Databricksクイックスタートガイドのコンテンツです。
Manage clusters | Databricks on AWS [2021/3/21時点]の翻訳です。
本記事では、Databricksクラスターをどのように管理するのかを説明します。これには、表示、変更、開始、停止、削除、アクセスコントロール、パフォーマンス監視、ログが含まれます。
クラスターの表示
ワークスペースのクラスターを表示するには、サイドバーのクラスターアイコンをクリックします。
![]()
二つのタブ: All-Purpose ClustersとJob Clustersでクラスター一覧が表示されます。


それぞれのタブには、以下が表示されます:
- クラスター名
- 状態(英語)
- ノード数
- ドライバー、ワーカーノードのタイプ
- Databricksランタイムのバージョン
- クラスターの作成者、ジョブのオーナー
クラスターの共通的な情報に加え、All-Purpose Clustersタブでは、 にクラスターにアタッチされているノートブックの数が表示されます。
にクラスターにアタッチされているノートブックの数が表示されます。
All-purposeクラスター名の左のアイコンはクラスターがピン留めされているか、クラスターがhigh concurrency(英語)クラスターなのか、table access control(英語)が有効化されているのかが表示されます:
- ピン留め

- 起動中
 、停止中
、停止中
- 標準のクラスター
- 稼働中

- 停止

- 稼働中
- ハイコンカレンシークラスター
- 稼働中

- 停止

- 稼働中
- アクセス拒否
- 稼働中

- 停止

- 稼働中
- テーブルACLが有効
- 稼働中

- 停止

- 稼働中
All-purposeクラスターの一番右に表示されるリンク、ボタンは、Spark UI、ログ、停止、再起動、クローン、アクセス権、削除のアクションにリンクしています。

Jobクラスターの一番右に表示されるリンク、ボタンは、Job Runページ、Spark UI、ログ、停止、クローン、アクセス権のアクションにリンクしています。

クラスター一覧のフィルタリング
右上にあるフィルターフィールドとボタンを用いて、クラスター一覧をフィルタリングすることができます。

- あなたが作成したクラスターのみを表示するには、Created by meをクリックします。
- (cluster access control(英語)が有効化されている場合)あなたがアクセスできるクラスターのみを表示するには、Accessible by meをクリックします。
- Filterテキストフィールドに文字列を入力することで、クラスターを検索することができます。
クラスターのピン留め
停止されたクラスターは30日後に削除されます。停止後30日が経過してもall-purposeクラスターの設定が削除されないようにするには、管理者によってクラスターをピン留め(英語)することができます。最大70のクラスターをピン留めすることができます。
以下の方法でピン留めすることができます。
-
クラスター一覧
クラスターをピン留め、ピン留めの解除をするには、クラスター名の左のピンアイコンをクリックします。

-
クラスター詳細ページ
クラスターをピン留め、ピン留めの解除をするには、クラスター名の右のピンアイコンをクリックします。

また、プログラムからピン留めを行うために、Pin API(英語)を呼び出すことができます。
クラスター設定をJSON形式で参照
時には、JSON形式でクラスター設定を参照することが役立つことがあります。特にClusters API(英語)を用いて、同じ設定のクラスターを作成する際には有用です。既存のクラスターを参照する際に、Configurationタブで、右上のJSONをクリックするとJSONを参照することができますので、これをAPI呼び出しに貼り付けることができます。JSON表示部分は読み取り専用です。
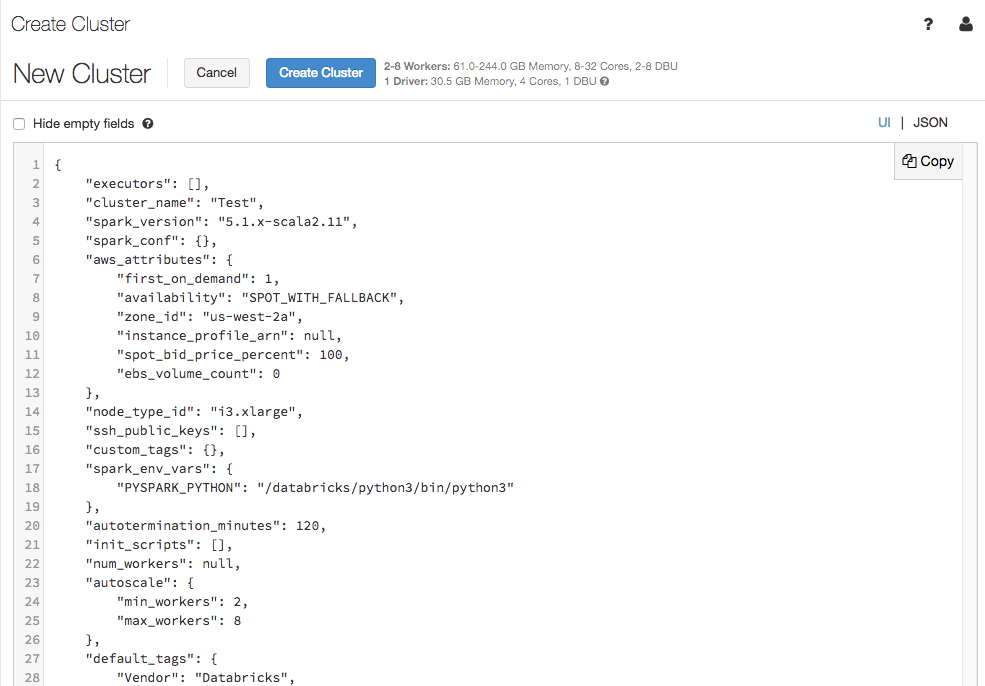
クラスターの編集
クラスター詳細ページからクラスター設定を編集することができます。

Edit APIエンドポイントを呼び出すことで、プログラムからクラスターを編集することができます。
注意
- クラスターにアタッチされたノートブックとジョブは、編集後もアタッチされ続けます。
- クラスターにインストールされたライブラリは、編集後もインストールされたままと編集後もインストールされたままとなります。
- 稼働中のクラスター(クラスターのサイズとアクセス権は除きます)の属性を編集した場合には再起動を行う必要があります。これは、クラスターを利用中のユーザーに影響を及ぼします。
- 稼働中、停止中の状態にあるクラスターのみを編集することができます。しかし、アクセス権に関しては、これら以外の状態のクラスター対しても、クラスター詳細ページで編集することができます。
編集できるクラスター設定の詳細に関しては、Configure clusters(英語)を参照ください。
クラスターのクローン
既存のクラスターをクローンして新たなクラスターを作成できます。
-
クラスター一覧

-
クラスター詳細ページ

クローン元のクラスターの設定が入力された状態でクラスター作成画面が表示されます。以下の情報はクローン先のクラスターには適用されません:
- クラスターのアクセス権
- ライブラリ
- アタッチされたノートブック
クラスターのアクセス権設定
Admin Console(英語)における、クラスターアクセス権によって、他のユーザーに対するきめ細かいアクセス権設定権限をユーザーに移譲することができます。大きく、2つのタイプのアクセス制御があります:
-
クラスター作成権限: 管理者はどのユーザーがクラスターを作成できるのかを選択できます。

-
クラスター単位の権限設定: クラスターに対してCan manage権限を有している場合には、クラスターアクションにある
 のアイコンをクリックすることで、どのユーザーがクラスターにアタッチ、再起動、サイズ変更できるのかを設定することができます。
のアイコンをクリックすることで、どのユーザーがクラスターにアタッチ、再起動、サイズ変更できるのかを設定することができます。

クラスターアクセス権、クラスター単位の権限をどのように設定するのかに関しては、Cluster access control(英語)を参照ください。
クラスターの起動
新たなクラスターを作成するのに加えて、以前停止したクラスターを起動することができます。これにより、元の設定を保持したまま、以前停止したクラスターを再作成することができます。
以下の方法でクラスターを起動することができます:
-
クラスター一覧

-
クラスター詳細ページ

-
ノートブックの
 クラスターアタッチのドロップダウンリスト
クラスターアタッチのドロップダウンリスト

Start API(英語)を利用することで、プログラムからクラスターを起動することができます。
Databricksにおいては、cluster ID(英語)でクラスターを一意に特定します。停止したクラスターを起動した場合、Databricksは同じIDでクラスターを再作成し、ライブラリをインストールし、ノートブックを再アタッチします。
ジョブにおけるクラスターの自動起動
既存の停止クラスターにアサインされたジョブ実行がスケジュールされた、あるいは、JDBC/ODBCインタフェースから停止クラスターに接続された場合には、クラスターは自動で再起動されます。詳細はCreate a job(英語)、JDBC connect(英語)を参照ください。
クラスター自動起動を用いることで、ジョブスケジュールのために手動でクラスターを再起動することなしに、クラスターの自動停止を設定することができます。さらに、停止クラスターに対してジョブをスケジュールすることで、クラスターの初期化処理をスケジュールすることができます。
自動でクラスターが再起動する前に、クラスター(英語)とジョブ(英語)のアクセス権が確認されます。
注意
Databricksプラットフォームバージョン2.70以前でクラスターが作成された場合、自動起動を利用することはできません。停止クラスターに対してジョブがスケジュールされた場合失敗します。
クラスターの停止
クラスターのリソースを保存するために、クラスターを停止することができます。停止クラスターでノートブックやジョブを実行することはできませんが、後で再利用(ジョブの場合は自動起動)できるように設定情報を保存することができます。手動で停止することもできますし、一定時間使われない場合に自動停止するように設定することもできます。Databricksはいつクラスターが停止したのかを記録します。停止クラスターの数が150を超えた場合には、古いものから削除します。

注意
新たなジョブクラスターでジョブを実行(推奨です)する際、ジョブが完了するとクラスターは停止し、これを起動することはできません。一方で、停止している既存all-purposeクラスターでジョブをスケジュールした場合、そのクラスターは自動起動します。
手動停止
以下の方法で手動停止を行うことができます。
-
クラスター一覧

-
クラスター詳細ページ

自動停止
クラスターの自動停止を設定することもできます。クラスター作成時に、クラスターを自動停止する不活性時間を指定することができます。最後にクラスターでコマンドが実行された時間と現在時刻の差が、指定された不活性時間を上回った場合、Databricksはクラスターを自動で停止します。
Sparkジョブ、構造化ストリーミング、JDBC呼び出しを含むクラスター上の全てのコマンドの実行が終了した際に、クラスターは不活性状態とみなされます。ここには、クラスターへのSSH接続を介したbashコマンドの実行は含まれません。
警告!
- クラスターはDStreamsの実行結果をレポートしません。すなわち、DStreams実行中にクラスターが自動停止される場合があります。DStreamを実行するクラスターで自動停止を無効にするか、構造化ストリーミングの利用をご検討ください。
- 自動停止はSparkジョブのみを監視し、ユーザー定義のローカルプロセスは監視しません。そのため、全てのSparkジョブが完了した場合、ローカルプロセスが稼働していたとしても、クラスターが自動停止する場合があります。
- 停止するまでは、不活性状態のクラスターでもDBUは消費され、クラウドサービスのインスタンスに対する課金も発生します。
自動停止の設定
クラスター作成ページのAutopilot OptionsにおけるAuto Terminationボックスで自動停止の設定を行うことができます。

重要!
クラスター作成時に、標準クラスター、ハイコンカレンシークラスター(英語)を選択するのかに応じて、自動停止のデフォルト値が異なります。
- 標準クラスターは、120分経過後に自動停止します。
- ハイコンカレンシークラスターでは、自動停止は設定されません。
Auto Terminationのチェックボックスを外すか、不活性状態の時間を0にすることで、自動停止をオプトアウトすることができます。
注意
自動停止機能は、最新のSparkで最適な動作をします。古いSparkバージョンにおいては、クラスターの活動を正確に報告しないなどの制限があります。例えば、JDBC、R、ストリーミングコマンドが古い活動時刻を報告し、不適切なクラスター停止につながる場合があります。バグフィクス、自動停止の改善などの恩恵を享受するために最新のSparkをご利用くだしあ。
予期しない停止
まれに、手動停止や自動停止によらず、予期せずにクラスターが停止することがあります。停止の理由や対策に関しては、Knowledge Base(英語)を参照ください。
クラスターの削除
クラスターの削除により、クラスターは停止され設定が削除されます。
警告!
このアクションを取り消すことはできません。
ピン留めされたクラスターを削除することはできません。削除するためには、管理者によってピンを解除する必要があります。
クラスターを削除するには、クラスター一覧にあるクラスターアクションの![]() アイコンをクリックします。
アイコンをクリックします。
Permanent delete API(英語)を使用することで、プログラムからクラスターを削除することができます。

Apache Spark UIでのクラスター情報の参照
Sparkジョブの詳細をSpark UIで参照することができます。以下の方法でSpark UIにアクセスすることができます:
- クラスター一覧: クラスターの行に表示されるSpark UIリンクをクリックします
- クラスター詳細ページ: Spark UIタブをクリックします
Spark UIは稼働中のクラスター、停止中のクラスター両方で表示することができます。

注意
停止クラスターが再起動すると、Spark UIには停止していたクラスターではなく、新たに起動したクラスターの情報が表示されます。
クラスターログの参照
Databricksは3種類のクラスター関連ログを提供します:
- クラスターイベントログ: 作成、停止、設定変更などクラスターのライフサイクルイベントを捕捉します。
- Apache Sparkドライバー、ワーカーログ: デバッグに活用できます。
- クラスターinit-scriptログ: init scriptのデバッグに活用できます。
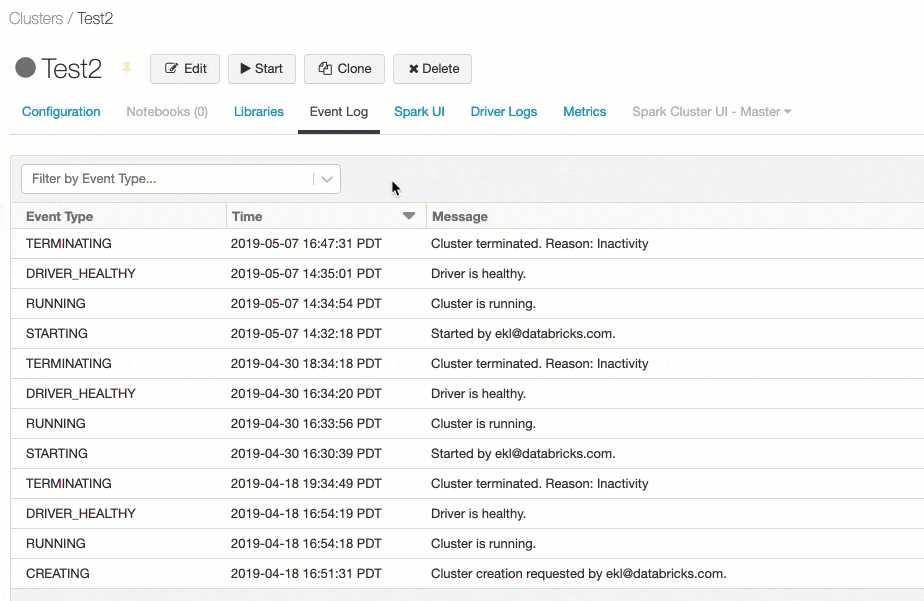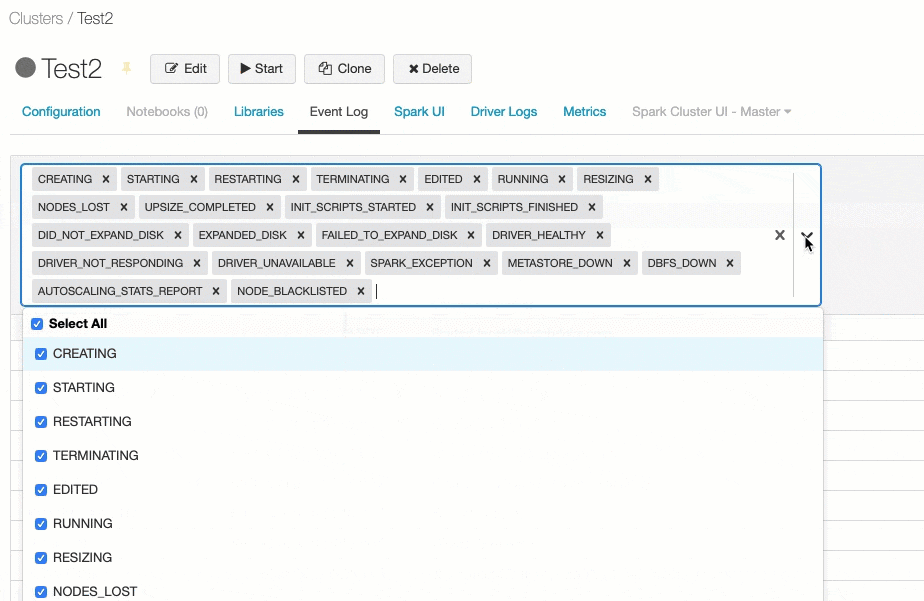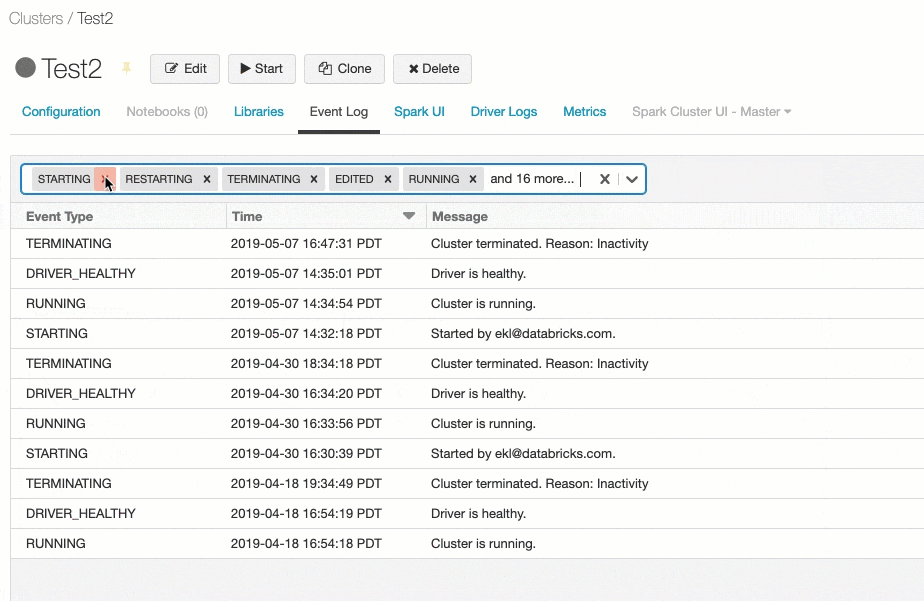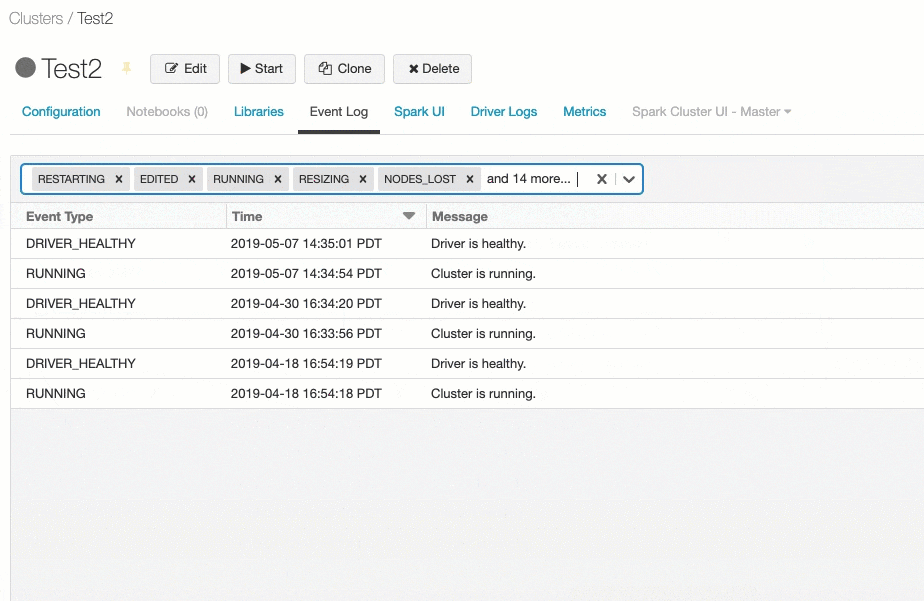
クラスターイベントログ
クラスターイベントログには、ユーザーによって手動で実行されたライフサイクルイベント、Databricksによって自動で実行されたライフサイクルイベントが含まれます。これらのイベントはクラスターのオペレーション、クラスターにおけるジョブの実行に影響を与えるものです。
サポートされているイベントタイプに関しては、REST APIのClusterEventType(英語)を参照ください。
クラスターイベントログの参照
-
サイドバーのclustersアイコンをクリックします。

-
クラスター名をクリックします。
-
Event Logタブをクリックします。

イベントをフィルタリングするには、**Filter by Event Type…**の をクリックし、一つ以上のイベントタイプにチェックを付けます。
をクリックし、一つ以上のイベントタイプにチェックを付けます。
特定のイベントを除外したい場合には、Select allを使うと便利です。
イベント詳細の参照
イベントの詳細を参照したい場合には、ログの行をクリックし、JSONタブをクリックします。

クラスターのドライバーノード、ワーカーノードのログ
ノートブック、ジョブ、ライブラリからの出力結果を参照するには、Sparkドライバーログを参照します。このログには以下の3種類のアウトプットが含まれます。
- 標準出力(Standard output)
- エラー出力(Standard error)
- Log4j logs
UIからこれらのドライバーログにアクセスするには、クラスター詳細ページのDriver Logsにアクセスします。

ログファイルは定期的にローテートされます。ページ上部から古いログから順にタイムスタンプと共に表示されます。トラブルシューティングのためにこれらのファイルをダウンロードできます。
ワーカーノードのログを参照するには、Spark UIを使用します。また、クラスターログの出力先を設定(英語)することができます。指定された格納場所に、ドライバーノード、ワーカーノードのログを保存することができます。
パフォーマンス監視
Databricksクラスターの性能を監視するために、Databricksでは、クラスター詳細ページからGangliaのメトリクスにアクセスすることができます。
また、Datadogのエージェントをクラスターにインストールし、あなたのDatadogアカウントにメトリクスを送信することができます。
Gangliaのメトリクス
GangliaのUIにアクセスするためには、クラスター詳細ページのMetricsタブにアクセスします。CPUメトリクスに関しては、Databricksランタイム全てのGanglia UIで参照することができます。GPUメトリクスはGPUが有効化されたクラスターでのみ参照できます。

メトリクスを参照するには、Ganglia UIリンクをクリックします。
過去のメトリクスを参照するには、スナップショットファイルをクリックします。スナップショットには、指定された時間までに蓄積されたメトリクスが含まれます。
メトリクス収集の設定
デフォルトでは、Databricksは15分間隔でGangliaのメトリクスを収集します。この周期を変更するには、init script(英語)かCluster Create API(英語)のspark_env_varsフィールドを用いて、環境変数DATABRICKS_GANGLIA_SNAPSHOT_PERIOD_MINUTESを設定します。
Datadogのメトリクス
クラスターにDatadogのエージェントをインストールし、Datadogのアカウントにメトリクスを送信することができます。以下のノートブックでは、クラスタースコープのinit script(英語)を用いて、どのようにDatadogのエージェントをインストールするのかを説明しています。