Databases and tables | Databricks on AWS [2021/3/22時点]の翻訳です。
警告!
こちらの内容は古いものとなっています。Databricksレイクハウスにおけるデータオブジェクトをご覧ください。
Databricksのデータベースはテーブルの集合体です。Databricksのテーブルは構造化データの集合体となります。Databricksテーブルに対して、Apache Sparkのデータフレーム(英語)でサポートされているあらゆる操作、フィルター、キャッシュを行うことができます。Spark API(英語)、Spark SQL(英語)を用いてテーブルに対してクエリーを実行することができます。
テーブルには2種類あります:グローバルテーブルとローカルテーブルです。グローバルテーブルは全てのクラスターからアクセスすることができます。DatabricksはグローバルテーブルをDatabricksのHiveメタストア、あるいは外部のHiveメタストア(英語)に登録します。Hiveサポートの詳細はApache Hive compatibility(英語)を参照ください。ローカルテーブルはHiveメタストアに登録されず、他のクラスターからはアクセスできません。これは一時ビューとも呼ばれます。
Create Table UI、または、プログラムからテーブルを作成することができます。DBFS上のファイル、あるいはサポートされている形式(英語)のデータからテーブルにデータを取り込むことができます。
要件
データベース、テーブルを作成、参照するためには起動しているクラスターが必要です。
データベースとテーブルの参照
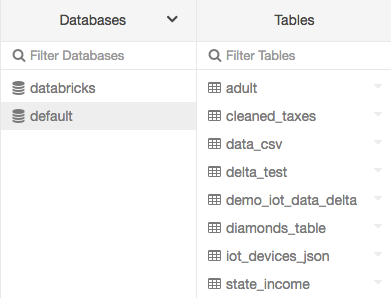
サイドバーの![]() をクリックします。Databricksはあなたがアクセス権を持つクラスターを選択します。
をクリックします。Databricksはあなたがアクセス権を持つクラスターを選択します。defaultデータベースが選択された状態でDatabasesフォルダーが表示されます。Tablesフォルダにはdefaultデータベースのテーブル一覧が表示されます。
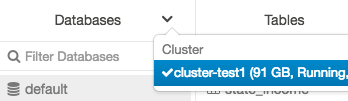
Databasesメニュー、Create Table UI、View Table UIからクラスターを変更することができます。例えば、Databasesメニューであれば:
- Databasesフォルダーの上部の
 をクリックします。
をクリックします。 - クラスターを選択します。
データベースの作成
SQLでデータベースを作成するには:
SQL
CREATE DATABASE <database-name> ...
他の選択肢に関しては、こちらをご覧ください。
- Databricksランタイム 7.x以上: CREATE DATABASE(英語)
- Databricksランタイム 5.5 LTS、6.x: Create Database(英語)
テーブルの作成
UIあるいはプログラムからテーブルを作成できます。
UIによるテーブルの作成
注意
UIでテーブルを作成する際、以下のことはできません。
- High Concurrency cluster(英語)を使用している際のファイルのアップロード。この場合、Databricksにデータをロードするためには、Databricks File System (DBFS)を使用してください。
- テーブルのアップデート。この場合、プログラムからテーブルを作成してください。
UIからテーブルを作成するとグローバルテーブルになります。
-
サイドバーの
 をクリックします。Databases、Tablesフォルダーが表示されます。
をクリックします。Databases、Tablesフォルダーが表示されます。 -
Databasesフォルダーでデータベースを選択します。
-
Tablesフォルダーの上部にあるAdd Dataをクリックします。

-
データソースを選択し、テーブルを設定する手順に従います。
- ファイルのアップロードはデフォルトでは有効になっています。Databricksの管理者がこの機能を無効(英語)にした場合、ファイルをアップロードすることはできませんが、他のデータソースにあるファイルを用いてテーブルを作成することはできます。

-
ファイルのアップロード
- ファイルをFileエリアにドラッグするか、Fileエリアをクリックし、ファイルを選択します。アップロード後にそれぞれのファイルパスが表示されます。ファイルパスは
/FileStore/tables/<filename>-<random-number>.<file-type>と言った形式になりますので、ノートブックでファイルパスを使用してデータを読み込みます。

- Create Table with UIをクリックします。
- データを参照するためのクラスターをClusterドロップダウンから選択します。
- ファイルをFileエリアにドラッグするか、Fileエリアをクリックし、ファイルを選択します。アップロード後にそれぞれのファイルパスが表示されます。ファイルパスは
-
S3
- Create Table with UIをクリックします。
- クラスタードロップダウンからクラスターを選択します。
- バケット名を入力します。選択したクラスターがS3にアクセスできるようになっている必要があります。
- Browse Bucketをクリックします。
- ファイルを選択します。
-
DBFS
- ファイルを選択します。
- Create Table with UIをクリックします。
- クラスタードロップダウンからクラスターを選択します。
-
- ファイルのアップロードはデフォルトでは有効になっています。Databricksの管理者がこの機能を無効(英語)にした場合、ファイルをアップロードすることはできませんが、他のデータソースにあるファイルを用いてテーブルを作成することはできます。
-
Preview Tableをクリックしてテーブルを参照します。
-
Table Nameフィールドで、デフォルトのテーブル名を上書きすることができます。テーブル名には小文字のアルファベット、数字、アンダースコアを含めることができますが、最初の文字は小文字のアルファベットかアンダースコアに限られます。
-
Create in Databaseフィールドで、選択されている
defaultデータベースを変更することができます。 -
File Typeで、識別されたファイルタイプを変更することができます。
-
CSVファイルの場合:
- Column Delimiterフィールドで、識別された区切り文字を変更することができます。
- 最初の行がタイトルであるかどうかを指定します。
- スキーマを推測するかどうかを指定します。
-
ファイルタイプがJSONの場合、ファイルがマルチラインなのかどうかを指定します。
-
Create Tableをクリックします。
ノートブックによるテーブルの作成
Create New Table UIには、あらゆるデータソースに接続できるDatabricksのクイックスタートノートブックを活用することができます。
- S3: Create Table in Notebookをクリックします。ノートブックをアタッチするクラスターがS3バケットにアクセスできるようになっている必要があります。
- DBFS: Create Table in Notebookをクリックします。
- 他のデータソース: Connectorのドロップダウンからデータソースタイプを選択し、Create Table in Notebookをクリックします。
プログラムでテーブルを作成
本章では、どのようにしてプログラムでグローバルテーブル、ローカルテーブルを作成するのかを説明します。
グローバルテーブルの作成
SQLでグローバルテーブルを作成するには以下を実行します。
SQL
CREATE TABLE <table-name> ...
他のオプションに関しては、Databricksランタイム 5.5 LTS及びDatabricksランタイム 6.4においてはCreate Table(英語)、Databricksランタイム 7.1以降においてはCREATE TABLE(英語)を参照ください。
PythonやScalaでデータフレームからグローバルテーブルを作成するには以下を実行します。
Python
dataFrame.write.saveAsTable("<table-name>")
ローカルテーブルの作成
PythonやScalaでデータフレームからローカルテーブルを作成するには以下を実行します。
Python
dataFrame.createOrReplaceTempView("<table-name>")
こちらはDatabricks File System (DBFS)上のファイルからdiamondsというローカルテーブルを作成する例となります。
Python
dataFrame = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv"
spark.read.format("csv").option("header","true")\
.option("inferSchema", "true").load(dataFrame)\
.createOrReplaceTempView("diamonds")
テーブルへのアクセス
テーブルに対して、詳細の参照、読み込み、アップデート、削除を行うことができます。
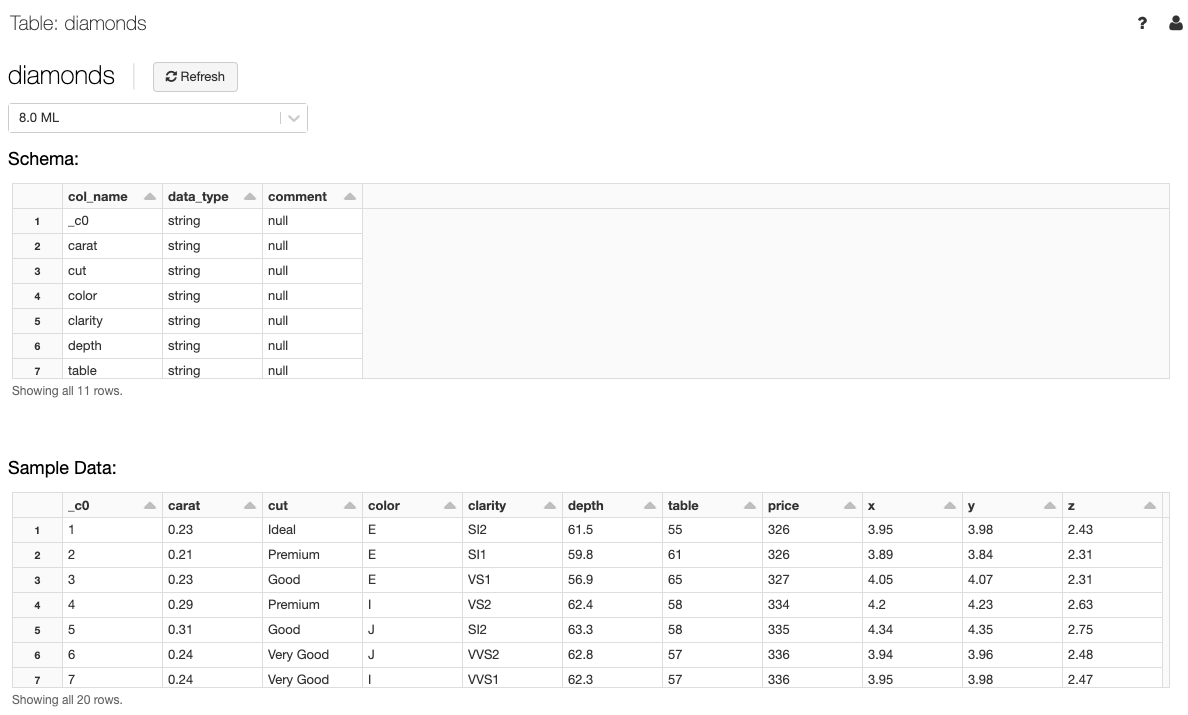
テーブル詳細の参照
テーブル詳細ではテーブルスキーマとサンプルデータを参照できます。
- サイドバーのをクリックします。
- Databasesフォルダーでデータベースをクリックします。
- Tablesフォルダーでテーブル名をクリックします。
- 必要に応じて、テーブルのプレビューをするためのクラスターをドロップダウンから選択します。
注意
テーブルのプレビューを表示するためには、Clusterドロップダウンで選択したクラスターでSpark SQLクエリーが実行されます。当該クラスターで別の処理が行われている場合、プレビューが表示されるまで時間がかかる場合があります。
テーブルに対するクエリー
以下が、それぞれの言語でdiamondsテーブルの内容を表示するサンプルになります。
SQL
SELECT * FROM diamonds
Python
diamonds = spark.sql("select * from diamonds")
display(diamonds.select("*"))
diamonds = spark.table("diamonds")
display(diamonds.select("*"))
R*
diamonds <- sql(sqlContext, "select * from diamonds")
display(diamonds)
diamonds <- table(sqlContext, "diamonds")
display(diamonds)
Scala
val diamonds = spark.sql("select * from diamonds")
display(diamonds.select("*"))
val diamonds = spark.table("diamonds")
display(diamonds.select("*"))
テーブルの更新
テーブルスキーマは不変(immutable)です。ですが、バックエンドにあるファイルを変更することでテーブルを更新することができます。
例えば、S3のディレクトリーから作成されたテーブルにおいては、当該ディレクトリでファイルの追加・削除を行うことでテーブルの中身を更新できます。
バックエンドのファイルを更新した後は、以下のコマンドでテーブルをリフレッシュします。
SQL
REFRESH TABLE <table-name>
これにより、バックエンドのファイルで更新があったとしても、テーブルにアクセスする際にSpark SQLで正しい内容を読み取ることができます。
テーブルの削除
UIでテーブルを削除
- サイドバーのをクリックします。
- テーブル名の隣にある
 をクリックし、Deleteを選択します。
をクリックし、Deleteを選択します。
プログラムでテーブルを削除
SQL
DROP TABLE <table-name>
マネージド、アンマネージドテーブル
全てのSpark SQLテーブルは、スキーマを格納するメタデータ情報とデータ自身を持っています。
マネージドテーブルは、Sparkがメタデータとデータの両方を管理するSpark SQLテーブルです。マネージドテーブルの場合、DatabricksはメタデータとデータをあなたのアカウントのDBFSに格納します。Spark SQLがテーブルを管理するので、DROP TABLE example_dataはメタデータとデータ両方を削除します。
マネージドテーブルを作成する一般的な方法は以下の通りとなります。
SQL
CREATE TABLE <example-table>(id STRING, value STRING)
Python
dataframe.write.saveAsTable("<example-table>")
もう一つの選択肢は、Spark SQLにはメタデータを管理させ、データの場所はあなたがコントロールするというものです。我々はこれをアンマネージドテーブルと呼びます。Spark SQLはメタデータを管理しますので、DROP TABLE example_dataを実行した際には、Sparkはメタデータのみを削除します。データ自身は削除しません。このため、あなたが指定した場所にデータは残り続けます。
CassandraやJDBCテーブルなどのデータソースにあるデータからアンマネージドテーブルを作成できます。Databricksでサポートしているデータタイプに関してはData sources(英語)を参照ください。アンマネージドを作成する一般的な方法は以下の通りです。
SQL
CREATE TABLE <example-table>(id STRING, value STRING) USING org.apache.spark.sql.parquet OPTIONS (PATH "<your-storage-path>")
Python
dataframe.write.option('path', "<your-storage-path>").saveAsTable("<example-table>")
テーブルコンテンツの置換
テーブルコンテンツを置換する方法には2つあります。シンプルなものと推奨のものです。
テーブルコンテンツ置換のシンプルな方法
テーブルコンテンツを置換するシンプルな方法は、テーブルのメタデータとデータを削除し、別のテーブルを作成するというものです。
マネージドテーブル
SQL
DROP TABLE IF EXISTS <example-table> // deletes the metadata and data
CREATE TABLE <example-table> AS SELECT ...
アンマネージドテーブル
SQL
DROP TABLE IF EXISTS <example-table> // deletes the metadata
Python
dbutils.fs.rm("<your-s3-path>", true) // deletes the data
SQL
CREATE TABLE <example-table> USING org.apache.spark.sql.parquet OPTIONS (PATH "<your-s3-path>") AS SELECT ...
警告!
上記のアプローチは妥当なものですが、S3にデータがある場合には、削除したデータと同じ場所に再作成しようとした際にS3 eventual consistency issuesの問題に遭遇する場合があります。一貫性問題に関して詳細を知りたい方は、ブログ記事S3mper: Consistency in the Cloudをご覧ください。
代替策としては、
-
SQL DLLを用いてテーブルを作成する。
CREATE TABLE <table-name> (id long, date string) USING PARQUET LOCATION "<storage-location>" -
新たな場所
<storage-location>にデータを格納する。 -
refresh table <table-name>を実行する。
テーブルコンテンツ置換の推奨方法
一貫性問題を回避するために、推奨するアプローチはテーブルを上書きするというものです。
Python
dataframe.write.mode("overwrite").saveAsTable("<example-table>") // Managed Overwrite
dataframe.write.mode("overwrite").option("path","<your-s3-path>").saveAsTable("<example-table>") // Unmanaged Overwrite
SQL
insert overwriteを追加います。この方法はマネージドテーブル、アンマネージドテーブルに適用できます。以下の例はアンマネージドテーブルに対するものです。
CREATE TABLE <example-table>(id STRING, value STRING) USING org.apache.spark.sql.parquet OPTIONS (PATH "<your-s3-path>")
INSERT OVERWRITE TABLE <example-table> SELECT ...
Scala
dataframe.write.mode(SaveMode.Overwrite).saveAsTable("<example-table>") // Managed Overwrite
dataframe.write.mode(SaveMode.Overwrite).option("path", "<your-s3-path>").saveAsTable("<example-table>") // Unmanaged Overwrite
テーブルのパーティション
Spark SQLは、テーブルに対するパーティション列を提供するために、ファイルストレージレベルで動的にパーティションを作成することができます。
パーティションされたテーブルの作成
以下の例は書き込んだデータをパーティションするものです。Spark SQLはパーティションを検知し、Hiveメタストアに登録します。
Scala
// Create managed table as select
dataframe.write.mode(SaveMode.Overwrite).partitionBy("id").saveAsTable("<example-table>")
// Create unmanaged/external table as select
dataframe.write.mode(SaveMode.Overwrite).option("path", "<file-path>").saveAsTable("<example-table>")
しかし、既存のデータからパーティションテーブルを作成する際は、Spark SQLは自動的にパーティションを検知し、Hiveメタストアに登録しません。この場合、SELECT * FROM <example-table>は結果を返しません。パーティションを登録するには、以下を実行してパーティションを作成します:MSCK REPAIR TABLE "<example-table>"
Scala
// Save data to external files
dataframe.write.mode(SaveMode.Overwrite).partitionBy("id").parquet("<file-path>")
// Create unmanaged/external table
spark.sql("CREATE TABLE <example-table>(id STRING, value STRING) USING parquet PARTITIONED BY(id) LOCATION "<file-path>"")
spark.sql("MSCK REPAIR TABLE "<example-table>"")
パーティションの刈り込み(pruning)
テーブルがスキャンされる際には、SparkはpartitionByを含むフィルター条件をプッシュダウンします。この場合、Sparkはこれらの条件に合致しないデータを読みません。例えば、<date>でパーティションされたテーブル<example-data>がある場合、SELECT max(id) FROM <example-data> WHERE date = '2010-10-10'と言ったクエリーは、クエリーで指定された条件と合致するdateを持つデータファイルのみを読み込みます。
テーブルのアクセスコントロール
テーブルアクセスコントロールによって、管理者とユーザーは他のユーザーに対してきめ細かいアクセスを設定することができます。詳細は、Databricksにおけるデータオブジェクトのアクセス権管理を参照ください。