルを使用する場合や高精度の評価を得たい場合には、質のいいデータがある程度存在することが望ましいとのことです。
Data Augmentationのタイミング
今後Data Augmentationを実装していく際は、keras(本稿でも使用)やPyTorch(以下の記事を参考)を使うことが多くなるかと思います。その際に感じるのが、Data Augmentationがどのタイミングで行われているか分かりにくいということです。さらに、その部分が分からないまま学習を進めるとData Augmentationを間違えて理解してしまう可能性があります。
- keras、PyTouchによりData Agumentationを実装する事が多く、その際に、どのタイミングで行われるか分かりづらいとのこと。
オフライン拡張
- データセットに存在する画像自体にData Augmentationを適用し、単純に画像の枚数を増やす手法とのこと。
- codexaさんの記事では、回転の変換を加えた例をあげている。
- 比較的、小さなデータセットの場合に適応されるとのことだが、この記事の著者は使ったことがないとのことでした。
- オフライン拡張では、データセットの容量が増加する点が注意点とのこと。画像のデータセットは大きく、それを単純に増やすと大容量のデータを保存できる領域が必要になる。(クラウドであれば、容量確保は問題ないだろうが、コストにも関わってくる。)
- データを増やす際には注意が必要。
オンライン拡張
- オンザフライ拡張(On-the-fly Augmentation)とも呼ばれているようです。
- オフライン拡張に比べて比較的一般的とのことです。
オンライン拡張を理解するためにはミニバッチ学習という言葉を理解する必要があります。簡単に記載すると、データセットを複数に分割したものを使用して学習を行うことです。一般的にディープラーニングではモデルを学習させる際にデータセットを複数のミニバッチに分割し、ミニバッチごとに学習を行います。オンライン拡張は、モデルに入力するミニバッチに対してData Augmentationを適用します。
- データセットを複数に分割し、ミニバッチという単位で学習し、モデルに入力するミニバッチ単位に、Data Agumentationを実施し、学習毎にランダムな、画像が生成されるとのことです。
エポックを複数にして学習を行えば、同じミニバッチでも違う画像を使用することができます。これにより、モデルからするとより多くの画像を学習に使用することができることになります。
- エポックとは、一つの訓練データを何回繰り返して学習させるかのことのようです。
- 上記があまり理解できていませんが、一回目のミニバッチで、一つの訓練データを使い、次のミニバッチで、元の画像から違う画像を生成して学習するということかなと。
- 後は、実装して確認してみたいと思います。
実践
- 実装は、kearsと呼ばれるニューラルネットワークのライブラリを用いる。
- 題材では、ハードウェアアクセラレータをGPUにすることとあります。インスタンスタイプとディスクサイズも変更しました。

準備
パッケージのインストール
- tensorflowをインストールします。
- tensorflowでは、動かなかったので、tensorflow-gpuをインストールしたら動きました。
- 両方必要なのか、tensorflow-gpuのみでよいかは、確認していません。
pip install tensorflow
pip install tensorflow-gpu
- kerasをインストールします。
pip install keras
画像の準備
ダウンロードとアップロード
- 上記でご紹介したフリー写真素材ぱくたそさんのサイトで、パンケーキの素材をダウンロードします。
利用に際して注意点
- こちらをご参考にされる方は、ぱくたそさんの利用規約を十分にご確認いただき、ご自身の責任の範囲にて作業してください。
- 損害や不具合等発生したとしても、当方では一切の責任を負いかねますのでご注意ください。
- Jupyterlabにアップロードします。
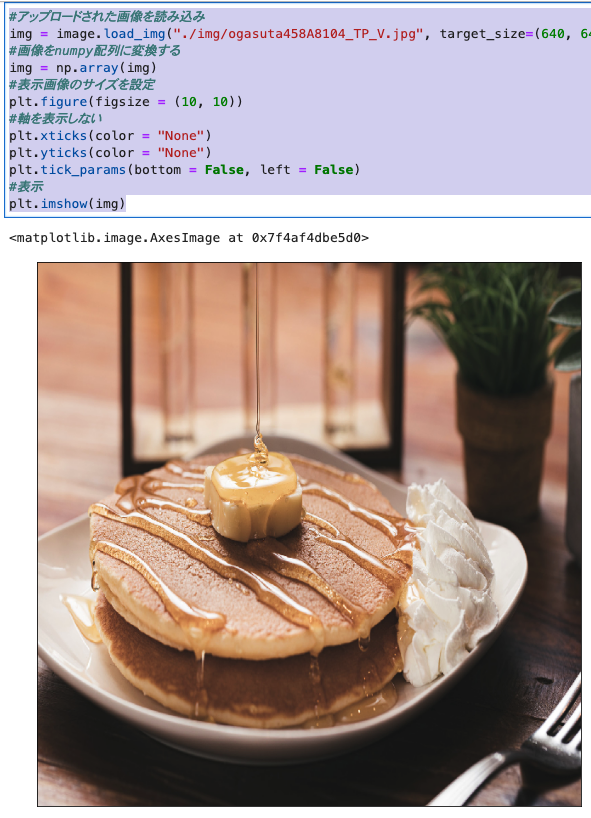
Jupyterlabで表示
#アップロードされた画像を読み込み
img = image.load_img("./img/ogasuta458A8104_TP_V.jpg", target_size=(640, 640))
#画像をnumpy配列に変換する
img = np.array(img)
#表示画像のサイズを設定
plt.figure(figsize = (10, 10))
#軸を表示しない
plt.xticks(color = "None")
plt.yticks(color = "None")
plt.tick_params(bottom = False, left = False)
#表示
plt.imshow(img)
- 表示されました。(パンケーキが食べたくなります。)
ImageDataGeneratorクラスについて
ImageDataGeneratorは、kerasが持つData Augmentationを行うためのクラスです。本稿ではこちらを用いてData Augmentationを実装していきます。ImageDataGeneratorクラスには様々な画像の変換がまとめて実装できるようになっています。以下のコードはImageDataGeneratorクラスのデフォルト引数になります。この中の引数の内、比較的よく使うものを中心に解説していきます。
- ImageDataGeneratorは、kerasが持つData Augmentationを行うクラス
- ImageDataGeneratorクラスには様々な画像の変換がまとめて実装できる
ImageDataGeneratorのメソッドについて
ImageDataGeneratorクラスはメソッドを使用してデータを受け取り、Data Augmentationを適用します。適用するときのメソッドは与えられるデータ形式によります。データに合わせて利用してください。本稿では画像はnumpyの配列として与えられているので、flowメソッドを使用します。これらのメソッドにも引数があります。また、他のメソッドも存在しますが、本稿の目的とは少しずれてしまうため、主要なメッソド以外は記載しません。ImageDataGeneratorクラスの他のメソッドに興味がある方はkerasの公式ドキュメントを参考にしてみてください。(参考:keras公式:ImageDataGenerator)
画像表示の準備
- 実際に画像処理を行う前に、画像表示用の関数を定義します。
- 各変換に対して、6枚の変換後の画像が表示されるようにします。
- 変換がランダムに行われるため、1枚では変換していない画像が表示される可能性がある。
- flowメソッドのseed値は固定しているので、表示される6枚の画像は何度同じセルを実行しても同様になります。
#画像表示用の関数を定義
def show(datagen, img):
#表示サイズを設定
plt.figure(figsize = (10, 5))
#画像をbatch_sizeの数ずつdataに入れる
#本稿は画像が一枚のため同じ画像がdataに入り続けることになる
for i, data in enumerate(datagen.flow(img, batch_size = 1, seed = 0)):
#表示のためnumpy配列からimgに変換する
show_img = array_to_img(data[0], scale = False)
#2×3の画像表示の枠を設定+枠の指定
plt.subplot(2, 3, i+1)
#軸を表示しない
plt.xticks(color = "None")
plt.yticks(color = "None")
plt.tick_params(bottom = False, left = False)
#画像を表示
plt.imshow(show_img)
#6回目で繰り返しを強制的に終了
if i == 5:
return
次にパンケーキの画像配列(img)に次元を1つ追加します。これはこの後使用するImageDataGeneratorクラスの入力が4次元である必要があるためです。現在imgの配列は640×640×3(縦×横×チャンネル数)になっています。これを1×640×640×3にします。この「1」は「データセット内の何番目の画像ですか?」という情報です。今回のデータセットには画像が1枚しかないと仮定するので1を追加します。
- ImageDataGeneratorクラスの入力が4次元のため、1次元追加する。
- データセットは画像が1枚しかないと仮定するので1を追加します。
#パンケーキの画像配列の形
print(img.shape)
#配列に次元を追加
img_cake=img[np.newaxis, :, :, :]
#次元追加後の配列の形
print(img_cake.shape)
- 実行結果は、以下のとおりです。

画像の回転(rotation_range)
- 画像の出力が同じではない。同じバッチでも違う変換が行われている。
- 1枚の画像が6枚になっているように見える。他の変換でも同様とのこと。
- 画像の回転の引数はrotation_rangeで設定されます。
#-180度〜+180度の間でランダムに回転するImageDataGeneratorを作成
rotation_datagen = ImageDataGenerator(rotation_range = 180)
#画像を表示
show(rotation_datagen, img_cake)
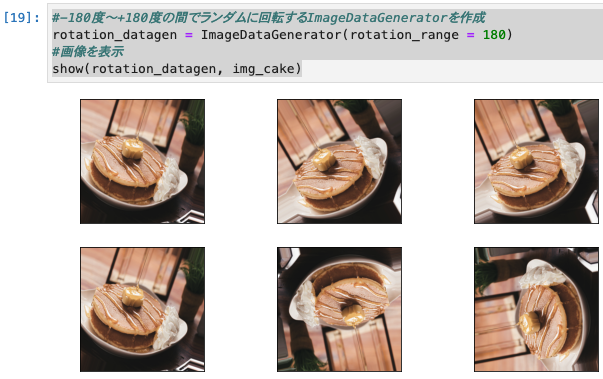
- おお、 表示されましたね。なんか感動。
rotation_datagen = ImageDataGenerator(rotation_range = 120)
#画像を表示
show(rotation_datagen, img_cake)
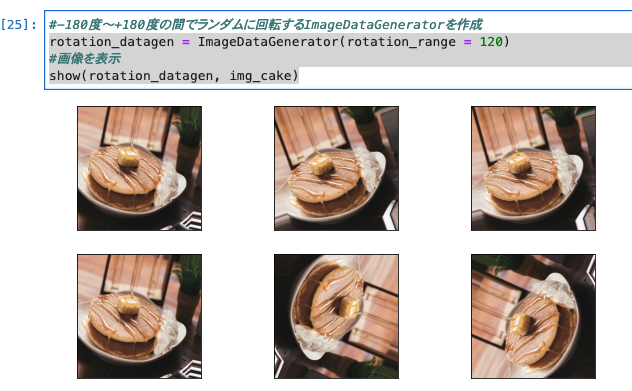
- 120度に変更してみました。確かに角度が少し変わりましたね。
左右平行移動(width_shift_range)
- 左右平行移動では、引数はwidth_shift_rangeで設定します。
- int型(50)の場合→指定されたピクセル(-50〜+50)の範囲で左右にランダムに動かします。
- list型([50,100])の場合→指定されたピクセル(-100,-50,+50,+100)の内、左右にランダムに動かします。
- float型(0.5)の場合→指定された値×画像の横幅(-320〜+320)の範囲で左右にランダムに動かします。
int型の例
#指定されたピクセル(-50〜+50)の範囲で左右にランダム
width_datagen = ImageDataGenerator(width_shift_range = 50)
show(width_datagen, img_cake)

list型の例
# 指定されたピクセル(-100,-50,+50,+100)の内、左右にランダムに動かします。
width_datagen = ImageDataGenerator(width_shift_range = [50,100])
show(width_datagen, img_cake)

float型の例
#-320〜+320の間でランダムに左右平行移動するImageDataGeneratorを作成
width_datagen = ImageDataGenerator(width_shift_range = 0.5)
show(width_datagen, img_cake)

上下平行移動(height_shift_range)
- 引数はheight_shift_rangeで設定します。
- int型(50)の場合→指定されたピクセル(-50〜+50)の範囲で上下にランダムに動かします。
- list型([50,100])の場合→指定されたピクセル(-100,-50,+50,+100)の内、上下にランダムに動かします。
- float型(0.5)の場合→指定された値×画像の縦幅(-320〜+320)の範囲で上下にランダムに動かします。
int型の例
# 指定されたピクセル(-50〜+50)の範囲で上下にランダムに動かします。
height_datagen = ImageDataGenerator(height_shift_range = 50)
show(height_datagen, img_cake)

list型の例
# 指定されたピクセル(-100,-50,+50,+100)の内、上下にランダムに動かします。
height_datagen = ImageDataGenerator(height_shift_range = [50,100])
show(height_datagen, img_cake)

float型の例
#-320〜+320の間でランダムに上下平行移動するImageDataGeneratorを作成
height_datagen = ImageDataGenerator(height_shift_range = 0.5)
show(height_datagen, img_cake)

拡大と縮小(zoom_range)
- 引数はzoom_rangeで設定します。
- float型(0.5)の場合→「1-指定された値」(0.5)〜「1+指定された値」(1.5)の範囲で拡大又は縮小します。
- list型([0.5,1.5])の場合→指定された値(0.5〜1.5)の範囲で拡大又は縮小します。
#0.5〜1.5の間でランダムに拡大又は縮小するImageDataGeneratorを作成
zoom_datagen = ImageDataGenerator(zoom_range = [0.5, 1.5])
show(zoom_datagen, img_cake)

画像のせん断(shear_range)
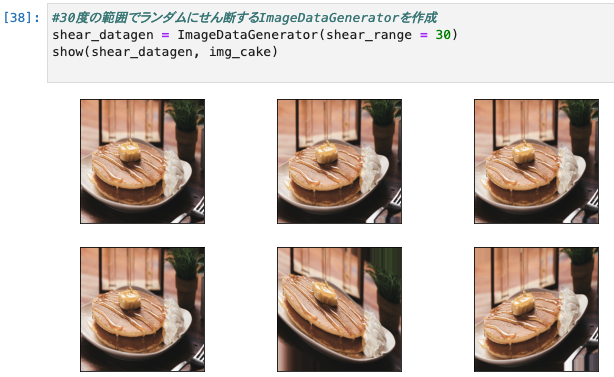
- せん断とは、四角形の画像を平行四辺形に変形する処理です。引数はshear_rangeで設定します。
- 引数のshare_rangeにはシアー角度を設定します。
- float型(30)の場合→指定されたシアー角度(30度)でせん断します。
#30度の範囲でランダムにせん断するImageDataGeneratorを作成
shear_datagen = ImageDataGenerator(shear_range = 30)
show(shear_datagen, img_cake)
画像の補間方法(fill_mode)
- 入力画像が枠内に合わない場合の補間方法にはいくつかの種類が存在します。全部で4種類存在します。引数はfill_modeで設定します。
- 「nearest」→一番近くの画素値で補間(デフォルト)
- 「constant」→定数で補間
- 「reflect」→反転して補間
- 「wrap」→繰り返しで補間
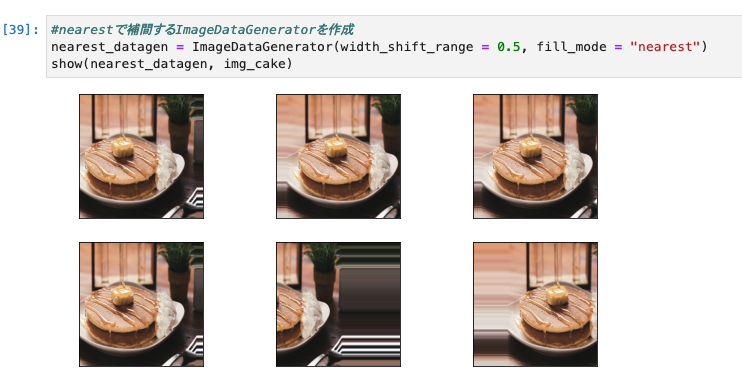
1.nearest
- 「aaaaaaa|abcd|ddddddd」のように一番近い画素値で外側を補完する方法
- この記事の著者は、デフォルトのこちらの補完を使用されているそうです。
#nearestで補間するImageDataGeneratorを作成
nearest_datagen = ImageDataGenerator(width_shift_range = 0.5, fill_mode = "nearest")
show(nearest_datagen, img_cake)
2.constant
- 「xxxxxxx|abcd|xxxxxxx」のように画像にかかわらず特定の値で補間できます。
- 今回の実装例では0に設定することで黒にしているとのことです。
- 補間する際の値の指定は「cval」引数を追加することで実現でき、補間を黒に設定することで、テストの際など、画像がどの程度傾いているかなど非常にわかりやすく表示することができる。とのことです。
#constantで補間するImageDataGeneratorを作成
constant_datagen = ImageDataGenerator(width_shift_range = 0.5, fill_mode = "constant", cval = 0)
show(constant_datagen, img_cake)

- ちなみに、-1を設定することで、白になりました。

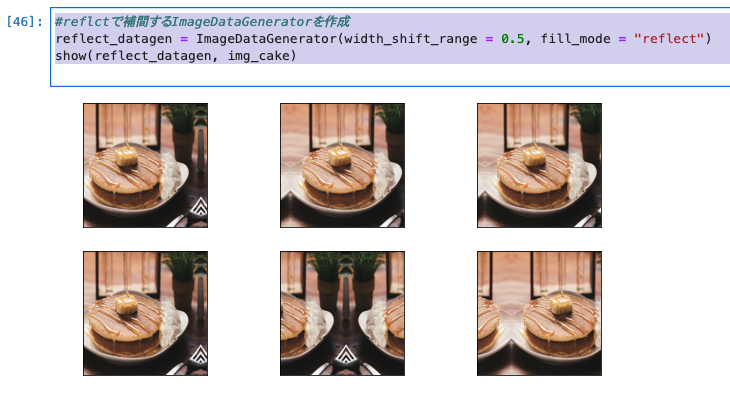
3.reflect
- reflectは画像に対して反転した画素で補間する方法です。「fill_mode = reflect」で実装できます。
- 「abcddcba|abcd|dcbaabcd」のように反転された画像が映ります。
#reflctで補間するImageDataGeneratorを作成
reflect_datagen = ImageDataGenerator(width_shift_range = 0.5, fill_mode = "reflect")
show(reflect_datagen, img_cake)
4.wrap
- 画像に対して繰り返すような画素で補間する方法です。
- 「fill_mode = wrap」で実装でき、「abcdabcd|abcd|abcdabcd」のように反転された画像が映ります。
#wrapで補間するImageDataGeneratorを作成
wrap_datagen = ImageDataGenerator(width_shift_range = 0.5, fill_mode = "wrap")
show(wrap_datagen, img_cake)

左右反転(horizontal_flip)
- 画像の左右反転です。引数はhorizontal_flipで設定します。
#ランダムに画像を左右反転するImageDataGeneratorを作成
horizontal_datagen = ImageDataGenerator(horizontal_flip = True)
show(horizontal_datagen, img_cake)

上下反転(vertical_flip)
- 画像の上下反転です。
- 引数はhorizontal_flipで設定します。
- 画像の向きや性質によっては使うことの多い変換とのことです。
- 使い方は左右反転と全く同じ。しかし、上下画像の反転は左右反転に比べて汎用性が低い場合が多ので注意が必要 とのことです。
- 前述した、「データセットに合わない変換」で、電車が逆さにした例がこれに、当てはまりますね。
#ランダムに画像を上下反転するImageDataGeneratorを作成
vertical_datagen = ImageDataGenerator(vertical_flip = True)
show(vertical_datagen, img_cake)

明るさの調整(Brightness_range)
- 明るさの調整です。引数はBrightness_rangeで設定します。
- 画像の明るさを変更できるため、画像自体が暗すぎる場合や明るすぎる場合に便利とのこと。
- Tupleとlist型があるようです。
- Tuple型((0.3,0.8))→指定した値の範囲(0.3〜0.8)でランダムに明るさを調整(1.0以下は暗く、1.0以上は明るくなる)
- list型([0.3,0.8])→指定した値の範囲(0.3〜0.8)でランダムに明るさを調整(1.0以下は暗く、1.0以上は明るくなる)
#画像の明るさを0.3〜0.8の間で調整(暗くする)
brightness_datagen = ImageDataGenerator(brightness_range = [0.3, 0.8])
show(brightness_datagen, img_cake)

チャンネルシフト(channel_shift_range)
- チャンネルシフトとは画像を構成するRGBのチャンネルの値を変更すること。
- 現在の設定は以下のとおりです。
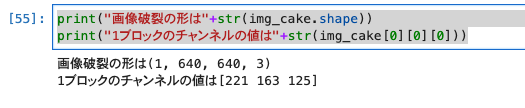
print("画像破裂の形は"+str(img_cake.shape))
print("1ブロックのチャンネルの値は"+str(img_cake[0][0][0]))
1.float型(100.0)の場合→指定した値(-100〜+100)値でチャンネルの範囲でチャンネルをシフトします。
#-100〜100の間でランダムにチャンネルシフトするImageDataGeneratorを作成
channel_datagen = ImageDataGenerator(channel_shift_range = 100)
show(channel_datagen, img_cake)

画素値のリスケーリング(rescale)
- 引数はrescaleで設定します。この値を設定すると他の変換を適応する前に指定した値を乗算します。
#各画素値を0〜1に収めるImageDataGeneratorを作成
rescale_datagen = ImageDataGenerator(rescale = 1./255)
show(rescale_datagen, img_cake)

- 全て真っ黒になった。次に半分くらいの明るさにしてみる。
rescale_datagen = ImageDataGenerator(rescale = 127.5/255)
show(rescale_datagen, img_cake)

データセット全体の平均を0にする(featurewise_center)
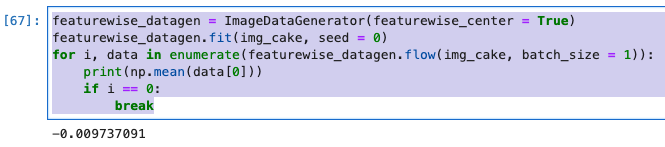
- featurewise_centerは与えられたデータセット全体の入力の画素値平均を0にします。負の値も持った上で画像を表現することができます。
- ニューラルネットワークなどに対する前処理などに使用できます。
featurewise_datagen = ImageDataGenerator(featurewise_center = True)
featurewise_datagen.fit(img_cake, seed = 0)
for i, data in enumerate(featurewise_datagen.flow(img_cake, batch_size = 1)):
print(np.mean(data[0]))
if i == 0:
break
各サンプルの平均を0にする(samplewise_center)
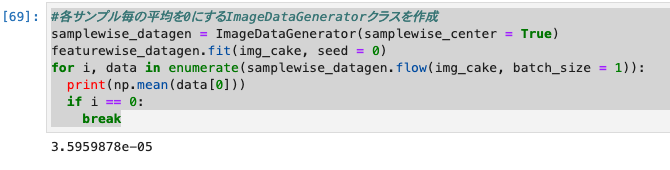
- samplewise_centerは与えられた各サンプルの入力の画素値平均を0にします。用途としてはfeaturewise_centerとほぼ同じ。
- 他の条件やモデルに合わせて良い方を使用します。こちらも平均値がほぼ0になっていることが確認できます。
#各サンプル毎の平均を0にするImageDataGeneratorクラスを作成
samplewise_datagen = ImageDataGenerator(samplewise_center = True)
featurewise_datagen.fit(img_cake, seed = 0)
for i, data in enumerate(samplewise_datagen.flow(img_cake, batch_size = 1)):
print(np.mean(data[0]))
if i == 0:
break
データセット全体の標準偏差を1にする(featurewise_std_normalization)
- featurewise_std_normalizationは与えられたデータセット全体の入力の標準偏差を1にします。
- この時、featurewise_centerはTrueにしなければならない。
- 出力を確認すると、平均がほぼ0、標準偏差がほぼ1になっていることが確認できる。
featurewise_std_datagen = ImageDataGenerator(featurewise_center = True, featurewise_std_normalization = True)
featurewise_std_datagen.fit(img_cake,seed = 0)
for i, data in enumerate(featurewise_std_datagen.flow(img_cake, batch_size = 1)):
print(np.mean(data[0]))
print(np.std(data[0]))
if i == 0:
break
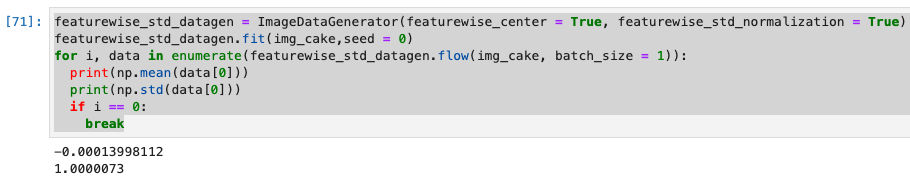
各サンプルの標準偏差を1にする(samplewise_std_normalization)
- samplewise_std_normalizationは与えられた各サンプルの入力の標準偏差を1にします。
- 用途としてはfeaturewise_std_normalizationとほぼ同じ、他の条件やモデルに合わせて良い方を使用するとのこと。
- 出力を確認すると大体ですが、平均が0、標準偏差が1になっていることが確認できる。
#各サンプル毎の平均を0、標準偏差を1にするImageDataGeneratorクラスを作成
samplewise_std_datagen = ImageDataGenerator(samplewise_center = True, samplewise_std_normalization = True)
samplewise_std_datagen.fit(img_cake,seed = 0)
for i, data in enumerate(samplewise_std_datagen.flow(img_cake, batch_size=1)):
print(np.mean(data[0]))
print(np.std(data[0]))
if i == 0:
break
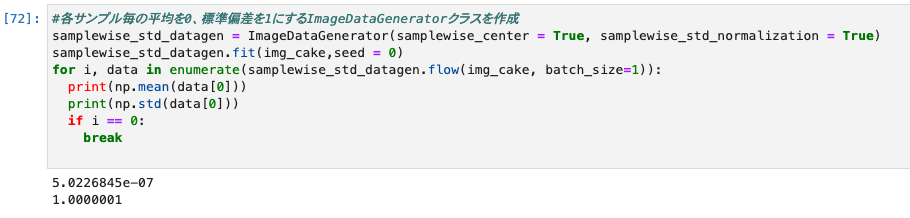
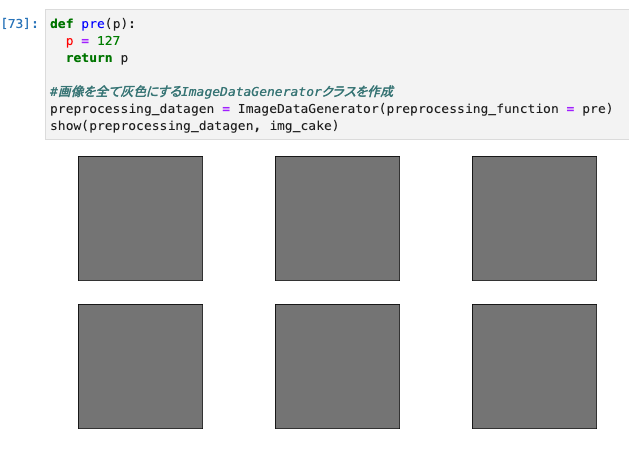
関数を使用した前処理(preprocessing_function)
- 他の各変換が行われる前に適用される関数を指定できる引数
- ImageDataGeneratorだけでもData Augmentationの種類としては十分だが、それ以外に自作で変換関数などをImageDataGenerator内で適用させることができる。
- 以下は、灰色に変換している例。
def pre(p):
p = 127
return p
#画像を全て灰色にするImageDataGeneratorクラスを作成
preprocessing_datagen = ImageDataGenerator(preprocessing_function = pre)
show(preprocessing_datagen, img_cake)
複数の変換の適用
- 実際のデータセットに対しては複数の変換を適用させることになる。
- 以下では、回転と左右平行移動と拡大縮小の3つの変換を組み合わせる。
- 「-30度から30度」の範囲でランダムに回転
- 「640×-0.3〜640×0.3」の範囲でランダムに水平平行移動
- 「0.7〜1.3」の範囲でランダムにズーム
#複数の変換を適用するImageDataGeneratorクラスを作成
double_datagen = ImageDataGenerator(rotation_range = 30, width_shift_range = 0.3, zoom_range = 0.3)
show(double_datagen, img_cake)

- 種類の変換を組み合わせると6枚の画像は全て違う画像となりました。
最も重要なのは「目的のために質の良いData Augmentationを行うこと」とのことでした。
そのために、常にテストデータを想定しながら、どのように画像を増やしたら精度が高まるかを考えることが必要。
ニューラルネットワークによるCIFAR-10の分類
-
実際のデータセットに対してData Augmentationを実装していきます。
-
Data Augmentationを行う場合と行わない場合について比較していきます。
-
以下の流れで進行します。
- データセットの読み込みと表示
- データの前処理
- モデル構築
- 学習1(Data Augmentationなし)
- 評価1
- 学習2(Data Augmentationあり)
- 評価2
-
上記の流れの中では、「3.データの前処理」にData Augmentationのコードを記載するのが一般的だが、Data Augmentationの比較をしにくくなってしまうため「5.学習1(Data Augmentationなし)」「7.学習2(Data Augmentationあり)」にそれぞれ必要コードを記載している。
1.必要なライブラリのインポート
#必要なライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from keras.models import Model
from keras.utils import np_utils
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Input
from keras.layers.pooling import MaxPool2D
from keras.layers.convolutional import Conv2D
from keras.layers.core import Dense, Flatten
import tensorflow as tf
tf.random.set_seed(0)
2.データセットの読み込みと表示
- データセットをロードする。
- 今回使用するデータはCIFAR-10、CIFAR10は10種類の物体のカラー写真からなるデータセットです。とのことです。
- 全体で学習用データが50000枚
- テスト用データが10000枚
- 10種類のラベル
- 「0」→飛行機(airplane)
- 「1」→自動車(automobile)
- 「2」→鳥(bird)
- 「3」→猫(cat)
- 「4」→鹿(deer)
- 「5」→犬(dog)
- 「6」→カエル(flog)
- 「7」→馬(horse)
- 「8」→船(ship)
- 「9」→トラック(truck)
CIFAR-100
CIFAR-10よりもラベル数が多いCIFAR-100も存在します。
参考:THE CIFAR-10/CIFAR-100
- 以下のコードを実行すると、数十秒でダウンロードされました。
#cifar10をダウンロード
(x_train, y_train),(x_test, y_test) = cifar10.load_data()
データセットの確認
- まずはCIFAR-10がどのようなデータセットなのか把握する。
- どのようなデータセットを使用する場合にも、必ず最初にEDA(探索的データ分析)を行うこと。 ←これは重要。覚えておこう。
- まずは画像を表示させるところから始る。以下では、1枚ずつ確認するのは大変なので、30枚をいっぺんに表示している。
#ラベルの設定
labels = np.array([
'airplane', #飛行機
'automobile',#自動車
'bird', #鳥
'cat', #猫
'deer', #鹿
'dog', #犬
'frog', #カエル
'horse', #馬
'ship', #船
'truck' #トラック
])
#画像の表示のための関数
def image_show(x, y, labels):
plt.figure(figsize = (13, 10))
for i in range(30):
plt.subplot(5, 6, i+1)
#軸を表示しない
plt.xticks(color = "None")
plt.yticks(color = "None")
plt.tick_params(bottom = False, left = False)
#タイトルをラベルの名前で表示
plt.title(labels[y[i][0]])
#表示
plt.imshow(x[i])
return
#画像を表示
image_show(x_train, y_train, labels)
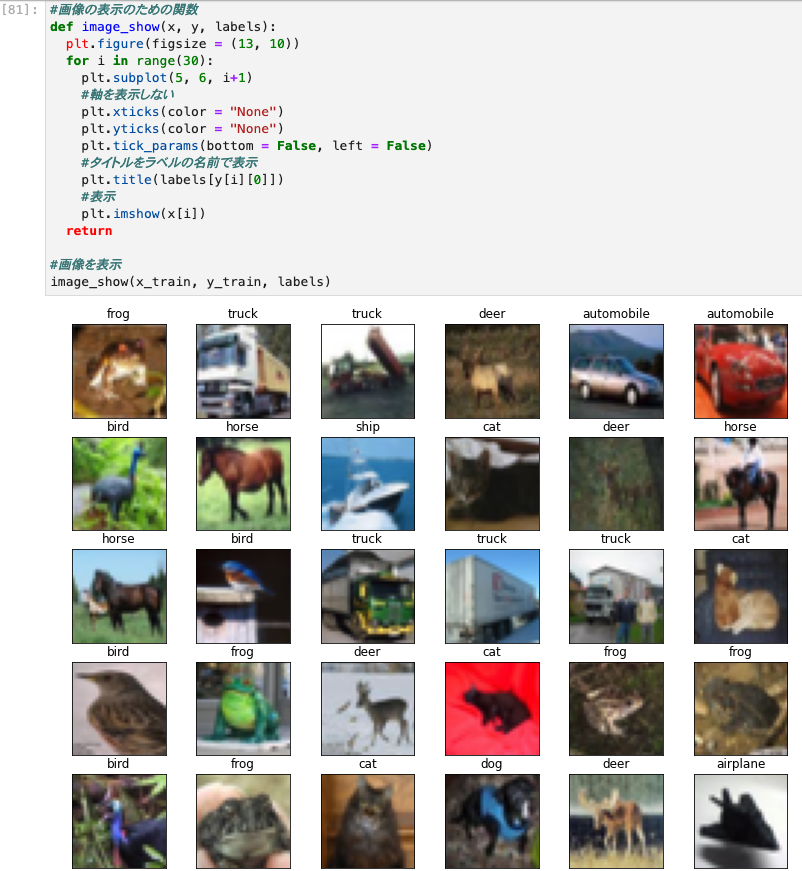
- ぼんやりだが確認できました。
3.データの前処理
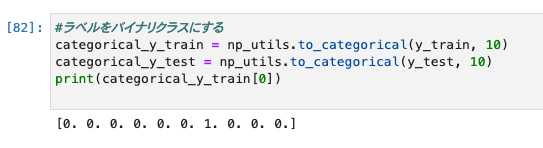
- ラベルはバイナリクラスに変更します。
- yの値を10個の数値の配列に変換しています。
- イメージは、以下のとおりです。
- y = 5 = [0,0,0,0,1,0,0,0,0,0]
- y = 0 = [1,0,0,0,0,0,0,0,0,0]
#ラベルをバイナリクラスにする
categorical_y_train = np_utils.to_categorical(y_train, 10)
categorical_y_test = np_utils.to_categorical(y_test, 10)
print(categorical_y_train[0])
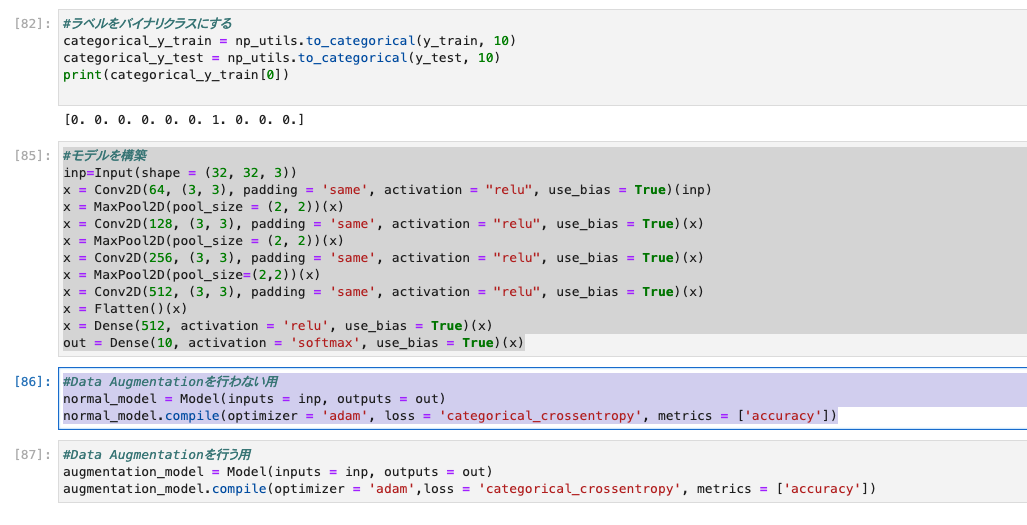
4.モデル構築
- 今回のモデルは畳み込み(Conv)層が4つ、プーリング(Pooling)層が3つ、全結合(Dense)層が2つとのことです。
- 畳み込み層のカーネルサイズを3×3
- 画像サイズが変わらないよう(”same”)に設定
- 活性化関数にはReLU関数を用いる
- プーリング層にはMaxPoolingを使用
- 全結合層は最終的に出力が10で活性化関数をsoftmaxにしている。
- このあたり、CNNや画像認識の知識がないと、わからないのかも。自分はちょっとわかりませんが進めます。
#モデルを構築
inp=Input(shape = (32, 32, 3))
x = Conv2D(64, (3, 3), padding = 'same', activation = "relu", use_bias = True)(inp)
x = MaxPool2D(pool_size = (2, 2))(x)
x = Conv2D(128, (3, 3), padding = 'same', activation = "relu", use_bias = True)(x)
x = MaxPool2D(pool_size = (2, 2))(x)
x = Conv2D(256, (3, 3), padding = 'same', activation = "relu", use_bias = True)(x)
x = MaxPool2D(pool_size=(2,2))(x)
x = Conv2D(512, (3, 3), padding = 'same', activation = "relu", use_bias = True)(x)
x = Flatten()(x)
x = Dense(512, activation = 'relu', use_bias = True)(x)
out = Dense(10, activation = 'softmax', use_bias = True)(x)
- Data Augmentationを行わない時と行う時の2種類を作成します。どちらもモデルの条件は同じにします。
Data Augmentationを行わない用
#Data Augmentationを行わない用
normal_model = Model(inputs = inp, outputs = out)
normal_model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])
Data Augmentationを行う用
#Data Augmentationを行う用
augmentation_model = Model(inputs = inp, outputs = out)
augmentation_model.compile(optimizer = 'adam',loss = 'categorical_crossentropy', metrics = ['accuracy'])
5.学習1(Data Augmentationなし)
- Data Augmentationがない場合の学習を行います。
- Data Augmentationは行わないが、ニューラルネットワークを使用するため、画像のピクセルを0〜1の間に収めるとのこと。
- ImageDataGeneratorクラスのスケーリングだけは適用します。テストデータも同様にスケーリングのみを適用します。その後、flowメソッドを使用してデータのバッチを生成します。
- 学習の条件は、バッチサイズを32、エポック数を20にしている。
#学習用のImageDataGeneratorクラスの作成
normal_train_datagen = ImageDataGenerator(rescale = 1./255)
#学習用のバッチの生成
normal_train_generator = normal_train_datagen.flow(x_train, categorical_y_train, batch_size = 32, seed = 0)
#テスト用のImageDataGeneratorクラスの作成
test_datagen = ImageDataGenerator(rescale = 1./255)
#テスト用のバッチの生成
test_generator = test_datagen.flow(x_test, categorical_y_test, batch_size = 32, seed=0)
#学習
normal_result = normal_model.fit(normal_train_generator,steps_per_epoch=len(x_train) / 32, epochs=20)
-
実行結果は、以下のとおりです。
-
おおよそ、1時間弱かかりました。インスタンスタイプのスペックを上げることで時間が短縮されるか今後、試してみたいです。

-
学習が完了したので、accuracyの推移を見るためにグラフでプロットを行います。
#accuracyのプロット
plt.plot(range(1, 21), normal_result.history['accuracy'], label = "train")
#軸ラベル名
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
#表示
plt.legend()
plt.show()
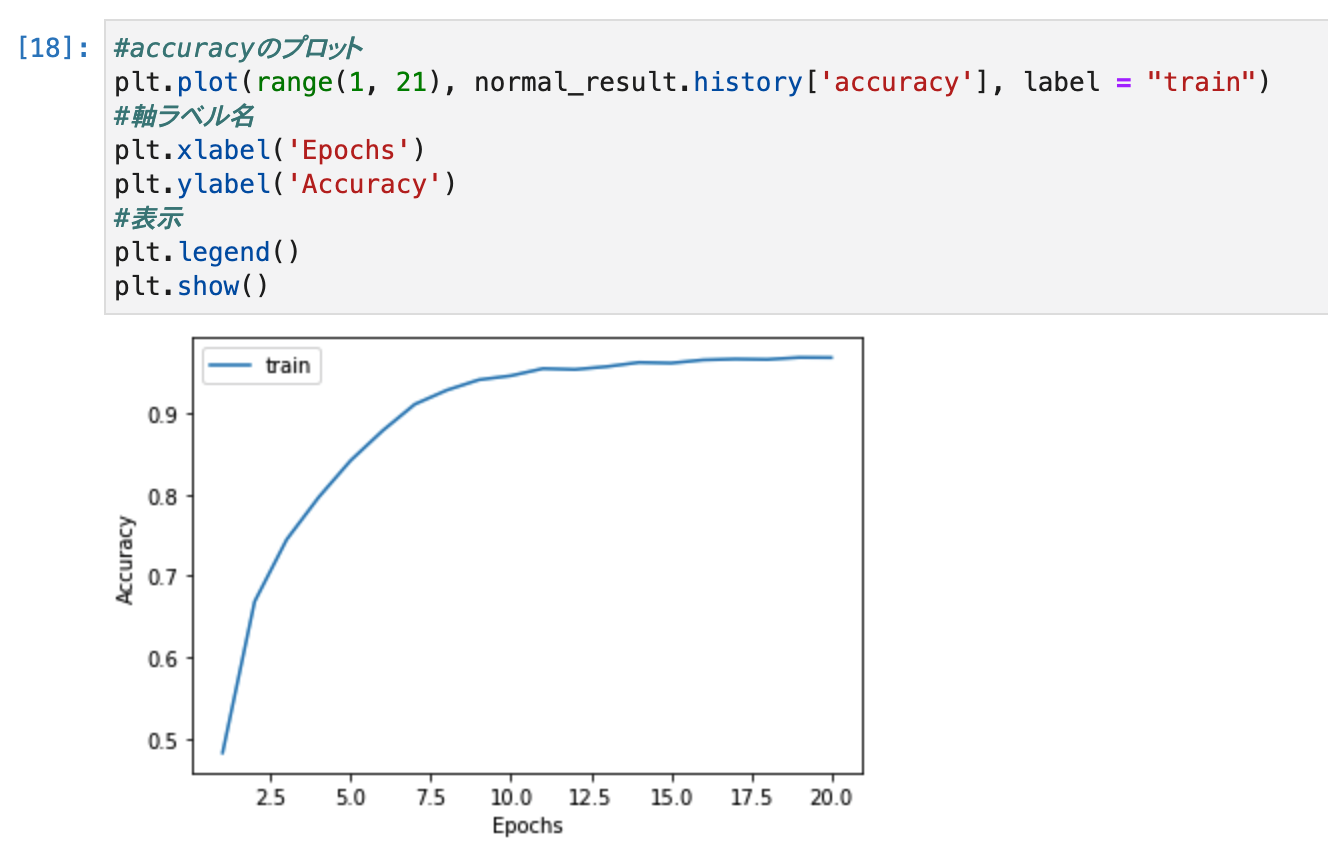
- エポック数が増えるにつれて、accuracyが向上していくことが分かります。(線形ではなく、一定以上になると微増になりました。)
6.評価1
- 学習データのaccuracyは0.9を上回るほど良い結果を残しており、これは、かなり正確に分類できていると言えるとのことです。
- これと同等の精度がテストデータでも得られれば問題ない。
- テストデータで評価を行います。評価にはevaluateメソッドを使用し、先ほど作成したtest_generatorを引数に渡してあげます。
- 学習用データとのaccuracyとの差に注目する。
#テスト用データを使って評価
normal_evaluate = normal_model.evaluate(test_generator)
- 実行結果は、以下のとおりです。

- 結果を見ると、学習時点では、0.96程度だったのに対して、テストデータでは、accuracyは0.74となりました。
- 過学習を引き起こしていることが、原因とのことです。
- モデルが学習用データに過度に適合したことにより、テストデータに対する評価が下がった。
- Data Augmentationを行わないことによって発生しうる事象の一例
7.学習2(Data Augmentationあり)
- まずはどのようなData Augmentationが有効かどうか考える。
- 先ほど表示した30枚の画像と同様の画像を表示して考えます。そして表示した画像から考えられる以下の点を仮説として挙げます。
#画像の表示
image_show(x_train, y_train, labels)
- 実行結果は、以下のとおりです。
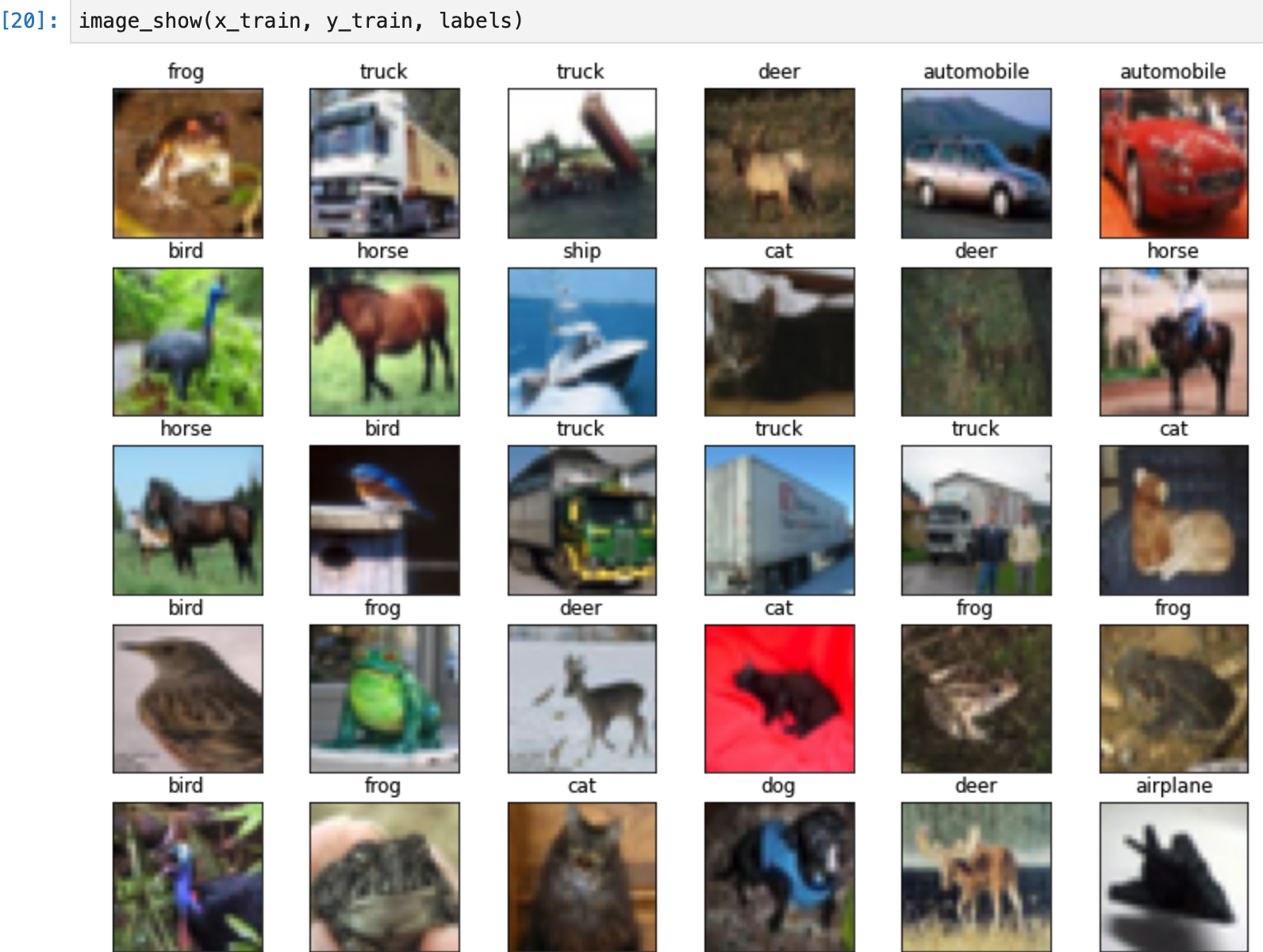
- 仮説
- 撮影時の向きはバラバラなので少し回転を加えた方が良さそうである。
- 動物の体の向きは左右バラバラなので左右反転をした方が良さそうである。
- フレーム内の動物の位置はズレているので少し、上下左右にシフトした方が良さそうである。
- 動物の大きさはバラバラなので少しズームをした方が良さそうである。
- 撮影時の明るさがバラバラなので少し色を変えた方が良さそうである。
以上の仮説をData Augmentationとして適用させ、「5.学習1」と同様にImageDataGeneratorクラスで変換を定義し、flowメソッドを使用してデータのバッチを生成します。
#学習用のImageDataGeneratorクラスの作成
augmentation_train_datagen = ImageDataGenerator(
#回転
rotation_range = 10,
#左右反転
horizontal_flip = True,
#上下平行移動
height_shift_range = 0.2,
#左右平行移動
width_shift_range = 0.2,
#ランダムにズーム
zoom_range = 0.2,
#チャンネルシフト
channel_shift_range = 0.2,
#スケーリング
rescale = 1./255
)
#学習用のバッチの生成
augmentation_train_generator = augmentation_train_datagen.flow(x_train, categorical_y_train, batch_size=32, seed=0)
- 学習時の条件も「5.学習1」と同様で、バッチサイズを32、エポック数を20 にしています。
#学習
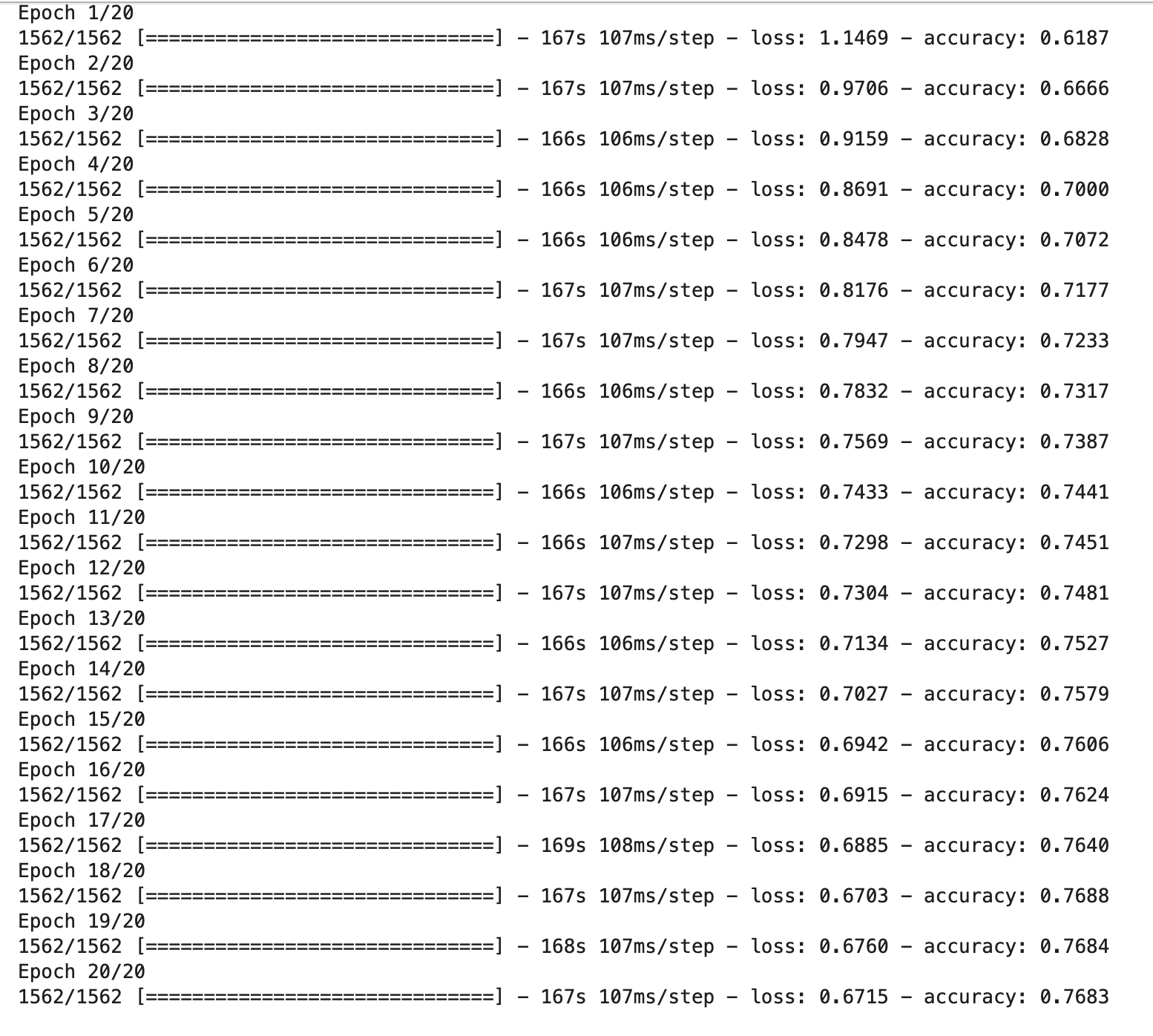
augmentation_result = augmentation_model.fit(augmentation_train_generator, steps_per_epoch = len(x_train) / 32, epochs = 20)
-
実行結果は、以下のとおりです。
-
今回も1時間弱かかりました。
-
次に、先程と同様にaccuracyの推移を見るためにグラフでプロットを行います。
#accuracyのプロット
plt.plot(range(1, 21), augmentation_result.history['accuracy'], label = "train")
#軸ラベル名
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
#表示
plt.legend()
plt.show()
- 実行結果は、以下のとおりです。
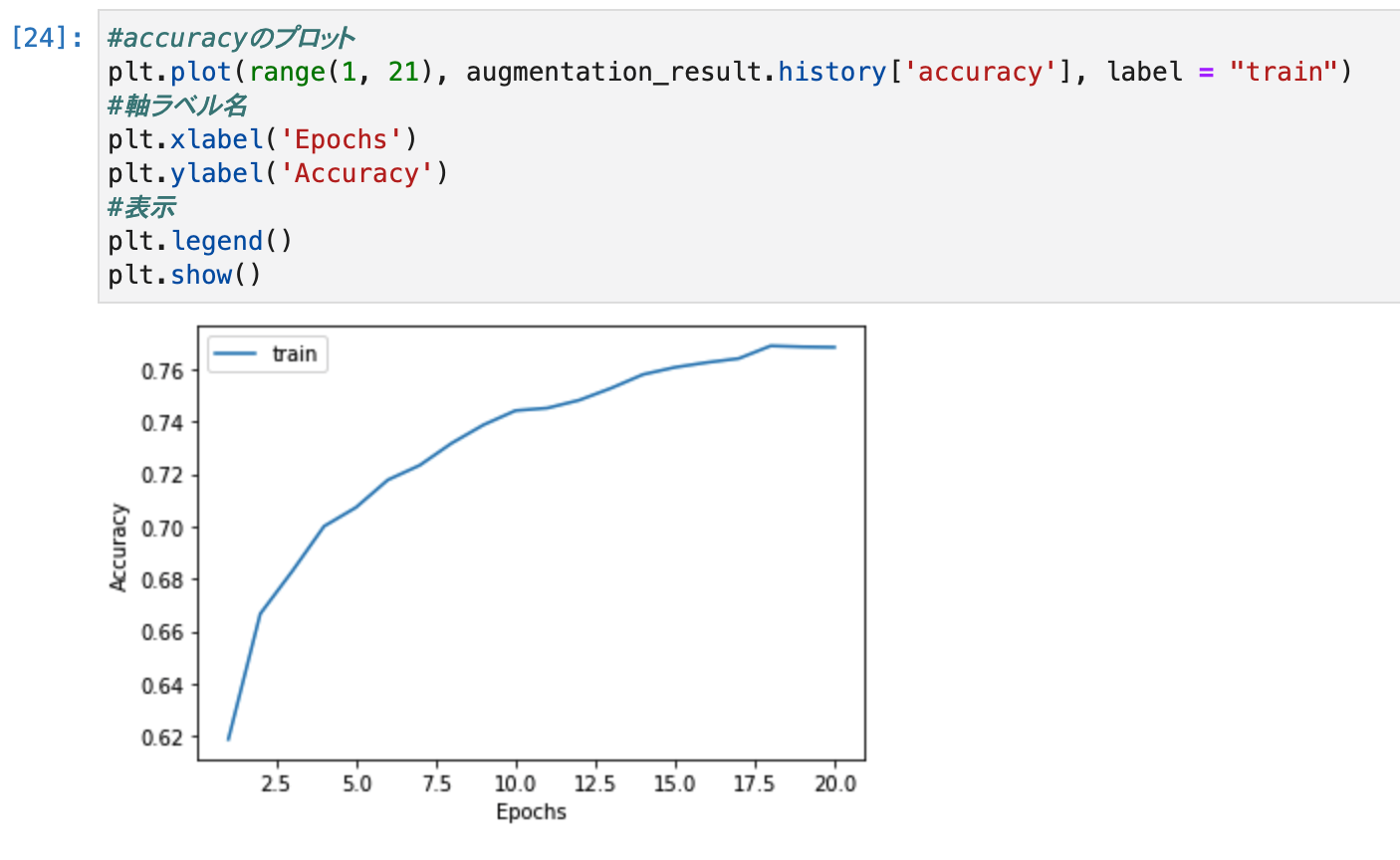
- 学習データのaccuracyは0.78程度でした。
- データ拡張しない場合と、比べると良い評価を得られていません。
8.評価2
- テストデータで評価を行います。
- 評価にはevaluateメソッドを使用し、先ほど作成したaugmentation_test_generatorを引数に渡します。
#テスト用データを使って評価
augmentation_evaluate = augmentation_model.evaluate(test_generator)

- テストデータのaccuracyも0.78程度になっています。データ拡張を行わない場合のaccuracyは0.74なので、こちらのほうが評価が高いと言えます。
- 理由の一つとして、Data Augmentationによって過学習を抑制できたことが挙げられます。
- Data Augmentationによって学習用データの画像が水増しされたことにより、モデルは本来用意されている画像数よりも多くの画像を学習に使用しました。(画像数は増えているのか?オンラインデータ拡張により実行時に増えていると思うが、どこかで数字で確認できないのか。)
- 学習用データの難易度も上がりましたが、テストデータに対する適合率も上がりました。
- 結果、テストデータのaccuracyはData Augmentationを行わない場合に比べて上がったと考えられます。
考察
- 今回は、データ拡張を学びました。データ拡張により、少ないデータを元に多くの学習データを用意することがで着ることが分かりました。
- 後半では、過学習による問題を、データ拡張で解決したチュートリアルを試しました。まだまだ理解も浅いし、コーディングも手に馴染んでいません。これからも継続して学び続けたいと思います。
- また、今後学習するにあたり、画像の素材をまとめているサイトがあることをしれたのは良かったです。
- 後半のチュートリアルでは、学習時間が1時間程度かかりました。今後、EC2のスペックをあげて性能が改善するのかも確認したいと思います。
参考