Time Series Forecasting With Prophet And Spark - Databricksの翻訳です。
続きの記事はこちらとなります。
時系列データ予測のサンプルノートブックはこちらからダウンロードできます。
時系列データの予測技術の進化は、小売においてより信頼性のある需要予測を可能としました。今や、ビジネスサイドが製品在庫を正確に調整できる様に、適切な精度およびスピードでこれらの予測値を提供することが、新たな課題になっています。これらの課題に直面している多くの企業が、Apache Spark™とFacebook Prophetを活用することで、過去のソリューションの精度およびスケーラビリティの課題を克服しています。
本記事では、時系列データ予測の重要性を議論し、サンプル時系列データの可視化を行います。そして、簡単なモデルを構築してFacebook Prophetの使用法を説明します。単一のモデル構築に慣れた後で、ProphetとApache Spark™を結合させ、どの様にして数百のモデルを一度に学習するのかをお見せします。これにより、これまでは実現困難であった、個々の製品、店舗レベルでの正確な予測が可能となります。
正確かつタイムリーな予測はこれまで以上に重要となっています
小売において成功するためには、製品・サービスの需要を予測するために時系列データを分析するスピードと精度を改善することが重要です。もし、多くの商品を店舗に配置してしまうと、棚や倉庫のスペースは圧迫され、商品は期限切れとなり、彼らの経営資源は在庫に縛られてしまい、製造業、あるいは顧客の行動パターンの変化によってもたらされる新たな機会に対応することが不可能となります。また、商品を少なく配置してしまうと、顧客は必要な商品が買えないということになります。予測のエラーは小売業にとって収益ロスになるだけでなく、長期間に渡って顧客のフラストレーションを増加させ、競合に走ってしまうことになりかねません。
新たな期待は、より正確な時系列データ予測の手法とモデルを要求しています
かつて、ERPシステムとサードパーティのソリューションはシンプルな時系列モデルに基づく需要予測機能を提供していました。しかし、技術の進歩と業界全体におけるプレッシャーから、多くの小売業はこれまで使っていた線形モデルや従来のアルゴリズムの先に目を向け始めています。
データサイエンスコミュニティでは、Facebook Prophetによって提供される様な新たなケイパビリティが人気を得ており、多くの企業はこれらの機械学習モデルを時系列予測に適用できないか模索しています。
![]()
この従来の予測ソリューションからの決別は、小売業に対して内製することを求めることになりました。これは、需要予測の複雑性だけではなく、定められた時間内に数十万、数百万の機械学習モデルを構築するために効率的に処理を分散させる必要があったためです。幸運なことに、Sparkを用いることで、これらのモデル構築を分散させることができ、製品・サービスに対する全体の需要を予測できる様になっただけではなく、個々の場所における、個々の製品の需要を予測できる様にもなりました。
時系列データにおける需要の季節性の可視化
個々の店舗、製品に対する高精度の需要予測を行うためにどの様にProphetを使うのかをデモンストレーションするために、Kaggleで公開されているデータセットを使います。これは、10店舗における、50アイテムに対する5年間の日別の販売データです。
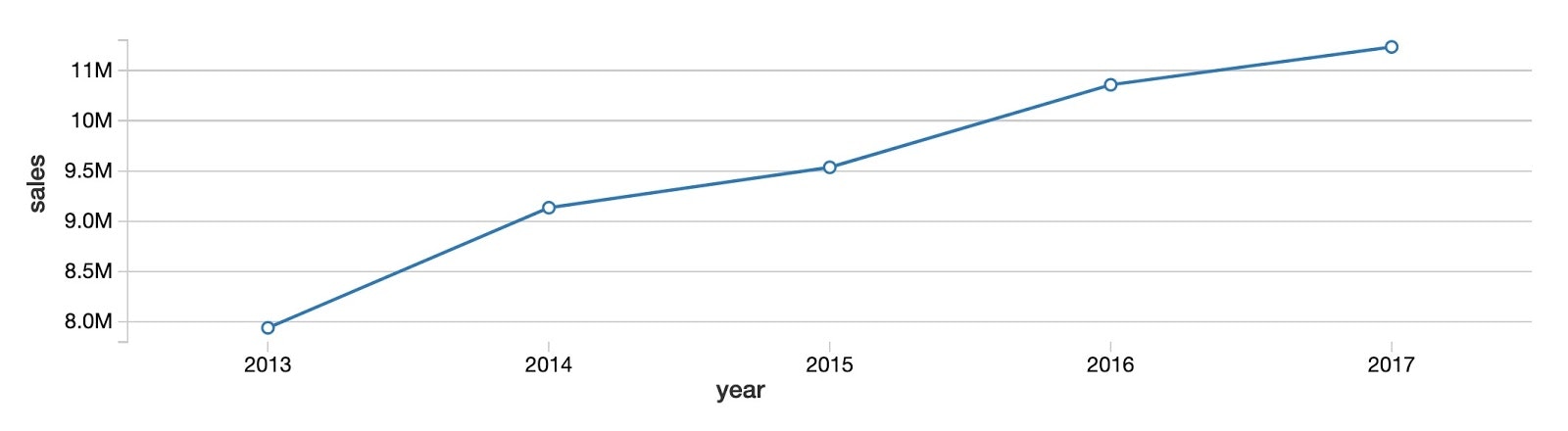
最初に、全商品、全店舗における年ごとの販売傾向を見てみます。下にある様に、特に飽和することなく、商品販売の合計が増加傾向にあることがわかります。
次に、同じデータを月ごとに見ることで、年ごとでは増加傾向にあったものが、月ごとでは単純に増加傾向にはないことがわかります。代わりに、夏を山、冬を谷とした明らかな季節性があることがわかります。Databricksのコラボレーティブノートブックにビルトインされている可視化機能を使うことで、チャート上にマウスカーソルを持っていくだけでデータの値を確認することができます。
曜日のレベルにおいては、セールスのピークが日曜日(weekday 0)にあり、月曜日(weekday 1)には激減し、以降徐々に増加傾向にあることがわかります。

Facebook Prophetにおける時系列データ予測モデル
上のチャートに現れている通り、このデータは、年レベル、週レベルでの季節性を伴って上昇傾向を示していることがわかります。Prophetは、この様にデータにおいて重複するパターンを取り扱うために設計されました。
Facebook Prophetはscikit-learn APIのパターンに従っているので、sklearnの経験がある人は簡単に利用できます。まず、2つの列を持ったpandasデータフレームをインプットとして渡す必要があります:最初の列は日付、第二の列は予測すべき値(本ケースにおいては売り上げ)を指定します。データが適切な形でフォーマットされているのであれば、モデル構築は容易です。
import pandas as pd
from fbprophet import Prophet
# instantiate the model and set parameters
model = Prophet(
interval_width=0.95,
growth='linear',
daily_seasonality=False,
weekly_seasonality=True,
yearly_seasonality=True,
seasonality_mode='multiplicative'
)
# fit the model to historical data
model.fit(history_pd)
これにより、データに対してモデルをフィットしたことになります。次にこのモデルを90日間の予測に使いましょう。下のコードでは、make_future_dataframeメソッドを使って、過去の日付と未来の90日を含むデータセットを定義しています。
future_pd = model.make_future_dataframe(
periods=90,
freq='d',
include_history=True
)
# predict over the dataset
forecast_pd = model.predict(future_pd)
これだけです!これで、Prophetにビルトインされている.plotメソッドで、実際の値と予測された値、さらには将来の予測値をまとめて可視化することができます。需要パターンにおける週ごとの季節性、年ごとの季節性が予測結果にも反映されているのがわかるかと思います。
predict_fig = model.plot(forecast_pd, xlabel='date', ylabel='sales')
display(predict_fig)

この可視化は若干ビジーです。Bartosz Mikulskiが見事にブレークダウンしていますので、是非参照ください。要は、黒い点が実際の値を示しており、暗い青の線が予測値、明るい青が95%の信頼区間となっています。
ProphetとSparkによる数百のモデルの並列トレーニング
単一の時系列予測モデルを構築できることを示しましたが、次にApache Sparkの力を借りて、我々の努力を倍増させます。我々の目的はデータセット全体に対する単一の予測を行うことではなく、個々の製品・店舗の組み合わせに対して、数百のモデルを構築し予測を行うことです。これを逐次的に実行した場合には、信じられないほど時間を要することになります。
この様にモデルを構築することで、例えば雑貨店チェーンにおいて、Sandusky店で注文すべき牛乳の量、Cleveland店で注文すべき牛乳の量をそれぞれ予測できる様になります。
時系列データ処理を分散処理するためのSparkデータフレームの使い方
c
もちろん、ワーカーノード(コンピューター)のクラスターにおけるモデル学習は、より多くのクラウドインフラストラクチャー及びそのコストを必要とします。しかし、オンデマンドでのクラウドリソースの高い可用性により、企業は必要に応じて迅速かつ柔軟にリソースを確保できます。これによって、自前で長い期間資産を持つことなしに、高いスケーラビリティを確保できます。
Sparkにおける分散データ処理の鍵となるメカニズムがデータフレームです。データをSparkデータフレームに読み込むことで、データはクラスターにおけるノードに分散されます。これにより各ワーカーは並列でデータのサブセットを処理できる様になり、処理全体に要する時間を削減することできます。
もちろん、個々のワーカーは処理に必要なデータに対するアクセス権を持つ必要があります。データにおけるキーの値(本ケースでは店舗とアイテムの組み合わせ)に基づきグルーピングを行い、特定のワーカーノードにこれらのキー値に対応する時系列データを持ってきます。
store_item_history
.groupBy('store', 'item')
# . . .
ここでは、どの様に効率的に並列でモデルを学習させるのかを示すために、groupByのコードを示していますが、実際には、次節でデータに対してUDFを適用するまでは使いません。
pandasのユーザー定義関数(UDFs)の活用
店舗とアイテムに基づいて、適切に時系列データをグルーピングすることで、個々のグループに対してモデルを構築することができます。これを行うためには、pandasにおけるユーザー定義関数(UDF)を利用できます。これにより、データフレームにおける各グループに対して、カスタム関数を適用することが可能となります。
このUDFは、個々のグループに対してモデルをトレーニングするだけではなく、モデルから得られる予測値も取得します。この関数は個々のグループとは独立して、データフレームにおける各グループを学習・予測しますが、最終的な結果は一つのデータフレームにまとめる形となります。これにより、店舗・アイテムレベルでの予測を生成しつつも、結果を単一のデータセットとして分析者に提示することが可能になります。
以下に、一部省略したPythonコードを示しますが、我々のUDFは比較的わかりやすいものになっています。UDFはpandas_udfメソッドに返却するデータのスキーマ及び受け取るデータのタイプを指定することで生成されます。
関数定義では、モデルを生成し、設定を行い受け取ったデータに対してフィッティングを行います。モデルによる予測を行い、関数の戻り値として予測データを返却します。
@pandas_udf(result_schema, PandasUDFType.GROUPED_MAP)
def forecast_store_item(history_pd):
# instantiate the model, configure the parameters
model = Prophet(
interval_width=0.95,
growth='linear',
daily_seasonality=False,
weekly_seasonality=True,
yearly_seasonality=True,
seasonality_mode='multiplicative'
)
# fit the model
model.fit(history_pd)
# configure predictions
future_pd = model.make_future_dataframe(
periods=90,
freq='d',
include_history=True
)
# make predictions
results_pd = model.predict(future_pd)
# . . .
# return predictions
return results_pd
まとめると、まずgroupByを用いて、店舗とアイテムの組み合わせに基づくデータグループを作成し、データグループに対してapplyを用いモデルのフィッティング、予測を行います。
個々のグループに対して関数を適用することで返却されるデータセットには、予測を実行した日付を追加します。これにより、繰り返しモデル構築を行なった際にデータを追跡でき、これらの機能を本番環境に移行する際にデータを特定するのに役立ちます。
from pyspark.sql.functions import current_date
results = (
store_item_history
.groupBy('store', 'item')
.apply(forecast_store_item)
.withColumn('training_date', current_date())
)
次のステップ
ここまでの取り組みにより、店舗・アイテムに紐づく時系列予測モデルを構築することができました。SQLクエリを用いて、分析者は個々の製品に対して仕立てられた予測値を参照することができます。以下のチャートにおいては、製品#1の10店舗における需要予測をプロットしています。チャートからわかる様に、店舗によって需要予測は異なっていますが、全体的なパターンには一貫性があります。
新たなセールスデータを取得する都度、既存のデータセットに追加することで効率的に新たな予測値を得ることができます。これにより、分析者は状況の変化に応じてビジネスの予測を更新することができます。より詳細を知りたい場合には、オンデマンドウェビナー「スターバックスは、Facebook ProphetとAzure Databricksを用いて、どの様に大規模需要予測を実現したのか」を参照ください。

続きの記事:
サプライチェーンの需要予測を改善する新たな手法 - Qiita