背景・目的
私は、現在データエンジニアリングを生業としています。普段は、データ基盤の構築や、パフォーマンスチューニングなどビックデータに関する業務に従事しています。
ビックデータの収集や、蓄積、分析などの環境構築の経験はそこそこありますが、機械学習による予測や分類などのスキルは持ち合わせていませんでした。
今まで機械学習を避け続けてきましたが、一念発起し学ぼうと思います。
学び方としては、AWS Certified Machine Learning – Specialty(以降、ML試験という。)の勉強を通して、理解を深めていきます。ML試験のガイドの第2分野に、探索的データ解析が登場しましたのでそこから学びたいと思います。
今回は、グラフ化について学びたいと思います。
2.3 機械学習のデータを分析および視覚化する
・ グラフ化 (散布図、時系列、ヒストグラム、ボックスプロット)
なお、過去の機械学習の調べてみたシリースは下記にまとめています。
-
2.探索的データ分析
-
2.1.モデリング用のデータをサニタイズおよび準備する
-
2.2.特徴エンジニアリングを実行する
-
機械学習プロセス
まとめ
- seabornは可視化ライブラリで様々なグラフを描ける。
概要
今回は、codexaさんのseaborn 徹底入門!Pythonを使って手軽で綺麗なデータ可視化8連発を元に整理したいと思います。
可視化の必要性
データの可視化が必要な理由は、以下のとおりです。
- そのデータを生み出している事象をより正確に理解する。
- 機械学習での予測を用いる際に、使うべきデータを適切に選んだりするため。
そのためにはまず、データを可視化して大きな特徴を掴み、データ同士の相関を知ることが必要とのことです。
どうやるのか
Pythonでデータを可視化するには、Pandasでデータを集計・加工し、その上でmatplotlibやseabornというライブラリで可視化します。
seabornの特徴
- しーぼーんという。
- Pythonの可視化ライブラリ
- 内部でmatplotlibが動作している。
- 洗練された図を描く言上でき、matplotlibと比べて少ないコードで図が掛ける。
- ただし、matplotlibのユーザのほうが多い。
データセットの確認
ライブラリをインポートする。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
データセットは、titanicを利用します。
df = sns.load_dataset('titanic')
最初の5行を利用します。
df.head()
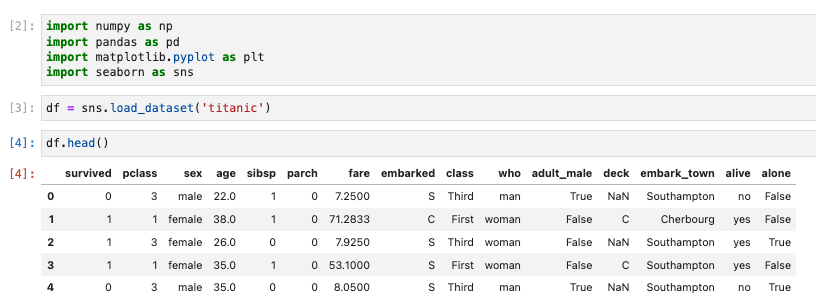
棒グラフを描く −複数の項目の値を比較する−
-
sns.catplotは性別や年齢の分布を見るようにカテゴリごとに分布を比較する場合に用いる。- kindで用いた手法を指定する。
- xに可視化したい変量を指定し、dataにその変量を持つデータフレームを指定
- kindにはcountを指定する。
sns.catplot(x="pclass", data=df, kind="count")
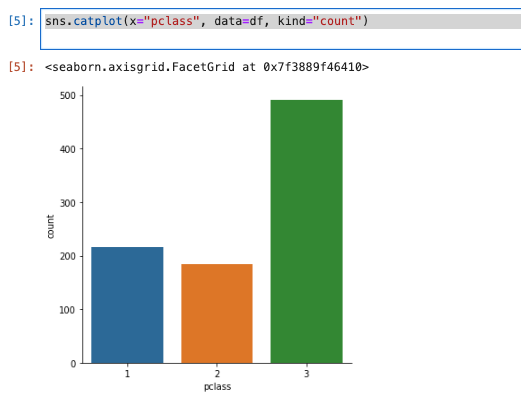
ヒストグラムを描く −ひとつの変量の分布を可視化する−
- ヒストグラムは、ある一つの変量を複数の階級(bin)に分け、それぞれの階級にいくつのデータが含まれるのかを棒グラフの形で表現したもの。
-
sns.distplotを使用する。- 引数には、PandasのSeries、Numpyの1d-array、Pythonのリストを指定する。
sns.distplot(df['age'])
plt.show()
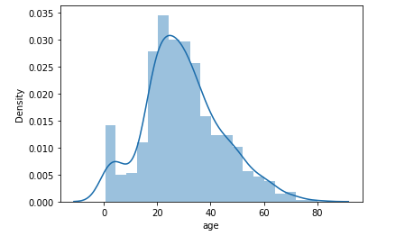
- 20代前半の人が多い。
- 幅4で全部で20階級(bin)を持っている。階級の数は指定しない場合自動的に決まる。binsを指定することもできる。
- KDE(カーネル密度推定)と呼ばれる手法で計算された確率密度関数を削除する場合は、kde=Falseを指定する。以下に示す。
sns.distplot(df['age'], kde=False)
plt.show()
箱ひげ図を描く −基本統計量を可視化する−
- 多くの基本統計量を可視化できるのが箱ひげ図の特徴です。
- 四分位数を用いて、外れ値を特定でききる。
-
sns.catplotを使用して、kind='box'を指定します。
sns.catplot(x='sex', y='age', data=df, kind='box', hue='survived')
plt.show()
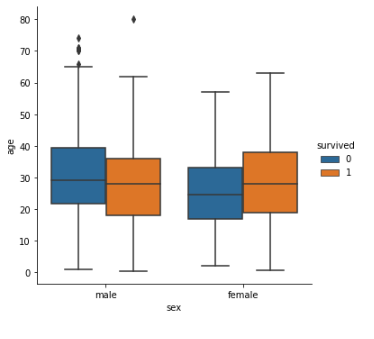
- kindを
boxからboxenを指定することで、より詳細な情報を得られる表示方法に変えることが出来ます。
sns.catplot(x='sex', y='age', data=df, kind='boxen', hue='survived')
plt.show()
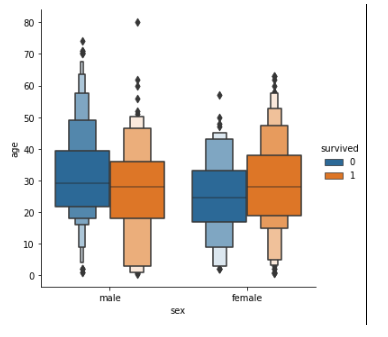
棒グラフを描く −平均値を可視化する−
- カテゴリーごとの平均値にのみに興味がある場合は、
sns.catplotでkind='bar'を指定することで棒グラフで平均値の比較ができる。
sns.catplot(x='sex', y='age', data=df, kind='bar', hue='survived')
plt.show()
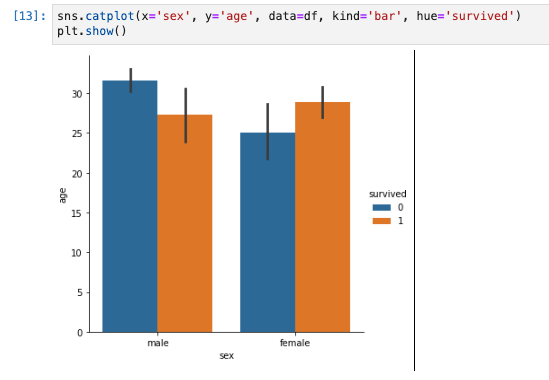
-
estimator=np.medianを指定することで中央値の比較が可能になる。
sns.catplot(x='sex', y='age', data=df, kind='bar', hue='survived', estimator=np.median)
plt.show()
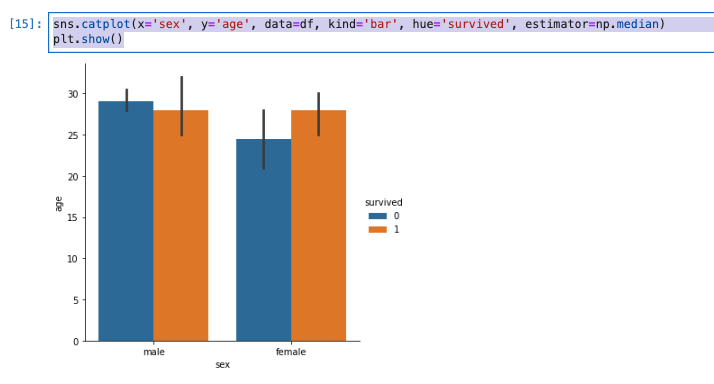
scatter plotを描く −分布を詳細に表示する−
- 一つのデータを一つの天として表示します。
-
sns.caplotでkindを指定なしの場合のデフォルト。
sns.catplot(x='sex', y='age', data=df)
plt.show()
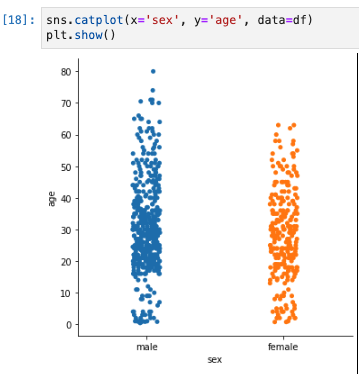
- 上記だと多くの点が集中し分布が確認しづらくなる箇所がある。
- swarm plotを使う。
kind='swarm'を使う。
#swarm plotの表示
sns.catplot(x='sex', y='age', data=df, kind='swarm')
plt.show()
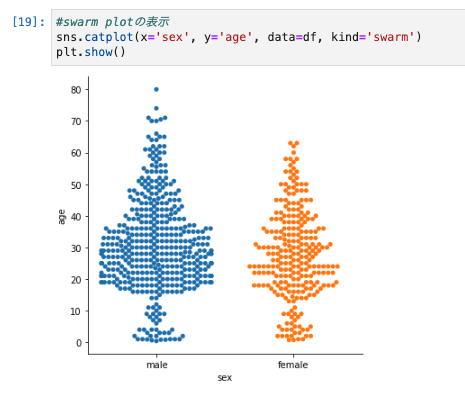
- ラベルごとの分布を見る。
-
hue='survived'を指定する。
sns.catplot(x='sex', y='age', data=df, kind='swarm', hue='survived')
plt.show()
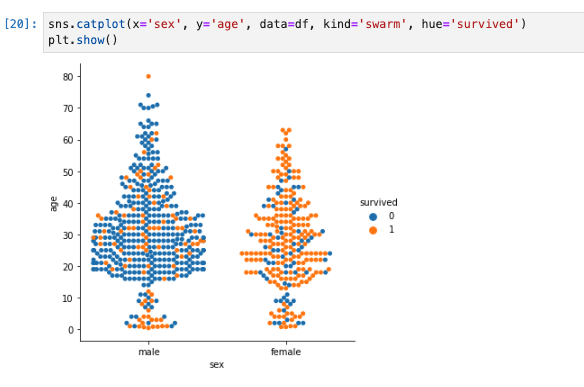
- 女性は生存の割合が高く、男性は10歳以下での生存の割合が高い事がわかる。
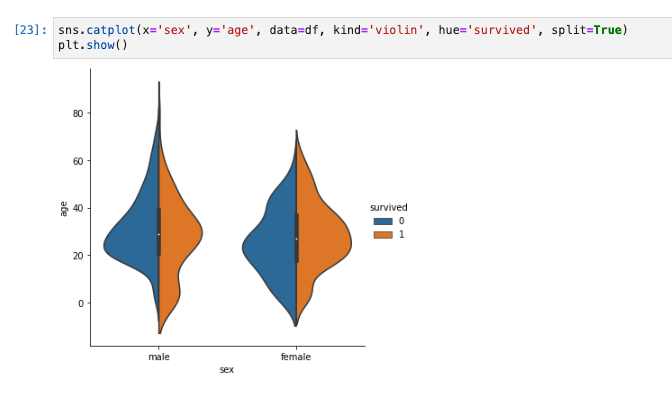
ヴァイオリンプロットを描く −scatter plotを滑らかにし、箱ひげ図を加える−
- 箱ひげ図は中央値、最大値、最小値を比較するのに向いているが、分布の様子を比較することが出来ない。
-
kind=’violin’を指定することでバイオリン図を表示できる。
sns.catplot(x='sex', y='age', data=df, kind='violin', hue='survived')
plt.show()
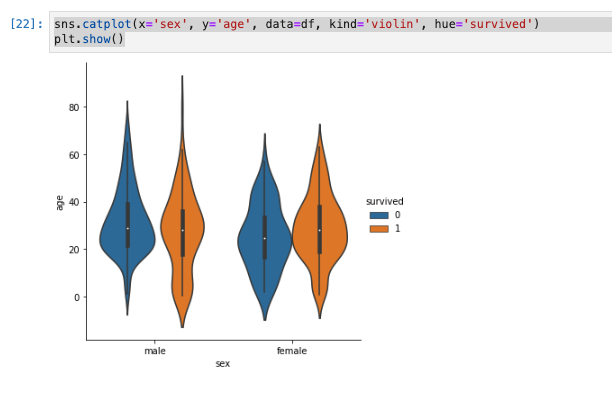
-
split=Trueを指定すると、hue をラベルごとに結合させた形にすることができます。
sns.catplot(x='sex', y='age', data=df, kind='violin', hue='survived', split=True)
plt.show()
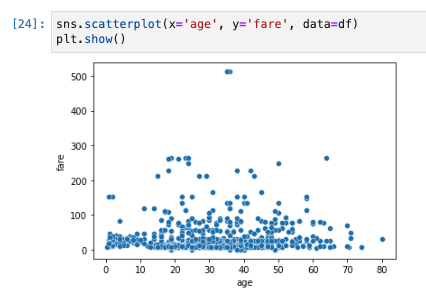
散布図を描く −二つの数量データの関係を可視化する−
- 年齢(age)と運賃(fare)のように2つの数量データの関係性をみるには散布図を利用します。
- 散布図は、横軸と縦軸それぞれに1つずつ変量を対応させ、各データをプロットしたものです。
-
sns.scatterplotで描くことができ、引数は以下のように指定します。- x=横軸, y=縦軸, data=データフレーム
sns.scatterplot(x='age', y='fare', data=df)
plt.show()
- 散布図の上と右に、各変量のヒストグラムを併せて表示する方法として、
sns.jointplotがあります。 - 各々の変数単独の分布を同時に確認できるのが特徴。
- 上記の散布図では、データが密集し見づらくなった。
- 引数に
kind='hex'を指定して、データの密度を色の濃淡で表現します。 - 散布図とヒストグラムを同時に表示する。
sns.jointplot(x='age', y='fare', data=df, kind='hex')
plt.show()
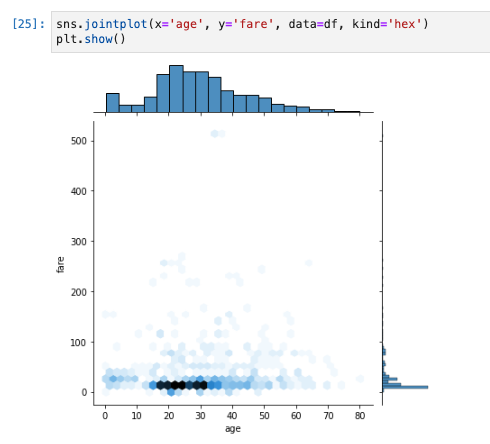
- 年齢が20歳〜30歳で安いチケットを持っている乗客が多い
- 高いチケットをもっている客がかなり少ない
散布図行列を描く −全ての変量の組の関係を可視化する−
- sns.scatterplot を用いることで2つの変量の散布図を描くことができますが、関係性を確かめたい変量がいつも2つしかないとは限らない。
- つ以上の変量がある場合に、それぞれの関係を1組ずつ可視化するのは面倒.
-
sns.pairplotでまとめて散布図を描くことができる。 - 各散布図は行列の形式に並べられて、これを散布図行列と呼ぶ。
- データに多くの変量が含まれている場合、個別の散布図を描く前に
sns.pairplotを使用してまとめて散布図をみると、どの変量間の関係性が重要そうであるか検討をつけることが可能です。 - irisデータセットを使用して確認する。
df2 = sns.load_dataset('iris')
df2.head()
-
sns.pairplotは引数としてDataFrameを受け取ります。
sns.pairplot(df2)
plt.show()
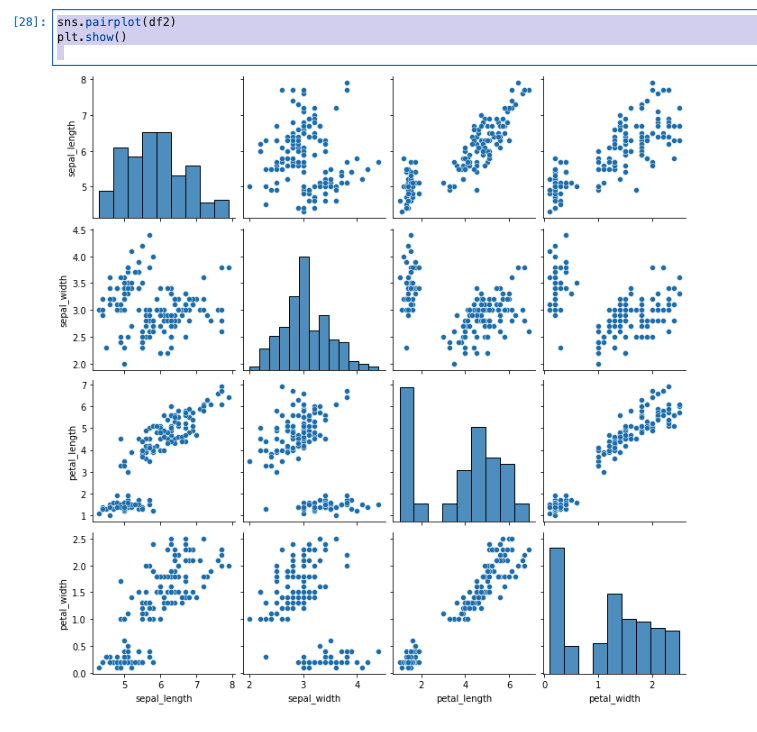
- 全ての変量の組み合わせについて、散布図が書かれていることが分かりました!
- 対角線上には、それぞれの変量についてのヒストグラムが描かれている。
- 引数に
hueを指定することで、ラベル毎に色付けできる。アヤメの種類を示すspeciesを指定する。
sns.pairplot(data=df2, hue='species')
plt.show()
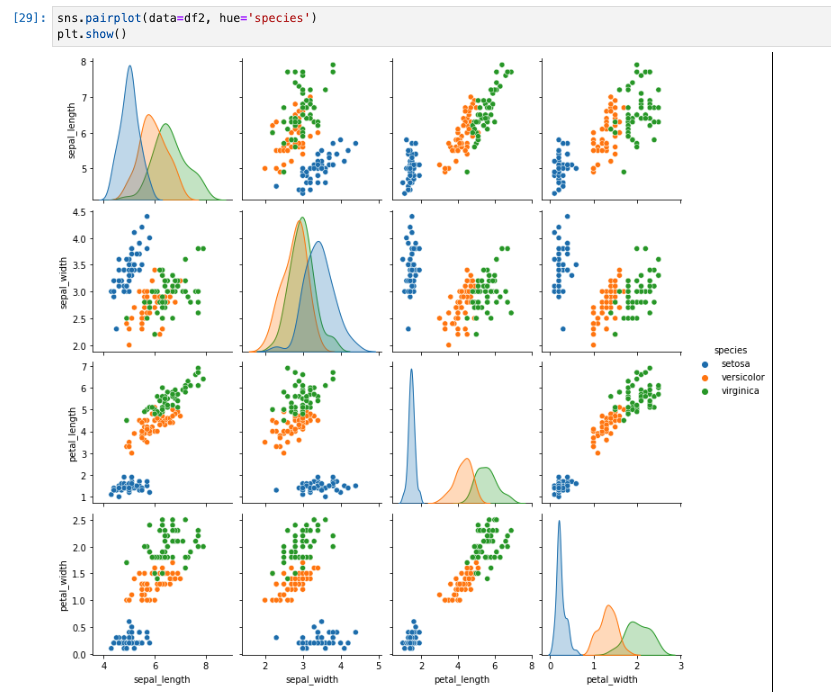
考察
説明変数を探す際に事前にデータセットを確認すると思いますが、seabornを使いグラフ化しざっくりと確認することが出来ます。
また、はじめにpairplotを使用してざっくりと各変数ごとの組み合わせを確認し、その後各変数について詳細を確認することで効率よく探すことができます。
参考