Visualizations | Databricks on AWS [2021/3/30時点]の翻訳です。
Databricksでは、display、displayHTML関数を用いて、様々な可視化を行うことができます。
また、Databricksでは、Python、Rネイティブの可視化ライブラリも利用でき、サードパーティのライブラリをインストールすることができます。
display関数
display関数はいくつかのデータタイプ、可視化をサポートしています。
本章では以下を説明します。
データタイプ
データフレーム
Databricksでデータフレームを可視化する簡単な方法は、display(<dataframe-name>)を呼び出すことです。例えば、ダイアモンドの色でグルーピングされ、平均価格を含むダイアモンドデータセットdiamonds_dfのSparkデータフレームがある場合には以下を実行します。
Python
from pyspark.sql.functions import avg
diamonds_df = spark.read.csv("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header="true", inferSchema="true")
display(diamonds_df.select("color","price").groupBy("color").agg(avg("price")))
ダイアモンドの色と平均価格がテーブルとして表示されます。

ティップス
display関数を読んだ後にOKと表示される場合は、渡したデータフレームが空であることがほとんどです。
display()はpandas DataFramesをサポートしています。displayを使わずにpandas、Koalasデータフレームを参照した場合、Jupyterノートブックで表示されるのと同じようにテーブルが表示されます。
データフレームdisplayメソッド
注意
Databricksランタイム7.1以降で利用できます。
PySpark、pandas、Koalasデータフレームは、Databricksのdisplay関数を呼び出す、displayメソッドを持っています。Dataframeの操作後に呼び出すことができます。例えば、
Python
diamonds_df = spark.read.csv("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header="true", inferSchema="true")
diamonds_df.select("color","price").display()
あるいは、連鎖したDataframe操作の最後に追加できます。
Python
from pyspark.sql.functions import avg
diamonds_df = spark.read.csv("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header="true", inferSchema="true")
diamonds_df.select("color","price").groupBy("color").agg(avg("price")).display()
画像
displayは、画像を含む列をHTMLでレンダリングします。displayは、SparkのImageSchemaに該当するデータフレームのカラムに対して、サムネイルを作成します。readImages:org.apache.spark.sql.DataFrameによる画像読み込みが成功した場合、サムネイルがレンダリングされます。他の方法で生成された画像に対しては、Databricksは、以下の制約を持つ1、3、4チャンネルイメージ(それぞれのチャンネルは単一のバイト)をサポートしています。
-
1チャンネルイメージ:
modeフィールドは0であること。height、width、nChannelフィールドはdataフィールドのバイナリ画像データを正確に表現すること。 -
3チャンネルイメージ:
modeフィールドは16であること。height、width、nChannelフィールドはdataフィールドのバイナリ画像データを正確に表現すること。dataフィールドは3バイトチャンクのピクセルデータが含まれていること。それぞれのピクセルが(blue, green, red)の順のチャンネルになっていること。 -
4チャンネルイメージ:
modeフィールドは24であること。height、width、nChannelフィールドはdataフィールドのバイナリ画像データを正確に表現すること。dataフィールドは4バイトチャンクのピクセルデータが含まれていること。それぞれのピクセルが(blue, green, red, alpha)の順のチャンネルになっていること。
例
フォルダーに以下の画像があるものとします。

ImageSchema.readImagesで画像をデータフレームに読み込み、データフレームを表示した際、displayは画像のサムネイルをレンダリングします:
Python
from pyspark.ml.image import ImageSchema
image_df = ImageSchema.readImages(sample_img_dir)
display(image_df)

構造化ストリーミングデータフレーム
リアルタイムでストリーミングクエリーの結果を可視化するには、ScalaあるいはPythonで構造化ストリーミングデータフレームにdisplayを適用します。
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
displayは以下のオプションパラメータをサポートしています:
-
streamName: ストリーミングクエリーの名前 -
trigger(Scala)、processing Time(Python): ストリーミングクエリーの実行間隔。指定されない場合は、システムは以前の処理が終わり次第すぐに新たなデータをチェックします。本番環境でのコストを削減するためには、常にトリガー間隔を指定することをお勧めします。Databricksランタイム8.0以降では、デフォルトのトリガー間隔は500msです。 -
checkpointLocation: システムがチェックポイント情報を書き込む場所を指定します。指定されない場合には、システムは自動的にDBFS上に一時的なチェックポイントの格納場所を生成します。ストリーム処理を中断したところから再開できるようにするために、チェックポイントの格納場所を指定する必要があります。常にcheckpointLocationオブションを指定することをお勧めします。
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
より詳細に関しては、Starting Streaming Queries(英語)を参照ください。
プロット
displayは以下のプロットタイプをサポートしています:
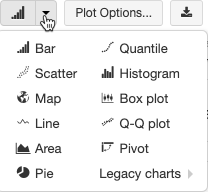
チャートタイプの選択、設定
棒グラフにするには、棒グラフアイコン をクリックします:
をクリックします:

他のプロットタイプを選択するには、棒グラフアイコンの右の をクリックしてプロットタイプを選択します。
をクリックしてプロットタイプを選択します。
チャートツールバー
棒グラフ、線グラフは、豊富なインタラクションをサポートするビルトインのツールバーを持っています。
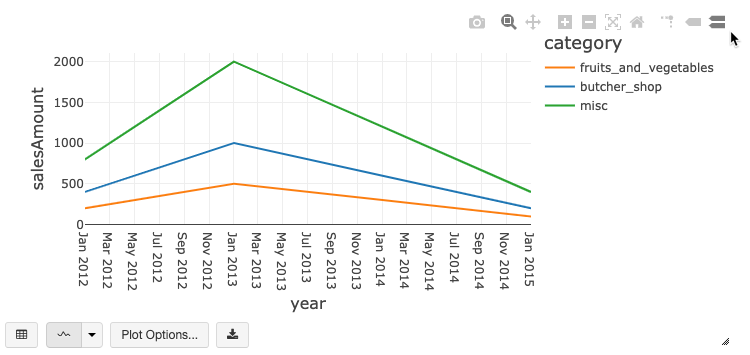
グラフを設定するには、**Plot Options…**をクリックします。

線グラフはいくつかのカスタムオプションを有しています: Y軸のレンジの設定、点の表示・非表示、Y軸をlogスケールで表示。
これらのチャートタイプに関しては、Legacy line charts(英語)を参照ください。
チャート間の色の一貫性
Databricksでは、シリーズセットとグローバルという2種類のチャート間の色の一貫性をサポートしています。
シリーズセットの色の一貫性は、順序が異なるデータセットがあったとしても同じ値に同じ色を割り当てるというものです(例えば、A = ["Apple", "Orange", "Banana"]とB = ["Orange", "Banana", "Apple"])。プロットする前に値は並び替えられるので、凡例も同じ順序になり(["Apple", "Banana", "Orange"])、同じ値に同じ色が割り当てられます。しかし、データセットC = ["Orange", "Banana"]がある場合、要素が異なるため、データセットAと一貫性持つことができません。並び替えアルゴリズムは、最初の色をデータセットCの"Banana"に割り当てますが、2番目の色をデータセットAの"Banana"に割り当ててしまいます。これらのデータセットで一貫性を保ちたい場合には、グラフがグローバルで色の一貫性を持つように設定することができます。
グローバルの色の一貫性では、データセットがどのような要素を持とうとも一貫性を保つように色がマッピングされます。有効化するためには、それぞれのグラフでGlobal color consistencyをチェックします。
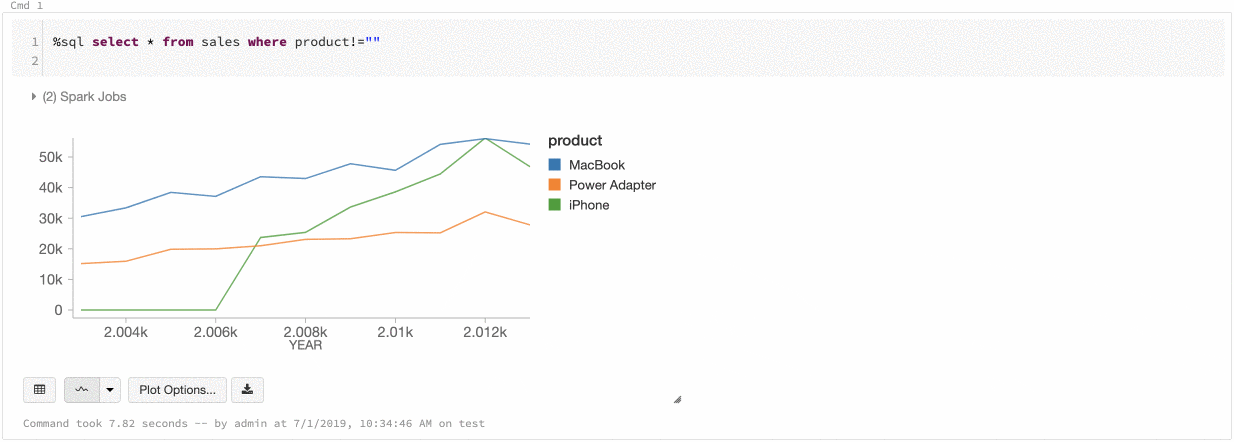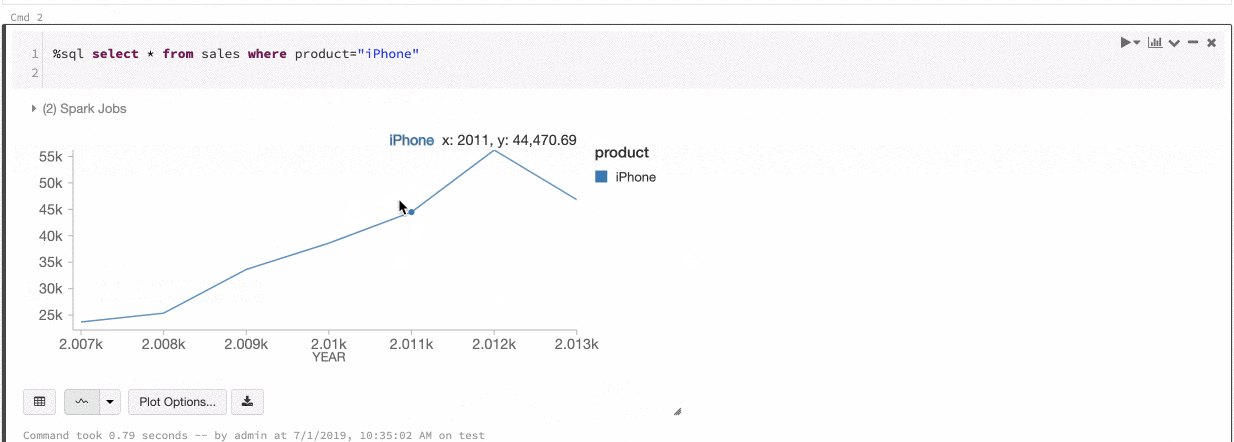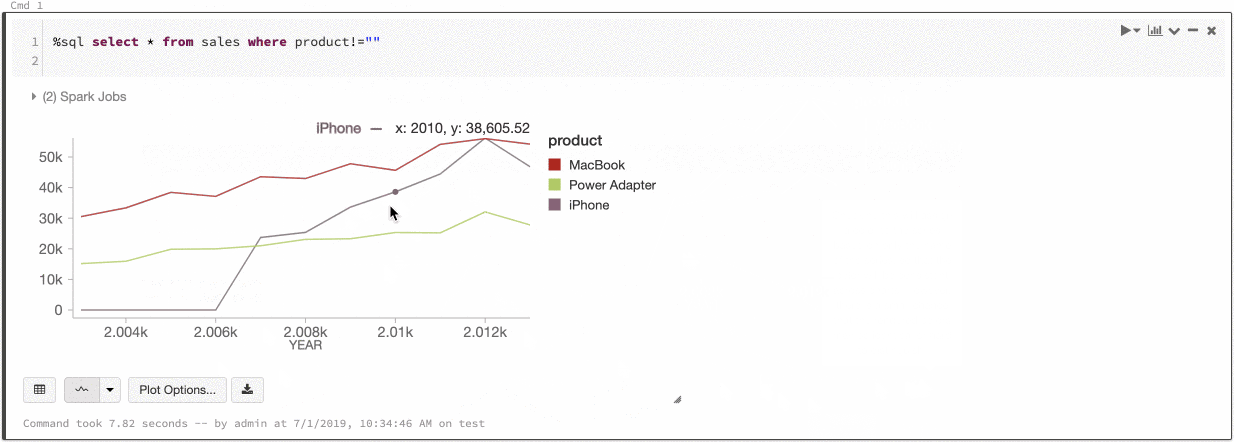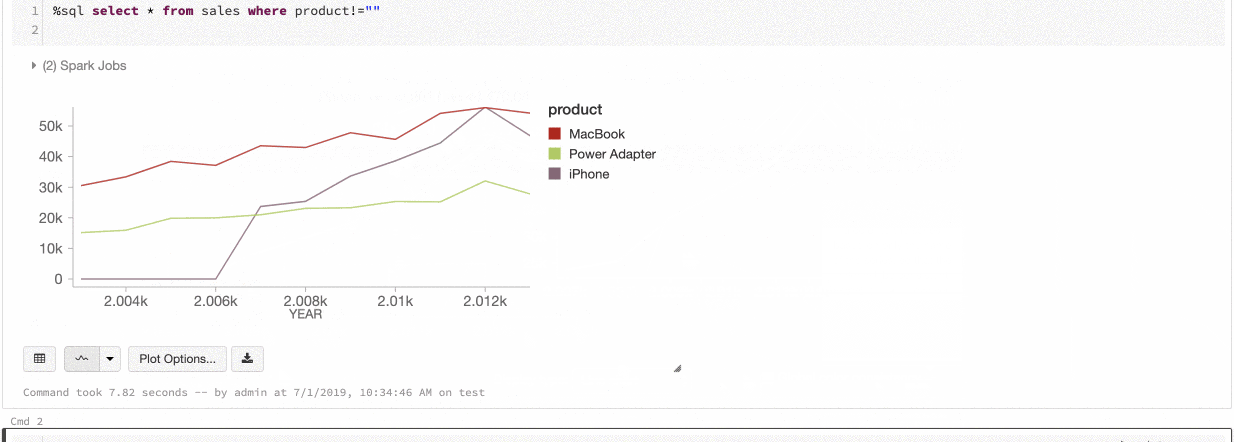
注意
この一貫性を実現するために、Databricksは値から色のハッシュ値を直接計算します。衝突(異なる値が同じ色にマッピングされる)を避けるためには、大規模な色の集合に対してハッシュ値を計算する必要があります。これは、似たような色に値がマッピングされ、色を見分けにくくなるという副作用をもたらします。
機械学習の可視化
標準的なグラフに加え、displayは以下の機械学習トレーニングパラメータ、トレーニング結果の可視化をサポートしています。
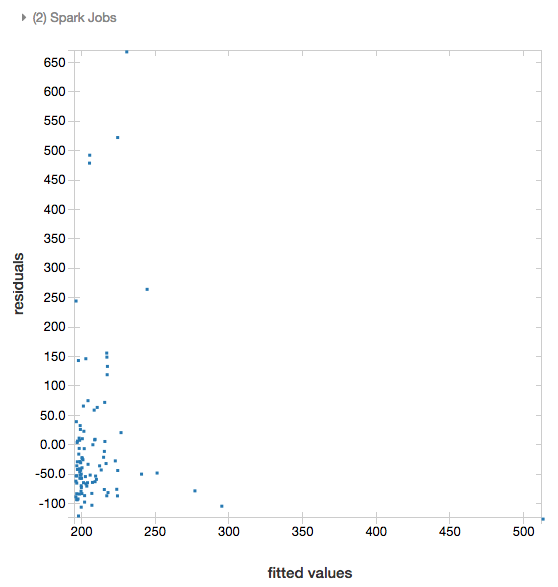
残差(Residual)
線形回帰、ロジスティック回帰において、displayはfitted versus residualsのプロットをレンダリングします。このプロットを行うには、モデルとデータフレームをdisplayに渡します。
Python
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
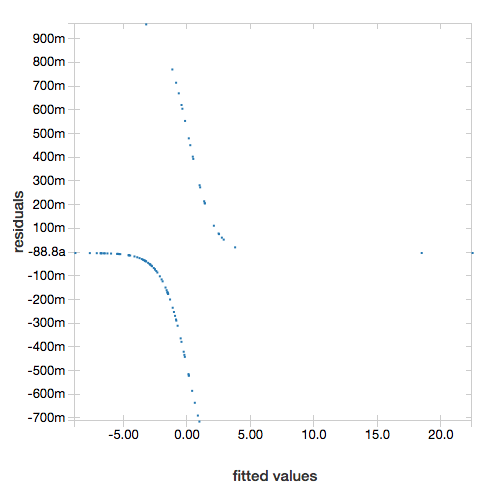
ROCカーブ
ロジスティック回帰においては、displayはROCカーブをプロットします。このプロットを行うには、displayにモデル、fitメソッドで用いたデータ、そして "ROC"パラメーターを指定します。
以下の例では、様々な属性から年収が50K以下なのか50K以上なのかを予測する分類機を構築します。国勢調査データから得られる成人のデータは、48842人の情報と年収から構成されています。
本章のサンプルコードではワンホットエンコーディングを使用します。Apache 3.0で関数名が変更になっているため、Databricksランタイムのバージョンによっては、若干コードが変更になります。Databricksランタイム6.x以下を使用している場合には、コメントに記載されているように、2箇所の修正が必要となります。
Python
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
# If you are using Databricks Runtime 6.x or below, comment out the preceding line and uncomment the following line.
# from pyspark.ml.feature import OneHotEncoderEstimator, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# If you are using Databricks Runtime 6.x or below, comment out the preceding line and uncomment the following line.
# encoder = OneHotEncoderEstimator(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")

残差を表示するには、"ROC"パラメーターを削除します。
Python
display(lrModel, preppedDataDF)
決定木
display関数は決定木のレンダリングをサポートしています。この可視化を行うためには、決定木モデルをdisplayに指定します。
以下の例では、手書きされた数字の画像を含むMNISTデータセットから数字(0-9)を識別する決定木をトレーンングし、決定木を表示します。
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)

displayHTML関数
Databricksノートブック(Python、R、Scala)はdisplayHTML関数によるHTMLグラフィクスの表示をサポートしています。どのようなHTML、CSS、JavaScriptのコードを渡すことができます。この関数は、D3のようなJavaScriptライブラリを用いたインタラクティブなグラフィクス表示をサポートしています。
displayHTMLを用いた例は以下のとおりです:
注意
displayHTMLのiframeはドメインdatabricksusercontent.comから提供され、iframeサンドボックスはallow-same-origin属性を含んでいます。あなたのブラウザーからdatabricksusercontent.comにアクセスできる必要があります。企業ネットワークでブロックされている場合には、許可リストに追加する必要があります。
プログラミング言語による可視化
本章では以下を説明します。
- Pythonによる可視化
- Rによる可視化
- Scalaによる可視化
- SQLによる可視化
Pythonによる可視化
Pythonでデータをプロットするには、以下のようにdisplay関数を使います。
Python
diamonds_df = spark.read.csv("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header="true", inferSchema="true")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
本章では、以下を説明します。
ディープダイブのためのPythonノートブック
displayを使ったPythonでの可視化をより知りたい場合には、以下のノートブックを参照ください。
Seaborn
プロットするために、他のPythonライブラリを使うことができます。Databricksランタイムには、Seaborn可視化ライブラリが含まれています。Seabornでプロットするには、ライブラリをインポートし、プロットを作成し、プロットをdisplay関数に渡すだけです。
Python
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)

他のPythonライブラリ
Rによる可視化
Rでデータをプロットするには、以下のようにdisplay関数を使用します。
R
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
Rデフォルトのplot関数を使うこともできます。
R
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)

どのようなRの可視化パッケージを使うことも可能です。Rノートブックは結果のプロットを.pngとしてキャプチャし、インラインで表示します。
本章では以下を説明します。
Lattice
Latticeパッケージは、変数、変数間の関係を表示するtrellisグラフをサポートしています。
R
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")

DandEFA
DandEFAパッケージはダンデライオンプロットをサポートしています。
R
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)

Plotly
PlotlyのRパッケージは、htmlwidgets for Rに依存しています。インストール方法とノートブックに関しては、htmlwidgetsを参照ください。
その他のRライブラリ
Scalaによる可視化
Scalaでデータをプロットするには、以下のようにdisplay関数を使います。
Scala
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
ディープダイブのためのScalaノートブック
displayによるScalaでの可視化を学びたい場合には、こちらのノートブックを参照ください。
SQLによる可視化
SQLクエリーを実行した際、Databricksは自動で一部のデータを抽出し、テーブル形式で表示します。
SQL
SELECT color, avg(price) AS price FROM diamonds GROUP BY color ORDER BY COLOR
ここからグラフのタイプを選択できます。