はじめに
どうも。スクレイピング歴4日の初心者です。
本日もスクレイピングを勉強したので学習内容をQiitaにまとめます。
対象としている方々
pythonの初学者。for分と変数について少しでも理解がある方。
最近毎日qiitaにログインしているので記事内にて分からない部分等ございましたら、
コメント頂ければ。
この記事を書くきっかけ
- qiitaのmarkdownに慣れるため。
- ライティングスキル/表現力諸々の向上。
- 学習内容のアウトプット。忘備録。
- 全て理解して行っている訳ではないので、分からない部分を掘り起こす為。
- for文の理解を深めるため。
バックナンバー
- 初学者が勉強するSelenium。①
- 初学者が勉強するSelenium。②
- seleniumはCopy_full_xpathで少し楽になる
- 初学者が勉強するBeautiful Soup①
- 初学者が勉強するBeautiful Soup②
- 初学者が勉強するBeautiful Soup②
- Beautiful Soupで画像を取得
- BeautifulSoupでURLを一括取得
- 複数ページにわたる情報の取得。スクレイピング。
- 複数に渡るページでの画像収集スクレイピング
学習教材。
Beautiful Soup部分。59:42~
youtubeで「スクレイピング」と検索すると真っ先に出てくると思います。
動画の完成度が高く、私はこのチャンネルでよく学習をしています。
今回は動画通りに行えばできるはずです。2020/12/19日に投稿されたものですが、2022年7月現在でもその通りに行う事が出来ました。
開発環境
- Windows11
- jupyter lab
学習
それでは動画に沿って学習を進めていきます。とはいっても動画をなぞるだけですが…。
目標:web上から単数の項目の塊を取得してdf化する。
書き起こしてお伝えするのは難しいですが、図で表すといかがでしょうか?
具体的には観光地名とそれぞれの評点を取ってdfでまとめます。
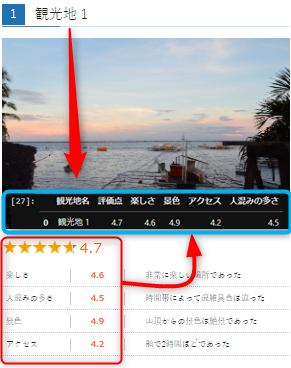
少し長くなりますので手順を細かく分けてお伝え致します。
手順① モジュールのインポートとurlの取得
まずはモジュールをインポート。
今回のスクレイピングモジュールをインストールします。
from bs4 import BeautifulSoup
import requests
import bs4
import pandas as pd
欲しい情報があるurlを変数に入れます。ここら辺部分は意識せずルールとして認識しております。
"res = requests.get(url)"でそのurlが適切に取得できているか確認します。Response [200]ならOK。
どうやらResponse [200]とは「正常に処理された」という意味みたいです。404の反対みたいで縁起がいいですね![]()
url = "https://scraping-for-beginner.herokuapp.com/ranking/" #欲しい情報があるurlを変数に格納
res = requests.get(url)
res
#結果
# Response [200] ⇒処理が成功して正常にレスポンスができている状態
手順② その取得したURLの確認
それでは実際に取得したurlはどのような形になっているのか確認します。
soup = BeautifulSoup(res.text, "html.parser")# htmlの構造を除いてみます。
# soup
print(soup.prettify()) #これが全体…
結果は下記のようになります。長いので省略しますが…。
<!DOCTYPE html>
<html dir="ltr" lang="en">
<head>
<meta charset="utf-8"/>
<title>
Webスクレイピング入門者のためのサイト
</title>
<!-- Compiled and minified CSS -->
.
.
.
ページのhtml情報を取得できました。そこから必要な情報を更に限定します。
手順③ その取得したURLから必要な部分を抽出
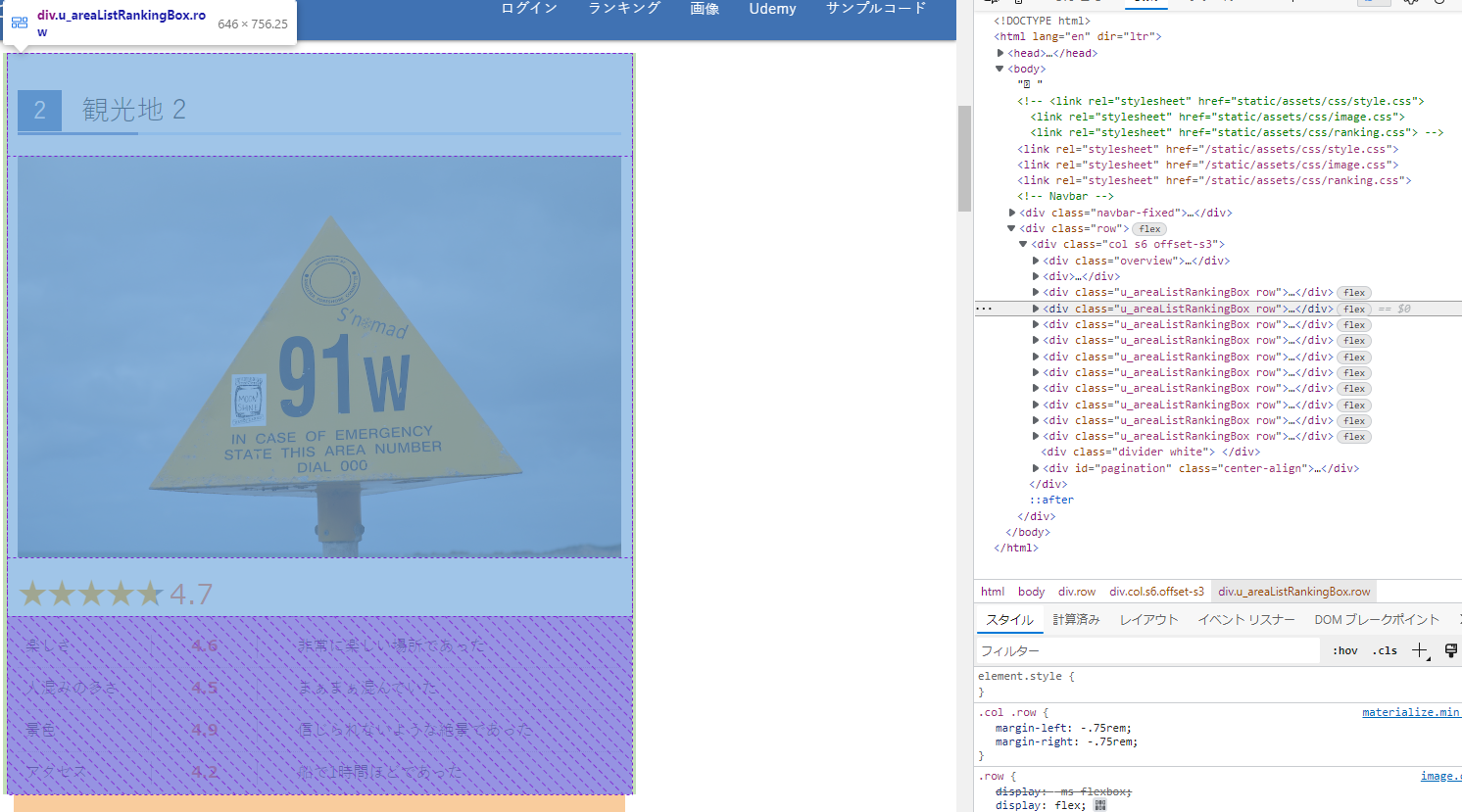
spots = soup.find_all("div",attrs = {"class":"u_areaListRankingBox"})
spots
上記コードですと、このページの全ての観光地要素を取得します。つまり、
観光地1~10の名前、それぞれの項目の評価点等。下記画像のように、観光地の項目の数だけ、「u_areaListRankingBox」がありますので。このセクションのコードや画像を繰り返し参照してイメージを持って頂ければ幸いです。
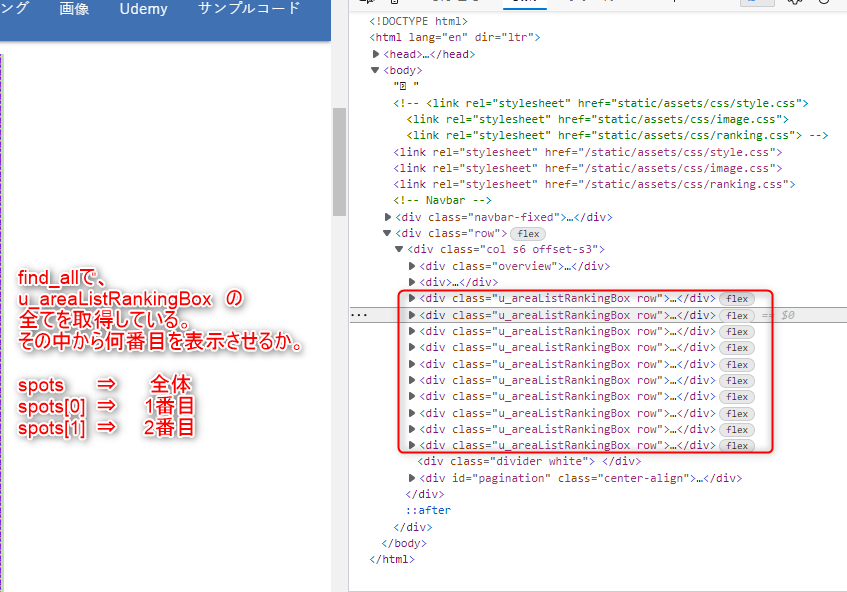
#spots #全体
spots[0] #1番目
#spots[1] #2番目
数ある「u_areaListRankingBox」の中でどちらを参照したいか。つまり観光地1~10どちらを表示させたいか。は上記コードで設定する事が出来ます。
コメントアウトを駆使して実行結果の変化を確認してみてください。
済みましたら今回はその沢山取れた観光地の1番最初のパート観光地1を変数に入れてみましょう。
spot = spots[0]
観光地
結果
<div class="u_areaListRankingBox row">
<div class="u_title col s12">
<p><h2><span class="badge">1</span>観光地 1</h2></p>
</div>
<!-- 観光地イメージ -->
<div class="place_img col s12">
<img alt="" src="/static/assets/img/img1.JPG"/>
</div>
<!-- 総合評価 -->
<div class="u_rankBox col s12">
<span style="--rate: 94.0%;"></span><span class="evaluateNumber">4.7</span><br/>
</div>
<!-- 各カテゴリ評価 -->
<div class="u_categoryTipsItem col s12">
<dl>
<dt>楽しさ</dt>
<dd class="is_rank"><span class="evaluateNumber">4.6</span></dd>
<dd class="comment">1日中飽きることなく遊び続けられた</dd>
</dl>
<dl>
<dt>人混みの多さ</dt>
<dd class="is_rank"><span class="evaluateNumber">4.5</span></dd>
<dd class="comment">空いていた</dd>
</dl>
<dl>
<dt>景色</dt>
<dd class="is_rank"><span class="evaluateNumber">4.9</span></dd>
<dd class="comment">景色に魅了された</dd>
</dl>
<dl>
<dt>アクセス</dt>
<dd class="is_rank"><span class="evaluateNumber">4.2</span></dd>
<dd class="comment">交通の便が悪かった</dd>
</dl>
</div>
<div class="divider">
</div>
</div>
これが観光地1の情報なのですね。
具体的には下記画像のパートのみを取得しております。
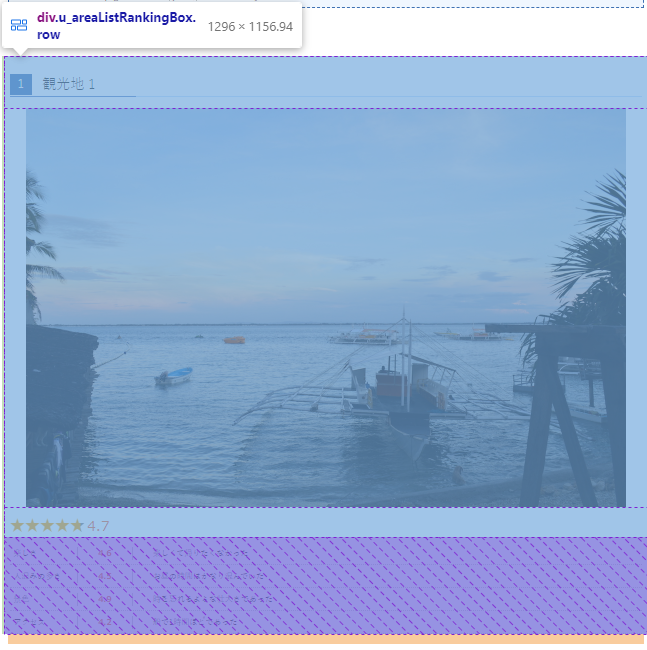
ひとまずここまで取得できました。次のパートはそこからさらに絞っていきましょう。
手順④ 更に限定する⇒名前の取得
- 最初に、名前(観光地名)を取得しましょう。
名前が含まれているクラスを検証で探します。
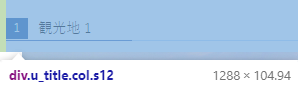
spot_name = spot.find("div",attrs = {"class":"u_title col s12"})
spot_name
#結果
<div class="u_title col s12">
<p><h2><span class="badge">1</span>観光地 1</h2></p>
</div>
大分近づきましたね。更にこの部分も邪魔なので抽出しましょう。

#spot_name.find("span",attrs = {"class": "badge"}.extract() #これはダメ。
spot_name[0].find("span",attrs = {"class": "badge"}).extract() #これなら良い。
上記のspt_nameの出力結果はリストです。Beautifulsoup の find メソッドはリスト全体には使用する事が出来ないので、
「リストの一番目」という意味での[0]が必要です。
とにかくこれで名前抽出が出来ました
手順⑤ 要素(総合評価点)の取得
- 評点(総合評価)を取得します。
評点を取得し変数"eval_num"に格納します。
手順としてはいつも通り、spot(上記のコード)や検証から探してきましょう。
探した結果、classの"u_rankBox col s12"にあるみたいです。
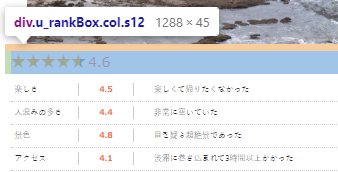
eval_num = spot.find("div",attrs = {"class":"u_rankBox col s12"})
eval_num
#結果
<div class="u_rankBox col s12">
<span style="--rate: 94.0%;"></span><span class="evaluateNumber">4.7</span><br/>
</div>
このままでは分かりにくいので.textでテキストのみ抽出してみましょう。
eval_num = spot.find("div",attrs = {"class":"u_rankBox col s12"}).text
eval_num
#結果
'\n4.7\n'
評価点[4.7]がかなり近づいてきましたね。しかし
- 余計な
\nがあります。これも取り除きましょう。 - 更に型も
floatに矯正しましょう。
eval_num = float(eval_num.replace("\n",""))
float()で要素を囲い小数点化。
replace処理で"\n"を""に置き換えました。""とは?何もなし。という事です。つまり邪魔な要素を「何もなし」に置き換えたという事です。
考えとしては多様回りくどいですが、記法は簡単で応用が利きますよね。
手順⑥ 要素(他の評価点)の取得
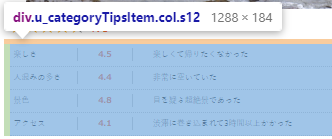
categoryItems = spot.find_all("div",attrs = {"class":"u_categoryTipsItem col s12"})
categoryItems
#結果
[<div class="u_categoryTipsItem col s12">
<dl>
<dt>楽しさ</dt>
<dd class="is_rank"><span class="evaluateNumber">4.6</span></dd>
<dd class="comment">一人旅には最適でした</dd>
</dl>
<dl>
<dt>人混みの多さ</dt>
<dd class="is_rank"><span class="evaluateNumber">4.5</span></dd>
<dd class="comment">非常に混んでいた</dd>
</dl>
<dl>
<dt>景色</dt>
<dd class="is_rank"><span class="evaluateNumber">4.9</span></dd>
<dd class="comment">自然の素晴らしさを味わった</dd>
</dl>
<dl>
<dt>アクセス</dt>
<dd class="is_rank"><span class="evaluateNumber">4.2</span></dd>
<dd class="comment">船で1時間ほどであった</dd>
</dl>
</div>]
内容を確認してみたところ、どうやら項目がそれぞれdlに囲まれて区切られてるみたいです。
それならばdlの内容をfind_allで取りに行きましょう。
categoryItems = categoryItems[0].find_all("dl") #リストなので[0]でfindに対応させる。
#結果
[<dl>
<dt>楽しさ</dt>
<dd class="is_rank"><span class="evaluateNumber">4.6</span></dd>
<dd class="comment">一人旅には最適でした</dd>
</dl>,
<dl>
<dt>人混みの多さ</dt>
<dd class="is_rank"><span class="evaluateNumber">4.5</span></dd>
<dd class="comment">非常に混んでいた</dd>
</dl>,
<dl>
<dt>景色</dt>
<dd class="is_rank"><span class="evaluateNumber">4.9</span></dd>
<dd class="comment">自然の素晴らしさを味わった</dd>
</dl>,
<dl>
<dt>アクセス</dt>
<dd class="is_rank"><span class="evaluateNumber">4.2</span></dd>
<dd class="comment">船で1時間ほどであった</dd>
</dl>]
<div class="u_categoryTipsItem col s12">と</div>が外れています。
なんとなく構造が見えますでしょうか?。同じような入れ子になっていますね。
これはfind_allでまとめて取得しているので、このように単数に分けて出力確認することも可能です。
categoryItems[0]
categoryItems[1]
#結果
<dl>
<dt>人混みの多さ</dt>
<dd class="is_rank"><span class="evaluateNumber">4.5</span></dd>
<dd class="comment">非常に混んでいた</dd>
</dl>
この中から、それぞれの項目の要素を全て抽出したいのですが、どうすればよいでしょうか…。
結論:for文を使います。
察しの良いあなたなら気づいたと思います。同じ事を繰り返すにはfor文です。
それでは早速取り掛かりましょう。
- まずは辞書型のインスタンス(入れ物)を準備しましょう。
details = {}
そしてfor文を回します。
for categoryItem in categoryItems: #変数にひとつづつ入れる。
category = categoryItem.dt.text #categoryにはそれぞれの評価項目(dt)が入る。
rank = float(categoryItem.span.text) #その評価項目(span)の評価点が入る。
details[category] =rank #その2つの辞書型を作成。
#結果
{'楽しさ': 4.6, '人混みの多さ': 4.5, '景色': 4.9, 'アクセス': 4.2}
まあこのfor文だけの説明では慣れていないと分かりにくいかも知れません。
なので画像の説明もお付け致します。
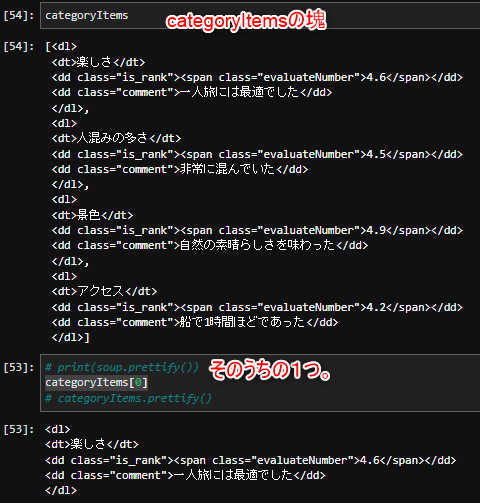
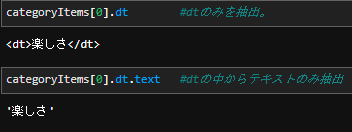
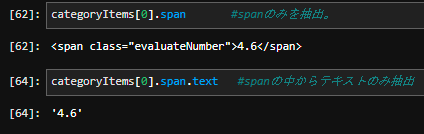
この画像を参照して頂いた後に改めてfor文のコードをご覧いただければと。
因みにdetails[category] =rankの補足ですが、
辞書のインスタンス(空箱)であるkeyをcategoryに。valueをrankに。という事です。
更に["観光地名"]と["評価点"] も辞書に追加しましょう。
details["観光地名"] = spot_name #keyが文字列の"観光地名" valueが実際の観光地の名前
details["評価点"] = eval_num #keyが文字列の"評価点" valueが実際の評価点
details
#結果
{'楽しさ': 4.6,
'人混みの多さ': 4.5,
'景色': 4.9,
'アクセス': 4.2,
'観光地名': ['観光地 1'],
'評価点': 4.7}
それでは辞書をdfに変換しましょう。
import pandas as pd
details = pd.DataFrame(details)
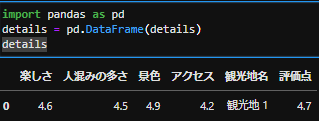
上手くdf化できましたが、順番が良くないですよね。
それならば並び替えましょう。
details= details[['観光地名','評価点','楽しさ','景色','アクセス','人混みの多さ']]#カラム並び替え。
details
上手く並び替えることができました。並び替えの手順は「こういうものなんだ」と割り切って覚える方が良いかも知れません。
最後の流れのスクショを共有致します。
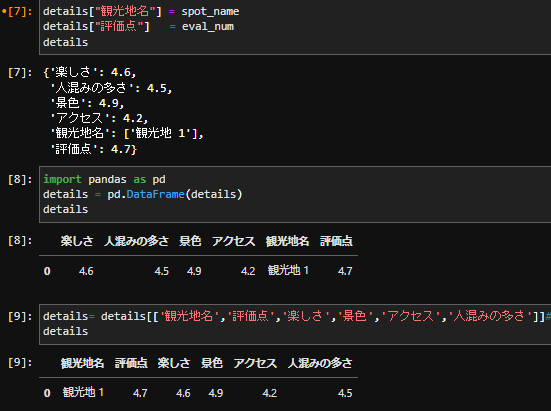
総まとめのコード
# ライブラリやモジュールをimport
from bs4 import BeautifulSoup
import requests
import bs4
url = "https://scraping-for-beginner.herokuapp.com/ranking/" #取得したい情報のあるURLを選択。
res = requests.get(url) #その情報を取得
soup = BeautifulSoup(res.text, "html.parser") # "html.parser"⇒htmlの構造を解析するもの。
#動画では1時間50分辺りの部分
soup = BeautifulSoup(res.text, "html.parser")
spots = soup.find_all("div",attrs = {"class":"u_areaListRankingBox"}) #特定の部分を抜き出し。
spot = spots[0] #更にその1番目を抜き出し。
spot_name = spot.find_all("div",attrs = {"class":"u_title col s12"})
spot_name[0].find("span",attrs = {"class": "badge"}).extract() #邪魔な要素を排除。
spot_name[0] = spot_name[0].text.replace("\n","") #ここでようやく観光地1をget
#評価点
eval_num = spot.find("div",attrs = {"class":"u_rankBox col s12"}).text
eval_num = float(eval_num.replace("\n",""))
categoryItems = spot.find_all("div",attrs = {"class":"u_categoryTipsItem col s12"})
categoryItems = categoryItems[0].find_all("dl")
#for文。更に観光地名と評点を追加。
details = {}
for categoryItem in categoryItems: #要素を一つづつcategoryItemに入れる。
category = categoryItem.dt.text #カテゴリにはそれぞれの名前(dt要素)が形式で入る。
rank = float(categoryItem.span.text) #その評価項目の評価点(span要素)がテキスト形式で入る。
details[category] =rank #辞書に格納
details["観光地名"] = spot_name #辞書に追加。
details["評価点"] = eval_num #辞書に追加。
details = pd.DataFrame(details)
details = details[['観光地名','評価点','楽しさ','景色','アクセス','人混みの多さ']]#カラム並び替え。
details
終わりに
いかがでしたか?結構長いコードになってしまいましたね。今回「1」のみでしたが、次回は「1~10」全てを取得したいと思います。
「観光地1」のみをを取得するのでさえ、長いコードで大変でしたが、それの10倍の仕事をしなければならないと…。どれだけ大変なコードを書かなければならないのだ…と初めは僕もそう思っていましたが![]() 。
。
それでは次回もよろしくお願い致します。