背景・目的
私は、現在データエンジニアリングを生業としています。普段は、データ基盤の構築や、パフォーマンスチューニングなどビックデータに関する業務に従事しています。
ビックデータの収集や、蓄積、分析などの環境構築の経験はそこそこありますが、機械学習による予測や分類などのスキルは持ち合わせていませんでした。
今まで機械学習を避け続けてきましたが、一念発起し学ぼうと思います。
学び方としては、AWS Certified Machine Learning – Specialty(以降、ML試験という。)の勉強を通して、理解を深めていきます。ML試験のガイドの第2分野に、探索的データ解析が登場しましたのでそこから学びたいと思います。
今回は、クラスタリングのエルボー法について学びたいと思います。
2.3 機械学習のデータを分析および視覚化する
・クラスタリング (階層型、診断、エルボープロット、クラスターサイズ
なお、過去の機械学習の調べてみたシリースは下記にまとめています。
- 2.探索的データ分析
- 2.1.モデリング用のデータをサニタイズおよび準備する
- 2.2.特徴エンジニアリングを実行する
- 2.3 機械学習のデータを分析および視覚化する
- 機械学習プロセス
まとめ
エルボープロットにより、急激に変わる箇所を可視化し最適なクラスタ数を見つける。
概要
エルボー法とは?
クラスタの数に応じて、SSEを計算しグラフ化し、その形状から最適なクラスタ数を選択する手法です。
SSEとは?
Sum of Squared errors of predictionの略。クラスタ内誤差平方和と呼ばれるもの。
各クラスタの重心から、各点までの距離の総和のように考えておけばよい。
グラフを見ながら、SSEとクラスタ数がなるべく小さくなる組み合わせを見つける。
グラフでみると、急激に変わるところがある。このポイントが最適なクラスタ数となる。
実践
こちらの記事「エルボー法とは , サンプルデータへの適用例」を参考に、手を動かします。ありがとうございます。
ライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
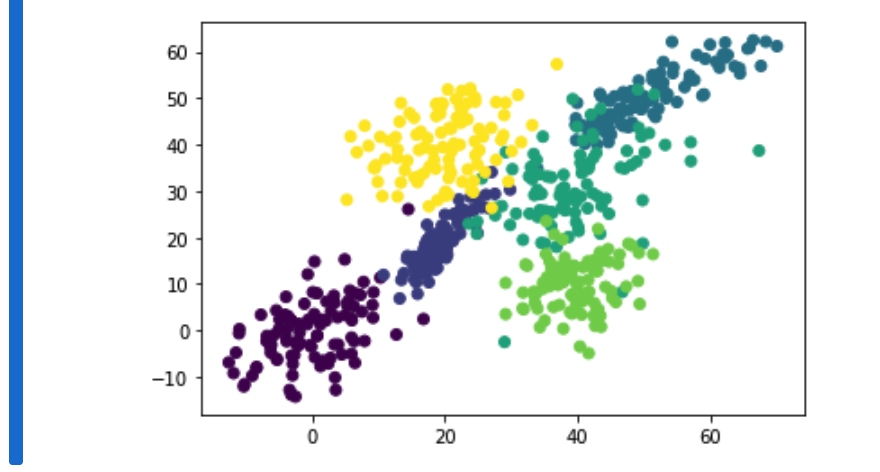
散布図でデータを確認
mu = [[0,0], [20,20], [50,50], [40,30], [40,10], [20,40]]
sigma = [ [[30,20],[20,50]], [[20,30],[10,20]], [[60,40],[20,20]], [[60,20],[20,60]] ,[[30,10],[10,30]],[[50,20],[20,50]] ]
points = 100
clusters = []
for index in range(len(mu)):
cluster = np.random.multivariate_normal(mu[index], sigma[index], points)
dig = np.full((points,1),index+1, dtype=int)
cluster = np.hstack((cluster,dig))
clusters = np.r_[clusters,cluster] if len(clusters) > 0 else cluster
plt.scatter(x=clusters[:,0], y=clusters[:,1],c=clusters[:,2])
kmeans_model = KMeans(n_clusters=6, init='random',max_iter=10).fit(clusters[:,:2])
labels = kmeans_model.labels_
distortions = []
numClusters = 10
for i in range(1,numClusters):
kmeans_model = KMeans(n_clusters=i, init='random',max_iter=10)
kmeans_model.fit(clusters[:,:2])
distortions.append(kmeans_model.inertia_)
plt.plot(range(1,numClusters),distortions,marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.show()
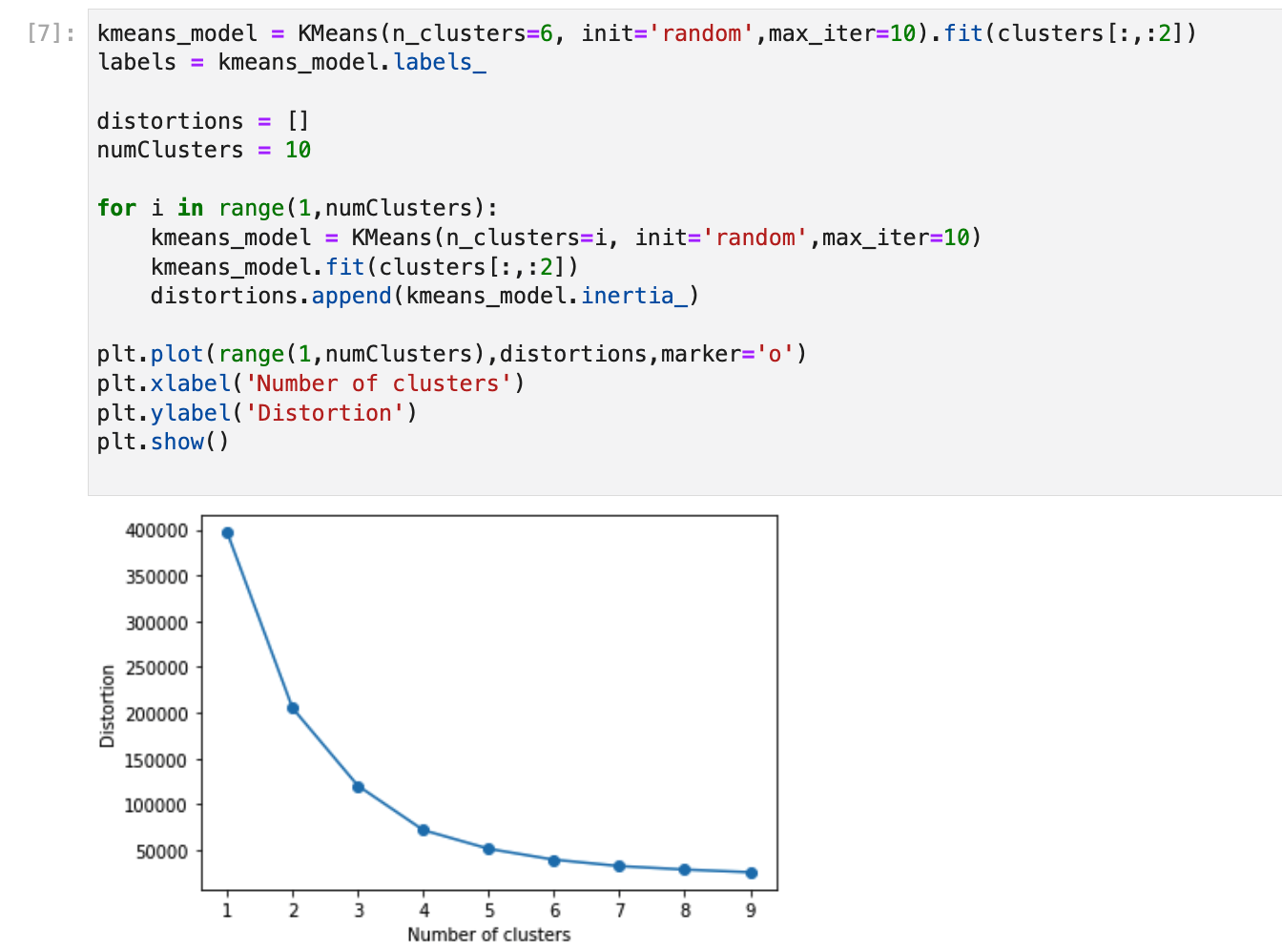
- 4〜6あたりでサチっています。
考察
今回は、エルボー法(エルボープロット)について試してみました。クラスタ数を決める方法では他にもシルエット分析などがあるようです。
参考