背景・目的
私は、現在データエンジニアリングを生業としています。普段は、データ基盤の構築や、パフォーマンスチューニングなどビックデータに関する業務に従事しています。
ビックデータの収集や、蓄積、分析などの環境構築の経験はそこそこありますが、機械学習による予測や分類などのスキルは持ち合わせていませんでした。
今まで機械学習を避け続けてきましたが、一念発起し学ぼうと思います。
学び方としては、AWS Certified Machine Learning – Specialty(以降、ML試験という。)の勉強を通して、理解を深めていきます。ML試験のガイドの第2分野に、探索的データ解析が登場しましたのでそこから学びたいと思います。
今回は、以下のうちOne-Hotエンコーディングについて学びたいと思います。
特徴エンジニアリングの概念を分析/評価する (データのビニング、トークナイゼーション、外れ値、合成的特徴、One-Hotエンコーディング、次元低減)
なお、過去の機械学習の調べてみたシリースは下記にまとめています。
-
2.探索的データ分析
-
2.1.モデリング用のデータをサニタイズおよび準備する
-
2.2.特徴エンジニアリングを実行する
-
機械学習プロセス
まとめ
- データは、以下の種類に分けられます。
| データの種類 | 分類 | 説明 |
|---|---|---|
| 量的データ | - | 枚数、身長、金額など数値で推し量ることができるデータ |
| 質的データ(カテゴリカルデータ) | 順序尺度 | 数値自体には意味がないが、順序に意味がある。 例えば、地震など |
| 名義尺度 | 数値自体に意味がないことに加えて、順序についても意味がないもの。 例えば、血液型など |
- 機械学習では、生データを0と1に変換して扱いやすくするためデータ変換を行う。この変数をダミー変数といい、ダミー変数に変換することをOne-Hotエンコーディングといいます。
- ダミー変数は独立した値である名義尺度に用いられる。順序尺度に用いることは一般的にはありません。
- ダミー変数に変換すると値の種類分だけ列を持つため、メモリなどのリソース使用量が増えます。
概要
codexaさんの「ダミー変数(One-Hotエンコーディング)とは?実装コードを交えて徹底解説」を参考に整理します。ありがとうございます。
データには、以下の二種類にわけられ、特に質的データについては前処理を行い、扱いやすいデータに直して機械学習しやすい形へ変換してあげる必要があります。
- 量的データ
- 身長、時刻など数値として意味があるもの
- 質的データ(カテゴリカルデータ)
- 性別、順位など分類や順位など分類や区別を行うた目のデータ
以降では、カテゴリカルデータに対する前処理に着目し、ダミー変数について整理します。
ダミー変数とは?
カテゴリカル(質的)データを0または、1で表現した変数のこと。
性別のデータに男性と女性というカテゴリカルデータが存在していた場合、このデータは数値ではないので実際にデータ分析を行うには扱いづらいのでそれぞれを1と0で表す。
このように、数値として扱えないデータを0と1に数値化する際に用いられる変数をダミー変数という。
| 性別 | 男か? | 女か? |
|---|---|---|
| 男 | 1 | 0 |
| 女 | 0 | 1 |
- ビット列で表すような形式と思われる。
カテゴリカルデータには、順序尺度と名義尺度がある。以降に記載します。
順序尺度
数値自体には意味がないが、順序に意味がある。地震の尺度など。震度は数値が大きくなるにつれて揺れが大きくなるが震度1に対して3が3倍強いわけではない。
数値自体や間隔に意味はなく、数値の大小関係のみが意味を持つ。
名義尺度
数値自体に意味がないことに加えて、順序についても意味がないものを指す。性別や血液型など。
例えば、A型=1.B型=2、O型=3、AB型=4として数値置き換えて考えたときに、4のAB型が1のA型に対して、4倍の何かを持つであったり順序新見があるものではなく、
単純に分類のために使用される。
ダミー変数が用いられる場面
ダミー変数は、名義尺度に適用されるのが一般的です*順序尺度を0と1で表現することは困難なため、順序尺度では用いられない。
名義尺度と順序尺度をダミー変数で置き換えた場合の例を比較します。
■ 順序尺度
| 震度 | 震度1 | 震度2 | 震度3 |
|---|---|---|---|
| 震度1 | 1 | 0 | 0 |
| 震度2 | 0 | 1 | 0 |
| 震度3 | 0 | 0 | 1 |
- 震度をそれぞれ表現する場合3列の表になる。
- 震度の列には大小が存在するが、ダミー変数で変換したあとの状態では大小関係が認識でない。
■名義尺度
| 血液型 | A | B | O | AB |
|---|---|---|---|---|
| A | 1 | 0 | 0 | 0 |
| B | 0 | 1 | 0 | 0 |
| O | 0 | 0 | 1 | 0 |
| AB | 0 | 0 | 0 | 1 |
- 血液型には元から大小関係が存在していない。ダミー変数に変換したあと独立した形式なるが、問題ない。
One-Hotエンコーディングとは
One-Hotエンコーディングとは、ダミー変数を用いた変換と同じ意味です。機械学習では、ダミー変数を用いた前処理のことを、One-Hotエンコーディングと呼ぶ。
One−Hotエンコーディングは、シンプルだが元データの種類分だけ変換後には列が作られることになり、メモリ使用量が大きくなる注意点もある。
実際のデータ変換では、様々な前処理を駆使してデータを扱いやすい形に変換させますが、カテゴリカルデータに0から順番に番号を振るLabelエンコーディング、カテゴリカルデータの出現回数をカウントするCountエンコーディングなどがある。
実践
データセットの確認
- seaborn上のtitanicのデータセットを使用する。
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.preprocessing import OneHotEncoder
df = sns.load_dataset('titanic')
df.head()
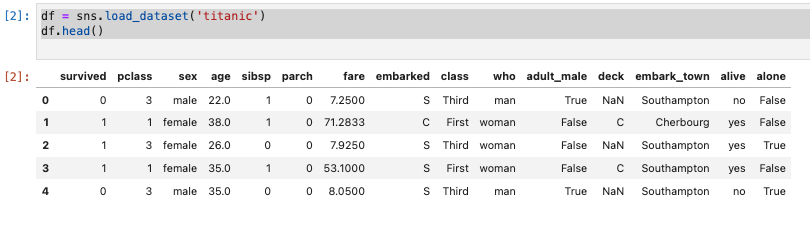
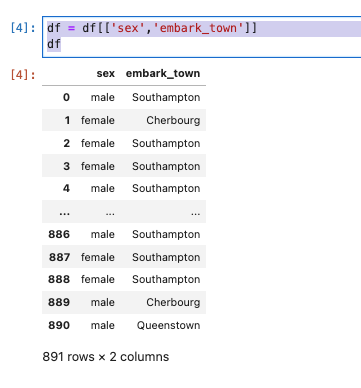
- 名義尺度の列(sexとembark_town)を確認します。
df = df[['sex','embark_town']]
df
データセットの欠損値を削除
欠損値を確認し、存在していれば削除します。
# Nullか?そしてその合計値は?
df.isnull().sum()
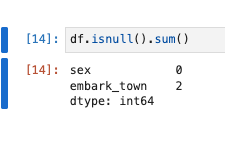
- embark_town(出港地)2件存在していましたのでdropnaで削除します。
- dropnaは、how='any'がデフォルトで、欠損値NaNが1つでも含まれる行、列を削除します。
- 行列方向は、axisにより決まる。0またはindexで行方向(デフォルト)、1またはcolumnが列方向です。
df = df.dropna()
df.isnull().sum()
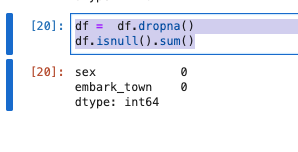
- 削除後の欠損値を確認し0件になりました。
データセットの種類を確認
print(df["sex"].unique())
print(df["embark_town"].unique())
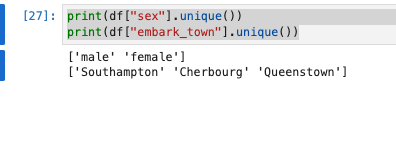
- sexはmaleとfemaleの2種類、embark_townは、Southampton、Cherbourg、Queenstownの3種類存在することが確認できました。
One-Hotエンコーディングの実装
pandasのget_dummies
pandasのget_dummies()を使用します。
- デフォルトでは変換前の列名_変換前の変数名になります。
- 引数を渡すことで、欠損値をダミー変数で扱ったり列名を変更したり出来ます。
df = pd.get_dummies(df)
df
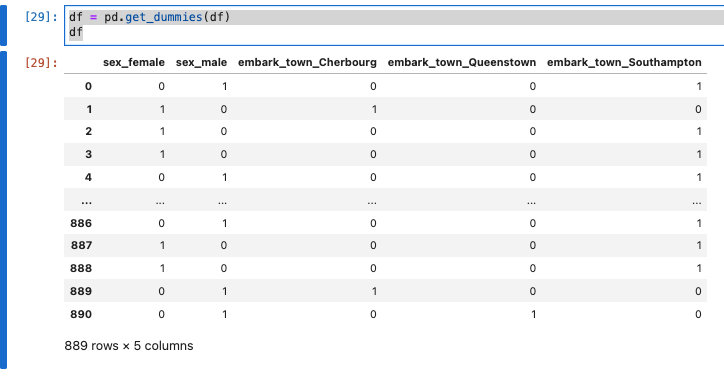
- sexは、sex_famale、sex_maleに分けられ、0と1に変換されている。
- embark_townは、embark_town_Cherbourg、embark_town_Queenstown、embark_town_Southamptonに分けられ、0と1に変換されている。
scikit-learnのOneHotEncoder
scikit-learnのOneHotEncoder()を使用します。
- 引数をsparse=Falseで戻り値を配列にし見やすくなる。Trueの場合は、疎行列が返される。
- dypes=intで整数値を返す。デフォルトはfloatです。
oe = OneHotEncoder(sparse = False,dtype = int)
sl_np = oe.fit_transform(df)
sl_np
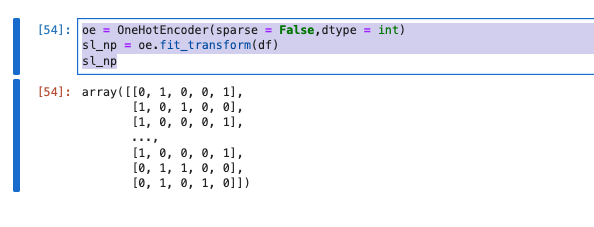
- 戻り値がnumpyのarrayになる。scikit-learnのOneHotEncoderではDataFrameを返すことが出来ないため、pd.Dataframe()を使用してDataFrame似直します。
sl_df = pd.DataFrame(data = sl_np,columns = ["sex_female","sex_male","embark_town_Cherbourg","embark_town_Queenstown","embark_town_Southampton"])
sl_df

考察
今回は、ダミー変数(One-Hotエンコーディング)について学びました。
One-Hotエンコーディングでは、事前にデータセットに欠損値が含まれているか確認し削除等することが必要になります。そのまま放置すると、エラーになるか、デフォルト値で置き換えられてしまいます。
今回、sckit-learnとpandasの2種類を試しました。pandasのgetdummies()のほうが扱いやすいですがメモリ消費量が大きい傾向にあるようです。大規模データセットでは列を絞り込む(疎行列)などが必要とのことでした。
機械学習のトレーニングや推論に用いる元になるデータでは、実際は0や1のような数値ではないためOne-Hotエンコーディングにより前処理で変換しておくなど実務的な内容が学べた気になりました。
引き続き学んで行きたいと思います。
参考