はじめに
どうも。スクレイピング歴10日の初心者です。
本日もスクレイピングを勉強したので学習内容をQiitaにまとめます。
環境
beautifulsoup4
windows11
jupyterlab
本記事の趣旨
beautifulsoup4を用いてサイトのURLの一括取得方法を学習したので忘備録兼シェア致します。
バックナンバー
- 初学者が勉強するSelenium。①
- 初学者が勉強するSelenium。②
- seleniumはCopy_full_xpathで少し楽になる
- 初学者が勉強するBeautiful Soup①
- 初学者が勉強するBeautiful Soup②
- Beautiful Soupで画像を取得
- BeautifulSoupでURLを一括取得
- 複数ページにわたる情報の取得。スクレイピング。
- 複数に渡るページでの画像収集スクレイピング
教材
上記の動画27分40秒辺りからの内容です。
下記の記事は私がアウトプットの為にまとめたbeautiful soupの記事です。
目標
- こちらのサイト内のURLをまとめて取得したい。
- 他にも条件により取得したいサイトを厳選したい。
最終的にはこのようなdfを取得することを目標とします。
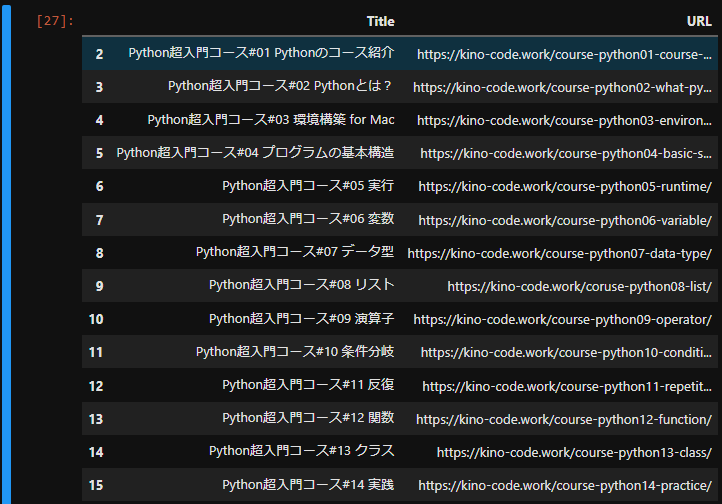
学習
それでは順々に学習していきましょう。
段階① モジュールのインポートと要素の確認
# ライブラリやモジュールをimport
from bs4 import BeautifulSoup
import requests
import bs4
import pandas as pd
今回学習用に用いるサイトのurlを取得します。
url = "https://kino-code.work/python-scraping/"
res = requests.get(url)
res
と返ってきたらここまで正常に動作しております。
取得したurlのhtml情報を確認します。このhtmlの中から必要な情報を抽出しましょう。
parse_html = BeautifulSoup(res.text, "html.parser")
print(parse_html.prettify())
#結果
<!DOCTYPE html>
<html lang="ja">
<head>
<script async="" src="https://www.googletagmanager.com/gtag/js?id=UA-140862964-1">
</script>
<script>
・
・
・
htmlの情報を取得することが出来ました。しかしこのままでは多すぎるのでaタグのみ取得します。htmlの構造上、urlはaタグに含まれているのでその部分を一括取得します。

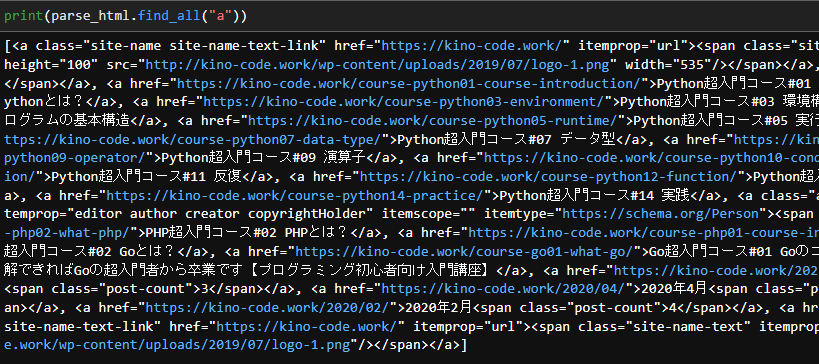
print(parse_html.find_all("a"))
いかがでしょうか。実行結果に大量のaタグが表示されたと思います。
find_allはbeautiful soupで取得したurlの中から指定した要素を一括取得するメソッドです。
取得した要素はリストにて返されます。
ひとまずこれらaタグの束を変数に格納しましょう。
title_lists = parse_html.find_all("a")
段階② 要素の取得
find_allで抽出したのでtitle_listsはリスト型です。それぞれの内容を確認してみましょう。
.string/.textでテキストのみを抽出する事が出来ます。
title_lists[3].string
title_lists[4].string
title_lists[5].string
#結果
Python超入門コース#02 Pythonとは?
Python超入門コース#03 環境構築 for Mac
Python超入門コース#04 プログラムの基本構造
リストなので今度はfor文を用いて全て抽出してみます。
for a in title_lists:
print(a.string)
#結果
None
ホーム
Python超入門コース#01 Pythonのコース紹介
Python超入門コース#02 Pythonとは?
Python超入門コース#03 環境構築 for Mac
Python超入門コース#04 プログラムの基本構造
Python超入門コース#05 実行
Python超入門コース#06 変数
Python超入門コース#07 データ型
Python超入門コース#08 リスト
Python超入門コース#09 演算子
Python超入門コース#10 条件分岐
Python超入門コース#11 反復
Python超入門コース#12 関数
Python超入門コース#13 クラス
Python超入門コース#14 実践
キノコード
PHP超入門コース#02 PHPとは?
PHP超入門コース#01コース紹介
Go超入門コース#02 Goとは?
Go超入門コース#01 Goのコース紹介
【Go言語 超入門コース】15.実践|すべて理解できればGoの超入門者から卒業です【プログラミング初心者向け入門講座】
None
None
None
None
None
None
None
いくつかNoneがありましたが、aタグの文字列の部分のみ抽出する事が出来ました。
同じ要領でurlの部分も抽出してみましょう。
for a in title_lists:
print(a.attrs["href"])
#結果
https://kino-code.work/
https://kino-code.work
https://kino-code.work/course-python01-course-introduction/
https://kino-code.work/course-python02-what-python/
https://kino-code.work/course-python03-environment/
https://kino-code.work/course-python04-basic-structure/
https://kino-code.work/course-python05-runtime/
https://kino-code.work/course-python06-variable/
https://kino-code.work/course-python07-data-type/
https://kino-code.work/coruse-python08-list/
https://kino-code.work/course-python09-operator/
https://kino-code.work/course-python10-conditional-branch/
https://kino-code.work/course-python11-repetition/
https://kino-code.work/course-python12-function/
https://kino-code.work/course-python13-class/
https://kino-code.work/course-python14-practice/
https://kino-code.work/author/kino_tsurayasu/
https://kino-code.work/course-php02-what-php/
https://kino-code.work/course-php01-course-introduction-2/
https://kino-code.work/course-go02-what-go-2/
https://kino-code.work/course-go01-what-go/
https://kino-code.work/course-go15-practice/
https://kino-code.work/2021/10/
https://kino-code.work/2020/05/
https://kino-code.work/2020/04/
https://kino-code.work/2020/03/
https://kino-code.work/2020/02/
https://kino-code.work/2020/01/
https://kino-code.work/
urlのみを抽出する事が出来ました。
どちらもfor文の基本で、
- title_listsの中にある複数の要素(aタグ)を一つ変数aに格納する
- それら一つづつをを文字列のみ/urlのみ状態にする
- printで表示する
- 一つ終わったら次の一つに回る
とのプロセスで回っております。
段階③ for文で効率良く要素の取得
まずは初めにインスタンス(入れ物)を作成します。この中に名前やurlが格納されます。
その後にfor文を構築していきましょう。このような記述はいかがでしょうか?
name_list = [] #nameインスタンスの作成
url_list = [] #url インスタンスの作成
for i in title_lists: #for文で1つづつ要素を回す。
name_list.append(i.string) #title_listに回ってきた要素のテキストのみ状態を格納
url_list.append(i.attrs["href"]) #name_list に回ってきた要素のurlのみ状態を格納
コメントで解説も加えておきました。for文は私のようなプログラミング初心者には中々とっつきにくいですので。とにかく、これでリストの中にはそれぞれの要素が格納されているはずです。
最後にこのリスト2つを辞書型にして出力しましょう。
#辞書のkeyにname_listを格納し名前は"Title"、valueにurl_listを格納し名前は"URL"としています。
df_name_url = pd.DataFrame({"Title":title_list, "URL":url_list})
df_name_url
ここまでのまとめ。
必要な部分のみ記載しております。
from bs4 import BeautifulSoup
import requests
import bs4
import pandas as pd
url = "https://kino-code.work/python-scraping/"
res = requests.get(url)
parse_html = BeautifulSoup(res.text, "html.parser")
title_lists = parse_html.find_all("a")
name_list = []
url_list = []
for i in title_lists:
name_list.append(i.string)
url_list.append(i.attrs["href"])
df_title_url = pd.DataFrame({"Title":name_list, "URL":url_list})
df_title_url
段階④ 取得要素の確認
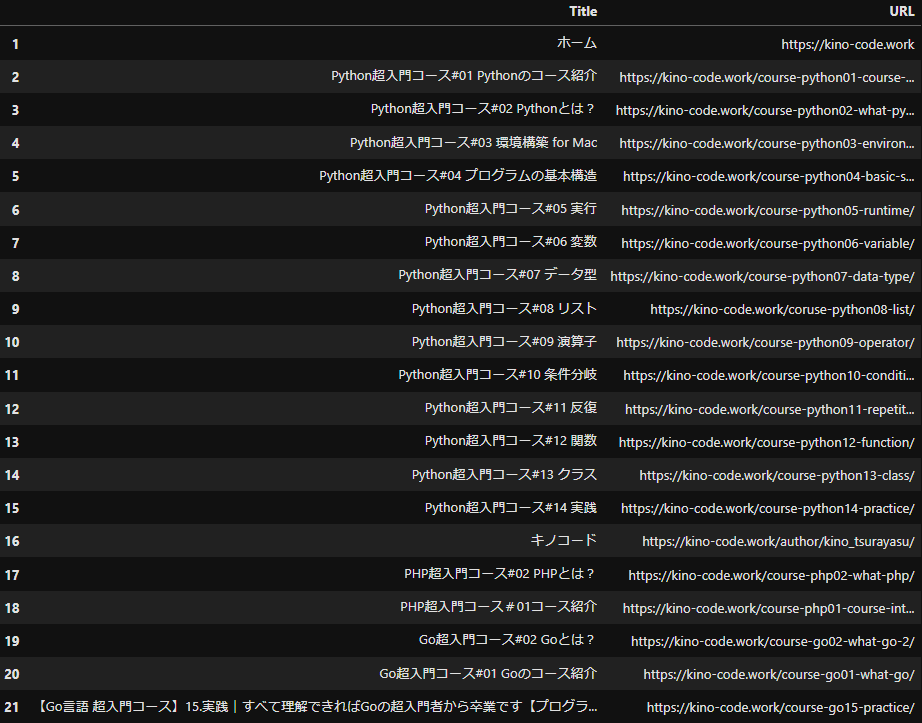
#欠損値の削除
df_title_url = df_title_url.dropna(how='any')
df_title_url
これでnoneは削除されました。dropnaは欠損値Nanを削除するメソッドです。
そして()の中の引数anyですが、欠損値が一つでも含まれる行が削除されるというオプションです。因みにhow='any'はデフォルトなので()の引数は何もなしでも大丈夫です。
- 結果
段階⑤ 取得要素の絞り込み
#pythonのみ抽出
df_title_url = df_title_url[df_title_url['Title'].str.contains('Python')]
df_title_url
このコードではいかがでしょうか?
結果を表示します。
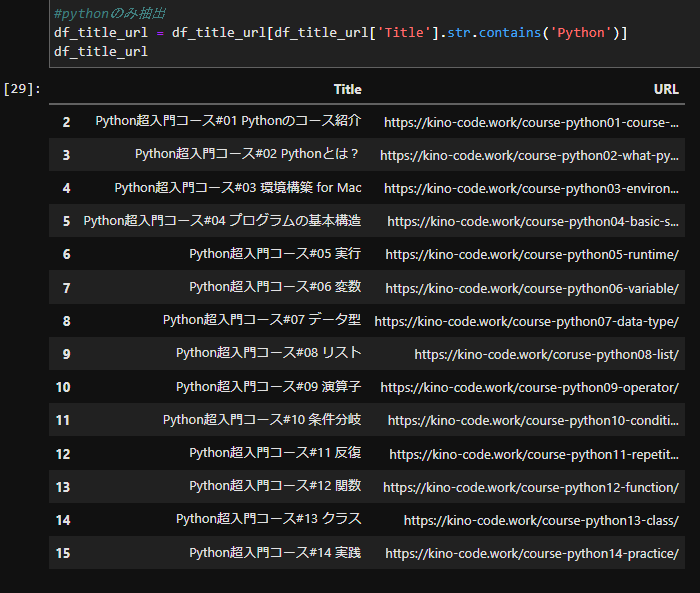
かなりまとまった結果になりました。今回はこれでゴールとします。
追伸:上記のコードdf_title_url = df_title_url[df_title_url['Title'].str.contains('Python')] は私自身、理解が曖昧であった為、補足説明致します。
まずは、df_title_url['Title'].str.contains('Python')とはどのような意味でしょうか?
これはdfであるdf_title_urlのカラム"Title"の中に文字列"python"が含まれているもの という意味です。実際に実行してみましょう。
df_title_url_python = df_title_url['Title'].str.contains('Python')
df_title_url_python
結果
画像の通り、bool型を返し、判断は可能です。しかし目的は異なりますよね。
目的はそのtrueの要素を抽出してdfにしたい。という事です。
その為にはこのように
df_title_url_python = [df_title_url['Title'].str.contains('Python')]
df_title_url_python
[]で括る必要があります。そうすれば、bool型でtrueのみ抽出してdfに起こす事が出来ます。
総まとめのコード
from bs4 import BeautifulSoup
import requests
import bs4
import pandas as pd
url = "https://kino-code.work/python-scraping/"
res = requests.get(url)
parse_html = BeautifulSoup(res.text, "html.parser")
title_lists = parse_html.find_all("a")
name_list = []
url_list = []
for i in title_lists:
name_list.append(i.string)
url_list.append(i.attrs["href"])
df_title_url = pd.DataFrame({"Title":name_list, "URL":url_list})
df_title_url
#欠損値の削除
df_title_url = df_title_url.dropna(how='any')
df_title_url
#pythonのみ抽出
df_title_url = df_title_url[df_title_url['Title'].str.contains('Python')]
df_title_url
終わりに
今回はスクレイピングを楽しく学び、業務に役立てる気配を感じました。
しかし具体的にはどのようにスクレイピング技術を役立てられるかはまだ思いつかず模索中です。
そしてfor文やpandasの1部もスクレイピングを学習し、Qiitaにまとめるまでは理解しにくい所もあったのですが、その部分も浮き彫りにして解消できて何よりでした。
近々の目標はスクレイピングの技術を用いて簡単なアプリや自動化のシステムを作成する事です。