はじめに
こちらは以前記入したこちらの続きの内容となります。
簡単にあらすじを紹介させて頂きます。
前回はBeatutiful Soupを用いて1つの塊の情報(観光地1)を取得しました。利用したサイトはこちらです。今回1つではなく、10個全てを取得したいと思います。
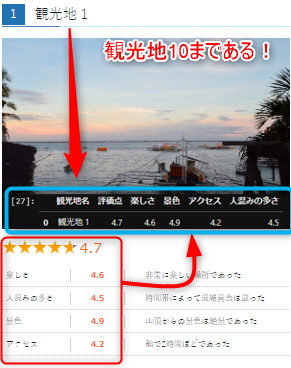
バックナンバー
-
教材
- 開発環境
Windows11 / jupyter lab
前回のコード
# ライブラリやモジュールをimport
from bs4 import BeautifulSoup
import requests
import bs4
url = "https://scraping-for-beginner.herokuapp.com/ranking/"
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser") # "html.parser"⇒htmlの構造を解析するもの。
soup = BeautifulSoup(res.text, "html.parser")
spots = soup.find_all("div",attrs = {"class":"u_areaListRankingBox"}) #特定の部分を抜き出し。
spot = spots[0] #更にその1番目を抜き出し。
spot_name = spot.find_all("div",attrs = {"class":"u_title col s12"})
spot_name[0].find("span",attrs = {"class": "badge"}).extract() #邪魔な要素を排除。
spot_name[0] = spot_name[0].text.replace("\n","") #ここでようやく観光地1をget
#評価点
eval_num = spot.find("div",attrs = {"class":"u_rankBox col s12"}).text
eval_num = float(eval_num.replace("\n",""))
categoryItems = spot.find_all("div",attrs = {"class":"u_categoryTipsItem col s12"})
# categoryItems = categoryItems[0].find_all("dl")
categoryItems = categoryItems[0].find_all("dl")
#for文。更に観光地名と評点を追加。
details = {}
for categoryItem in categoryItems: #この行の意味が分からない。
category = categoryItem.dt.text #カテゴリにはそれぞれの評価項目が入る。#感想は入らない。
rank = float(categoryItem.span.text) #その評価項目の評価点が入る。
details[category] =rank
details["観光地名"] = spot_name
details["評価点"] = eval_num
details= details[['観光地名','評価点','楽しさ','景色','アクセス','人混みの多さ']]#カラム並び替え。
details
実装
①段階。前回のおさらいと相違点。
ここは前回といつも通り。htmlの中から、欲しい情報をfind_allする所まで進めます。
# ライブラリやモジュールをimport
from bs4 import BeautifulSoup
import requests
import bs4
url = "https://scraping-for-beginner.herokuapp.com/ranking/"
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser") # "html.parser"⇒htmlの構造を解析するもの。
spots = soup.find_all("div",attrs = {"class":"u_areaListRankingBox"}) #その全体の中から欲しい情報があるエリアを絞る。
spots
これも前回と同じ通り。前回の手順③をご参照くださいませ。このように元となる要素を取得してください。
#spots #全体
spots[0] #1番目
#spots[1] #2番目
前回はspot[0]のみでしたが、今回はspot全体から要素を取ってくることです。
それを踏まえて②へ進みましょう
②段階。ひとまず全体から俯瞰。
これは結論のコードを先に提示した方がイメージがわくかもしれません。
data = []
#観光地名
spots = soup.find_all("div",attrs = {"class":"u_areaListRankingBox"}) #特定の部分を抜き出し。
for spot in spots:
spot_name = spot.find_all("div",attrs = {"class":"u_title col s12"})
spot_name[0].find("span",attrs = {"class": "badge"}).extract() #邪魔な要素を排除。
spot_name[0] = spot_name[0].text.replace("\n","") #ここでようやく観光地1をget
#評価点
eval_num = spot.find("div",attrs = {"class":"u_rankBox col s12"}).text
eval_num = float(eval_num.replace("\n",""))
categoryItems = spot.find_all("div",attrs = {"class":"u_categoryTipsItem col s12"})
# categoryItems = categoryItems[0].find_all("dl")
categoryItems = categoryItems[0].find_all("dl")
details = {}
for categoryItem in categoryItems:
category = categoryItem.dt.text
rank = float(categoryItem.span.text)
details[category] =rank
details["観光地名"] = spot_name
details["評価点"] = eval_num
data.append(details)
…見覚えがあるコードですよね?「前回とほとんど変わらないじゃん…と」。
更に分かりやすく理解して頂く為、両者を比較を提示致します。是非画像を拡大してご覧いただければ。
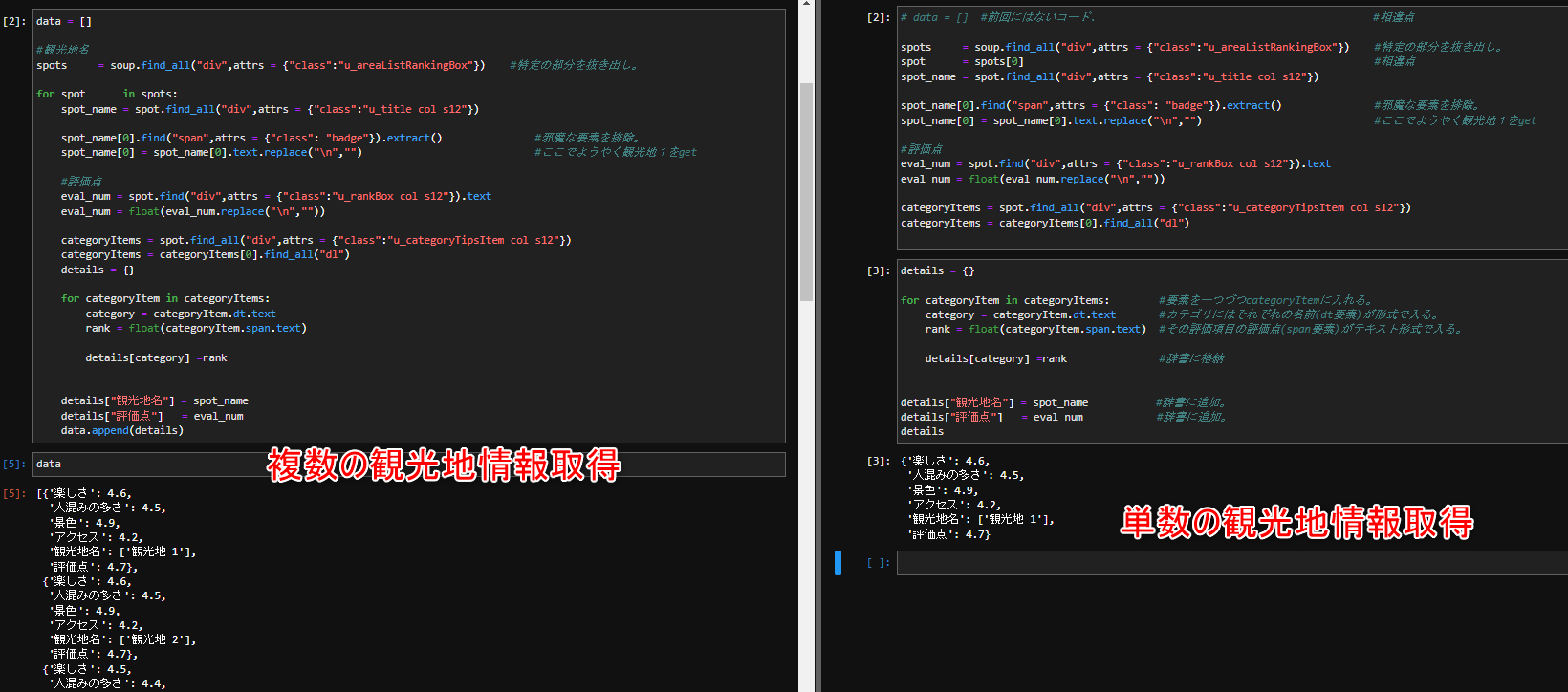
それでは間違い探しです。違いはどこでしょうか?
答えは2~3個程度です。data = []があったりfor文と段落、コードブロックの分け方位でしょうか。なんだか出来そうな気がしませんか![]() ?
?
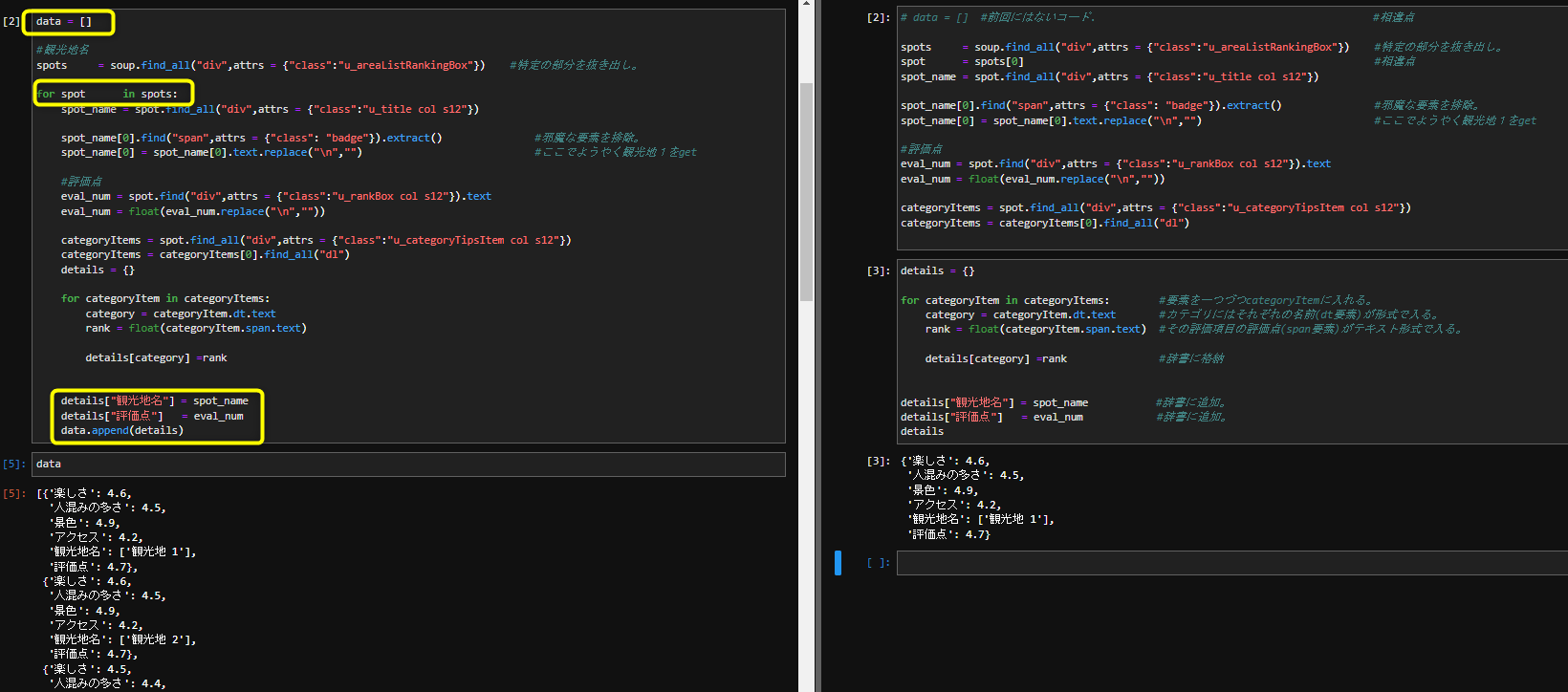
③相違点の詳細確認
#複数取得ver
data = []
#観光地名
for spot in spots:
#単数取得ver
spot = spots[0]
ご覧の通り、複数取得はfor文ですね。dataというインスタンス(箱)を作成して1周したら、その内容を箱に詰めてもう1周という事ですね。
- 単数取得を完成させる。⇒それを繰り返す。
このようなイメージをして頂ければ。
他にも後半も段落が異なります。
#単数取得
details = {}
for categoryItem in categoryItems: #要素を一つづつcategoryItemに入れる。
category = categoryItem.dt.text #カテゴリにはそれぞれの名前(dt要素)が形式で入る。
rank = float(categoryItem.span.text) #その評価項目の評価点(span要素)がテキスト形式で入る。
details[category] =rank #辞書に格納
details["観光地名"] = spot_name #辞書に追加。
details["評価点"] = eval_num #辞書に追加。
details
#複数取得
for categoryItem in categoryItems:
category = categoryItem.dt.text
rank = float(categoryItem.span.text)
details[category] =rank
details["観光地名"] = spot_name
details["評価点"] = eval_num
data.append(details)
複数取得の場合は観光地名と評価点もfor文の中に格納されています。
それらを踏まえた上でfor文の中にfor文がある内包表記の流れを確認してみます。
汚い画像ですがご了承ください
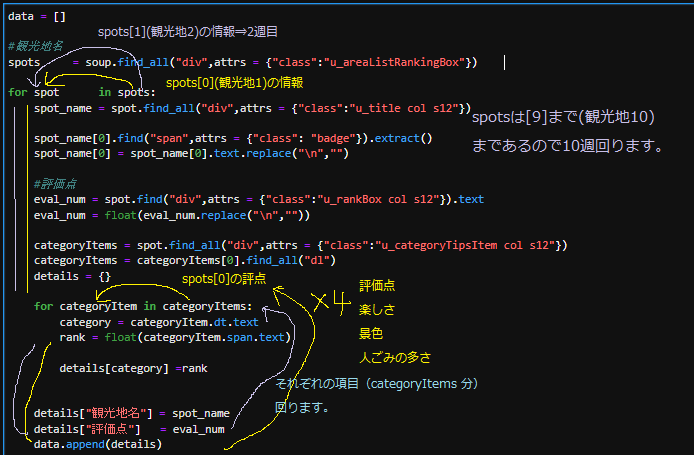
…いかがですかね?自分なりに分かりやすく説明したつもりなのですが、
かなり見栄えは悪いですね。
人に教えるスキルはまだ持ち合わせていなくて…。
④段階
こちらのコードは前回の⑥又は総まとめをご参照下さい。
要はdf化して出力しています。
import pandas as pd
df = pd.DataFrame(data)
df = df[['観光地名','評価点','楽しさ','景色','アクセス','人混みの多さ']]#カラム並び替え。
df
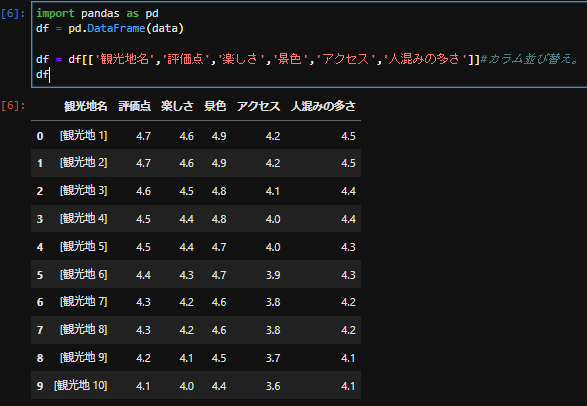
総まとめコード
# ライブラリやモジュールをimport
from bs4 import BeautifulSoup
import requests
import bs4
import pandas as pd
url = "https://scraping-for-beginner.herokuapp.com/ranking/"
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser") # "html.parser"⇒htmlの構造を解析するもの。
data = []
#観光地名
spots = soup.find_all("div",attrs = {"class":"u_areaListRankingBox"})
for spot in spots:
spot_name = spot.find_all("div",attrs = {"class":"u_title col s12"})
spot_name[0].find("span",attrs = {"class": "badge"}).extract()
spot_name[0] = spot_name[0].text.replace("\n","")
#評価点
eval_num = spot.find("div",attrs = {"class":"u_rankBox col s12"}).text
eval_num = float(eval_num.replace("\n",""))
categoryItems = spot.find_all("div",attrs = {"class":"u_categoryTipsItem col s12"})
categoryItems = categoryItems[0].find_all("dl")
details = {}
for categoryItem in categoryItems:
category = categoryItem.dt.text
rank = float(categoryItem.span.text)
details[category] =rank
details["観光地名"] = spot_name
details["評価点"] = eval_num
data.append(details)
df = pd.DataFrame(data)
df = df[['観光地名','評価点','楽しさ','景色','アクセス','人混みの多さ']]#カラム並び替え。
df
終わりに。
所処説明が冗長になってしまい申し訳ございません。
自分の説明スキルの無さを自覚する事もありましたが、
まだ初めて間もないのでとりあえず数をこなしたいと思います。
ポイントとして
- 苦労して単数取得できればfor文を回してまとめてとる事が出来る。
- その為には構造を見抜くhtml読解力とfor文に親しむ事。(内包表記も)
課題としては
- for文や長いコードの際には人に分かりやすく説明文字起こしができていない実感がある。
- 果たしてこのfor文を応用して別のサイトからスクレイピングをする事が出来るのか?練習を重ねる事。
- スクレイピングとfor文は相性が良い。他の内包表記やlambda式も用いてスクレイピングができるようになること。
次回は画像をまとめて取得と思います。勿論こちらのサイトで。