ハンズオン形式で気軽にデータブリックスを触ってみよう!でご説明した内容です。私の視点でJupyter notebookとDatabricksと比較した内容となっています。
サンプルノートブックはこちらからダウンロードできます。
講義資料
Databricksの会社紹介、Databricksの提供するレイクハウス誕生の背景をご説明しています。
データブリックスとは?
まず初めに、データブリックスを説明させてください。データブリックスはApache Sparkを実行するためのマネージドプラットフォームです。つまり、Sparkを利用するために、複雑なクラスター管理の考え方や、面倒なプラットフォームの管理手順を学ぶ必要がないということです。
また、データブリックスは、Sparkを利用したワークロードを円滑にするための機能も提供しています。GUIでの操作を好む方向けに、マウスのクリックで操作できるプラットフォームとなっています。しかし、UIに加えて、データ処理のワークロードをジョブで自動化したい方向けには、洗練されたAPIも提供しています。エンタープライズでの利用に耐えるために、データブリックスにはロールベースのアクセス制御や、使いやすさを改善するためだけではなく、管理者向けにコストや負荷軽減のための最適化が図られています。
データブリックスの提供機能
データ・AIに関する作業を効率化するために、データブリックスは様々な機能を提供していますが、以下の3つに分類されます。
- 大量データを高速処理するための基盤
- 生産性高くデータ・AIに関する作業を行うためのワークスペース
- 機械学習モデルを管理するための仕組み
このワークショップでは主に2.ワークスペースをご説明します。

コミュニティエディションの制限
フルバージョンのデータブリックスと比較してコミュニティエディションには以下の制限があります。
- 作成できるクラスターは15GB RAM、2 Core CPUのシングルノードのみ
- ワークスペースに追加できるユーザー数は最大3名まで
- クラスターのリージョンはus-westのみ
- 使用できない機能
- ジョブのスケジュール機能
- クラスターのオートスケーリング機能
- Git連携
- MLflowの一部モデル管理機能(レジストリ、RESTサービング)
- REST APIによるワークスペースの制御
- セキュリティ、ロールベースのアクセス制御、監査、シングルサインオン
- BIツール連携のサポート
参考資料
用語集
データブリックスには理解すべきキーとなるコンセプトがあります。これらの多くは画面左側のサイドバーにアイコンとして表示されています。これらは、エンドユーザーであるあなたのために用意された基本的なツールとなります。これらはウェブアプリケーションのUIからも利用できますし、REST APIからも利用できます。
-
Workspaces(ワークスペース)
- Databricksで行う作業はワークスペース上で実施することになります。あなたのコンピューターのフォルダー階層のように、**notebooks(ノートブック)やlibraries(ライブラリ)を保存でき、それらを他のユーザーと共有することができます。ワークスペースはデータとは別となっており、データを格納するために用いるものではありません。これらは単にnotebooks(ノートブック)やlibraries(ライブラリ)**を保存するためのものであり、データを操作するためにこれらを使用することになります。
-
Notebooks(ノートブック)
- ノートブックはコマンドを実行するためのセルの集合です。セルには以下の言語を記述することができます:
Scala、Python、R、SQL、Markdown。ノートブックにはデフォルトの言語が存在しますが、セルレベルで言語を指定することも可能です。これは、セルの先頭に%[言語名]十することで実現できます。例えば、%pythonです。すぐにこの機能を利用することになります。 - コマンドを実行するためには、ノートブックは**cluster(クラスター)**に接続される必要がありますが、永久につながっている必要はありません。これによって、ウェブ経由で共有したり、ローカルマシンにダウンロードすることができます。
- ノートブックのデモ動画をこちらから参照できます。
-
Dashboards(ダッシュボード)
- **Dashboards(ダッシュボード)はnotebooks(ノートブック)**から作成することができ、ダッシュボードを生成したコードを非表示にして結果のみを表示する手段として利用することができます。
- **Notebooks(ノートブック)は、ワンクリックでjobs(ジョブ)**としてスケジュールすることができ、データパイプラインの実行、機械学習の更新、ダッシュボードの更新などを行うことができます。
- ノートブックはコマンドを実行するためのセルの集合です。セルには以下の言語を記述することができます:
-
Libraries(ライブラリ)
- ライブラリは、あなたが問題を解決するために必要となる追加機能を提供するパッケージあるいはモジュールです。これらは、ScalaやJava jarによるカスタムライブラリ、Pythonのeggsやカスタムのパッケージとなります。あなた自身の手でライブラリを記述し手動でアップロードできますし、pypiやmavenなどのパッケージ管理ユーティリティ経由で直接インストールすることもできます。
-
Tables(テーブル)
- テーブルはあなたとあなたのチームが分析に使うことになる構造化データです。テーブルはいくつかの場所に存在します。テーブルはAmazon S3やAzure Blob Storageに格納できますし、現在使用しているクラスターにも格納できます。あるいは、メモリーにキャッシュすることも可能です。詳細はDatabricksにおけるデータベースおよびテーブル - Qiitaを参照ください。
-
Clusters(クラスター)
- クラスターは、あなたが単一のコンピューターとして取り扱うことのできるコンピューター群です。Databricksにおいては、効果的に20台のコンピューターを1台としてと扱えることを意味します。クラスターを用いることで、あなたのデータに対して**notebooks(ノートブック)やlibraries(ライブラリ)のコードを実行することができます。これらのデータはS3に格納されている構造化データかもしれませんし、作業しているクラスターに対してtable(テーブル)**としてアップロードされた非構造化データかもしれません。
- クラスターにはアクセス制御機能があることに注意してください。
- クラスターのデモ動画はこちらとなります。
-
Jobs(ジョブ)
- ジョブによって、既存のcluster(クラスター)あるいはジョブ専用のクラスター上で実行をスケジュールすることができます。実行対象はnotebooks(ノートブック)、jars、pythonスクリプトとなります。ジョブは手動で作成できますが、REST API経由でも作成できます。
- ジョブのデモ動画は[こちら](<http://www.youtube.com/embed/srI9yNOAbU0)となります。
基本的な使い方
ワークスペース画面左のサイドバーからDatabricksの主要な機能にアクセスします。
サイドバーのコンテンツは選択するペルソナ(Data Science & Engineering、Machine Learning、SQL)によって決まります。
- Data Science & Engineering: PythonやR、SQLを用いてノートブックを作成し実行するペルソナ
- Machine Learning: モデル管理や特徴量ストアを活用してノートブックを作成するペルソナ
- SQL: BIを行うペルソナ
サイドバーの使い方
-
デフォルトではサイドバーは畳み込まれた状態で表示され、アイコンのみが表示されます。サイドバー上にカーソルを移動すると全体を表示することができます。
-
ペルソナを変更するには、Databricksロゴの直下にあるアイコンからペルソナを選択します。

-
次回ログイン時に表示されるペルソナを固定するには、ペルソナの隣にある
 をクリックします。再度クリックするとピンを削除することができます。
をクリックします。再度クリックするとピンを削除することができます。 -
サイドバーの一番下にあるMenu optionsで、サイドバーの表示モードを切り替えることができます。Auto(デフォルト)、Expand(展開)、Collapse(畳み込み)から選択できます。
-
機械学習に関連するページを開く際には、ペルソナは自動的にMachine Learningに切り替わります。
Databricksのヘルプリソース
データブリックスには、Apache Sparkとデータブリックスを効果的に使うために学習する際に、助けとなる様々なツールが含まれています。データブリックスには膨大なApache Sparkのドキュメントが含まれており。Webのどこからでも利用可能です。リソースには大きく二つの種類があります。Apace Sparkとデータブリックスの使い方を学ぶためのものと、基本を理解した方が参照するためのリソースです。
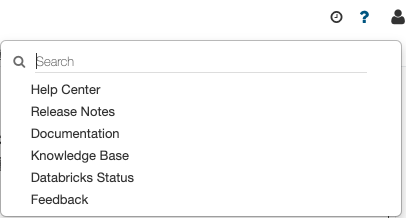
これらのリソースにアクセスするには、画面右上にあるクエスチョンマークをクリックします。サーチメニューでは、以下のドキュメントを検索することができます。
-
Help Center(ヘルプセンター)
- Help Center - Databricksにアクセスして、ドキュメント、ナレッジベース、トレーニングなどのリソースにアクセスできます。
-
Release Notes(リリースノート)
- 定期的に実施される機能アップデートの内容を確認できます。
-
Documentation(ドキュメント)
- マニュアルにアクセスできます。
-
Knowledge Base(ナレッジベース)
- 様々なノウハウが蓄積されているナレッジベースにアクセスできます。
-
Databricks Status(ステータス)
- データブリックスの稼働状況を表示します。
-
Feedback(フィードバック)
- 製品に対するフィードバックを投稿できます。
データブリックスを使い始める方向けに資料をまとめたDatabricksクイックスタートガイドもご活用ください。
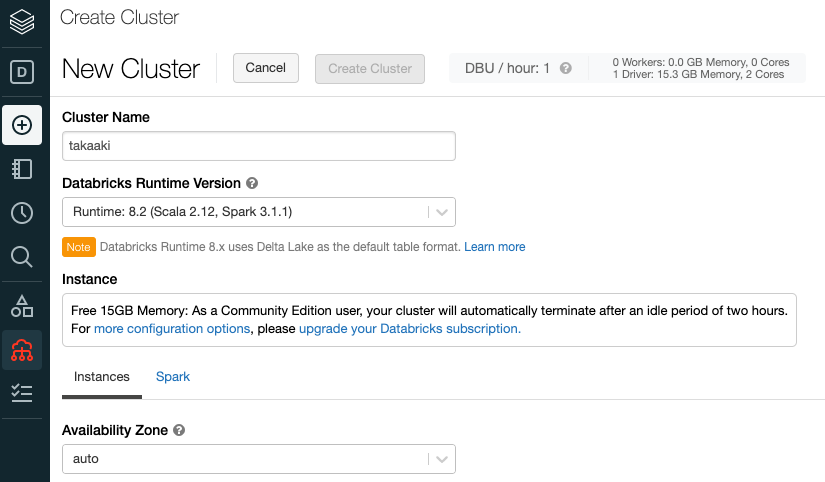
クラスターの作成
- 左のサイドバーの Compute を右クリック。新しいタブもしくはウィンドウを開く。
- クラスタページにおいて Create Cluster をクリック。
- クラスター名を [自分の名前(takaakiなど)] とする。
- 最後に Create Cluster をクリックすると、クラスターが起動 !
ノートブックを作成したクラスターに紐付けて、run all コマンドを実行
- ノートブックに戻ります。
- 左上の ノートブック メニューバーから、
 > [自分の名前] を選択。
> [自分の名前] を選択。 - クラスターが
 から
から  へ変更となったら
へ変更となったら  Run All をクリック。
Run All をクリック。
本ハンズオンでは操作の流れが分かるようにステップ毎に実行していきます。
Databricksの良いところ
以降では、主にJupyter notebookと比較したデータブリックスのメリットをご説明します。
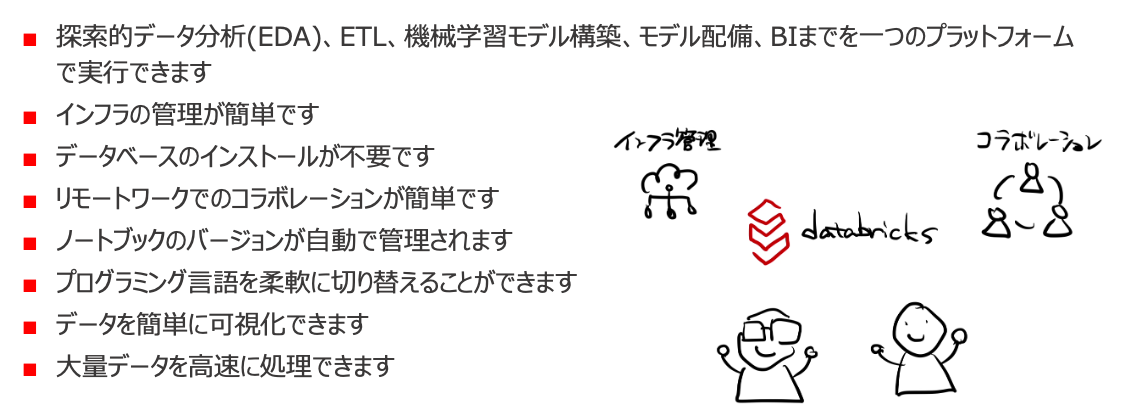
探索的データ分析(EDA)、ETL、機械学習モデル構築、モデル配備、BIまでを一つのプラットフォームで実行できます
Jupyter notebookは主にEDAと機械学習モデル構築に焦点を置いていますが、データブリックスでは分析の前段のデータ加工からデータパイプラインの構築、モデルの構築からデプロイ、ひいては経営層向けに提示するBIレポート作成までもカバーしています。

インフラの管理が簡単です
上で説明したように、クリックだけの操作でSparkクラスターを起動することができます。フルバージョンのデータブリックスでは、任意のスペックのクラスターを構成でき、オートスケーリングを活用することができます。

参考情報
- Databricksにおけるクラスター作成 - Qiita
- Databricksにおけるクラスター管理 - Qiita
- Databricksクラスター設定のベストプラクティス - Qiita
- DatabricksにおけるPythonライブラリ管理 - Qiita
- Databricksにおけるジョブ管理 - Qiita
データベースのインストールが不要です
データブリックスでは最初からデータベースとしてHiveメタストアを利用できます。以下ではSQLを用いてデータベースを操作してみます。%sqlに関しては後ほどご説明します。
参考情報
%sql
SHOW DATABASES;

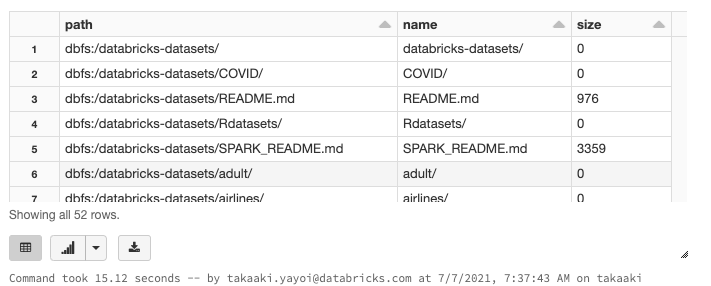
Databricks環境の/databricks-datasets配下には様々なサンプルデータが格納されています。定期的に更新されるCOVID-19データセットも含まれています。以下のセルではサンプルデータの一覧を表示しています。%fsに関しては後ほどご説明します。
参考情報
%fs
ls /databricks-datasets
%sql
-- テーブルが存在する場合には削除します
DROP TABLE IF EXISTS diamonds;
-- OPTIONSでcsvのファイルパス(path)、ヘッダーがあること(header)を指定し、USINGでファイルフォーマットを指定してdiamondsテーブを作成します
CREATE TABLE diamonds(_c0 INT,
carat DOUBLE,
cut STRING,
color STRING,
clarity STRING,
depth DOUBLE,
table INT,
price INT,
x DOUBLE,
y DOUBLE,
z DOUBLE)
USING csv
OPTIONS (path "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header "true");
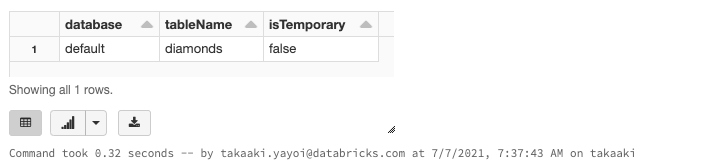
%sql
SHOW TABLES;
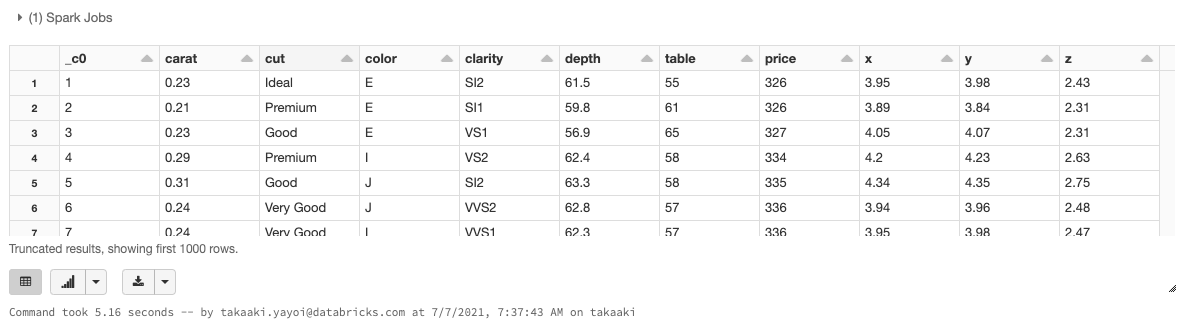
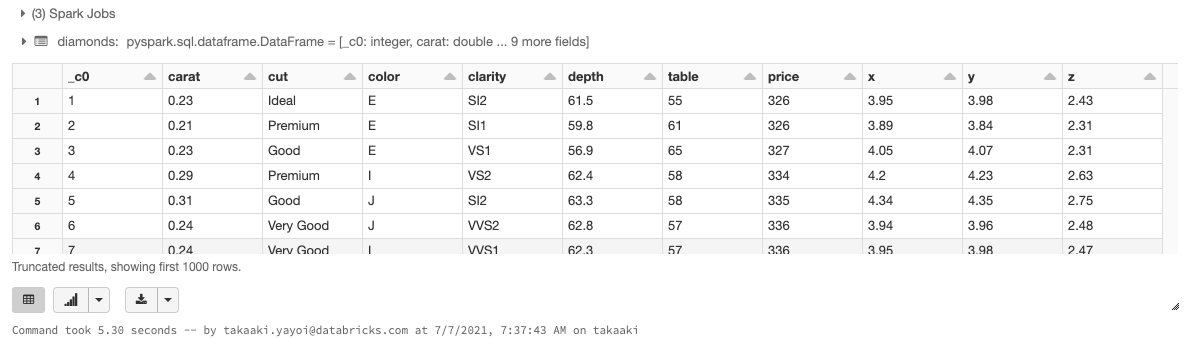
%sql
SELECT * FROM diamonds
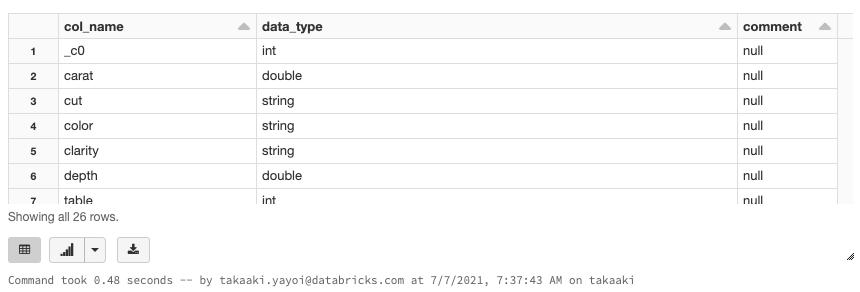
%sql
-- テーブルのメタデータを確認します
DESCRIBE EXTENDED diamonds
作成したデータベースおよびテーブルは左のサイドバーのDataからも参照できます。
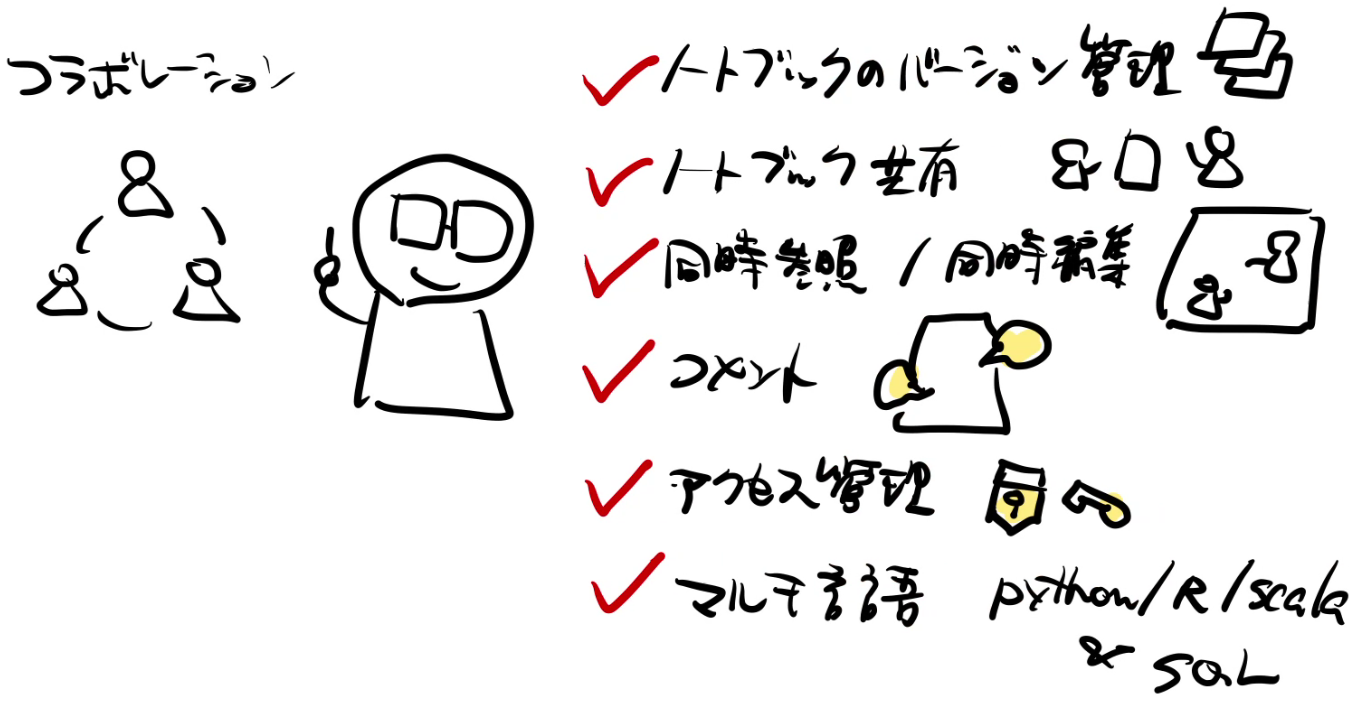
リモートワークでのコラボレーションが簡単です
遠隔地であってもリアルタイム、時間差でのコミュニケーションを容易に行うことができます。

ノートブックのバージョンが自動で管理されます
データブリックスはノートブックに対する基本的なバージョン管理機能を提供します。画面右上のRevision historyから過去のノートブックを参照できます。それぞれのバージョンに対して、コメントの追加、復旧、バージョンの削除、バージョン履歴の削除を行うことができます。Githubのリポジトリと連携することもできます。
参考資料
プログラミング言語を柔軟に切り替えることができます
Jupyter NotebookでもR用のカーネルをインストールすることで、ノートブックでRを利用することは可能です。データブリックスのノートブックではPython/R/Scala/SQLをネイティブでサポートしています。今お使いのノートブック名の右に(Python)と表示されているのは、このノートブックのデフォルト言語がPythonであることを意味しています。クリックすることでデフォルト言語を変更することができます。
ノートブックレベルでの言語指定に加えて、セル単位で言語が指定できます。上で%sqlというマジックコマンドを指定しましたが、ノートブックはデフォルト言語がPythonのままで、当該セルの言語をSQLに切り替えました。これによって、「データベースを操作するときには直接SQLを記述したい」、「ここはPythonのAPIを使った方が便利だ」というケースに柔軟に対応できます。
言語指定以外のマジックコマンドには以下のようなものがあります。
-
%sh: ノートブック上でシェルコードを実行できます。 -
%fs: dbutilsファイルシステムコマンドを実行できます。詳細はDatabricks CLI(英語)を参照ください。 -
%md: マークダウン言語を用いてテキスト、画像、数式などと言った様々なドキュメンテーションを行うことができます。
参考資料
# ノートブックのデフォルト言語はPythonです
# 上で使用したダイアモンドデータセットを読み込みます
dataPath = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv"
# inferSchemaはデータを読み込んで自動的にカラムの型を識別するオプションです。データを読み込む分のコストがかかります。
diamonds = spark.read.format("csv")\
.option("header","true")\
.option("inferSchema", "true")\
.load(dataPath)
# display関数でデータフレームを表示します
display(diamonds)
%rマジックコマンドを指定することで、Rも使用できます。
%r
library(SparkR)
# データソースからSparkデータフレームを作成
diamondsDF <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
head(diamondsDF)

データを簡単に可視化できます
Jupyter notebookでは可視化を行う際にはmatplotlibなどを用いてグラフを生成する必要がありますが、データブリックスには可視化機能がビルトインされています。SQLでレコードを取得したり、display関数でデータフレームを表示した際に現れるグラフボタンを押すことで簡単に可視化を行えます。
参考資料
%sql
SELECT * FROM diamonds
上のセルを実行後、グラフボタンを押した後に表示されるPlot Optionsをクリックすると以下の画面が表示されます。
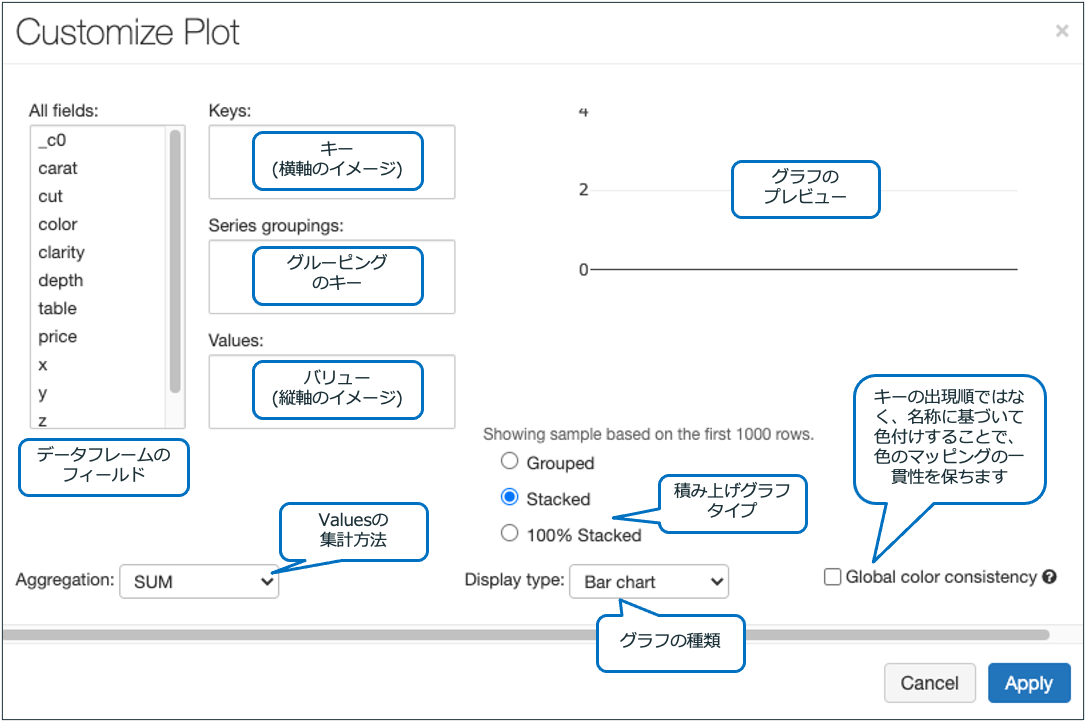
以下のように設定を行い棒グラフを表示してみます。設定後、Applyをクリックし、確認メッセージ対してはConfirmをクリックします。
- Keys: All fieldsからcutをドラッグ&ドロップ
- Values: All fieldsからpriceをドラッグ&ドロップ
- Aggregation: SUMを選択
- Display type: Bar chartを選択
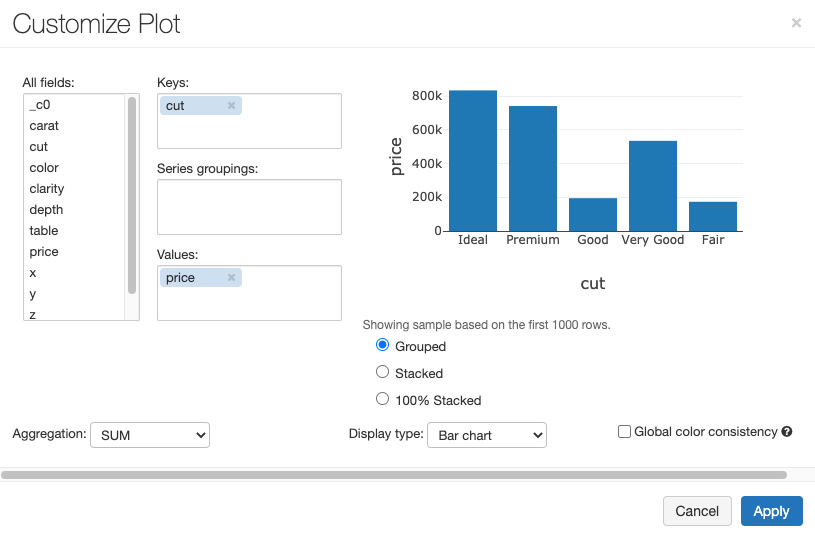
以下のようなグラフが表示されます。
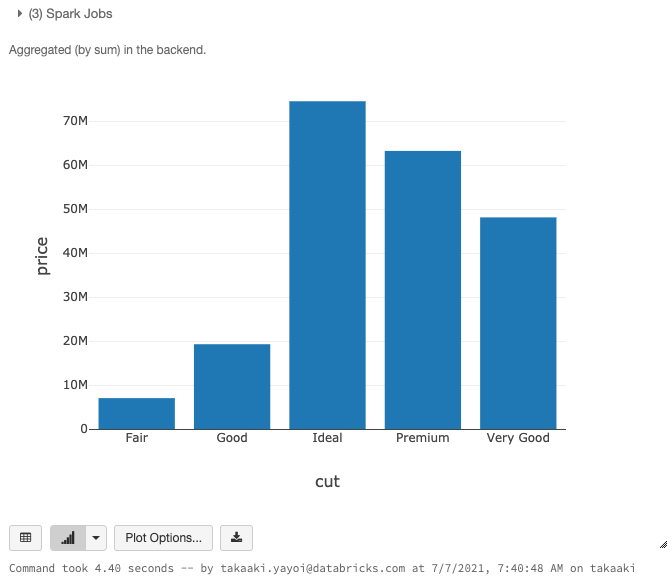
大量データを高速に処理できます
Jupyter Notebookでは処理しきれない大量データも、データブリックスなら簡単に処理・分析できます。
注意
本章は、ハンズオンで使用している環境(Community Edition)の都合上、ハンズオンの対象外となります。講師が投影するノートブックを参照ください。説明に用いたノートブックはこちらからダウンロードできます。
データレイクに信頼性とパフォーマンスをもたらすDelta Lake
さらに、Delta Lakeを活用することで高速なETL処理を実現することができます。

信頼性
- 次世代データフォーマット技術
- トランザクションログによるACIDコンプライアンス
- DMLサポート(INSERTだけではなくUPDATE/DELETE/MERGEをサポート)
- データ品質管理 (スキーマ・エンフォース)
- バッチ処理とストリーム処理の統合
- タイムトラベル (データのバージョン管理)
パフォーマンス
- スケーラブルなメタデータ
- コンパクション (Bin-Packing)
- データ・パーティショニング
- データ・スキッピング
- ZOrderクラスタリング
- ストリーム処理による低いレイテンシー
Delta LakeはApache Spark™と連携することで、凄まじいスケーラビリティと性能を提供します。インデックス、パーティショニングなど最適化された機能によって、Delta Lakeの利用者はETLワークロードを48%高速にしています。今日は詳細をご説明できませんが、Delta Lakeに特化したワークショップも開催予定です!

さいごに
本書ではデータブリックスの良さと基本的な機能をご紹介させていただきました。
データブリックスの利用を開始される方向けに翻訳資料をまとめたクイックスタートガイドを提供しておりますので、データブリックスに興味を持たれた方はご一読いただければと思います。
また、以下で提供されているサンプルノートブックなどをお試しいただければと思います。
- DatabricksにおけるCOVID-19データセットの活用: データコミュニティで何ができるのか - Qiita
- RayとMLflow: 分散機械学習アプリケーションの本格運用 - Qiita
- Databricksにおける機械学習による病理画像分析の自動化 - Qiita
- DatabricksとAzure Synapse Analyticsの連携 (実践編) - Qiita
- DatadogによるDatabricksクラスター監視 - Qiita
- Koalasのご紹介 - Qiita
- Databricks Apache Spark機械学習チュートリアル - Qiita
- 機械学習の本格運用:デプロイメントからドリフト検知まで - Qiita
- Facebook ProphetとApache Sparkを用いた大規模・高精度時系列データ予測 - Qiita
データブリックスではユーザーコミュニティによる定例会を開催しています。
コミュニティエディションでは使用できない全ての機能を利用するために、フルバージョンのデータブリックスの無料トライアルをご利用いただくことも可能です。