はじめに
どうも。スクレイピング歴9日の初心者です。
本日もスクレイピングを勉強したので学習内容をQiitaにまとめます。
環境
selenium==4.3.0
windows11
jupyterlab
本記事の趣旨
selemiumのスクレイピングにて従来行っていた方法よりも少し楽になる方法を見つけたので忘備録もかねてシェア致します。
バックナンバー
- 初学者が勉強するSelenium。①
- 初学者が勉強するSelenium。②
- seleniumはCopy_full_xpathで少し楽になる
- 初学者が勉強するBeautiful Soup①
- 初学者が勉強するBeautiful Soup②
- 初学者が勉強するBeautiful Soup②
- Beautiful Soupで画像を取得
- BeautifulSoupでURLを一括取得
- 複数ページにわたる情報の取得。スクレイピング。
- 複数に渡るページでの画像収集スクレイピング
教材
学習
selemiumにてwebブラウザを検証で場所を指定する時、少し面倒くさく感じませんか?
elem_pass = browser.find_element('id',"password")
elem_username = browser.find_element('name',"username")
elem_click = browser.find_element('id',"login-btn")
selemium4では毎回idやnameを探して上記のように引数に当てはめなければならないですよね。
私はこれが大変でした。
- idやname等場所を指定する要素を探す苦労。
- それらしい物を入力して引数に当てはめても実行できるかの不安。
この課題の解決方法の一種を学びましたので記載します。
単一取得で使用できる事を確認致しました。findのみで、find_allはできませんでした。
方法
結論 ⇒ 単一指定なら Copy_full_xpath
それでは手順を紹介します。今回は下記サイトを使用します。
いつも通り「検証」で場所を指定します。ここまでは一緒です。
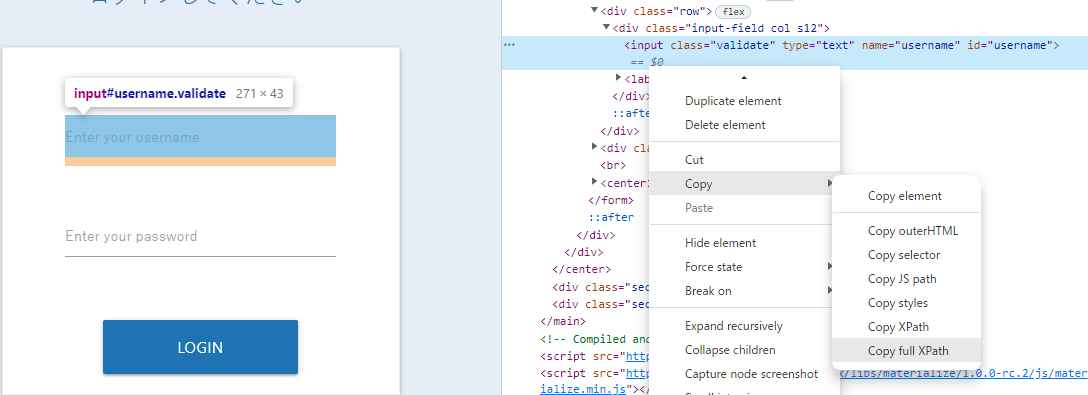
しかしここからidやname(場合によってはclass)等のどれを選んで情報を入力するのか少し悩むわけです。この場合、単一指定ならばひとまずCopy_full_xpathで取得して貼り付けるのはいかがでしょうか?
これが
elem_pass = browser.find_element('id',"password")
elem_username = browser.find_element('name',"username")
elem_click = browser.find_element('id',"login-btn")
こうなります。当然動作は同一です。
elem_pass = browser.find_element("xpath","/html/body/main/center/div[2]/div/form/div[3]/div/input")
elem_username = browser.find_element("xpath","/html/body/main/center/div[2]/div/form/div[2]/div/input")
elem_click = browser.find_element("xpath","/html/body/main/center/div[2]/div/form/center/div/button")
- 第一引数に"xpath"と指定する
- 第二引数に Copy_full_xpath で取得した情報をコピペする。
方法としてはかなりシンプルになりました。
長所と短所。
この方法における現時点で思いつく長所、短所を記載します。
長所
- 操作方法が簡単
- idやname,classを探す手間が省ける
- 要素を見つけられない時でも使用できる。
短所
- スマートじゃない。
- 慣れている人ではid/name等を第一引数とした方が可読性が高い?
- htmlの構造への理解が遅くなる。
といったところでしょうか。
最後に
要素を見つけられない時とはどのような場合かを一緒に確認してみましょう。
例えばこのページの「ダウンロード」には要素(idやname)が見つかりません。この場合ではbrowser.find_element("xpath",~~~)が役立ちそうです。
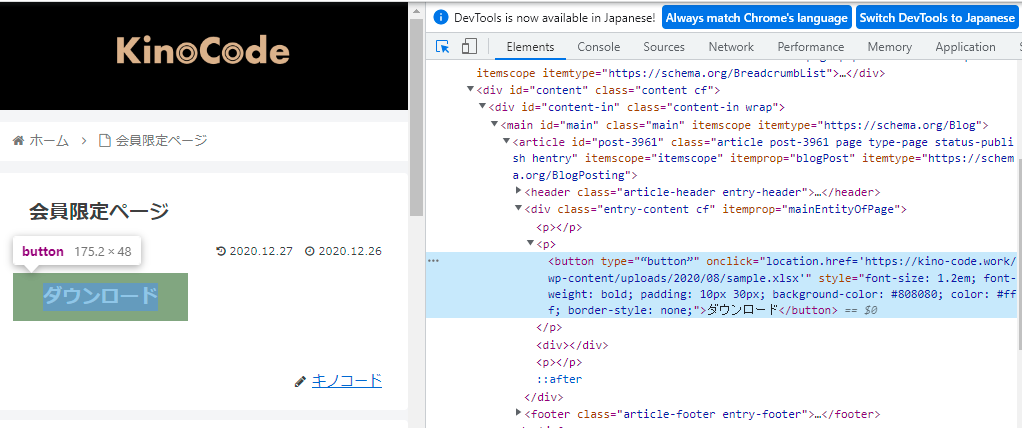
- このページにたどり着けない場合はログインを経て再度アクセスして頂ければと思います。
USER = 'test_user' #ログインする際のユーザー名
PASS = 'test_pw' #ログインする際のpass名
総まとめのコード
こちらが従来のやり方で取得したもので、
#モジュールのインポート
!pip install selenium
from selenium import webdriver
from time import sleep
import pandas as pd
browser = webdriver.Chrome("C:/****/****/Desktop/Jupyter/lab/スクレイピング/chromedriver.exe")
url = "https://scraping-for-beginner.herokuapp.com/login_page"
browser.get(url)
elem_username = elem_username = browser.find_element('id',"username")
elem_username.clear()
elem_username.send_keys('imanishi')
elem_pass = browser.find_element('name',"password")
elem_pass.clear()
elem_pass.send_keys('kohei')
elem_click = browser.find_element('id',"login-btn")
elem_click.click()
こちらが"xpath"とCopy_full_xpathを用いたものです。
#モジュールのインポート
!pip install selenium
from selenium import webdriver
from time import sleep
import pandas as pd
#ブラウザの起動⇒成功
browser = webdriver.Chrome("C:/****/user/Desktop/Jupyter/lab/スクレイピング/chromedriver.exe")
#お好きなURLを指定してアクセス
url = "https://scraping-for-beginner.herokuapp.com/login_page"
browser.get(url)
elem_username = browser.find_element('xpath',"/html/body/main/center/div[2]/div/form/div[2]/div/input")
elem_username.send_keys('imanishi')
elem_pass = browser.find_element('xpath',"/html/body/main/center/div[2]/div/form/div[3]/div/input")
elem_pass.send_keys('kohei')
elem_click = browser.find_element('xpath',"/html/body/main/center/div[2]/div/form/center/div/button")
elem_click.click()
皆様はどちらを使用なさいますか。
終わりに
いかがでしょうか?簡単ですが、要素の単一取得の際に使用できるxpathとCopy_full_xpathを紹介させて頂きました。
この調子でアンテナを広げて使用できる武器を増やし整理していければと常々思います。