New Methods for Improving Supply Chain Demand Forecastingの翻訳です。
前回の記事の日本語版はこちらとなります。
原因因子による高精度の需要予測(fine-grain demand forecasting)
多くの組織が精度の高い需要予測を急速に採用しています
多くの小売製造業の人たちが、オムニチャネルのイノベーションの土台を作り、運転資本を削減し、コストを削減するために、サプライチェーンマネジメントを改善しようとしています。顧客の購買行動の変化が、サプライチェーンに対する新たな圧力となっています。製品、サービスに対する需要は、人件費、在庫管理、供給・生産計画、貨物、物流など多くのエリアにおける決定要因となるため、需要予測を通じて顧客をより理解しようとする取り組みは、この様な方向性における良いスタート地点となります。
AI Frontierの記事によれば、McKinsey & Companyは、小売のサプライチェーンの予測精度が10%から20%に改善することにより、在庫管理コストが5%削減され、2%〜3%の利益改善が見込めると主張しています。従来のサプライチェーン予測ツールは、期待された成果を出すことに失敗しています。小売における需要予測は平均32%のエラーがあるという主張に基づけば、少しの予測精度の改善であっても、多くの小売業においては多くの改善が見られることになります。結果として、多くの組織はプレパッケージされた予測ソリューションには見切りをつけ、需要予測スキルを内製し、かつては計算リソースの制限から予測精度に関して妥協していた過去の取り組みを見直しています。
これらの取り組みの重要なところは、より細かいレベルで、時系列、位置情報、製品情報に基づく予測をするという点です。高精度の需要予測は、需要を満たせるレベルで需要に影響を与えるパターンを捕捉できる可能性を秘めています。これまでは、市場レベル、流通レベルにおける商品クラスごとに短期間の予測を、月、週単位で行い、特定の店舗、日時に当該クラスの商品が配送される様に予測値を用いていたのかもしれませんが、高精度需要予測においては、特定の場所の特定の商品の動的特性を反映したより局所的なモデルの構築を可能にします。
高精度需要予測における課題
高精度需要予測がエキサイティングなものに聞こえる一方で、多くの課題もあります。第一に、集約型予測を用いないことにより、生成される予測モデルおよび予測値は爆発的な量になります。要求される処理能力は、既存の予測ツールでは実現不可能なものであるか、実現できるとしても、得られる情報を鮮度よく提供することが不可能です。この制限は、企業に対して、処理される商品分類の数と精度のトレードオフを突きつけることになります。
以前のブログで検証した様に、効率的な処理の実行、モデル構築の並列処理を実現し、上記課題を解決するためにApache Sparkを活用することができます。Databricksの様にクラウドネイティブのプラットフォームにSparkをデプロイすることで、需要に応じて柔軟に計算リソースを増減させることで、コストを予算内に収めること納めるが可能となります。第二の、かつ、解決すべき最も困難な課題は、集約した際に見える需要パターンが、より詳細なレベルでデータを検証した際には見えてこない場合があることを理解することです。アリストテレスの言葉を借りると、「個々の集合体よりも全体が大き句なることは頻繁にあるということです。我々は、分析をより詳細なレベルで行うことになりますので、粒度の粗いレベルでモデル化されたパターンが見えてこない場合があり、これは粒度の粗いレベルでは有効だったテクニックを活用することが難しくなることを意味します。予測の文脈におけるこの問題は、多くの実践者によって言及されており1950年代のHenri Theilにまで遡ることができます。
我々はトランザクションレベルの精度に目を向けることになりますので、個々の顧客の需要および購買意思に影響を及ぼす外部要因にも注意を払う必要があります。集計を行なった際、これらは平均化されるかもしれませんが、傾向や季節性は、粒度が細かいレベルであっても時系列変化を生み出すので、これらも予測モデルに直接組み込む必要があります。
最後に挙げるのは、より細かいレベルの粒度に目を向けることで、データ構造が従来型の予測テクニックが使えない可能性が高まるということです。より粒度の細かいトランザクションに目を向けるほど、データにおける不活性状態に取り組まなくてはならない可能性が高まるということです。このレベルの粒度においては、目的変数、特に販売数の様なカウントデータを取り扱う際には、単純な変換では対応し切れないほどのデータの偏りに対処しなくてはならず、多くのデータサイエンティストが慣れ親しんでいた領域外の予測技術を用いることが必要になってきます。
履歴データへのアクセス
詳細に関しては、データ準備のノートブックを参照ください。
これらの課題を検証するために、ここでは、Citi Bike NYCと呼ばれるニューヨーク市における自転車シェアプログラムの移動履歴データを活用します。Citi Bike NYCは「自転車を解放し、ニューヨークを解放する」を目標としている企業です。このサービスにより、ニューヨークエリアにある850以上のレンタルステーションにおいて自転車を借りることが可能になっています。この企業は、13,000台以上の自転車を保有しており、40,000台にまで増やす予定です。Citi Bikeにおいては、100,000以上の利用者があり、1日あたり14,000回以上の利用があります。
Citi Bike NYCは自転車が置かれた場所から、今後利用が予測される場所に自転車を再配置しています。Citi Bike NYCは小売業や製造業が日々取り組んでいるのと同様の課題に直面していました。どうすれば、リソースを最適な場所に配置できる様に需要を予測できるか? 仮に需要を低く見積もってしまえば、収益機会を逃すことになるし、潜在的には顧客の気分を害することになります。逆に需要を高く見積もってしまうと、使われない自転車の在庫を抱えることになります。
この公開されたデータセットには、プログラムが開始した2013年半ばから先月までの自転車レンタルに関する情報が含まれています。この履歴データには、どの自転車がいつどのステーションでレンタルされ、いつどこに返却されたのかが含まれています。ここでは、ステーションを小売値における店舗と考え、レンタル開始をトランザクションと考えます。この様にして、このデータを長期間に渡る詳細なトランザクションデータと近似して、予測に用います。
このモデリングの取り組みにおいては、考慮すべき外部要因を識別する必要があります。外部要因として、休日および過去の(および未来の)気象情報を外部要因とします。休日データセットに関しては、シンプルにPythonのholidaysライブラリから2013年から現在までの休日データを使用します。気象情報に関しては、人気のある気象情報アグリゲーターであるVisual Crossingから時間単位で抽出を行います。
利用規約上、Citi Bike NYCとVisual Crossingのデータセットを直接シェアすることはできません。ここで述べられている結果を再現したい方は、データ提供者のサイトを訪れ、利用規約を確認の上、適切な方法で自身の環境にデータをダウンロードしてください。我々は、分析に必要なでーた変換ロジックを提供します。
トランザクションデータの検証
2020年1月時点で、Citi Bike NYCのシェアプログラムは、ニューヨークエリアにおいて、特にマンハッタン地区を中心として864のアクティブなステーションを有しています。2019年だけでも、400万強のレンタルがあり、ピークの日には14,000のレンタルが発生しています。

プログラムの開始後、レンタル数は増加し続けています。この成長の背景には自転車利用の増加があると考えられますが、多くの要因は全体的なステーションネットワークの拡張にあると考えられます。


ネットワークにおけるレンタルステーション数でレンタル数を正規化すると、ステーションあたりの利用者数は過去数年間で徐々に増加しているのがわかります。
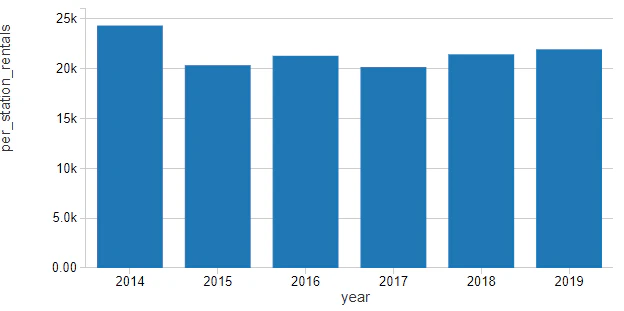
正規化したレンタル数を見ると、春に増加し、夏・秋にピークとなり、自転車には適さない気候の冬には底打ちになるというように、利用者数には季節性があることがわかります。

このパターンは都市の最高気温(華氏)のパターンに追従しているように見えます。

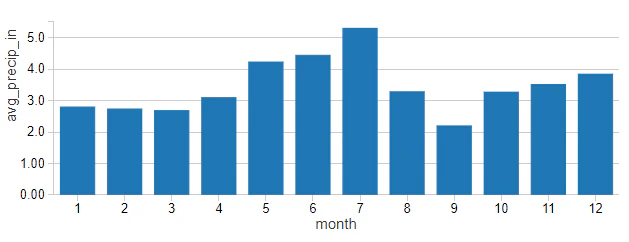
気温のパターンと月の利用者数を切り離すのは難しいかもしれませんが、降水量に関しては必ずしもそうとは言えません。
日曜日が1で土曜日が7で表現される曜日ごとの傾向を見ると、他の自転車シェアリングプログラムで見られるのと同様に、ニューヨーカーは自転車を通勤手段として使っていることがわかります。
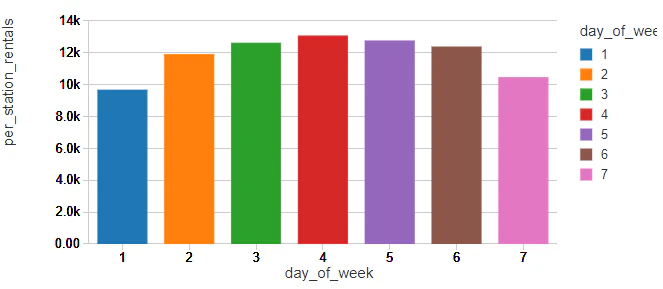
パターンを時間別にブレークダウンすると、標準的な通勤時間帯にスパイクがあることがわかります。週末においては、緩やかな傾向を示しており、当初の仮説を裏付けています。

興味深いパターンは休日にもあります。曜日に関係なく、週末のパターンに類似したものとなっています。休日の存在はこれらの傾向の特異点となるかもしれません。これらのグラフからは、信頼性のある予測を行うためには休日を特定することが重要であることを示していることが読み取れます。

時間別に集計すると、ニューヨークはまさに眠らない街であることがわかります。実際には、自転車がレンタルされていない時間の割合の多いステーションは多く存在しています。
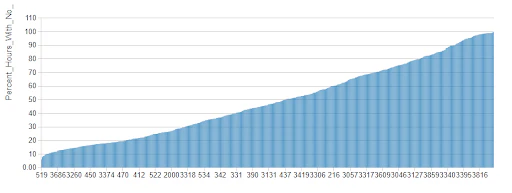
これらのアクティビティ量の差は、予測をこなう際に問題になり得ます。1時間から4時間の範囲において、全くレンタルが発生しないステーションは多く存在しますが、それぞれのステーションにおいてレンタルが発生しない期間は急激に減少します。

利用されていない期間の問題を避けるために、時間の粒度を大きくするのではなく、このデータセットに対して代替の予測手法がどのように貢献するのかを検証するために、ここでは時間単位での予測を試みます。大部分が利用されていないステーションの予測はそれほど面白いものではありませんので、我々は上位200のアクティブなステーションを対象にします。
Facebook Prophetによる自転車シェアレンタルの予測
ステーションごとの自転車レンタルを予測するに際して、我々は時系列予測で人気の高いPythonライブラリのFacebook Prophetを利用します。モデルは日次、週次、年次の季節性パターンの線形増加を探索するために設定されています。休日が関連づけられた期間データセットを用いることで、アルゴリズムによって抽出された全体傾向、季節性に対して、特異点が影響を及ぼすことを避けることができます。
前回のブログポストで述べたようにスケールアウトできるパターンを使用します。モデルはアクティブな200ステーションそれぞれの36時間の予測を生成します。全体として、モデルはRoot Mean Squared Error(RMSE)は5.44、Mean Average Proportional Error(MAPE)は0.73(MAPEの計算においては実際のゼロは1に調整されます)の精度を達成しました。
これらのメトリクスは、レンタルをそれなりの精度で予測していますが、時間あたりの利用率が急激に変動した場合には精度が良くないことを示しています。個々のステーションのレンタル数を可視化することで、この傾向を容易に確認できます。例えば、E 39 St & Aveのステーション518においては、RMSEは4.58、MAPEは0.69となっています:
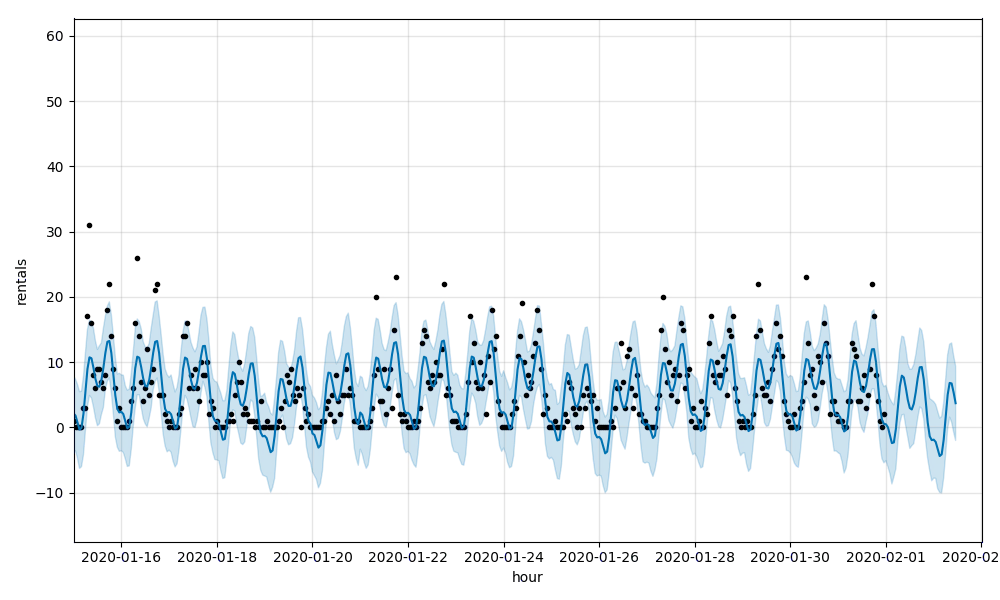
モデルを気温と降水量を考慮するように調整します。全体的には、RMSEは5.35、MAPEは0.72となります。わずかに改善しましたが、モデルはまだステーション単位での急激な利用者数の変化に追従できていません。ステーション518のRMSEは4.51、MAPEは0.68です。
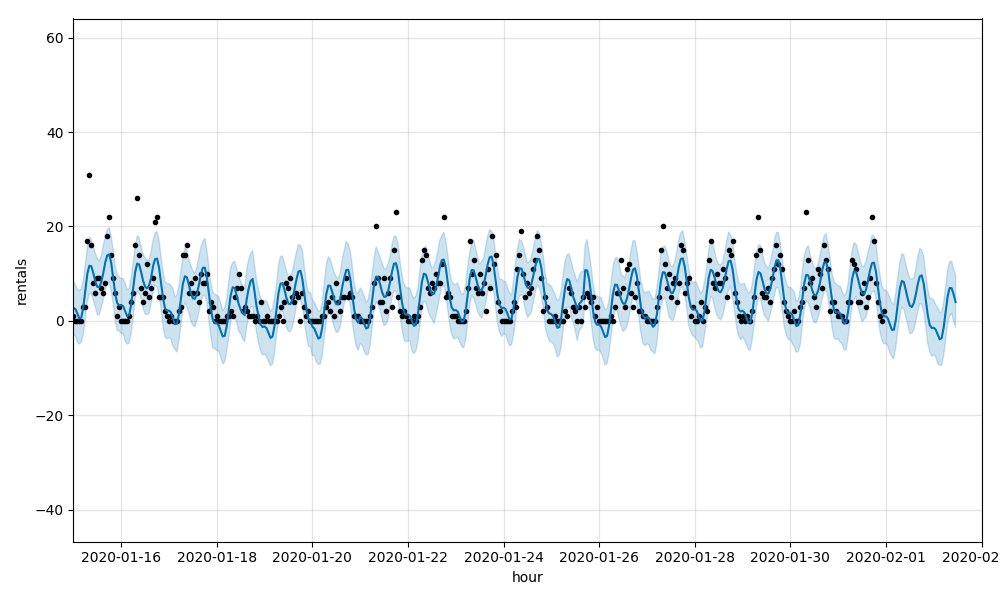
両方の時系列モデルにおいて、高次の値を予測することが難しいケースは、ポアソン分布を持つデータを予測する際には典型的なものとなっています。このような分布においては、平均値以上のロングテールを伴う、平均値周辺に集まる大量の値を見ることになります。平均値の反対側においては、ゼロ値の底が存在し、データは偏りのあるものとなってしまいます。今時点では、Facebook Prophetはデータが正規(Gaussian)分布であることを前提としていますが、ポアソン分布のサポートが現在議論されている状況です。
サプライチェーン需要予測の他のアプローチ
だとしたら、我々はここからどうすればいいのでしょうか? 解決策の一つとして、Facebook Prophetのコントリビュータが検討しているのと同様に、従来の時系列予測モデルの文脈で、ポアソン回帰の機能を活用するというものが挙げられます。素晴らしいアプローチにも思えますが、自身で実装するには十分なドキュメントが存在しておらず、他の方法が存在しないか検討した方が良さそうです。
別のアプローチとしては、非ゼロの規模とゼロ値期間の発生頻度をモデル化するというものが挙げられます。それぞれのモデルのアウトプットを結合して予測を行います。Croston's methodと呼ばれるこの手法は、あるデータサイエンティストが自身で実装したものもありますが、最近リリースされたcroston Python libraryでサポートされています。しかし、これはあまり広く使われている手法ではありませんし(手法自体は1970年代から存在しています)、我々としてはアウトオブボックスでできることを好みます。
このため、ランダムフォレストによる回帰がそれなりに適していると考えます。一般的に、決定木は多くの統計手法のようにデータ分布の制約を受けません。予測変数の値のレンジは、トレーニング前にレンタル数の平方根を取るなどして変形させた方が好ましいことを示しています。もちろん、変形しない状態でトレーニングした際の精度も見た方が良いです。
モデルを活用するためには、いくつかの特徴量エンジニアリングが必要となります。データには強い季節性が年レベル、週レベル、日レベルで存在していることが、EDAから明らかになっています。このことから、特徴量として年、月、曜日、時間を特徴量とします。また、休日フラグも特徴量に含めます。
ランダムフォレスト回帰と時間に基づく特徴量を用いて、全体的に3.4のRMSE、0.39の MAPEに到達できました。ステーション518においては、RMSEは3.09、MAPEは0.38となっています。
これらの時系列特徴量と、降水量、気温のデータを活用することで、より変動が激しい場合でも(完全ではないにしても)より良い精度を達成することができます。ステーション518においては、RMSEは2.14まで減少し、MAPEは0.26になりました。全体的には、RMSEは2.37、MAPEは0.26となり、自転車レンタル数の予測においては、気候データが重要であることがわかりました。

結果から得られる示唆
高精度の需要予測においては、モデル構築においてこれまでと異なるアプローチを考える必要が出てくるかもしれません。ハイレベルでの時系列パターンでは平均化、要約されてしまう外部要因も、高精度の需要予測においては明示的に組み込む必要があるかもしれません。平均した場合には隠れてしまう、データ分布のパターンもモデリングアプローチにおいては変化を組み込む必要があるかもしれません。このデータセットにおいては、時間ごとの気候データを取り込み、従来の時系列予測技術ではなく、入力データに適したアルゴリズムを選択することで、うまく問題に取り組むことができました。
他の外部要因、代替のアルゴリズムを探す過程で、あるサブセットデータにおいては、他のものより良い精度を出すケースがあるかもしれません。新たなデータが追加された際には、これまでうまく動いていたアルゴリズムを捨てる決断をし、新たな技術を検討する必要があるかもしれません。
高精度需要予測を試行しているお客様とともに我々が見た一般的なパターンでは、それぞれのトレーニング、予測のサイクルで複数の技術を評価し、有効なものを自動化されたモデルとして作り上げます。モデルを作り上げる際には、あるデータのサブセットにおいて、最高の精度を出すモデルをベストモデルと位置付けます。最終的には、適用するアルゴリズムとデータが調和した状態となり、適切なデータサイエンスが行われていることを確認します。しかし、本記事で繰り返し述べたように、そこには単一のソリューションは存在しません。このような状況において、Apache SparkやDatabricksと言ったプラットフォームを活用することで、可能性のある方向性を全て検証するための計算資源を手にすることができ、ビジネス課題を解決するためのベストなソリューションを提供することができます。