Best practices: Cluster configuration | Databricks on AWS [2022/10/11時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricksクイックスタートガイドのコンテンツです。
Databricksは、低いコストでベストなパフォーマンスを得られるようにクラスターを作成、設定する際に数多くのオプションを提供します。しかし、ワークロードに最適な設定を決定する際にこの柔軟性が課題となるケースもあります。ユーザーがクラスターをどのように活用するのかを注意深く検討することは、既存クラスターを設定、新規クラスターを作成する際に設定を選択する際の助けになります。設定を決定する際に検討すべき項目には以下のものがあります。
- どのようなタイプのユーザーがクラスターを利用するのか?データサイエンティストはデータエンジニアやデータアナリストとは異なる要件に基づいて、異なるタイプのジョブを実行することになるでしょう。
- クラスターでどのようなタイプのワークロードが実行されるか?例えば、バッチの抽出、変換、ロード(ETL)ジョブは分析ワークロードと異なる要件を持つことになるでしょう。
- 目指すべきサービスレベルアグリーメント(SLA)とは何か?
- 予算の制約は何か?
本書では、これらの検討に基づいて様々なシナリオにおける推奨設定事項をご説明します。本書ではDatabricksクラスターの特定の機能を議論し、考慮すべき点をご説明します。
設定に対する意思決定に際しては、コストとパフォーマンスのトレードオフが求められるケースがあります。クラスターのコストの主要要素は、クラスターによって消費されるDatabricksユニット(DBU)と、クラスターと実行するのに必要となるインフラリソースのコストとなります。目立たない副次的なコストには、SLAを満たせないことによるビジネスコストや、貧弱なコントロールによって失わられるリソース、従業員の生産性が挙げられます。
クラスターの機能
クラスター設定シナリオの詳細を議論する前に、Databricksクラスターの機能と、それらの機能をどのように活用するかを理解することは重要です。
オールパーパスクラスターとジョブクラスター
クラスターを作成する際に、クラスタータイプをオールパーパスクラスターかジョブクラスターから選択します。オールパーパス(all-purpose)クラスターは複数のユーザーで共有でき、アドホック分析、データ探索、開発においてはベストな選択肢と言えます。処理の実装が完了して本格運用の準備が整ったら、その処理をジョブクラスターで実行するように切り替えます。ジョブクラスターはジョブが終了した際に削除されるので、リソースの利用料とコストを削減することができます。
クラスターモード
注意
本書ではレガシーなクラスターUIを説明しています。プレビューのUIの詳細に関しては、Create a clusterをご覧ください。これには、クラスターアクセスタイプとモードの用語の変更が含まれています。新規のクラスタータイプとレガシークラスタータイプの比較に関しては、Clusters UI changes and cluster access modesをご覧ください。プレビューUIにおいては、
- スタンダードモードクラスターは今では分離なし共有アクセスモードクラスターと呼ばれます。
- テーブルACLを使うハイコンカレンシークラスターは今では共有アクセスモードクラスターと呼ばれます。
Databricksでは3つのクラスターモードをサポートしています。Standard、High ConcurrencyとSingle Nodeです。多くの一般的なケースではStandardとSingle Nodeクラスターを使用します。
警告!
スタンダードモードのクラスター(分離なし共有クラスター)は複数のユーザーで共有することができますが、ユーザー間のアイソレーションはありません。テーブルACLやクレディンシャルパススルーの様な追加のセキュリティ設定を伴わないハイコンカレンシークラスターを使用している際にはスタンダードモードクラスターと同じ設定が使用されます。アカウント管理者はこれらのタイプのクラスターにおいてDatabricksワークスペース管理者の内部認証情報の自動生成を抑止することができます。よりセキュアな選択肢として、テーブルACLを使用するハイコンカレンシークラスターの様な代替案を使用することをお勧めします。
- Standard cluster(標準クラスター)は、大規模データをApache Sparkで処理するのに適しています。
- Single Node cluster(シングルノードクラスター)は、小規模データを利用するジョブや、シングルノードの機械学習ライブラリのような非分散のワークロードを行うためのものです。
- High Concurrency cluster(ハイコンカレンシークラスター)は、複数のユーザーがリソースを共有したい場合やアドホックなジョブを実行する際に最適です。通常、管理者がハイコンカレンシークラスターを作成します。ハイコンカレンシークラスターではオートスケーリングを活用することをお勧めします。
オンデマンド、スポットインスタンス
AWSには二つのインスタンスティアがあります:オンデマンドとスポットです。オンデマンドにおいては、長期のコミットメントなしに秒単位で計算資源を利用しただけの課金が発生します。スポットインスタンスにおいては、余剰のAmazon EC2インスタンスを利用することができ、あなた自身が最大支払額を指定することができます。現在のスポットマーケットプライスが、最大スポット支払額を上回った場合には、スポットインスタンスは停止されます。多くのケースでスポットインスタンスはオンデマンドインスタンスより安価であるため、同じ予算においても、アプリケーションを実行する際にコストを削減することができるため、より高価な計算資源を利用することでスループットを改善することができます。
Databricksにおいては、オンデマンドインスタンスと(カスタムスポットプライスを指定した)スポットインスタンスを組み合わせてクラスターを構成することができ、ユースケースに合わせてクラスターを構築することができます。例えば、下の設定においては、ドライバーノードと4台のワーカーノードはオンデマンドインスタンス、残りの4台のワーカーノードはスポットインスタンス(最大のスポットインスタンスプライスはオンデマンドの100%)として起動すべきと設定しています。
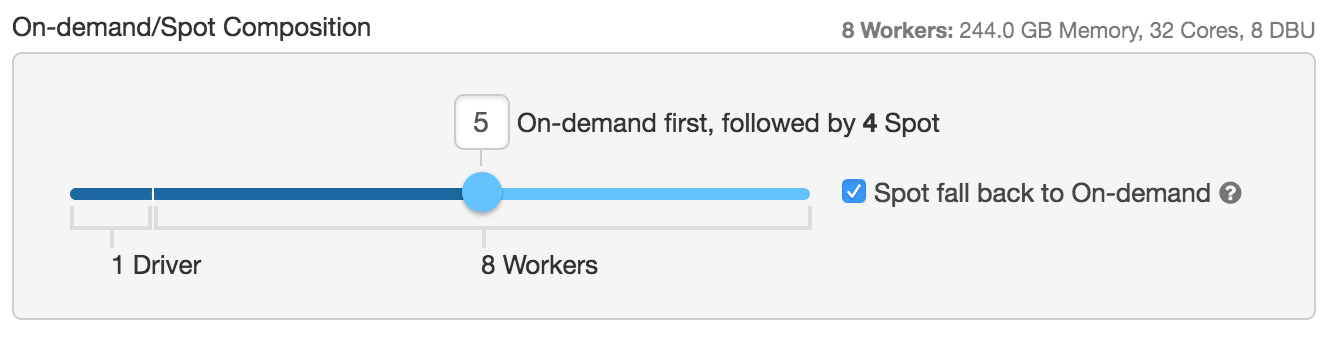

スポットインスタンスの停止が起きたとしてもクラスターの状態保持できるように、Sparkのドライバーノードはオンデマンドインスタンスとして起動することをお勧めします。(ドライバーノードを含む)全てをスポットインスタンスとして起動すると、スポットマーケットの価格変動でドライバーインスタンスが失われると、キャッシュされたデータ、テーブルは削除されてしまいます。
もう一つ注意しなくてはいけない設定項目は、Spot fall back to On-demandです。オンデマンドとスポットから構成されるハイブリッドクラスターを稼働させている際に、スポットインスタンスの獲得に失敗、あるいはスポットインスタンスを失ったとしても、Databrikcsはオンデマンドインスタンスを利用し、期待する性能を実現します。この設定が無いと、クラスターに処理の遅延あるいは処理の失敗が発生し、期待する性能が得られません。ユースケースに対するコスト感度、重要度に応じてオンデマンドとスポットの比率を決定することをお勧めします。
ティップ
適切なインスタンスタイプとリージョンを決定する際には、Amazon Spot Instance Advisorを活用できます。
オートスケーリング
オートスケーリングを活用することで、リソース利用量を最適化するためにワークロードに応じて、ワーカーノードの数を自動で増減することができます。オートスケーリングを有効化することで、DatabricksはSparkジョブを実行するのに最適なワーカーの数を自動的に決定します。オートスケーリングを用いることで、ワークロードに適した数のクラスターを気にすることなしに、クラスターの高い利用率を実現できます。これにより二つのメリットを享受することができます:
- 固定サイズのクラスターと比較して多くのケースでコストを削減できます。
- 固定サイズのクラスターで能力不足が生じた場合と比較して、オートスケーリングのワークロードは高速に動作します。
- spark-submitジョブやいくつかのpythonパッケージなど、いくつかのワークロードはオートスケーリングクラスターとの互換性がありません。
- シングルユーザーのオールパーパスクラスターにおいて、最小ワーカー数が少なく設定されている場合、オートスケーリングによって開発や分析がスローダウンするケースがあります。これは実行しているコマンドやクエリーが数分に渡ることがあり、クラスターがアイドル状態になった際にコストを節約するためにスケールダウンが発生するためです。次のコマンドが実行された際には、クラスターマネージャーはスケールアップしようとしますが、クラウドプロバイダーからインスタンスを取得するのに数分を要することがあります。この際、ジョブは不十分なリソースで実行しなくてはならず、結果を主とkするのに時間を要することになります。ワーカーの最小数を引き上げることで改善はできますが、このことはコストも引き上げることになります。これは、コストと性能のバランスを取るべきもう一つの例となります。
- Delta Cachingを使用している際には、ノードが削除された際にはノードにキャッシュされたいかなるデータも削除されることに留意してください。ワークロードにおいてキャッシュデータの維持が重要な場合には、固定サイズのクラスターを利用することを検討してください。
- ETLワークロードでジョブクラスターを利用している場合、ジョブが当面変更されない場合には適切にクラスターをチューニングすることでサイジングすることができます。しかし、データサイズが増加する際にはオートスケーリングによって柔軟性を手にすることができます。また、最適化されたオートスケーリングによって、長い期間実行されるジョブのクラスターが想定されるより利用されない、他のプロセスの結果を待つ必要がある場合において、コストを削減することができます。繰り返しになりますが、クラスターが適切にスケールアップする際にも微小な遅れが生じる場合が相rます。ジョブに対して厳しいSLAが求められる場合には、固定サイズのクラスターが優れた選択肢かもしれませんし、Databricksのプールを活用してクラスター起動時間を削減した方が良いかもしれません。
Databricksではローカルストレージのオートスケーリングもサポートしています。ローカルストレージのオートスケーリングによって、クラスターのSparkワーカーのディスク空き容量を監視します。ワーカーのディスクの空きが減ってきた際、Databricksは自動的にディスク容量が枯渇する前にマネージドのボリュームを追加します。
プール
プールを活用することで、利用可能なインスタンスの群を維持し、クラスターの起動、スケールアップに要する時間を短縮できます。コストを最小化しつつ処理時間を改善するためにプールの活用をお勧めします。
Databricksランタイムのバージョン
オールパーパスクラスターにおいては、最新のDatabricksランタイムを活用することをお勧めします。最新のバージョンを利用することで、最新の最適化、コードとロード済みパッケージの互換性を活用できます。
運用のワークロードを実行するジョブクラスターに関しては、長期サポート(LTS)Databricksランタイムの利用をご検討ください。LTSバージョンを利用することで、互換性に関する問題を回避し、ワークロードをアップグレードする前に包括的なテストが行えます。機械学習やゲノミクスの最新ユースケースを活用する際には、特定のDatabricksランタイムのバージョンの利用を検討ください。
クラスターポリシー
Databricksのクラスターポリシーを活用することで、管理者はクラスターの作成、設定に制限をかけることができます。このガイドで議論される推奨事項を活用してください。クラスターポリシーの詳細に関しては、cluster policies best practices guideを参照ください。
自動停止
多くのユーザーはクラスターの利用が終わった際にクラスターを停止しようとは思いません。幸運なことに、特定期間(デフォルトは120分)が経過した後にクラスターは自動で停止します。
管理者はクラスターポリシーを作成する際にデフォルトの設定を変更することができます。設定値を引き下げることで、クラスターのアイドル時間を減らしコストを削減できます。クラスターが停止しされた際には、すべての変数、一時テーブル、キャッシュ、関数、オブジェクトなどすべての状態が失われることに注意してください。クラスターが再起動した際に、これらの状態が復元される必要があるかもしれません。開発者が30分の昼食に席を外した場合、同じ状態に戻すまでに同じ時間を無駄にすることになるかもしれません。
重要!
アイドル状態のクラスターはDBUを消費し続け、停止前のアイドル状態のクラウドインスタンスにも課金が発生します。
ガーベージコレクション
本書で議論されている他の話題と比べて目立つものではないかもしれませんが、ガーベージコレクションに注意を払うことで、クラスターのジョブ実行性能を最適化できる可能性があります。大容量のRAMによって、ジョブの性能を改善できるかもしれませんが、ガーベージコレークションの際に遅延を生じる可能性があります。
長期間のガーベージコレクションの影響を最小化するために、それぞれのインスタンスに大容量のRAMを割り当てることを避けてください。ワーカーに対して大容量のメモリーを割り当てることは、長期間のガーベージコレクションを引き起こします。代わりに、小規模のRAMをインスタンスに割り当て、ジョブが大量のメモリを必要とするのであれば、より大量のインスタンスをデプロイするようにしてください。しかし、クラスターのサイジングの検討で議論しているような、多くのシャッフルを必要とするようなワークロードのように、大容量メモリの少数のノードが適しているケースがあります。
クラスターのアクセスコントロール
に種類のクラスター権限を設定できます。
- ユーザーがクラスターを作成できるかどうかを制御できるAllow Cluster Creation権限
- 特定のクラスターを利用、編集できるかを設定するクラスターレベルの権限
クラスターの権限設定に関しては、cluster access controlを参照ください。
クラスター作成(Allow Cluster Creation)権限がある、あるいはポリシーの設定に基づいたクラスター作成を許可するクラスターポリシーにアクセスできる場合にはクラスターを作成することができます。クラスターの作成者はオーナーとなり、Can Manage権限を有することになります。これによって、クラスターに対するデータアクセス権限の制約の中で、他のユーザーにクラスターを共有することができます。
一般的なシナリオにおいては、クラスター設定を決定するためにクラスター権限とクラスターポリシーを理解することが重要になります。
クラスタータグ
組織内の異なるグループがクラウドリソースを使う際にクラスタータグを利用することで、容易にコストをモニタリングできます。クラスターを作成する際に、キーバリューの形式でタグを指定することで、DatabricksはインスタンスのEBSなどのクラウドリソースにタグを付与します。詳細はクラスターポリシーにおけるタグの適用を参照ください。
クラスターのサイジングの検討
Databricksにおいては、一つのワーカーノードあたり一つのエグゼキューターが稼働します。このため、Databricksアーキテクチャーの文脈においてはワーカーとエグゼキューターが同じ意味で用いられます。クラスターサイズはワーカーの数で決定されると考えるかもしれませんが、他に考慮すべき要因があります。
- トータルのエグゼキューターのコア(コンピュート): 全エグゼキューターのトータルのコア数。この値がクラスターの最大並列実行数を決定します。
- トータルのエグゼキューターのメモリー: 全エグゼキューターのトータルのRAM。ディスクに溢れる前にメモリに蓄積できるデータ量を決定します。
- エグゼキューターのローカルストレージ: ローカルディスクストレージのタイプと総量。主にシャッフルとキャッシュの際のメモリ溢れ(スピル)が発生した場合に使用されます。
追加で検討すべきことには、上記の要因に影響を与えるワーカーのインスタンスタイプとサイズがあります。クラスターのサイジングをする際には以下を検討してください。
- ワークロードはどれだけのデータを消費するのか?
- ワークロードの計算の複雑性はどの程度か?
- どこからデータを読み込むのか?
- 外部ストレージにおいてデータはどのようにパーティショニングされているのか?
- どれだけの並列性を必要とするのか?
これらの疑問に答えることは、ワークロードに最適なクラスター設定を決定するのに役立ちます。狭い変換(入力パーティションが一つの出力パーティションに影響を及ぼす)のみを行うシンプルなETLワークロードにおいては、計算最適化設定に注力します。大量のシャッフルが予想され、メモリーおよびデータ溢れのためのディスクサイズが重要になります。シャッフルが大量に発生するワークロードにおいて、少数の大規模インスタンスはマシン間のデータ転送のネットワークI/Oを削減します。
ワーカーの数とワーカーインスタンスタイプのサイズにはトレードオフの関係があります。40コア、100GBメモリーを持つ2つのワーカーのクラスターは、10コア、25GBメモリーを持つ8台のワーカーと同程度の計算性能、メモリーを有することになります。
同じデータを何度も読み込む場合には、キャッシュの恩恵を受けることができます。Delta Cacheとストレージ最適化設定を検討してください。
クラスターのサイジング例
以下の例では、特定のタイプのワークロードに適したクラスターの推奨設定を説明します。ここでは、避けるべき設定を理由とともに説明します。
データ分析
データ分析においては複数のパーティションからデータを読み込んで処理することが一般的であり、このことはシャッフルを引き起こしてしまいます。少数のノードのクラスターによって、シャッフルの際のネットワーク、ディスクI/Oを削減することができます。特に一人の分析者をサポートするケースにおいては、以下の図におけるクラスターAが最適な選択肢となります。
クラスターDは、少量のメモリー、ストレージの大量のノードから構成されるため、データの処理の際に大量のシャッフルが発生することになり、最悪の性能をもたらすことになります。

分析ワークロードにおいては、同じデータを繰り返し読み込むケースが多くなりますので、Delta Cacheを有効化して、ストレージ最適化のインスタンスタイプを選択することをお勧めします。
分析ワークロードで推奨する他の機能には以下のものがあります。
- 利用されない時間が続いた後に、クラスターが停止されるように自動停止を有効化してください。
- 分析者特有のワークロードに応じてオートスケーリングの活用を検討ください。
- 事前に定義されたインスタンスタイプ、一貫性のある設定にクラスターを統一できるようにプールの活用を検討ください。
このケースで有用ではない可能性がある機能は以下の通りです。
- このケースでは大量データを生成しないのでストレージオートスケーリングは不要です。
- クラスターは一人で利用されるので、共有に適したハイコンカレンシークラスターは適していません。
基本的なバッチETL
joinや集計などの広い変換を必要としないシンプルなETLジョブにおいては、計算処理最適化クラスターを活用すべきです。このタイプのワークロードにおいては、以下の図のいずれのクラスターも許容できるものとなります。

計算最適化インスタンスタイプがお勧めです。これらは比較的安価であり、このタイプのワークロードは大量のメモリー、ストレージを必要としません。
プールを活用することで、クラスター起動時間を削減し、トータルのジョブパイプライン実行時間を削減できるので、シンプルなETLジョブにおいてもメリットがが生まれます。しかし、このタイプのワークロードは多くの場合、ジョブを実行するのに十分な時間だけ稼働するスケジュールジョブとして実行されるので、この場合プールを活用するメリットはありません。
このケースで有用ではない可能性がある機能は以下の通りです。
- データの再読み込みは発生しないためDelta Cachingは不適です。
- スケジュールジョブとして実行されるので自動停止は不要です。
- 計算能力とストレージはユースケースに合わせて事前に設定されるべきなのでオートスケーリングはお勧めしません。
- クラスターはシングルジョブとして実行されるので、共有に適したハイコンカレンシークラスターは適していません。
複雑なバッチETL
unionや複数テーブルのjoinなどの処理を必要とするより複雑なETLジョブにおいては、シャッフルされるデータ量を最小化することが重要となります。クラスターのワーカー数を削減することでシャッフルを最小化できますので、クラスターDではなく、クラスターAのように少数のクラスターを検討すべきです。
複雑な変換処理は計算資源を多く必要としますので、ワークロードに最適なコアを割り当てるためには、クラスターにノードを追加する必要があるかもしれません。
シンプルなETLジョブと同様、計算最適化のインスタンスタイプをお勧めします。これらは比較的安価であり、このタイプのワークロードは大量のメモリー、ストレージを必要としません。また、シンプルなETLジョブ同様に、クラスターの起動時間を削減し、ジョブパイプライン実行に要するトータルの時間を削減するためにプールの活用を検討ください。
このケースで有用ではない可能性がある機能は以下の通りです。
- データの再読み込みは発生しないためDelta Cachingは不適です。
- スケジュールジョブとして実行されるので自動停止は不要です。
- 計算能力とストレージはユースケースに合わせて事前に設定されるべきなのでオートスケーリングはお勧めしません。
- クラスターはシングルジョブとして実行されるので、共有に適したハイコンカレンシークラスターは適していません。
機械学習モデルのトレーニング
初回の機械学習モデルのトレーニングは実験的なものであるため、クラスターAのような小規模クラスターがお勧めです。小規模クラスターはシャッフルの影響も軽減します。
ステージが進むなどして、安定性が課題になるのであれば、より規模の大きいクラスターBやクラスターCがお勧めです。
ノード間のデータシャッフルのオーバーヘッドのため大規模なクラスターDはお勧めしません。

同じデータを繰り返し読み込むため、Delta Cachingを有効化したストレージ最適化インスタンスの活用、トレーニングデータのキャッシュがお勧めです。ストレージ最適化インスタンスの計算能力、ストレージサイズが不十分である場合には、GPU最適化ノードの利用を検討ください。この場合、Delta Cachingを利用できないというデメリットがあります。
分析のワークロードで推奨する他の機能には以下のものがあります。
- 利用されない時間が続いた後に、クラスターが停止されるように自動停止を有効化してください。
- 分析者特有のワークロードに応じてオートスケーリングの活用を検討ください。
- 事前に定義されたインスタンスタイプ、一貫性のある設定にクラスターを統一できるようにプールの活用を検討ください。
このケースで有用ではない可能性がある機能は以下の通りです。
- クラスターのスケールダウンでデータが失われるのでオートスケーリングはお勧めしません。加えて、特定の機械学習ジョブはすべての利用可能なノードを必要としますので、この場合オートスケーリングを使用すべきではありません。
- このケースでは大量データを生成しないのでストレージオートスケーリングは不要です。
- クラスターは一人で利用されるので、共有に適したハイコンカレンシークラスターは適していません。
一般的なシナリオ
以下のセクションでは、一般的なクラスターの利用パターンに対する推奨クラスター設定を説明します。
- マルチユーザーによるデータ分析、アドホックデータ処理
- 機械学習のような特定のユースケース
- スケジュールバッチジョブのサポート
マルチユーザークラスター
シナリオ
データ分析、アドホックのクエリーを行う複数のユーザーに対してデータアクセス手段を提供する必要があります。利用料は時間に応じて変動し、多くのジョブはそれほどリソースを消費しません。ユーザーは多くの場合データに対する読み取りのみが必要で、シンプルなユーザーインタフェースを通じて分析を行い、ダッシュボードを構築したいと考えています。
クラスター提供の推奨アプローチは、オートスケーリングを伴うクラスターを提供するというハイブリッドのアプローチです。ハイブリッドアプローチでは、オンデマンドインスタンスの数とスポットインスタンスの数を定義し、インスタンスの際少数、再代数を指定してオートスケーリングを有効化します。

このクラスターは常時稼働であり、グループのユーザーが利用することができ、負荷に応じてスケールアップ・ダウンします。
ユーザーにはクラスターを開始・停止する権限はありませんが、初期状態から設定されているオンデマンドインスタンスはユーザーからのクエリに即座に反応します。ユーザーのクエリがより多くのキャパシティを必要とした際には、ワークロードに対応できるようにオートスケーリングがより多くのノード(多くはスポットインスタンス)を配置します。
- インタラクティブワークフローにおける高負荷クエリの取り扱い - 終了しないクエリを自動的に管理
- タスクのプリエンプション - 長期実行クエリと短期実行クエリの共存
- ローカルストレージのオートスケーリング - マルチテナントにおけるストレージ枯渇(シャッフル)の回避
このアプローチにより、以下の理由から全体的なコストを削減できます:
- 共有クラスターモデルの活用
- オンデマンド・スポットインスタンスの活用
- 固定サイズのクラスターではなくオートスケーリングを活用することで不要な課金を回避
特定のワークロード
シナリオ
データサイエンティストが複雑なデータ探索や機械学習アルゴリズムを実行するといった、組織内の特定のユースケース、チームにクラスターを提供する必要があります。典型的なパターンは、ユーザーは短時間でデータ分析を行うというものです。
このタイプのワークロードにおけるベストなアプローチは、デフォルト値、固定値、設定のレンジを事前定義した設定のクラスターポリシーを作成するというものです。これにはインスタンスの数、インスタンスタイプ、スポットとオンデマンドインスタンスの比率、ロール、インストールすべきライブラリなどが含まれます。クラスターポリシーを活用することでユーザーは高度な要件に対しても、ユースケースに応じた設定を行い迅速にクラスターを起動でき、ポリシーによってコスト、コンプライアンスを制御することができます。

このアプローチは、ユーザーに対してクラスターを起動することのできるより強い権限を与えるものですが、依然として事前に定義した設定の制限をかけることでコストをコントロールすることが可能です。また、このアプローチにおいては、異なるグループのユーザーに対して、異なるデータへのアクセスが許された異なるクラスターを割り当てることも可能です。
このアプローチにおける欠点は、クラスターにおけるあらゆる変更、設定、ライブラリなど全てにおいて管理者の関与が必要となることです。
バッチワークロード
シナリオ
データ前処理を行う本番ETL処理など、スケジューリングされたバッチジョブに対してクラスターを提供する必要があります。ここでのベストプラクティスはそれぞれのジョブ実行で新規にクラスターを起動するというものです。新規クラスターによるジョブ実行によって、共有クラスターで他の作業と競合することによるSLA違反や処理失敗を避けることができます。ジョブの重要度レベルに応じて、SLAを満足するためにオンデマンドインスタンを使用できますし、コスト低減のためにスポットインスタンスとオンデマンドインスタンスを組み合わせることも可能です。
