はじめに
どうも。スクレイピング歴7日の初心者です。
本日もスクレイピングを勉強したので学習内容をQiitaにまとめます。
類似記事はこちら。
バックナンバー
- 初学者が勉強するSelenium。①
- 初学者が勉強するSelenium。②
- seleniumはCopy_full_xpathで少し楽になる
- 初学者が勉強するBeautiful Soup①
- 初学者が勉強するBeautiful Soup②
- 初学者が勉強するBeautiful Soup③
- Beautiful Soupで画像を取得
- BeautifulSoupでURLを一括取得
- 複数ページにわたる情報の取得。スクレイピング。
- 複数に渡るページでの画像収集スクレイピング
対象としている方々
pythonの初学者。for分と変数について少しでも理解がある方。
最近毎日qiitaにログインしているので記事内にて分からない部分等ございましたら、コメント頂ければ嬉しいです。
この記事を書くきっかけ
- qiitaのmarkdownに慣れるため。
- ライティングスキル/表現力諸々の向上。
- 学習内容のアウトプット。忘備録。
- 画像スクレイピングをおさらいして応用を考える為。
学習教材。
Beautiful Soup部分。1:56:16~
youtubeで「スクレイピング」と検索すると真っ先に出てくると思います。
動画の完成度が高く、私はこのチャンネルでよく学習をしています。
今回は動画通りに行えばできるはずです。2020/12/19日に投稿されたものですが、2022年7月現在でもその通りに行う事が出来ました。
開発環境
- Windows11
- jupyter lab
学習
それでは動画に沿って学習を進めていきます。とはいっても動画をなぞるだけですが…。
- 目標:web上からpythonを用いて画像を取得し任意のフォルダに格納する。
こちらのサイトにある沢山の画像を一括で取得することを本記事の目標とします。
少し長くなりますので手順を細かく分けてお伝え致します。
単一の画像取得
段階① モジュールのインポートと取得urlのhtml確認
# ライブラリやモジュールをimport
from bs4 import BeautifulSoup
import requests
import bs4
今回学習用に用いるサイトのurlを取得します。
url = "https://scraping-for-beginner.herokuapp.com/image"
res = requests.get(url)
取得したurlのhtml情報を確認します。このhtmlの中から必要な情報を抽出しましょう。
soup = BeautifulSoup(res.text, "html.parser")
# print(soup.prettify())
soup
#結果
<!DOCTYPE html>
<html dir="ltr" lang="en">
<head>
<meta charset="utf-8"/>
<title>Webスクレイピング入門者のためのサイト</title>
<!-- Compiled and minified CSS -->
・
・
・
段階② 必要な部分を抽出
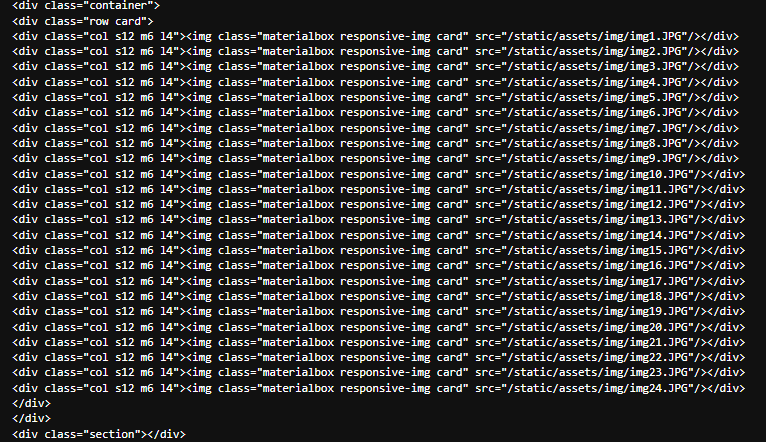
検証でも確認しましょう。

ひとまず、この中の最初の一つを取得します。
「一つだけなら左クリックで「名前を付けて保存」した方が早いじゃないか」とおっしゃらずに。
- まずはimgが格納されているクラスを格納し表示しましょう。
上記画像を参照したら"class" "col s12 m6 l4"がそれらしいのでひとまずfind_allで抽出しましょう。
下記のような2つのやり方があります。
- 検証からimgが格納されているクラスを抽出する。
imgs = soup.find_all("div",attrs = {"class":"col s12 m6 l4"}) #このページ内の"class":"col s12 m6 l4"を全て取得する。
- imgという文字列が含まれている内容を全て抽出する。
img_tag = soup.find_all("img")
img_tag
どちらでも結構です。
段階③ 画像アドレスを取得する
- 取得したimgからsrcを抽出する。
- その抽出したsrcとウェブページを合体する。
- できた結果を確認する。
となります。
web上での画像の扱い(url)を確認する為に、画像アドレスをコピーして確認してみると、
https://scraping-for-beginner.herokuapp.com/static/assets/img/img1.JPGでした。
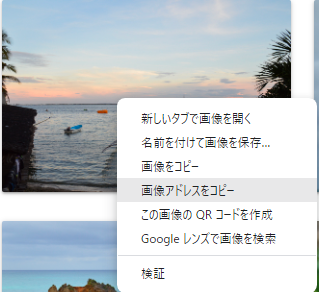
構成は、
https://scraping-for-beginner.herokuapp.com + img_tag[0]["src"] です。
前半は今回取得した際のurl、https://scraping-for-beginner.herokuapp.com/imageの
https://scraping-for-beginner.herokuapp.com部分です。
つまり画像URLはサイトのURLの一部 + imgのsrc という事です。
img_tag[0]["src"] #一番最初のimgのsrcを取得します。
#結果
'/static/assets/img/img1.JPG'
root_url = "https://scraping-for-beginner.herokuapp.com" #これは何なのか分からない。
img_url = root_url + img_tag[0]["src"] #足し算
img_url
#結果
#'https://scraping-for-beginner.herokuapp.com/static/assets/img/img1.JPG'
これで画像を取得する事が出来ました。
段階④ 環境上で画像を取得する
先ほど取得したimg_urlを用います。
requests.get(img_url)で取得している事も確認できました。
from PIL import Image
import io
requests.get(img_url)
#<Response [200]>
これでimg_urlにて画像を取得し環境上で表示する事が出来ます。
確認用に実行して頂ければ。下記のコードはこのようなものと割り切って頂ければと思います。
img = Image.open(io.BytesIO(requests.get(img_url).content))
img

好きな場所に好きな名前で画像の保存をしてください。
下記の例ではDpwnloadにtestという名前でjpeg形式で保存しました。
#画像の保存
img.save("C:/****/****/Downloads/test.jpeg")
総まとめのコード
ここまでの流れを踏まえて単一画像取得の総まとめコードを記載します。
確認の為の表示は省いてあります。
# ライブラリやモジュールをimport
from bs4 import BeautifulSoup
import requests
import bs4
from PIL import Image
import io
#取得したい画像があるURLの情報を変数に格納。
url = "https://scraping-for-beginner.herokuapp.com/image"
res = requests.get(url)
#そのサイトのhtmlを変数に格納
soup = BeautifulSoup(res.text, "html.parser")
#画像が欲しいのでimg要素を全摘出する。
img_tag = soup.find_all("img")
#その中の一番最初(リスト0番目)のsrcを摘出して変数に格納。
img_tag[0]["src"]
root_url = "https://scraping-for-beginner.herokuapp.com"
#root_urlとimgのsrcを足している。
img_url = root_url + img_tag[0]["src"]
#画像の保存
img.save("C:/****/****/Downloads/test.jpeg")
複数の画像取得
基本的な考え方
1つを取得する。その取得した際に用いた同じコード、同じ考え方に則り、いかにfor文を駆使して自動で回すかを考える。私が7日で至ったスクレイピングの考えです。
今回もこの考えを踏襲し、買いのコードまでは同じです。
# ライブラリやモジュールをimport
from bs4 import BeautifulSoup
import requests
import bs4
from PIL import Image
import io
#取得したい画像があるURLの情報を変数に格納。
url = "https://scraping-for-beginner.herokuapp.com/image"
res = requests.get(url)
#そのサイトのhtmlを表示
soup = BeautifulSoup(res.text, "html.parser")
#画像が欲しいのでimg要素を全摘出する。
img_tag = soup.find_all("img")
同じサイトから同じように画像のsrcを取得しています。画像でも同じ範囲を示しておきます。
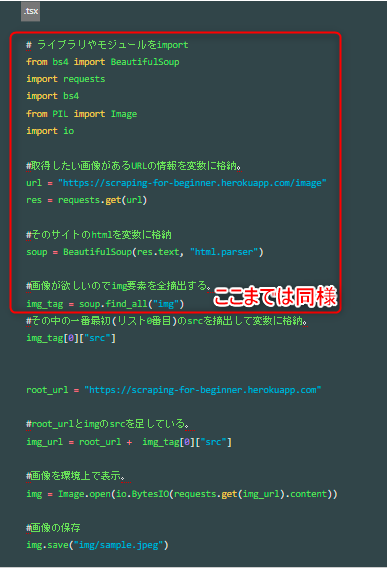
相違点
今一度、単一の画像取得のコードを見直してみましょう。着目点は
- ページ内のimgを全て取得したい。
- それらを保存したい。
です。どの部分をどのようにしてfor文で回せば複数の画像が取得できますでしょうか?
img_tag[0]["src"] #[0]番目のimgのsrcを取得する。
root_url = "https://scraping-for-beginner.herokuapp.com" #画像アドレスの前半部分を取得する。
#root_urlとimgのsrcを結合。
img_url = root_url + img_tag[0]["src"]
#画像を環境上で表示。
img = Image.open(io.BytesIO(requests.get(img_url).content))
#画像の保存
img.save("img/sample.jpeg")
img_tag[0]["src"] の番号がが0,1,2,3... となれば画像をどんどん取得できる。
このように思いませんか?
しかし画像毎にそれぞれ別の名前にしなければ、どんどん上書き保存されますので、最後に取得した画像しか保存できません。つまり、
- img_tagの番号を順々に回し、かつそれぞれ別の名前で保存する
という処置が必要となります。いかがでしょうか?
for img_tag in enumerate(img_tags):
root_url = "https://scraping-for-beginner.herokuapp.com"
img_url = root_url + img_tag["src"]
img.save(f'img/{i}.jpeg')
これでは①の「img_tagの番号を順々に回す」という点は達成されています。
しかしながら、②の「それぞれ別の名前で保存する」という条件が達成されておりません。
どのような工夫をするべきでしょうか?
例えばその場合、このようなコードはいかがでしょう?
for i,img_tag in enumerate(img_tags):
root_url = "https://scraping-for-beginner.herokuapp.com"
img_url = root_url + img_tag["src"]
img.save(f'img/{i}.jpeg')
#i :画像毎のインデックスが格納されます。
#img_tag:画像毎の[src]が格納されます。
#img :画像フォルダ名
enumerateを使用しました。私はこの学習をするまで完全に忘れていました。
enumerateはfor文と組み合わせて、リストの要素だけでなくインデックスも取得するという関数です。詳しくはQiita
をどうぞ。
- インデックスを取得してどうするの?
「名前を付けて保存」の名前に組み込みます。そうするとインデックス毎に名前が変更されるので、どんどん上書きされる事はありませんよね。それを踏まえてこのようなコードを利用します。
更にf文字列を用いております。それぞれのインデクス番号を名前として保存しています。
以上で複数の画像取得のコードが完成です。最後に総まとめコードをご覧になって復習して頂けると嬉しいです。
総まとめのコード
# ライブラリやモジュールをimport
from bs4 import BeautifulSoup
import requests
import bs4
from PIL import Image
import io
#取得したい画像があるURLの情報を変数に格納。
url = "https://scraping-for-beginner.herokuapp.com/image"
res = requests.get(url)
#そのサイトのhtmlを表示
soup = BeautifulSoup(res.text, "html.parser")
#画像が欲しいのでimg要素を全摘出する。
img_tag = soup.find_all("img")
for i,img_tag in enumerate(img_tags):
root_url = "https://scraping-for-beginner.herokuapp.com"
img_url = root_url + img_tag["src"]
img = Image.open(io.BytesIO(requests.get(img_url).content)) #f strings以外で出来ないものか…?
img.save(f'img/{i}.jpeg')
考察、まとめ
今回は簡単ですが、画像の一括取得を行ってみました。
やはり今まで通りのスクレイピングの基本とさして変化はなく、
- 単数を取得⇒複数取得
- 単数を取得したコードのどの部分をfor で繰り返すか。
のポイントが重要だと再認識致しました。
そしてこの動画通りに習った事がきちんと身についていて、応用ができるかを近々確認するつもりです。お疲れさまでした。